放大
ERDDAP™ - 重载、网格、群組、聯盟和云计算
ERDDAP :
ERDDAP™ 一個網絡應用程式和網路服務, 此網頁討論與沉重相關的問題 ERDDAP™ 透過網格、群組、聯盟、云计算,
原文于2009年6月编写。 尚未有重大改變。 這是最后一次更新 2019-04-15.
分局
這個網頁的內容是Bob Simons的个人意見, National Oceanic and Atmospheric Administration . 計算很簡單 但我覺得結論是對的 我在計算中是否使用了錯誤的邏輯? 如果有,那是我的錯 請發郵件與更正 erd dot data at noaa dot gov .
-
- –
重載/ 限制
重用,獨立 ERDDAP™ 將會受到限制 (從最可能到最小可能) 由:
遠端來源頻率
- 遠端資料來源的頻寬, 即使有高效率的連接 (例如,通过 OPeNDAP ) 除非遠端資料來源有很高的網路連接 ERDDAP 反應會受到多快的限制 ERDDAP™ 可以從資料來源取得資料。 解答是將數據集複製到 ERDDAP 硬碟,也許有 EDDGrid 复制 或 EDD 表格 .
ERDDAP 伺服器頻率
- 除非 ERDDAP 伺服器的網路連接率很高 ERDDAP 反應會受到多快的限制 ERDDAP™ 能夠從資料來源取得資料,以及多快 ERDDAP™ 可以把資料傳回客戶端。 唯一的解決辦法就是更快的網路連接。
記憶
- 如果有很多同時的要求 ERDDAP™ 可能內存已耗盡, 並暫時拒絕新的要求 。 ( ERDDAP™ 也有兩種機制可以避免,) 所以伺服器內存越多越好 在32位的伺服器上, 4+ GB真的好, 2 GB是好的, 在64位的伺服器上, 你几乎可以完全避免問題, 得到很多的記憶力。 看 \- Xmx 和 - Xms 設定值 用于 ERDDAP 貓咪 安 ERDDAP™ 用於64位伺服器、8GB內存和-Xmx設定為4000M的電腦上,
已驅動波段
- 存取儲存在伺服器硬碟上的資料比存取遠端資料快得多。 即使如此,如果 ERDDAP™ 伺服器有非常高的頻寬網路連接, 在硬碟上的資料可能會成為瓶颈 。 部分溶液是用得更快 (例如,10 000卢比) 磁性硬碟或 SSD 硬碟 (如果成本合理) . 另一個解決方案是在不同的驅動器上儲存不同的數據集, 這樣累积的硬碟寬度就更高了 。
檔案已儲存太多
- 檔案太多 快取 目錄 - ERDDAP™ 儲存所有影像, 但只儲存某些類型的資料要求 。 數據集的缓存目錄可能會有大量的檔案 。 這會減慢檔案是否在快取內的要求 (真的!) .<快取 分鐘( gt; in) 設定. xml 讓您在刪除前設定檔案在快取中可以存在多久 。 設下小數目可以減少問題。
CPU
- 只有兩件事需要很多 CPU 時間:
- NetCDF 4和 HDF 5現在支持內部壓縮資料 。 解壓大壓縮 NetCDF 4/ HDF 5 個資料檔案需要10秒或更多秒 。 (這不是執行錯誤 這是壓縮的本性) 所以,對數據集的數據集的多份同步要求 被儲存在壓縮的檔案中會對任何伺服器造成嚴重壓力. 如果有問題, 解答方式是將流行的數據集儲存在未壓縮的檔案中, 或是用更多核心的 CPU 取得伺服器 。
- 做圖 (包括地圖) :每圖約0.2 - 1秒. 所以如果有很多對圖片的同時要求 ( WMS 客戶常常會提出6個同步要求!) ,可能有CPU限制。 當多個使用者在執行中 WMS 客戶,這就成問題了
-
- –
多重同樣 ERDDAP 裝填平衡?
問題常常是:"為了處理沉重的負擔,我可以設置多個相同的 ERDDAP 与负荷平衡?" 這是個很有趣的問題 因為它很快就會進入核心 ERDDAP 是設計 快速回答是"不"。 我知道這是個令人失望的答案 但有兩個直接原因 和一些更大的根本原因 ERDDAP™ 使用不同的方法 (联邦 ERDDAP s, 本文件主要描述) 我相信這是個更好的辦法
某些直接原因,你無法/不該建立多重相同的 ERDDAP s 是:
- 給定 ERDDAP™ 讀取每個資料檔, 當它第一次可用時, 以便找到檔案中的資料範圍 。 然后在索引檔案中儲存此資訊 。 之後,當用戶要求數據時, ERDDAP™ 用此索引來找出要搜尋的資料的檔案 。 如果有多重相同 ERDDAP 每個人都會做這份索引 白費力氣 根據以下描述的聯邦制,索引只有一次,由其中一位 ERDDAP s.
- 某些類型的使用者要求 (例如, .nc , png, pdf 檔案) ERDDAP™ 必須在回覆傳送之前將整份檔案制成 。 所以 ERDDAP™ 短暫地儲存這些檔案 。 如果有相同的要求 (尤其是網址嵌入網頁的影像) , ERDDAP™ 可以重用缓存檔案 。 在多重相同的系統中 ERDDAP s, 那些缓存的檔案不共享, 所以每個 ERDDAP™ 不必要和浪費的重生 .nc , png, 或 pdf 檔案 。 依據以下描述的聯盟制度,檔案只由其中一位 ERDDAP s,并重新使用。
- ERDDAP 訂閱系統不是被多個共享的 ERDDAP s. 例如,如果載入平衡器會送一個用戶到一個 ERDDAP™ 而使用者订阅数据集,然后是另一個 ERDDAP 不會知道這份訂約的 稍后, 如果載入平衡器將使用者送至不同的 ERDDAP™ 要求他/她的訂閱清單,另一個 ERDDAP™ 會說沒有 (導致他/她對另一個 ERED 的重复訂閱 DAP ) . 依據以下描述, ERDDAP .
是的,對于這些問題,我可以 (非常努力) 設計解決方案 (共享資訊 ERDDAP s) 但我想 联合会 ERDDAP s 方法 (本文主要描述) 是更好的解決方法 部分是因為它處理了其他的問題 ERDDAP 數據來源分散,
最好接受我沒有設計的簡單事實 ERDDAP™ 以相同方式部署 ERDDAP s有載量平衡器。 我自覺地設計了 ERDDAP™ 在聯合大會內好好工作 ERDDAP s,我相信它有很多优点。 值得注意的是, ERDDAP s完全符合我們現實世界中 分散分布的數據中心系統 (想想不同的IOOS區域, 或不同的海岸觀察區域, 或NCEI的不同部位, 或是其他100個數據中心。 NOAA 或全球1000個數據中心) . 而不是告訴世界所有數據中心 他們需要放棄自己的努力 把所有的數據放進集中的「數據湖」 (這是個可怕的想法, 分散式制度 ) , ERDDAP 它的設計和世界一樣有效 產生數據的數據中心可以繼續維持、管理及服務他們的數據 (他們應該) 然而,与 ERDDAP™ 中, ERDDAP ,不需要將數據傳送中央集團 ERDDAP™ 或儲存重复的資料副本。 實際上,特定數據集可以同时提供 從 a ERDDAP™ 數據的產生與儲存 (例如,戈莫斯) , 從 a ERDDAP™ 在母組織 (例如,IOOS中心) , 從所有... NOAA ERDDAP™ , 來自全美聯邦政府 ERDDAP™ , 從全球 ERDDAP™ (海豹) , 特殊 ERDDAP s (例如, ERDDAP™ 專門研究HAB的學院) , 基本上都是即時有效的 因為只有中繼資料會在 ERDDAP 不是數據 最好的是,在初次之后 ERDDAP™ 在原組織,所有其他 ERDDAP S可以快速建立 (工作幾小時) , (一個不需要任何RAID來儲存資料的伺服器, 因為它沒有在本地儲存資料) 所以成本非常低 相較於建立和维持中央數據中心與數據湖的費用, 對我來說 ERDDAP 分權的聯邦方式是遠遠的,遠超級的
在給定的數據中心需要多重時 ERDDAP 以满足高需求, ERDDAP 其設計完全能匹配或超過多個同樣型的性能 ERDDAP s -a -a 你總是可以設置 多重复合 ERDDAP s (以下讨论) ,其中每一個都從其他的 ERDDAP s,不負載平衡。 這樣的話 我建議你給每個合成人一個點子 ERDDAP 不同名字/身份,如果可能,在世界各地建立 (例如,不同的AWS區域) 例如, ERD 東方, ERD 西部, ERD IE, ERD FR, ERD QQIT , 讓使用者有意识地、 反复地與特定的工作 ERDDAP ,加上你從一個失敗點移除了風險
-
- –
网格、群組和聯盟
在非常重的用途下,單獨使用 ERDDAP™ 會碰到一個或一個以上的 限制 以上所列,甚至所提出的解决办法都不足。 在這種情況下 ERDDAP™ 具有容易建構可縮放格子的特性 (也叫做群組或聯盟) 四, ERDDAP s 能讓系統處理非常重的用途 (例如,大数据中心) .
我用 网格 以表示 電腦群組 所有部件可能或可能不实际位于某一设施,可能或可能不集中管理。 共用、中央所有和管理的网格的优点 (群組) 是他們從规模經濟中获益 (特别是人的工作量) 并簡化 使系統的部份 運作良好。 非中央所有和管理的网格的优势 (联合会) 也有可能提供一些额外的錯誤承受力。 下面我提出的解決方案對所有網格、群組和聯邦地貌都非常有效。
設計可伸縮系統的基本想法是找出潜在的瓶颈,然后設計系統,以便能按需要复制部分系統以缓解瓶颈. 最理想的是,每個複製部分的容量都呈線性地增加 (縮放效率) . 除非每個瓶颈都有可伸展的解決方案, 可伸缩性 跟效率不同 (如何快速完成工作——各部分的效率) . 伸展性可以讓系統長大來應付任何關鍵需求。 效率 (比例) 确定需要多少伺服器等才能满足特定的需求。 效率非常重要,但總是有限度的。 可伸縮性是建立能處理的系統的唯一切实可行的解決方案 非常 重用。 最理想的是,该系统是可伸展和高效的。
目標
此設計的目標是:
- 建立可伸展的建築 (很容易被複製到過重的部份) . 建立高效的系統, 盡最大可能增加數據的可用性和吞吐量, (成本幾乎總是一個問題。)
- 平衡系統各部分的能力 以免系統的某一部分覆蓋另一部分
- 做一個簡單的建築,使系統容易建立和管理.
- 造一個與所有格子地形相關的建筑
- 如果某部分變得過重, (複製大數據集所需的時間總是會限制系統處理對特定數據集突增需求的能力。)
- (如果可能) 做一個與任何特徵無關的建築 云计算 服務或其他外部服務 (因為它不需要它們) .
建 议
我們的建議是
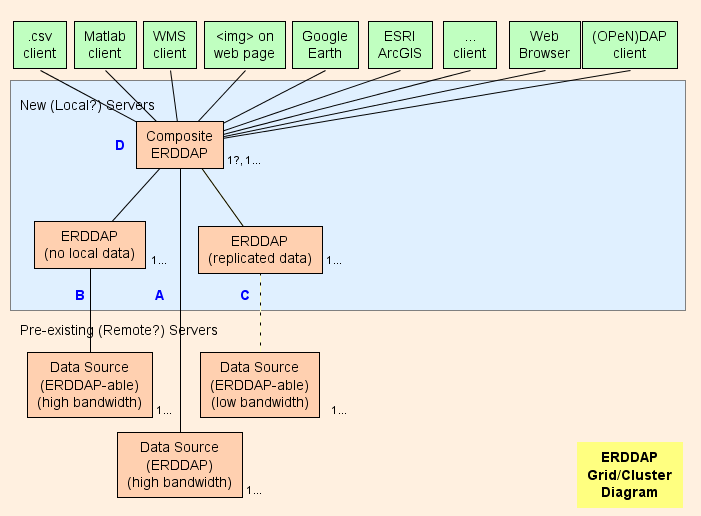
- 基本上,我建議建立合成器 ERDDAP™ ( D 在圖中) ,是常數 ERDDAP™ 但是它只是提供其他的數據 ERDDAP s. 網格的建築要盡量移動工作 (CPU 使用、內存使用、帶宽使用) 自复合 ERDDAP™ 至彼 ERDDAP s.
- ERDDAP™ 有兩種特殊的數據集類型, EDDGrid 來自 Erddap 和 EDD 表格來自 Erddap ,指 其他資料集 ERDDAP s.
- 當合成 ERDDAP™ 從這些數據集、 复合資訊中收到對數據或影像的要求 ERDDAP™ 重定向 其它資料要求 ERDDAP™ 伺服器。 其结果是:
- 這很有效率 (CPU、內存和帶寬) 因為不然
- 复合材料 ERDDAP™ 必須將資料要求傳送至另一個 ERDDAP .
- 其他 ERDDAP™ 必須取得數據, 重新格式化, 並傳送數據到合成器 ERDDAP .
- 复合材料 ERDDAP™ 必須接收資料 (使用附加帶宽) 重塑它 (使用额外的 CPU 時間與內存) ,並傳送資料到使用者 (使用附加帶宽) . 重新定向數據要求并允許其他要求 ERDDAP™ 將回應直接傳送使用者、 复合體 ERDDAP™ 基本上不花 CPU 時間、 內存或帶寬 。
- 重定向對使用者透明, 不管客戶端軟體如何 (瀏覽器或任何其他軟體或命令行工具) .
- 這很有效率 (CPU、內存和帶寬) 因為不然
网格部件
A : 每一個有高頻率的遠端資料來源 OPeNDAP 伺服器, 您可以直接連接遠端伺服器 。 如果遠端伺服器是 ERDDAP™ 使用 EDDGrid 來自 Erddap 或 EDD 表格 ERDDAP 伺服于合成中 ERDDAP . 如果遠端伺服器是其它類型 DAP 伺服器,例如THREDDS, Hyrax ,或GrADS,使用 EDDGrid 從Dap。
B : 每 ERDDAP - 可用的資料來源 (資料來源 ERDDAP 可以讀取資料) 有一個高頻率伺服器, 另設一個 ERDDAP™ 提供此資料來源的資料。
- 如果多次 ERDDAP 數據要求不多 你可以把它們整合成一個 ERDDAP .
- 如果 ERDDAP™ 專門從遠端來源取得數據的要求太多, ERDDAP s 存取遠端資料來源 。 在特殊情况下,這可能合理,但這更可能會覆蓋遠端資料來源 (是自欺欺人) 也阻止其他使用者存取遠端資料來源 (不好) . 在這樣的情况下,考慮建立另一個 ERDDAP™ 以服務於此數據集, 並複製此數據集 ERDDAP 硬碟 (你看 C ) ,可能与 EDDGrid 复制 和/或 EDD 表格 .
- B 伺服器必須公開存取 。
C : 每 ERDDAP - 具有低波段width伺服器的可用資料來源 (或是因其他原因服務慢) ,考慮建立另一個 ERDDAP™ 并保存此數據集的副本 ERDDAP 硬碟,也許是用 EDDGrid 复制 和/或 EDD 表格 . 如果多次 ERDDAP 數據要求不多 你可以把它們整合成一個 ERDDAP . C 伺服器必須公開存取 。
复合 ERDDAP
D : 复合材料 ERDDAP™ 是常數 ERDDAP™ 但是它只是提供其他的數據 ERDDAP s.
- 因為合成 ERDDAP™ 包含所有數據集的資訊, 它能快速回應對數據集清單的要求 (全文搜索、 類別搜索、 所有數據集清單) ,以及要求单个数据集的資料存取表, Make A Graph 窗体,或 WMS 信息頁面。 這些都是小的, 动态生成的 HTML 頁面, 基於內存中持有的信息 。 所以反應很快
- 因為對實際數據的要求 很快就被轉換到另一個 ERDDAP s, 复合材料 ERDDAP™ 不使用任何 CPU 時間、 內存或帶寬, 可以快速回應對實際資料的要求 。
- 越多越好 (CPU、內存、帶宽) 自复合 ERDDAP™ 至彼 ERDDAP s, 复合材料 ERDDAP™ 可以提供所有數據集的資料, 但仍跟隨大量使用者的數據要求。
- 初步測試顯示, ERDDAP™ 可以在 CPU 時間 ~ 1ms 內回答大部分要求, 或是 1000 個要求/ 秒 。 因此 8 個核心處理器應該能回應 8000 個要求/秒 。 雖然可以預想到更高的活動會減速, 數據中心寬度很可能會在合成器之前很久成為瓶颈 ERDDAP™ 成為瓶颈。
最新最大值 (時間) ?
其 EDDGrid 合成件中的 Erddap 表格 ERDDAP™ 只有當來源數據集是時, 才能變更它所儲存的每個來源數據集的資訊 "重載" 和一些元数据變更 (例如,時間變數的 actual\_range ) ,从而生成订阅通知。 如果來源數據集的資料常有變更 (例如,每秒新增數據) 使用 "更新" 系統以注意到基底資料的频繁變更, EDDGrid / Table FromErdddap 在下一個數據集"重載"之前不會被通知這些常見的變更,所以 EDDGrid 來自Erddap的表格不會完全更新 您可以變更來源數據集, 以最小化此問題 。<將 EveryNiminutes & gt; 重新載入更小的值 (60?) 以便有更多訂閱通知告知 EDDGrid / Table FromErddap 來更新它關於來源数据集的信息 。
或者,如果你的數據管理系統知道來源数据集有新的數據 (例如, 透過複製資料檔案的文稿) 如果不是太频繁 (例如,每5分鐘,或频率较低) 有更好的辦法
- 不要用<更新 EveryNMILIS & gt; 以保持源資料集的更新 。
- 設定來源数据集<將 Everyniminutes & gt; 重新載入到更大的數字 (1440年?) .
- 讓文稿聯繫來源数据集 國旗網址 复制到新資料檔後立即建立 。 這會使來源數據集完美更新, 使其產生訂閱通知, 會傳送至 EDDGrid / Table from Erddap 資料集。 那會導致 EDDGrid / Table from Erddap 資料集要完美更新 (5秒內新增資料) . 以及所有能有效做到的事 (不需要重新載入數據集) .
多合成 ERDDAP s
- 在非常極端的情況下,或為容錯,你可能想要建立不止一個复合體 ERDDAP . 可能其他部分 (尤其是,数据中心的帶宽) 在合成之前很久 ERDDAP™ 成為一個瓶颈。 因此,解決方案可能是建立更多,地域多样,數據中心 (鏡子) ,各有一套复合材料 ERDDAP™ 伺服器 ERDDAP 和 (至少) 相關數據集的鏡像副本, 此設定也提供錯誤容應和資料備份 (通过复制) . 這樣的話,最好的辦法是 ERDDAP s有不同的網址。
如果你真的想要所有合成物 ERDDAP s 要有相同的 URL, 使用一個前端系統, 將指定使用者只指定為合成器之一 。 ERDDAP s (基于 IP 位址) ,所以所有使用者的請求都只到其中一個合成器 ERDDAP s. 原因有二:
- 當一個基底的數據集重新載入, 元数据變更時 (例如, 網格化数据集中的新資料檔會產生時間變數 actual\_range 更改) ,复合 ERDDAP s會稍稍不同步,但與 最终一致性 . 通常,他們會在5秒內恢復靜默 但有時會更久 如果使用者做了一個依赖于 ERDDAP™ 訂閱 短短的同步性問題會變得嚴重
- 2+复合材料 ERDDAP s 每個都保持自己的訂閱 (因為上面描述的同步問題) .
所以一個使用者應該被引向其中一個合成器 ERDDAP 避免這些問題。 如果其中之一 ERDDAP 前端系統可以重定向 ERDDAP 使用者到另一個使用者 ERDDAP™ 完了 然而,如果能力問題 造成第一種合成物 ERDDAP™ 失敗 (超熱度的使用者? a 拒絕服役 ?) ,这使得它很可能会將使用者重定向到其他复合材料 ERDDAP s 將會造成 串流失敗 . 因此,最強健的設置是配制 ERDDAP s 有不同的網址。
或者,也許更好,建立多組合 ERDDAP s 沒有負载平衡。 在這個情況下,你應該指出, ERDDAP 不同名字/身份,如果可能,在世界各地建立 (例如,不同的AWS區域) 例如, ERD 東方, ERD 西部, ERD IE, ERD FR, ERD QQIT, 讓使用者有意识地, 重复工作於特定 ERDDAP .
- \[ 在一個伺服器上运行的 高性能系統的迷人設計, 請看這個 郵件 . \]
高需求数据集
在非常不尋常的情況下,其中一個 A , B ,或 C ERDDAP 因為帶寬或硬碟限制, s 無法跟得上要求, 复制資料有道理 (再次) 到另一伺服器+硬 驱动器+ ERDDAP ,可能与 EDDGrid 复制 和/或 EDD 表格 . 雖然有原始的數據集和复制的數據集似乎很理想, ERDDAP™ , 這很困難, 因為兩個數據集會在不同的時期 稍有不同 (特別是,在原始資料收到新資料后, 但在复制的数据集收到副本之前) . 因此,我建議數據集的標題稍有不同 (例如, " ... (复制 # 1) "和. (复制 # 2) " 或者 " (# 鏡子 # n ) " 或 " (伺服器 # n ) ") 分類的數據集 ERDDAP . 使用者通常會看到 鏡像站台 所以這不該讓他們感到驚訝或失望。 因為某個網站的頻寬限制, 將鏡頭定位到另一個網站可能很合理。 如果鏡像复制品在不同的數據中心, 只需從數據中心的合成器存取 ERDDAP™ ,不同的标题 (例如, "Miror #1") 不需要
RAID 和普通硬碟
如果一個大數據集或一组數據集沒有大量使用, 在 RAID 上儲存數據可能是有道理的, 因為它能提供錯誤的容納性, 但是如果數據集被大量使用,將數據复制到另一個伺服器+可能更合理 ERDDAP™ + 硬碟 (類似 谷歌的工作 ) 而不是用一個伺服器和RAID來儲存多套數據集,因為您可以使用兩套伺服器+hardDrive+ ERDDAP 直到其中一個失敗
失敗
如果...
- 需要一個數據集的請求激增 (例如,所有同學同時要求相似的資料) ? 只有 ERDDAP™ 伺服此數據集會被覆蓋、減慢或拒絕要求 。 复合材料 ERDDAP™ 和其他 ERDDAP 不會有影響的 由于系統內特定數據集的限制因素是带有數據的硬碟 (不是 ERDDAP ) ,唯一的解决方案 (不直接) 是在不同的伺服器上复制数据集+ hardDrive+ ERDDAP .
- 安 A , B ,或 C ERDDAP™ 失敗 (例如,硬碟故障) ? 只有數據集 (s) 由它效勞 ERDDAP™ 受到影響。 如果數據集 (s) 在另一台伺服器+hardDrive+上反射 ERDDAP ,效果微乎其微。 如果問題是硬盤在 5 或 6 RAID 中失敗, 您只需取代磁碟並讓 RAID 重建磁碟上的資料 。
- 复合材料 ERDDAP™ 失敗? 如果你想做一個非常 高可用性 你可以設置 多重复合 ERDDAP s (上文) ,使用类似 尼金克斯 或 特拉菲克 處理負载平衡。 注意: ERDDAP™ 可以處理大量使用者的大量要求,因為 要求中繼資料數量小, 要求提供資料 (可能很大) 重定向到孩子 ERDDAP s.
簡單, 可縮放
這個系統很容易建立和管理, 特定數據中心唯一真正的限制是數據中心的頻寬和系統的成本.
寬度
注意系統常用元件的大概帶宽:
| 构成部分 | 近似波段 (GBytes/s) | | -- -- | -- -- | | DDR 記憶體 | 2.5 | | SSD 驅動程式 | 1 | | SATA 硬碟 | 0.3 | | 以太网 | 0.1 | | OC-12 | 0.06 | | OC-3 | 0.015 | | T1 | 0.0002美元 |
一個SATA硬碟 (0.3GB/s) 在一個伺服器上 ERDDAP™ 可以饱和 Gigabit 以太网局域网 (0.1GB/s) . 和一個Gigabit以太网局域網 (0.1GB/s) 可以饱和 OC- 12 網路連接 (0.06GB/s) . 至少一個來源列出 OC-12 線路 每月耗費約10萬美元。 (對,這些計算基於將系統推向極限, 但這些計算對計劃及平衡系統的部位是有用的。) 顯然你數據中心的網絡連接很迅速 是系統最貴的部分 你可以輕而易舉地建一個網格 有一打伺服器可以跑一打 ERDDAP S能快速抽出大量資料, 部分解决办法是:
- 鼓励客戶端要求數據的子集, 如果這就是需要的 。 如果客戶端只需要一個小區域的資料或更低的解析度, 那就是他們應該要求的 。 子設定是协议的核心焦點 ERDDAP™ 支援要求資料 。
- 鼓励傳送壓縮的資料 。 ERDDAP™ 压缩 如果它找到「接受編碼」,則會傳送資料 HTTP GET 要求信头。 所有網頁瀏覽器都使用"接受編碼",並自動解壓回應. 其他客戶 (例如,電腦程序) 要明確使用它。
- 將您的伺服器控制在 ISP 或其他網站上, 提供相对便宜的頻寬成本 。
- 以 ERDDAP 以分散成本。 然後可以連結您的合成器 ERDDAP™ 其 ERDDAP s.
注意: 云计算 也提供所有你需要的網路頻寬,
關於設計可伸展、高容量、容錯系統的一般資訊, 釋放它 .
像樂高
軟體設計師常試著善用 軟體設計模式 解決問題 好模式是好的,因為它們包裝好,容易創作和工作,通用的解決方法,導致具有良好性能的系統. 模式名稱不规范,所以我會稱之為模式 ERDDAP™ 使用樂高模式。 每個樂高 (各 ERDDAP ) 簡單、小、標準、獨立、磚頭 (資料伺服器) 有一個定義的介面, 可以讓它與其它 legos 連接 ( ERDDAP s) . 部分 ERDDAP™ 构成此系統的有: 訂閱與旗下URL系統 (允許在 ERDDAP s) ,EDD... 從 Erddap 轉換系統,以及 RESTful 使用者或其他人可以產生的資料要求 ERDDAP s. 因此,給予兩個或更多的legos ( ERDDAP s) ,可以建立大量不同的形状 (網路地形 ERDDAP s) . 當然,它的設計和特色 ERDDAP™ 或許只是為了讓一個特定的地貌 能夠和最佳化 但我們覺得 ERDDAP 樂高類型的設計提供了一個很好的,通用的解决方案,可以讓任何 ERDDAP™ 管理者 (或管理者群組) 創造出各種不同的聯邦地形 例如,一個單一組織可以建立3個 (或更多) ERDDAP s 如 ERDDAP™ 上面的网格/群組圖 . 或分布的群組 (伊歐斯? 海岸觀察? NEI? 西北? NOAA ? USGS? 數據網? 近南? 利特? 哦? 博德? ONC? JRC? 衛星?) 可以設置一個 ERDDAP™ 每個小前哨站 (所以數據可以靠近來源) 然后建立合成器 ERDDAP™ 中央辦公室的虛擬數據集 (總是完美更新的) 每一個小前哨 ERDDAP s. 是的,所有 ERDDAP s,安裝在世界各地的不同機構中, ERDDAP s和/或提供其他資料 ERDDAP s, 形成由 ERDDAP s. 太酷了! 所以,和樂高一樣, 可能性是无限的。 所以這是個很好的模式 所以這是個很好的設計 ERDDAP .
不同類型的要求
這項數據伺服器地形討論的現實性複雜點之一, 這多半是另一回事 (有多快? ERDDAP™ 是否對數據要求有反應?) 根據地貌討論 (處理資料伺服器之間的關係, 而哪個伺服器有實際資料) . ERDDAP™ 當然,試著高效地處理所有類型的請求, 但處理一些比其他更好的。
- 很多要求都很簡單 例如: 此數據集的元数据是什么 ? 或: 此網格化的數據集的時間維度值是多少 ? ERDDAP™ 以盡快處理這些( 通常在<=2 ms),保存此信息于記憶中.
- 有些要求有些困难。 例如: 給我這個數據集 (在一個資料檔中) . 這些要求可以相对快速地處理 因為沒有那麼難
- 有些要求很困難,因此很耗時。 例如: 給我這個數據集 (可能是在 10,000+ 資料檔案中, 或是從壓縮的資料檔案中, 每份要花10秒才能解壓) . ERDDAP™ v2.0 引入了一些新的、更快的應用方式, 但有另外一種方法 ERDDAP™ 尚未支援 : 特定數據集的數據檔子集可以儲存並分析在不同的電腦上, 然后在原始伺服器上將結果合并 。 這方法叫做 映射 而以 哈多普 第一個 (?) 開源的 MapReduce 程式, (如果您需要地圖 ERDDAP ,請發送電子郵件請求至 erd.data at noaa.gov .) 谷歌的 大查詢 有趣的是,它似乎是用于子設定表格數據集的 MapReduce 的實施,它是其中之一 ERDDAP 其主要目標 很可能你可以建立 ERDDAP™ BigQuery 資料集 數據庫中的 EDD 表格 因為大查詢可以通过 JDBC 介面存取 。
這是我的意見
是的,算法很簡單 (而現在稍有日期) 但我覺得結論是對的 我在計算中是否使用了錯誤的邏輯? 如果有,那是我的錯 請發郵件與更正 erd dot data at noaa dot gov .
-
- –
云计算
一些公司提供云计算服务 (例如, 亞馬遜網路服務 和 谷歌云平台 ) . 网站托管公司 提供更簡單的服務, 自 ERDDAP™ 网格只是由 ERDDAP s 自此 ERDDAP 是 Java 可在Tomcat 執行的網頁應用程式 (最常见的應用程式伺服器) 或其他應用程式伺服器, ERDDAP™ 网格在云服務或網站主機網站上。 這些服務的优点是:
- 提供非常高的頻寬網路連接。 光是這個,就有理由使用這些服務。
- 他們只收你的服務費 例如, 您可以存取高頻率的網路連接, 但您只付實際資料轉接費 。 讓你們建立一個很少被壓迫的系統 (即使是在高峰期需求) ,不需要支付很少使用的容量。
- 它們很容易展開 您可以在不到一分鐘內改變伺服器類型或增加多少伺服器或儲存多少 。 光是這個,就有理由使用這些服務。
- 他們讓你脫離很多管理服務器和網路的職責 光是這個,就有理由使用這些服務。
其缺点是:
- 他們的服務收費很多 (絕對值,不是說不是好價值) . 上面的價格是... Amazon EC2 . 這些價格 (截至2015年6月) 會下來的
但數據檔案與要求數量較少。
未來的價格會更低, 但數據檔和要求數量會更大 。
所以細節有變化 但情況仍然很穩定
也不是服務价格太高 而是我們在使用和買很多服務
- 資料傳輸 - 資料傳輸到系統已自由 (耶!) . 數據傳出為0.09/GB。 1台SATA硬碟 (0.3GB/s) 在一個伺服器上 ERDDAP™ 可以饱和 Gigabit 以太网局域网 (0.1GB/s) . 一個 Gigabit 以太網 LAN (0.1GB/s) 可以饱和 OC- 12 網路連接 (0.06GB/s) . 如果一個OC-12連接器能傳送~15萬GB/月, 數據傳輸成本可能高达15萬GB@0.09/GB=13500美元/月, 顯然,如果你有十幾個辛勤工作 ERDDAP 您的每月數據傳輸費可能很大 (最多162 000美元/月) . (也不是服務價格太高 而是我們在使用和買很多服務)
- 數據儲存——亞馬遜每TB收取50美元/月. (相較於買下一家4TB企業,) 所以如果你需要把很多數據儲存在雲中 可能會很貴 (例如,100TB成本5000美元/月) . 但除非你擁有大量數據, 這比帶寬/數據傳輸成本要小。 (也不是服務價格太高 而是我們在使用和買很多服務)
子集
- 子設定問題 : 從資料檔案中高效傳送資料的唯一方法就是有正在傳送資料的程序 (例如, ERDDAP ) 執行於一個在本地硬碟上儲存資料的伺服器 (或類似快速存取 SAN 或本地RAID) . 允許本地檔案系統 ERDDAP™ (和基本文庫,例如 netcdf-java) 要求從檔案中指定位元組, 並很快得到回應 。 很多類型的資料要求 ERDDAP™ 到檔案 (特別是格子化的資料要求,其中梯度值 > 1) 如果程序需要從非本地端的檔案中要求完整檔案或大塊檔案, 無法有效完成 。 (故慢) 資料儲存系統,然后提取子集。 如果云集不給 ERDDAP™ 快速存取檔案的位元範圍 (和本地文件一樣快) , ERDDAP 取得數據將是一個嚴重的瓶颈,
主機資料
以上成本效益分析的替代方法 (根據資料所有者 (例如, NOAA ) 付錢把數據存放在云中) 2012年左右,亞馬遜 (在较小程度上,一些其他云提供商) 開始在它們的雲中托管一些數據集 (AWS S3) 免費 (如果使用者租用 AWS EC2 計算例與數據合作,) . 因為上傳數據的時間和成本已經是零。 用 ERDDAP™ v2.0, 有新的功能可以方便執行 ERDDAP 云:
- 現在,A EDDGrid 從 File 或 EDDTable From Files 資料集中可以從遠端的資料檔建立並透過網路存取 (例如AWS S3桶) 使用<取自Url> 及<快取大小 GB> 選項 。 ERDDAP™ 將保持最近使用的資料檔案的本地快取 。
- 如果從檔案來源檔案的 EDD Table 已壓縮 (例如, .tgz ) , ERDDAP™ 當它讀到他們的時候,他們將自動消解。
- 現在 ERDDAP™ 應答給定要求的線線會產生工人線線,以便在要求的分節上工作,如果你使用<nThreads & gt; 選項 。 此平行化應能更快地應答困難的要求。
這些變更解決了 AWS S3 不提供本地端、 區塊階級檔案儲存與檔案的問題 (舊) 存取 S3 資料的問題 。 (多年前 (~2014年) 但現在要短得多,所以沒有那麼大) 總之 這意味著建立 ERDDAP™ 在云中效果更好了
謝謝你 多虧了馬修·阿羅特和他的團體 在最初的OOI的努力中 ERDDAP™ 在云中,以及在云中,
-
- –
数据集的远程复制
有一個共同的問題 關于以上討論 ERDDAP s: 遠端复制数据集。 基本問題是: 數據提供商維持一個偶爾變更的數據集, 而使用者想要保持此數據集的最新本地副本 (任何原因) . 顯然,這有很多變化。 有些變化比其他變化更難處理
- 快速更新 更難讓本地的數據機更新 立即 (例如,在3秒內) 而不是在幾小時內
- 频繁的變更 频繁的變化比很少的變化更難處理. 比起每0.1秒的變更,
- 小變更 對來源檔案的微小改變比全新的檔案更難處理 。 如果小變更可能在檔案的任何地方,這就更是特別的了 。 微小的變化更難侦測, 新的檔案很容易被偵測到, 傳輸效率也很高 。
- 全部數據集 保持完整的數據集更新比保持最近的数据更難。 有些使用者只需要最近的数据 (例如,過去8天的價值) .
- 多份副本 在不同的網站保持多份遠距副本比保持一份遠距副本更難。 這是縮放問題
使用者的需求與期望。 很多變化都很難解決 一個情況的最好解決方案往往不是另一個情況的最好解決方案,
相關 ERDDAP™ 工具
ERDDAP™ 提供數個工具, 可以用作維持數據集遠端副本的系統的一部分 :
- ERDDAP 是 RSS (富人網站簡介?) 服務
提供快速檢查遙控器上的資料集的方法 ERDDAP™ 已改變。 - ERDDAP 是 訂閱服務
更有效率 (比 RSS ) 方式: 當數據集更新, 更新結果有變更時, 它會立即發送電子郵件或聯絡網址給每個訂閱者 。 它很有效率,因為它會盡快發生 而且沒有白費力氣 (投票 RSS 服務) . 使用者可以使用其他工具 (像 IFTTT ) 以回應訂閱系統的電子郵件通知。 例如,使用者可以訂閱遠端的數據集 ERDDAP™ 并使用 IFTTT 對訂閱的電子郵件通知做出反應並啟動更新本地端的數據集 。 - ERDDAP 是 旗子系統
提供一种方法 ERDDAP™ 管理員告訴他/她的數據集 ERDDAP 盡快重載 國旗的 URL 形式可以很容易地在文稿中使用. 國旗的 URL 形式也可以用作訂閱的動作 。 - ERDDAP 是 "files" 系統
可以提供特定數據集的來源檔案的存取權, 包括檔案的 Apache 樣式目錄清單 (網址存取資料夾) 它有每個檔案的下載網址、上次修改的時間和大小。 一個壞處是使用 "files" 系統是來源檔案可能有不同的變數名稱和不同的中繼資料 。 ERDDAP . 如果遙控器 ERDDAP™ 數據集提供了其來源檔案的存取權, 它開啟了一個窮人的rsync版本的可能性: 本地系統很容易看到哪些遠端檔案已經變更, 需要下載 。 (看 從Url 選項中快取 下方可以使用這個)
解决方案
雖然問題有很多變化, 也有很多可能的解決方案,
自訂, Brute 強制解决方案
一個明顯的解決辦法是手動自訂解議, 因此可以對特定情況进行优化: 建立一套系統, 探測/辨識哪些資料已經變更, 將資訊傳送給使用者, 讓使用者可以要求變更的資料 。 好吧,你可以做到的,但有缺点:
- 自訂解決法是很多工作。
- 自訂溶液通常會被定制到給定的數據集和給定的使用者系統,所以無法輕易重用.
- 自訂解决方案必須由您建立和维护 。 (這可不是什么好主意 避免工作,找別人來做工作,總是好主意!)
由他人建立和维持的一般解決方案,
rs
rs 是目前 令人驚訝的好一般目的解議 以保持源碼電腦上的檔案集 在使用者的遠端電腦上同步 。 工作方式是:
- 一些事件 (例如, ERDDAP™ 訂閱系統事件) 啟動 rsync, (或者,一個 cron 工作每天在使用者的電腦上的特定時間執行 rsync)
- 在源碼電腦上聯繫rsync,
- 它為每個檔案的區塊計算一系列的散列, 將這些散列傳送給使用者的 rsync,
- 將此資訊與相關資訊作比較,
- 要求變更的檔案 。
考虑到它所做的一切, rsync的操作非常快 (例如, 十秒加數據傳送時間) 和非常高效。 有 rsync 的變化 以不同情況优化 (例如, 預計和剪切每個來源檔案的區塊的散列) .
rsync的主要弱點是: 需要一些努力才能建立 (安保) ; 有一些縮放問題; 而且它不適合讓 NRT 数据集真正更新 (比如說,每5分鐘多使用rs氣很尷尬) . 如果你能處理弱點, 或者它們不影響你的處境, rsync 是一個非常好的,一般目的的解決方案,
上面有件東西 ERDDAP™ 要將 rsync 服務的支援加入到 ERDDAP (可能很辛苦吧) ,以便任何客戶端都能使用 rsync (或變體) 以保持数据集的最新副本。 如果有人想研究,請發郵件 erd.data at noaa.gov .
也有其他程式可以多或少做 rsync 做的工作, 有時會引向數據集的复制 (通常在檔案抄本層面) 例如, Unidata 是 碘 .
從 Url 快取
從Url 的快取 設定值可用 (始于 ERDDAP™ v2.0) 全部 ERDDAP 從檔案中建立數據集的數據集類型 (基本上,所有子類 EDDGrid 從檔案 和 檔案中的 EDD 表格 ) . 快取 FromUrl 通过快取從遠端來源複製來自動下載及維持本地資料檔案, 使得此檔案無足輕重 從厄爾設置。 遠端檔案可以放在Web 存取資料夾或THREDDS提供的類似目錄的檔案清單中, Hyrax S3桶,或 ERDDAP 是 "files" 系統。
如果遠端檔案的來源是遠端 ERDDAP™ 提供來源檔案的數據集 ERDDAP™ "files" 系統,然後你可以 訂閱 到遠端數據集,並使用 國旗網址 以您本地端的數據集為訂閱的動作 。 然後, 當遠端數據集變更時, 它會聯絡您的數據集的旗子網址, 它會告訴它重新載入 ASAP, 它會偵測並下載已變更的遠端數據檔 。 這一切發生得很快 (通常~5秒加上下載已變更的檔案所需的時間) . 如果來源數據集變更是定期新增的檔案, 而現有的檔案永遠不會變更, 此方法就大有效果 。 如果數據常被附在所有人身上, (或大部分) , 因為您的本地端數據集常下載整個遠端數據集 。 (這就是需要像激素一樣的方法的地方。)
歸檔ADataset
ERDDAP™ 是 歸檔ADataset 通常數據集中會加入數據, 但舊數據永遠不會變更。 基本上 ERDDAP™ 管理者可以執行 ArchiveADataset (也許在劇本上,或許由cron經營) 指定要提取的數據集的子集 (可能在多個檔案中) 套件中 .zip 或 .tgz 檔案,以便您可以把檔案寄給有興趣的人或群組 (例如, 存档的 NCEI) 或者提供它下載。 例如,你可以每天12: 10運行ArchiveADataset,並讓它成為 .zip 從前一天的12點到今天的12點 (或者,做這個每周,每月,或每年, 视需要。) 因為被包裝的檔案是從線下產生的, 所以沒有超時或數據太多的危險, 因為會有標準 ERDDAP™ 要求。
ERDDAP™ 標準的要求系統
ERDDAP™ 標準的請求系統在數據集中常加入資料時, 是另一個好的解答, 但舊數據從未變更 。 基本上,任何人都可以使用標準的要求來取得特定時間範圍的資料. 例如,每天12:10,你可以要求從前一天中午12:00到今天中午12:00的遠端數據集提供所有資料。 限制 (相對於 ArchiveADataset 方法) 是暫停的風險, 或是有太多的數據供單一檔案使用 。 您可以更频繁地要求更短的時段以避免限制 。
從 HttpGet 的 EDD 表格
\[ 此選項目前尚未存在, \]
新的 從 HttpGet 的 EDD 表格 數據集類型 ERDDAP™ v2.0 可以預想另一個解決方案。 此類型的數據集所保持的基底檔案, 主要是紀錄數據集變更的檔案 。 應該可以定期建立維持本地數據集的系統 (或基于扳机) 要求自上次要求起對遠端數據集的所有變更 。 那也一樣有效 (或更多) 而不是 rsync , 並且會處理很多困難的情景, 但只有遠端和本地的數據集是 EDDTable FromHtpGet 數據集, 才能工作 。
如果有人想工作,請聯繫 erd.data at noaa.gov .
已分发資料
以上所有解決方案都無法解決問題的硬變化, (NRT) 數據集很困難 部分是因為所有可能的情形
一個很好的解答: 不要試圖复制數據。 相反,使用唯一的权威來源 (一個數據集 ERDDAP ) ,由資料提供者维护 (例如,) . 所有想從數據庫得到資料的使用者 總是從來源得到資料 例如,基于瀏覽器的應用程式從一個基于 URL 的要求中取得資料,所以要求是否是從遠端伺服器上傳到原始來源並不重要 (而不是主機的伺服器) . 許多人一直提倡此分配數據方法, (例如,Roy Mendelssohn 過去20多年) . ERDDAP 网格/ 成型模型 (此文件的前80%) 以此方法为基础。 這個解決方案就像一把劍對著高德恩·諾特——整個問題都消失了.
- 這種解決方法非常簡單
- 因為沒有做任何工作來保留複製的數據集, (s) 最新消息
- 使用者可以隨時取得最新資料 (例如,只有0.5秒) .
- 它的尺寸非常大 而且有方法可以提高比例 (參考此文件前80%的討論。)
不,這不是解決所有可能情況的辦法 但對绝大多数人來說,這是個很好的辦法 通常值得努力解決這些問題, 或與這些弱點同住, 如果/ 當這個解決方案對特定情況真的不可接受, 例如當您真的必須有當地的資料副本時, 請考慮以上討論的其他解決方案 。
結 论
雖然沒有一個簡單的解決方案 能完美地解決所有情況下的所有問題 (如 rsync 和 分布的資料幾乎是) 希望有足夠的工具和選擇 這樣你才能找到一個可接受的解決方案