स्केलिंग
ERDDAP™ - हेवी लोड, ग्रिड, क्लस्टर्स, फेडरेशन और क्लाउड कम्प्यूटिंग
ERDDAP :
ERDDAP™ एक वेब अनुप्रयोग और एक वेब सेवा है जो विविध स्थानीय और दूरस्थ स्रोतों से वैज्ञानिक डेटा को एकत्रित करती है और सामान्य फ़ाइल स्वरूपों में डेटा के सबसेट को डाउनलोड करने और ग्राफ और मैप बनाने का एक सरल, सुसंगत तरीका प्रदान करती है। यह वेब पेज भारी से संबंधित मुद्दों पर चर्चा करता है ERDDAP™ ग्रिड, क्लस्टर, federations और क्लाउड कंप्यूटिंग के माध्यम से अत्यंत भारी भार से निपटने के लिए उपयोग भार और संभावनाओं की पड़ताल करता है।
मूल संस्करण जून 2009 में लिखा गया था। इसमें कोई महत्वपूर्ण बदलाव नहीं हुआ है। यह आखिरी अपडेट 2019-04-15 था।
अस्वीकरण
इस वेब पेज की सामग्री बॉब सिमोन व्यक्तिगत राय हैं और जरूरी नहीं कि सरकार या सरकार की किसी भी स्थिति को प्रतिबिंबित करें। National Oceanic and Atmospheric Administration । गणना सरल है, लेकिन मुझे लगता है कि निष्कर्ष सही हैं। क्या मैं दोषपूर्ण तर्क का उपयोग करता हूं या मेरी गणना में गलती करता हूं? यदि ऐसा है तो गलती अकेले मेरा है। कृपया सुधार के साथ एक ईमेल भेजें erd dot data at noaa dot gov ।
हेवी लोड / कंस्ट्रक्शन
भारी उपयोग के साथ, एक स्टैंडअलोन ERDDAP™ रोका जाएगा (कम से कम संभावना) द्वारा:
रिमोट सोर्स बैंडविड्थ
- दूरस्थ डेटा स्रोत की बैंडविड्थ - यहां तक कि एक कुशल कनेक्शन के साथ (उदाहरण के लिए, माध्यम से OPeNDAP ) जब तक दूरस्थ डेटा स्रोत में बहुत अधिक बैंडविड्थ इंटरनेट कनेक्शन नहीं होता है, तब तक ERDDAP 'प्रतिक्रियाओं को कैसे तेजी से नियंत्रित किया जाएगा ERDDAP™ डेटा स्रोत से डेटा प्राप्त कर सकते हैं। एक समाधान डेटासेट को कॉपी करना है ERDDAP शायद हार्ड ड्राइव के साथ EDDGrid कॉपी या EDDTableCopy ।
ERDDAP सर्वर बैंडविड्थ
- असहाय ERDDAP सर्वर में एक बहुत ही उच्च बैंडविड्थ इंटरनेट कनेक्शन है, ERDDAP 'प्रतिक्रियाओं को कैसे तेजी से नियंत्रित किया जाएगा ERDDAP™ डेटा स्रोतों से डेटा प्राप्त कर सकते हैं और कैसे तेजी से ERDDAP™ ग्राहकों को डेटा वापस कर सकते हैं। एकमात्र समाधान एक तेज़ इंटरनेट कनेक्शन प्राप्त करना है।
स्मृति
- यदि एक साथ कई अनुरोध हैं, ERDDAP™ स्मृति से बाहर निकल सकते हैं और अस्थायी रूप से नए अनुरोधों को मना कर सकते हैं। ( ERDDAP™ इससे बचने के लिए और अगर ऐसा होता है तो परिणामों को कम करने के लिए कुछ तंत्र हैं।) इसलिए सर्वर में अधिक मेमोरी बेहतर है। 32-बिट सर्वर पर, 4+ जीबी वास्तव में अच्छा है, 2 जीबी ठीक है, कम अनुशंसित नहीं है। 64-बिट सर्वर पर, आप लगभग पूरी तरह से स्मृति के बहुत सारे द्वारा समस्या से बच सकते हैं। देखें \-Xmx और -Xms सेटिंग्स के लिए ERDDAP /Tomcat। An ERDDAP™ 8GB मेमोरी के साथ 64-बिट सर्वर वाले कंप्यूटर पर भारी उपयोग हो रहा है और -Xmx 4000M के लिए सेट शायद ही कभी, अगर कभी स्मृति द्वारा बाधित है।
हेड ड्राइव बैंडविड्थ
- सर्वर की हार्ड ड्राइव पर संग्रहीत डेटा तक पहुंच दूरस्थ डेटा तक पहुंचने की तुलना में बहुत तेज़ है। यहां तक कि अगर ERDDAP™ सर्वर में एक बहुत ही उच्च बैंडविड्थ इंटरनेट कनेक्शन है, यह संभव है कि हार्ड ड्राइव पर डेटा तक पहुंचना बोतलबंद होगा। आंशिक समाधान तेजी से उपयोग करना है (उदाहरण के लिए, 10,000 आरपीएम) चुंबकीय हार्ड ड्राइव या एसएसडी ड्राइव (यदि यह अर्थ लागत-वार बनाता है) । एक अन्य समाधान विभिन्न ड्राइव पर विभिन्न डेटासेट स्टोर करना है, ताकि संचयी हार्ड ड्राइव बैंडविड्थ बहुत अधिक हो।
Too Many Files.
- बहुत सारी फाइलों में एक कैश निर्देशिका — ERDDAP™ सभी छवियों को कैश करता है, लेकिन केवल कुछ प्रकार के डेटा अनुरोधों के लिए डेटा को कैश करता है। डेटासेट के लिए कैश डायरेक्टरी के लिए यह संभव है कि इसमें बड़ी संख्या में फाइलें अस्थायी रूप से हो जाएं। यह देखने के लिए अनुरोध को धीमा कर देगा कि क्या फ़ाइल कैश में है या नहीं (वास्तव में!) ।<कैश मिनट> in साइटमैप आपको यह निर्धारित करने की अनुमति देता है कि जब तक फ़ाइल को डिलीट होने से पहले कैश में किया जा सकता है। एक छोटी संख्या की स्थापना इस समस्या को कम कर देगी।
सीपीयू
- केवल दो चीजें सीपीयू समय लेती हैं:
- NetCDF 4 और 4 HDF 5 अब डेटा के आंतरिक संपीड़न का समर्थन करते हैं। एक बड़े संकुचित NetCDF 4/4 HDF 5 डेटा फ़ाइल 10 या अधिक सेकंड ले सकती है। (यह एक कार्यान्वयन दोष नहीं है। यह संपीड़न की प्रकृति है।) इसलिए, संपीड़ित फ़ाइलों में संग्रहीत डेटासेट के साथ डेटासेट के लिए एकाधिक एक साथ अनुरोध किसी भी सर्वर पर गंभीर तनाव डाल सकता है। यदि यह एक समस्या है, तो समाधान असंपीड़ित फ़ाइलों में लोकप्रिय डेटासेट को स्टोर करना है, या अधिक कोर वाले सीपीयू के साथ सर्वर प्राप्त करना है।
- ग्राफ़ बनाना (नक्शे सहित) लगभग 0.2 - 1 प्रति ग्राफ। इसलिए यदि ग्राफ के लिए कई एक साथ अद्वितीय अनुरोध थे ( WMS ग्राहक अक्सर 6 एक साथ अनुरोध करते हैं!) , वहाँ एक CPU सीमा हो सकता है। जब एकाधिक उपयोगकर्ता चल रहे हैं WMS ग्राहक, यह एक समस्या बन जाती है।
एकाधिक पहचान ERDDAP लोड संतुलन के साथ एस?
अक्सर सवाल उठता है: "भारी भार से निपटने के लिए, मैं एकाधिक समान सेट कर सकता हूं ERDDAP लोड संतुलन के साथ एस? यह एक दिलचस्प सवाल है क्योंकि यह जल्दी से मूल के लिए हो जाता है ERDDAP डिजाइन त्वरित उत्तर "नहीं" है। मुझे पता है कि एक निराशाजनक जवाब है, लेकिन कुछ प्रत्यक्ष कारण हैं और कुछ बड़े मूलभूत कारण क्यों मैंने डिजाइन किया है ERDDAP™ एक अलग दृष्टिकोण का उपयोग करने के लिए (संघटन ERDDAP S, इस दस्तावेज़ के थोक में वर्णित) जो मैं मानता हूँ वह बेहतर समाधान है।
कुछ प्रत्यक्ष कारण क्यों आप एकाधिक समान क्यों स्थापित नहीं कर सकते / नहीं कर सकते ERDDAP एस हैं:
- देना ERDDAP™ जब यह पहली बार फाइल में डेटा की श्रेणियों को खोजने के लिए उपलब्ध हो जाता है तो प्रत्येक डेटा फ़ाइल को पढ़ता है। इसके बाद यह जानकारी एक इंडेक्स फाइल में स्टोर करती है। बाद में, जब डेटा के लिए उपयोगकर्ता अनुरोध आता है, ERDDAP™ उस सूचकांक का उपयोग यह पता लगाने के लिए करता है कि कौन से फ़ाइलों को अनुरोधित डेटा के लिए देखने के लिए। यदि वहाँ कई समान थे ERDDAP s, वे प्रत्येक इस अनुक्रमण को कर रहे थे, जो प्रयास किया गया है। नीचे वर्णित federated प्रणाली के साथ, अनुक्रमण केवल एक बार किया जाता है, एक द्वारा ERDDAP S.
- कुछ प्रकार के उपयोगकर्ता अनुरोधों के लिए (उदाहरण के लिए .nc पीडीएफ फाइलें) ERDDAP™ जवाब भेजे जाने से पहले पूरी फाइल बनाना होगा। तो ERDDAP™ इन फ़ाइलों को थोड़े समय के लिए कैश करता है। यदि एक समान अनुरोध आता है (जैसा कि यह अक्सर करता है, विशेष रूप से उन छवियों के लिए जहां यूआरएल एक वेब पेज में एम्बेडेड है) , ERDDAP™ उस कैश्ड फ़ाइल का पुन: उपयोग कर सकते हैं। एकाधिक समान प्रणाली में ERDDAP उन कैश्ड फ़ाइलों को साझा नहीं किया जाता है, इसलिए प्रत्येक ERDDAP™ अनावश्यक और बेकार ढंग से फिर से बनाना .nc , .png, or .pdf files. नीचे वर्णित federated प्रणाली के साथ, फ़ाइलों को केवल एक बार बनाया जाता है, एक द्वारा ERDDAP S, and reused.
- ERDDAP सदस्यता प्रणाली एकाधिक द्वारा साझा करने के लिए सेट नहीं है ERDDAP S. उदाहरण के लिए, यदि लोड बैलेंसर एक उपयोगकर्ता को एक उपयोगकर्ता को भेज देता है ERDDAP™ और उपयोगकर्ता डेटासेट की सदस्यता लेता है, फिर दूसरा ERDDAP उस सदस्यता के बारे में नहीं जानते होंगे। बाद में, यदि लोड बैलेंसर उपयोगकर्ता को अलग-अलग में भेज देता है ERDDAP™ और उसकी सदस्यता की एक सूची के लिए पूछता है, अन्य ERDDAP™ नहीं कहेगा (उसे दूसरे ERED पर एक डुप्लिकेट सदस्यता बनाने के लिए अग्रणी DAP ) । नीचे वर्णित federated प्रणाली के साथ, सदस्यता प्रणाली को बस मुख्य, सार्वजनिक, समग्र द्वारा संभाला जाता है। ERDDAP ।
हाँ, उनमें से प्रत्येक समस्या के लिए मैं सकता हूँ (महान प्रयास के साथ) एक समाधान इंजीनियर (जानकारी साझा करने के लिए ERDDAP s) लेकिन मुझे लगता है फेडरेशन-ऑफ- ERDDAP दृष्टिकोण (इस दस्तावेज़ के थोक में वर्णित) एक बेहतर समग्र समाधान है, आंशिक रूप से क्योंकि यह अन्य समस्याओं के साथ सौदा करता है कि एकाधिक-identical- ERDDAP S-with-a-load-संतुलन दृष्टिकोण भी दुनिया में डेटा स्रोतों की विकेन्द्रीकृत प्रकृति को संबोधित करना शुरू नहीं करता है।
यह सरल तथ्य यह है कि मैंने डिजाइन नहीं किया था स्वीकार करना सबसे अच्छा है ERDDAP™ एकाधिक समान के रूप में तैनात किया जाना ERDDAP लोड बैलेंसर के साथ मैं लगातार डिजाइन ERDDAP™ अच्छी तरह से काम करने के लिए ERDDAP मैं मानता हूँ कि कई फायदे हैं। विशेष रूप से, एक संघ का संघ ERDDAP S पूरी तरह से डेटा केन्द्रों की विकेन्द्रीकृत, वितरित प्रणाली है कि हम वास्तविक दुनिया में है के साथ गठबंधन है (विभिन्न IOOS क्षेत्रों, या विभिन्न कोस्टवॉच क्षेत्रों, या NCEI के विभिन्न हिस्सों, या 100 अन्य डेटा केंद्रों के बारे में सोचते हैं। NOAA , या विभिन्न NASA DAACs, या दुनिया भर में 1000 के डेटा सेंटर) । दुनिया के सभी डेटा केंद्रों को बताने के बजाय कि उन्हें अपने प्रयासों को छोड़ने और उनके सभी डेटा को केंद्रीकृत "डाटा झील" में रखने की आवश्यकता है। (यहां तक कि अगर यह संभव था, तो यह कई कारणों से एक भयानक विचार है - विभिन्न विश्लेषणों को देखें जो कई फायदे दिखाते हैं विकेन्द्रीकृत प्रणाली ) , ERDDAP यह दुनिया के साथ काम करता है। प्रत्येक डेटा सेंटर जो डेटा का उत्पादन करता है, उसे बनाए रखने, ठीक करने और अपने डेटा की सेवा करने के लिए जारी रख सकता है। (जैसा कि उन्हें होना चाहिए) अभी तक, ERDDAP™ , डेटा भी तुरंत एक केंद्रीकृत से उपलब्ध हो सकता है ERDDAP डेटा को केंद्रीकृत करने की आवश्यकता के बिना ERDDAP™ या डेटा की डुप्लिकेट प्रतियां संग्रहीत करना। वास्तव में, एक निश्चित डेटासेट एक साथ उपलब्ध हो सकता है से ERDDAP™ उस संगठन में जो डेटा उत्पन्न और वास्तव में स्टोर करता है (उदाहरण के लिए, GoMOOS) , से ERDDAP™ मूल संगठन में (उदाहरण के लिए, IOOS सेंट्रल) , सभी से NOAA ERDDAP™ , सभी अमेरिकी संघीय सरकार से ERDDAP™ , वैश्विक ERDDAP™ (GOOS) , और विशेष से ERDDAP s (उदाहरण के लिए, एक ERDDAP™ एचएबी अनुसंधान के लिए समर्पित एक संस्थान में) , सभी अनिवार्य रूप से तत्काल और कुशलतापूर्वक क्योंकि केवल मेटाडाटा को बीच में स्थानांतरित किया जाता है ERDDAP S, डेटा नहीं। सबसे अच्छा, प्रारंभिक के बाद ERDDAP™ मूल संगठन में, अन्य सभी ERDDAP जल्दी से सेट किया जा सकता है (कुछ घंटों का काम) न्यूनतम संसाधनों के साथ (एक सर्वर जिसे डेटा स्टोरेज के लिए किसी भी RAID की आवश्यकता नहीं है क्योंकि यह स्थानीय रूप से कोई डेटा स्टोर नहीं करता है) इस प्रकार, वास्तव में न्यूनतम लागत पर। तुलना करें कि डेटा झील के साथ एक केंद्रीकृत डेटा केंद्र स्थापित करने और बनाए रखने की लागत और वास्तव में एक विशाल, वास्तव में महंगा, इंटरनेट कनेक्शन की आवश्यकता, साथ ही केंद्रीकृत डेटा केंद्र की उपस्थितित्मक समस्या भी असफलता का एक बिंदु है। मेरे लिए ERDDAP s विकेन्द्रीकृत, federated दृष्टिकोण अब तक बेहतर है।
उन स्थितियों में जहां किसी दिए गए डेटा सेंटर को एकाधिक की आवश्यकता होती है ERDDAP उच्च मांग को पूरा करने के लिए, ERDDAP 's डिजाइन पूरी तरह से मिलान करने या एकाधिक-identical- के प्रदर्शन से अधिक करने में सक्षम है ERDDAP S-with-a-load-संतुलन दृष्टिकोण। आपके पास हमेशा सेटिंग का विकल्प होता है एकाधिक समग्र ERDDAP s (नीचे चर्चा) उनमें से प्रत्येक दूसरे से अपने सभी डेटा प्राप्त करता है ERDDAP भार संतुलन के बिना एस। इस मामले में, मैं अनुशंसा करता हूं कि आप प्रत्येक समग्र को देने का एक बिंदु बनाते हैं ERDDAP एक अलग नाम / पहचान है और यदि संभव हो तो उन्हें दुनिया के विभिन्न हिस्सों में सेट करना (उदाहरण के लिए, विभिन्न AWS क्षेत्रों) , उदाहरण के लिए, ERD \_US \_East, ERD \_US \_West, ERD आईई ERD \_FR, ERD \_IT, ताकि उपयोगकर्ता लगातार, बार-बार, एक विशिष्ट के साथ काम करें ERDDAP इसके अतिरिक्त लाभ के साथ आप असफलता के एक बिंदु से जोखिम को हटा दिया है।
ग्रिड, क्लस्टर और फेडरेशन
बहुत भारी उपयोग के तहत, एक एकल स्टैंडअलोन ERDDAP™ एक या अधिक में चला जाएगा बाधा ऊपर सूचीबद्ध और यहां तक कि सुझाए गए समाधान अपर्याप्त होंगे। ऐसी स्थितियों के लिए, ERDDAP™ विशेषताएं हैं जो स्केलेबल ग्रिड का निर्माण करना आसान बनाते हैं (इसे क्लस्टर या federations भी कहा जाता है) of ERDDAP जो सिस्टम को बहुत भारी उपयोग को संभालने की अनुमति देता है (उदाहरण के लिए, एक बड़े डेटा सेंटर के लिए) ।
मैं उपयोग कर रहा हूँ ग्रिड सामान्य शब्द के रूप में एक प्रकार का संकेत देने के लिए कंप्यूटर क्लस्टर जहां सभी भाग शारीरिक रूप से एक सुविधा में स्थित हो सकते हैं या नहीं हो सकते हैं और केंद्रीय रूप से प्रशासित नहीं हो सकते हैं। सहकारी, केंद्रीय स्वामित्व और प्रशासित ग्रिड का लाभ (क्लस्टर) यह है कि वे पैमाने की अर्थव्यवस्थाओं से लाभान्वित होते हैं (विशेष रूप से मानव कार्यभार) और सिस्टम के कुछ हिस्सों को अच्छी तरह से एक साथ काम करने के लिए सरल। गैर-co-located ग्रिड, गैर-केंद्रीय स्वामित्व और प्रशासित का लाभ (federation) यह है कि वे मानव कार्यभार और लागत को वितरित करते हैं और कुछ अतिरिक्त दोष सहिष्णुता प्रदान कर सकते हैं। समाधान मैं सभी ग्रिड, क्लस्टर और फेडरेशन topographies के लिए अच्छी तरह से काम करता है।
स्केलेबल सिस्टम को डिजाइन करने का मूल विचार संभावित बाधाओं की पहचान करना है और फिर सिस्टम को डिजाइन करना है ताकि सिस्टम के कुछ हिस्सों को बोतलबंदी को कम करने के लिए आवश्यकतानुसार दोहराया जा सके। आदर्श रूप से, प्रत्येक दोहरा हुआ हिस्सा सिस्टम के उस हिस्से की क्षमता को रैखिक रूप से बढ़ाता है (स्केलिंग की दक्षता) । यह प्रणाली स्केलेबल नहीं है जब तक कि प्रत्येक बाधा के लिए स्केलेबल समाधान नहीं होता है। स्केलेबिलिटी दक्षता से अलग है (कैसे जल्दी से एक कार्य किया जा सकता है - भागों की दक्षता) । स्केलेबिलिटी सिस्टम को किसी भी स्तर की मांग को संभालने की अनुमति देती है। दक्षता (स्केलिंग और भागों के हिस्से) यह निर्धारित करता है कि कितने सर्वर आदि को मांग के स्तर को पूरा करने की आवश्यकता होगी। दक्षता बहुत महत्वपूर्ण है, लेकिन हमेशा सीमा होती है। स्केलेबिलिटी एक सिस्टम बनाने का एकमात्र व्यावहारिक समाधान है जो संभाल सकता है बहुत भारी उपयोग। आदर्श रूप से, सिस्टम स्केलेबल और कुशल होगा।
गोल
इस डिजाइन के लक्ष्य हैं:
- एक स्केलेबल आर्किटेक्चर बनाने के लिए (किसी भी हिस्से को दोहराकर आसानी से एक्स्टेंसिबल हो सकता है जो ओवर-बर्ड हो जाता है) । एक कुशल प्रणाली बनाने के लिए जो उपलब्ध कंप्यूटिंग संसाधनों को दिए गए डेटा की उपलब्धता को अधिकतम करता है। (लागत लगभग हमेशा एक मुद्दा है।)
- सिस्टम के कुछ हिस्सों की क्षमताओं को संतुलित करने के लिए ताकि सिस्टम का एक हिस्सा दूसरे भाग को अभिभूत न हो।
- एक सरल वास्तुकला बनाने के लिए ताकि सिस्टम को स्थापित करना और प्रशासित करना आसान हो।
- एक वास्तुकला बनाने के लिए जो सभी ग्रिड टोपोग्राफी के साथ अच्छी तरह से काम करता है।
- एक ऐसी प्रणाली बनाने के लिए जो सुंदर ढंग से विफल हो जाती है और एक सीमित तरीके से यदि कोई हिस्सा अति-बर्ड हो जाता है। (एक बड़े डेटासेट की प्रतिलिपि बनाने के लिए आवश्यक समय हमेशा एक विशिष्ट डेटासेट की मांग में अचानक वृद्धि से निपटने की प्रणाली की क्षमता को सीमित करेगा।)
- (यदि संभव हो) एक ऐसी वास्तुकला बनाने के लिए जो किसी विशिष्ट विशिष्ट से जुड़ा नहीं है क्लाउड कंप्यूटिंग सेवा या अन्य बाह्य सेवाएं (क्योंकि उन्हें इसकी आवश्यकता नहीं है) ।
सिफारिश
हमारी सिफारिशें हैं
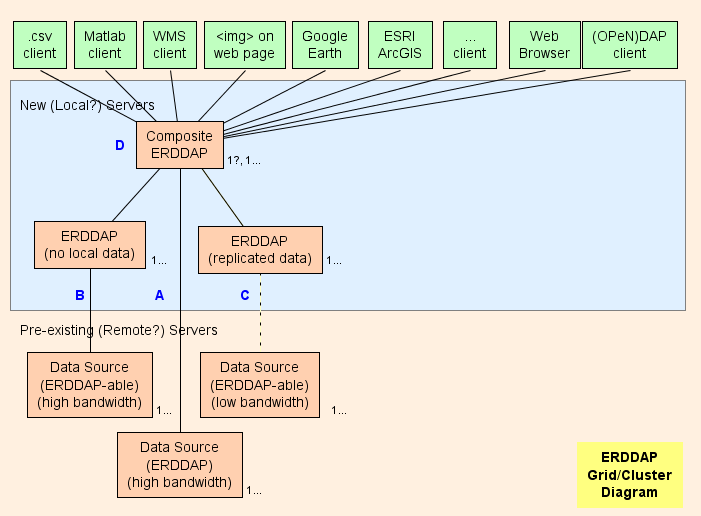
- मूल रूप से, मैं सुझाव देता हूँ कि एक समग्र स्थापना ERDDAP™ ( D आरेख में) , जो एक नियमित है ERDDAP™ सिवाय इसके कि यह सिर्फ दूसरे से डेटा प्रदान करता है ERDDAP S. ग्रिड की वास्तुकला को जितना संभव हो उतना काम करने के लिए डिज़ाइन किया गया है (CPU उपयोग, मेमोरी उपयोग, बैंडविड्थ उपयोग) समग्र से ERDDAP™ अन्य ERDDAP S.
- ERDDAP™ दो विशेष डेटासेट प्रकार हैं, EDDGrid सेंध और EDDTableFromErddap , जो संदर्भित करता है अन्य डेटासेट ERDDAP S.
- जब समग्र ERDDAP™ इन डेटासेट, समग्र से डेटा या छवियों के लिए अनुरोध प्राप्त करता है ERDDAP™ पुनर्निर्देशन अन्य को डेटा अनुरोध ERDDAP™ सर्वर परिणाम है:
- यह बहुत कुशल है (सीपीयू, मेमोरी और बैंडविड्थ) अन्यथा
- समग्र ERDDAP™ अन्य को डेटा अनुरोध भेजना है ERDDAP ।
- अन्य ERDDAP™ डेटा प्राप्त करना, इसे सुधारना और डेटा को समग्र में संचारित करना है ERDDAP ।
- समग्र ERDDAP™ डेटा प्राप्त करना (अतिरिक्त बैंडविड्थ का उपयोग करना) इसे सुधारना (अतिरिक्त CPU समय और स्मृति का उपयोग करना) , और उपयोगकर्ता को डेटा संचारित (अतिरिक्त बैंडविड्थ का उपयोग करना) । डेटा अनुरोध को पुनर्निर्देशित करके और अन्य की अनुमति देकर ERDDAP™ उपयोगकर्ता को सीधे प्रतिक्रिया भेजने के लिए, समग्र ERDDAP™ अनिवार्य रूप से डेटा अनुरोधों पर कोई सीपीयू समय, मेमोरी या बैंडविड्थ खर्च नहीं करता है।
- ग्राहक सॉफ्टवेयर की परवाह किए बिना उपयोगकर्ता के लिए पुनर्निर्देशित है (ब्राउज़र या किसी अन्य सॉफ्टवेयर या कमांड लाइन टूल) ।
- यह बहुत कुशल है (सीपीयू, मेमोरी और बैंडविड्थ) अन्यथा
ग्रिड पार्ट्स
A : प्रत्येक दूरस्थ डेटा स्रोत के लिए जिसमें एक उच्च बैंडविड्थ है OPeNDAP सर्वर, आप सीधे दूरस्थ सर्वर से जुड़ सकते हैं। यदि दूरस्थ सर्वर एक है ERDDAP™ उपयोग EDDGrid FromErddap or EDDTableFrom ERDDAP समग्र में डेटा की सेवा करने के लिए ERDDAP । यदि दूरस्थ सर्वर कुछ अन्य प्रकार का है DAP सर्वर, उदाहरण के लिए, THREDDS, Hyrax , या GrADS, उपयोग EDDGrid FromDap.
बी प्रत्येक के लिए ERDDAP -able डेटा स्रोत (डेटा स्रोत ERDDAP डेटा पढ़ सकते हैं) इसमें एक उच्च बैंडविड्थ सर्वर है, एक और सेट अप करें ERDDAP™ ग्रिड में जो इस डेटा स्रोत से डेटा की सेवा के लिए जिम्मेदार है।
- यदि ऐसे कई ERDDAP डेटा के लिए कई अनुरोध प्राप्त नहीं कर रहे हैं, आप उन्हें एक में समेकित कर सकते हैं ERDDAP ।
- यदि ERDDAP™ एक दूरस्थ स्रोत से डेटा प्राप्त करने के लिए समर्पित बहुत सारे अनुरोध प्राप्त कर रहा है, अतिरिक्त जोड़ने का प्रलोभन है ERDDAP दूरस्थ डेटा स्रोत तक पहुंचने के लिए। विशेष मामलों में यह समझ सकता है, लेकिन यह अधिक संभावना है कि यह दूरस्थ डेटा स्रोत को अभिभूत करेगा। (जो आत्म-defeating है) और अन्य उपयोगकर्ताओं को दूरस्थ डेटा स्रोत तक पहुंचने से रोकता है (जो अच्छा नहीं है) । ऐसे मामले में, किसी अन्य को स्थापित करने पर विचार करें ERDDAP™ उस डेटासेट की सेवा करने और उस पर डेटासेट की प्रतिलिपि बनाने के लिए ERDDAP हार्ड ड्राइव (देखें C ) शायद EDDGrid कॉपी और/or EDDTableCopy ।
- बी सर्वर सार्वजनिक रूप से सुलभ होना चाहिए।
C प्रत्येक के लिए ERDDAP -able डेटा स्रोत जिसमें कम बैंडविड्थ सर्वर है (या अन्य कारणों से एक धीमी सेवा है) , एक दूसरे को स्थापित करने पर विचार करें ERDDAP™ और उस पर डेटासेट की एक प्रति को संग्रहीत करना ERDDAP शायद हार्ड ड्राइव के साथ EDDGrid कॉपी और/or EDDTableCopy । यदि ऐसे कई ERDDAP डेटा के लिए कई अनुरोध प्राप्त नहीं कर रहे हैं, आप उन्हें एक में समेकित कर सकते हैं ERDDAP । C सर्वर सार्वजनिक रूप से सुलभ होना चाहिए।
समग्र ERDDAP
D : समग्र ERDDAP™ नियमित ERDDAP™ सिवाय इसके कि यह सिर्फ दूसरे से डेटा प्रदान करता है ERDDAP S.
- क्योंकि समग्र ERDDAP™ सभी डेटासेटों के बारे में स्मृति में जानकारी है, यह डेटासेट की सूची के लिए अनुरोधों को तुरंत जवाब दे सकता है (पूर्ण पाठ खोज, श्रेणी खोज, सभी डेटासेट की सूची) एक व्यक्तिगत डेटासेट के डेटा एक्सेस फॉर्म के लिए अनुरोध करता है, एक ग्राफ फॉर्म बनाता है, या WMS सूचना पट्ट ये सभी छोटे, गतिशील रूप से उत्पन्न होते हैं, जिन्हें स्मृति में आयोजित जानकारी के आधार पर HTML पृष्ठ हैं। इसलिए प्रतिक्रियाएं बहुत तेज हैं।
- क्योंकि वास्तविक डेटा के लिए अनुरोध जल्दी से दूसरे पर रीडायरेक्ट हो जाते हैं ERDDAP S, समग्र ERDDAP™ किसी भी सीपीयू समय, मेमोरी या बैंडविड्थ का उपयोग किए बिना वास्तविक डेटा के लिए जल्दी से अनुरोधों का जवाब दे सकता है।
- जितना संभव हो उतना काम स्थानांतरित करके (सीपीयू, मेमोरी, बैंडविड्थ) समग्र से ERDDAP™ अन्य ERDDAP S, समग्र ERDDAP™ सभी डेटासेट से डेटा की सेवा करने के लिए प्रकट हो सकता है और फिर भी बड़ी संख्या में उपयोगकर्ताओं से बहुत बड़ी संख्या में डेटा अनुरोधों के साथ रख सकता है।
- प्रारंभिक परीक्षण इंगित करता है कि समग्र ERDDAP™ सीपीयू समय, या 1000 अनुरोध / सेकंड के ~ 1ms में अधिकांश अनुरोधों का जवाब दे सकते हैं। इसलिए 8 कोर प्रोसेसर लगभग 8000 अनुरोधों / सेकंड का जवाब देने में सक्षम होना चाहिए। हालांकि उच्च गतिविधि के फटने की कल्पना करना संभव है जो धीमी गति का कारण बनता है। यह संभावना है कि डेटा सेंटर बैंडविड्थ समग्र होने से पहले बोतलबंद हो जाएगा ERDDAP™ बोतलबंद हो जाता है।
अप करने के लिए तारीख अधिकतम (समय) ?
The The most of the EDDGrid /TableFromErddap समग्र में ERDDAP™ जब स्रोत डेटासेट होता है तो केवल प्रत्येक स्रोत डेटासेट के बारे में अपनी संग्रहीत जानकारी बदलता है "reload"ed मेटाडाटा परिवर्तन का कुछ टुकड़ा (उदाहरण के लिए, समय चर actual\_range ) जिससे सदस्यता अधिसूचना उत्पन्न होती है। यदि स्रोत डेटासेट में डेटा होता है जो अक्सर बदलता है (उदाहरण के लिए, प्रत्येक सेकंड में नया डेटा) और उपयोग "update" अंतर्निहित डेटा में लगातार परिवर्तन को नोटिस करने के लिए सिस्टम, EDDGrid /TableFromErddap अगले डेटासेट "रीलोड" तक इन लगातार परिवर्तनों के बारे में सूचित नहीं किया जाएगा, इसलिए EDDGrid /TableFromErddap पूरी तरह से अद्यतन नहीं होगा। आप स्रोत डेटासेट के बदलकर इस समस्या को कम कर सकते हैं<ReloadEveryNMinutes> एक छोटा सा मूल्य (60?) इतना है कि वहाँ अधिक सदस्यता अधिसूचनाओं को बताने के लिए कर रहे हैं EDDGrid /TableFromErddap स्रोत डेटासेट के बारे में अपनी जानकारी अद्यतन करने के लिए।
यदि आपके डेटा प्रबंधन प्रणाली को पता चलता है कि स्रोत डेटासेट में नया डेटा है (उदाहरण के लिए, एक स्क्रिप्ट के माध्यम से जो एक डेटा फ़ाइल को जगह में कॉपी करता है) , और अगर वह सुपर लगातार नहीं है (उदाहरण के लिए, हर 5 मिनट, या कम लगातार) एक बेहतर समाधान है:
- उपयोग न करें<अद्यतन EveryNMillis> स्रोत डेटासेट अप-टू-डेट रखने के लिए।
- स्रोत डेटासेट सेट करें<ReloadEveryNMinutes> एक बड़ी संख्या में (1440?) ।
- स्क्रिप्ट स्रोत डेटासेट से संपर्क करें ध्वज यूआरएल इसके ठीक बाद एक नई डेटा फ़ाइल को जगह में कॉपी किया जाता है। इससे स्रोत डेटासेट पूरी तरह से अप-टू-डेट होने का कारण बनता है और इसे सदस्यता अधिसूचना उत्पन्न करने का कारण बनता है, जिसे भेजा जाएगा। EDDGrid /TableFromErddap डेटासेट। यही कारण है कि नेतृत्व करेंगे EDDGrid /TableFromErddap डेटासेट पूरी तरह से अद्यतन करने के लिए (अच्छी तरह से, नए डेटा के 5 सेकंड के भीतर जोड़ा जा रहा है) । वह सब जो कुशलतापूर्वक किया जाएगा (अनावश्यक डेटासेट रीलोड के बिना) ।
एकाधिक समग्र ERDDAP s
- बहुत चरम मामलों में, या गलती सहिष्णुता के लिए, आप एक से अधिक समग्र स्थापित करना चाहते हैं ERDDAP । यह संभावना है कि सिस्टम के अन्य हिस्सों (विशेष रूप से, डेटा सेंटर की बैंडविड्थ) समग्र होने से पहले एक समस्या बन जाएगी ERDDAP™ एक bottleneck हो जाता है। इसलिए समाधान शायद अतिरिक्त, भौगोलिक रूप से विविध, डेटा केंद्रों को स्थापित करना है (दर्पण) प्रत्येक एक समग्र के साथ ERDDAP™ सर्वर ERDDAP s और (कम से कम) डेटासेट की दर्पण प्रतियां जो उच्च मांग में हैं। ऐसा सेटअप भी दोष सहिष्णुता और डेटा बैकअप प्रदान करता है (कॉपी करके) । इस मामले में, यह सबसे अच्छा है अगर समग्र ERDDAP s अलग यूआरएल है।
यदि आप वास्तव में सभी समग्र चाहते हैं ERDDAP एक ही यूआरएल होने के लिए, एक फ्रंट एंड सिस्टम का उपयोग करें जो किसी दिए गए उपयोगकर्ता को केवल एक समग्र में सौंप देता है। ERDDAP s (IP पते पर आधारित) इसलिए कि सभी उपयोगकर्ता के अनुरोध केवल एक समग्र में से एक के पास जाते हैं ERDDAP S. दो कारण हैं:
- जब एक अंतर्निहित डेटासेट को पुनः लोड किया जाता है और मेटाडाटा परिवर्तन (उदाहरण के लिए, एक ग्रिड डेटासेट में एक नई डेटा फ़ाइल समय चर का कारण बनती है actual\_range बदलना) समग्र ERDDAP एस अस्थायी रूप से सिंक से थोड़ा बाहर हो जाएगा, लेकिन साथ में सतत स्थिरता । आम तौर पर, वे 5 सेकंड के भीतर फिर से सिंच करेंगे, लेकिन कभी-कभी यह लंबा होगा। यदि कोई उपयोगकर्ता एक स्वचालित प्रणाली बनाता है जो निर्भर करता है ERDDAP™ सदस्यता कि ट्रिगर क्रियाओं, संक्षिप्त तुल्यकालन समस्याओं महत्वपूर्ण हो जाएगा।
- 2+ समग्र ERDDAP प्रत्येक सदस्यता के अपने सेट को बनाए रखने (ऊपर वर्णित वाक्य समस्या के कारण) ।
इसलिए किसी दिए गए उपयोगकर्ता को केवल एक समग्र के लिए निर्देशित किया जाना चाहिए ERDDAP इन समस्याओं से बचने के लिए। यदि एक समग्र ERDDAP S नीचे चला जाता है, फ्रंट एंड सिस्टम को रीडायरेक्ट कर सकते हैं कि ERDDAP उपयोगकर्ता दूसरे के लिए ERDDAP™ यह ऊपर है। हालांकि, अगर यह एक क्षमता समस्या है जो पहले समग्र का कारण बनता है ERDDAP™ असफल होना (एक overzealous उपयोगकर्ता? a डैनियल ऑफ सर्विस हमले ?) यह बहुत संभावना है कि अपने उपयोगकर्ताओं को अन्य समग्र में पुनर्निर्देशित करना ERDDAP s एक कारण होगा कैस्केड विफलता । इस प्रकार, सबसे मजबूत सेटअप में समग्र होना है ERDDAP विभिन्न यूआरएल के साथ
या, शायद बेहतर, एकाधिक समग्र स्थापित करना ERDDAP भार संतुलन के बिना एस। इस मामले में, आपको प्रत्येक को देने का एक बिंदु बनाना चाहिए ERDDAP एक अलग नाम / पहचान है और यदि संभव हो तो उन्हें दुनिया के विभिन्न हिस्सों में सेट करना (उदाहरण के लिए, विभिन्न AWS क्षेत्रों) , उदाहरण के लिए, ERD \_US \_East, ERD \_US \_West, ERD आईई ERD \_FR, ERD \_IT, ताकि उपयोगकर्ता सचेत रूप से, बार-बार एक विशिष्ट के साथ काम करें ERDDAP ।
- \[ एक सर्वर पर चलने वाले उच्च प्रदर्शन प्रणाली के आकर्षक डिजाइन के लिए, इसे देखें मेलिनेटर का विस्तृत विवरण । \]
बहुत उच्च मांग में डेटासेट
वास्तव में असामान्य मामले में कि एक A , बी या C ERDDAP बैंडविड्थ या हार्ड ड्राइव सीमाओं के कारण अनुरोधों के साथ नहीं रख सकते हैं, यह डेटा कॉपी करने के लिए समझ में आता है (फिर) पर दूसरे सर्वर+hard ड्राइव+ ERDDAP शायद EDDGrid कॉपी और/or EDDTableCopy । जबकि यह मूल डेटासेट के लिए आदर्श हो सकता है और कॉपी डेटासेट समग्र में एक डेटासेट के रूप में निर्बाध रूप से दिखाई देता है ERDDAP™ इसलिए, यह मुश्किल है क्योंकि दो डेटासेट अलग-अलग राज्यों में अलग-अलग समय पर होंगे। (विशेष रूप से, मूल के बाद नया डेटा प्राप्त होता है, लेकिन इससे पहले कि कॉपी डेटासेट अपनी प्रतिलिपि प्राप्त करता है) । इसलिए, मैं अनुशंसा करता हूं कि डेटासेट को थोड़ा अलग शीर्षक दिया जाए (उदाहरण के लिए, "... (प्रतिलिपि #1) "... (प्रतिलिपि #2) ", या शायद" (दर्पण # n ) " (सर्वर # n ) ") और समग्र में अलग डेटासेट के रूप में दिखाई देते हैं ERDDAP । उपयोगकर्ताओं का उपयोग सूची देखने के लिए किया जाता है दर्पण स्थल लोकप्रिय फ़ाइल डाउनलोड साइटों पर, इसलिए यह उन्हें आश्चर्यचकित या निराश नहीं होना चाहिए। किसी दिए गए साइट पर बैंडविड्थ सीमाओं के कारण, यह किसी अन्य साइट पर स्थित दर्पण को रखने के लिए समझ सकता है। यदि दर्पण कॉपी एक अलग डेटा सेंटर पर है, तो उस डेटा सेंटर के समग्र द्वारा एक्सेस किया गया है। ERDDAP™ विभिन्न शीर्षक (उदाहरण के लिए, "mirror #1") आवश्यक नहीं है।
RAIDs बनाम रेगुलर हार्ड ड्राइव
यदि एक बड़े डेटासेट या डेटासेट का एक समूह भारी उपयोग नहीं किया जाता है, तो यह डेटा को RAID पर स्टोर करने के लिए समझ सकता है क्योंकि यह गलती सहनशीलता प्रदान करता है और चूंकि आपको किसी अन्य सर्वर की प्रसंस्करण शक्ति या बैंडविड्थ की आवश्यकता नहीं है। लेकिन अगर डेटासेट का भारी उपयोग किया जाता है, तो यह किसी अन्य सर्वर पर डेटा कॉपी करने के लिए अधिक समझ सकता है + ERDDAP™ हार्ड ड्राइव (समान Google क्या करता है ) एक सर्वर और RAID का उपयोग करने के बजाय कई डेटासेट को स्टोर करने के लिए क्योंकि आपको सर्वर + हार्ड ड्राइव + दोनों का उपयोग करना है ERDDAP ग्रिड में जब तक उनमें से एक विफल रहता है।
विफलता
क्या होता है?
- एक डेटासेट के लिए अनुरोधों की एक फट है (उदाहरण के लिए, एक कक्षा में सभी छात्र समान डेटा का अनुरोध करते हैं) ? केवल ERDDAP™ उस डेटासेट की सेवा करने से अभिभूत और धीमा हो जाएगा या अनुरोधों को अस्वीकार कर दिया जाएगा। समग्र ERDDAP™ अन्य ERDDAP नहीं होगा। चूंकि सिस्टम के भीतर दिए गए डेटासेट के लिए सीमित कारक डेटा के साथ हार्ड ड्राइव है (नहीं ERDDAP ) एकमात्र समाधान (तत्काल नहीं) एक अलग सर्वर+hardDrive+ पर डेटासेट की एक प्रति बनाना है ERDDAP ।
- An A , बी या C ERDDAP™ विफल (उदाहरण के लिए, हार्ड ड्राइव विफलता) ? केवल डेटासेट (s) उसके द्वारा सेवा ERDDAP™ प्रभावित होते हैं। यदि डेटासेट (s) किसी अन्य सर्वर+hardDrive+ पर प्रतिबिंबित होता है ERDDAP , प्रभाव न्यूनतम है। यदि समस्या 5 या 6 RAID स्तर में एक हार्ड ड्राइव विफलता है, तो आप ड्राइव की जगह लेते हैं और ड्राइव पर डेटा का पुनर्निर्माण करते हैं।
- समग्र ERDDAP™ विफल? यदि आप एक प्रणाली बनाना चाहते हैं तो बहुत कुछ उच्च उपलब्धता , आप सेट कर सकते हैं एकाधिक समग्र ERDDAP s (ऊपर चर्चा) , कुछ का उपयोग करना NGINX या ट्रेफ़िक लोड संतुलन को संभालने के लिए। ध्यान दें कि दिए गए समग्र ERDDAP™ बड़ी संख्या में उपयोगकर्ताओं के अनुरोधों को संभाल सकते हैं क्योंकि मेटाडाटा के लिए अनुरोध छोटे होते हैं और स्मृति में है कि जानकारी द्वारा नियंत्रित होते हैं, और डेटा के लिए अनुरोध (जो बड़ा हो सकता है) बच्चे को पुनर्निर्देशित किया जाता है ERDDAP S.
सरल, स्केलेबल
इस प्रणाली को स्थापित करना और प्रशासित करना आसान है, और आसानी से Extensible है जब इसका कोई हिस्सा अति-बर्ड हो जाता है। किसी दिए गए डेटा सेंटर के लिए एकमात्र वास्तविक सीमाएं डेटा सेंटर की बैंडविड्थ और सिस्टम की लागत हैं।
बैंडविड्थ
सिस्टम के आमतौर पर इस्तेमाल किए जाने वाले घटकों की लगभग बैंडविड्थ को नोट करें:
| घटक | लगभग बैंडविड्थ (GBytes/s) |
|---|---|
| डीडीआर मेमोरी | 2.5 |
| एसएसडी ड्राइव | 1 |
| SATA हार्ड ड्राइव | 0.3 |
| गीगाबिट ईथरनेट | 0.1 |
| OC-12 | 0.06 |
| OC-3 | 0.015 |
| T1 | 0.0002 |
तो, एक SATA हार्ड ड्राइव (0.3GB/s) एक सर्वर पर ERDDAP™ शायद एक गीगाबिट ईथरनेट लैन को संतृप्त कर सकता है (0.1GB/s) । और एक गीगाबिट ईथरनेट लैन (0.1GB/s) शायद एक OC-12 इंटरनेट कनेक्शन संतृप्त कर सकते हैं (0.06GB/s) । और कम से कम एक स्रोत OC-12 लाइनों को सूचीबद्ध करता है जो प्रति माह $100,000 की लागत रखता है। (हां, ये गणना प्रणाली को अपनी सीमाओं पर धकेलने पर आधारित हैं, जो अच्छा नहीं है क्योंकि यह बहुत सुस्त प्रतिक्रियाओं की ओर जाता है। लेकिन ये गणना योजना के लिए उपयोगी हैं और सिस्टम के हिस्सों को संतुलित करने के लिए उपयोगी हैं।) स्पष्ट रूप से, आपके डेटा सेंटर के लिए एक उपयुक्त फास्ट इंटरनेट कनेक्शन अब तक सिस्टम का सबसे महंगा हिस्सा है। आप आसानी से और अपेक्षाकृत सस्ते में एक दर्जन सर्वर के साथ एक ग्रिड का निर्माण कर सकते हैं जो एक दर्जन चल रहा है ERDDAP जो जल्दी डेटा के बहुत सारे बाहर पंप करने में सक्षम है, लेकिन एक उपयुक्त तेजी से इंटरनेट कनेक्शन बहुत महंगा होगा। आंशिक समाधान हैं:
- यदि आवश्यक हो तो ग्राहकों को डेटा के सबसेट का अनुरोध करने के लिए प्रोत्साहित करें। यदि ग्राहक को केवल एक छोटे से क्षेत्र या कम रिज़ॉल्यूशन पर डेटा की आवश्यकता होती है, तो यह वही है जो उन्हें अनुरोध करना चाहिए। सबसेटिंग प्रोटोकॉल का एक केंद्रीय ध्यान है ERDDAP™ डेटा का अनुरोध करने का समर्थन करता है।
- संपीड़ित डेटा को संचारित करने के लिए प्रोत्साहित करें। ERDDAP™ संपीड़न यदि यह "accept-encoding" पाता है तो डेटा ट्रांसमिशन HTTP GET अनुरोध शीर्षलेख सभी वेब ब्राउज़र "accept-encoding" का उपयोग करते हैं और स्वचालित रूप से प्रतिक्रिया को अस्वीकार करते हैं। अन्य ग्राहक (उदाहरण के लिए, कंप्यूटर प्रोग्राम) इसे स्पष्ट रूप से उपयोग करना है।
- अपने सर्वर को एक आईएसपी या अन्य साइट पर कॉल करें जो अपेक्षाकृत कम महंगी बैंडविड्थ लागत प्रदान करता है।
- सर्वर को सर्वर से अलग करें ERDDAP अलग अलग संस्थाओं के लिए इतना है कि लागत बिखरे हुए हैं। फिर आप अपने समग्र लिंक कर सकते हैं ERDDAP™ उनके लिए ERDDAP S.
ध्यान दें कि क्लाउड कम्प्यूटिंग और वेब होस्टिंग सेवाएं आपको आवश्यक सभी इंटरनेट बैंडविड्थ प्रदान करती हैं, लेकिन कीमत की समस्या को हल नहीं करते हैं।
स्केलेबल, उच्च क्षमता, दोष-सहिष्णु प्रणालियों के डिजाइन के बारे में सामान्य जानकारी के लिए, माइकल टी। नागरद की पुस्तक देखें इसे जारी करना ।
लाइक Legos
सॉफ्टवेयर डिजाइनर अक्सर अच्छा उपयोग करने की कोशिश करते हैं सॉफ्टवेयर डिजाइन पैटर्न समस्याओं को हल करने के लिए। अच्छा पैटर्न अच्छा है क्योंकि वे अच्छे, आसान बनाने और काम करने के लिए, सामान्य प्रयोजन समाधान है कि अच्छी संपत्ति के साथ सिस्टम के लिए नेतृत्व में शामिल हैं। पैटर्न के नाम मानकीकृत नहीं हैं, इसलिए मैं उस पैटर्न को बुलाऊंगा जिसे ERDDAP™ लेगो पैटर्न का उपयोग करता है। प्रत्येक लेगो (प्रत्येक ERDDAP ) एक सरल, छोटा, मानक, स्टैंड-अलोन, ईंट है (डेटा सर्वर) एक परिभाषित इंटरफ़ेस के साथ जो इसे अन्य लेगोस से जोड़ा जा सकता है ( ERDDAP s) । भागों ERDDAP™ जो इस प्रणाली को बनाने के लिए हैं: सदस्यता और flagURL प्रणाली (जो बीच संचार की अनुमति देता है ERDDAP s) ईडीडी... FromErddap redirect system, और सिस्टम की प्रणाली RESTful उपयोगकर्ताओं या अन्य द्वारा उत्पन्न डेटा के लिए अनुरोध ERDDAP S. इस प्रकार, दो या अधिक legos दिया ( ERDDAP s) , आप विभिन्न आकारों की एक बड़ी संख्या बना सकते हैं (नेटवर्क टोपोलॉजी ERDDAP s) । निश्चित रूप से, डिजाइन और सुविधाओं की ERDDAP™ अलग-अलग किया जा सकता है, लेगो जैसी नहीं, शायद सिर्फ एक विशिष्ट टोपोलॉजी के लिए सक्षम और अनुकूलन करने के लिए। लेकिन हमें लगता है कि ERDDAP Lego-like डिजाइन एक अच्छा, सामान्य उद्देश्य समाधान प्रदान करता है जो किसी भी सक्षम बनाता है ERDDAP™ व्यवस्थापक (या प्रशासकों का समूह) सभी प्रकार के विभिन्न फेडरेशन टोपोलॉजी बनाने के लिए। उदाहरण के लिए, एक एकल संगठन तीन सेट अप कर सकता है (या अधिक) ERDDAP जैसा कि दिखाया गया है ERDDAP™ ग्रिड / क्लस्टर आरेख ऊपर । या एक वितरित समूह (IOS? कोस्ट वाच? NCEI? NWS? NOAA ? USGS? डेटाबेस क्या? क्या? OOI? BODC? ONC? JRC? WMO?) एक सेट कर सकते हैं ERDDAP™ प्रत्येक छोटे आउटपोस्ट में (इसलिए डेटा स्रोत के करीब रह सकता है) और फिर एक समग्र स्थापित करें ERDDAP™ वर्चुअल डेटासेट के साथ केंद्रीय कार्यालय में (जो हमेशा पूरी तरह से अप-टू-डेट होते हैं) प्रत्येक छोटी चौकी से ERDDAP S. वास्तव में, सभी ERDDAP S, दुनिया भर के विभिन्न संस्थानों में स्थापित, जो अन्य से डेटा प्राप्त करते हैं ERDDAP S and/or डेटा प्रदान करने के लिए अन्य ERDDAP एस, का एक विशाल नेटवर्क बनाने ERDDAP S. कैसे शांत है? इसलिए, जैसा कि लेगो के साथ, संभावनाएं अनंत हैं। यही कारण है कि यह एक अच्छा पैटर्न है। क्यों यह के लिए एक अच्छा डिजाइन है ERDDAP ।
अनुरोध के विभिन्न प्रकार
डेटा सर्वर टोपोलॉजी की इस चर्चा की वास्तविक जीवन जटिलताओं में से एक यह है कि विभिन्न प्रकार के अनुरोधों और विभिन्न प्रकार के अनुरोधों को अनुकूलित करने के विभिन्न तरीके हैं। यह ज्यादातर एक अलग मुद्दा है (कैसे तेजी से कर सकते हैं ERDDAP™ डेटा के साथ डेटा के अनुरोध का जवाब देता है?) धर्मशास्त्र चर्चा से (जो डेटा सर्वर के बीच संबंधों से संबंधित है और किस सर्वर में वास्तविक डेटा है) । ERDDAP™ निश्चित रूप से, सभी प्रकार के अनुरोधों को कुशलतापूर्वक संभालने की कोशिश करता है, लेकिन दूसरों की तुलना में कुछ बेहतर संभालता है।
- कई अनुरोध सरल हैं। उदाहरण के लिए: इस डेटासेट के लिए मेटाडाटा क्या है? या: इस ग्रिड डेटासेट के लिए समय आयाम के मान क्या हैं? ERDDAP™ इन को जितनी जल्दी हो सके संभालने के लिए डिज़ाइन किया गया है (आमतौर पर)<इस जानकारी को स्मृति में रखकर =2 ms)
- कुछ अनुरोध मामूली रूप से कठिन होते हैं। उदाहरण के लिए: मुझे एक डेटासेट का यह सबसेट दें (जो एक डेटा फ़ाइल में है) । इन अनुरोधों को जल्दी से संभाला जा सकता है क्योंकि वे मुश्किल नहीं हैं।
- कुछ अनुरोध कठिन हैं और इस प्रकार समय लेने वाले हैं। उदाहरण के लिए: मुझे एक डेटासेट का यह सबसेट दें (जो 10,000+ डेटा फ़ाइलों में से किसी में हो सकता है, या संपीड़ित डेटा फ़ाइलों से हो सकता है जो प्रत्येक को 10 सेकंड तक डिकंप्रेस करने में सक्षम हो सकता है।) । ERDDAP™ v2.0 ने इन अनुरोधों से निपटने के लिए कुछ नए, तेज़ तरीके पेश किए, विशेष रूप से अनुरोध-हैंडलिंग थ्रेड को कई वर्कर थ्रेड्स को स्पॉन करने की अनुमति देकर जो अनुरोध के विभिन्न सबसेट्स से निपटते हैं। लेकिन इस समस्या का एक और दृष्टिकोण है जो ERDDAP™ अभी तक समर्थन नहीं करता है: किसी दिए गए डेटासेट के लिए डेटा फ़ाइलों के सबसेट को अलग-अलग कंप्यूटरों पर संग्रहीत और विश्लेषण किया जा सकता है, और फिर मूल सर्वर पर संयुक्त परिणाम। इस दृष्टिकोण को बुलाया जाता है नक्शा और द्वारा अनुकरण किया जाता है हाडोप पहला (?) ओपन सोर्स MapReduce प्रोग्राम, जो Google पेपर से विचारों पर आधारित था। (यदि आपको आवश्यकता है MapReduce in ERDDAP , कृपया एक ईमेल अनुरोध भेजें erd.data at noaa.gov ।) गूगल बिग क्वीयर दिलचस्प है क्योंकि ऐसा लगता है कि यह MapReduce का कार्यान्वयन होता है जो सारणीबद्ध डेटासेट को सबसेट करने के लिए लागू होता है, जो कि एक है ERDDAP मुख्य लक्ष्य यह संभावना है कि आप एक बना सकते हैं ERDDAP™ एक BigQuery डेटासेट से डेटासेट के माध्यम से EDDTableFromDatabase क्योंकि BigQuery एक JDBC इंटरफ़ेस के माध्यम से पहुँचा जा सकता है।
ये मेरी राय हैं।
हाँ, गणना सरल है (अब थोड़ा दिनांकित) लेकिन मुझे लगता है कि निष्कर्ष सही हैं। क्या मैं दोषपूर्ण तर्क का उपयोग करता हूं या मेरी गणना में गलती करता हूं? यदि ऐसा है तो गलती अकेले मेरा है। कृपया सुधार के साथ एक ईमेल भेजें erd dot data at noaa dot gov ।
क्लाउड कम्प्यूटिंग
कई कंपनियां क्लाउड कंप्यूटिंग सेवाएं प्रदान करती हैं (उदाहरण के लिए अमेज़न वेब सर्विसेज और Google क्लाउड प्लेटफ़ॉर्म ) । वेब होस्टिंग कंपनियों १९९० के दशक के मध्य से सरल सेवाओं की पेशकश की है, लेकिन "बंद" सेवाओं ने सिस्टम की लचीलापन और पेशकश की सेवाओं की सीमा को काफी बढ़ा दिया है। चूंकि ERDDAP™ ग्रिड ERDDAP बाद में ERDDAP s हैं Java वेब अनुप्रयोग जो टॉमकैट में चल सकते हैं (सबसे आम अनुप्रयोग सर्वर) या अन्य अनुप्रयोग सर्वर, यह एक स्थापित करने के लिए अपेक्षाकृत आसान होना चाहिए ERDDAP™ क्लाउड सर्विस या वेब होस्टिंग साइट पर ग्रिड। इन सेवाओं के फायदे हैं:
- वे बहुत उच्च बैंडविड्थ इंटरनेट कनेक्शन तक पहुंच प्रदान करते हैं। यह अकेले इन सेवाओं का उपयोग करने की अनुमति देता है।
- वे केवल आपके द्वारा उपयोग की जाने वाली सेवाओं के लिए शुल्क लेते हैं। उदाहरण के लिए, आपको एक बहुत ही उच्च बैंडविड्थ इंटरनेट कनेक्शन तक पहुंच मिलती है, लेकिन आप केवल वास्तविक डेटा के लिए भुगतान करते हैं। यह आपको एक ऐसी प्रणाली बनाने की अनुमति देता है जो शायद ही कभी भारी हो जाती है (यहां तक कि चरम मांग पर भी) शायद ही कभी इस्तेमाल होने वाली क्षमता के लिए भुगतान किए बिना।
- वे आसानी से extensible हैं। आप सर्वर प्रकारों को बदल सकते हैं या एक मिनट से भी कम समय में कई सर्वर या जितना चाहें उतना संग्रहण जोड़ सकते हैं। यह अकेले इन सेवाओं का उपयोग करने की अनुमति देता है।
- वे आपको सर्वर और नेटवर्क चलाने के कई प्रशासनिक कर्तव्यों से मुक्त करते हैं। यह अकेले इन सेवाओं का उपयोग करने की अनुमति देता है।
इन सेवाओं के नुकसान हैं:
- वे अपनी सेवाओं के लिए चार्ज करते हैं, कभी-कभी बहुत कुछ (निरपेक्ष शब्दों में; नहीं कि यह एक अच्छा मूल्य नहीं है) । यहां सूचीबद्ध कीमतें अमेज़न EC2 । ये कीमतें (जून 2015 तक) नीचे आ जाएगा।
अतीत में, कीमतें अधिक थीं, लेकिन डेटा फाइलें और अनुरोधों की संख्या छोटी थी।
भविष्य में, कीमतें कम होंगी, लेकिन डेटा फाइलें और अनुरोधों की संख्या बड़ी होगी।
इसलिए विवरण बदल जाता है, लेकिन स्थिति अपेक्षाकृत स्थिर रहती है।
और यह नहीं है कि सेवा अतिरंजित है, यह है कि हम बहुत सारी सेवा का उपयोग और खरीद रहे हैं।
- डेटा ट्रांसफर - सिस्टम में डेटा ट्रांसफर अब मुफ्त हैं (हाँ!) । सिस्टम से बाहर डेटा ट्रांसफर $0.09/GB है। एक SATA हार्ड ड्राइव (0.3GB/s) एक सर्वर पर ERDDAP™ शायद एक गीगाबिट ईथरनेट लैन को संतृप्त कर सकता है (0.1GB/s) । एक गीगाबिट ईथरनेट लैन (0.1GB/s) शायद एक OC-12 इंटरनेट कनेक्शन संतृप्त कर सकते हैं (0.06GB/s) । यदि एक OC-12 कनेक्शन ~ 150,000 GB / माह संचारित कर सकता है, तो डेटा ट्रांसफर लागत लगभग 150,000 GB @ $0.09 / GB = $13,500 / माह हो सकती है, जो एक महत्वपूर्ण लागत है। स्पष्ट रूप से, यदि आपके पास एक दर्जन कड़ी मेहनत है ERDDAP क्लाउड सर्विस पर, आपका मासिक डेटा ट्रांसफर शुल्क पर्याप्त हो सकता है ($162,000/माह तक) । (फिर भी, यह नहीं है कि सेवा अधिक है, यह है कि हम बहुत सारी सेवा का उपयोग और खरीद रहे हैं।)
- डेटा संग्रहण - अमेज़ॅन प्रति टीबी $ 50 / माह का शुल्क लेता है। (इसकी तुलना ~$50/टीबी के लिए 4 टीबी एंटरप्राइज ड्राइव को आउटराइट खरीदने के लिए की जाती है, हालांकि RAID को इसमें डाल दिया जाता है और प्रशासनिक लागत कुल लागत में शामिल होती है।) यदि आपको क्लाउड में बहुत सारे डेटा स्टोर करने की आवश्यकता है, तो यह काफी महंगा हो सकता है (उदाहरण के लिए, 100TB की लागत 5000/माह होगी) । लेकिन जब तक आपके पास वास्तव में बड़ी मात्रा में डेटा नहीं है, तब तक यह बैंडविड्थ / डेटा ट्रांसफर लागत की तुलना में एक छोटा मुद्दा है। (फिर भी, यह नहीं है कि सेवा अधिक है, यह है कि हम बहुत सारी सेवा का उपयोग और खरीद रहे हैं।)
सबसेटिंग
- सबसेटिंग समस्या: डेटा फ़ाइलों से डेटा को कुशलतापूर्वक वितरित करने का एकमात्र तरीका यह है कि प्रोग्राम जो डेटा वितरित कर रहा है। (उदाहरण के लिए ERDDAP ) एक सर्वर पर चल रहा है जिसमें स्थानीय हार्ड ड्राइव पर संग्रहीत डेटा है (या इसी तरह तेजी से एक SAN या स्थानीय RAID के लिए उपयोग) । स्थानीय फ़ाइल सिस्टम अनुमति देता है ERDDAP™ (और अंतर्निहित पुस्तकालय, जैसे कि netcdf-java) फ़ाइलों से विशिष्ट बाइट रेंज का अनुरोध करने के लिए और बहुत जल्दी प्रतिक्रियाएं प्राप्त करें। कई प्रकार के डेटा अनुरोधों से ERDDAP™ फ़ाइल में (विशेष रूप से ग्रिड डेटा अनुरोध जहां स्ट्राइड मूल्य है > 1) यदि कार्यक्रम को पूरी फ़ाइल या एक गैर-स्थानीय से फ़ाइल के बड़े हिस्से का अनुरोध करना है तो कुशलतापूर्वक नहीं किया जा सकता है। (इसलिए धीमी) डेटा संग्रहण प्रणाली और फिर एक सबसेट निकालने। यदि क्लाउड सेटअप नहीं देता है ERDDAP™ फ़ाइलों की बाइट रेंज तक तेजी से पहुंच (के रूप में तेजी से स्थानीय फ़ाइलों के साथ) , ERDDAP डेटा तक पहुंच एक गंभीर बाधा होगी और क्लाउड सेवा का उपयोग करने के अन्य लाभों को अस्वीकार करेगा।
होस्ट डेटा
उपरोक्त लागत लाभ विश्लेषण का विकल्प (जो डेटा मालिक पर आधारित है (उदाहरण के लिए NOAA ) अपने डेटा को क्लाउड में संग्रहीत करने के लिए भुगतान करना) 2012 के आसपास पहुंचे जब अमेज़न (और कम हद तक, कुछ अन्य क्लाउड प्रदाता) अपने क्लाउड में कुछ डेटासेट की मेजबानी करना शुरू कर दिया (AWS S3) मुफ्त में (संभवतः इस उम्मीद के साथ कि अगर उपयोगकर्ता उस डेटा के साथ काम करने के लिए AWS EC2 कम्प्यूट उदाहरण किराए पर ले जाएगा तो वे अपनी लागत को ठीक कर सकते हैं) । स्पष्ट रूप से, यह बादल कंप्यूटिंग को बहुत अधिक लागत प्रभावी बनाता है, क्योंकि डेटा अपलोड करने का समय और लागत अब शून्य है। साथ ERDDAP™ v2.0, चलने की सुविधा के लिए नई सुविधाएँ हैं ERDDAP एक बादल में:
- अब, एक EDDGrid FromFiles or EDDTableFromFiles डेटासेट डेटा फ़ाइलों से बनाया जा सकता है जो इंटरनेट के माध्यम से दूरस्थ और सुलभ हैं। (उदाहरण के लिए, AWS S3 बाल्टी) उपयोग करके<CashFromUrl> और<कैशाइज़ जीबी> विकल्प. ERDDAP™ हाल ही में प्रयुक्त डेटा फ़ाइलों के स्थानीय कैश को बनाए रखेगा।
- अब, यदि कोई EDDTableFromFiles स्रोत फ़ाइलों को संकुचित किया जाता है (उदाहरण के लिए .tgz ) , ERDDAP™ जब यह उन्हें पढ़ता है तो स्वचालित रूप से उन्हें डिकंप्रेस करेगा।
- अब, ERDDAP™ किसी दिए गए अनुरोध का जवाब देने वाले धागे से वर्कर धागे को अनुरोध के उपखंडों पर काम करने के लिए प्रेरित करेंगे यदि आप उपयोग करते हैं<nThreads> विकल्प. यह समांतरीकरण कठिन अनुरोधों के लिए तेजी से प्रतिक्रिया की अनुमति देना चाहिए।
ये परिवर्तन AWS S3 की समस्या को हल करते हैं, जो स्थानीय, ब्लॉक-लेवल फाइल स्टोरेज और नहीं प्रदान करते हैं। (पुराना) S3 डेटा तक पहुंच की समस्या एक महत्वपूर्ण अंतराल है। (बहुत साल पहले (~2014) लेकिन अब बहुत कम है और इतना महत्वपूर्ण नहीं है।) सभी में इसका मतलब है कि सेटिंग ERDDAP™ क्लाउड में अब बेहतर काम करता है।
धन्यवाद — Matthew Arrott के लिए कई धन्यवाद और उनके समूह के मूल OOI प्रयास में उनके काम पर डालने के लिए ERDDAP™ बादल और परिणामस्वरूप चर्चा में।
डेटासेट की दूरस्थ प्रतिकृति
वहाँ एक आम समस्या है कि ग्रिड और federations के ऊपर चर्चा से संबंधित है ERDDAP S: डेटासेट की दूरस्थ प्रतिकृति। बुनियादी समस्या यह है: एक डेटा प्रदाता डेटासेट को बनाए रखता है जो कभी-कभी बदलता है और एक उपयोगकर्ता इस डेटासेट की अप-टू-डेट स्थानीय प्रतिलिपि बनाए रखना चाहता है। (किसी भी कारण से) । स्पष्ट रूप से, इस की विविधताओं की एक बड़ी संख्या है। कुछ बदलाव दूसरों की तुलना में निपटने के लिए बहुत कठिन हैं।
- फास्ट अपडेट स्थानीय डेटासेट को अप-टू-डेट रखने के लिए यह कठिन है तुरंत (उदाहरण के लिए, 3 सेकंड के भीतर) स्रोत में हर बदलाव के बाद, इसके बजाय, उदाहरण के लिए, कुछ घंटों के भीतर।
- बार-बार बदलाव बार बार बार बार बार बार बार बार बार बार बार बदलाव करना मुश्किल होता है। उदाहरण के लिए, एक बार एक दिवसीय परिवर्तन हर 0.1 सेकंड में बदलाव से निपटने के लिए बहुत आसान होते हैं।
- छोटे बदलाव एक स्रोत फ़ाइल में छोटे बदलाव पूरी तरह से नई फ़ाइल से निपटने के लिए कठिन हैं। यह विशेष रूप से सच है कि फ़ाइल में छोटे बदलाव कहीं भी हो सकते हैं। छोटे बदलावों का पता लगाना मुश्किल होता है और डेटा को अलग करना मुश्किल होता है जिसे दोहराने की आवश्यकता होती है। नई फ़ाइलों का पता लगाने और हस्तांतरण करने के लिए कुशल हैं।
- संपूर्ण डेटासेट पूरे डेटा सेट अप-टू-डेट को रखना हाल के डेटा को बनाए रखने की तुलना में कठिन है। कुछ उपयोगकर्ताओं को हाल ही में डेटा की आवश्यकता होती है (उदाहरण के लिए, पिछले 8 दिन के लायक) ।
- एकाधिक Copies विभिन्न साइटों पर कई दूरस्थ प्रतियों को बनाए रखना एक दूरस्थ प्रतिलिपि बनाए रखने की तुलना में कठिन है। यह स्केलिंग समस्या है।
स्पष्ट रूप से स्रोत डेटासेट और उपयोगकर्ता की जरूरतों और अपेक्षाओं के संभावित प्रकार के बदलावों की एक बड़ी संख्या है। कई बदलाव हल करने के लिए बहुत मुश्किल हैं। एक स्थिति के लिए सबसे अच्छा समाधान अक्सर किसी अन्य स्थिति के लिए सबसे अच्छा समाधान नहीं है - अभी तक एक सार्वभौमिक महान समाधान नहीं है।
प्रासंगिक ERDDAP™ उपकरण
ERDDAP™ कई उपकरण प्रदान करते हैं जिनका उपयोग किसी सिस्टम के हिस्से के रूप में किया जा सकता है जो डेटासेट की दूरस्थ प्रति को बनाए रखने की कोशिश करता है:
- ERDDAP ' RSS (रिच साइट सारांश?) सेवा
यह जांचने का एक त्वरित तरीका प्रदान करता है कि रिमोट पर डेटासेट क्या है ERDDAP™ बदल गया है। - ERDDAP ' सदस्यता सेवा
अधिक कुशल है (तुलना RSS ) दृष्टिकोण: यह तुरंत एक ईमेल भेजेगा या प्रत्येक ग्राहक को एक URL से संपर्क करेगा जब भी डेटासेट अद्यतन हो जाता है और अद्यतन में बदलाव आया। यह कुशल है कि यह ASAP होता है और कोई बर्बाद प्रयास नहीं होता है (मतदान के साथ RSS सेवा) । उपयोगकर्ता अन्य उपकरणों का उपयोग कर सकते हैं (लाइक आईएफटीटी ) सदस्यता प्रणाली से ईमेल अधिसूचनाओं पर प्रतिक्रिया करने के लिए। उदाहरण के लिए, एक उपयोगकर्ता रिमोट पर डेटासेट की सदस्यता ले सकता है ERDDAP™ और IFTTT का उपयोग सदस्यता ईमेल सूचनाएं पर प्रतिक्रिया करने और स्थानीय डेटासेट को अद्यतन करने के लिए किया जाता है। - ERDDAP ' ध्वज प्रणाली
एक रास्ता प्रदान करता है ERDDAP™ प्रशासक अपने / उसके डेटासेट को बताने के लिए ERDDAP ASAP को फिर से लोड करने के लिए। किसी ध्वज का यूआरएल रूप आसानी से स्क्रिप्ट में इस्तेमाल किया जा सकता है। किसी ध्वज का यूआरएल रूप भी सदस्यता के लिए कार्रवाई के रूप में इस्तेमाल किया जा सकता है। - ERDDAP ' "files" प्रणाली
किसी दिए गए डेटासेट के लिए स्रोत फ़ाइलों तक पहुंच प्रदान कर सकता है, जिसमें फ़ाइलों की अपाचे-शैली निर्देशिका सूची शामिल है। ("वेब एक्सेसिबल फ़ोल्डर") जिसमें प्रत्येक फ़ाइल का डाउनलोड URL, अंतिम संशोधित समय और आकार होता है। उपयोग करने का एक डाउनसाइड "files" सिस्टम यह है कि स्रोत फ़ाइलों में डेटासेट की तुलना में अलग-अलग परिवर्तनीय नाम और अलग मेटाडाटा हो सकता है क्योंकि यह दिखाई देता है ERDDAP । यदि रिमोट ERDDAP™ डेटासेट अपनी स्रोत फ़ाइलों तक पहुंच प्रदान करता है, जो कि rsync के एक खराब व्यक्ति के संस्करण की संभावना को खोलता है: यह देखने के लिए एक स्थानीय प्रणाली के लिए आसान हो जाता है कि रिमोट फाइलें बदल गई हैं और इसे डाउनलोड करने की आवश्यकता है। (देखें कैशFromUrl विकल्प नीचे जो इस का उपयोग कर सकते हैं।)
समाधान
हालांकि समस्या और संभावित समाधानों की एक अनंत संख्या के लिए विविधताओं की एक बड़ी संख्या है, समाधानों के लिए बुनियादी दृष्टिकोणों का सिर्फ एक मुट्ठी भर है:
कस्टम, ब्रूट फोर्स सॉल्यूशंस
एक स्पष्ट समाधान एक कस्टम समाधान है, जो इसलिए किसी दिए गए स्थिति के लिए अनुकूलित किया गया है: एक ऐसा सिस्टम बनाएं जो उस डेटा को बदलने / संपादित करता है, और उस जानकारी को उपयोगकर्ता को भेजता है ताकि उपयोगकर्ता परिवर्तित डेटा का अनुरोध कर सके। ठीक है, आप ऐसा कर सकते हैं, लेकिन नुकसान हैं:
- कस्टम समाधान बहुत सारे काम हैं।
- कस्टम समाधान आमतौर पर एक दिए गए डेटासेट को अनुकूलित किया जाता है और उपयोगकर्ता के सिस्टम को दिया जाता है जिसे वे आसानी से पुन: उपयोग नहीं कर सकते हैं।
- कस्टम समाधान आपके द्वारा बनाए रखा जाना चाहिए। (यह कभी एक अच्छा विचार नहीं है। यह हमेशा काम से बचने और काम करने के लिए किसी और को पाने के लिए एक अच्छा विचार है!)
मैं इस दृष्टिकोण को हतोत्साहित करता हूं क्योंकि सामान्य समाधानों की तलाश करना लगभग हमेशा बेहतर होता है, किसी अन्य व्यक्ति द्वारा निर्मित और बनाए रखा जाता है, जिसे आसानी से विभिन्न स्थितियों में पुन: उपयोग किया जा सकता है।
हिन्दी
हिन्दी एक उपयोगकर्ता के दूरस्थ कंप्यूटर पर सिंक में एक स्रोत कंप्यूटर पर फ़ाइलों का संग्रह रखने के लिए मौजूदा, आश्चर्यजनक रूप से अच्छा, सामान्य उद्देश्य समाधान है। जिस तरह से यह काम करता है:
- कुछ आयोजन (उदाहरण के लिए, एक ERDDAP™ सदस्यता प्रणाली घटना) चल रहा है rsync ट्रिगर, (या, एक क्रोन नौकरी उपयोगकर्ता के कंप्यूटर पर रोज़ाना विशिष्ट समय पर rsync चलाता है)
- जो स्रोत कंप्यूटर पर rsync संपर्क करता है,
- जो प्रत्येक फ़ाइल के हिस्से के लिए हैश की एक श्रृंखला की गणना करता है और उपयोगकर्ता के rsync को उन हैश को संचारित करता है,
- जो उस जानकारी को फाइलों की उपयोगकर्ता की प्रतिलिपि के लिए समान जानकारी की तुलना करता है,
- जो तब उन फ़ाइलों के टुकड़ों का अनुरोध करता है जो बदल गए हैं।
यह सब कुछ ध्यान में रखते हुए, rsync बहुत जल्दी काम करता है (उदाहरण के लिए, 10 सेकंड प्लस डेटा ट्रांसफर समय) और बहुत कुशलतापूर्वक। वहाँ हैं Rsync की विविधता कि विभिन्न स्थितियों के लिए अनुकूलन (उदाहरण के लिए, प्रत्येक स्रोत फ़ाइल के हिस्से के हैश को प्रीकैल्लेट करके और कैश करके) ।
Rsync की मुख्य कमजोरी हैं: इसे स्थापित करने के लिए कुछ प्रयास किए जाते हैं (सुरक्षा मुद्दे) कुछ स्केलिंग मुद्दे हैं; और एनआरटी डेटासेट को वास्तव में अप-टू-डेट रखने के लिए यह अच्छा नहीं है (उदाहरण के लिए, यह हर 5 मिनट से अधिक rsync का उपयोग करने के लिए अजीब है) । यदि आप कमजोरियों से निपट सकते हैं, या यदि वे आपकी स्थिति को प्रभावित नहीं करते हैं, तो rsync एक उत्कृष्ट, सामान्य प्रयोजन समाधान है कि कोई भी डेटासेट के दूरस्थ प्रतिकृति से जुड़े कई परिदृश्यों को हल करने के लिए अभी उपयोग कर सकता है।
वहाँ पर एक आइटम है ERDDAP™ Rsync सेवाओं के लिए समर्थन जोड़ने की कोशिश करने के लिए सूची ERDDAP (शायद एक बहुत मुश्किल काम) इसलिए कि किसी भी ग्राहक rsync का उपयोग कर सकते हैं (या एक संस्करण) डेटासेट की अप-टू-डेट प्रति बनाए रखने के लिए। यदि कोई इस पर काम करना चाहता है, तो कृपया ईमेल करें erd.data at noaa.gov ।
अन्य कार्यक्रम हैं जो अधिक या कम क्या करते हैं, कभी-कभी डेटासेट प्रतिकृति के लिए उन्मुख होते हैं। (हालांकि अक्सर फ़ाइल-कॉपी स्तर पर) , उदाहरण के लिए, Unidata ' आईडी ।
Url से कैश
कैशFromUrl सेटिंग उपलब्ध है (शुरू ERDDAP™ v2.0) सभी के लिए ERDDAP डेटासेट प्रकार जो फ़ाइलों से डेटासेट बनाते हैं (मूल रूप से, सभी उपवर्गों के EDDGrid सेफिल और EDDTableFromFiles ) । कैश FromUrl इसे स्वचालित रूप से स्थानीय डेटा फ़ाइलों को कैश के माध्यम से दूरस्थ स्रोत से कॉपी करके स्वचालित रूप से डाउनलोड करने और बनाए रखने की कोशिश करता है। FromUrl सेटिंग. दूरस्थ फाइलें एक वेब एक्सेसिबल फ़ोल्डर या THREDDS द्वारा दी गई एक निर्देशिका जैसी फ़ाइल सूची में हो सकती हैं। Hyrax एक S3 बाल्टी, या ERDDAP ' "files" प्रणाली।
यदि दूरस्थ फ़ाइलों का स्रोत दूरस्थ है ERDDAP™ डेटासेट जो स्रोत फ़ाइलों को माध्यम से प्रदान करता है ERDDAP™ "files" प्रणाली, तो आप कर सकते हैं सदस्यता दूरस्थ डेटासेट के लिए, और दूरस्थ डेटासेट का उपयोग करें ध्वज यूआरएल सदस्यता के लिए कार्रवाई के रूप में अपने स्थानीय डेटासेट के लिए। फिर, जब भी दूरस्थ डेटासेट बदलता है, तो यह आपके डेटासेट के लिए ध्वज यूआरएल से संपर्क करेगा, जो इसे ASAP को फिर से लोड करने के लिए कहेगा, जो बदली हुई दूरस्थ डेटा फ़ाइलों का पता और डाउनलोड करेगा। यह सब बहुत जल्दी होता है (आमतौर पर ~5 सेकंड के साथ-साथ परिवर्तित फ़ाइलों को डाउनलोड करने के लिए आवश्यक समय) । यह दृष्टिकोण बहुत अच्छा काम करता है यदि स्रोत डेटासेट में परिवर्तन समय-समय पर जोड़ा जा रहा है और जब मौजूदा फ़ाइलें कभी नहीं बदल जाती हैं। यह दृष्टिकोण अच्छी तरह से काम नहीं करता है अगर डेटा अक्सर सभी के लिए भेजा जाता है (या अधिक) मौजूदा स्रोत डेटा फ़ाइलों के कारण तब आपका स्थानीय डेटासेट अक्सर पूरे दूरस्थ डेटासेट को डाउनलोड कर रहा है। (यहीं एक rsync-like दृष्टिकोण की आवश्यकता है।)
पुरालेख ADataset
ERDDAP™ ' पुरालेख ADataset डेटा को अक्सर डेटासेट में जोड़ा जाता है, लेकिन पुराने डेटा को कभी बदल नहीं दिया जाता है। मूल रूप से, एक ERDDAP™ व्यवस्थापक पुरालेखADataset चला सकते हैं (शायद एक स्क्रिप्ट में, शायद क्रोन द्वारा चलाया जाता है) और एक डेटासेट की एक सबसेट निर्दिष्ट करें जिसे वे निकालना चाहते हैं (शायद कई फाइलों में) पैकेज .zip या .tgz फ़ाइल, ताकि आप इच्छुक लोगों या समूहों को फाइल भेज सकें (उदाहरण के लिए, एन.सी.ई.आई.) इसे डाउनलोड करने के लिए उपलब्ध कराएं। उदाहरण के लिए, आप 12:10 पूर्वाह्न पर हर रोज पुरालेखADataset चला सकते हैं और यह एक बनाते हैं .zip पिछले दिन 12:00 बजे से 12:00 बजे तक (या, इस साप्ताहिक, मासिक, या वार्षिक, आवश्यकतानुसार करते हैं।) चूंकि पैकेज्ड फ़ाइल ऑफ़लाइन उत्पन्न होती है, इसलिए टाइमआउट या बहुत अधिक डेटा का कोई खतरा नहीं होता है, क्योंकि एक मानक के लिए होगा ERDDAP™ अनुरोध
ERDDAP™ मानक अनुरोध प्रणाली
ERDDAP™ 'मानक अनुरोध प्रणाली एक वैकल्पिक अच्छा समाधान है जब डेटा को अक्सर डेटासेट में जोड़ा जाता है, लेकिन पुराने डेटा को कभी बदल नहीं दिया जाता है। मूल रूप से, कोई भी विशिष्ट समय के लिए डेटा प्राप्त करने के लिए मानक अनुरोधों का उपयोग कर सकता है। उदाहरण के लिए, 12:10 बजे रोज़मर्रा, आप पिछले दिन 12:00 बजे से लेकर 12:00 बजे तक दूरस्थ डेटासेट से सभी डेटा के लिए अनुरोध कर सकते हैं। सीमा (पुरालेखADataset दृष्टिकोण की तुलना) एक टाइमआउट का जोखिम है या एक फ़ाइल के लिए बहुत अधिक डेटा है। आप छोटी अवधि के लिए अधिक बार अनुरोध करके सीमा से बच सकते हैं।
EDDTableFromHttpGet
\[ यह विकल्प अभी तक मौजूद नहीं है, लेकिन निकट भविष्य में निर्माण करना संभव है। \]
नया EDDTableFromHttpGet डेटासेट प्रकार में ERDDAP™ v2.0 किसी अन्य समाधान की कल्पना करना संभव बनाता है। इस प्रकार के डेटासेट द्वारा बनाए गए अंतर्निहित फाइलें अनिवार्य रूप से उन फ़ाइलों को लॉग करती हैं जो डेटासेट में परिवर्तन रिकॉर्ड करती हैं। एक ऐसी प्रणाली बनाना संभव होना चाहिए जो समय-समय पर स्थानीय डेटासेट को बनाए रखता है (या एक ट्रिगर पर आधारित) उस अंतिम अनुरोध के बाद से दूरस्थ डेटासेट में किए गए सभी परिवर्तनों का अनुरोध करना। यह कुशल होना चाहिए (या अधिक) rsync की तुलना में और कई कठिन परिदृश्यों को संभालेंगे, लेकिन केवल तभी काम करेगा जब रिमोट और स्थानीय डेटासेट EDDTableFromHttpGet डेटासेट हैं।
यदि कोई इस पर काम करना चाहता है, तो कृपया संपर्क करें erd.data at noaa.gov ।
वितरित डेटा
उपरोक्त समाधानों में से कोई भी समस्या के कठिन बदलावों को हल करने का एक बड़ा काम नहीं करता है क्योंकि निकट वास्तविक समय की प्रतिकृति (एनआरटी) डेटासेट बहुत कठिन है, आंशिक रूप से सभी संभावित परिदृश्यों के कारण।
एक महान समाधान है: डेटा को दोहराने की कोशिश भी नहीं करता है। इसके बजाय, एक आधिकारिक स्रोत का उपयोग करें (एक डेटासेट ERDDAP ) , डेटा प्रदाता द्वारा बनाए रखा (उदाहरण के लिए, क्षेत्रीय कार्यालय) । सभी उपयोगकर्ता जो उस डेटासेट से डेटा चाहते हैं, हमेशा इसे स्रोत से प्राप्त करते हैं। उदाहरण के लिए, ब्राउज़र-आधारित एप्लिकेशन डेटा को URL-आधारित अनुरोध से प्राप्त करते हैं, इसलिए यह बात नहीं करना चाहिए कि अनुरोध दूरस्थ सर्वर पर मूल स्रोत के लिए है। (वही सर्वर जो ईएसएम की मेजबानी कर रहा है) । बहुत से लोग लंबे समय तक इस वितरित डेटा दृष्टिकोण का समर्थन कर रहे हैं (उदाहरण के लिए, पिछले 20+ वर्षों के लिए रॉय मेनडेल्ससोन) । ERDDAP ग्रिड / फेडरेशन मॉडल (इस दस्तावेज़ का शीर्ष 80%) इस दृष्टिकोण पर आधारित है। यह समाधान एक गोर्डियन नॉट के लिए तलवार की तरह है - पूरी समस्या दूर हो जाती है।
- यह समाधान आश्चर्यजनक रूप से सरल है।
- यह समाधान आश्चर्यजनक रूप से कुशल है क्योंकि प्रतिकृति डेटासेट रखने के लिए कोई काम नहीं किया जाता है (s) अप-टू-डेट।
- उपयोगकर्ता किसी भी समय नवीनतम डेटा प्राप्त कर सकते हैं (उदाहरण के लिए, केवल ~ 0.5 सेकंड की विलंबता के साथ) ।
- यह बहुत अच्छी तरह से पैमाने पर है और स्केलिंग में सुधार करने के तरीके हैं। (इस दस्तावेज़ के शीर्ष 80% पर चर्चा देखें।)
नहीं, यह सभी संभावित स्थितियों के लिए एक समाधान नहीं है, लेकिन यह विशाल बहुमत के लिए एक महान समाधान है। यदि कुछ स्थितियों में इस समाधान के साथ समस्याएं / कमजोरी होती हैं, तो अक्सर उन समस्याओं को हल करने या उन कमजोरियों के साथ रहने के लिए इस समाधान के आश्चर्यजनक फायदे के कारण काम करने लायक होता है। यदि यह समाधान वास्तव में किसी निश्चित स्थिति के लिए अस्वीकार्य है, उदाहरण के लिए, जब आपके पास वास्तव में डेटा की स्थानीय प्रतिलिपि होनी चाहिए, तो उपर्युक्त अन्य समाधानों पर विचार करें।
निष्कर्ष
जबकि कोई एकल, सरल समाधान नहीं है जो पूरी तरह से सभी परिदृश्यों में सभी समस्याओं को हल करता है (चूंकि Rsync और वितरित डेटा लगभग हैं) , उम्मीद है कि पर्याप्त उपकरण और विकल्प हैं ताकि आप अपनी विशेष स्थिति के लिए स्वीकार्य समाधान पा सकें।