Skalowanie
ERDDAP™ - Heavy Loads, Grids, Clusters, Federations, and Cloud Computing
ERDDAP :
ERDDAP™ jest aplikacją internetową i usługą internetową, która gromadzi dane naukowe z różnych lokalnych i oddalonych źródeł i oferuje prosty, spójny sposób pobierania podzbiorów danych we wspólnych formatach plików oraz tworzenia wykresów i map. Ta strona omawia problemy związane z ciężkimi ERDDAP™ obciążenia eksploatacyjne i analizuje możliwości radzenia sobie z niezwykle ciężkimi ładunkami poprzez sieci, klastry, federacje i chmury obliczeniowe.
Oryginalna wersja została napisana w czerwcu 2009 roku. Nie zaszły żadne znaczące zmiany. Ostatnia aktualizacja 2019- 04- 15.
DISCLAIMER
Treść tej strony internetowej jest Bob Simons osobiste opinie i nie muszą odzwierciedlać stanowiska rządu lub National Oceanic and Atmospheric Administration . Obliczenia są uproszczone, ale myślę, że wnioski są prawidłowe. Czy użyłem błędnej logiki czy popełniłem błąd w moich obliczeniach? Jeśli tak, to moja wina. Proszę wysłać e-mail z poprawką do erd dot data at noaa dot gov .
Ciężkie obciążenia / ograniczenia
Z ciężkim użyciem, samotne ERDDAP™ będzie ograniczona (od większości do najmniej prawdopodobnych) przez:
Zdalna szerokość pasma źródła
- Szerokość pasma zdalnego źródła danych - nawet z efektywnym połączeniem (np. poprzez OPeNDAP ) , chyba że zdalne źródło danych ma bardzo duże łącze internetowe z przepustowością, ERDDAP Odpowiedzi będą ograniczone przez jak szybko ERDDAP™ może pobierać dane ze źródła danych. Rozwiązaniem jest skopiowanie zbioru danych na ERDDAP Dysk twardy, może z EDDGrid Kopiuj lub EDDTableCopy .
ERDDAP Szerokość pasma serwera
- Chyba że ERDDAP Serwer ma bardzo duże łącze internetowe, ERDDAP Odpowiedzi będą ograniczone przez jak szybko ERDDAP™ może uzyskać dane ze źródeł danych i jak szybko ERDDAP™ może zwrócić dane klientom. Jedynym rozwiązaniem jest uzyskanie szybszego połączenia internetowego.
Pamięć
- Jeśli jest wiele jednoczesnych wniosków, ERDDAP™ może zabraknąć pamięci i tymczasowo odrzucić nowe prośby. ( ERDDAP™ ma kilka mechanizmów, aby tego uniknąć i zminimalizować konsekwencje, jeśli tak się stanie.) Im więcej pamięci na serwerze, tym lepiej. Na 32-bitowym serwerze, 4 + GB jest naprawdę dobre, 2 GB jest w porządku, mniej nie jest zalecane. Na 64-bitowym serwerze można niemal całkowicie uniknąć problemu poprzez uzyskanie dużo pamięci. Patrz Ustawienia\ -Xmx i -Xms zamiast ERDDAP Tomcat. An ERDDAP™ coraz intensywne wykorzystanie na komputerze z 64-bitowym serwerem z 8GB pamięci i -Xmx ustawionym na 4000M jest rzadko, jeśli kiedykolwiek, ograniczone przez pamięć.
Had Drive Bandwidth
- Dostęp do danych przechowywanych na dysku twardym serwera jest znacznie szybszy niż dostęp do danych zdalnych. Nawet jeśli, jeśli ERDDAP™ Serwer posiada bardzo duże łącze internetowe, możliwe jest, że dostęp do danych na dysku twardym będzie wąskim gardłem. Częściowy roztwór ma być używany szybciej (np. 10 000 RPM) magnetyczne dyski twarde lub dyski SSD (Jeśli to ma sens, to ma to sens.) . Innym rozwiązaniem jest przechowywanie różnych zbiorów danych na różnych dyskach, tak aby łączna szerokość pasma dysku twardego była znacznie wyższa.
Zbyt wiele plików buforowanych
- Zbyt wiele plików w cache katalog - ERDDAP™ buforuje wszystkie obrazy, ale tylko buforuje dane dla niektórych rodzajów żądań danych. Jest możliwe, aby katalog pamięci podręcznej dla zbioru danych miał czasowo dużą liczbę plików. To spowolni żądania, aby sprawdzić, czy plik jest w pamięci podręcznej (Naprawdę!) .<cache Protokół & gt; w setup.xml pozwala ustawić jak długo plik może być w pamięci podręcznej zanim zostanie usunięty. Ustawienie mniejszej liczby zminimalizowałoby ten problem.
CPU
- Tylko dwie rzeczy zajmują dużo czasu procesora:
- NetCDF 4 oraz HDF 5 teraz obsługuje wewnętrzną kompresję danych. Dekompresja dużej kompresji NetCDF 4 / HDF 5 plików danych może zająć 10 lub więcej sekund. (To nie jest błąd wdrożeniowy. Taka jest natura kompresji.) Tak więc wielokrotne jednoczesne żądania zbiorów danych z danymi zapisanymi w skompresowanych plikach mogą spowodować poważne obciążenie każdego serwera. Jeśli jest to problem, rozwiązaniem jest przechowywanie popularnych zbiorów danych w nieskompresowanych plikach lub uzyskanie serwera z procesorem z większą ilością rdzeni.
- Wykonywanie wykresów (w tym mapy) : około 0,2 - 1 sekunda na wykres. Więc gdyby było wiele jednocześnie unikalnych wniosków o wykresy ( WMS Klienci często składają 6 jednoczesnych wniosków!) , może być ograniczenie procesora. Gdy działa wielu użytkowników WMS Klienci, to staje się problemem.
Wielokrotne Identyczne ERDDAP Jest z Load Balancing?
Często pojawia się pytanie: ERDDAP s z równowagą obciążenia? "To interesujące pytanie, ponieważ szybko dociera do sedna ERDDAP Projekt. Szybka odpowiedź brzmi "nie". Wiem, że to rozczarowująca odpowiedź, ale jest kilka bezpośrednich powodów i kilka większych podstawowych powodów, dla których zaprojektowałem ERDDAP™ stosowanie innego podejścia (federacja ERDDAP s, opisane w większości niniejszego dokumentu) To lepsze rozwiązanie.
Niektóre bezpośrednie powody, dla których nie można / nie powinno się ustawić wielu identycznych ERDDAP s są:
- A ERDDAP™ odczytuje każdy plik danych, gdy po raz pierwszy staje się dostępny, aby znaleźć zakresy danych w pliku. Następnie przechowuje te informacje w pliku indeksowym. Później, gdy pojawi się prośba użytkownika o dane, ERDDAP™ wykorzystuje ten indeks do ustalenia, w jakich plikach szukać żądanych danych. Gdyby było wiele identycznych ERDDAP s, każdy z nich robiłby to indeksowanie, co jest marnowaniem wysiłku. Z systemem federacyjnym opisany poniżej, indeksacja jest wykonywana tylko raz, przez jeden z ERDDAP b.
- Dla niektórych rodzajów wniosków użytkowników (np. dla .nc , .png, .pdf file) ERDDAP™ musi zrobić cały plik przed wysłaniem odpowiedzi. Więc... ERDDAP™ Ukrywa te pliki przez krótki czas. Jeśli pojawi się identyczny wniosek (jak to często robi, szczególnie w przypadku obrazów, w których adres URL jest osadzony na stronie internetowej) , ERDDAP™ może ponownie użyć tego pliku. W systemie wielu identycznych ERDDAP s, te pliki buforowane nie są udostępniane, więc każdy ERDDAP™ niepotrzebnie i marnotrawnie odtworzyć .nc , .png, lub .pdf plików. Z federacyjnego systemu opisanego poniżej, pliki są wykonane tylko raz, przez jeden z ERDDAP s i ponownie wykorzystane.
- ERDDAP system subskrypcji nie jest ustawiony do współdzielenia przez wiele ERDDAP b. Na przykład, jeśli balancer obciążenia wysyła użytkownika do jednego ERDDAP™ i użytkownik subskrybuje zestaw danych, a następnie inne ERDDAP S nie będzie wiedział o tej subskrypcji. Później, jeśli balancer obciążenia wysyła użytkownika do innego ERDDAP™ i prosi o listę swoich subskrypcji, inne ERDDAP™ że nie ma żadnego (prowadząc go do duplikatu subskrypcji innego ERE DAP ) . Z federacyjnego systemu opisanego poniżej, system subskrypcji jest po prostu obsługiwany przez główne, publiczne, złożone ERDDAP .
Tak, za każdy z tych problemów, mógłbym (z wielkim wysiłkiem) inżynier rozwiązania (udostępnianie informacji między ERDDAP s) , ale myślę, że Federacja... ERDDAP Podejście (opisane w większości niniejszego dokumentu) jest o wiele lepszym rozwiązaniem ogólnym, częściowo dlatego, że zajmuje się innymi problemami, które multiple-identical- ERDDAP s-with-a-load- balancer podejście nie zaczyna nawet zajmować się zdecentralizowanym charakterem źródeł danych na świecie.
Najlepiej zaakceptować prosty fakt, że nie zaprojektowałem ERDDAP™ do zastosowania jako wielokrotne identyczne ERDDAP s z balancer obciążenia. Świadomie zaprojektowałem ERDDAP™ dobrze pracować w federacji ERDDAP s, które moim zdaniem ma wiele zalet. W szczególności, federacja ERDDAP s jest doskonale dopasowany do zdecentralizowanego, rozproszonego systemu centrów danych, który mamy w świecie rzeczywistym (Pomyśl o różnych regionach IOOS, lub różnych regionach CoastWatch, lub różnych częściach NCEI, lub 100 innych centrów danych w NOAA , lub różnych DAAC NASA, lub 1000 centra danych na całym świecie) . Zamiast mówić wszystkim centrom danych na świecie, że muszą porzucić swoje wysiłki i umieścić wszystkie swoje dane w scentralizowanym "jeziorze danych" (nawet gdyby było to możliwe, jest to okropny pomysł z wielu powodów - zobacz różne analizy pokazujące liczne zalety systemy zdecentralizowane ) , ERDDAP Projekt działa ze światem. Każde centrum danych, które wytwarza dane, może kontynuować utrzymanie, kurację i obsługę swoich danych (jak należy) A jednak... ERDDAP™ , dane mogą być również natychmiast dostępne z scentralizowanych ERDDAP , bez potrzeby przekazywania danych do scentralizowanego ERDDAP™ lub przechowywanie kopii danych. W rzeczywistości dany zbiór danych może być dostępny jednocześnie od ERDDAP™ w organizacji, która wyprodukowała i faktycznie przechowuje dane (np. GoMOOS) , od ERDDAP™ w organizacji macierzystej (np. centrum IOOS) , od wszystkich... NOAA ERDDAP™ , od rządu federalnego ERDDAP™ , od globalnego ERDDAP™ (GOOS) , oraz ze specjalistycznych ERDDAP s (np. ERDDAP™ w instytucji poświęconej badaniom HAB) , wszystkie zasadniczo natychmiast i skutecznie, ponieważ tylko metadane są przekazywane między ERDDAP s, nie dane. Najlepsze ze wszystkich, po wstępnym ERDDAP™ w organizacji pochodzącej - wszystkie pozostałe ERDDAP s można szybko skonfigurować (kilka godzin pracy) , z minimalnymi zasobami (jeden serwer, który nie potrzebuje żadnych danych do przechowywania danych, ponieważ nie przechowuje żadnych danych lokalnie) , a tym samym za naprawdę minimalne koszty. Porównaj to z kosztem utworzenia i utrzymania scentralizowanego centrum danych z jeziorem danych oraz potrzebą prawdziwie masywnego, naprawdę drogiego połączenia internetowego, plus towarzyszący problem scentralizowanego centrum danych jako pojedynczego punktu porażki. Dla mnie, ERDDAP s zdecentralizowane, federacyjne podejście jest daleko, znacznie lepsze.
W sytuacjach, gdy dane centrum danych potrzebuje wielu ERDDAP s do zaspokojenia wysokiego zapotrzebowania, ERDDAP jego konstrukcja jest w pełni zdolna do dopasowania lub przekroczenia wydajności wielokrotnego identycznego - ERDDAP Z-z-ładowarka-balancer podejście. Zawsze masz możliwość ustawienia wieloskładnikowy ERDDAP s (jak omówiono poniżej) , z których każdy otrzymuje wszystkie swoje dane od innych ERDDAP s, bez równoważenia obciążenia. W tym przypadku, zalecam, aby zwrócić uwagę, aby dać każdy z kompozytów ERDDAP s inna nazwa / tożsamość i, jeśli to możliwe, zakładanie ich w różnych częściach świata (np. różne regiony AWS) , np., ERD Na wschód, ERD Zachód, ERD _ _ IE, ERD FR, ERD \ _ IT, tak, że użytkownicy świadomie, wielokrotnie, pracować z konkretnego ERDDAP , z dodatkiem korzyści, że usunął ryzyko z jednego punktu porażki.
Grids, Clusters, and Federations
Pod bardzo dużym użyciem, jeden samodzielny ERDDAP™ wpadnie na jeden lub więcej z ograniczenia wymienione powyżej, a nawet proponowane rozwiązania będą niewystarczające. W takich sytuacjach, ERDDAP™ posiada funkcje ułatwiające budowę skalowalnych sieci (nazywane również klastrami lub federacjami) z ERDDAP s, które pozwalają systemowi na bardzo intensywne stosowanie (np. dla dużego centrum danych) .
Używam siatka jako termin ogólny wskazujący rodzaj klaster komputerowy jeżeli wszystkie części mogą lub nie mogą być fizycznie umieszczone w jednym obiekcie i mogą być zarządzane centralnie. Korzyść z sieci współzlokalizowanych, centralnie posiadanych i zarządzanych (klastry) że korzystają z ekonomii skali (zwłaszcza obciążenie pracą człowieka) i uprościć, aby części systemu działały dobrze razem. Korzyści z sieci niewspółzlokalizowanych, niecentralnie będących własnością i zarządzanych (federacje) jest to, że dystrybuują obciążenie pracą człowieka i koszty, i mogą zapewnić dodatkową tolerancję błędów. Rozwiązanie, które proponuję poniżej, działa dobrze dla wszystkich topografii siatki, klastrów i federacji.
Podstawową ideą zaprojektowania skalowalnego systemu jest zidentyfikowanie potencjalnych wąskich gardeł, a następnie zaprojektowanie systemu tak, aby części systemu mogły być replikowane w razie potrzeby w celu zmniejszenia wąskich gardeł. Idealnie, każda replikowana część zwiększa pojemność tej części systemu liniowo (efektywność skalowania) . System nie jest skalowalny, chyba że istnieje skalowalne rozwiązanie dla każdego wąskiego gardła. Skalowalność różni się od wydajności (jak szybko można wykonać zadanie - wydajność części) . Skalowalność pozwala na wzrost systemu do obsługi każdego poziomu popytu. Efektywność (ze skalowania i części) określa, ile serwerów itd., będzie potrzebnych do zaspokojenia określonego poziomu popytu. Efektywność jest bardzo ważna, ale zawsze ma granice. Skalowalność jest jedynym praktycznym rozwiązaniem do budowy systemu, który może obsługiwać Bardzo często ciężkie użycie. Idealnie, system będzie skalowalny i wydajny.
Cele
Celem projektu jest:
- Aby zrobić skalowalną architekturę (jeden, który jest łatwo rozciągalny poprzez powielanie każdej części, która staje się nadmiernie obciążona) . Stworzenie skutecznego systemu, który maksymalizuje dostępność i przepustowość danych z uwzględnieniem dostępnych zasobów obliczeniowych. (Koszt jest prawie zawsze problemem.)
- Aby zrównoważyć możliwości części systemu, aby jedna część systemu nie przytłoczyła kolejnej części.
- Aby stworzyć prostą architekturę tak, że system jest łatwy w konfiguracji i administrowaniu.
- Aby stworzyć architekturę, która działa dobrze ze wszystkimi topografiami siatki.
- Stworzenie systemu, który zawiedzie z wdzięcznością i w ograniczonym stopniu, jeśli jakakolwiek część stanie się nadmiernie obciążona. (Czas potrzebny do skopiowania dużych zbiorów danych zawsze ograniczy zdolność systemu do radzenia sobie z nagłym wzrostem zapotrzebowania na określony zbiór danych.)
- (Jeśli to możliwe) Aby stworzyć architekturę, która nie jest związana z żadnym konkretnym przetwarzanie w chmurze usługi lub inne usługi zewnętrzne (bo ich nie potrzebuje.) .
Zalecenia
Nasze zalecenia to:
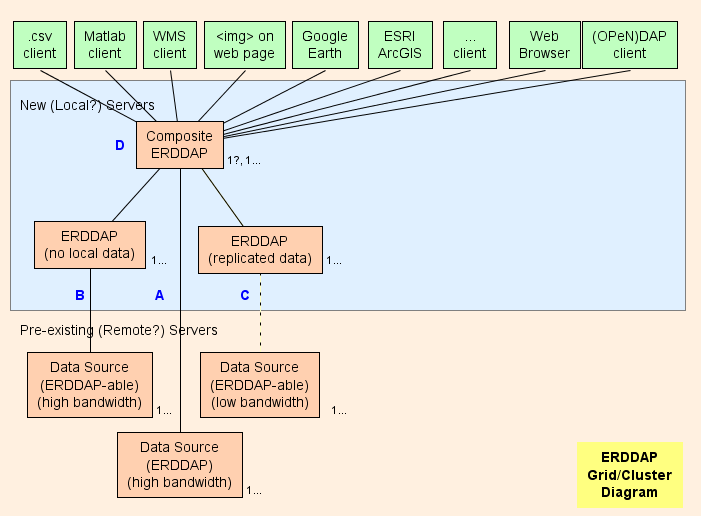
- W zasadzie, proponuję ustawić Kompozyt ERDDAP™ ( D na diagramie) , który jest regularny ERDDAP™ z wyjątkiem tego, że służy tylko do transmisji danych z innych ERDDAP b. Architektura sieci ma na celu przesunięcie jak największej ilości pracy (Wykorzystanie procesora, wykorzystanie pamięci, wykorzystanie przepustowości) z kompozytu ERDDAP™ do innych ERDDAP b.
- ERDDAP™ posiada dwa specjalne typy zbiorów danych, EDDGrid FromErddap oraz EDDTableFromErddap , które odnoszą się do zbiory danych dotyczące innych ERDDAP b.
- Kiedy kompozyt ERDDAP™ otrzymuje wniosek o dane lub obrazy z tych zbiorów danych, złożone ERDDAP™ przekierowanie żądania danych do innych ERDDAP™ serwer. Wynik jest następujący:
- To bardzo skuteczne. (CPU, pamięć i szerokość pasma) , ponieważ inaczej
- Składnik ERDDAP™ musi wysłać wniosek o dane do innego ERDDAP .
- Drugi ERDDAP™ musi uzyskać dane, przeformatować je i przesłać dane do kompozytu ERDDAP .
- Składnik ERDDAP™ musi otrzymać dane (z wykorzystaniem dodatkowej przepustowości) , przeformatować go (za pomocą dodatkowego czasu procesora i pamięci) oraz przekazują dane użytkownikowi (z wykorzystaniem dodatkowej przepustowości) . Przekierowanie wniosku o dane i pozwolenie na inne ERDDAP™ wysłać odpowiedź bezpośrednio do użytkownika, kompozyt ERDDAP™ zasadniczo nie wydaje czasu procesora, pamięci lub szerokości pasma na żądanie danych.
- Przekierowanie jest przejrzyste dla użytkownika niezależnie od oprogramowania klienta (przeglądarka lub inne oprogramowanie lub narzędzie linii poleceń) .
- To bardzo skuteczne. (CPU, pamięć i szerokość pasma) , ponieważ inaczej
Części siatki
A : Dla każdego zdalnego źródła danych o dużej przepustowości OPeNDAP serwer, można połączyć się bezpośrednio z zdalnym serwerem. Jeśli zdalny serwer jest ERDDAP™ , EDDGrid FromErddap lub EDDTableFrom ERDDAP służyć danych zawartych w składance ERDDAP . Jeśli zdalny serwer jest innym rodzajem DAP serwer, np. THREDDS, Hyrax lub GRADS, używać EDDGrid FromDap.
B : Dla każdego ERDDAP - możliwe źródło danych (źródło danych, z którego ERDDAP może odczytać dane) który ma serwer wysokiej przepustowości, skonfigurować inny ERDDAP™ w sieci odpowiedzialnej za obsługę danych z tego źródła danych.
- Jeśli kilka takich ERDDAP s nie otrzymują wielu wniosków o dane, można je skonsolidować w jednym ERDDAP .
- Jeśli ERDDAP™ dedykowany do uzyskiwania danych z jednego zdalnego źródła jest coraz zbyt wiele wniosków, istnieje pokusa, aby dodać dodatkowe ERDDAP s do dostępu do zdalnego źródła danych. W szczególnych przypadkach może to mieć sens, ale jest bardziej prawdopodobne, że to obezwładni zdalne źródło danych (która jest samopokonana) oraz uniemożliwiają innym użytkownikom dostęp do zdalnego źródła danych (Co nie jest miłe.) . W takim przypadku, rozważyć utworzenie innego ERDDAP™ aby podać ten jeden zestaw danych i skopiować zbiór danych na tym ERDDAP dysk twardy (patrz C ) , być może z EDDGrid Kopiuj lub EDDTableCopy .
- B serwery muszą być publicznie dostępne.
C : Dla każdego ERDDAP -możliwe źródło danych, które posiada serwer o małej przepustowości (lub jest wolnym serwisem z innych powodów) , rozważyć utworzenie innego ERDDAP™ i przechowywanie kopii zbioru danych na ten temat ERDDAP Dyski twarde, być może z EDDGrid Kopiuj lub EDDTableCopy . Jeśli kilka takich ERDDAP s nie otrzymują wielu wniosków o dane, można je skonsolidować w jednym ERDDAP . C serwery muszą być publicznie dostępne.
Składnik ERDDAP
D : Składnik ERDDAP™ jest regularny ERDDAP™ z wyjątkiem tego, że służy tylko do transmisji danych z innych ERDDAP b.
- Ponieważ kompozyt ERDDAP™ posiada w pamięci informacje o wszystkich zbiorach danych, może szybko odpowiedzieć na wnioski o listy zbiorów danych (pełne wyszukiwanie tekstu, wyszukiwanie kategorii, lista wszystkich zbiorów danych) oraz wnioski o indywidualny formularz dostępu do danych, formularz wykresu, lub WMS strona informacyjna. Są to małe, dynamicznie generowane strony HTML oparte na informacjach przechowywanych w pamięci. Więc odpowiedzi są bardzo szybkie.
- Ponieważ prośby o rzeczywiste dane są szybko przekierowywane do innych ERDDAP s, złożony ERDDAP™ może szybko odpowiadać na żądania dotyczące rzeczywistych danych bez użycia jakiegokolwiek czasu procesora, pamięci lub szerokości pasma.
- Przesuwając jak najwięcej pracy (CPU, pamięć, szerokość pasma) z kompozytu ERDDAP™ do innych ERDDAP s, złożony ERDDAP™ może wydawać się służyć do danych ze wszystkich zbiorów danych, a jednak nadal nadążać za bardzo dużą liczbą żądań od dużej liczby użytkowników.
- Wstępne badania wskazują, że złożony ERDDAP™ może odpowiedzieć na większość żądań w ~ 1ms czasu procesora, lub 1000 żądań / sekund. Zatem 8-rdzeniowy procesor powinien być w stanie odpowiedzieć na około 8000 żądań / sekund. Mimo, że możliwe jest widzenie wybuchów wyższej aktywności, które spowodowałyby spowolnienie, jest to duża przepustowość. Prawdopodobnie przepustowość centrum danych będzie wąskim gardłem na długo przed kompozytem ERDDAP™ staje się wąskim gardłem.
Up- to- date max (czas) ?
W EDDGrid / TableFromErddap w kompozycie ERDDAP™ Tylko zmienia przechowywane informacje o każdym zbiorze danych źródłowych, gdy zbiór danych źródłowych jest "reload" i jakaś zmiana metadanych (np. zmienna czasu actual\_range ) w ten sposób generuje powiadomienie o subskrypcji. Jeśli zbiór danych źródłowych zawiera dane, które często się zmieniają (na przykład, nowe dane co sekundę) i wykorzystuje "update" system do zauważenia częstych zmian w danych podstawowych, EDDGrid / TableFromErddap nie będzie informowany o tych częstych zmian do następnego zbioru danych "przeładować", więc EDDGrid / TableFromErddap nie będzie idealnie / na randce. Możesz zminimalizować ten problem zmieniając zbiór danych źródłowych<przeładowanie EveryNMinutes & gt; do mniejszej wartości (60?) tak, że istnieje więcej powiadomień subskrypcji do powiadomienia EDDGrid / TableFromErddap aktualizuje informacje o zbiorze danych źródłowych.
Lub, jeśli Twój system zarządzania danymi wie, kiedy zbiór danych źródłowych posiada nowe dane (np. za pomocą skryptu kopiującego plik danych na miejsce) i jeśli to nie jest zbyt częste (np. co 5 minut lub rzadziej) Jest lepsze rozwiązanie:
- Nie używaj<updateEveryNMillis & gt; aby utrzymać zbiór danych źródłowych na bieżąco.
- Ustaw zbiór danych źródłowych<przeładowanie EveryNMinutes & gt; do większej liczby (1440?) .
- Niech skrypt skontaktuje się z zbiorem danych źródłowych URL flagi zaraz po skopiowaniu nowego pliku danych. Doprowadzi to do perfekcyjnego uaktualnienia zbioru danych źródłowych i spowoduje wygenerowanie powiadomienia o subskrypcji, które zostanie wysłane do EDDGrid / TableFromErddap dataset. To poprowadzi do EDDGrid / TableFromErddap dataset to be perfectly up- to- date (w ciągu 5 sekund od dodania nowych danych) . I wszystko to będzie zrobione efektywnie. (bez zbędnych przeładowań zbioru danych) .
Wieloskładnikowy ERDDAP s
- W bardzo ekstremalnych przypadkach, lub dla tolerancji błędów, może chcesz ustawić więcej niż jeden złożony ERDDAP . Prawdopodobnie inne części systemu (w szczególności przepustowość centrum danych) stanie się problemem na długo przed kompozytem ERDDAP™ staje się wąskim gardłem. Rozwiązaniem jest prawdopodobnie utworzenie dodatkowych, zróżnicowanych geograficznie centrów danych (lusterka) , każdy z jednym kompozytem ERDDAP™ i serwerów z ERDDAP s oraz (co najmniej) lustrzane kopie zbiorów danych, które są w dużym zapotrzebowaniu. Taka konfiguracja zapewnia również tolerancję błędów i backup danych (poprzez kopiowanie) . W tym przypadku najlepiej jest, jeśli złożony ERDDAP s mają różne adresy URL.
Jeśli naprawdę chcesz wszystkie kompozyty ERDDAP s aby mieć ten sam adres URL, użyj systemu z przodu, który przypisuje danego użytkownika tylko jednemu z kompozytów ERDDAP s (w oparciu o adres IP) , tak aby wszystkie prośby użytkownika przejść do tylko jednego z kompozytów ERDDAP b. Istnieją dwa powody:
- Kiedy podstawowy zbiór danych jest przeładowany i metadane się zmieniają (np. nowy plik danych w zbiorze danych z zawiązanymi ustawieniami powoduje powstanie zmiennej czasu actual\_range do zmiany) , kompozyt ERDDAP s będzie chwilowo nieznacznie poza synchronizacją, ale z ewentualna spójność . Zwykle w ciągu 5 sekund ponownie się zsynchronizują, ale czasami będzie to dłuższe. Jeśli użytkownik tworzy zautomatyzowany system, który opiera się na ERDDAP™ subskrypcje które wywołują działania, krótkie problemy synchronizacji staną się znaczące.
- Składnik 2 + ERDDAP s każdy zachowuje własny zestaw subskrypcji (ze względu na problem synchronizacji opisany powyżej) .
Tak więc dany użytkownik powinien być skierowany do jednego z kompozytów ERDDAP aby uniknąć tych problemów. Jeżeli jeden ze złożonych ERDDAP s idzie w dół, system przedni może przekierować, że ERDDAP użytkowników do innego ERDDAP™ To koniec. Jednakże, jeśli jest to problem zdolności, który powoduje pierwszy złożony ERDDAP™ do porażki (Nadgorliwy użytkownik? a atak zaprzeczający służbie ?) , to sprawia, że bardzo prawdopodobne, że przekierowanie użytkowników do innych złożonych ERDDAP do awaria kaskadowania . Tak więc, najbardziej wytrzymałe ustawienie jest mieć kompozytowe ERDDAP s z różnymi adresami URL.
Albo, być może lepiej, skonfigurować wiele kompozytów ERDDAP s bez równoważenia obciążenia. W tym przypadku, należy umieścić punkt dając każdy z ERDDAP s inna nazwa / tożsamość i, jeśli to możliwe, zakładanie ich w różnych częściach świata (np. różne regiony AWS) , np., ERD Na wschód, ERD Zachód, ERD _ _ IE, ERD FR, ERD \ _ IT, tak, że użytkownicy świadomie, wielokrotnie pracować z konkretnego ERDDAP .
- \[ Dla fascynującego projektu systemu wysokiej wydajności działającego na jednym serwerze, zobacz to szczegółowy opis nadawcy . \]
Dane w bardzo wysokim popycie
W naprawdę niezwykłym przypadku, że jeden z A , B lub C ERDDAP s nie może nadążyć za żądaniami z powodu ograniczeń przepustowości lub dysku twardego, ma sens kopiowanie danych (ponownie) na inny serwer + twardy Napęd + ERDDAP , być może z EDDGrid Kopiuj lub EDDTableCopy . Choć może wydawać się idealne, aby oryginalny zestaw danych i skopiowany zestaw danych pojawiają się płynnie jako jeden zestaw danych w kompozycie ERDDAP™ , Jest to trudne, ponieważ dwa zestawy danych będą w nieco różnych stanach w różnych czasach (w szczególności, gdy oryginał otrzymuje nowe dane, ale zanim skopiowany zbiór danych otrzyma swoją kopię) . Dlatego zalecam, aby zbiory danych były nieco różne (np. "... (kopia # 1) "i"... (kopia # 2) "albo może" (lusterko # n ) "lub" (serwer # n ) ") i pojawiają się jako oddzielne zbiory danych w kompozycie ERDDAP . Użytkownicy są przyzwyczajeni do przeglądania list lusterka na popularnych stronach pobierania plików, więc nie powinno ich to zaskoczyć lub rozczarować. Ze względu na ograniczenia przepustowości w danym miejscu, może mieć sens, aby lustro znajduje się w innym miejscu. Jeśli lustrzana kopia jest w innym centrum danych, dostęp tylko przez ten kompleks centrum danych ERDDAP™ , różne tytuły (np. "lusterko # 1) nie są konieczne.
Rysunki kontra regularne jazdy twarde
Jeżeli duży zestaw danych lub grupa zbiorów danych nie są wykorzystywane w sposób intensywny, może mieć sens przechowywanie danych na RAID, ponieważ oferuje tolerancję błędów i ponieważ nie potrzebujesz mocy przetwarzania lub przepustowości innego serwera. Ale jeśli zestaw danych jest intensywnie używany, może mieć więcej sensu kopiowanie danych na innym serwerze + ERDDAP™ + dysk twardy (podobne do co robi Google ) zamiast używać jednego serwera i RAID do przechowywania wielu zbiorów danych, ponieważ można używać zarówno serwera + HardDrive + ERDDAP jest w sieci dopóki jeden z nich nie zawiedzie.
Nieprawidłowości
Co się stanie jeśli...
- Istnieje fala wniosków o jeden zestaw danych (na przykład, wszyscy studenci w klasie jednocześnie wymagają podobnych danych) ? Tylko ERDDAP™ Służenie temu zestawowi danych będzie przytłoczone i spowolnione lub odrzucone wnioski. Składnik ERDDAP™ i inne ERDDAP s nie będzie naruszone. Ponieważ czynnikiem ograniczającym dla danego zbioru danych w systemie jest dysk twardy z danymi (nie ERDDAP ) , jedynym rozwiązaniem (nienatychmiastowy) jest zrobić kopię zbioru danych na innym serwerze + HardDrive + ERDDAP .
- An A , B lub C ERDDAP™ niepowodzenie (np. awaria dysku twardego) ? Tylko zbiór danych (s) Służy temu ERDDAP™ są dotknięte. Jeśli zbiór danych (s) jest mirrored na innym serwerze + HardDrive + ERDDAP , efekt jest minimalny. Jeśli problemem jest awaria dysku twardego na poziomie 5 lub 6 RAID, wystarczy zastąpić dysk i RAID odbudować dane na dysku.
- Składnik ERDDAP™ Nie? Jeśli chcesz zrobić system z bardzo wysoka dostępność , możesz ustawić wieloskładnikowy ERDDAP s (jak omówiono powyżej) , używając czegoś takiego NGINX lub Traefik Przewodniczący do obsługi równowagi obciążenia. Należy zauważyć, że dany kompozyt ERDDAP™ może obsłużyć bardzo dużą liczbę żądań od dużej liczby użytkowników, ponieważ wnioski o metadane są małe i są obsługiwane przez informacje, które są w pamięci, oraz wnioski o dane (które mogą być duże) są przekierowane do dziecka ERDDAP b.
Proste, skalowalne
System ten jest łatwy do skonfigurowania i zarządzania, i łatwo go rozszerzyć, gdy jakakolwiek jego część staje się przeciążona. Jedyne rzeczywiste ograniczenia dla danego centrum danych to szerokość pasma i koszt systemu.
Szerokość pasma
Należy zwrócić uwagę na przybliżoną szerokość pasma powszechnie stosowanych elementów systemu:
| Składnik | Przybliżona szerokość pasma (GBytes / s) |
|---|---|
| Pamięć DDR | 2, 5 |
| Napęd SSD | 1 |
| Dysk twardy SATA | 0, 3 |
| Gigabit Ethernet | 0, 1 |
| OC- 12 | 0, 06 |
| OC- 3 | 0, 015 |
| T1 | 0, 0002 |
Jeden dysk SATA (0,3GB / s) na jednym serwerze z jednym ERDDAP™ może prawdopodobnie nasycić Gigabit Ethernet LAN (0,1GB / s) . I jeden Gigabit Ethernet LAN (0,1GB / s) może prawdopodobnie nasycić OC- 12 Internet (0,06GB / s) . I przynajmniej jedno źródło zawiera listę linii OC- 12 kosztujących około 100.000 dolarów miesięcznie. (Tak, obliczenia te opierają się na pchnięciu systemu do jego granic, co nie jest dobre, ponieważ prowadzi do bardzo powolnych reakcji. Ale te obliczenia są przydatne do planowania i równoważenia części systemu.) Oczywiście, odpowiednio szybkie połączenie internetowe dla centrum danych jest zdecydowanie najdroższą częścią systemu. Można łatwo i stosunkowo tanio zbudować sieć z tuzin serwerów uruchamiających tuzin ERDDAP s, które jest w stanie szybko pompować wiele danych, ale odpowiednio szybkie połączenie internetowe będzie bardzo, bardzo drogie. Roztwory częściowe to:
- Zachęcanie klientów do żądania podzbiorów danych, jeśli tylko to jest potrzebne. Jeśli klient potrzebuje danych tylko dla małego regionu lub w niższej rozdzielczości, to o to powinni poprosić. Subsetting jest centralnym elementem protokołów ERDDAP™ obsługa żądania danych.
- Zachęcać do przekazywania skompresowanych danych. ERDDAP™ kompresja transmisja danych, jeżeli w kodowaniu "accept- encoding" znajduje się HTTP GET nagłówek żądania. Wszystkie przeglądarki używają "accept- encoding" i automatycznie dekompresują odpowiedź. Inni klienci (np. programy komputerowe) muszą go wyraźnie użyć.
- Kolokacja serwerów w ISP lub innej witrynie, która oferuje relatywnie niższe koszty przepustowości.
- Disperse serwerów z ERDDAP s do różnych instytucji, tak aby koszty były rozproszone. Następnie możesz połączyć swój kompozyt ERDDAP™ im ERDDAP b.
Zauważ, że Cloud Computing i usługi hostingu internetowego oferują wszystkie łącza internetowe, których potrzebujesz, ale nie rozwiązuj problemu cen.
Aby uzyskać ogólne informacje na temat projektowania skalowalnych, o dużej pojemności, systemów odpornych na uszkodzenia, zobacz książkę Michaela T. Nygarda Uwolnić .
Jak Lego
Projektanci oprogramowania często starają się używać dobrego Wzory projektowania oprogramowania rozwiązywać problemy. Dobre wzorce są dobre, ponieważ zawierają dobre, łatwe w tworzeniu i pracy rozwiązania ogólnego celu, które prowadzą do systemów o dobrych właściwościach. Nazwy wzorów nie są standaryzowane, więc nazwę je wzorem. ERDDAP™ używa wzoru Lego. Każdy Lego (każdy ERDDAP ) jest prosty, mały, standardowy, samodzielny, cegła (serwer danych) z określonym interfejsem, który pozwala na połączenie go z innymi lego ( ERDDAP s) . Części ERDDAP™ który tworzą ten system są: systemy subskrypcji i flagURL (która pozwala na komunikację między ERDDAP s) , EDD... FromErddap redirect system, i system RESTful wnioski o dane, które mogą być generowane przez użytkowników lub inne ERDDAP b. Tak więc, biorąc dwa lub więcej lego ( ERDDAP s) , można stworzyć ogromną liczbę różnych kształtów (topologie sieci ERDDAP s) . Jasne, projekt i cechy ERDDAP™ mógł być zrobiony inaczej, nie jak Lego, być może tylko po to, aby włączyć i zoptymalizować dla jednej konkretnej topologii. Ale czujemy, że ERDDAP Lego-podobny projekt oferuje dobre, ogólne rozwiązanie, które umożliwia ERDDAP™ administrator (lub grupy administratorów) do tworzenia różnego rodzaju topologii federacyjnych. Na przykład, jedna organizacja może ustawić trzy (lub więcej) ERDDAP s jak pokazano w ERDDAP™ Schemat siatki / klastra powyżej . Albo podzielona grupa (IOOS? CoastWatch? NCEI? NWS? NOAA ? USGS? DataONE? NEON? - Tak. OOI? BODC? ONC? JRC? WMO?) może ustawić jeden ERDDAP™ w każdej małej placówce (więc dane mogą pozostać blisko źródła) a następnie ustawić kompozyt ERDDAP™ w centralnym biurze z wirtualnymi zbiorami danych (które są zawsze doskonale up- to- date) z każdego z małych placówek ERDDAP b. W rzeczy samej, wszystkie ERDDAP s, zainstalowane w różnych instytucjach na całym świecie, które otrzymują dane z innych ERDDAP i / lub przekazywać dane innym osobom ERDDAP s, tworzą gigantyczną sieć ERDDAP b. Czy to nie fajne? Tak jak w przypadku Lego, możliwości są nieograniczone. Dlatego to dobry wzór. Dlatego jest to dobry projekt dla ERDDAP .
Różne rodzaje wniosków
Jednym z komplikacji real- life tej dyskusji topologii serwerów danych jest to, że istnieją różne rodzaje wniosków i różne sposoby optymalizacji dla różnych rodzajów wniosków. Jest to głównie oddzielny problem (Jak szybko może ERDDAP™ z danymi odpowiadającymi na wniosek o dane?) z dyskusji topologicznej (która zajmuje się relacjami pomiędzy serwerami danych i który serwer posiada rzeczywiste dane) . ERDDAP™ , oczywiście, stara się radzić sobie ze wszystkimi rodzajami wniosków skutecznie, ale radzi sobie niektóre lepiej niż inne.
- Wiele próśb jest prostych. Na przykład: Jakie są metadane dla tego zbioru danych? Albo: Jakie są wartości wymiaru czasu dla tego zbioru danych? ERDDAP™ jest przeznaczony do obsługi tych jak najszybciej (zwykle w<= 2 ms) poprzez zachowanie tej informacji w pamięci.
- Niektóre prośby są umiarkowanie trudne. Na przykład: Daj mi ten podzbiór zbioru danych (który jest w jednym pliku danych) . Żądania te można rozpatrywać stosunkowo szybko, ponieważ nie są one trudne.
- Niektóre wnioski są trudne, a zatem czasochłonne. Na przykład: Daj mi ten podzbiór zbioru danych (które mogą być w dowolnym z 10 000 + plików danych, lub mogą być ze skompresowanych plików danych, które każdy zajmuje 10 sekund do dekompresji) . ERDDAP™ v2.0 wprowadziła kilka nowych, szybszych sposobów radzenia sobie z tymi wnioskami, w szczególności poprzez umożliwienie nitki do obsługi zapytania do spawania kilku wątków pracowników, które dotyczą różnych podzbiorów wniosku. Ale istnieje inne podejście do tego problemu, które ERDDAP™ nie obsługuje jeszcze: podzbiory plików danych dla danego zbioru danych mogą być przechowywane i analizowane na oddzielnych komputerach, a następnie wyniki łączone na oryginalnym serwerze. Takie podejście jest nazywane MapReduce i jest przykładem Hadoop , pierwszy (?) open- source Program MapReduxe, który został oparty na pomysłach z papieru Google. (Jeśli potrzebna jest ERDDAP , prosimy wysłać wniosek e-mail do erd.data at noaa.gov .) Google BigQuery jest interesujące, ponieważ wydaje się, że jest to implementacja MapRedue zastosowana do podstawiania zbiorów danych tabelarycznych, które są jednym z ERDDAP główne cele. Prawdopodobnie można utworzyć ERDDAP™ zbiór danych z zbioru danych BigQuery poprzez EDDTableFromDatabase ponieważ BigQuery można uzyskać dostęp przez interfejs JDBC.
To moje zdanie.
Tak, obliczenia są uproszczone. (a teraz lekko datowany) , ale myślę, że wnioski są prawidłowe. Czy użyłem błędnej logiki czy popełniłem błąd w moich obliczeniach? Jeśli tak, to moja wina. Proszę wysłać e-mail z poprawką do erd dot data at noaa dot gov .
Cloud Computing
Kilka firm oferuje usługi przetwarzania w chmurze (np., Amazon Web Services oraz Platforma Google Cloud ) . Firmy hostingowe WWW oferowały prostsze usługi od połowy 1990 roku, ale usługi "chmura" znacznie zwiększyły elastyczność systemów i zakres oferowanych usług. Od czasu ERDDAP™ siatka składa się z ERDDAP s i od ERDDAP s Java aplikacje internetowe, które mogą działać w Tomcat (najczęstszy serwer aplikacji) lub innych serwerów aplikacji, powinno być stosunkowo łatwo skonfigurować ERDDAP™ sieci na usługi w chmurze lub stronie hostingu. Korzyści płynące z tych usług to:
- Oferują dostęp do bardzo dużych połączeń internetowych. To samo może uzasadniać korzystanie z tych usług.
- Płacą tylko za twoje usługi. Na przykład, masz dostęp do bardzo dużego łącza internetowego, ale płacisz tylko za faktyczne dane przekazywane. To pozwala zbudować system, który rzadko jest przytłoczony (nawet przy szczytowym popycie) , bez konieczności płacenia za zdolność, która jest rzadko wykorzystywana.
- Łatwo je rozszerzyć. Możesz zmienić typy serwerów lub dodać tyle serwerów lub tyle pamięci, ile chcesz, w mniej niż minutę. To samo może uzasadniać korzystanie z tych usług.
- Uwolnili cię od wielu obowiązków administracyjnych związanych z prowadzeniem serwerów i sieci. To samo może uzasadniać korzystanie z tych usług.
Wadą tych usług są:
- Oni pobierają opłaty za swoje usługi, czasami dużo (w wartościach bezwzględnych; nie, że nie jest to dobra wartość) . Ceny wymienione tutaj są dla Amazon EC2 . Ceny te (od czerwca 2015 r.) zejdzie.
W przeszłości ceny były wyższe, ale pliki danych i liczba wniosków były mniejsze.
W przyszłości ceny będą niższe, ale pliki danych i liczba wniosków będą większe.
Szczegóły się zmieniają, ale sytuacja pozostaje stosunkowo stała.
I nie chodzi o to, że usługa jest przeceniana, ale o to, że używamy i kupujemy dużo usług.
- Transfer danych - Transfer danych do systemu jest teraz wolny (Tak!) . Transfer danych z systemu wynosi $0.09 / GB. Jeden dysk twardy SATA (0,3GB / s) na jednym serwerze z jednym ERDDAP™ może prawdopodobnie nasycić Gigabit Ethernet LAN (0,1GB / s) . Jedna Gigabit Ethernet LAN (0,1GB / s) może prawdopodobnie nasycić OC- 12 Internet (0,06GB / s) . Jeśli jedno połączenie OC- 12 może przesłać ~ 150.000 GB / miesiąc, koszty transferu danych mogą wynosić aż 150 000 GB @ $0.09 / GB = 13,500 $/ miesiąc, co jest znaczącym kosztem. Najwyraźniej, jeśli masz tuzin ciężko pracujących ERDDAP s na usługi w chmurze, miesięczne opłaty za transfer danych mogą być znaczne (do 162,000 dolarów / miesiąc) . (Nie chodzi o to, że usługa jest przeceniana, ale o to, że używamy i kupujemy dużo usług.)
- Przechowywanie danych - Amazon pobiera opłaty $50 / miesiąc za TB. (Porównaj to z zakupem 4TB przedsiębiorstwo jazdy bezpośrednio dla ~ $50 / TB, chociaż RAID umieścić go i koszty administracyjne dodać do kosztów całkowitych.) Więc jeśli trzeba przechowywać wiele danych w chmurze, może to być dość drogie (np. 100TB kosztowałoby $5000 / miesiąc) . Ale jeśli nie masz naprawdę dużej ilości danych, jest to mniejszy problem niż koszty transmisji danych / przepustowości. (Nie chodzi o to, że usługa jest przeceniana, ale o to, że używamy i kupujemy dużo usług.)
Poddanie
- Problem z subustawianiem: Jedynym sposobem skutecznego rozpowszechniania danych z plików danych jest posiadanie programu, który je rozpowszechnia. (np., ERDDAP ) działa na serwerze, który posiada dane przechowywane na lokalnym dysku twardym (lub podobnie szybki dostęp do SAN lub lokalnej RAID) . Lokalne systemy plików pozwalają ERDDAP™ (i biblioteki bazowe, takie jak netcdf- java) aby zażądać określonego bajtu zakresy z plików i uzyskać odpowiedzi bardzo szybko. Wiele rodzajów wniosków o dane z ERDDAP™ do pliku (w szczególności wnioski o podanie danych w sieci, gdzie wartość kroku jest > 1) nie może być wykonane skutecznie, jeśli program musi zażądać całego pliku lub dużych fragmentów pliku z nielokalnego (więc wolniej) system przechowywania danych, a następnie wyodrębnić podzbiór. Jeśli konfiguracja chmur nie daje ERDDAP™ szybki dostęp do zakresów bajtów plików (tak szybko jak w przypadku plików lokalnych) , ERDDAP dostęp do danych będzie poważnym wąskim gardłem i negacją innych korzyści z korzystania z usługi w chmurze.
Hosted Data
Alternatywa dla powyższej analizy kosztów korzyści (który opiera się na właścicielu danych (np., NOAA ) płatności za ich dane przechowywane w chmurze) przybył około 2012, kiedy Amazon (i w mniejszym stopniu, niektórzy inni dostawcy chmur) zaczęli hostować kilka zbiorów danych w ich chmurze (AWS S3) za darmo (przypuszczalnie mając nadzieję, że będą mogli odzyskać swoje koszty, jeśli użytkownicy wynajmą AWS EC2 obliczając instancje do pracy z tymi danymi) . Wyraźnie sprawia to, że przetwarzanie w chmurze znacznie bardziej opłacalne, ponieważ czas i koszty przesyłania danych i hostingu są teraz zero. Z ERDDAP™ v2.0, istnieją nowe funkcje ułatwiające pracę ERDDAP w chmurze:
- Teraz EDDGrid Pliki FromFiles lub EDDTableFromFiles mogą być tworzone z plików danych, które są zdalne i dostępne przez Internet (np. wiadra AWS S3) za pomocą<cacheFromUrl & gt; oraz<Rozmiar kapsułki Opcje GB & gt;. ERDDAP™ będzie utrzymywać lokalny pamięci podręcznej ostatnio używanych plików danych.
- Teraz, jeśli jakiekolwiek pliki źródłowe EDDTableFromFiles są skompresowane (np., .tgz ) , ERDDAP™ automatycznie zdekompresuje je, gdy je przeczyta.
- Teraz... ERDDAP™ wątek odpowiadający na dane żądanie będzie spawn wątki pracowników do pracy na podsekcjach wniosku, jeśli korzystać z<nThreads & gt; opcje. To równoległe podejście powinno umożliwić szybsze reagowanie na trudne żądania.
Zmiany te rozwiązują problem AWS S3 nie oferując lokalną, block- poziom przechowywania plików i (stary) problem dostępu do danych S3 o znacznym opóźnieniu. (Lata temu (- 2014) , że opóźnienie było znaczące, ale teraz jest o wiele krótszy, a więc nie tak znaczące.) W sumie, to znaczy, że ustawienie ERDDAP™ w chmurze działa teraz znacznie lepiej.
Dzięki. - Wielkie podziękowania dla Matthew Arrotta i jego grupy w oryginalnej OOI wysiłku za ich pracę na umieszczenie ERDDAP™ w chmurze i wynikające z niej dyskusje.
Zdalna replikacja zbiorów danych
Istnieje wspólny problem związany z powyższą dyskusją o sieciach i federacjach ERDDAP s: zdalna replikacja zbiorów danych. Podstawowym problemem jest: dostawca danych utrzymuje zbiór danych, który zmienia się sporadycznie, a użytkownik chce utrzymać miejscową kopię up- to- date tego zbioru danych (z różnych powodów) . Najwyraźniej istnieje ogromna liczba różnic. Niektóre warianty są o wiele trudniejsze do rozwiązania niż inne.
- Szybkie aktualizacje Trudniej utrzymać lokalny zestaw danych na bieżąco natychmiast (np. w ciągu 3 sekund) po każdej zmianie źródła, a nie, na przykład, w ciągu kilku godzin.
- Częste zmiany Częste zmiany są trudniejsze do rozwiązania niż rzadkie zmiany. Na przykład zmiany jednego dnia są o wiele łatwiejsze do rozwiązania niż zmiany co 0.1 sekundy.
- Małe zmiany Małe zmiany w pliku źródłowym są trudniejsze do rozwiązania niż zupełnie nowy plik. Jest to szczególnie prawdziwe, jeśli małe zmiany mogą być gdziekolwiek w pliku. Niewielkie zmiany są trudniejsze do wykrycia i utrudniają odizolowanie danych, które należy powielić. Nowe pliki są łatwe do wykrycia i skuteczne do transferu.
- Cały zbiór danych Utrzymanie całego zbioru danych na bieżąco jest trudniejsze niż utrzymywanie tylko ostatnich danych. Niektórzy użytkownicy potrzebują najnowszych danych (np. ostatnie 8 dni) .
- Wiele kopii Utrzymanie wielu zdalnych kopii w różnych miejscach jest trudniejsze niż utrzymanie jednej zdalnej kopii. To jest problem skalowania.
Oczywiście istnieje ogromna liczba różnych rodzajów zmian w zbiorze danych źródłowych oraz potrzeb i oczekiwań użytkownika. Wiele wariantów jest bardzo trudnych do rozwiązania. Najlepszym rozwiązaniem dla jednej sytuacji jest często nie najlepsze rozwiązanie dla innej sytuacji - nie ma jeszcze uniwersalnego wielkiego rozwiązania.
Odpowiednie ERDDAP™ Narzędzia
ERDDAP™ oferuje kilka narzędzi, które mogą być stosowane jako część systemu, który ma na celu utrzymanie zdalnej kopii zbioru danych:
- ERDDAP jest RSS (Rich Site Streszczenie?) obsługa
oferuje szybki sposób, aby sprawdzić, czy zestaw danych na pilocie ERDDAP™ Zmienił się. - ERDDAP jest usługi subskrypcji
jest bardziej wydajny (niż RSS ) podejście: natychmiast wyśle e-mail lub skontaktujemy się z adresem URL do każdego abonenta za każdym razem, gdy zestaw danych jest aktualizowany i aktualizacja skutkuje zmianą. Jest to skuteczne, ponieważ dzieje się to jak najszybciej i nie ma zmarnowanych wysiłków (jak w sondażach RSS obsługa) . Użytkownicy mogą używać innych narzędzi (jak IFTTT ) reagować na powiadomienia e-mail z systemu subskrypcji. Na przykład, użytkownik może subskrybować zestaw danych na pilocie ERDDAP™ i użyć IFTTT do reagowania na powiadomienia e-mail subskrypcji i uruchomić aktualizację lokalnego zbioru danych. - ERDDAP jest system flag
zapewnia sposób na ERDDAP™ administrator informuje o zestawie danych ERDDAP Przeładować jak najszybciej. Formę URL flagi można łatwo wykorzystać w skryptach. Formę URL flagi można również wykorzystać jako akcję subskrypcji. - ERDDAP jest "files" system
może zaoferować dostęp do plików źródłowych dla danego zbioru danych, w tym listę katalogów w stylu Apache- ("folder dostępny w sieci") który posiada adres URL pobierania każdego pliku, ostatni zmodyfikowany czas i rozmiar. Jedna minuta używania "files" system jest, że pliki źródłowe mogą mieć różne nazwy zmiennych i inne metadane niż zbiór danych, jak to pojawia się w ERDDAP . Jeśli pilot ERDDAP™ zestaw danych oferuje dostęp do swoich plików źródłowych, który otwiera możliwość wersji rsync Poor- man: to staje się łatwe dla lokalnego systemu, aby zobaczyć, które zdalne pliki się zmieniły i trzeba pobrać. (Patrz opcja cacheFromUrl poniżej którego można skorzystać z tego.)
Rozwiązania
Pomimo ogromnej liczby zmian w problemie i nieskończonej liczby możliwych rozwiązań, istnieje tylko kilka podstawowych podejść do rozwiązań:
Własny, Brute Force Solutions
Oczywistym rozwiązaniem jest rękodzieło niestandardowe rozwiązanie, które jest zatem zoptymalizowane dla danej sytuacji: zrobić system, który wykrywa / identyfikuje, które dane się zmieniły, i wysyła te informacje do użytkownika, aby użytkownik mógł poprosić zmienione dane. Możesz to zrobić, ale są wady:
- Niestandardowe rozwiązania to dużo pracy.
- Rozwiązania niestandardowe są zwykle tak dostosowane do danego zbioru danych i podane w systemie użytkownika, że nie można ich łatwo ponownie używać.
- Niestandardowe rozwiązania muszą być budowane i utrzymywane przez Ciebie. (To nigdy nie jest dobry pomysł. To zawsze dobry pomysł, aby uniknąć pracy i znaleźć kogoś innego do pracy!)
Odradzam przyjęcie tego podejścia, ponieważ prawie zawsze lepiej jest szukać ogólnych rozwiązań, zbudowanych i utrzymywanych przez kogoś innego, które można łatwo ponownie wykorzystać w różnych sytuacjach.
rsync
rsync jest istniejącym, zdumiewająco dobrym, ogólnym rozwiązaniem do przechowywania kolekcji plików na komputerze źródłowym synchronizacji na zdalnym komputerze użytkownika. To działa tak:
- Zdarzenie (np. ERDDAP™ impreza systemu subskrypcji) uruchamia rsync, (lub, praca cron działa rsync w określonych czasach codziennie na komputerze użytkownika)
- który kontaktuje się z rsync na komputerze źródłowym,
- która oblicza serię hash dla fragmentów każdego pliku i przesyła je do rsync użytkownika,
- które porównuje te informacje z podobnymi informacjami dla kopii plików użytkownika,
- które następnie żąda fragmentów plików, które uległy zmianie.
Biorąc pod uwagę wszystko, co robi, rsync działa bardzo szybko (np. 10 sekund plus czas transmisji danych) i bardzo efektywnie. Są zmiany rsync które optymalizują w różnych sytuacjach (np. poprzez prekalkulację i buforowanie pęknięć fragmentów każdego pliku źródłowego) .
Głównymi słabościami rsync są: potrzeba trochę wysiłku, aby utworzyć (kwestie bezpieczeństwa) ; są pewne problemy skalowania; i nie jest to dobre dla utrzymania zbiorów danych NRT naprawdę up- to- date (np., to niezręczne używać rsync więcej niż około co 5 minut) . Jeśli możesz poradzić sobie ze słabościami lub jeśli nie wpływają one na twoją sytuację, rsync jest doskonałym, ogólnym rozwiązaniem, które każdy może teraz wykorzystać do rozwiązania wielu scenariuszy związanych z zdalną replikacją zbiorów danych.
Jest coś na temat ERDDAP™ Aby zrobić listę, aby spróbować dodać wsparcie dla usług rsync do ERDDAP (Prawdopodobnie trudne zadanie.) , aby każdy klient mógł używać rsync (lub wariant) do utrzymania kopii up- to- date zbioru danych. Jeśli ktoś chce nad tym popracować, proszę wysłać e-mail erd.data at noaa.gov .
Istnieją inne programy, które robią mniej lub bardziej to, co rsync robi, czasami zorientowane na replikację zbioru danych (chociaż często na poziomie kopiowania plików) , np., Unidata jest IDD .
Cache From Url
The cacheFromUrl ustawienia są dostępne (rozpoczynając od ERDDAP™ v2.0) dla wszystkich ERDDAP typy zbioru danych, które tworzą zestawy danych z plików (w zasadzie, wszystkie podklasy EDDGrid Pliki FromFiles oraz Pliki EDDTableFromFiles ) . cache FromUrl sprawia, że jest trywialne automatyczne pobieranie i utrzymywanie lokalnych plików danych poprzez kopiowanie ich ze zdalnego źródła za pośrednictwem bufora Naprawa FromUrl. Zdalne pliki mogą znajdować się w katalogu Web Accessible lub w liście plików typu directory- oferowanej przez THREDDS, Hyrax , wiadro S3, lub ERDDAP jest "files" system.
Jeśli źródło zdalnych plików jest zdalne ERDDAP™ zestaw danych, który oferuje pliki źródłowe za pośrednictwem ERDDAP™ "files" system, wtedy można subskrypcja do zdalnego zbioru danych i używać URL flagi dla lokalnego zbioru danych jako działania dla subskrypcji. Następnie, za każdym razem, gdy zmieniany jest zdalny zbiór danych, skontaktujemy się z adresem URL flagi dla twojego zbioru danych, który przeładuje się jak najszybciej, co wykryje i pobierze zmienione pliki danych zdalnych. To wszystko dzieje się bardzo szybko. (zwykle ~ 5 sekund plus czas potrzebny na pobranie zmienionych plików) . To podejście działa świetnie, jeśli zmiany zbioru danych źródłowych są nowymi plikami okresowo dodawanymi i kiedy istniejące pliki nigdy się nie zmieniają. To podejście nie działa dobrze, jeśli dane są często dołączane do wszystkich (lub większość) istniejących plików danych źródłowych, ponieważ wtedy lokalny zbiór danych często pobiera cały zestaw danych zdalnych. (To tutaj potrzebne jest podejście podobne do rsync.)
ArchiveADATASET
ERDDAP™ jest ArchiveADATASET jest dobrym rozwiązaniem, gdy dane są często dodawane do zbioru danych, ale dane starsze nigdy się nie zmieniają. Zasadniczo ERDDAP™ administrator może uruchomić ArchiveADATAset (Może w scenariuszu, być może prowadzony przez cron) i określić podzbiór zbioru danych, który chcą wyodrębnić (być może w wielu plikach) i opakowanie w .zip lub .tgz plik, aby wysłać plik do zainteresowanych osób lub grup (np. NCEI do archiwizacji) lub udostępnić do pobrania. Na przykład, można uruchomić ArchiveAdataset codziennie o 12: 10 rano i mieć to zrobić .zip ze wszystkich danych od 12: 00 do 12: 00 dzisiaj. (Albo robić to co tydzień, co miesiąc lub co roku, w razie potrzeby.) Ponieważ plik zapakowany jest generowany w trybie offline, nie ma zagrożenia przerwami czasowymi lub zbyt dużą ilością danych, jak byłoby w przypadku standardu ERDDAP™ Wniosek.
ERDDAP™ standardowy system żądania
ERDDAP™ standardowy system żądania jest alternatywnym dobrym rozwiązaniem, gdy dane są często dodawane do zbioru danych, ale starsze dane nigdy się nie zmieniają. Zasadniczo, każdy może użyć standardowych żądań, aby uzyskać dane przez określony zakres czasu. Na przykład, codziennie o 12: 10, możesz poprosić o wszystkie dane ze zdalnego zbioru danych od 12: 00 do 12: 00. Ograniczenie (w porównaniu z podejściem ArchiveADATASET) jest to ryzyko opóźnienia lub zbyt wiele danych dla jednego pliku. Można uniknąć ograniczenia poprzez częstsze wnioski o mniejsze okresy.
EDDTableFromHttpGet
\[ Ta opcja jeszcze nie istnieje, ale wydaje się możliwe, aby zbudować w najbliższej przyszłości. \]
Nowy EDDTableFromHttpGet typ zbioru danych w ERDDAP™ v2.0 umożliwia wyobrażenie sobie innego rozwiązania. Podstawowe pliki przechowywane przez ten typ zbioru danych to zasadniczo pliki logowania, które rejestrują zmiany w zbiorze danych. Powinno być możliwe zbudowanie systemu, który utrzymuje zbiór lokalnych danych przez okresowo (lub na podstawie spustu) żądania wszystkich zmian wprowadzonych do zdalnego zbioru danych od ostatniego wniosku. To powinno być tak skuteczne (lub więcej) niż rsync i będzie obsługiwać wiele trudnych scenariuszy, ale będzie działać tylko wtedy, gdy zdalne i lokalne zbiory danych są EDDTableFromHttpGet zbiorów danych.
Jeśli ktoś chce nad tym popracować, prosimy o kontakt. erd.data at noaa.gov .
Dane rozproszone
Żadne z powyższych rozwiązań nie rozwiązuje trudnych zmian problemu, ponieważ powielanie w czasie rzeczywistym (NRT) Zestawy danych są bardzo trudne, częściowo ze względu na wszystkie możliwe scenariusze.
Jest świetne rozwiązanie: nawet nie próbuj powielać danych. Zamiast tego, użyj jednego autorytatywnego źródła (jeden zbiór danych na jeden ERDDAP ) , utrzymywane przez dostawcę danych (np. biuro regionalne) . Wszyscy użytkownicy, którzy chcą danych z tego zbioru danych zawsze dostają je ze źródła. Na przykład aplikacje oparte na przeglądarce pobierają dane z aplikacji opartych na URL, więc nie powinno mieć znaczenia, że żądanie jest do pierwotnego źródła na zdalnym serwerze (nie ten sam serwer, który hostuje EMS) . Wiele osób od dawna popiera takie podejście do rozproszonych danych. (np. Roy Mendelssohn w ciągu ostatnich 20 + lat) . ERDDAP model sieci / federacji (Top 80% niniejszego dokumentu) opiera się na tym podejściu. To rozwiązanie jest jak miecz dla Gordiana Knota - cały problem znika.
- To niezwykle proste rozwiązanie.
- Rozwiązanie to jest niezwykle skuteczne, ponieważ nie wykonuje się żadnej pracy, aby utrzymać replikowany zestaw danych (s) Up- to-date.
- Użytkownicy mogą uzyskać najnowsze dane w każdej chwili (np. z opóźnieniem tylko ~ 0,5 sekundy) .
- Skala jest całkiem dobra i są sposoby na poprawę skalowania. (Zobacz dyskusję na szczycie 80% niniejszego dokumentu.)
Nie, to nie jest rozwiązanie dla wszystkich możliwych sytuacji, ale jest to świetne rozwiązanie dla większości. Jeżeli w pewnych sytuacjach występują problemy / słabości związane z tym rozwiązaniem, warto często pracować nad rozwiązaniem tych problemów lub żyć z tymi słabościami z powodu oszałamiających zalet tego rozwiązania. Jeśli / kiedy rozwiązanie to jest naprawdę nie do przyjęcia dla danej sytuacji, np. gdy naprawdę musisz mieć lokalną kopię danych, to rozważ inne rozwiązania omówione powyżej.
Wniosek
Chociaż nie ma jednego, prostego rozwiązania, które doskonale rozwiązuje wszystkie problemy we wszystkich scenariuszach (jak rsync i rozproszone dane prawie są) , Mam nadzieję, że istnieją wystarczające narzędzia i opcje, aby można było znaleźć akceptowalne rozwiązanie dla konkretnej sytuacji.