Scala
ERDDAP™ - Caricamenti pesanti, Griglia, cluster, federazioni e cloud computing
ERDDAP :
ERDDAP™ è un'applicazione web e un servizio web che aggrega i dati scientifici provenienti da diverse fonti locali e remote e offre un modo semplice e coerente per scaricare sottoinsiemi dei dati in formati di file comuni e fare grafici e mappe. Questa pagina web parla di questioni relative a pesanti ERDDAP™ i carichi di utilizzo ed esplora le possibilità di trattare carichi estremamente pesanti tramite griglie, cluster, federazioni e cloud computing.
La versione originale è stata scritta nel giugno 2009. Non ci sono stati cambiamenti significativi. Ultimo aggiornamento 2019-04-15.
DISCLAI
I contenuti di questa pagina web sono opinioni personali di Bob Simons e non riflettono necessariamente alcuna posizione del Governo o del National Oceanic and Atmospheric Administration . I calcoli sono semplicistici, ma credo che le conclusioni siano corrette. Ho usato la logica difettosa o ho commesso un errore nei miei calcoli? Se è così, la colpa è mia da sola. Si prega di inviare una e-mail con la correzione a erd dot data at noaa dot gov .
-
- No.
Carico pesante / vincoli
Con un uso pesante, un standalone ERDDAP™ sarà limitato (da più a meno probabile) di:
Larghezza di banda a distanza
- Larghezza di banda di una fonte di dati remota — Anche con una connessione efficiente (ad esempio, via OPeNDAP ) , a meno che una fonte di dati remota abbia una connessione Internet molto alta larghezza di banda, ERDDAP "le risposte saranno limitate da quanto velocemente ERDDAP™ può ottenere i dati dalla fonte di dati. Una soluzione è quella di copiare il dataset ERDDAP Il disco rigido, forse con EDDGrid Copia o EDDTableCopy .
ERDDAP Larghezza di banda del server
- A meno che ERDDAP Il server ha una connessione Internet ad alta larghezza di banda, ERDDAP "le risposte saranno limitate da quanto velocemente ERDDAP™ può ottenere i dati dalle fonti di dati e quanto velocemente ERDDAP™ può restituire i dati ai clienti. L'unica soluzione è quella di ottenere una connessione Internet più veloce.
Memoria
- Se ci sono molte richieste simultanee, ERDDAP™ può esaurire la memoria e rifiutare temporaneamente nuove richieste. ( ERDDAP™ ha un paio di meccanismi per evitare questo e per minimizzare le conseguenze se accade.) Quindi più memoria nel server è migliore. Su un server a 32 bit, 4+ GB è davvero buono, 2 GB va bene, meno non è raccomandato. Su un server a 64 bit, si può quasi completamente evitare il problema ottenendo un sacco di memoria. Vedi il Impostazioni \-Xmx e -Xms per ERDDAP - Tomcat. An ERDDAP™ ottenere un uso pesante su un computer con un server a 64 bit con 8GB di memoria e -Xmx impostato a 4000M è raramente, se mai, limitato dalla memoria.
Larghezza di trasmissione
- L'accesso ai dati memorizzati sul disco rigido del server è molto più veloce dell'accesso ai dati remoti. Anche così, se il ERDDAP™ server ha una connessione Internet molto alta larghezza di banda, è possibile che l'accesso ai dati sul disco rigido sarà un collo di bottiglia. Una soluzione parziale è quella di utilizzare più velocemente (ad esempio, 10.000 RPM) dischi rigidi magnetici o unità SSD (se ha senso il costo) . Un'altra soluzione è quella di memorizzare diversi set di dati su diverse unità, in modo che la larghezza di banda del disco rigido cumulativa è molto più alta.
Troppi file incassati
- Troppi file in un cache elenco ERDDAP™ memorizza tutte le immagini, ma memorizza solo i dati per determinati tipi di richieste di dati. È possibile che la directory della cache per un set di dati abbia un gran numero di file temporaneamente. Questo rallenterà le richieste per vedere se un file è nella cache (Davvero!) .<cache Minuti > in setup.xml consente di impostare quanto tempo un file può essere nella cache prima che venga eliminato. Impostare un numero più piccolo ridurrebbe questo problema.
CPU
- Solo due cose richiedono molto tempo della CPU:
- NetCDF 4 e HDF 5 ora supportano la compressione interna dei dati. Decomprimere un grande compresso NetCDF 4 / HDF 5 file di dati possono richiedere 10 o più secondi. (Non e' colpa dell'implementazione. E' la natura della compressione.) Così, più richieste simultanee di set di dati con i dati memorizzati in file compressi possono mettere una forte tensione su qualsiasi server. Se questo è un problema, la soluzione è quella di memorizzare i dataset popolari in file non compressi, o ottenere un server con una CPU con più core.
- Creazione di grafici (comprese le mappe) : circa 0,2 - 1 secondo per grafico. Quindi, se ci sono state molte richieste simultanee uniche per i grafici ( WMS i clienti spesso fanno 6 richieste simultanee!) , ci potrebbe essere una limitazione della CPU. Quando più utenti sono in esecuzione WMS clienti, questo diventa un problema.
-
- No.
Identica multipla ERDDAP s con il bilanciamento del carico?
La domanda viene spesso: "Per affrontare carichi pesanti, posso impostare più identici ERDDAP s con bilanciamento del carico?" È una domanda interessante perché arriva rapidamente al centro di ERDDAP Il design. La risposta rapida è "no". So che è una risposta deludente, ma ci sono un paio di ragioni dirette e alcune ragioni fondamentali più grandi per cui ho progettato ERDDAP™ utilizzare un approccio diverso (una federazione ERDDAP s, descritto nella maggior parte di questo documento) , che credo sia una soluzione migliore.
Alcuni motivi diretti perché non è possibile / non deve impostare più identico ERDDAP sono:
- Un dato ERDDAP™ legge ogni file di dati quando diventa disponibile per la prima volta per trovare gli intervalli di dati nel file. Poi memorizza quelle informazioni in un file di indice. Più tardi, quando viene richiesta un utente per i dati, ERDDAP™ utilizza tale indice per capire quali file cercare per i dati richiesti. Se c'era più identico ERDDAP s, ognuno farebbe questo indicizzazione, che è sprecato sforzo. Con il sistema federato descritto di seguito, l'indicizzazione è fatta solo una volta, da uno dei ERDDAP S.
- Per alcuni tipi di richieste degli utenti (ad esempio, per .nc , .png, .pdf file) ERDDAP™ deve fare l'intero file prima che la risposta possa essere inviata. Quindi... ERDDAP™ memorizza questi file per un breve periodo di tempo. Se viene richiesta identica (come spesso fa, soprattutto per le immagini in cui l'URL è incorporato in una pagina web) ♪ ERDDAP™ può riutilizzare quel file cache. In un sistema di più identico ERDDAP s, quei file memorizzati nella cache non sono condivisi, quindi ogni ERDDAP™ sarebbe inutilmente e sprecato ricreare .nc , .png, o file .pdf. Con il sistema federato descritto di seguito, i file sono fatti solo una volta, da uno dei ERDDAP s, e riutilizzato.
- ERDDAP Il sistema di abbonamento non è configurato per essere condiviso da più ERDDAP S. Ad esempio, se il bilanciatore di carico invia un utente a uno ERDDAP™ e l'utente si iscrive a un dataset, poi l'altro ERDDAP non sarà a conoscenza di quell'abbonamento. Più tardi, se il bilanciatore di carico invia l'utente a un diverso ERDDAP™ e chiede una lista dei suoi abbonamenti, gli altri ERDDAP™ dirà che non ci sono (che lo conduce a fare un abbonamento duplicato sull'altro ERED DAP ) . Con il sistema federato descritto di seguito, il sistema di abbonamento è gestito semplicemente dal principale, pubblico, composito ERDDAP .
Sì, per ognuno di questi problemi, potrei (con grande sforzo) progettare una soluzione (condividere le informazioni tra ERDDAP #) ma penso che federazione ERDDAP approccio (descritto nella maggior parte di questo documento) è una soluzione complessiva molto migliore, in parte perché si occupa di altri problemi che il multi-identico- ERDDAP l'approccio s-with-a-load-balancer non inizia nemmeno ad affrontare, in particolare la natura decentralizzata delle fonti di dati nel mondo.
È meglio accettare il semplice fatto che non ho progettato ERDDAP™ da distribuire come più identico ERDDAP s con un bilanciatore di carico. Ho progettato consapevolmente ERDDAP™ lavorare bene all'interno di una federazione ERDDAP s, che credo abbia molti vantaggi. In particolare, una federazione ERDDAP s è perfettamente allineato con il sistema decentralizzato e distribuito di data center che abbiamo nel mondo reale (pensare alle diverse regioni IOOS, o alle diverse regioni CoastWatch, o alle diverse parti di NCEI, o agli altri 100 data center in NOAA , o i diversi DAAC della NASA, o i 1000 di data center in tutto il mondo) . Invece di dire a tutti i data center del mondo che hanno bisogno di abbandonare i loro sforzi e mettere tutti i loro dati in un "lago dati" centralizzato (anche se fosse possibile, è un'idea orribile per numerosi motivi -- vedere le varie analisi che mostrano i numerosi vantaggi di sistemi decentralizzati ) ♪ ERDDAP Il design funziona con il mondo così com'è. Ogni data center che produce dati può continuare a mantenere, curare e servire i propri dati (come dovrebbero) , e ancora, con ERDDAP™ , i dati possono essere immediatamente disponibili da un centralizzato ERDDAP , senza la necessità di trasmettere i dati al centralizzato ERDDAP™ o la memorizzazione di copie duplicate dei dati. Infatti, un dato set di dati puÃ2 essere disponibile simultaneamente da un ERDDAP™ all'organizzazione che ha prodotto e in realtà memorizza i dati (ad esempio, GoMOOS) ♪ da un ERDDAP™ all'organizzazione genitoriale (ad esempio, IOOS centrale) ♪ da un tutto... NOAA ERDDAP™ ♪ da un governo all-US-federale ERDDAP™ ♪ da un mondo globale ERDDAP™ (GOOS) ♪ e da specialisti ERDDAP # (ad esempio, un ERDDAP™ presso un istituto dedicato alla ricerca HAB) ♪ tutto essenzialmente istantaneamente ed efficiente perché solo i metadati vengono trasferiti tra ERDDAP s, non i dati. Meglio di tutti, dopo l'iniziale ERDDAP™ all'organizzazione originaria, tutte le altre ERDDAP s può essere impostato rapidamente (poche ore di lavoro) , con risorse minime (un server che non ha bisogno di RAID per l'archiviazione dei dati in quanto non memorizza dati localmente) , e quindi a costo veramente minimo. Confrontare che al costo di configurare e mantenere un centro dati centralizzato con un lago di dati e la necessità di una connessione Internet veramente massiccia, veramente costosa, più il problema del data center centralizzato è un unico punto di fallimento. A me, ERDDAP l'approccio decentralizzato e federato è di gran lunga superiore.
In situazioni in cui un data center ha bisogno di più ERDDAP s per soddisfare l'alta domanda, ERDDAP Il design è pienamente in grado di abbinare o superare le prestazioni del multi-identico- ERDDAP approccio s-with-a-load-balancer. Hai sempre la possibilità di configurare multipli compositi ERDDAP # (come discusso di seguito) , ognuno dei quali ottiene tutti i loro dati da altri ERDDAP s, senza bilanciamento del carico. In questo caso, vi consiglio di fare un punto di dare ciascuno dei compositi ERDDAP s un nome / identità diverso e se possibile impostarli in diverse parti del mondo (ad esempio, diverse regioni AWS) Per esempio, ERD \_US\_East, ERD \_US\_West, ERD \_IE, ERD \_FR, ERD \_IT, in modo che gli utenti consapevolmente, ripetutamente, lavorare con uno specifico ERDDAP , con il beneficio aggiunto che hai rimosso il rischio da un unico punto di fallimento.
-
- No.
Griglia, cluster e federazioni
Sotto un uso molto pesante, un singolo standalone ERDDAP™ verrà eseguito in uno o più dei vincoli elencati sopra e anche le soluzioni suggerite saranno insufficienti. Per tali situazioni, ERDDAP™ ha caratteristiche che rendono facile la costruzione di griglie scalabili (anche chiamati cluster o federazioni) di ERDDAP s che permettono al sistema di gestire un uso molto pesante (ad esempio, per un grande data center) .
Sto usando griglia come termine generale per indicare un tipo di cluster computer dove tutte le parti possono o non possono essere fisicamente situate in una struttura e possono o non possono essere gestite centralmente. Un vantaggio di griglie co-locate, di proprietà centrale e amministrate (cluster) che beneficiano di economie di scala (soprattutto il carico di lavoro umano) e semplificare rendendo le parti del sistema funzionano bene insieme. Un vantaggio di griglie non trasferite, non centralmente possedute e amministrate (federazioni) è che distribuiscono il carico di lavoro umano e il costo, e possono fornire qualche ulteriore tolleranza di guasto. La soluzione che propongo di seguito funziona bene per tutte le topografie di griglia, cluster e federazioni.
L'idea di base di progettare un sistema scalabile è identificare i potenziali colli di bottiglia e quindi progettare il sistema in modo che le parti del sistema possano essere replicate come necessario per alleviare i colli di bottiglia. Idealmente, ogni parte replicata aumenta la capacità di quella parte del sistema linearmente (efficienza di scaling) . Il sistema non è scalabile a meno che non vi sia una soluzione scalabile per ogni collo di bottiglia. Scalabilità è diverso dall'efficienza (come rapidamente un compito può essere fatto — efficienza delle parti) . La scalabilità consente al sistema di crescere per gestire qualsiasi livello di domanda. Efficienza (di scaling e delle parti) determina quanti server, ecc., saranno necessari per soddisfare un determinato livello di domanda. L'efficienza è molto importante, ma ha sempre dei limiti. La scalabilità è l'unica soluzione pratica per costruire un sistema in grado di gestire Molto bene. uso pesante. Idealmente, il sistema sarà scalabile ed efficiente.
Obiettivi
Gli obiettivi di questo design sono:
- Per fare un'architettura scalabile (una che è facilmente estensibile replicando qualsiasi parte che diventa sovraccarica) . Per rendere un sistema efficiente che massimizza la disponibilità e il throughput dei dati forniti alle risorse di calcolo disponibili. (Il costo è quasi sempre un problema.)
- Per bilanciare le capacità delle parti del sistema in modo che una parte del sistema non travolga un'altra parte.
- Per fare una semplice architettura in modo che il sistema sia facile da configurare e amministrare.
- Fare un'architettura che funziona bene con tutte le topografie della griglia.
- Fare un sistema che fallisce con grazia e in modo limitato se qualsiasi parte diventa sovraccaricata. (Il tempo necessario per copiare un grande dataset limiterà sempre la capacità del sistema di affrontare con improvvisi aumenti della domanda di un dataset specifico.)
- (Se possibile) Fare un'architettura che non è legata a qualsiasi specifica cloud computing servizio o altri servizi esterni (perché non ha bisogno di loro) .
Raccomandazione
Le nostre raccomandazioni
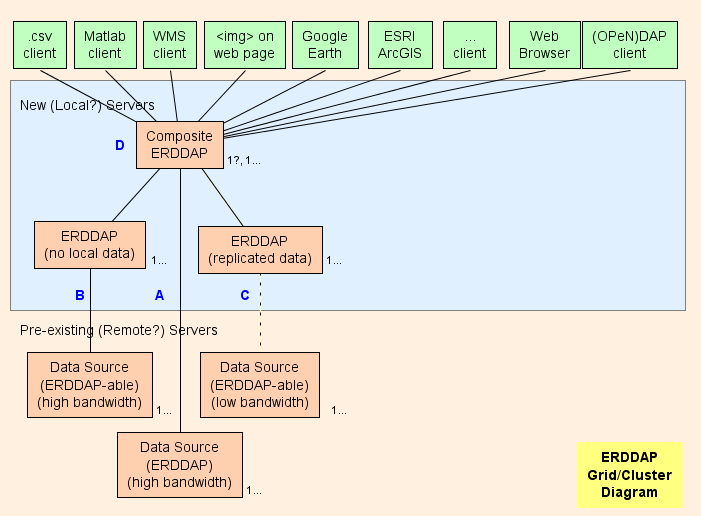
- Fondamentalmente, suggerisco di creare un composto ERDDAP™ ( D nel diagramma) , che è normale ERDDAP™ tranne che serve solo i dati da altri ERDDAP S. L'architettura della griglia è progettata per spostare il più possibile il lavoro (utilizzo della CPU, utilizzo della memoria, utilizzo della larghezza di banda) dal composito ERDDAP™ all'altro ERDDAP S.
- ERDDAP™ ha due tipi di dataset speciali, EDDGrid Da Erddap e EDDTableFromErddap , che si riferisce set di dati su altri ERDDAP S.
- Quando il composito ERDDAP™ riceve una richiesta di dati o immagini da questi dataset, il composito ERDDAP™ reindirizzamenti la richiesta di dati all'altro ERDDAP™ server. Il risultato è:
- Questo è molto efficiente (CPU, memoria e larghezza di banda) , perché altrimenti
- Il composito ERDDAP™ deve inviare la richiesta di dati all'altro ERDDAP .
- L'altro ERDDAP™ deve ottenere i dati, riformattare e trasmettere i dati al composito ERDDAP .
- Il composito ERDDAP™ deve ricevere i dati (usando larghezza di banda extra) # Riformalo # (utilizzando tempo e memoria CPU extra) , e trasmettere i dati all'utente (usando larghezza di banda extra) . Reindirizzando la richiesta di dati e consentendo all'altro ERDDAP™ inviare la risposta direttamente all'utente, il composito ERDDAP™ non passa essenzialmente tempo di CPU, memoria, o larghezza di banda sulle richieste di dati.
- Il reindirizzamento è trasparente per l'utente indipendentemente dal software client (un browser o qualsiasi altro software o strumento di riga di comando) .
- Questo è molto efficiente (CPU, memoria e larghezza di banda) , perché altrimenti
Parti di macinazione
A : Per ogni sorgente di dati remota che ha una larghezza di banda elevata OPeNDAP server, è possibile connettersi direttamente al server remoto. Se il server remoto è un ERDDAP™ , uso EDDGrid Da Erddap o EDDTableFrom ERDDAP per servire i dati nel composito ERDDAP . Se il server remoto è un altro tipo di DAP server, ad esempio, THREDDS, Hyrax , o GrADS, uso EDDGrid Da papa'.
B Per ogni ERDDAP - fonte di dati (una fonte di dati da cui ERDDAP può leggere i dati) che ha un server ad alta larghezza di banda, impostare un altro ERDDAP™ nella griglia che è responsabile per il servizio dei dati da questa fonte di dati.
- Se alcuni di questi ERDDAP s non stanno ottenendo molte richieste di dati, è possibile consolidarli in uno ERDDAP .
- Se ERDDAP™ dedicato a ottenere i dati da una fonte remota è ottenere troppe richieste, c'è la tentazione di aggiungere ulteriore ERDDAP s per accedere alla fonte di dati remota. In casi particolari questo può avere senso, ma è più probabile che questo travolga la fonte di dati remota (che è auto-defezione) e anche impedire ad altri utenti di accedere alla sorgente dati remota (che non è bello) . In tal caso, prendere in considerazione la creazione di un altro ERDDAP™ per servire tale dataset e copiare il dataset su quello ERDDAP Il disco rigido (vedi C ) , forse con EDDGrid Copia e/o EDDTableCopy .
- B i server devono essere accessibili pubblicamente.
C Per ogni ERDDAP -able data source che ha un server a bassa larghezza di banda (o è un servizio lento per altri motivi) , prendere in considerazione la creazione di un altro ERDDAP™ e memorizzare una copia del dataset su questo ERDDAP I dischi rigidi, forse con EDDGrid Copia e/o EDDTableCopy . Se alcuni di questi ERDDAP s non stanno ottenendo molte richieste di dati, è possibile consolidarli in uno ERDDAP . C i server devono essere accessibili pubblicamente.
Composito ERDDAP
D : Il composito ERDDAP™ è normale ERDDAP™ tranne che serve solo i dati da altri ERDDAP S.
- Perché il composito ERDDAP™ ha informazioni in memoria di tutti i dataset, può rispondere rapidamente alle richieste di elenchi di set di dati (ricerca di testo completo, categoria ricerche, l'elenco di tutti i set di dati) , e le richieste di un modulo di accesso dati di un singolo set di dati, fare un modulo di grafico, o WMS pagina delle informazioni. Queste sono tutte piccole, generate dinamicamente, pagine HTML basate su informazioni che si tengono in memoria. Quindi le risposte sono molto veloci.
- Poiché le richieste di dati effettivi sono rapidamente reindirizzate all'altro ERDDAP s, il composito ERDDAP™ può rispondere rapidamente alle richieste di dati reali senza utilizzare qualsiasi tempo della CPU, memoria o larghezza di banda.
- Spostando il più possibile il lavoro (CPU, memoria, larghezza di banda) dal composito ERDDAP™ all'altro ERDDAP s, il composito ERDDAP™ può apparire per servire i dati da tutti i dataset e ancora tenere il passo con un gran numero di richieste di dati da un gran numero di utenti.
- I test preliminari indicano che il composito ERDDAP™ può rispondere alla maggior parte delle richieste in ~1ms di tempo della CPU, o 1000 richieste/secondo. Quindi un processore di 8 core dovrebbe essere in grado di rispondere a circa 8000 richieste/secondo. Anche se è possibile prevedere scoppi di attività più alta che causerebbe rallentamenti, che è un sacco di throughput. È probabile che la larghezza di banda del data center sarà il collo di bottiglia molto prima del composito ERDDAP™ diventa il collo di bottiglia.
Max aggiornato (tempo) ?
The EDDGrid /TableFromErddap in composito ERDDAP™ solo modifica le informazioni memorizzate su ogni dataset sorgente quando il dataset sorgente è "ricarica" e qualche pezzo di cambiamenti di metadati (ad esempio, la variabile di tempo actual\_range ) , generando così una notifica di abbonamento. Se il dataset sorgente ha dati che cambiano frequentemente (ad esempio, nuovi dati ogni secondo) e utilizza "aggiornamento" sistema per rilevare frequenti modifiche ai dati sottostanti, EDDGrid /TableFromErddap non sarà avvisato di questi frequenti cambiamenti fino al successivo set di dati "ricarica", così il EDDGrid /TableFromErddap non sarà perfettamente aggiornato. È possibile ridurre al minimo questo problema modificando il dataset sorgente<reloadEveryNMinutes> a un valore più piccolo (60? 15?) in modo che ci sono più notifiche di abbonamento per raccontare EDDGrid /TableFromErddap per aggiornare le sue informazioni sul dataset sorgente.
Oppure, se il sistema di gestione dei dati sa quando il dataset sorgente ha nuovi dati (ad esempio, tramite uno script che copia un file di dati in atto) , e se non è super frequente (ad esempio, ogni 5 minuti, o meno frequenti) C'è una soluzione migliore:
- Non usare<updateEveryNMillis> per mantenere aggiornati i dati di origine.
- Impostare il dataset sorgente<reloadEveryNMinutes> a un numero maggiore (1440?) .
- Fai contattare lo script del dataset sorgente URL della bandiera subito dopo che copia un nuovo file di dati in atto. Ciò porterà al set di dati di origine essere perfettamente aggiornato e causare la creazione di una notifica di abbonamento, che verrà inviata al EDDGrid /TableFromErddap dataset. Questo porterà EDDGrid /TableFromErddap dataset per essere perfettamente aggiornato (bene, entro 5 secondi dall'aggiunta di nuovi dati) . E tutto ciò che sarà fatto in modo efficiente (senza inutili ricarica dataset) .
Composizione multipla ERDDAP #
- In casi molto estremi, o per la tolleranza di guasto, si può desiderare di impostare più di un composito ERDDAP . È probabile che altre parti del sistema (in particolare, la larghezza di banda del data center) diventerà un problema molto prima del composito ERDDAP™ diventa un collo di bottiglia. Quindi la soluzione è probabilmente per impostare ulteriori, geografici diversi, data center (specchi) , ciascuno con un composito ERDDAP™ e server con ERDDAP e (almeno) copie a specchio dei dataset che sono in alta domanda. Tale configurazione fornisce anche tolleranza di errore e backup dei dati (tramite copia) . In questo caso, è meglio se il composito ERDDAP s hanno URL differenti.
Se davvero vuoi tutto il composito ERDDAP s per avere lo stesso URL, utilizzare un sistema front-end che assegna un dato utente a uno solo dei compositi ERDDAP # (in base all'indirizzo IP) , in modo che tutte le richieste dell'utente vadano a uno solo dei composito ERDDAP S. Ci sono due ragioni:
- Quando un dataset sottostante viene ricaricato e i metadati cambiano (ad esempio, un nuovo file di dati in un set di dati grigliato causa la variabile di tempo actual\_range a cambiare) , il composito ERDDAP s sarà temporaneamente leggermente fuori dalla sincronia, ma con consistenza eventuale . Normalmente, ri-sincroniranno entro 5 secondi, ma a volte sarà più lungo. Se un utente effettua un sistema automatizzato che si basa su ERDDAP™ sottoscrizioni che attivano le azioni, i brevi problemi di sincronizzazione diventeranno significativi.
- 2+ composito ERDDAP e ciascuno mantiene il proprio insieme di abbonamenti (a causa del problema di sincronizzazione descritto sopra) .
Quindi un dato utente dovrebbe essere diretto a uno solo dei composito ERDDAP s per evitare questi problemi. Se uno dei compositi ERDDAP s va giù, il sistema front-end può reindirizzare che ERDDAP Gli utenti di un altro ERDDAP™ E' finita. Tuttavia, se si tratta di un problema di capacità che causa il primo composito ERDDAP™ fallire (un utente troppo zelante? a attacco denial-of-service ?) , questo rende molto probabile che reindirizzare i suoi utenti ad altri composito ERDDAP s causerà guasto a cascata . Così, la configurazione più robusta è quella di avere composito ERDDAP s con URL diversi.
O, forse meglio, impostare più composito ERDDAP s senza bilanciamento del carico. In questo caso, si dovrebbe fare un punto di dare ciascuno dei ERDDAP s un nome / identità diverso e se possibile impostarli in diverse parti del mondo (ad esempio, diverse regioni AWS) Per esempio, ERD \_US\_East, ERD \_US\_West, ERD \_IE, ERD \_FR, ERD \_IT, in modo che gli utenti consapevolmente, ripetutamente lavorare con uno specifico ERDDAP .
- \[ Per un design affascinante di un sistema ad alte prestazioni in esecuzione su un server, vedere questo descrizione dettagliata di Mailinator . \]
Datasets in altissima domanda
Nel caso davvero insolito che uno dei A ♪ B o C ERDDAP s non può tenere il passo con le richieste a causa delle limitazioni della larghezza di banda o del disco rigido, ha senso copiare i dati (di nuovo) su un altro server+hard Drive+ ERDDAP , forse con EDDGrid Copia e/o EDDTableCopy . Mentre può sembrare ideale per avere il dataset originale e il dataset copiato appaiono senza soluzione di continuità come un dataset nel composito ERDDAP™ , questo è difficile perché i due set di dati saranno in stati leggermente diversi in tempi diversi (in particolare, dopo che l'originale ottiene nuovi dati, ma prima che il dataset copiato ottiene la sua copia) . Pertanto, consiglio che i dataset siano dati titoli leggermente diversi (ad esempio, "... (copia #1) "e "... (copia #2) ", o forse " (specchio n ) " o " (server n ) ") e appaiono come set di dati separati nel composito ERDDAP . Gli utenti sono utilizzati per vedere le liste di siti mirror in siti di download di file popolari, in modo che questo non dovrebbe sorprendere o deluderli. A causa di limitazioni di larghezza di banda in un dato sito, potrebbe avere senso avere lo specchio situato in un altro sito. Se la copia dello specchio è in un centro dati diverso, accessibile solo dal composito di quel data center ERDDAP™ , i diversi titoli (ad esempio, "mirror #1) Non sono necessari.
RAID contro dischi rigidi regolari
Se un grande dataset o un gruppo di dataset non sono pesantemente utilizzati, può avere senso memorizzare i dati su un RAID in quanto offre tolleranza di errore e dal momento che non è necessario il potere di elaborazione o la larghezza di banda di un altro server. Ma se un dataset viene utilizzato pesantemente, potrebbe avere più senso copiare i dati su un altro server + ERDDAP™ + disco rigido (simile a ciò che Google fa ) piuttosto che utilizzare un server e un RAID per memorizzare più set di dati in quanto è possibile utilizzare sia server+hardDrive+ ERDDAP s in griglia finché uno di loro non fallisce.
Inadempimento
Cosa succede se...
- C'è una serie di richieste per un set di dati (ad esempio, tutti gli studenti di una classe richiedono simultaneamente dati simili) ? Solo ERDDAP™ servire quel dataset sarà sopraffatto e rallentare o rifiutare richieste. Il composito ERDDAP™ e altri ERDDAP Non saranno colpiti. Poiché il fattore limitante per un dato set di dati all'interno del sistema è il disco rigido con i dati (non ERDDAP ) , l'unica soluzione (non immediato) è fare una copia del set di dati su un server diverso+hardDrive+ ERDDAP .
- An A ♪ B o C ERDDAP™ fallisce (ad esempio, guasto del disco rigido) ? Solo il dataset (#) servito da quello ERDDAP™ sono colpiti. Se il dataset (#) è specchiato su un altro server+hardDrive+ ERDDAP , l'effetto è minimo. Se il problema è un guasto del disco rigido in un livello 5 o 6 RAID, è sufficiente sostituire l'unità e avere il RAID ricostruire i dati sull'unità.
- Il composito ERDDAP™ fallisce? Se si desidera fare un sistema con molto elevata disponibilità , si può impostare multipli compositi ERDDAP # (come discusso sopra) , usando qualcosa come NGINX o Traefik per gestire il bilanciamento del carico. Si noti che un dato composito ERDDAP™ può gestire un gran numero di richieste da un gran numero di utenti perché le richieste di metadati sono piccole e sono gestite da informazioni che sono in memoria, e richieste di dati (che possono essere grandi) sono reindirizzati al bambino ERDDAP S.
Semplice, scalabile
Questo sistema è facile da configurare e amministrare, e facilmente estensibile quando qualsiasi parte di esso diventa sovraccaricato. Le uniche limitazioni reali per un data data center sono la larghezza di banda del data center e il costo del sistema.
Larghezza di banda
Notare la larghezza di banda approssimativa dei componenti comunemente utilizzati del sistema:
| Componenti | Larghezza di banda approssimativa (GBytes/s) |
|---|---|
| Memoria DDR | 2,5 |
| Unità SSD | 1 |
| Disco rigido SATA | 0 |
| Gigabit Ethernet | 0,1 |
| OC-12 | 0.06 |
| OC-3 | 0.015 |
| T1 | 0.0002 |
Quindi, un disco rigido SATA (0,3 GB/i) su un server con uno ERDDAP™ può probabilmente saturare una LAN Ethernet Gigabit (0.1GB/s) . E una Gigabit Ethernet LAN (0.1GB/s) può probabilmente saturare una connessione Internet OC-12 (0.06GB/s) . E almeno una fonte elenca linee OC-12 che costano circa $100,000 al mese. (Sì, questi calcoli si basano sul spingere il sistema ai suoi limiti, che non è buono perché porta a risposte molto lente. Ma questi calcoli sono utili per la pianificazione e per il bilanciamento delle parti del sistema.) Chiaramente, una connessione Internet adeguata per il vostro data center è di gran lunga la parte più costosa del sistema. Si può facilmente e relativamente a buon mercato costruire una griglia con una dozzina di server che eseguono una dozzina ERDDAP s che è in grado di pompare un sacco di dati rapidamente, ma una connessione Internet opportunamente veloce sarà molto, molto costoso. Le soluzioni parziali sono:
- Incoraggia i client a richiedere sottoinsiemi dei dati se è tutto ciò che è necessario. Se il cliente ha bisogno solo di dati per una piccola regione o ad una risoluzione più bassa, è quello che dovrebbero richiedere. Subsetting è un focus centrale dei protocolli ERDDAP™ supporti per la richiesta di dati.
- Incoraggiare la trasmissione di dati compressi. ERDDAP™ compresse una trasmissione di dati se trova "accept-encoding" nel HTTP GET richiedere l'intestazione. Tutti i browser web utilizzano "accept-encoding" e decomprimere automaticamente la risposta. Altri clienti (ad esempio, programmi per computer) deve usarlo esplicitamente.
- Colocate i vostri server in un ISP o in un altro sito che offre costi di larghezza di banda relativamente meno costosi.
- Disperse i server con ERDDAP s a istituzioni diverse in modo che i costi siano dispersi. Puoi quindi collegare il tuo composito ERDDAP™ a loro ERDDAP S.
Nota: Cloud Computing e servizi web hosting offrono tutta la larghezza di banda Internet di cui hai bisogno, ma non risolvere il problema dei prezzi.
Per informazioni generali sulla progettazione di sistemi scalabili, ad alta capacità, tolleranti errori, vedere il libro di Michael T. Nygard Rilasciare .
Come Legos
I progettisti di software spesso cercano di usare il bene modelli di progettazione software risolvere i problemi. Buoni modelli sono buoni perché incapsulate bene, facile da creare e lavorare con, soluzioni generali che portano a sistemi con buone proprietà. I nomi dei modelli non sono standardizzati, quindi chiamerò il modello che ERDDAP™ utilizza il modello Lego. Ogni lego (ciascuno ERDDAP ) è un semplice, piccolo, standard, stand-alone, mattoni (server dati) con un'interfaccia definita che permette di essere collegata ad altri legos ( ERDDAP #) . Le parti di ERDDAP™ che compongono questo sistema sono: l'abbonamento e i sistemi flagURL (che permette la comunicazione tra ERDDAP #) L'ESD... FromErddap sistema redirect, e il sistema di RESTful richieste di dati che possono essere generati da utenti o altri ERDDAP S. Così, dato due o più legos ( ERDDAP #) , è possibile creare un numero enorme di forme diverse (topologie di rete ERDDAP #) . Certo, il design e le caratteristiche di ERDDAP™ avrebbe potuto essere fatto in modo diverso, non Lego-come, forse solo per consentire e ottimizzare per una specifica topologia. Ma sentiamo che ERDDAP Il design Lego-like offre una buona soluzione generale che consente qualsiasi ERDDAP™ amministratore (o gruppo di amministratori) creare tutti i tipi di diverse topologie federazioni. Per esempio, una singola organizzazione potrebbe costituire tre (o più) ERDDAP s come mostrato nella ERDDAP™ Diagramma Griglia/Cluster sopra . O un gruppo distribuito (IOOS? CoastWatch? NCEI? NWS? NOAA ? USGS? DataONE? No? LTER? OOI? BODC? ONC? CCR? WMO?) può impostare uno ERDDAP™ in ogni piccolo avamposto (in modo che i dati possano rimanere vicini alla fonte) e poi impostare un composito ERDDAP™ nell'ufficio centrale con dataset virtuali (che sono sempre perfettamente aggiornati) da ogni piccolo avamposto ERDDAP S. Infatti, tutti ERDDAP s, installato in varie istituzioni di tutto il mondo, che ottengono dati da altri ERDDAP s e/o fornire dati ad altri ERDDAP s, formare una rete gigante di ERDDAP S. Che figata! Così, come da Lego, le possibilità sono infinite. Ecco perché questo è un buon modello. Ecco perché questo è un buon design per ERDDAP .
Diversi tipi di richieste
Una delle complicazioni della vita reale di questa discussione delle topologie del server dati è che ci sono diversi tipi di richieste e modi diversi per ottimizzare per i diversi tipi di richieste. Questo è per lo più un problema separato (Quanto velocemente può ERDDAP™ con i dati rispondono alla richiesta di dati?) dalla discussione di topologia (che si occupa delle relazioni tra i server di dati e quali server ha i dati effettivi) . ERDDAP™ , naturalmente, cerca di trattare con tutti i tipi di richieste in modo efficiente, ma gestisce alcuni meglio di altri.
- Molte richieste sono semplici. Per esempio: Quali sono i metadati per questo dataset? Oppure: Quali sono i valori della dimensione del tempo per questo dataset grigliato? ERDDAP™ è progettato per gestire questi il più rapidamente possibile (solitamente in<=2 ms) mantenendo queste informazioni in memoria.
- Alcune richieste sono moderatamente difficili. Per esempio: Dammi questo sottoinsieme di un set di dati (che è in un file di dati) . Queste richieste possono essere gestite relativamente rapidamente perché non sono così difficili.
- Alcune richieste sono difficili e quindi richiedono tempo. Per esempio: Dammi questo sottoinsieme di un set di dati (che potrebbe essere in uno qualsiasi dei file di dati 10.000+, o potrebbe essere da file di dati compressi che ogni prendono 10 secondi per decomprimere) . ERDDAP™ v2.0 ha introdotto alcuni nuovi e più veloci modi per affrontare queste richieste, in particolare consentendo al thread di gestione delle richieste di deporre diversi thread dei lavoratori che affrontano diversi sottoinsiemi della richiesta. Ma c'è un altro approccio a questo problema che ERDDAP™ non supporta ancora: i sottoset dei file di dati per un dato set di dati potrebbero essere memorizzati e analizzati su computer separati, e quindi i risultati combinati sul server originale. Questo approccio si chiama MappaRiduzione ed è esemplare da Hadoop Il primo (?) open-source MapRidurre programma, che era basato su idee di un giornale di Google. (Se hai bisogno di MapReduce in ERDDAP , si prega di inviare una richiesta e-mail a erd.data at noaa.gov .) Google's BigQuery è interessante perché sembra essere un'implementazione di MapReduce applicato a sottosetting set di dati tabulari, che è uno dei ERDDAP Gli obiettivi principali. È probabile che tu possa creare un ERDDAP™ dataset da un dataset BigQuery tramite EDDTableDatabase perché BigQuery può essere accessibile tramite un'interfaccia JDBC.
Queste sono le mie opinioni.
Sì, i calcoli sono semplicistici (e ora leggermente datato) , ma credo che le conclusioni siano corrette. Ho usato la logica difettosa o ho commesso un errore nei miei calcoli? Se è così, la colpa è mia da sola. Si prega di inviare una e-mail con la correzione a erd dot data at noaa dot gov .
-
- No.
Cloud Computing
Molte aziende offrono servizi di cloud computing (ad esempio, Servizi web Amazon e Google Cloud Piattaforma ) . Web hosting aziende hanno offerto servizi più semplici dalla metà del 1990, ma i servizi "cloud" hanno notevolmente ampliato la flessibilità dei sistemi e la gamma di servizi offerti. Dal ERDDAP™ griglia solo consiste di ERDDAP s e da ERDDAP # Java applicazioni web che possono funzionare in Tomcat (il server di applicazione più comune) o altri server di applicazione, dovrebbe essere relativamente facile configurare un ERDDAP™ griglia su un servizio cloud o sito web hosting. I vantaggi di questi servizi sono:
- Essi offrono l'accesso a connessioni Internet molto alte larghezza di banda. Questo solo può giustificare l'utilizzo di questi servizi.
- Essi addebitano solo per i servizi che si utilizzano. Ad esempio, si ottiene l'accesso a una connessione Internet molto alta larghezza di banda, ma si paga solo per i dati reali trasferiti. Che ti permette di costruire un sistema che raramente viene sopraffatto (anche al picco della domanda) , senza dover pagare per la capacità che raramente viene utilizzata.
- Sono facilmente estensibili. È possibile modificare i tipi di server o aggiungere il maggior numero di server o la quantità di archiviazione che si desidera, in meno di un minuto. Questo solo può giustificare l'utilizzo di questi servizi.
- Essi vi liberano da molti dei doveri amministrativi di gestire i server e le reti. Questo solo può giustificare l'utilizzo di questi servizi.
Gli svantaggi di questi servizi sono:
- Essi addebitano per i loro servizi, a volte molto (in termini assoluti; non che non sia un buon valore) . I prezzi indicati qui sono per Amazon EC2 . Questi prezzi (a partire da giugno 2015) scenderà.
In passato, i prezzi erano più alti, ma i file di dati e il numero di richieste erano più piccoli.
In futuro, i prezzi saranno inferiori, ma i file di dati e il numero di richieste saranno più grandi.
Quindi i dettagli cambiano, ma la situazione rimane relativamente costante.
E non è che il servizio è troppo costoso, è che stiamo usando e l'acquisto di un sacco di servizio.
- Trasferimento dati — I trasferimenti di dati nel sistema sono ora gratuiti (Si'!) . I trasferimenti di dati fuori dal sistema sono $0.09/GB. Un disco rigido SATA (0,3 GB/i) su un server con uno ERDDAP™ può probabilmente saturare una LAN Ethernet Gigabit (0.1GB/s) . Una rete Ethernet Gigabit (0.1GB/s) può probabilmente saturare una connessione Internet OC-12 (0.06GB/s) . Se una connessione OC-12 può trasmettere ~ 150.000 GB/mese, i costi di trasferimento dati potrebbero essere pari a 150.000 GB @ $0.09/GB = $13,500/mese, che è un costo significativo. Chiaramente, se avete una dozzina di laboriosi ERDDAP s su un servizio cloud, le spese mensili di trasferimento dati potrebbero essere sostanziali (fino a $162,000/mese) . (Ancora una volta, non è che il servizio è troppo costoso, è che stiamo usando e l'acquisto di un sacco di servizio.)
- Archiviazione dati — Amazon addebita $50/mese per TB. (Confrontare che per acquistare un drive 4TB enterprise outright per ~ $ 50 / TB, anche se il RAID per metterlo in e costi amministrativi aggiungere al costo totale.) Quindi, se è necessario memorizzare un sacco di dati nel cloud, potrebbe essere abbastanza costoso (ad esempio, 100TB costerebbe $5000/mese) . Ma a meno che non si dispone di una quantità davvero grande di dati, questo è un problema più piccolo rispetto ai costi di trasferimento di banda / dati. (Ancora una volta, non è che il servizio è troppo costoso, è che stiamo usando e l'acquisto di un sacco di servizio.)
Sospensione
- Il problema di sottosetting: L'unico modo per distribuire efficacemente i dati dai file di dati è quello di avere il programma che sta distribuendo i dati (ad esempio, ERDDAP ) in esecuzione su un server che ha i dati memorizzati su un disco rigido locale (o simile accesso rapido a un SAN o RAID locale) . I file system locali consentono ERDDAP™ (e librerie sottostanti, come netcdf-java) richiedere intervalli di byte specifici dai file e ottenere risposte molto rapidamente. Molti tipi di richieste di dati da ERDDAP™ al file (in particolare richieste di dati grigliate in cui il valore del passo è > 1) non può essere fatto in modo efficiente se il programma deve richiedere l'intero file o grandi pezzi di un file da un non-locale (quindi più lento) sistema di archiviazione dati e quindi estrarre un sottoinsieme. Se la configurazione del cloud non dà ERDDAP™ accesso rapido a intervalli byte dei file (veloce come con i file locali) ♪ ERDDAP L'accesso ai dati sarà un grave collo di bottiglia e nega altri vantaggi di utilizzare un servizio cloud.
Dati ospitati
Un'alternativa all'analisi delle prestazioni di costo superiore (che si basa sul titolare dei dati (ad esempio, NOAA ) il pagamento dei dati da memorizzare nel cloud) è arrivato intorno al 2012, quando Amazon (e in misura minore, alcuni altri fornitori di cloud) ha iniziato ad ospitare alcuni set di dati nel loro cloud (AWS S3) gratis (presumibilmente con la speranza che possano recuperare i loro costi se gli utenti avrebbero affittato istanze di calcolo AWS EC2 per lavorare con quei dati) . Chiaramente, questo rende il cloud computing molto più conveniente, perché il tempo e il costo per caricare i dati e ospitarlo sono ora zero. Con ERDDAP™ v2.0, ci sono nuove funzionalità per facilitare l'esecuzione ERDDAP in una nuvola:
- Ora, un EDDGrid FromFiles o EDDTableFromFiles dataset può essere creato da file di dati che sono remoti e accessibili tramite Internet (ad esempio, secchi AWS S3) usando<cacheFromUrl> e<cacheSize GB> opzioni. ERDDAP™ manterrà una cache locale dei file di dati più recenti utilizzati.
- Ora, se qualsiasi file sorgente EDDTableFromFiles viene compresso (ad esempio, .tgz ) ♪ ERDDAP™ li decomprime automaticamente quando li legge.
- Ora, ERDDAP™ thread rispondendo a una data richiesta saranno deposte i fili del lavoratore a lavorare su sottosezioni della richiesta se si utilizza la<nThreads> opzioni. Questa parallelizzazione dovrebbe consentire risposte più rapide alle richieste difficili.
Queste modifiche risolvono il problema di AWS S3 non offrendo archiviazione di file locale, a livello di blocco e il (vecchio) problema di accesso ai dati S3 che hanno un ritardo significativo. (Anni fa (~ 2014) , quel ritardo era significativo, ma ora è molto più breve e quindi non così significativo.) Tutto sommato, significa che l'impostazione ERDDAP™ nel cloud funziona molto meglio ora.
Grazie. — Molte grazie a Matthew Arrott e al suo gruppo nello sforzo OOI originale per il loro lavoro sul mettere ERDDAP™ nel cloud e le discussioni risultanti.
-
- No.
Replica a distanza di Datasets
C'è un problema comune che è legato alla discussione sopra di griglie e federazioni di ERDDAP s: replica remota di datasets. Il problema di base è: un data provider mantiene un dataset che cambia di tanto in tanto e un utente vuole mantenere una copia locale aggiornata di questo dataset (per una varietà di motivi) . Chiaramente, ci sono un numero enorme di variazioni di questo. Alcune variazioni sono molto più difficili da affrontare rispetto ad altre.
- Aggiornamenti veloci È più difficile mantenere aggiornati i dati locali immediatamente (ad esempio, entro 3 secondi) dopo ogni cambiamento alla fonte, piuttosto che, per esempio, in poche ore.
- Variazioni frequenti I cambiamenti frequenti sono più difficili da affrontare rispetto ai cambiamenti infrequenti. Ad esempio, i cambiamenti di una volta al giorno sono molto più facili da affrontare rispetto ai cambiamenti ogni 0,1 secondi.
- Piccoli cambiamenti I piccoli cambiamenti in un file sorgente sono più difficili da affrontare di un file completamente nuovo. Questo è particolarmente vero se i piccoli cambiamenti possono essere ovunque nel file. I piccoli cambiamenti sono più difficili da rilevare e rendono difficile isolare i dati che devono essere replicati. I nuovi file sono facili da rilevare ed efficienti da trasferire.
- Intero Dataset Mantenere un intero dataset up-to-date è più difficile che mantenere solo i dati recenti. Alcuni utenti hanno solo bisogno di dati recenti (ad esempio, l'ultimo 8 giorni vale) .
- Copie multiple Mantenere più copie remote in diversi siti è più difficile di mantenere una copia remota. Questo è il problema della scala.
Ci sono ovviamente un numero enorme di variazioni di possibili tipi di modifiche al dataset sorgente e delle esigenze e aspettative dell'utente. Molte delle variazioni sono molto difficili da risolvere. La soluzione migliore per una situazione non è spesso la soluzione migliore per un'altra situazione — non c'è ancora una grande soluzione universale.
Rilevamento ERDDAP™ Strumenti
ERDDAP™ offre diversi strumenti che possono essere utilizzati come parte di un sistema che cerca di mantenere una copia remota di un set di dati:
- ERDDAP ' RSS (Ricco del Sito?) servizio
offre un modo rapido per verificare se un set di dati su un telecomando ERDDAP™ è cambiato. - ERDDAP ' servizio di abbonamento
è più efficiente (di RSS ) approccio: invierà immediatamente un'e-mail o contatterà un URL a ciascun abbonato ogni volta che il dataset verrà aggiornato e l'aggiornamento ha comportato una modifica. E 'efficace in quanto accade al più presto e non c'è uno sforzo sprecato (come inquinare un RSS servizio) . Gli utenti possono utilizzare altri strumenti (come IFTTT ) reagire alle notifiche e-mail dal sistema di abbonamento. Ad esempio, un utente potrebbe iscriversi a un set di dati su un telecomando ERDDAP™ e utilizzare IFTTT per reagire alle notifiche e-mail di abbonamento e attivare l'aggiornamento del dataset locale. - ERDDAP ' sistema di segnalazione
fornisce un modo per un ERDDAP™ amministratore per indicare un set di dati sul suo / suo ERDDAP per ricaricare il prima possibile. La forma URL di una bandiera può essere facilmente utilizzata negli script. Il modulo URL di una bandiera può anche essere utilizzato come azione per un abbonamento. - ERDDAP ' "files" sistema
può offrire l'accesso ai file sorgente per un dato set di dati, tra cui un elenco di directory in stile Apache dei file (una "Cartella di accesso Web") che ha l'URL di download di ogni file, l'ultima volta modificata e la dimensione. Un lato negativo dell'utilizzo "files" il sistema è che i file sorgente possono avere diversi nomi variabili e metadati diversi rispetto al dataset come appare nel ERDDAP . Se un telecomando ERDDAP™ dataset offre l'accesso ai file sorgente, che apre la possibilità di una versione rsync di un povero: diventa facile per un sistema locale vedere quali file remoti sono cambiati e devono essere scaricati. (Vedere la opzione cacheFromUrl sotto che può fare uso di questo.)
Soluzioni
Anche se ci sono un numero enorme di variazioni al problema e un numero infinito di possibili soluzioni, ci sono solo una manciata di approcci di base alle soluzioni:
Soluzioni personalizzate, Brute Force
Una soluzione ovvia è quella di realizzare una soluzione personalizzata, che è quindi ottimizzata per una determinata situazione: fare un sistema che rileva/identifica quali dati sono cambiati e invia queste informazioni all'utente in modo che l'utente possa richiedere i dati modificati. Beh, puoi farlo, ma ci sono svantaggi:
- Le soluzioni personalizzate sono un sacco di lavoro.
- Le soluzioni personalizzate sono di solito così personalizzate per un dato set di dati e dato il sistema dell'utente che non possono essere facilmente riutilizzati.
- Le soluzioni personalizzate devono essere costruite e mantenute da voi. (Non e' mai una buona idea. È sempre una buona idea evitare il lavoro e ottenere qualcun altro per fare il lavoro!)
Sfido di prendere questo approccio perché è quasi sempre meglio cercare soluzioni generali, costruite e mantenute da qualcun altro, che possono essere facilmente riutilizzate in situazioni diverse.
r
r è l'esistente, sorprendentemente buona, soluzione di scopo generale per mantenere una raccolta di file su un computer sorgente in sincronia su un computer remoto dell'utente. Il modo in cui funziona è:
- qualche evento (ad esempio, un ERDDAP™ evento del sistema di abbonamento) attiva rsync, (o, un lavoro di cron esegue rsync a orari specifici ogni giorno sul computer dell'utente)
- che contatta rsync sul computer sorgente,
- che calcola una serie di hashes per i pezzi di ogni file e trasmette quelle hashes alla rsync dell'utente,
- che confronta tali informazioni con le informazioni simili per la copia dell'utente dei file,
- che poi richiede i pezzi di file che sono cambiati.
Considerando tutto ciò che fa, rsync opera molto rapidamente (ad esempio, 10 secondi più il tempo di trasferimento dati) e molto efficiente. Ci sono variazioni di rsync che ottimizzano per diverse situazioni (ad esempio, precalcolando e caching le ceneri dei pezzi di ogni file sorgente) .
Le principali debolezze di rsync sono: ci vuole qualche sforzo per impostare (questioni di sicurezza) ; ci sono alcuni problemi di scaling; e non è bene per mantenere i set di dati NRT veramente aggiornati (ad esempio, è imbarazzante usare rsync più di circa ogni 5 minuti) . Se si può trattare con le debolezze, o se non influiscono sulla vostra situazione, rsync è una soluzione eccellente, scopo generale che chiunque può utilizzare in questo momento per risolvere molti scenari che coinvolgono la replica remota di dataset.
C'è un elemento sul ERDDAP™ Per fare elenco per cercare di aggiungere il supporto per i servizi rsync a ERDDAP (probabilmente un compito piuttosto difficile) , in modo che qualsiasi client possa utilizzare rsync (o una variante) per mantenere una copia aggiornata di un dataset. Se qualcuno vuole lavorare su questo, per favore e-mail erd.data at noaa.gov .
Ci sono altri programmi che fanno più o meno ciò che rsync fa, a volte orientato alla replica di dataset (anche se spesso a livello di file-copia) Per esempio, Unidata ' IDD .
Cache da Url
La cacheDaUrl l'impostazione è disponibile (a partire da ERDDAP™ v.) per tutti ERDDAP 's tipi di dataset che fanno set di dati da file (fondamentalmente, tutte le sottoclassi di EDDGrid Da Fili e EDDTableFromFiles ) . cache DaUrl rende banale scaricare e mantenere automaticamente i file di dati locali copiandoli da una sorgente remota tramite la cache Dalla regolazione Url. I file remoti possono essere in una cartella di accesso Web o in un elenco di file simile a directory offerto da THREDDS, Hyrax , un secchio S3 o ERDDAP ' "files" sistema.
Se la fonte dei file remoti è un telecomando ERDDAP™ dataset che offre i file sorgente tramite il ERDDAP™ "files" sistema, allora si può sottoscritto al set di dati remoto, e utilizzare URL della bandiera per il vostro set di dati locale come azione per l'abbonamento. Poi, ogni volta che il set di dati remoto cambia, contatterà l'URL della bandiera per il vostro set di dati, che gli dirà di ricaricare ASAP, che rileva e scarica i file di dati remoti modificati. Tutto questo accade molto rapidamente (di solito ~5 secondi più il tempo necessario per scaricare i file modificati) . Questo approccio funziona grande se le modifiche del dataset sorgente sono nuovi file che vengono periodicamente aggiunti e quando i file esistenti non cambiano mai. Questo approccio non funziona bene se i dati sono spesso aggiunti a tutti (o più) dei file di dati di origine esistenti, perché allora il vostro set di dati locale viene spesso scaricato l'intero set di dati remoto. (Questo è dove è necessario un approccio rsync-like.)
ArchivioAzione
ERDDAP™ ' ArchivioAzione è una buona soluzione quando i dati vengono aggiunti a un set di dati frequentemente, ma i dati più vecchi non vengono mai modificati. Fondamentalmente, un ERDDAP™ amministratore può eseguire ArchiveADataset (forse in uno script, forse eseguito da cron) e specificare un sottoinsieme di un set di dati che vogliono estrarre (forse in più file) e pacchetto in un .zip o .tgz file, in modo da poter inviare il file a persone o gruppi interessati (ad esempio, NCEI per l'archiviazione) o renderlo disponibile per il download. Ad esempio, è possibile eseguire ArchiveADataset tutti i giorni alle 12:10 e farlo fare un .zip di tutti i dati dalle 12:00 sono il giorno precedente fino alle 12:00 di oggi. (Oppure, fai questo settimanale, mensile o annuale, come necessario.) Poiché il file pacchetto è generato offline, non c'è pericolo di un timeout o troppi dati, come ci sarebbe per uno standard ERDDAP™ richiesta.
ERDDAP™ Sistema di richiesta standard
ERDDAP™ Il sistema di richiesta standard è una buona soluzione alternativa quando i dati vengono aggiunti a un set di dati frequentemente, ma i dati più vecchi non vengono mai modificati. Fondamentalmente, chiunque può utilizzare richieste standard per ottenere i dati per una specifica gamma di tempo. Ad esempio, alle 12:10 di tutti i giorni, si potrebbe fare una richiesta per tutti i dati da un dataset remoto dalle 12:00 del giorno precedente fino alle 12:00 di oggi. La limitazione (rispetto all'approccio ArchiveADataset) è il rischio di un timeout o ci sono troppi dati per un singolo file. È possibile evitare la limitazione facendo richieste più frequenti per periodi di tempo più piccoli.
EDDTableDaHttpGet
\[ Questa opzione non esiste ancora, ma sembra possibile costruire nel prossimo futuro. \]
Il nuovo EDDTableDaHttpGet tipo di dataset in ERDDAP™ v2.0 permette di prevedere un'altra soluzione. I file sottostanti mantenuti da questo tipo di dataset sono essenzialmente file di registro che registrano le modifiche al dataset. Dovrebbe essere possibile costruire un sistema che mantiene un dataset locale periodicamente (o in base a un trigger) richiedere tutte le modifiche apportate al set di dati remoto dall'ultima richiesta. Questo dovrebbe essere efficiente. (o più) che rsync e gestirebbe molti scenari difficili, ma funzionerebbe solo se i set di dati remoti e locali sono EDDTableFromHttpGet set di dati.
Se qualcuno vuole lavorare su questo, si prega di contattare erd.data at noaa.gov .
Dati distribuiti
Nessuna delle soluzioni sopra fa un ottimo lavoro per risolvere le dure variazioni del problema perché la replica di quasi in tempo reale (N.) datasets è molto difficile, in parte a causa di tutti gli scenari possibili.
C'è una grande soluzione: non provare nemmeno a replicare i dati. Invece, utilizzare l'unica fonte autorevole (un dataset su uno ERDDAP ) , mantenuto dal fornitore di dati (per esempio, un ufficio regionale) . Tutti gli utenti che vogliono dati da quel dataset lo ottengono sempre dalla fonte. Ad esempio, le applicazioni basate sul browser ottengono i dati da una richiesta basata su URL, quindi non dovrebbe importare che la richiesta sia alla fonte originale su un server remoto (non lo stesso server che ospita l'ESM) . Molte persone stanno sostenendo questo approccio Distributed Data da molto tempo (ad esempio, Roy Mendelssohn per gli ultimi 20+ anni) . ERDDAP modello di griglia/federazione (l'80% superiore di questo documento) si basa su questo approccio. Questa soluzione è come una spada a un nodo Gordian — l'intero problema va via.
- Questa soluzione è incredibilmente semplice.
- Questa soluzione è incredibilmente efficiente dal momento che nessun lavoro è fatto per mantenere un set di dati replicato (#) up-to-date.
- Gli utenti possono ottenere i dati più recenti in qualsiasi momento (ad esempio, con una latenza di solo ~0,5 secondi) .
- Scala abbastanza bene e ci sono modi per migliorare la scalatura. (Vedere la discussione al vertice 80% di questo documento.)
No, questa non è una soluzione per tutte le situazioni possibili, ma è una grande soluzione per la stragrande maggioranza. Se ci sono problemi / debolezze con questa soluzione in determinate situazioni, spesso vale la pena lavorare per risolvere quei problemi o vivere con quelle debolezze a causa dei vantaggi incredibili di questa soluzione. Se / quando questa soluzione è veramente inaccettabile per una determinata situazione, ad esempio, quando si deve veramente avere una copia locale dei dati, quindi prendere in considerazione le altre soluzioni discusse sopra.
Conclusioni
Mentre non c'è una soluzione semplice e semplice che risolve perfettamente tutti i problemi in tutti gli scenari (come rsync e dati distribuiti quasi sono) , speriamo ci siano strumenti e opzioni sufficienti in modo da poter trovare una soluzione accettabile per la vostra situazione particolare.