Schalen
ERDDAP™ - Zware belasting, rasters, Clusters, Federaties en Cloud Computing
ERDDAP :
ERDDAP™ is een webapplicatie en een webservice die wetenschappelijke gegevens uit verschillende lokale en externe bronnen samenvoegt en een eenvoudige, consistente manier biedt om deelverzamelingen van de gegevens in gemeenschappelijke bestandsformaten te downloaden en grafieken en kaarten te maken. Deze web pagina bespreekt kwesties met betrekking tot zwaar ERDDAP™ gebruik ladingen en verkent mogelijkheden voor het omgaan met extreem zware lasten via roosters, clusters, federaties en cloud computing.
De originele versie is geschreven in juni 2009. Er zijn geen significante veranderingen geweest. Dit is voor het laatst bijgewerkt 2019-04-15.
DISCLAIMER
De inhoud van deze webpagina zijn Bob Simons persoonlijke meningen en niet noodzakelijkerwijs weerspiegelt een standpunt van de regering of de National Oceanic and Atmospheric Administration . De berekeningen zijn simplistisch, maar ik denk dat de conclusies juist zijn. Heb ik verkeerde logica gebruikt of een fout gemaakt in mijn berekeningen? Zo ja, dan is de schuld alleen aan mij. Stuur een e-mail met de correctie naar erd dot data at noaa dot gov .
Zware lasten/beperkingen
Met zwaar gebruik, een standalone ERDDAP™ zal worden beperkt (van meest naar minst waarschijnlijk) door:
Bronbandbreedte op afstand
- De bandbreedte van een databron op afstand, zelfs met een efficiënte verbinding (bv. via OPeNDAP ) , tenzij een externe gegevensbron een zeer hoge bandbreedte internetverbinding heeft, ERDDAP 's Antwoorden zullen worden beperkt door hoe snel ERDDAP™ kan gegevens van de gegevensbron te krijgen. Een oplossing is om de dataset te kopiëren naar ERDDAP 's harde schijf, misschien met EDDGrid Kopiëren of EDDtabelkopie .
ERDDAP 's Serverbandbreedte
- Tenzij ERDDAP 's server heeft een zeer hoge bandbreedte internetverbinding, ERDDAP 's Antwoorden zullen worden beperkt door hoe snel ERDDAP™ kan gegevens uit de gegevensbronnen en hoe snel ERDDAP™ kan gegevens terugsturen naar de klanten. De enige oplossing is om een snellere internetverbinding te krijgen.
Geheugen
- Als er veel gelijktijdige verzoeken, ERDDAP™ kan zonder geheugen en tijdelijk weigeren nieuwe verzoeken. ( ERDDAP™ heeft een aantal mechanismen om dit te voorkomen en om de gevolgen te minimaliseren als het gebeurt.) Hoe meer geheugen in de server, hoe beter. Op een 32-bits server is 4+ GB echt goed, 2 GB is oké, minder wordt niet aanbevolen. Op een 64-bits server kunt u het probleem bijna geheel vermijden door veel geheugen te krijgen. Zie \-Xmx en -Xms instellingen voor ERDDAP Tomcat. Een ERDDAP™ Het krijgen van zwaar gebruik op een computer met een 64-bits server met 8GB geheugen en -Xmx ingesteld op 4000M is zelden, indien ooit, beperkt door geheugen.
Had Drive Bandbreedte
- Toegang tot gegevens die zijn opgeslagen op de harde schijf van de server is veel sneller dan toegang tot gegevens op afstand. Toch, als de ERDDAP™ server heeft een zeer hoge bandbreedte internetverbinding, het is mogelijk dat toegang tot gegevens op de harde schijf een knelpunt zal zijn. Een gedeeltelijke oplossing is sneller te gebruiken (b.v. 10.000 RPM) magnetische harde schijven of SSD-schijven (als het logisch is kostenbewust) . Een andere oplossing is om verschillende datasets op verschillende schijven op te slaan, zodat de cumulatieve bandbreedte van de harde schijf veel hoger is.
Te veel bestanden
- Te veel bestanden in een cache map ERDDAP™ caches alle afbeeldingen, maar alleen caches de gegevens voor bepaalde soorten gegevensverzoeken. Het is mogelijk dat de cache directory voor een dataset een groot aantal bestanden tijdelijk heeft. Dit vertraagt verzoeken om te zien of er een bestand in de cache zit (Echt waar!) .<cache Minuten> in setup.xml kunt u instellen hoe lang een bestand kan worden in de cache voordat het wordt verwijderd. Een kleiner getal zou dit probleem minimaliseren.
CPU
- Slechts twee dingen kosten veel CPU tijd:
- NetCDF 4 en HDF 5 ondersteunt nu interne compressie van gegevens. Een grote gecomprimeerde decomprimeren NetCDF 4 / HDF 5 gegevensbestand kan 10 of meer seconden duren. (Dat is geen uitvoeringsfout. Het is de aard van compressie.) Dus, meerdere gelijktijdige verzoeken naar datasets met gegevens opgeslagen in gecomprimeerde bestanden kan een ernstige spanning op elke server. Als dit een probleem is, is de oplossing om populaire datasets op te slaan in niet-gecomprimeerde bestanden, of een server te krijgen met een CPU met meer cores.
- Grafieken maken (inclusief kaarten) : ruwweg 0,2 - 1 seconde per grafiek. Dus als er veel gelijktijdige unieke verzoeken voor grafieken ( WMS Klanten doen vaak 6 gelijktijdige verzoeken!) Er kan een CPU beperking zijn. Wanneer meerdere gebruikers actief zijn WMS Klanten, dit wordt een probleem.
Meerdere identieke ERDDAP Bij Load Balancing?
De vraag komt vaak op: "Om te gaan met zware lasten, kan ik meerdere identieke ERDDAP ' Het is een interessante vraag omdat het snel tot de kern van ERDDAP Het ontwerp. Het snelle antwoord is nee. Ik weet dat dit een teleurstellend antwoord is, maar er zijn een paar directe redenen en enkele grotere fundamentele redenen waarom ik ERDDAP™ om een andere aanpak te gebruiken (een federatie van ERDDAP s, beschreven in het grootste deel van dit document) , wat volgens mij een betere oplossing is.
Enkele directe redenen waarom u niet kan/moet instellen meerdere identieke ERDDAP s zijn:
- A gegeven ERDDAP™ leest elk gegevensbestand wanneer het voor het eerst beschikbaar wordt om de reeksen gegevens in het bestand te vinden. Het slaat die informatie dan op in een indexbestand. Later, als er een gebruikersverzoek voor gegevens binnenkomt, ERDDAP™ gebruikt die index om uit te zoeken welke bestanden om in te kijken voor de gevraagde gegevens. Als er meerdere identieke ERDDAP S, ze zouden elk deze indexering doen, die verspilde inspanning. Met het hieronder beschreven gefedereerde systeem wordt de indexering slechts eenmaal uitgevoerd door één van de ERDDAP s.
- Voor sommige soorten gebruikersverzoeken (bv. voor .nc , .png, .pdf bestanden) ERDDAP™ moet het hele bestand te maken voordat het antwoord kan worden verzonden. Dus. ERDDAP™ Deze dossiers worden kort bewaard. Indien een identiek verzoek binnenkomt (zoals het vaak doet, vooral voor afbeeldingen waar de URL is ingebed in een webpagina) , ERDDAP™ kan dat gecached bestand hergebruiken. In een systeem van meerdere identieke ERDDAP s, die gecachede bestanden worden niet gedeeld, dus elk ERDDAP™ zou onnodig en verspillend de .nc , .png, of .pdf bestanden. Met het gefedereerde systeem dat hieronder wordt beschreven, worden de bestanden slechts eenmaal, door een van de ERDDAP en hergebruikt.
- ERDDAP 's abonnementssysteem is niet ingesteld om gedeeld te worden door meerdere ERDDAP s. Bijvoorbeeld, als de load balancer stuurt een gebruiker naar een ERDDAP™ en de gebruiker abonneert zich op een dataset, dan de andere ERDDAP S zal niet op de hoogte zijn van dat abonnement. Later, als de load balancer stuurt de gebruiker naar een andere ERDDAP™ en vraagt om een lijst van zijn/haar abonnementen, de andere ERDDAP™ zal zeggen dat er geen (waarbij hij/zij een dubbel abonnement neemt op de andere ERED DAP ) . Met het hieronder beschreven gefedereerde systeem wordt het abonnementssysteem eenvoudigweg behandeld door de belangrijkste, publieke, samengestelde ERDDAP .
Ja, voor elk van deze problemen, kon ik (met grote moeite) maak een oplossing (om de informatie te delen tussen ERDDAP s) , maar ik denk dat Federatie-van- ERDDAP Aanpak (beschreven in het grootste deel van dit document) Het is een veel betere algemene oplossing, mede omdat het andere problemen behandelt die de multi-identieke- ERDDAP s-with-a-load-balancer aanpak begint niet eens aan te pakken, met name de gedecentraliseerde aard van de gegevensbronnen in de wereld.
Het is het beste om het simpele feit te accepteren dat ik niet heb ontworpen ERDDAP™ in te zetten als meerdere identieke ERDDAP s met een belastingsbalans. Ik heb bewust ontworpen ERDDAP™ goed te werken binnen een federatie van ERDDAP S, wat volgens mij vele voordelen heeft. Met name een federatie van ERDDAP s is perfect afgestemd op het gedecentraliseerde, gedistribueerde systeem van datacenters dat we hebben in de echte wereld (Denk aan de verschillende IOOS regio's, of de verschillende CoastWatch regio's, of de verschillende delen van NCII, of de 100 andere datacenters in NOAA , of de verschillende NASA DAACs, of de 1000's van datacenters over de hele wereld) . In plaats van alle datacenters van de wereld te vertellen dat ze hun inspanningen moeten opgeven en al hun gegevens in een gecentraliseerd "datameer" moeten stoppen (Zelfs als het mogelijk was, is het een verschrikkelijk idee om tal van redenen -- zie de verschillende analyses die de talrijke voordelen van gedecentraliseerde systemen ) , ERDDAP Het ontwerp werkt met de wereld zoals het is. Elk datacenter dat gegevens produceert, kan doorgaan met onderhouden, curatoren en hun gegevens bedienen. (zoals ze zouden moeten) , en toch, ERDDAP™ , de gegevens kunnen ook direct beschikbaar zijn vanuit een gecentraliseerd ERDDAP , zonder dat de gegevens aan de gecentraliseerde ERDDAP™ hetzij een kopie van de gegevens opslaan. Inderdaad, een gegeven dataset kan tegelijkertijd beschikbaar zijn van een ERDDAP™ bij de organisatie die de gegevens heeft geproduceerd en opgeslagen (bv. GoMOOS) , van een ERDDAP™ bij de moederorganisatie (b.v. IOOS centraal) , Van een all- NOAA ERDDAP™ , van een federale regering van de VS ERDDAP™ , van een globale ERDDAP™ (GOOS) , en van gespecialiseerd ERDDAP s (bv. een ERDDAP™ aan een instelling voor HAB-onderzoek) , alle in wezen onmiddellijk, en efficiënt omdat alleen de metagegevens wordt overgedragen tussen ERDDAP s, niet de gegevens. Het beste van alles, na de eerste ERDDAP™ bij de organisatie van oorsprong, alle andere ERDDAP s kunnen snel ingesteld worden (een paar uur werken) , met minimale middelen (een server die geen RAID's nodig heeft voor gegevensopslag omdat het geen gegevens lokaal opslaat) , en dus tegen werkelijk minimale kosten. Vergelijk dat met de kosten van het opzetten en onderhouden van een gecentraliseerd datacenter met een data meer en de behoefte aan een echt enorme, echt dure, internetverbinding, plus het bijbehorende probleem van het centrale datacenter is een enkel punt van mislukking. Voor mij, ERDDAP De gedecentraliseerde, gefedereerde aanpak is veel beter.
In situaties waarin een gegeven datacenter meerdere ERDDAP s om aan de hoge vraag te voldoen; ERDDAP Het ontwerp is volledig in staat de prestaties van het meervoudige-identieke- ERDDAP S-with-a-load-balancer benadering. Je hebt altijd de mogelijkheid om op te zetten meervoudige samenstelling ERDDAP s (zoals hieronder besproken) , die elk al hun gegevens van andere ERDDAP s, zonder belastingsbalancering. In dit geval raad ik u aan om een punt te maken van elk van de composieten ERDDAP s een andere naam / identiteit en indien mogelijk in verschillende delen van de wereld (Bijvoorbeeld verschillende AWS-regio's) , bijvoorbeeld, ERD Oost, ERD West, ERD O_IE, ERD \_FR, ERD \_IT, zodat gebruikers bewust, herhaaldelijk, werken met een specifieke ERDDAP , met het toegevoegde voordeel dat u het risico hebt verwijderd van een enkel punt van mislukking.
Rasters, Clusters en Federaties
Onder zeer zwaar gebruik, een enkele standalone ERDDAP™ zal een of meer van de beperkingen De hierboven genoemde en zelfs voorgestelde oplossingen zullen onvoldoende zijn. Voor dergelijke situaties, ERDDAP™ heeft functies die het gemakkelijk maken om schaalbare roosters te bouwen (ook clusters of federaties genoemd) van ERDDAP s waarmee het systeem zeer zwaar kan omgaan (bv. voor een groot datacenter) .
Ik gebruik raster als algemene aanduiding van een type computercluster wanneer alle onderdelen al dan niet fysiek in één installatie zijn gevestigd en al dan niet centraal worden beheerd. Een voordeel van gemeenschappelijke, centraal beheerde en beheerde netwerken (clusters) is dat zij profiteren van schaalvoordelen (vooral de menselijke werklast) en vereenvoudigen om de delen van het systeem goed samen te laten werken. Een voordeel van niet-gecolocatieerde netten, niet-centraal eigendom en beheerd (federaties) is dat zij de menselijke werklast en de kosten verdelen en een extra fouttolerantie kunnen bieden. De oplossing die ik hieronder voorstel werkt goed voor alle raster, cluster, en federatie topografische.
Het basisidee om een schaalbaar systeem te ontwerpen is om de potentiële knelpunten te identificeren en vervolgens het systeem zo te ontwerpen dat delen van het systeem kunnen worden nagebootst als nodig is om de knelpunten te verlichten. Idealiter verhoogt elk gekopieerd deel de capaciteit van dat deel van het systeem lineair (efficiëntie van schalen) . Het systeem is niet schaalbaar tenzij er een schaalbare oplossing is voor elke bottleneck. Schaalbaarheid verschilt van efficiëntie (hoe snel een taak kan worden uitgevoerd • efficiëntie van de onderdelen) . Schaalbaarheid stelt het systeem in staat om met elk niveau van vraag om te gaan. Efficiëntie (van schalen en van delen) bepaalt hoeveel servers etc. nodig zijn om aan een bepaalde vraag te voldoen. Efficiëntie is heel belangrijk, maar heeft altijd grenzen. Schaalbaarheid is de enige praktische oplossing voor het bouwen van een systeem dat zeer zwaar gebruik. Idealiter zal het systeem schaalbaar en efficiënt zijn.
Doelstellingen
De doelstellingen van dit ontwerp zijn:
- Een schaalbare architectuur maken (een die gemakkelijk uitbreidbaar is door het repliceren van een deel dat overbelast raakt) . Een efficiënt systeem maken dat de beschikbaarheid en doorvoer van de gegevens maximaliseert gezien de beschikbare computerbronnen. (Kosten zijn bijna altijd een probleem.)
- Om de mogelijkheden van de delen van het systeem in evenwicht te brengen zodat het ene deel van het systeem geen ander deel overweldigt.
- Een eenvoudige architectuur te maken zodat het systeem eenvoudig te installeren en beheren is.
- Om een architectuur te maken die goed werkt met alle rastertopografieën.
- Om een systeem te maken dat sierlijk en op een beperkte manier faalt als een deel overbelast raakt. (De tijd die nodig is om een grote datasets te kopiëren, beperkt altijd het vermogen van het systeem om te gaan met plotselinge stijgingen van de vraag naar een specifieke dataset.)
- (Indien mogelijk) Om een architectuur te maken die niet gebonden is aan specifieke cloud computing diensten of andere externe diensten (Omdat het ze niet nodig heeft.) .
Aanbevelingen
Onze aanbevelingen zijn
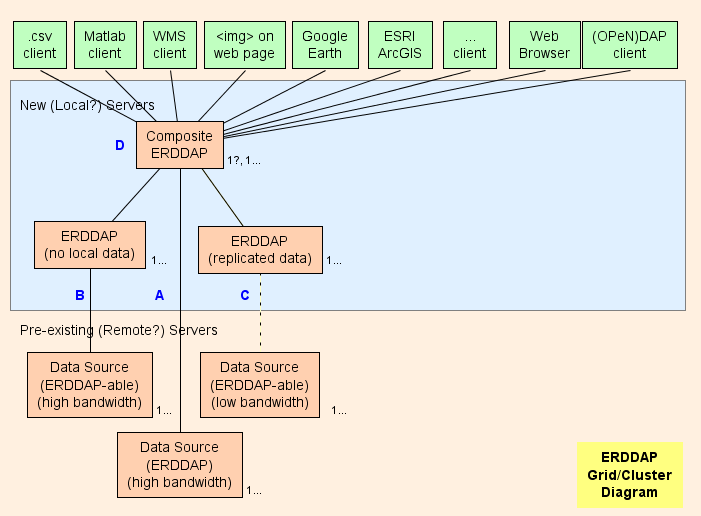
- Ik stel voor om een composite op te zetten. ERDDAP™ ( D in het diagram) , dat is een regelmatige ERDDAP™ behalve dat het alleen gegevens van andere ERDDAP s. De architectuur van het raster is ontworpen om zoveel mogelijk werk te verschuiven (CPU-gebruik, geheugengebruik, bandbreedtegebruik) van de samenstelling ERDDAP™ aan de andere ERDDAP s.
- ERDDAP™ twee speciale datasets heeft, EDDGrid VanErdap en EDDtabelVanErdap , die betrekking hebben op datasets op andere ERDDAP s.
- Wanneer de samenstelling ERDDAP™ ontvangt een verzoek om gegevens of afbeeldingen uit deze datasets, de samenstelling ERDDAP™ omleidingen het verzoek om gegevens aan de andere ERDDAP™ server. Het resultaat is:
- Dit is erg efficiënt. (CPU, geheugen en bandbreedte) , omdat anders
- De samenstelling ERDDAP™ moet het gegevensverzoek naar de andere ERDDAP .
- De andere ERDDAP™ moet de gegevens te krijgen, opnieuw te formatteren, en de gegevens te verzenden naar de samenstelling ERDDAP .
- De samenstelling ERDDAP™ moet de gegevens ontvangen (met extra bandbreedte) , herformatteren (met extra CPU tijd en geheugen) , en verzend de gegevens naar de gebruiker (met extra bandbreedte) . Door het omleiden van de gegevens verzoek en het toestaan van de andere ERDDAP™ om het antwoord direct naar de gebruiker te sturen, de composiet ERDDAP™ besteedt in wezen geen CPU tijd, geheugen, of bandbreedte aan gegevensverzoeken.
- De omleiding is transparant naar de gebruiker, ongeacht de client software (een browser of een andere software of command line tool) .
- Dit is erg efficiënt. (CPU, geheugen en bandbreedte) , omdat anders
Rasteronderdelen
A : Voor elke externe databron met een hoge bandbreedte OPeNDAP server, u kunt rechtstreeks verbinding maken met de externe server. Als de externe server een ERDDAP™ Gebruik EDDGrid FromErdap of EDDtableVan ERDDAP om de gegevens in de samenstelling te dienen ERDDAP . Als de externe server een ander type is DAP server, bv. THredDS, Hyrax Gebruik EDDGrid Van Dap.
B : Voor elke ERDDAP -able data source (een gegevensbron waaruit ERDDAP kan data lezen) die een high-bandwidth server heeft, een andere server instellen ERDDAP™ in het net dat verantwoordelijk is voor het bedienen van de gegevens van deze gegevensbron.
- Indien verscheidene ERDDAP s krijgen niet veel verzoeken voor gegevens, kunt u ze consolideren in een ERDDAP .
- Indien de ERDDAP™ gewijd aan het verkrijgen van gegevens van een externe bron krijgt te veel verzoeken, is er een verleiding om extra toe te voegen ERDDAP s om toegang te krijgen tot de externe gegevensbron. In speciale gevallen kan dit zinvol zijn, maar het is waarschijnlijker dat dit de externe databron zal overweldigen (Dat is zelfvernietigend.) en ook voorkomen dat andere gebruikers toegang krijgen tot de externe gegevensbron (Wat niet leuk is.) . In een dergelijk geval, overwegen ERDDAP™ om die ene dataset te gebruiken en de dataset daarop te kopiëren ERDDAP 's harde schijf (zie C ) , met EDDGrid Kopiëren en/of EDDtabelkopie .
- B servers moeten openbaar toegankelijk zijn.
C : Voor elke ERDDAP -able data source met een server met lage bandbreedte (of een langzame dienst is om andere redenen) , overwegen een andere ERDDAP™ en een kopie van de dataset op te slaan ERDDAP 's harde schijven, misschien met EDDGrid Kopiëren en/of EDDtabelkopie . Indien verscheidene ERDDAP s krijgen niet veel verzoeken voor gegevens, kunt u ze consolideren in een ERDDAP . C servers moeten openbaar toegankelijk zijn.
Samengesteld ERDDAP
D : De samenstelling ERDDAP™ is regelmatig ERDDAP™ behalve dat het alleen gegevens van andere ERDDAP s.
- Omdat de samenstelling ERDDAP™ heeft informatie in het geheugen over alle datasets, het kan snel reageren op verzoeken voor lijsten van datasets (zoekopdrachten in volledige tekst, zoekopdrachten in categorie, de lijst van alle datasets) , en verzoeken om een individuele dataset Data Access Form, Make A Graph formulier, of WMS info pagina. Dit zijn allemaal kleine, dynamisch gegenereerde, HTML-pagina's gebaseerd op informatie die in het geheugen wordt gehouden. De reacties zijn dus zeer snel.
- Omdat verzoeken om feitelijke gegevens snel worden doorgestuurd naar de andere ERDDAP s, de samenstelling ERDDAP™ kan snel reageren op verzoeken om feitelijke gegevens zonder gebruik te maken van CPU tijd, geheugen, of bandbreedte.
- Door zoveel mogelijk werk te verschuiven (CPU, geheugen, bandbreedte) van de samenstelling ERDDAP™ aan de andere ERDDAP s, de samenstelling ERDDAP™ kan lijken gegevens uit alle datasets te dienen en toch bij te houden met zeer grote aantallen gegevensverzoeken van een groot aantal gebruikers.
- Voorlopige tests geven aan dat de samenstelling ERDDAP™ kan reageren op de meeste verzoeken in ~1ms van CPU tijd, of 1000 verzoeken / seconde. Een 8 core processor moet dus ongeveer 8000 verzoeken/seconden kunnen beantwoorden. Hoewel het mogelijk is om te zien uitbarstingen van hogere activiteit die vertragingen zou veroorzaken, dat is veel doorvoer. Het is waarschijnlijk dat de bandbreedte van het datacenter de bottleneck lang voor de composiet zal zijn ERDDAP™ wordt het knelpunt.
max. up-to-date (tijd) ?
De EDDGrid /TableFromErdap in de compositie ERDDAP™ verandert alleen de opgeslagen informatie over elke brondataset wanneer de brondataset "herladen"ed en een stukje metadata verandert (bv. de tijdvariabele actual\_range ) , waardoor het genereren van een abonnement kennisgeving. Als de bronset gegevens heeft die vaak veranderen (bijvoorbeeld, nieuwe data elke seconde) en gebruikt de "Bijwerken" systeem om frequente wijzigingen in de onderliggende gegevens op te merken, de EDDGrid /TableFromErdap zal niet worden geïnformeerd over deze frequente wijzigingen tot de volgende dataset "herladen," zodat de EDDGrid /TableFromErdap zal niet perfect up-to-date zijn. U kunt dit probleem minimaliseren door het wijzigen van de brondataset's<herladenEveryNMinutes> naar een kleinere waarde (60?) zodat er meer abonnementsnotificaties zijn om de EDDGrid /TableFromErdap om de informatie over de bronset bij te werken.
Of, als uw data management systeem weet wanneer de bron dataset nieuwe gegevens heeft (b.v. via een script dat een gegevensbestand op zijn plaats kopieert) , en als dat niet super frequent is (b.v. elke 5 minuten, of minder frequent) Er is een betere oplossing:
- Niet gebruiken<updateEveryNMillis> om de bronset up-to-date te houden.
- De brondataset instellen<herladenEveryNMinutes> naar een groter getal (1440?) .
- Laat het script contact opnemen met de brondataset vlag URL Direct nadat het kopieert een nieuw gegevensbestand op zijn plaats. Dat zal ertoe leiden dat de brondataset perfect up-to-date is en ervoor zorgt dat het een abonnementsmelding genereert, die naar de EDDGrid /TableFromErdap dataset. Dat zal leiden tot de EDDGrid /TableFromErdap dataset perfect up-to-date (Nou ja, binnen 5 seconden na toevoeging van nieuwe gegevens) . En dat alles zal efficiënt gebeuren. (zonder onnodige datasetherladen) .
Meervoudige samenstelling ERDDAP s
- In zeer extreme gevallen, of voor fouttolerantie, kunt u meer dan één composiet instellen ERDDAP . Het is waarschijnlijk dat andere delen van het systeem (met name de bandbreedte van het datacenter) zal een probleem worden lang voordat de samenstelling ERDDAP™ wordt een knelpunt. Dus de oplossing is waarschijnlijk om extra, geografisch diverse datacenters op te zetten (spiegels) , elk met één composiet ERDDAP™ en servers met ERDDAP s en (ten minste) spiegel kopieën van de datasets die in hoge vraag. Een dergelijke setup biedt ook fouttolerantie en data back-up (via kopiëren) . In dit geval is het het beste als de samenstelling ERDDAP s hebben verschillende URL's.
Als je echt alle compositie wilt ERDDAP s om dezelfde URL te hebben, gebruik een frontend systeem dat een gegeven gebruiker toewijst aan slechts één van de composite ERDDAP s (gebaseerd op het IP-adres) , zodat alle verzoeken van de gebruiker gaan naar slechts een van de composiet ERDDAP s. Er zijn twee redenen:
- Wanneer een onderliggende dataset wordt herladen en de metagegevens verandert (Bijvoorbeeld, een nieuw gegevensbestand in een gerasterde dataset veroorzaakt de tijdvariabele actual\_range wijzigen) , de samenstelling ERDDAP s zal tijdelijk iets uit de synchronisatie, maar met uiteindelijke consistentie . Normaal gesproken zullen ze binnen 5 seconden opnieuw synchroniseren, maar soms zal het langer duren. Als een gebruiker een geautomatiseerd systeem maakt dat afhankelijk is van ERDDAP™ abonnementen De korte synchroniciteitsproblemen zullen significant worden.
- De 2+ composiet ERDDAP e elk hun eigen reeks abonnementen behouden (vanwege het hierboven beschreven synchronisatieprobleem) .
Dus een gegeven gebruiker moet worden gericht op slechts een van de composiet ERDDAP Om deze problemen te voorkomen. Als één van de composieten ERDDAP s gaat naar beneden, het front end systeem kan omleiden dat ERDDAP 's gebruikers naar een andere ERDDAP™ Dat is boven. Als het echter een capaciteitsprobleem is dat de eerste samengestelde ERDDAP™ om te falen (Een overijverige gebruiker? a denial-of-service aanval ?) , dit maakt het zeer waarschijnlijk dat het omleiden van de gebruikers naar andere composiet ERDDAP er cascading-fout . Dus, de meest robuuste setup is om composiet ERDDAP s met verschillende URL's.
Of, misschien beter, meerdere samenstellingen instellen ERDDAP s zonder belastingsbalancering. In dit geval moet u een punt van geven elk van de ERDDAP s een andere naam / identiteit en indien mogelijk in verschillende delen van de wereld (Bijvoorbeeld verschillende AWS-regio's) , bijvoorbeeld, ERD Oost, ERD West, ERD O_IE, ERD \_FR, ERD \_IT, zodat gebruikers bewust, herhaaldelijk werken met een specifieke ERDDAP .
- \[ Voor een fascinerend ontwerp van een systeem met hoge prestaties op één server, zie dit gedetailleerde beschrijving van Mailinator . \]
Datasets in zeer hoge vraag
In het echt ongebruikelijke geval dat een van de A , B , of C ERDDAP s kan de verzoeken niet bijhouden vanwege bandbreedte of beperkingen op de harde schijf, het is zinvol om de gegevens te kopiëren (opnieuw) naar een andere server+hard Drive+ ERDDAP , met EDDGrid Kopiëren en/of EDDtabelkopie . Hoewel het misschien ideaal lijkt om de originele dataset te hebben en de gekopieerde dataset naadloos lijkt als één dataset in de composiet ERDDAP™ , dit is moeilijk omdat de twee datasets in iets verschillende toestanden zullen zijn op verschillende tijdstippen (met name, nadat het origineel krijgt nieuwe gegevens, maar voordat de gekopieerde dataset krijgt zijn kopie) . Daarom raad ik aan om de datasets iets verschillende titels te geven (b.v. (kopie #1) En... (kopie #2) " of misschien " (spiegel # n ) " of " (server # n ) ") en verschijnen als aparte datasets in de samenstelling ERDDAP . Gebruikers worden gebruikt om lijsten van spiegelplaatsen bij populaire file download sites, dus dit moet niet verbazen of teleurstellen hen. Vanwege bandbreedte beperkingen op een bepaalde site, kan het zinvol zijn om de spiegel op een andere site. Als de spiegelkopie in een ander datacenter is, alleen toegankelijk door de samenstelling van dat datacenter ERDDAP™ , de verschillende titels (b.v., "mirror #1) Dat is niet nodig.
RAID's versus reguliere harde schijven
Als een grote dataset of een groep datasets niet zwaar worden gebruikt, kan het zinvol zijn om de gegevens op een RAID op te slaan, omdat het fouttolerantie biedt en omdat je de verwerkingskracht of bandbreedte van een andere server niet nodig hebt. Maar als een dataset zwaar wordt gebruikt, kan het logischer zijn om de gegevens op een andere server te kopiëren + ERDDAP™ + harde schijf (vergelijkbaar met wat Google doet ) in plaats van één server en een RAID te gebruiken om meerdere datasets op te slaan, omdat je beide server+hardDrive+ mag gebruiken ERDDAP S in het raster totdat een van hen faalt.
Mislukt
Wat als...
- Er is een uitbarsting van verzoeken voor één dataset (b.v. alle studenten in een klas tegelijkertijd soortgelijke gegevens aanvragen) ? Alleen de ERDDAP™ die die dataset zal worden overweldigd en vertragen of weigeren verzoeken. De samenstelling ERDDAP™ en andere ERDDAP Het zal niet beïnvloed worden. Aangezien de beperkende factor voor een bepaalde dataset binnen het systeem is de harde schijf met de gegevens (niet ERDDAP ) , de enige oplossing (niet onmiddellijk) is om een kopie te maken van de dataset op een andere server+hardDrive+ ERDDAP .
- Een A , B , of C ERDDAP™ mislukt (bv. harde schijffalen) ? Alleen de dataset (s) door die ERDDAP™ zijn aangetast. Als de dataset (s) wordt gespiegeld op een andere server+hardDrive+ ERDDAP , het effect is minimaal. Als het probleem is een harde schijf defect in een niveau 5 of 6 RAID, je gewoon vervangen van de schijf en laat de RAID opnieuw de gegevens op de schijf.
- De samenstelling ERDDAP™ Mislukt? Als u een systeem wilt maken met zeer hoge beschikbaarheid , kunt u opzetten meervoudige samenstelling ERDDAP s (zoals hierboven besproken) , met behulp van iets als NGINX of Traefik om het balanceren van de lading te verwerken. Merk op dat een bepaalde samenstelling ERDDAP™ kan omgaan met een zeer groot aantal verzoeken van een groot aantal gebruikers, omdat verzoeken om metagegevens zijn klein en worden behandeld door informatie in het geheugen, en verzoeken om gegevens (die groot kunnen zijn) worden doorgestuurd naar het kind ERDDAP s.
Eenvoudig, schaalbaar
Dit systeem is eenvoudig op te zetten en te beheren, en gemakkelijk uitbreidbaar wanneer een deel ervan overbelast raakt. De enige echte beperkingen voor een gegeven datacenter zijn de bandbreedte van het datacenter en de kosten van het systeem.
Bandbreedte
Let op de geschatte bandbreedte van veelgebruikte componenten van het systeem:
| Onderdeel | Geschatte bandbreedte (GBytes/s) |
|---|---|
| DDR-geheugen | 2,5 |
| SSD-station | 1 |
| SATA harde schijf | 0,3 |
| Gigabit ethernet | 0,1 |
| OC-12 | 0,06 |
| OC-3 | 0,015 |
| T1 | 0,0002 |
Dus, een SATA harde schijf (0,3 GB/s) op één server met één ERDDAP™ kan waarschijnlijk een Gigabit Ethernet LAN verzadigen (0,1 GB/s) . En een Gigabit Ethernet LAN (0,1 GB/s) kan waarschijnlijk een OC-12 internetverbinding verzadigen (0,06 GB/s) . En minstens één bron bevat OC-12 lijnen die ongeveer $100.000 per maand kosten. (Ja, deze berekeningen zijn gebaseerd op het duwen van het systeem tot zijn grenzen, wat niet goed is omdat het leidt tot zeer trage reacties. Maar deze berekeningen zijn nuttig voor planning en voor het balanceren van delen van het systeem.) Duidelijk, een passende snelle internetverbinding voor uw datacenter is veruit het duurste deel van het systeem. U kunt eenvoudig en relatief goedkoop een raster bouwen met een dozijn servers met een dozijn ERDDAP s die in staat is om veel gegevens snel uit te pompen, maar een passende snelle internetverbinding zal zeer, zeer duur zijn. De gedeeltelijke oplossingen zijn:
- Moedig cliënten aan om deelgroepen van de gegevens aan te vragen als dat alles is wat nodig is. Als de klant alleen gegevens nodig heeft voor een kleine regio of bij een lagere resolutie, dan is dat wat ze zouden moeten vragen. Subsetting is een centrale focus van de protocollen ERDDAP™ ondersteuning voor het aanvragen van gegevens.
- Stimuleer het verzenden van gecomprimeerde gegevens. ERDDAP™ kompres een gegevensoverdracht indien zij in de HTTP GET Vraag header. Alle webbrowsers gebruiken "accept-encoding" en decomprimeren automatisch het antwoord. Overige cliënten (bv. computerprogramma's) moeten het expliciet gebruiken.
- Colocate uw servers op een ISP of andere site die relatief minder dure bandbreedte kosten.
- Verdeel de servers met de ERDDAP De kosten worden verdeeld over de verschillende instellingen. U kunt dan uw compositie koppelen ERDDAP™ aan hun ERDDAP s.
Merk op dat Cloud Computing en webhosting diensten bieden alle Internet bandbreedte die je nodig hebt, maar los het prijsprobleem niet op.
Voor algemene informatie over het ontwerpen van schaalbare, hoge capaciteit, fouttolerante systemen, zie Michael T. Nygards boek Laat het los .
Net als Lego's
Software ontwerpers proberen vaak om goed te gebruiken software ontwerp patronen problemen op te lossen. Goede patronen zijn goed omdat ze goed inkapselen, gemakkelijk te creëren en werken met algemene oplossingen die leiden tot systemen met goede eigenschappen. Patroon namen zijn niet gestandaardiseerd, dus ik noem het patroon dat ERDDAP™ gebruikt het Legopatroon. Elke Lego (elk ERDDAP ) is een eenvoudige, kleine, standaard, stand-alone, baksteen (dataserver) met een gedefinieerde interface waarmee het kan worden gekoppeld aan andere legos ( ERDDAP s) . De onderdelen van ERDDAP™ die deel uitmaken van dit systeem zijn: de abonnement en flagURL systemen (die communicatie mogelijk maakt tussen ERDDAP s) De EDD... Van Erddap redirect systeem, en het systeem van RESTful verzoeken om gegevens die door gebruikers of andere ERDDAP s. Dus, gegeven twee of meer legos ( ERDDAP s) , kunt u een groot aantal verschillende vormen (netwerktopologieën van ERDDAP s) . Natuurlijk, het ontwerp en de kenmerken van ERDDAP™ Het had anders gekund, niet Lego-achtig, misschien alleen om één specifieke topologie in te schakelen en te optimaliseren. Maar we voelen dat ERDDAP 's Lego-achtige ontwerp biedt een goede, algemene oplossing die ERDDAP™ beheerder (of groep beheerders) allerlei soorten federatietopologieën te creëren. Een enkele organisatie zou bijvoorbeeld drie (of meer) ERDDAP s zoals aangegeven in de ERDDAP™ Raster/Clusterdiagram hierboven . Of een gedistribueerde groep (IOOS? Kustwacht? NCII? NWS? NOAA ? USGS? Dataone? NEON? LTER? Ooi? BDC? ONC? JRC? WMO?) kan een instellen ERDDAP™ in elke kleine buitenpost (zodat de gegevens dicht bij de bron kunnen blijven) en dan een composiet opzetten ERDDAP™ in het centrale kantoor met virtuele datasets (die altijd perfect up-to-date zijn) van elk van de kleine buitenpost ERDDAP s. Inderdaad, alle van de ERDDAP s, geïnstalleerd bij verschillende instellingen over de hele wereld, die gegevens van andere ERDDAP s en/of andere gegevens verstrekken ERDDAP s, vormen een reusachtig netwerk van ERDDAP s. Hoe cool is dat?! Net als bij Lego zijn de mogelijkheden eindeloos. Daarom is dit een goed patroon. Daarom is dit een goed ontwerp voor ERDDAP .
Verschillende soorten verzoeken
Een van de echte complicaties van deze discussie van dataserver topologieën is dat er verschillende soorten verzoeken en verschillende manieren om te optimaliseren voor de verschillende soorten verzoeken. Dit is meestal een aparte kwestie (Hoe snel kan de ERDDAP™ met de gegevens reageren op het verzoek om gegevens?) van de topologie discussie (die betrekking heeft op de relaties tussen dataservers en welke server de werkelijke gegevens heeft) . ERDDAP™ , natuurlijk, probeert om te gaan met alle soorten verzoeken efficiënt, maar behandelt sommige beter dan anderen.
- Veel verzoeken zijn eenvoudig. Bijvoorbeeld: Wat zijn de metagegevens voor deze dataset? Of: Wat zijn de waarden van de tijddimensie voor deze gerasterde dataset? ERDDAP™ is ontworpen om deze zo snel mogelijk te behandelen (meestal in<=2 ms) door deze informatie in het geheugen te houden.
- Sommige verzoeken zijn matig moeilijk. Bijvoorbeeld: Geef me deze subset van een dataset (die zich in één gegevensbestand bevindt) . Deze verzoeken kunnen relatief snel worden behandeld omdat ze niet zo moeilijk zijn.
- Sommige verzoeken zijn moeilijk en dus tijdrovend. Bijvoorbeeld: Geef me deze subset van een dataset (die in een van de 10.000+ gegevensbestanden kunnen zijn, of van gecomprimeerde gegevensbestanden die elk 10 seconden duren om te decomprimeren) . ERDDAP™ v2.0 introduceerde een aantal nieuwe, snellere manieren om met deze verzoeken om te gaan, met name door het toestaan van de verzoek-behandeling draad te paaien verschillende werknemers draden die verschillende subgroepen van het verzoek aanpakken. Maar er is een andere benadering van dit probleem die ERDDAP™ ondersteunt nog niet: subsets van de gegevensbestanden voor een gegeven dataset kunnen worden opgeslagen en geanalyseerd op afzonderlijke computers, en vervolgens de resultaten gecombineerd op de oorspronkelijke server. Deze benadering heet Kaartverminderen en wordt geïllustreerd door Hadoop , de eerste (?) open-source MapReduce-programma, dat gebaseerd was op ideeën uit een Google-document. (Als u MapReduce nodig heeft in ERDDAP , stuur een e-mail verzoek naar erd.data at noaa.gov .) Googles BigQuery is interessant omdat het lijkt te zijn een implementatie van MapReduce toegepast op subsetting tabel datasets, dat is een van ERDDAP De belangrijkste doelen. Het is waarschijnlijk dat u een ERDDAP™ dataset van een BigQuery dataset via EDDTableFromDatabase omdat BigQuery toegankelijk is via een JDBC interface.
Dit zijn mijn meningen.
Ja, de berekeningen zijn simplistisch (en nu enigszins gedateerd) , maar ik denk dat de conclusies juist zijn. Heb ik verkeerde logica gebruikt of een fout gemaakt in mijn berekeningen? Zo ja, dan is de schuld alleen aan mij. Stuur een e-mail met de correctie naar erd dot data at noaa dot gov .
Cloud Computing
Verschillende bedrijven bieden cloud computing diensten (bv. Amazon Web Services en Google Cloud Platform ) . Webhostingbedrijven sinds het midden van de jaren negentig eenvoudiger diensten hebben aangeboden, maar de "cloud"-diensten hebben de flexibiliteit van de systemen en het aanbod van diensten aanzienlijk vergroot. Sinds de ERDDAP™ raster bestaat enkel uit ERDDAP s en sinds ERDDAP er Java webapplicaties die kunnen draaien in Tomcat (de meest voorkomende toepassingsserver) of andere applicatieservers, het moet relatief gemakkelijk zijn om een ERDDAP™ raster op een cloudservice of webhosting site. De voordelen van deze diensten zijn:
- Ze bieden toegang tot zeer hoge bandbreedte internetverbindingen. Alleen al dit kan het gebruik van deze diensten rechtvaardigen.
- Ze rekenen alleen voor de diensten die u gebruikt. U krijgt bijvoorbeeld toegang tot een zeer hoge bandbreedte internetverbinding, maar u betaalt alleen voor daadwerkelijk overgedragen gegevens. Dat laat je een systeem bouwen dat zelden overweldigd wordt (zelfs bij piekvraag) , zonder te hoeven betalen voor capaciteit die zelden wordt gebruikt.
- Ze zijn gemakkelijk uitbreidbaar. Je kunt in minder dan een minuut van servertype veranderen of zoveel servers toevoegen als je wilt. Alleen al dit kan het gebruik van deze diensten rechtvaardigen.
- Ze bevrijden u van vele administratieve taken van het draaien van de servers en netwerken. Alleen al dit kan het gebruik van deze diensten rechtvaardigen.
De nadelen van deze diensten zijn:
- Ze rekenen voor hun diensten, soms veel (in absolute termen; niet dat het geen goede waarde is) . De hier vermelde prijzen zijn voor Amazon EC2 . Deze prijzen (Vanaf juni 2015) zal naar beneden komen.
In het verleden waren de prijzen hoger, maar de gegevensbestanden en het aantal verzoeken waren kleiner.
In de toekomst zullen de prijzen lager zijn, maar de gegevensbestanden en het aantal verzoeken zullen groter zijn.
Dus de details veranderen, maar de situatie blijft relatief constant.
En het is niet dat de service te duur is, het is dat we veel van de service gebruiken en kopen.
- Gegevensoverdracht (Ja!) . Gegevensoverdrachten uit het systeem zijn $0,09/GB. Eén SATA harde schijf (0,3 GB/s) op één server met één ERDDAP™ kan waarschijnlijk een Gigabit Ethernet LAN verzadigen (0,1 GB/s) . Een Gigabit Ethernet LAN (0,1 GB/s) kan waarschijnlijk een OC-12 internetverbinding verzadigen (0,06 GB/s) . Als één OC-12-verbinding ~150.000 GB/maand kan verzenden, kunnen de kosten voor gegevensoverdracht oplopen tot 150.000 GB @ $0.09/GB = $13.500/maand, wat een aanzienlijke kostenpost is. Duidelijk, als je een dozijn hardwerkende ERDDAP s op een cloudservice, uw maandelijkse Data Transfer kosten kunnen aanzienlijk zijn (tot $ 162.000/maand) . (Nogmaals, het is niet dat de service te duur is, het is dat we veel van de service gebruiken en kopen.)
- Gegevensopslag (Vergelijk dat aan het kopen van een 4TB enterprise drive regelrecht voor ~ $50/TB, hoewel de RAID om het te zetten in en administratieve kosten bijdragen aan de totale kosten.) Dus als u nodig hebt om veel gegevens op te slaan in de cloud, kan het vrij duur (Bijvoorbeeld, 100 TB zou $5000/maand kosten) . Maar tenzij je een echt grote hoeveelheid gegevens, dit is een kleiner probleem dan de bandbreedte / gegevensoverdracht kosten. (Nogmaals, het is niet dat de service te duur is, het is dat we veel van de service gebruiken en kopen.)
Onderverdeling
- Het subsetprobleem: De enige manier om gegevens efficiënt te verspreiden van gegevensbestanden is om het programma dat is het verspreiden van de gegevens (bv. ERDDAP ) draait op een server die de gegevens heeft opgeslagen op een lokale harde schijf (of even snel toegang tot een SAN of lokale RAID) . Lokale bestandssystemen toestaan ERDDAP™ (en onderliggende bibliotheken, zoals netcdf-java) om specifieke byte te vragen varieert van de bestanden en krijg reacties zeer snel. Vele soorten verzoeken om gegevens van ERDDAP™ naar het bestand (met name gerasterde gegevensverzoeken waarbij de stapwaarde > is 1) kan niet efficiënt worden gedaan als het programma moet het hele bestand of grote brokken van een bestand uit een niet-locale aanvragen (dus langzamer) gegevensopslagsysteem en vervolgens een subset uitpakken. Als de cloud instelling niet geeft ERDDAP™ snelle toegang tot bytebereiken van de bestanden (zo snel als met lokale bestanden) , ERDDAP 's toegang tot de gegevens zal een ernstige bottleneck en andere voordelen van het gebruik van een cloud service te ontkennen.
Gehoste gegevens
Een alternatief voor de bovenstaande kosten-batenanalyse (die is gebaseerd op de gegevenseigenaar (bv. NOAA ) betalen voor de opslag van hun gegevens in de cloud) Amazon kwam rond 2012, toen Amazon (en in mindere mate, sommige andere cloudproviders) begon met het hosten van een aantal datasets in hun cloud (AWS S3) gratis (vermoedelijk met de hoop dat ze hun kosten zouden kunnen herstellen als gebruikers AWS EC2 berekenen instanties om te werken met die gegevens) . Het is duidelijk dat dit cloud computing veel goedkoper maakt, omdat de tijd en kosten om de data te uploaden en hosting nu nul zijn. Met ERDDAP™ v2.0, er zijn nieuwe functies om het uitvoeren te vergemakkelijken ERDDAP in een wolk:
- Nu, een EDDGrid FromFiles of EDDTableFromFiles dataset kan worden gemaakt uit gegevensbestanden die op afstand en toegankelijk zijn via internet (bv. AWS S3-emmers) door de<cacheFromUrl> en<cachegrootte GB> opties. ERDDAP™ zal een lokale cache van de meest recent gebruikte gegevensbestanden behouden.
- Nu, als een EDDTableFromFiles bronbestanden zijn gecomprimeerd (bv. .tgz ) , ERDDAP™ zal ze automatisch decomprimeren wanneer het ze leest.
- Nu, de ERDDAP™ draad reageren op een gegeven verzoek zal paaien werknemer threads om te werken op subsecties van het verzoek als u gebruik maakt van de<nTreads> opties. Deze parallelisering moet snellere antwoorden op moeilijke verzoeken mogelijk maken.
Deze veranderingen oplossen het probleem van AWS S3 niet het aanbieden van lokale, blok-niveau bestandsopslag en de (oud) probleem van de toegang tot S3-gegevens met een aanzienlijke vertraging. (Jaren geleden (2014) , die vertraging was aanzienlijk, maar is nu veel korter en dus niet zo significant.) Al met al betekent het dat ERDDAP™ in de cloud werkt nu veel beter.
Bedankt. Veel dank aan Matthew Arrott en zijn groep in de oorspronkelijke OOI inspanning voor hun werk op het zetten ERDDAP™ in de cloud en de daaruit voortvloeiende discussies.
Remote Replication of Datasets
Er is een veel voorkomend probleem dat verband houdt met de bovengenoemde discussie over netwerken en federaties van ERDDAP s: remote replicatie van datasets. Het basisprobleem is: een data provider onderhoudt een dataset die af en toe verandert en een gebruiker wil een up-to-date lokale kopie van deze dataset behouden (om allerlei redenen) . Het is duidelijk dat er een groot aantal variaties zijn. Sommige variaties zijn veel moeilijker te behandelen dan andere.
- Snelle updates Het is moeilijker om de lokale dataset up-to-date te houden onmiddellijk (b.v. binnen 3 seconden) na elke verandering aan de bron, in plaats van bijvoorbeeld binnen een paar uur.
- Regelmatige wijzigingen Frequente veranderingen zijn moeilijker te verwerken dan frequente veranderingen. Zo zijn veranderingen eenmaal per dag veel gemakkelijker te verwerken dan veranderingen per 0,1 seconde.
- Kleine wijzigingen Kleine wijzigingen in een bronbestand zijn moeilijker te verwerken dan een geheel nieuw bestand. Dit is vooral waar als de kleine wijzigingen overal in het bestand. Kleine veranderingen zijn moeilijker te detecteren en maken het moeilijk om de gegevens te isoleren die moeten worden gerepliceerd. Nieuwe bestanden zijn gemakkelijk te detecteren en efficiënt over te dragen.
- Volledige dataset Een hele dataset up-to-date houden is moeilijker dan het bijhouden van recente gegevens. Sommige gebruikers hebben alleen recente gegevens nodig (b.v. de laatste 8 dagen) .
- Meerdere exemplaren Het behouden van meerdere remote kopieën op verschillende sites is moeilijker dan het handhaven van een remote kopie. Dit is het schaalprobleem.
Er zijn natuurlijk een groot aantal variaties van mogelijke soorten veranderingen in de bronset en van de behoeften en verwachtingen van de gebruiker. Veel van de variaties zijn zeer moeilijk op te lossen. De beste oplossing voor een situatie is vaak niet de beste oplossing voor een andere situatie.Er is nog geen universele geweldige oplossing.
Relevant ERDDAP™ Hulpmiddelen
ERDDAP™ biedt verschillende tools die kunnen worden gebruikt als onderdeel van een systeem dat een kopie op afstand van een dataset wil behouden:
- ERDDAP 's RSS (Rich Site Samenvatting?) dienst
biedt een snelle manier om te controleren of een dataset op een remote ERDDAP™ is veranderd. - ERDDAP 's abonnementsdienst
is efficiënter (dan RSS ) aanpak: het zal onmiddellijk een e-mail of contact opnemen met een URL naar elke abonnee wanneer de dataset wordt bijgewerkt en de update resulteerde in een verandering. Het is efficiënt omdat het zo snel mogelijk gebeurt en er geen verspilde moeite is (Als met polling an RSS dienst) . Gebruikers kunnen andere hulpmiddelen gebruiken (zoals IFTTT ) om te reageren op de e-mailmeldingen van het abonnementssysteem. Een gebruiker kan zich bijvoorbeeld abonneren op een dataset op een remote ERDDAP™ en gebruik IFTTT om te reageren op de aanmelding e-mail notificaties en trigger updaten van de lokale dataset. - ERDDAP 's vlagsysteem
biedt een manier voor een ERDDAP™ beheerder om een dataset te vertellen over zijn/haar ERDDAP om zo snel mogelijk opnieuw te laden. De URL-vorm van een vlag kan gemakkelijk gebruikt worden in scripts. De URL-vorm van een vlag kan ook gebruikt worden als actie voor een abonnement. - ERDDAP 's "files" systeem
kan toegang bieden tot de bronbestanden voor een bepaalde dataset, inclusief een Apache-stijl directory lijst van de bestanden (een "Web Toegankelijke Map") waarin elk bestand download URL, laatst gewijzigde tijd en grootte heeft. Een nadeel van het gebruik van de "files" systeem is dat de bronbestanden verschillende variabele namen en metadata kunnen hebben dan de dataset zoals deze in ERDDAP . Als een remote ERDDAP™ dataset biedt toegang tot zijn bronbestanden, die de mogelijkheid van een arme-man versie van rsync opent: het wordt gemakkelijk voor een lokaal systeem om te zien welke remote bestanden zijn veranderd en moeten worden gedownload. (Zie cacheVanUrl-optie Hieronder kunnen we hiervan gebruik maken.)
Oplossingen
Hoewel er een groot aantal variaties in het probleem en een oneindig aantal mogelijke oplossingen zijn, zijn er slechts een handjevol fundamentele benaderingen van oplossingen:
Aangepaste, Brute Force-oplossingen
Een voor de hand liggende oplossing is om een aangepaste oplossing te maken, die daarom geoptimaliseerd is voor een bepaalde situatie: maak een systeem dat de gegevens detecteert/identificeert en stuurt die informatie naar de gebruiker zodat de gebruiker de gewijzigde gegevens kan aanvragen. Je kunt dit, maar er zijn nadelen:
- Aangepaste oplossingen zijn veel werk.
- Aangepaste oplossingen worden meestal zo aangepast aan een bepaalde dataset en gegeven gebruikerssysteem dat ze niet gemakkelijk kunnen worden hergebruikt.
- Aangepaste oplossingen moeten door u worden gebouwd en onderhouden. (Dat is nooit een goed idee. Het is altijd een goed idee om werk te vermijden en iemand anders het werk te laten doen!)
Ik ontmoedig deze benadering, omdat het bijna altijd beter is om algemene oplossingen te zoeken, gebouwd en onderhouden door iemand anders, die gemakkelijk kan worden hergebruikt in verschillende situaties.
rsync
rsync is de bestaande, verbluffend goede, algemene oplossing voor het houden van een verzameling bestanden op een broncomputer in sync op de externe computer van een gebruiker. Het werkt zo:
- enkele gebeurtenis (bv. een ERDDAP™ evenement abonnementssysteem) activeert rsync, (of, een cron job draait rsync op specifieke tijden elke dag op de computer van de gebruiker)
- welke contacten rsync op de broncomputer hebben;
- die een reeks hashes berekent voor stukken van elk bestand en deze hashes doorstuurt naar de rsync van de gebruiker,
- die deze informatie vergelijkt met soortgelijke informatie voor de kopie van de bestanden van de gebruiker;
- die dan de stukken van bestanden die zijn veranderd.
Gezien alles wat het doet, rsync werkt zeer snel (b.v. 10 seconden plus dataoverdrachttijd) en zeer efficiënt. Er zijn variaties van rsync die optimaliseren voor verschillende situaties (b.v. door de hashes van elk bronbestand voor te berekenen en te cachen) .
De belangrijkste zwakke punten van rsync zijn: (veiligheidsvraagstukken) ; er zijn een aantal schaalproblemen; en het is niet goed voor het houden van NRT datasets echt up-to-date (Bijvoorbeeld, het is ongemakkelijk om rsync meer dan ongeveer elke 5 minuten te gebruiken) . Als je met de zwakke punten om kunt gaan, of als ze je situatie niet beïnvloeden, is rsync een uitstekende, algemene oplossing die iedereen nu kan gebruiken om veel scenario's op te lossen waarbij datasets op afstand worden herhaald.
Er is een item op de ERDDAP™ Te doen lijst om ondersteuning voor rsync diensten toe te voegen aan ERDDAP (Waarschijnlijk een vrij moeilijke taak.) , zodat elke client rsync kan gebruiken (of een variant) een bijgewerkte kopie van een dataset bijhouden. Als iemand hieraan wil werken, mail dan erd.data at noaa.gov .
Er zijn andere programma's die min of meer doen wat rsync doet, soms gericht op datasetreplicatie (Hoewel vaak op een bestand-kopie niveau) , bijvoorbeeld, Unidata 's IDD .
Cache van Url
De cacheVanUrl instelling is beschikbaar (beginnend met ERDDAP™ v2.0) voor alle ERDDAP 's dataset types die datasets van bestanden maken (In principe, alle subklassen van EDDGrid FromFiles en EDDTableFromFiles ) . cache FromUrl maakt het triviaal om de lokale gegevensbestanden automatisch te downloaden en te onderhouden door ze van een externe bron via de cache te kopiëren FromUrl instelling. De remote bestanden kunnen in een Web Accessible Map of een directory-achtige bestandslijst worden aangeboden door THREDDS, Hyrax , een S3-emmer, of ERDDAP 's "files" systeem.
Als de bron van de remote bestanden een remote is ERDDAP™ dataset die de bronbestanden via de ERDDAP™ "files" systeem, dan kunt u abonneren naar de externe dataset, en gebruik de vlag URL voor uw lokale dataset als actie voor het abonnement. Dan, wanneer de dataset op afstand verandert, zal het contact opnemen met de vlag URL voor uw dataset, die zal vertellen om ASAP te herladen, die de gewijzigde remote gegevensbestanden zal detecteren en downloaden. Dit alles gebeurt heel snel. (meestal ~5 seconden plus de tijd die nodig is om de gewijzigde bestanden te downloaden) . Deze aanpak werkt geweldig als de brongegevensset wijzigingen zijn nieuwe bestanden periodiek worden toegevoegd en wanneer de bestaande bestanden nooit veranderen. Deze aanpak werkt niet goed als gegevens vaak aan alle (of de meeste) van de bestaande brongegevensbestanden, omdat dan uw lokale dataset vaak de gehele dataset op afstand downloadt. (Hier is een rsync-achtige aanpak nodig.)
ArchiefADataset
ERDDAP™ 's ArchiefADataset is een goede oplossing wanneer gegevens vaak aan een dataset worden toegevoegd, maar oudere gegevens worden nooit gewijzigd. In principe, een ERDDAP™ beheerder kan ArchiveADataset draaien (Misschien in een script, misschien gerund door cron) en geef een subset van een dataset die ze willen extraheren (misschien in meerdere bestanden) en verpakking in een .zip of .tgz bestand, zodat u het bestand kunt verzenden naar geïnteresseerde mensen of groepen (bv. NCII voor archivering) of maak het beschikbaar om te downloaden. Bijvoorbeeld, je zou kunnen draaien ArchiveADataset elke dag om 12:10 uur en laat het een .zip van alle gegevens van 12:00 uur de vorige dag tot 12:00 uur vandaag. (Of doe dit wekelijks, maandelijks of jaarlijks, indien nodig.) Omdat het verpakte bestand offline wordt gegenereerd, bestaat er geen gevaar voor een timeout of te veel data, omdat er voor een standaard ERDDAP™ verzoek.
ERDDAP™ 's standaard aanvraagsysteem
ERDDAP™ het standaard aanvraagsysteem is een alternatieve goede oplossing wanneer gegevens vaak aan een dataset worden toegevoegd, maar oudere gegevens worden nooit gewijzigd. In principe kan iedereen standaard verzoeken gebruiken om gegevens te krijgen voor een bepaald tijdsbestek. Bijvoorbeeld, om 12:10 u elke dag, kunt u een verzoek voor alle gegevens van een remote dataset van 12:00 u de vorige dag tot 12:00 u vandaag. De beperking (vergeleken met de ArchiefADataset aanpak) is het risico van een timeout of er te veel gegevens voor een enkel bestand. U kunt de beperking vermijden door vaker verzoeken te doen voor kleinere termijnen.
EDDTableFromHttpGet
\[ Deze optie bestaat nog niet, maar lijkt mogelijk om in de nabije toekomst te bouwen. \]
Het nieuwe EDDTableFromHttpGet datasettype in ERDDAP™ v2.0 maakt het mogelijk om een andere oplossing voor te stellen. De onderliggende bestanden die door dit type dataset worden onderhouden zijn in wezen logbestanden die wijzigingen in de dataset registreren. Het moet mogelijk zijn om een systeem te bouwen dat een lokale dataset bijhoudt door periodiek (of gebaseerd op een trigger) verzoeken om alle wijzigingen die sinds dat laatste verzoek in de dataset op afstand zijn aangebracht. Dat moet even efficiënt zijn. (of meer) dan rsync en zou omgaan met vele moeilijke scenario's, maar zou alleen werken als de remote en lokale datasets zijn EDDTableFromHttpGet datasets.
Als iemand hieraan wil werken, neem dan contact op. erd.data at noaa.gov .
Gedistribueerde gegevens
Geen van de bovenstaande oplossingen doet een groot werk van het oplossen van de harde variaties van het probleem omdat replicatie van bijna real time (NRT) datasets is erg moeilijk, mede door alle mogelijke scenario's.
Er is een geweldige oplossing: probeer zelfs niet om de gegevens te repliceren. Gebruik in plaats daarvan de enige gezaghebbende bron (één dataset op één ERDDAP ) , onderhouden door de dataprovider (bv. een regionaal kantoor) . Alle gebruikers die gegevens van die dataset willen, krijgen het altijd van de bron. Bijvoorbeeld, browser-gebaseerde apps krijgen de gegevens van een URL-verzoek, dus het maakt niet uit dat het verzoek is naar de oorspronkelijke bron op een externe server (niet dezelfde server die het ESM host) . Veel mensen pleiten al lange tijd voor deze Distributed Data benadering (bv. Roy Mendelssohn gedurende de laatste 20+ jaar) . ERDDAP 's net/federation model (de top 80% van dit document) is gebaseerd op deze benadering. Deze oplossing is als een zwaard voor een Gordian Knot
- Deze oplossing is verbluffend eenvoudig.
- Deze oplossing is verbluffend efficiënt omdat er geen werk wordt gedaan om een gerepliceerde dataset bij te houden (s) bijgewerkt.
- Gebruikers kunnen op elk moment de nieuwste gegevens krijgen (b.v., met een latentie van slechts 0,5 seconde) .
- Het schalen vrij goed en er zijn manieren om schaalvergroting te verbeteren. (Zie de discussie bovenaan 80% van dit document.)
Nee, dit is niet een oplossing voor alle mogelijke situaties, maar het is een geweldige oplossing voor de overgrote meerderheid. Als er in bepaalde situaties problemen zijn/zwakke punten met deze oplossing, is het vaak de moeite waard om die problemen op te lossen of met die zwakheden te leven vanwege de verbluffende voordelen van deze oplossing. Als/wanneer deze oplossing echt onaanvaardbaar is voor een bepaalde situatie, bijvoorbeeld wanneer je echt een lokale kopie van de gegevens moet hebben, dan moet je de andere hierboven besproken oplossingen overwegen.
Conclusie
Hoewel er geen enkele, eenvoudige oplossing die perfect alle problemen in alle scenario's oplost (als rsync en gedistribueerde gegevens bijna zijn) , hopelijk zijn er voldoende tools en opties zodat u een aanvaardbare oplossing voor uw specifieke situatie kunt vinden.