Skalering
ERDDAP™ - Heavy Loads, Grids, Clusters, Federasjoner og Cloud Computing
ERDDAP :)
ERDDAP™ er en webapplikasjon og en webtjeneste som samler vitenskapelige data fra forskjellige lokale og eksterne kilder og tilbyr en enkel, konsekvent måte å laste ned undergrupper av data i felles filformater og lage grafer og kart. Denne siden diskuterer problemer relatert til tunge ERDDAP™ bruk belastninger og utforsker muligheter for å håndtere ekstremt tunge belastninger via rutenett, klynger, forbund og sky databehandling.
Den opprinnelige versjonen ble skrevet i juni 2009. Det har ikke vært noen signifikante endringer. Dette ble sist oppdatert 2019-04-15.
DISCLAIMER
Innholdet på denne siden er personlige meninger og reflekterer ikke nødvendigvis noen stilling som Norge eller Norge har National Oceanic and Atmospheric Administration .. Beregningene er enklere, men jeg tror konklusjonene er riktige. Brukte jeg feilaktig logikk eller gjorde feil i beregningene? I så fall er feilen min alene. Vennligst send en e-post med rettelsen til erd dot data at noaa dot gov ..
Tunge belastninger / ulemper
Med tung bruk, en frittstående ERDDAP™ vil bli begrenset (fra mest til minst sannsynlig) av:
Fjernkilde Bandbredde
- En ekstern datakildes båndbredde — selv med en effektiv tilkobling (f.eks. via OPeNDAP ) , med mindre en ekstern datakilde har en meget høy båndbredde Internett-tilkobling, ERDDAP Svarene vil bli begrenset av hvor raskt ERDDAP™ kan få data fra datakilden. En løsning er å kopiere datasettet på ERDDAP Harddisk, kanskje med EDDGrid Kopier eller EDDTableCopy ..
ERDDAP serverbåndbredde
- Med mindre ERDDAP serveren har en veldig høy båndbredde Internett-tilkobling, ERDDAP Svarene vil bli begrenset av hvor raskt ERDDAP™ kan få data fra datakildene og hvor raskt ERDDAP™ kan returnere data til kundene. Den eneste løsningen er å få raskere Internett-tilkobling.
Minne
- Hvis det er mange samtidige forespørsler, ERDDAP™ kan være ute av hukommelse og midlertidig avvise nye forespørsler. ( ERDDAP™ har et par mekanismer for å unngå dette og minimere konsekvensene hvis det skjer.) Jo mer minne i serveren er jo bedre. På en 32-biters server er 4+ GB veldig bra, 2 GB er ok, mindre anbefales ikke. På en 64-biters server kan du nesten helt unngå problemet ved å få mye minne. Se \-Xmx og -Xms innstillinger for ERDDAP /Tomcat. An ERDDAP™ å få kraftig bruk på en datamaskin med en 64-biters server med 8GB minne og -Xmx satt til 4000M er sjelden, om noen gang, begrenset av minne.
Har drevet bandbredde
- Å få tilgang til data som er lagret på serverens harddisk er svært raskere enn å få tilgang til fjerndata. Selv om ERDDAP™ server har en meget høy båndbredde Internett-tilkobling, det er mulig at tilgang til data på harddisken vil være en flaskehals. En delvis løsning er å bruke raskere (f.eks. 10 000 RPM) magnetiske harddisker eller SSD-stasjoner (Hvis det gir mening, kostnad-vis) .. En annen løsning er å lagre ulike datasett på forskjellige stasjoner, slik at den kumulative harddiskbredde er mye høyere.
For mange filer cached
- For mange filer i en cache katalog — ERDDAP™ caches alle bilder, men bare caches data for visse typer dataforespørsler. Det er mulig for cache-katalogen for et datasett å ha et stort antall filer midlertidig. Dette vil bremse forespørsler for å se om en fil er i bufferen (virkelig!) ..<cache Minutter> i config.xml lar deg angi hvor lenge en fil kan være i cache før den slettes. Å sette et mindre antall vil minimere dette problemet.
CPU
- Bare to ting tar mye CPU tid:
- NetCDF 4 og HDF 5 støtter nå intern kompresjon av data. Dekomprimere en stor komprimert NetCDF 4 / HDF 5 datafil kan ta 10 eller flere sekunder. (Det er ingen implementeringsfeil. Det er kompresjonens natur.) Så, kan flere samtidige forespørsler til datasett med data lagret i komprimerte filer sette en alvorlig belastning på enhver server. Hvis dette er et problem, er løsningen å lagre populære datasett i ukomprimerte filer, eller få en server med en CPU med flere kjerner.
- Lage grafer (inkludert kart) : ca. 0.2 - 1 sekund per graf. Så hvis det var mange samtidige unike forespørsler om grafer ( WMS Kunder gjør ofte 6 samtidige forespørsler!) Det kan være en CPU-begrensning. Når flere brukere kjører WMS Kunder, dette blir et problem.
Flere identiske ERDDAP Med Load Balancing?
Spørsmålet kommer ofte opp: " For å håndtere tunge belastninger, kan jeg sette opp flere identiske ERDDAP s med belastningsbalansering?" Det er et interessant spørsmål fordi det raskt kommer til kjernen av ERDDAP Design. Det raske svaret er " nei". Jeg vet at det er et skuffende svar, men det er et par direkte grunner og noen større grunner til at jeg designet ERDDAP™ å bruke en annen tilnærming (en føderasjon av ERDDAP s, beskrevet i hovedparten av dette dokumentet) Som jeg tror er en bedre løsning.
Noen direkte grunner til at du ikke kan/skal ikke sette opp flere identiske ERDDAP S er:
- En gitt ERDDAP™ leser hver datafil når den først blir tilgjengelig for å finne dataområdet i filen. Deretter lagrer den informasjonen i en indeksfil. Når en bruker ber om data kommer inn, ERDDAP™ bruker den indeksen for å finne ut hvilke filer som skal se etter de ønskede dataene. Hvis det var flere identiske ERDDAP De vil alle gjøre dette indeksering, som er bortkastet innsats. Med det fedrerte system beskrevet nedenfor, gjøres indekseringen kun én gang, ved en av de ERDDAP S.
- For noen typer brukerforespørsler (f.eks. .nc , .png, .pdf filer) ERDDAP™ må lage hele filen før svaret kan sendes. Så ERDDAP™ mellomlager disse filene for kort tid. Hvis en identisk forespørsel kommer (som det ofte gjør, spesielt for bilder der URL er innebygd i en nettside) , ERDDAP™ kan gjenbruke den cachede filen. I et system av flere identiske ERDDAP s, de cachede filene er ikke delt, så hver ERDDAP™ vil nødvendig og avfallsfullt gjenskape .nc , .png eller .pdf-filer. Med det feedererte systemet som er beskrevet nedenfor, er filene bare laget én gang, av en av ERDDAP og gjenbrukt.
- ERDDAP abonnementssystemet er ikke satt opp til å deles av flere ERDDAP S. Hvis for eksempel lastbalansen sender en bruker til en ERDDAP™ og brukeren abonnerer på et datasett, deretter den andre ERDDAP Jeg vet ikke om det abonnementet. Senere, hvis lastebalanseren sender brukeren til en annen ERDDAP™ og spør om en liste over hans/hennes abonnementer, den andre ERDDAP™ vil si at det ikke er noen (leder ham/henne til å gjøre et duplikat abonnement på den andre ERED DAP ) .. Med det federerte systemet beskrevet nedenfor håndteres abonnementssystemet enkelt av det viktigste, offentlige, sammensatte ERDDAP ..
For hvert av disse problemene kunne jeg (med stor innsats) ingeniør en løsning (å dele informasjonen mellom ERDDAP s) Men jeg tror Forbundet ERDDAP tilnærming (beskrevet i hovedparten av dette dokumentet) er en mye bedre helhetlig løsning, delvis fordi det håndterer andre problemer som multi-idential- ERDDAP s-with-a-load-balancer tilnærmingen begynner ikke engang å adressere, spesielt den desentraliserte arten av datakildene i verden.
Det er best å akseptere det enkle faktum at jeg ikke designet ERDDAP™ å bli brukt som flere identiske ERDDAP med en lastbalanse. Jeg er bevisst designet ERDDAP™ å fungere godt innenfor en føderasjon av ERDDAP som jeg tror har mange fordeler. En føderasjon av ERDDAP S er perfekt tilpasset det desentraliserte, distribuerte systemet av datasentre som vi har i den virkelige verden (Tenk på de ulike IOOS-regionene eller de ulike CoastWatch-regionene, eller de ulike delene av NCEI, eller de 100 andre datasentrene i NOAA , eller de forskjellige NASA DAACs eller 1000-tallet av datasentre over hele verden) .. I stedet for å fortelle alle verdens datasentre at de trenger å forlate sin innsats og sette alle sine data i en sentralisert - datasjø - (Selv om det var mulig, er det en forferdelig ide av mange grunner - se de ulike analysene som viser de mange fordelene ved desentraliserte systemer ) , ERDDAP Design fungerer med verden som den er. Hvert datasenter som produserer data, kan fortsette å vedlikeholde, kurere og betjene sine data. (som de skal) , og likevel, med ERDDAP™ Dataene kan også umiddelbart være tilgjengelige fra en sentralisert ERDDAP uten behov for å overføre dataene til den sentraliserte ERDDAP™ eller å lagre kopier av dataene. Faktisk kan et gitt datasett være tilgjengelig samtidig fra en ERDDAP™ på organisasjonen som produsert og faktisk lagrer dataene (For eksempel GoMOOS) , fra en ERDDAP™ hos foreldreorganisasjonen (f.eks. IOOS sentralt) , fra en all- NOAA ERDDAP™ , fra en all-USA-føderal regjering ERDDAP™ , fra en global ERDDAP™ (GOOS) , fra spesialisert ERDDAP s (f.eks. en ERDDAP™ på en institusjon viet til HAB forskning) , alt i hovedsak øyeblikkelig, og effektivt fordi bare metadata overføres mellom ERDDAP ikke dataene. Best av alt, etter den første ERDDAP™ i den opprinnelige organisasjonen, alle de andre ERDDAP S kan konfigureres raskt (Noen timers arbeid) Med minimale ressurser (en server som ikke trenger RAIDs for datalagring siden den lagrer ingen data lokalt) , og dermed til virkelig minimal kostnad. Sammenlign det til kostnadene ved å sette opp og opprettholde et sentralisert datasenter med en datasjø og behovet for en virkelig massiv, virkelig dyr, Internett-tilkobling, pluss det tilsvarande problemet med det sentraliserte datasenteret er et enkelt punkt for feil. Til meg, ERDDAP Desentralisert, matet tilnærming er langt, langt overlegen.
I situasjoner der et gitt datasenter trenger flere ERDDAP å møte høy etterspørsel, ERDDAP designen er fullt i stand til å matche eller overskride ytelsen til fler-idential- ERDDAP S-with-a-load-balancer tilnærming. Du har alltid muligheten til å sette opp flere kompositter ERDDAP s (Som diskutert nedenfor) Hver av dem får alle sine data fra andre ERDDAP S, uten belastningsbalansering. I dette tilfellet anbefaler jeg at du gjør et poeng med å gi hver kompositt ERDDAP et annet navn/identitet og om mulig etablere dem i forskjellige deler av verden (For eksempel ulike AWS-regioner) f.eks. ERD \_USA__Øst, ERD \_US\_West, ERD \_IE, ERD \_FR, ERD \_IT, slik at brukerne bevisst, gjentatte ganger, jobber med en bestemt ERDDAP , med den ekstra fordelen som du har fjernet risikoen fra et enkelt feilpunkt.
Grids, Clusters og Føderasjoner
Under svært tung bruk, en enkelt frittstående ERDDAP™ vil komme inn i en eller flere Begrensninger De foreslåtte løsningene vil være utilstrekkelige. For slike situasjoner, ERDDAP™ har funksjoner som gjør det enkelt å bygge skalerbare rutenett (Også kalt klynger eller forbund) av ERDDAP som tillater systemet å håndtere svært tung bruk (f.eks. for et stort datasenter) ..
Jeg bruker rutenett som et generelt uttrykk for å angi en type datahop når alle deler kan eller ikke kan være fysisk plassert i ett anlegg og kan eller ikke kan administreres sentralt. En fordel med samlokaliserte, sentralt eide og administrerte rutenett (Kluster) At de drar nytte av stordriftsøkonomi (Særlig den menneskelige arbeidsbelastningen) Forenkle deler av systemet fungerer godt sammen. En fordel med ikke-samlokaliserte rutenett, ikke-sentralt eid og administrert (Forbund) er at de distribuerer den menneskelige arbeidsbelastningen og kostnadene, og kan gi noen ekstra feiltoleranse. Løsningen jeg foreslår nedenfor fungerer godt for alle rutenett, klynge og føderasjon topografier.
Den grunnleggende ideen om å utforme et skalerbart system er å identifisere potensielle flaskehalser og deretter utforme systemet slik at deler av systemet kan replikeres etter behov for å lindre flaskehalsene. Ideelt sett øker hver kopidel kapasiteten til den delen av systemet lineært (Effektiv skalering) .. Systemet er ikke skalerbart med mindre det er en skalerbar løsning for hver flaskehals. Skalerbarhet Det er forskjellig fra effektivitet (Hvor raskt en oppgave kan gjøres - effektiviteten av delene) .. Skalerbarhet gjør det mulig for systemet å vokse til å håndtere ethvert nivå av etterspørsel. Effektivitet (av skalering og av deler) bestemme hvor mange servere, etc., vil bli nødvendig for å møte et gitt nivå av etterspørsel. Effektivitet er svært viktig, men har alltid grenser. Skalerbarhet er den eneste praktiske løsningen til å bygge et system som kan håndtere meget Tung bruk. Ideelt sett vil systemet være skalerbart og effektivt.
Mål
Målet med dette designet er:
- For å lage en skalerbar arkitektur (en som lett kan utvides ved å kopiere deler som blir overbelastet) .. For å gjøre et effektivt system som maksimerer tilgjengeligheten og gjennomgangen av dataene gitt tilgjengelige dataressurser. (Kostnaden er nesten alltid et problem.)
- For å balansere evnene til delene av systemet slik at en del av systemet ikke vil overvelde en annen del.
- For å gjøre en enkel arkitektur slik at systemet er enkelt å konfigurere og administrere.
- For å lage en arkitektur som fungerer bra med alle nett topografier.
- For å lage et system som mislykkes yndelig og på en begrenset måte hvis en del blir overbelastet. (Tiden som kreves for å kopiere en stor datasett vil alltid begrense systemets evne til å håndtere plutselig økning i etterspørselen etter et bestemt datasett.)
- (Om mulig) Å lage en arkitektur som ikke er bundet til noen bestemt sky databehandling Tjeneste eller andre eksterne tjenester (Fordi det ikke trenger dem) ..
Anbefalinger
Våre anbefalinger er
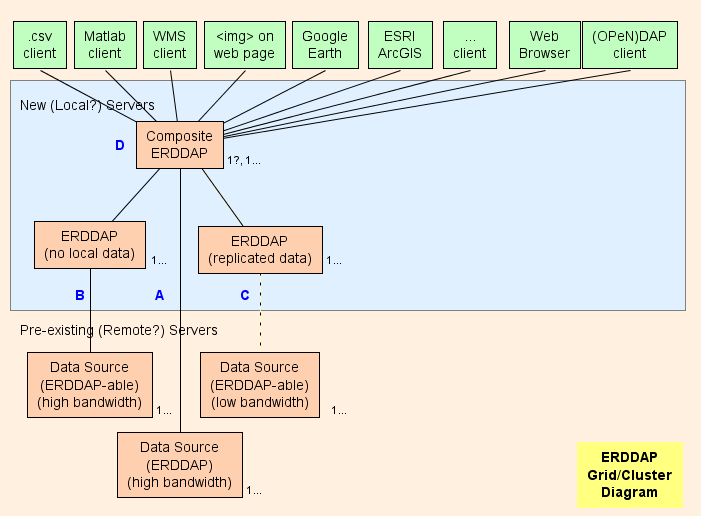
- I utgangspunktet foreslår jeg å etablere en Composite ERDDAP™ ( D I diagrammet) som er regelmessig ERDDAP™ Bortsett fra at det bare serverer data fra andre ERDDAP S. Nettets arkitektur er utformet for å skifte så mye arbeid som mulig (CPU bruk, minnebruk, båndbredde bruk) fra det sammensatte ERDDAP™ til den andre ERDDAP S.
- ERDDAP™ har to spesielle datasettstyper, EDDGrid FraErddap og EDDTableFraErddap som refererer til Datasett på andre ERDDAP S.
- Når sammensetningen ERDDAP™ mottar en forespørsel om data eller bilder fra disse datasettene, sammensetningen ERDDAP™ omdirigerer Dataforespørselen til den andre ERDDAP™ server. Resultatet er:
- Dette er meget effektivt (CPU, minne og båndbredde) fordi ellers
- Sammensetningen ERDDAP™ må sende dataforespørselen til den andre ERDDAP ..
- Den andre ERDDAP™ må få dataene, reformatere dem og overføre dataene til sammensetningen ERDDAP ..
- Sammensetningen ERDDAP™ må motta dataene (bruker ekstra båndbredde) , reformatere det (bruk ekstra CPU tid og minne) og overføre dataene til brukeren (bruker ekstra båndbredde) .. Ved å omdirigere dataforespørselen og tillate den andre ERDDAP™ å sende responsen direkte til brukeren, sammensetningen ERDDAP™ Bruker i det vesentlige ingen CPU-tid, minne eller båndbredde på dataforespørsler.
- Omdirigeringen er gjennomsiktig for brukeren uansett klientprogramvaren (en nettleser eller andre programvare eller kommandolinjeverktøy) ..
- Dette er meget effektivt (CPU, minne og båndbredde) fordi ellers
Grid Deler
A :) For alle eksterne datakilder som har høy båndbredde OPeNDAP server, kan du koble direkte til den eksterne serveren. Hvis den eksterne serveren er en ERDDAP™ , bruk EDDGrid FraErddap eller EDDTableFrå ERDDAP å betjene dataene i sammensetningen ERDDAP .. Hvis den eksterne serveren er en annen type DAP server, f.eks. Hyrax , eller GRADS, bruk EDDGrid Fra Dap.
B For alle ERDDAP -bar datakilde (en datakilde som ERDDAP kan lese data) som har en høy bandbredde-server, konfigurer en annen ERDDAP™ i rutenettet som er ansvarlig for å betjene data fra denne datakilden.
- Hvis flere slike ERDDAP s får ikke mange forespørsler om data, kan du konsolidere dem til én ERDDAP ..
- Hvis ERDDAP™ Dedikert til å få data fra en fjernkilde er å få for mange forespørsler, det er en fristelse til å legge til ytterligere ERDDAP for å få tilgang til fjerndatakilden. I spesielle tilfeller kan dette gi mening, men det er mer sannsynlig at dette vil overvelde fjerndatakilden (som er selvforsvarende) og også hindre andre brukere i å få tilgang til fjerndatakilden (som ikke er hyggelig) .. I et slikt tilfelle, vurdere å sette opp en annen ERDDAP™ å tjene det ett datasett og kopiere datasettet på det ERDDAP harddisken (se C ) Kanskje med EDDGrid Kopier og/eller EDDTableCopy ..
- B servere må være offentlig tilgjengelige.
C For alle ERDDAP -bar datakilde som har en lavbåndsbredde-server (eller er en langsom tjeneste av andre grunner) Tenk å sette opp en annen ERDDAP™ og lagre en kopi av datasettet på det ERDDAP harddisker, kanskje med EDDGrid Kopier og/eller EDDTableCopy .. Hvis flere slike ERDDAP s får ikke mange forespørsler om data, kan du konsolidere dem til én ERDDAP .. C servere må være offentlig tilgjengelige.
Composite ERDDAP
D :) Sammensetningen ERDDAP™ er en vanlig ERDDAP™ Bortsett fra at det bare serverer data fra andre ERDDAP S.
- Fordi sammensetningen ERDDAP™ har informasjon til minne om alle datasettene, det kan raskt svare på forespørsler om lister over datasett (fulltekstsøk, kategorisøk, listen over alle datasett) , og forespørsler om et enkelt datasetts datatilgangsskjema, lage et grafskjema eller WMS infoside. Dette er alle små, dynamisk genererte HTML-sider basert på informasjon som holdes i minnet. Svarene er veldig raske.
- Fordi forespørsler om faktiske data raskt omdirigeres til den andre ERDDAP s, sammensetningen ERDDAP™ kan raskt svare på forespørsler om faktiske data uten å bruke noen CPU-tid, minne eller båndbredde.
- Ved å skifte så mye arbeid som mulig (CPU, minne, båndbredde) fra det sammensatte ERDDAP™ til den andre ERDDAP s, sammensetningen ERDDAP™ kan vise seg å betjene data fra alle datasettene og likevel holde tritt med svært mange dataforespørsler fra et stort antall brukere.
- Foreløpige tester indikerer at sammensetningen ERDDAP™ kan svare på de fleste forespørsler i ~ 1ms CPU-tid, eller 1000 forespørsler/sekund. En 8 kjerneprosessor bør derfor kunne svare på ca. 8000 forespørsler/sekund. Selv om det er mulig å se brudd på høyere aktivitet som vil føre til nedgang, er det mye gjennomstrømning. Det er sannsynlig at båndbredde i datasenteret vil være flaskehalsen lenge før sammensetningen ERDDAP™ blir flaskehalsen.
Oppdatert max (tid) ?
Den EDDGrid /TabellFraErddap i sammensetningen ERDDAP™ Bare endrer sin lagrede informasjon om hvert kildedatasett når kildedatasettet er reload-ed Noen metadata endringer (For eksempel tidsvariabelens actual\_range ) og dermed generere et abonnementsvarsel. Hvis kildedatasettet har data som endres ofte (For eksempel nye data hvert sekund) og bruker "update" system for å merke hyppige endringer i de underliggende dataene, EDDGrid /TabellFromErddap vil ikke bli varslet om disse hyppige endringene før neste datasett " reload", så den EDDGrid /TabellFraErddap vil ikke være helt oppdatert. Du kan minimere dette problemet ved å endre kildedatasettets<reloadEveryNMinutes> til en mindre verdi (60? 15?) slik at det er flere abonnementsvarsler å fortelle EDDGrid /TabellFraErddap å oppdatere sin informasjon om kildedatasettet.
Hvis datahåndteringssystemet vet når kildedatasettet har nye data (f.eks. via et skript som kopierer en datafil på plass) , og hvis det ikke er super hyppig (f.eks. hvert 5. minutt eller mindre hyppig) Det finnes en bedre løsning:
- Ikke bruk<oppdaterEveryNMillis> for å holde kildedatasettet oppdatert.
- Angi kildedatasettets<reloadEveryNMinutes> til et større antall (1440?) ..
- Ta kontakt med kildedatasettet flagg URL rett etter det kopierer en ny datafil på plass. Det vil føre til at kildedatasettet er helt oppdatert og får det til å generere et abonnementsvarsel, som vil bli sendt til EDDGrid /TableFraErddap datasett. Det vil lede EDDGrid /TableFraErddap datasett å være perfekt oppdatert (innen 5 sekunder etter at nye data er lagt til) .. Alt som vil bli gjort effektivt (uten unødvendige datasett) ..
Flere Composite ERDDAP s
- I svært ekstreme tilfeller, eller for feiltoleranse, kan det hende du vil sette opp mer enn én kompositt ERDDAP .. Det er sannsynlig at andre deler av systemet (spesielt datasenterets båndbredde) vil bli et problem lenge før sammensetningen ERDDAP™ blir en flaskehals. Så løsningen er sannsynligvis å sette opp ytterligere, geografisk mangfoldige, datasentre (speil) Hver med én kompositt ERDDAP™ servere med ERDDAP S og (i det minste) speilkopier av datasett som er i høy etterspørsel. Et slikt oppsett gir også feiltoleranse og datasikkerhet (via kopiering) .. I dette tilfellet er det best om sammensetningen ERDDAP har ulike nettadresser.
Hvis du virkelig vil ha hele kompositten ERDDAP s å ha den samme URLen, bruk et frontendesystem som tildeler en gitt bruker til bare en av kompositten ERDDAP s (basert på IP-adressen) , slik at alle brukerens forespørsler går til bare en av komposittene ERDDAP S. Det er to grunner:
- Når en underliggende datasett lastes på nytt og metadataene endres (En ny datafil i et gitt datasett forårsaker for eksempel tidsvariabelens actual\_range å endre) , sammensetningen ERDDAP S vil være midlertidig litt ute av synch, men med Konsistens .. Normalt vil de re-synch innen 5 sekunder, men noen ganger vil det være lengre. Hvis en bruker gjør et automatisert system som er avhengig av ERDDAP™ abonnement som utløser handlinger, vil de korte synkroniseringsproblemene bli betydelige.
- 2+ kompositten ERDDAP Hver beholder sine egne abonnementer (På grunn av synch-problemet beskrevet ovenfor) ..
Så en gitt bruker bør rettes til bare en av sammensetningen ERDDAP For å unngå disse problemene. Hvis en av kompositten ERDDAP s går ned, fronten ende systemet kan omdirigere det ERDDAP brukere til en annen ERDDAP™ Det er opp. Men hvis det er et kapasitetsproblem som forårsaker den første kompositten ERDDAP™ å mislykkes (En overzealous bruker? a avslag på tjenesteangrep ?) , dette gjør det svært sannsynlig at omdirigere sine brukere til andre kompositt ERDDAP S vil forårsake en kaskading feil .. Derfor er det mest robuste oppsettet å ha sammensatt ERDDAP med ulike webadresser.
Eller kanskje bedre å sette opp flere kompositter ERDDAP uten lastbalansering. I dette tilfellet bør du gjøre et poeng å gi hver av ERDDAP et annet navn/identitet og om mulig etablere dem i forskjellige deler av verden (For eksempel ulike AWS-regioner) f.eks. ERD \_USA__Øst, ERD \_US\_West, ERD \_IE, ERD \_FR, ERD \_IT, slik at brukerne bevisst, gjentatte ganger jobber med en bestemt ERDDAP ..
- \[ For et fascinerende design av et høyytelsessystem som kjører på én server, se dette detaljert beskrivelse av Mailinator .. \]
Datasett i svært høy etterspørsel
I det veldig uvanlige tilfellet at en av A , B , eller C ERDDAP s kan ikke holde tritt med forespørsler på grunn av båndbredde eller begrensninger på harddisken, det er fornuftig å kopiere dataene (igjen) på en annen server+hard Drive+ ERDDAP Kanskje med EDDGrid Kopier og/eller EDDTableCopy .. Selv om det kan virke ideelt å ha det originale datasettet og det kopierte datasettet virker sømløst som ett datasett i sammensetningen ERDDAP™ Dette er vanskelig fordi de to datasettene vil være i litt forskjellige tilstander til forskjellige tider (spesielt etter at det opprinnelige får nye data, men før det kopierte datasettet får sin kopi) .. Derfor anbefaler jeg at datasettene gis litt forskjellige titler. (F.eks. (kopi #1) " og "... (kopi #2) eller kanskje (speil # n ) " eller " (server # n ) ") og vises som separate datasett i sammensetningen ERDDAP .. Brukere brukes til å se lister over speilsider på populære fil nedlastingssider, så dette bør ikke overraske eller skuffe dem. På grunn av båndbreddebegrensninger på et gitt sted, kan det være fornuftig å ha speilet plassert på et annet sted. Hvis speilkopien befinner seg på et annet datasenter, kan du bare få tilgang til det datasenterets sammensetning. ERDDAP™ De forskjellige titlene (f.eks. "mirror #1) Det er ikke nødvendig.
RAIDs versus vanlige harddisker
Hvis et stort datasett eller en gruppe datasett ikke er sterkt brukt, kan det være fornuftig å lagre dataene på en RAID siden det tilbyr feiltoleranse og siden du ikke trenger behandlingseffekten eller båndbredden til en annen server. Men hvis et datasett er sterkt brukt, kan det være mer fornuftig å kopiere dataene på en annen server + ERDDAP™ + harddisk (Lignende som Hva Google gjør ) i stedet for å bruke én server og en RAID til å lagre flere datasett siden du får bruke både server+hardDrive+ ERDDAP i nettet til en av dem mislykkes.
Feil
Hva skjer hvis...
- Det er en utbrudd av forespørsler for ett datasett (Alle studenter i en klasse ber om lignende data samtidig.) ? Bare ERDDAP™ tjener at datasett vil bli overveldet og bremse eller nekte forespørsler. Sammensetningen ERDDAP™ og andre ERDDAP De vil ikke bli påvirket. Siden begrensningsfaktoren for et gitt datasett i systemet er harddisken med dataene (ikke ERDDAP ) Den eneste løsningen (Ikke umiddelbart) er å lage en kopi av datasettet på en annen server+hardDrive+ ERDDAP ..
- An A , B , eller C ERDDAP™ feil (f.eks. harddisksvikt) ? Bare datasettet (s) servert av det ERDDAP™ er berørt. Hvis datasettet (s) er speilet på en annen server+hardDrive+ ERDDAP Effekten er minimal. Hvis problemet er en harddiskfeil i et nivå 5 eller 6 RAID, erstatter du bare enheten og har RAID gjenoppbygge dataene på enheten.
- Sammensetningen ERDDAP™ mislykkes? Hvis du vil lage et system med svært høy tilgjengelighet Du kan sette opp flere kompositter ERDDAP s (Som omtalt ovenfor) å bruke noe som NGINX eller Traefik å håndtere belastningsbalansering. Legg merke til at en gitt sammensetning ERDDAP™ kan håndtere et stort antall forespørsler fra et stort antall brukere, fordi forespørsler om metadata er små og håndteres av informasjon som er i minnet, og Forespørsler om data (som kan være store) omdirigeres til barnet ERDDAP S.
Enkel, skalerbar
Dette systemet er enkelt å konfigurere og administrere, og lett ekstensibel når en del av det blir overbelastet. De eneste reelle begrensningene for et gitt datasenter er datasenterets båndbredde og kostnadene for systemet.
Bandbredde
Merk den omtrentlige båndbredde av vanlig brukte komponenter i systemet:
| Komponent | Omtrentlig båndbredde (GBytes/s) |
|---|---|
| DDR-minne | 2.5 |
| SSD-stasjon | 1 |
| SATA harddisk | 0.3 |
| Gigabit Ethernet | 0.1 |
| OC-12 | 0.06 |
| OC-3 | 0.015 |
| T1 | 0.0002 |
En SATA harddisk (0.3GB/s) på en server med en ERDDAP™ Kan sannsynligvis mette en Gigabit Ethernet LAN (0.1GB/s) .. Og én Gigabit Ethernet LAN (0.1GB/s) Kan sannsynligvis mette en OC-12 Internett-tilkobling (0.06GB/s) .. Og minst én kilde lister OC-12 linjer koster rundt $ 1000 i måneden. (Ja, disse beregningene er basert på å presse systemet til sine grenser, noe som ikke er bra fordi det fører til svært slitesterke reaksjoner. Men disse beregningene er nyttige for planlegging og for å balansere deler av systemet.) En passende rask Internett-forbindelse for datasenteret ditt er klart den dyreste delen av systemet. Du kan enkelt og relativt billig bygge et rutenett med et dusin servere kjører et dusin ERDDAP s som er i stand til å pumpe ut masse data raskt, men en passende rask Internett-tilkobling vil være svært, svært dyrt. De delvise løsningene er:
- Oppmuntre klienter til å be om undergrupper av data hvis det er alt som er nødvendig. Hvis klienten bare trenger data for en liten region eller ved en lavere oppløsning, er det det de bør be om. Undersetning er et sentralt fokus i protokollene ERDDAP™ støtter for å be om data.
- Oppmuntre til å sende komprimerte data. ERDDAP™ komprimering en dataoverføring hvis den finner " aksepterer- i HTTP GET forespørselsoverskrift. Alle nettlesere bruker " aksepterer-koding" og dekomprimerer automatisk responsen. Andre kunder (For eksempel dataprogrammer) Må bruke den eksplisitt.
- Kooker serverne dine på en internettleverandør eller et annet nettsted som tilbyr relativt billige båndbreddekostnader.
- Distribuer serverne med ERDDAP til ulike institusjoner slik at kostnadene fordeles. Deretter kan du koble sammen kompositten ERDDAP™ til deres ERDDAP S.
Merk at Sky Computing og web hosting tjenester tilbyr all Internett båndbredde du trenger, men ikke løse prisproblemet.
For generell informasjon om utforming av skalerbare, høy kapasitet, feiltolerante systemer, se Michael T. Nygards bok Utgivelse ..
Som Legos
Programvaredesignere prøver ofte å bruke bra programvare design mønstre å løse problemer. Gode mønstre er gode fordi de innkapsler gode, enkle å skape og jobbe med generelle løsninger som fører til systemer med gode egenskaper. Mønsternavn er ikke standardisert, så jeg vil kalle mønsteret som ERDDAP™ bruker Lego-mønsteret. Hver Lego (hver ERDDAP ) er en enkel, liten, standard, frittstående, murstein (dataserver) med et definert grensesnitt som gjør det mulig å være koblet til andre legos ( ERDDAP s) .. Delene av ERDDAP™ som utgjør dette systemet er: abonnements- og flaggURL-systemer (som muliggjør kommunikasjon mellom ERDDAP s) EDD... FraErddap omdirigeringssystem, og systemet RESTful forespørsler om data som kan genereres av brukere eller andre ERDDAP S. Dermed gitt to eller flere legos ( ERDDAP s) , kan du skape et stort antall forskjellige former (nettverkstopologier ERDDAP s) .. Selvfølgelig design og funksjoner av ERDDAP™ kunne ha blitt gjort annerledes, ikke Lego-lignende, kanskje bare for å aktivere og optimalisere for én bestemt topologi. Men vi føler det ERDDAP Lego-lignende design tilbyr en god, generell løsning som gjør det mulig ERDDAP™ administrator (eller gruppe administratorer) å skape alle typer ulike føderasjonstopologier. For eksempel kan en enkelt organisasjon opprette tre (eller mer) ERDDAP Som vist i ERDDAP™ Grid/Cluster Diagram ovenfor .. Eller en distribuert gruppe (IOOS? CoastWatch? NCEI? NWS? NOAA ? USGS? DataONE? Neon? LTER? OOI? BODC? Onc? JRC? WMO?) Kan sette opp en ERDDAP™ i hver liten utpost (Så dataene kan holde seg nær kilden) og deretter sette opp en sammensatt ERDDAP™ på sentralkontoret med virtuelle datasett (som alltid er helt oppdatert) fra hver av de små utpostene ERDDAP S. Alle i ERDDAP S, installert på ulike institusjoner rundt om i verden, som får data fra andre ERDDAP s og/eller gi data til andre ERDDAP S, danne et gigantisk nettverk av ERDDAP S. Hvor kult er det? Som med Lego er mulighetene uendelige. Derfor er dette et godt mønster. Derfor er dette et godt design for ERDDAP ..
Ulike typer forespørsler
En av de virkelige komplikasjonene i denne diskusjonen om dataserver topologier er at det finnes forskjellige typer forespørsler og ulike måter å optimalisere for de forskjellige typer forespørsler. Dette er for det meste et separat problem (Hvor raskt kan ERDDAP™ med dataene som svarer på forespørselen om data?) fra topologidiskusjonen (som omhandler forholdet mellom dataservere og hvilken server har de faktiske dataene) .. ERDDAP™ Selvfølgelig prøver å håndtere alle typer forespørsler effektivt, men håndterer noen bedre enn andre.
- Mange forespørsler er enkle. For eksempel: Hva er metadataene for dette datasettet? Eller: Hva er verdiene til tidsdimensjonen for dette rutenettet datasett? ERDDAP™ er designet for å håndtere disse så raskt som mulig (vanligvis i<= 2 ms) ved å holde denne informasjonen i minnet.
- Noen ønsker er moderat vanskelige. For eksempel: Gi meg denne delen av et datasett (som er i én datafil) .. Disse forespørsler kan håndteres relativt raskt fordi de ikke er så vanskelig.
- Noen forespørsler er harde og er dermed tidkrevende. For eksempel: Gi meg denne delen av et datasett (som kan være i noen av de 10 000 + datafilene, eller kan være fra komprimerte datafiler som hver tar 10 sekunder å dekomprimere) .. ERDDAP™ v2.0 introduserte noen nye, raskere måter å håndtere disse forespørsler på, spesielt ved å tillate forespørselshåndteringstråden å gyte flere arbeidsgjengere som håndterer forskjellige undergrupper av forespørselen. Men det er en annen tilnærming til dette problemet som ERDDAP™ bruker ennå ikke støtte: undergrupper av datafilene for et gitt datasett kan lagres og analyseres på separate datamaskiner, og deretter resultatene kombinert på den opprinnelige serveren. Denne tilnærmingen kalles MapReduce Eksempler på Hadoop Den første (?) Open-source MapReduce programmet, som var basert på ideer fra en Google-papir. (Hvis du trenger MapReduc in ERDDAP Send en e-postforespørsel til erd.data at noaa.gov ..) Googles StorQuery er interessant fordi det ser ut til å være en implementasjon av MapReduce brukt på underinnstilling tabular datasett, som er en av ERDDAP Hovedmålene. Det er sannsynlig at du kan skape en ERDDAP™ datasett fra et BigQuery-datasett via EDDTableFraDatabase fordi BigQuery kan nås via et JDBC-grensesnitt.
Dette er mine meninger.
Ja, beregningene er enklere (Nå litt datert) Jeg tror konklusjonene er riktige. Brukte jeg feilaktig logikk eller gjorde feil i beregningene? I så fall er feilen min alene. Vennligst send en e-post med rettelsen til erd dot data at noaa dot gov ..
Sky Computing
Flere selskaper tilbyr sky databehandling (f.eks. Amazon Web Services og Google Cloud Platform ) .. Web hosting selskaper har tilbudt enklere tjenester siden midten av 1990-tallet, men "cloud"-tjenestene har i stor grad utvidet fleksibiliteten til systemene og tilbys. Siden ERDDAP™ Nettet består av ERDDAP S og siden ERDDAP S er Java webprogrammer som kan kjøres i Tomcat (den vanligste programserveren) eller andre programservere, det bør være relativt enkelt å sette opp en ERDDAP™ Nett på en skytjeneste eller web hosting nettsted. Fordelene med disse tjenestene er:
- De tilbyr tilgang til svært høy båndbredde Internett-forbindelser. Dette kan rettferdiggjøre bruk av disse tjenestene.
- De belaster bare tjenestene du bruker. For eksempel får du tilgang til en meget høy båndbredde Internett-tilkobling, men du betaler bare for faktiske data overført. Det lar deg bygge et system som sjelden blir overveldet (Selv på topp etterspørsel) uten å måtte betale for kapasitet som sjelden brukes.
- De er lett ekstensible. Du kan endre servertyper eller legge til så mange servere eller så mye lagring som du vil, på mindre enn et minutt. Dette kan rettferdiggjøre bruk av disse tjenestene.
- De frigjør deg fra mange av de administrative pliktene til å kjøre servere og nettverk. Dette kan rettferdiggjøre bruk av disse tjenestene.
Ulemper ved disse tjenestene er:
- De tar betalt for sine tjenester, noen ganger mye (i absolutte termer; ikke at det er en god verdi) .. Prisene som er oppført her er for Amazon EC2 .. Disse prisene (fra juni 2015) Kommer ned.
Tidligere var prisene høyere, men datafiler og antall forespørsler var mindre.
I fremtiden vil prisene være lavere, men datafiler og antall forespørsler vil være større.
Så detaljene endres, men situasjonen forblir relativt konstant.
Og det er ikke at tjenesten er overpriset, det er at vi bruker og kjøper mye av tjenesten.
- Dataoverføring — Dataoverføring til systemet er nå gratis (Ja!) .. Dataoverføring ut av systemet er $0.09/GB. En SATA harddisk (0.3GB/s) på en server med en ERDDAP™ Kan sannsynligvis mette en Gigabit Ethernet LAN (0.1GB/s) .. En Gigabit Ethernet LAN (0.1GB/s) Kan sannsynligvis mette en OC-12 Internett-tilkobling (0.06GB/s) .. Hvis en OC-12-forbindelse kan overføre ~150.000 GB/måned, kan dataoverføringskostnadene være så mye som 150 000 GB @ $0.09/GB = $13.500/måned, som er en betydelig kostnad. Hvis du har et dusin hardt arbeid ERDDAP på en skytjeneste, kan dine månedlige dataoverføringsgebyrer være betydelige (opp til $162 000/måned) .. (Igjen, det er ikke at tjenesten er overpriset, det er at vi bruker og kjøper mye av tjenesten.)
- Datalagring — Amazon tar $50/måned per TB. (Sammenlign det for å kjøpe en 4TB virksomhetsdrift direkte for ~ $ 50 / TB, selv om RAID å sette det i og administrative kostnader legge til den totale kostnaden.) Så hvis du trenger å lagre mye data i skyen, kan det være ganske dyrt (For eksempel vil 100TB koste 5000 dollar/måned) .. Men med mindre du har en veldig stor mengde data, er dette et mindre problem enn båndbredde / dataoverføringskostnader. (Igjen, det er ikke at tjenesten er overpriset, det er at vi bruker og kjøper mye av tjenesten.)
Undersetting
- Problemene med undersetting: Den eneste måten å effektivt distribuere data fra datafiler er å ha programmet som distribuerer dataene (f.eks. ERDDAP ) kjører på en server som har data lagret på en lokal harddisk (eller på lignende måte rask tilgang til en SAN eller lokal RAID) .. Lokale filsystemer tillater ERDDAP™ (og underliggende biblioteker, som netcdf-java) å be om spesifikk byte varierer fra filene og få svar svært raskt. Mange typer dataforespørsler fra ERDDAP™ til filen (Spesielt nettbaserte dataforespørsler der trinnverdien er > 1) kan ikke gjøres effektivt hvis programmet må be om hele filen eller store deler av en fil fra en ikke-lokal (dermed langsommere) Datalagringssystem og deretter trekke ut en undergruppe. Hvis skyen ikke gir ERDDAP™ rask tilgang til byteområde av filene (så raskt som med lokale filer) , ERDDAP Tilgangen til dataene vil være en alvorlig flaskehals og nekte andre fordeler ved å bruke en skytjeneste.
Hostete data
Et alternativ til den ovennevnte kostnadsfordelsanalyse (som er basert på dataeieren (f.eks. NOAA ) Betal for at deres data skal lagres i skyen) Ankom i 2012, da Amazon (og i mindre grad andre skyleverandører) Startet hosting noen datasett i deres sky (AWS S3) gratis (Sannsynligvis med håp om at de kan gjenopprette kostnadene sine hvis brukerne vil leie AWS EC2 beregne tilfeller for å jobbe med disse dataene) .. Dette gjør sky databehandling mye mer kostnadseffektivt, fordi tiden og kostnadene for å laste opp dataene og hosting det er nå null. Med ERDDAP™ v2.0, det er nye funksjoner for å lette drift ERDDAP I en sky:
- Nå, a EDDGrid Fra Filer eller EDDTableFra files datasett kan opprettes fra datafiler som er eksterne og tilgjengelige via Internett (f.eks. AWS S3 bøtter) ved bruk av<cacheFra Url> og<cachestørrelse GB> alternativer. ERDDAP™ vil opprettholde en lokal cache av de mest brukte datafiler.
- Nå, hvis noen EDDTableFromFiles kildefiler er komprimert (f.eks. .tgz ) , ERDDAP™ vil automatisk dekomprimere dem når det leser dem.
- Nå, den ERDDAP™ tråd som svarer på en gitt forespørsel vil gyte arbeidertråder for å jobbe på underavsnitt i forespørselen hvis du bruker<nThreads> alternativer. Denne parallelliseringen bør gi raskere svar på vanskelige forespørsler.
Disse endringene løser problemet med AWS S3 som ikke tilbyr lokal fillagring på blokknivå og (gammel) Problem med tilgang til S3-data som har et betydelig lag. (år siden (~2014) , det laget var betydelig, men er nå mye kortere og så ikke så betydelig.) Alt i alt betyr det at det å etablere ERDDAP™ I skyen fungerer mye bedre nå.
Takk - Mange takk til Matthew Arrott og hans gruppe i den opprinnelige OOI innsatsen for deres arbeid med å sette ERDDAP™ i skyen og de resulterende diskusjonene.
Fjernreparasjon av datasett
Det er et felles problem som er relatert til den ovennevnte diskusjonen om rutenett og forbund ERDDAP s: fjernreplikasjon av datasett. Det grunnleggende problemet er: en dataleverandør opprettholder et datasett som endres av og til, og en bruker ønsker å opprettholde en oppdatert lokal kopi av dette datasettet. (av en rekke grunner) .. Det er åpenbart mange variasjoner av dette. Noen variasjoner er mye vanskeligere å håndtere enn andre.
- Raske oppdateringer Det er vanskeligere å holde den lokale datasettet oppdatert umiddelbart (f.eks. innen 3 sekunder) etter hver endring til kilden i stedet for for eksempel innen noen timer.
- Hyppige endringer Hyppige endringer er vanskeligere å håndtere enn sjeldne endringer. For eksempel er en dag endringer mye lettere å håndtere enn endringer hvert 0,1 sekund.
- Små endringer Små endringer i en kildefil er vanskeligere å håndtere enn en helt ny fil. Dette er spesielt sant hvis de små endringene kan være hvor som helst i filen. Små endringer er vanskeligere å oppdage og gjøre det vanskelig å isolere dataene som må kopieres. Nye filer er enkle å oppdage og effektiv å overføre.
- Hele datasettet Å holde et helt datasett oppdatert er vanskeligere enn å opprettholde nylige data. Noen brukere trenger bare nyere data (For eksempel den siste 8 dagens verdi) ..
- Flere kopier Vedlikehold av flere fjernkopier på ulike steder er vanskeligere enn å opprettholde én fjernkopi. Dette er skaleringsproblemet.
Det er åpenbart et stort antall variasjoner av mulige typer endringer i kildedatasettet og av brukerens behov og forventninger. Mange av variasjonene er svært vanskelige å løse. Den beste løsningen for én situasjon er ofte ikke den beste løsningen for en annen situasjon - det er ennå ikke en universell flott løsning.
Relevant ERDDAP™ Verktøy
ERDDAP™ tilbyr flere verktøy som kan brukes som en del av et system som søker å opprettholde en fjernkopi av et datasett:
- ERDDAP 's RSS (Rich Site Sammendrag?) service
tilbyr en rask måte å sjekke om et datasett på en ekstern ERDDAP™ Har endret seg. - ERDDAP 's abonnementstjeneste
En mer effektiv (enn RSS ) tilnærming: det vil umiddelbart sende en e-post eller kontakte en URL til hver abonnent når datasettet oppdateres og oppdateringen resulterte i en endring. Det er effektivt i at det skjer ASAP og det er ingen bortkastet innsats (som ved å velge et RSS service) .. Brukere kan bruke andre verktøy (som IFTTT ) å reagere på e-postvarsler fra abonnementssystemet. For eksempel kan en bruker abonnere på et datasett på en ekstern ERDDAP™ og bruk IFTTT til å reagere på abonnementsmeldinger og utløse oppdatering av det lokale datasettet. - ERDDAP 's flaggsystem
gir en måte for en ERDDAP™ administrator til å fortelle et datasett på hans/hennes ERDDAP å laste ASAP på nytt. URL-formen til et flagg kan enkelt brukes i skript. URL-skjemaet til et flagg kan også brukes som handling for et abonnement. - ERDDAP 's "files" systemet
kan tilby tilgang til kildefiler for et gitt datasett, inkludert en Apache-stil katalogliste over filene (a " Web Tilgjengelig mappe") som har hver fils nedlastingsadresse, sist endret tid og størrelse. En ulempe ved bruk av "files" systemet er at kildefilene kan ha forskjellige variabelnavn og forskjellige metadata enn datasettet som det vises i ERDDAP .. Hvis en fjern ERDDAP™ datasett tilbyr tilgang til sine kildefiler, som åpner opp muligheten for en dårligmanns versjon av rsync: det blir enkelt for et lokalt system å se hvilke eksterne filer har endret seg og må lastes ned. (Se cacheFra Url-alternativ Nedenfor som kan gjøre bruk av dette.)
Løsninger
Selv om det er et stort antall variasjoner i problemet og et uendelig antall mulige løsninger, er det bare en håndfull grunnleggende tilnærminger til løsninger:
Tilpasset, Brute Force Solutions
En åpenbar løsning er å håndverke en tilpasset løsning, som derfor optimaliseres for en gitt situasjon: lage et system som oppdager/identifiserer hvilke data som har endret seg, og sender denne informasjonen til brukeren slik at brukeren kan be om endret data. Du kan gjøre dette, men det er ulemper:
- Tilpassede løsninger er mye arbeid.
- Tilpassede løsninger er vanligvis så tilpasset et gitt datasett og gitt brukerens system at de ikke lett kan gjenbrukes.
- Tilpassede løsninger må bygges og vedlikeholdes av deg. (Det er aldri en god ide. Det er alltid en god ide å unngå jobb og få andre til å gjøre jobben!)
Jeg avviser å ta denne tilnærmingen fordi det nesten alltid er bedre å lete etter generelle løsninger, bygget og vedlikeholdt av noen andre, som lett kan gjenbrukes i forskjellige situasjoner.
rsync
rsync er den eksisterende, fantastiske, generelle formål løsningen for å holde en samling av filer på en kildedatamaskin i synkronisering på en brukers eksterne datamaskin. Måten den fungerer på er:
- Noen hendelser (f.eks. en ERDDAP™ abonnent system hendelse) utløser kjører rsync, (eller, en cron jobb kjører rsync på bestemte tidspunkter hver dag på brukerens datamaskin)
- som kontakter rsync på kildedatamaskinen,
- som beregner en rekke hashes for biter i hver fil og overfører disse hashes til brukerens rsync,
- som sammenligner denne informasjonen med den lignende informasjonen for brukerens kopi av filene,
- som så ber om biter av filer som har endret seg.
Med tanke på alt det den gjør, rsync opererer veldig raskt (f.eks. 10 sekunder pluss dataoverføringstid) og veldig effektivt. Det er variasjoner av rsync som optimaliserer ulike situasjoner (f.eks. ved å forhåndsberegne og kake hashene til bitene i hver kildefil) ..
De viktigste svakhetene i rsync er: det tar litt innsats å sette opp (sikkerhetsspørsmål) ; det er noen skalering problemer; og det er ikke bra for å holde NRT datasett virkelig oppdatert (For eksempel er det vanskelig å bruke rsync mer enn omtrent hvert femte minutt.) .. Hvis du kan håndtere svakhetene, eller hvis de ikke påvirker situasjonen din, er rsync en utmerket, generell løsning som alle kan bruke akkurat nå for å løse mange scenarier som involverer fjernreplikasjon av datasett.
Det finnes et element på ERDDAP™ For å gjøre listen for å prøve å legge til støtte for rsync-tjenester i ERDDAP (Kanskje en ganske vanskelig oppgave) , slik at enhver klient kan bruke rsync (eller en variant) å opprettholde en oppdatert kopi av et datasett. Hvis noen ønsker å jobbe med dette, vennligst e-post erd.data at noaa.gov ..
Det finnes andre programmer som gjør mer eller mindre det rsync gjør, noen ganger orientert til datasett replikasjon (men ofte på et fil-kopinivå) f.eks. Unidata 's IDD ..
Cache fra Url
CacheFromUrl innstilling er tilgjengelig (Begynner med ERDDAP™ v2.0) for alle ERDDAP Datasetttyper som gjør datasett fra filer (I utgangspunktet alle underklasser av EDDGrid FraFiles og EDDTableFra Filer ) .. cache FraUrl gjør det trivielt å automatisk laste ned og vedlikeholde lokale datafiler ved å kopiere dem fra en fjernkilde via cache Fra Url-innstillingen. Eksterne filer kan være i en web-tilgjengelig mappe eller en kataloglignende filliste som tilbys av TREDDS, Hyrax En S3-bøtte, eller ERDDAP 's "files" systemet.
Hvis kilden til eksterne filer er en fjern ERDDAP™ datasett som tilbyr kildefiler via ERDDAP™ "files" system, så kan du abonnenter til fjerndatasettet, og bruk flagg URL for din lokale datasett som handling for abonnementet. Så, når fjerndatasettet endres, vil det kontakte flaggadressen for datasettet ditt, som vil fortelle det å laste ASAP på nytt, som vil oppdage og laste ned de endret eksterne datafilene. Alt dette skjer veldig raskt (vanligvis ~5 sekunder pluss den tiden som kreves for å laste ned de endret filene) .. Denne tilnærmingen fungerer bra hvis endringer i kildedatasettet er nye filer som periodisk legges til og når eksisterende filer aldri endres. Denne tilnærmingen fungerer ikke bra hvis data ofte legges til alle (eller mest) av eksisterende kildedatafiler, fordi det lokale datasettet ofte lastes ned hele fjerndatasettet. (Det er her det trengs en rsync-lignende tilnærming.)
ArkivADataset
ERDDAP™ 's ArkivADataset er en god løsning når data legges til et datasett ofte, men eldre data endres aldri. I utgangspunktet, en ERDDAP™ administrator kan kjøre ArchiveADataset (kanskje i et manus, kanskje drevet av krone) og angi en undergruppe av et datasett som de ønsker å trekke ut (Kanskje i flere filer) pakke i et .zip eller .tgz fil, slik at du kan sende filen til interesserte personer eller grupper (f.eks. NCEI for arkivering) eller gjøre det tilgjengelig for nedlasting. For eksempel kan du kjøre ArchiveADataset hver dag kl. 12:10 og få det til å gjøre en .zip av alle data fra 12:00 til 12:00 i dag. (Gjør dette ukentlig, månedlig eller årlig etter behov.) Fordi den pakkede filen genereres offline, er det ingen fare for en tidsavbrudd eller for mye data, som det ville være for en standard ERDDAP™ Forespørsel.
ERDDAP™ standard forespørselssystem
ERDDAP™ Standardforespørselssystemet er en alternativ god løsning når data legges til et datasett ofte, men eldre data endres aldri. I utgangspunktet kan alle bruke standardforespørsler til å få data for et bestemt tidsområde. For eksempel, klokken 12:10 hver dag, kan du gjøre en forespørsel om alle data fra et fjerndatasett fra 12:00 den forrige dagen til 12:00 i dag. Begrensningen (sammenlignet med ArkivADataset-tilnærmingen) er risikoen for en tidsavbrudd eller det er for mye data for en enkelt fil. Du kan unngå begrensningen ved å gjøre hyppigere forespørsler i mindre perioder.
EDDTableFraHttpGet
\[ Dette alternativet eksisterer ennå ikke, men synes å være mulig å bygge i nær fremtid. \]
Den nye EDDTableFraHttpGet datasett type i ERDDAP™ v2.0 gjør det mulig å se på en annen løsning. De underliggende filene som opprettholdes av denne typen datasett er i hovedsak loggfiler som registrerer endringer i datasettet. Det bør være mulig å bygge et system som opprettholder et lokalt datasett regelmessig (eller basert på en utløser) be om alle endringer som er gjort i fjerndatasettet siden den siste forespørselen. Dette bør være like effektivt (eller mer) enn rsync og ville håndtere mange vanskelige scenarier, men ville bare fungere hvis fjerntliggende og lokale datasett er EDDTableFramtHttpGet datasett.
Hvis noen ønsker å jobbe med dette, vennligst kontakt erd.data at noaa.gov ..
Distribuerte data
Ingen av løsningene ovenfor gjør en god jobb med å løse de harde variasjonene av problemet fordi replikasjon av nær sanntid (NRT) Datasett er svært vanskelig, delvis på grunn av alle mulige scenarier.
Det finnes en god løsning: ikke prøv å kopiere data. Bruk den autoritative kilden (Ett datasett på én ERDDAP ) , vedlikeholdt av dataleverandøren (For eksempel et regionalt kontor) .. Alle brukere som vil ha data fra det datasettet får det alltid fra kilden. For eksempel får nettleserbaserte apper data fra en URL-basert forespørsel, slik at det ikke bør være viktig at forespørselen er til den opprinnelige kilden på en ekstern server (Ikke samme server som hoster ESM) .. Mange mennesker har proklamert denne distribuerte datatilnærmingen i lang tid (Roy Mendelssohn de siste 20+ årene) .. ERDDAP Grid/føderasjonsmodell (Topp 80% av dette dokumentet) er basert på denne tilnærmingen. Denne løsningen er som et sverd til en gordisk Knot - hele problemet forsvinner.
- Denne løsningen er utrolig enkel.
- Denne løsningen er fantastisk effektiv siden det ikke gjøres noe arbeid for å holde et replikert datasett (s) Oppdatert.
- Brukere kan når som helst få de nyeste dataene (f.eks. med en latens på bare ~0,5 sekund) ..
- Det skalerer ganske bra og det er måter å forbedre skalering. (Se diskusjonen på toppen av 80% i dette dokumentet.)
Nei, dette er ikke en løsning for alle mulige situasjoner, men det er en flott løsning for det aller fleste. Hvis det er problemer/svakheter med denne løsningen i visse situasjoner, er det ofte verdt å jobbe med å løse disse problemene eller leve med disse svakhetene på grunn av de fantastiske fordelene med denne løsningen. Hvis / når denne løsningen virkelig er uakseptabel for en gitt situasjon, f.eks. når du virkelig må ha en lokal kopi av dataene, så bør du vurdere de andre løsningene som diskuteres ovenfor.
Konklusjon
Mens det ikke finnes noen enkelt, enkel løsning som perfekt løser alle problemene i alle scenarier (som rsync og distribuerte data nesten er) Forhåpentligvis finnes det tilstrekkelige verktøy og alternativer slik at du kan finne en akseptabel løsning for din spesielle situasjon.