Élargissement
ERDDAP™ - Charges lourdes, Grilles, Clusters, Fédérations et Cloud Computing
ERDDAP :
ERDDAP™ est une application web et un service web qui regroupe des données scientifiques provenant de diverses sources locales et distantes et offre un moyen simple et cohérent de télécharger des sous-ensembles de données dans des formats de fichiers communs et de faire des graphiques et des cartes. Cette page Web traite des questions liées à ERDDAP™ l'utilisation charge et explore les possibilités de faire face à des charges extrêmement lourdes via des réseaux, des grappes, des fédérations et l'informatique en nuage.
La version originale a été écrite en juin 2009. Il n'y a eu aucun changement significatif. Dernière mise à jour: 2019-04-15.
DISCLAIMER
Le contenu de cette page Web est l'opinion personnelle de Bob Simons et ne reflète pas nécessairement la position du gouvernement ou de la National Oceanic and Atmospheric Administration . Les calculs sont simplistes, mais je pense que les conclusions sont correctes. Ai-je utilisé une logique erronée ou fait une erreur dans mes calculs? Si oui, la faute est la mienne seule. Veuillez envoyer un email avec la correction erd dot data at noaa dot gov .
-
- Oui.
Charges lourdes / contraintes
Avec un usage intensif, un standalone ERDDAP™ sera limité (de la plus à la moins probable) par:
Bande passante à source distante
- La bande passante d'une source de données distante — Même avec une connexion efficace (Par exemple, via OPeNDAP ) , sauf si une source de données distante possède une connexion Internet à bande passante très élevée, ERDDAP 's réponses seront limitées par la rapidité ERDDAP™ peut obtenir des données de la source de données. Une solution est de copier l'ensemble de données sur ERDDAP le disque dur, peut-être avec EDDGrid Copier ou EDDTableCopy .
ERDDAP La bande passante du serveur
- Sauf ERDDAP Le serveur a une connexion Internet très haute bande passante, ERDDAP 's réponses seront limitées par la rapidité ERDDAP™ peut obtenir des données des sources de données et à quelle vitesse ERDDAP™ peut retourner des données aux clients. La seule solution est d'obtenir une connexion Internet plus rapide.
Mémoire
- S'il y a de nombreuses demandes simultanées, ERDDAP™ peut manquer de mémoire et refuser temporairement de nouvelles requêtes. ( ERDDAP™ a quelques mécanismes pour éviter cela et minimiser les conséquences si cela se produit.) Donc plus de mémoire dans le serveur le mieux. Sur un serveur 32 bits, 4 Go+ est vraiment bon, 2 Go est correct, moins n'est pas recommandé. Sur un serveur 64 bits, vous pouvez presque entièrement éviter le problème en obtenant beaucoup de mémoire. Voir Paramètres \-Xmx et -Xms pour ERDDAP C'est Tomcat. Une ERDDAP™ L'utilisation lourde sur un ordinateur avec un serveur 64 bits avec 8 Go de mémoire et -Xmx réglé à 4000M est rarement, voire jamais, limitée par la mémoire.
La bande passante de Drive
- L'accès aux données stockées sur le disque dur du serveur est beaucoup plus rapide que l'accès aux données distantes. Malgré cela, si ERDDAP™ serveur a une connexion Internet très haute bande passante, il est possible que l'accès aux données sur le disque dur sera un goulot d'étranglement. Une solution partielle est d'utiliser plus rapidement (Par exemple, 10 000 RPM) disques durs magnétiques ou disques SSD (si cela a un sens en termes de coûts) . Une autre solution est de stocker différents ensembles de données sur différents disques, de sorte que la bande passante cumulée du disque dur est beaucoup plus élevée.
Trop de fichiers classés
- Trop de fichiers dans un cache répertoire — ERDDAP™ cache toutes les images, mais ne cache que les données pour certains types de requêtes de données. Il est possible que le répertoire cache d'un jeu de données ait un grand nombre de fichiers temporairement. Cela ralentira les requêtes pour voir si un fichier est dans le cache (Vraiment !) .<cache Compte rendu et compte rendu configuration.xml vous permet de définir combien de temps un fichier peut être dans le cache avant qu'il ne soit supprimé. La fixation d'un nombre plus petit permettrait de réduire au minimum ce problème.
CPU
- Seulement deux choses prennent beaucoup de temps CPU:
- NetCDF 4 et HDF 5 supporte désormais la compression interne des données. Décompression d'un grand comprimé NetCDF 4 / HDF 5 fichiers de données peuvent prendre 10 secondes ou plus. (Ce n'est pas une faute d'implémentation. C'est la nature de la compression.) Ainsi, plusieurs requêtes simultanées aux ensembles de données avec des données stockées dans des fichiers compressés peuvent mettre une pression sévère sur n'importe quel serveur. Si c'est un problème, la solution est de stocker des ensembles de données populaires dans des fichiers non compressés, ou obtenir un serveur avec un processeur avec plus de cœurs.
- Création de graphiques (y compris les cartes) : environ 0,2 à 1 seconde par graphique. Donc, s'il y avait beaucoup de demandes simultanées uniques de graphiques ( WMS clients font souvent 6 demandes simultanées!) , il pourrait y avoir une limitation CPU. Lorsque plusieurs utilisateurs fonctionnent WMS clients, cela devient un problème.
-
- Oui.
Plusieurs identiques ERDDAP avec Load Balancing ?
La question se pose souvent: "Pour faire face aux charges lourdes, puis-je configurer plusieurs identiques ERDDAP s avec équilibrage de charge?" C'est une question intéressante car elle arrive rapidement au cœur de ERDDAP La conception. La réponse rapide est "non". Je sais que c'est une réponse décevante, mais il y a quelques raisons directes et quelques raisons fondamentales plus importantes pour lesquelles j'ai conçu ERDDAP™ utiliser une approche différente (une fédération de ERDDAP s, décrits dans la majeure partie du présent document) , qui, je crois, est une meilleure solution.
Quelques raisons directes pour lesquelles vous ne pouvez pas/ne devriez pas configurer plusieurs identiques ERDDAP s sont:
- A donné ERDDAP™ lit chaque fichier de données lorsqu'il devient d'abord disponible afin de trouver les gammes de données dans le fichier. Il stocke ensuite ces informations dans un fichier index. Plus tard, quand une demande de données de l'utilisateur arrive, ERDDAP™ utilise cet index pour déterminer quels fichiers rechercher les données demandées. S'il y avait plusieurs identiques ERDDAP s, ils feraient chacun cette indexation, qui est un effort gaspillé. Avec le système fédéré décrit ci-dessous, l'indexation n'est faite qu'une fois, par l'un des ERDDAP Par.
- Pour certains types de requêtes d'utilisateurs (Par exemple, pour .nc , .png, .pdf fichiers) ERDDAP™ doit faire le fichier entier avant que la réponse puisse être envoyée. Alors ERDDAP™ cache ces fichiers pour une courte période. Si une demande identique est présentée (comme il le fait souvent, en particulier pour les images où l'URL est intégrée dans une page Web) , ERDDAP™ peut réutiliser ce fichier mis en cache. Dans un système de multiples identiques ERDDAP s, ces fichiers mis en cache ne sont pas partagés, donc chaque ERDDAP™ serait inutilement et gaspillé recréer le .nc Les fichiers .png ou .pdf. Avec le système fédéré décrit ci-dessous, les fichiers ne sont faits qu'une seule fois, par l'un des ERDDAP s, et réutilisé.
- ERDDAP le système d'abonnement n'est pas mis en place pour être partagé par plusieurs ERDDAP Par. Par exemple, si l'équilibreur de charge envoie un utilisateur à un ERDDAP™ et l'utilisateur s'inscrit à un jeu de données, puis l'autre ERDDAP s ne sera pas au courant de cet abonnement. Plus tard, si l'équilibreur de charge envoie l'utilisateur à un autre ERDDAP™ et demande une liste de ses abonnements, ERDDAP™ Dire qu'il n'y en a pas (lui permettant de faire un double abonnement sur l'autre ERED DAP ) . Avec le système fédéré décrit ci-dessous, le système d'abonnement est simplement géré par le principal, public, composite ERDDAP .
Oui, pour chacun de ces problèmes, je pourrais (avec un grand effort) concevoir une solution (de partager les informations entre ERDDAP s) Mais je pense que Fédération de ERDDAP approche (décrit dans la majeure partie du présent document) est une meilleure solution globale, en partie parce qu'elle traite d'autres problèmes que les ERDDAP L'approche s-with-a-load-balancer ne commence même pas à aborder, notamment la nature décentralisée des sources de données dans le monde.
Il est préférable d'accepter le simple fait que je n'ai pas conçu ERDDAP™ à déployer en tant que multiple identique ERDDAP s avec un régulateur de charge. J'ai conçu consciemment ERDDAP™ de bien travailler au sein d'une fédération de ERDDAP s, qui, je crois, présente de nombreux avantages. En particulier, une fédération de ERDDAP s est parfaitement aligné avec le système décentralisé et distribué de centres de données que nous avons dans le monde réel (pensez aux différentes régions de l'IOOS, ou aux différentes régions de CoastWatch, ou aux différentes parties de l'INCE, ou aux 100 autres centres de données NOAA , ou les différents DAAC de la NASA, ou les 1000 de centres de données dans le monde entier) . Au lieu de dire à tous les centres de données du monde qu'ils doivent abandonner leurs efforts et mettre toutes leurs données dans un « lac de données » centralisé (même si c'était possible, c'est une idée horrible pour de nombreuses raisons -- voir les différentes analyses montrant les nombreux avantages de systèmes décentralisés ) , ERDDAP Le design fonctionne avec le monde tel qu'il est. Chaque centre de données qui produit des données peut continuer de maintenir, de guérir et de servir leurs données (comme ils devraient) Et pourtant, avec ERDDAP™ , les données peuvent également être instantanément disponibles à partir d'un ERDDAP , sans la nécessité de transmettre les données au ERDDAP™ ou de stocker des copies en double des données. En effet, un ensemble de données peut être simultanément disponible d ' un ERDDAP™ auprès de l'organisation qui a produit et stocké les données (Par exemple, GoMOOS) , d ' un ERDDAP™ auprès de l ' organisation mère (Par exemple, IOS central) , d'un... NOAA ERDDAP™ , d'un gouvernement fédéral américain ERDDAP™ , d ' un système mondial ERDDAP™ (OBJET) , et des ERDDAP s (Par exemple, ERDDAP™ dans un établissement consacré à la recherche HAB) , tous essentiellement instantanément, et efficacement parce que seules les métadonnées sont transférées entre ERDDAP s, pas les données. Mieux que tout, après l'initiale ERDDAP™ à l'organisme d'origine, tous les autres ERDDAP s peut être configuré rapidement (quelques heures de travail) , avec des ressources minimales (un serveur qui n'a pas besoin de RAID pour le stockage des données car il ne stocke pas de données localement) , et donc à un coût vraiment minimal. Comparez cela au coût de la mise en place et de la maintenance d'un centre de données centralisé avec un lac de données et la nécessité d'une connexion Internet réellement massive, vraiment coûteuse, plus le problème qui accompagne le centre de données centralisé étant un seul point d'échec. Pour moi, ERDDAP L'approche décentralisée et fédérée est loin, bien supérieure.
Dans les situations où un centre de données donné a besoin de plusieurs ERDDAP s pour répondre à une demande élevée, ERDDAP 's conception est entièrement capable d'apparier ou de dépasser l'efficacité du multiple-identique- ERDDAP l'approche s-with-a-load-balancer. Vous avez toujours la possibilité de mettre en place multiples composites ERDDAP s (comme indiqué ci-après) , dont chacun obtient toutes leurs données de l'autre ERDDAP s, sans équilibre de charge. Dans ce cas, je recommande que vous fassiez un point de donner chacun des composites ERDDAP s un nom / identité différent et si possible les mettre en place dans différentes parties du monde (Par exemple, différentes régions de l'AWS) , par exemple, ERD \_US\_Est, ERD \_US\_Ouest, ERD \_IE, ERD \_FR, ERD \_IT, de sorte que les utilisateurs consciemment, à plusieurs reprises, travaillent avec un ERDDAP , avec l'avantage supplémentaire que vous avez retiré le risque d'un seul point d'échec.
-
- Oui.
Grilles, groupements et fédérations
Sous très forte utilisation, une seule ERDDAP™ rencontrera un ou plusieurs des contraintes et même les solutions proposées seront insuffisantes. Pour de telles situations, ERDDAP™ a des fonctionnalités qui le rendent facile à construire des grilles évolutives (également appelés groupements ou fédérations) des ERDDAP s qui permettent au système de gérer une utilisation très lourde (Par exemple, pour un grand centre de données) .
J'utilise grille comme terme général pour indiquer un type de cluster informatique où toutes les parties peuvent ou non être physiquement situées dans une installation et peuvent ou non être administrées centralement. Un avantage de grilles communes, centralisées et administrées (Groupes) est qu'ils bénéficient d'économies d'échelle (en particulier la charge de travail humaine) et simplifient le bon fonctionnement des parties du système. Un avantage des grilles non colocalisées, non centralisées et administrées (fédérations) est qu'ils répartissent la charge de travail humaine et le coût, et peut fournir une certaine tolérance de faute supplémentaire. La solution que je propose ci-dessous fonctionne bien pour toutes les topographies de grille, de grappe et de fédération.
L'idée de base de la conception d'un système modulable est d'identifier les goulets d'étranglement potentiels et de concevoir ensuite le système afin que des parties du système puissent être reproduites au besoin pour atténuer ces goulets d'étranglement. Idéalement, chaque pièce reproduite augmente la capacité de cette partie du système linéairement (efficacité de l'échelle) . Le système n'est pas évolutif sauf s'il existe une solution évolutive pour chaque goulot d'étranglement. Échelle est différent de l'efficacité (l'efficacité des pièces) . L'évolutivité permet au système de croître pour faire face à n'importe quel niveau de demande. Efficacité (et des parties) détermine combien de serveurs, etc., seront nécessaires pour répondre à un niveau de demande donné. L'efficacité est très importante, mais a toujours des limites. La scalabilité est la seule solution pratique pour construire un système capable de gérer Très Utilisation intensive. Idéalement, le système sera évolutif et efficace.
Objectifs
Les objectifs de cette conception sont les suivants :
- Faire une architecture évolutive (une qui est facilement extensible en reproduisant toute partie qui devient surchargée) . Établir un système efficace qui maximise la disponibilité et le débit des données compte tenu des ressources informatiques disponibles. (Le coût est presque toujours un problème.)
- Pour équilibrer les capacités des parties du système afin qu'une partie du système ne submerge pas une autre partie.
- Faire une architecture simple pour que le système soit facile à configurer et à administrer.
- Faire une architecture qui fonctionne bien avec toutes les topographies de grille.
- Faire un système qui échoue gracieusement et de manière limitée si une partie devient surchargée. (Le temps nécessaire à la copie d'un grand ensemble de données limitera toujours la capacité du système à faire face à l'augmentation soudaine de la demande d'un ensemble de données spécifique.)
- (Si possible) Pour faire une architecture qui n'est liée à aucune calcul en nuage services ou autres services externes (parce qu'il n'en a pas besoin) .
Recommandations
Nos recommandations sont
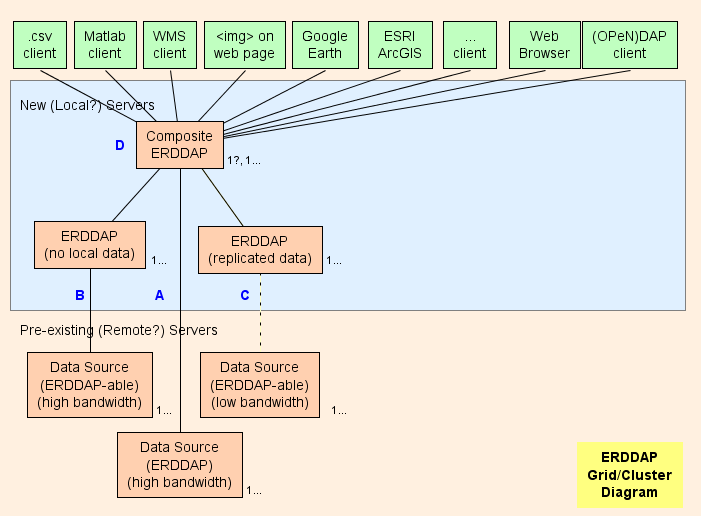
- En gros, je suggère de mettre en place un Composite ERDDAP™ ( D dans le diagramme) , qui est un ERDDAP™ sauf qu'il sert seulement des données d'autres ERDDAP Par. L'architecture de la grille est conçue pour déplacer le plus de travail possible (Utilisation du processeur, utilisation de la mémoire, utilisation de la bande passante) du Composite ERDDAP™ à l'autre ERDDAP Par.
- ERDDAP™ a deux types de données spécifiques, EDDGrid DeErddap et EDDTableDeErddap , qui se réfèrent à ensembles de données sur les autres ERDDAP Par.
- Lorsque le composite ERDDAP™ reçoit une demande de données ou d'images de ces ensembles de données, le composite ERDDAP™ redirections la demande de données à l'autre ERDDAP™ serveur. Le résultat est:
- C'est très efficace (CPU, mémoire et bande passante) , parce que autrement
- Le composite ERDDAP™ doit envoyer la demande de données à l'autre ERDDAP .
- L'autre ERDDAP™ doit obtenir les données, les reformater et les transmettre au composite ERDDAP .
- Le composite ERDDAP™ doit recevoir les données (utilisant une bande passante supplémentaire) , reformater (utilisant le temps et la mémoire CPU supplémentaires) , et transmettre les données à l'utilisateur (utilisant une bande passante supplémentaire) . En redirigeant la demande de données et en autorisant l'autre ERDDAP™ pour envoyer la réponse directement à l'utilisateur, le composite ERDDAP™ dépense essentiellement aucun temps CPU, mémoire ou bande passante sur les demandes de données.
- La redirection est transparente pour l'utilisateur quel que soit le logiciel client (un navigateur ou tout autre logiciel ou outil de ligne de commande) .
- C'est très efficace (CPU, mémoire et bande passante) , parce que autrement
Pièces de grille
Les parties de la grille sont:
A : Pour chaque source de données distante ayant une largeur de bande élevée OPeNDAP serveur, vous pouvez vous connecter directement au serveur distant. Si le serveur distant est un ERDDAP™ , utiliser EDDGrid DeErddap ou EDDTableDe ERDDAP pour servir les données dans le Composite ERDDAP . Si le serveur distant est un autre type de DAP serveur, p.ex. Hyrax , ou GrADS, utiliser EDDGrid De Dap.
B : Pour chaque ERDDAP - source de données utilisable (une source de données à partir de laquelle ERDDAP peut lire des données) qui a un serveur haut débit, ERDDAP™ dans la grille qui est chargée de fournir les données de cette source de données.
- Si plusieurs ERDDAP s ne reçoivent pas beaucoup de demandes de données, vous pouvez les regrouper en une seule ERDDAP .
- Si ERDDAP™ dédiée à obtenir des données d'une source distante est obtenir trop de requêtes, il ya une tentation d'ajouter ERDDAP s pour accéder à la source de données distante. Dans des cas particuliers, cela peut avoir un sens, mais il est plus probable que cela submergera la source de données distante (qui se défait) et empêche également les autres utilisateurs d'accéder à la source de données distante (ce qui n'est pas gentil) . Dans un tel cas, envisager de créer une autre ERDDAP™ pour servir cet ensemble de données et copier l'ensemble de données sur ce ERDDAP Le disque dur (voir C ) , peut-être avec EDDGrid Copier et/ou EDDTableCopy .
- B les serveurs doivent être accessibles au public.
C : Pour chaque ERDDAP -source de données à faible bande (ou est un service lent pour d'autres raisons) , envisager de créer une autre ERDDAP™ et stockant une copie de l'ensemble de données ERDDAP les disques durs, peut-être avec EDDGrid Copier et/ou EDDTableCopy . Si plusieurs ERDDAP s ne reçoivent pas beaucoup de demandes de données, vous pouvez les regrouper en une seule ERDDAP . C les serveurs doivent être accessibles au public.
Composite ERDDAP
D : Le composite ERDDAP™ est un régulier ERDDAP™ sauf qu'il sert seulement des données d'autres ERDDAP Par.
- Parce que le composite ERDDAP™ a des informations en mémoire de tous les ensembles de données, il peut répondre rapidement aux demandes de listes de ensembles de données (recherche texte complet, recherche de catégorie, la liste de tous les ensembles de données) , et les demandes pour un formulaire d'accès aux données d'un ensemble de données, faire un formulaire graphique, ou WMS page d'information. Ce sont toutes de petites pages HTML, générées dynamiquement, basées sur des informations qui sont conservées en mémoire. Les réponses sont donc très rapides.
- Parce que les demandes de données réelles sont rapidement redirigées vers l'autre ERDDAP s, le composé ERDDAP™ peut répondre rapidement aux demandes de données réelles sans utiliser de temps, de mémoire ou de bande passante CPU.
- En déplaçant autant de travail que possible (CPU, mémoire, bande passante) du Composite ERDDAP™ à l'autre ERDDAP s, le composé ERDDAP™ peut sembler servir des données de tous les ensembles de données et néanmoins se tenir au courant d'un très grand nombre de demandes de données émanant d'un grand nombre d'utilisateurs.
- Les essais préliminaires indiquent que les ERDDAP™ peut répondre à la plupart des demandes dans ~1ms de temps CPU, ou 1000 requêtes/seconde. Un processeur de 8 cœurs devrait donc pouvoir répondre à environ 8000 requêtes/seconde. Bien qu'il soit possible d'envisager des explosions d'activité plus élevée qui provoqueraient des ralentissements, c'est beaucoup de rendement. Il est probable que la bande passante du centre de données sera le goulot d'étranglement bien avant le composite ERDDAP™ devient le goulot d'étranglement.
Mise à jour max (heure) ?
Les EDDGrid /TableFromErddap dans le composite ERDDAP™ ne change que les informations stockées sur chaque ensemble de données source lorsque l'ensemble de données source est "recharger" et quelques modifications de métadonnées (Par exemple, la variable temporelle actual\_range ) , générant ainsi une notification d'abonnement. Si l'ensemble de données source a des données qui changent fréquemment (Par exemple, de nouvelles données chaque seconde) et utilise les "mise à jour" système pour remarquer les changements fréquents aux données sous-jacentes, EDDGrid /TableFromErddap ne sera pas informé de ces changements fréquents jusqu'à ce que le prochain jeu de données "recharge", donc le EDDGrid /TableFromErddap ne sera pas parfaitement à jour. Vous pouvez minimiser ce problème en modifiant les données source<recharger chaque NMinutes> à une valeur moindre (60 ? 15 ?) pour qu'il y ait plus de notifications d'abonnement EDDGrid /TableFromErddap pour mettre à jour ses informations sur l'ensemble de données source.
Ou, si votre système de gestion des données sait quand l'ensemble de données source a de nouvelles données (Par exemple, via un script qui copie un fichier de données en place) , et si ce n'est pas super fréquent (Par exemple, toutes les 5 minutes ou moins) , il y a une meilleure solution:
- Ne pas utiliser<mettre à jour chaque NMillis> pour tenir l'ensemble de données source à jour.
- Définir les données de la source<recharger chaque NMinutes> à un plus grand nombre (1440 ?) .
- Demandez au script de contacter l'ensemble de données source URL du drapeau juste après avoir copié un nouveau fichier de données en place. Cela permettra à l'ensemble de données source d'être parfaitement à jour et de générer une notification d'abonnement, qui sera envoyée au EDDGrid /TableFromErddap dataset. Cela conduira à EDDGrid /TableFromErddap dataset pour être parfaitement à jour (Eh bien, dans les 5 secondes de l'ajout de nouvelles données) . Et tout ce qui sera fait efficacement (sans recharge de données inutiles) .
Composite multiple ERDDAP s
- Dans des cas très extrêmes, ou pour la tolérance aux défauts, vous pouvez vouloir mettre en place plus d'un composite ERDDAP . Il est probable que d'autres parties du système (notamment, la bande passante du centre de données) deviendra un problème bien avant le composite ERDDAP™ devient un goulot d'étranglement. Donc la solution est probablement de mettre en place des centres de données supplémentaires, géographiquement divers (miroirs) , chacun avec un composite ERDDAP™ et serveurs avec ERDDAP s et (au moins) des copies miroirs des ensembles de données qui sont en forte demande. Une telle configuration fournit également la tolérance aux défauts et la sauvegarde des données (par copie) . Dans ce cas, il est préférable que le composite ERDDAP s ont des URLs différentes.
Si vous voulez vraiment tout le composite ERDDAP s pour avoir la même URL, utilisez un système frontal qui assigne un utilisateur donné à un seul des composites ERDDAP s (basé sur l'adresse IP) , de sorte que toutes les demandes de l'utilisateur vont à une seule des ERDDAP Par. Il y a deux raisons:
- Lorsqu'un ensemble de données sous-jacent est rechargé et que les métadonnées changent (Par exemple, un nouveau fichier de données dans un ensemble de données maillées provoque la variation de temps actual\_range changer) , le ERDDAP s sera temporairement légèrement hors de synch, mais avec cohérence éventuelle . Normalement, ils ré-synchent dans les 5 secondes, mais parfois ce sera plus long. Si un utilisateur fait un système automatisé qui s'appuie sur ERDDAP™ abonnements qui déclenchent des actions, les brefs problèmes de synchronisation deviendront importants.
- Le composé 2+ ERDDAP s chacun tient ses propres abonnements (en raison du problème de synchronisation décrit ci-dessus) .
Donc, un utilisateur donné devrait être dirigé vers un seul des composites ERDDAP s pour éviter ces problèmes. Si l'un des composés ERDDAP s descend, le système frontal peut rediriger ERDDAP Les utilisateurs à un autre ERDDAP™ C'est fini. Cependant, s'il s'agit d'un problème de capacité qui cause le premier composite ERDDAP™ à échouer (un utilisateur trop zélé ? a attaque de déni de service ?) , ce qui rend très probable que la réorientation de ses utilisateurs vers d'autres composites ERDDAP s provoquera défaillance en cascade . Ainsi, la configuration la plus robuste est d'avoir composite ERDDAP s avec différentes URLs.
Ou, peut-être mieux, installer plusieurs composites ERDDAP s sans équilibre de charge. Dans ce cas, vous devriez faire un point de donner chacun des ERDDAP s un nom / identité différent et si possible les mettre en place dans différentes parties du monde (Par exemple, différentes régions de l'AWS) , par exemple, ERD \_US\_Est, ERD \_US\_Ouest, ERD \_IE, ERD \_FR, ERD \_IT, de sorte que les utilisateurs travaillent consciemment avec un ERDDAP .
- \[ Pour une conception fascinante d'un système haute performance fonctionnant sur un serveur, voir ceci description détaillée de Mailinator . \]
Données en très forte demande
Dans le cas vraiment inhabituel que l'un des A , B ou C ERDDAP s ne peut pas suivre les demandes en raison des limitations de bande passante ou de disque dur, il est logique de copier les données (encore) sur un autre serveur+hard Démarrer+ ERDDAP , peut-être avec EDDGrid Copier et/ou EDDTableCopy . Bien qu'il puisse sembler idéal d'avoir l'ensemble de données original et l'ensemble de données copié apparaissent parfaitement comme un ensemble de données dans le composite ERDDAP™ , c'est difficile parce que les deux ensembles de données seront dans des états légèrement différents à des moments différents (notamment, après que l'original obtient de nouvelles données, mais avant que l'ensemble de données copié obtient sa copie) . Par conséquent, je recommande que les ensembles de données soient donnés des titres légèrement différents (Par exemple, "... (copie #1) "et "... (exemplaire #2) ", ou peut - être " (miroir N ) " ou " (serveur # N ) ") et apparaissent comme ensembles de données séparés dans le composite ERDDAP . Les utilisateurs sont habitués à voir des listes de sites miroirs sur les sites de téléchargement de fichiers populaires, donc cela ne devrait pas les surprendre ou les décevoir. En raison des limites de bande passante sur un site donné, il peut être logique d'avoir le miroir situé sur un autre site. Si la copie miroir se trouve dans un centre de données différent, accessible uniquement par le composite de ce centre de données ERDDAP™ , les différents titres (Par exemple, "miroir #1) ne sont pas nécessaires.
RAID versus disques durs réguliers
Si un grand jeu de données ou un groupe de ensembles de données ne sont pas fortement utilisés, il peut être logique de stocker les données sur un RAID puisqu'il offre une tolérance aux défauts et que vous n'avez pas besoin de la puissance de traitement ou de la bande passante d'un autre serveur. Mais si un ensemble de données est fortement utilisé, il peut être plus logique de copier les données sur un autre serveur + ERDDAP™ + disque dur (similaire à ce que Google fait ) plutôt que d'utiliser un serveur et un RAID pour stocker plusieurs ensembles de données puisque vous pouvez utiliser les deux serveurs+hardDrive+ ERDDAP s dans la grille jusqu'à ce que l'un d'eux échoue.
Défauts
Et si...
- Il y a une explosion de demandes pour un ensemble de données (Par exemple, tous les élèves d'une classe demandent simultanément des données similaires) ? Seul le ERDDAP™ servir cet ensemble de données sera submergé et ralentira ou refusera les demandes. Le composite ERDDAP™ et autres ERDDAP S ne sera pas affecté. Puisque le facteur limite pour un ensemble de données donné dans le système est le disque dur avec les données (pas ERDDAP ) , la seule solution (pas immédiatement) est de faire une copie de l'ensemble de données sur un serveur différent+hardDrive+ ERDDAP .
- Une A , B ou C ERDDAP™ échoue (Par exemple, défaillance du disque dur) ? Seul l'ensemble de données (s) servi par cela ERDDAP™ sont affectés. Si l'ensemble de données (s) est en miroir sur un autre serveur+hardDrive+ ERDDAP , l'effet est minime. Si le problème est une panne de disque dur dans un niveau 5 ou 6 RAID, vous remplacez simplement le disque et faites reconstruire les données RAID sur le disque.
- Le composite ERDDAP™ échoue ? Si vous voulez faire un système avec très haute disponibilité , vous pouvez installer multiples composites ERDDAP s (comme indiqué ci-dessus) , en utilisant quelque chose comme NGINX ou Traefik pour gérer l'équilibrage de la charge. Noter qu'un composite donné ERDDAP™ peut traiter un très grand nombre de demandes d'un grand nombre d'utilisateurs parce que les demandes de métadonnées sont petites et sont traitées par des informations qui sont en mémoire; Demandes de données (qui peuvent être grandes) sont redirigés vers l'enfant ERDDAP Par.
Simple, évolutive
Ce système est facile à mettre en place et à administrer, et facilement extensible quand une partie de celui-ci devient surchargée. Les seules limites réelles pour un centre de données donné sont la bande passante du centre de données et le coût du système.
Bande passante
Remarquez la bande passante approximative des composants couramment utilisés du système:
| Composante | Bande passante approximative (Goytes/s) |
|---|---|
| Mémoire DDR | 2,5 |
| Lecteur SSD | 1 |
| Disque dur SATA | 0,3 |
| Ethernet Gigabit | 0,1 |
| OC-12 | 0,06 |
| OC-3 | 0,015 |
| T1 | 0,0002 |
Donc, un disque dur SATA (0,3 Go/s) sur un serveur avec un ERDDAP™ peut probablement saturer un LAN Ethernet Gigabit (0,1 Go/s) . Et un réseau Ethernet Gigabit (0,1 Go/s) peut probablement saturer une connexion Internet OC-12 (0,06 Go/s) . Et au moins une source énumère les lignes OC-12 qui coûtent environ 100 000 $ par mois. (Oui, ces calculs sont basés sur le fait de pousser le système à ses limites, ce qui n'est pas bon parce qu'il conduit à des réponses très lentes. Mais ces calculs sont utiles pour la planification et l'équilibrage des parties du système.) De toute évidence, une connexion Internet suffisamment rapide pour votre centre de données est de loin la partie la plus chère du système. Vous pouvez facilement et relativement bon marché construire une grille avec une douzaine de serveurs fonctionnant une douzaine ERDDAP s qui est capable de pomper beaucoup de données rapidement, mais une connexion Internet suffisamment rapide sera très, très cher. Les solutions partielles sont:
- Encourager les clients à demander des sous-ensembles de données si c'est tout ce qui est nécessaire. Si le client a seulement besoin de données pour une petite région ou à une résolution inférieure, c'est ce qu'il devrait demander. La subs truction est au centre des protocoles ERDDAP™ soutien pour demander des données.
- Encourager la transmission de données compressées. ERDDAP™ compresses une transmission de données si elle trouve "encodage d'acceptation" HTTP GET en-tête de demande. Tous les navigateurs web utilisent le "encodage d'acceptation" et décompressent automatiquement la réponse. Autres clients (Par exemple, programmes informatiques) doivent l'utiliser explicitement.
- Colocatez vos serveurs sur un FAI ou un autre site qui offre des coûts de bande passante relativement moins élevés.
- Dispersez les serveurs avec le ERDDAP s à différentes institutions afin que les coûts soient dispersés. Vous pouvez alors lier votre composite ERDDAP™ à leur ERDDAP Par.
Notez que Informatique en nuage et les services d'hébergement web offrent toute la bande passante Internet dont vous avez besoin, mais ne résolvez pas le problème de prix.
Pour des informations générales sur la conception de systèmes évolutifs, de haute capacité, tolérants aux défauts, voir le livre de Michael T. Nygard Libérez-le .
Comme les Legos
Les concepteurs de logiciels essaient souvent d'utiliser le bon modèles de conception de logiciels résoudre des problèmes. De bons modèles sont bons parce qu'ils encapsulent bon, facile à créer et à travailler avec, des solutions d'usage général qui conduisent à des systèmes avec de bonnes propriétés. Les noms de modèles ne sont pas standardisés, donc je vais appeler le modèle qui ERDDAP™ utilise le modèle Lego. Chaque Lego (chaque ERDDAP ) est un simple, petit, standard, autonome, brique (serveur de données) avec une interface définie qui lui permet d'être lié à d'autres legos ( ERDDAP s) . Les parties de ERDDAP™ qui composent ce système sont: les systèmes d'abonnement et flagURL (qui permet la communication entre ERDDAP s) L'EDD... De système de redirection d'Erddap, et le système de RESTful demandes de données pouvant être générées par des utilisateurs ou d'autres ERDDAP Par. Ainsi, avec deux ou plusieurs legos ( ERDDAP s) , vous pouvez créer un grand nombre de formes différentes (topologies du réseau ERDDAP s) . Bien sûr, le design et les caractéristiques de ERDDAP™ aurait pu être fait différemment, pas comme Lego, peut-être juste pour permettre et optimiser pour une topologie spécifique. Mais nous sentons que ERDDAP 's Lego-like design offre une bonne, la solution d'usage général qui permet ERDDAP™ administrateur (ou groupe d'administrateurs) créer toutes sortes de topologies de fédération différentes. Par exemple, une seule organisation pourrait créer trois (ou plus) ERDDAP s comme indiqué dans ERDDAP™ Diagramme Grid/Cluster ci-dessus . Ou un groupe distribué (Ça va ? Garde-côte ? NCEI ? Les NWS ? NOAA ? Les USGS ? DataONE ? Neon ? Plus tard ? - Oui ? C'est ça ? Oui ? JRC ? L'OMM ?) peut mettre en place un ERDDAP™ dans chaque petit avant-poste (pour que les données restent proches de la source) puis mettre en place un composite ERDDAP™ dans le bureau central avec des ensembles de données virtuels (qui sont toujours parfaitement à jour) de chaque petit avant-poste ERDDAP Par. En effet, tous les ERDDAP s, installés dans diverses institutions à travers le monde, qui obtiennent des données d'autres ERDDAP s et/ou fournir des données à d'autres ERDDAP s, forment un réseau géant de ERDDAP Par. C'est cool ?! Ainsi, comme pour Lego, les possibilités sont infinies. C'est pourquoi c'est un bon modèle. C'est pourquoi c'est un bon design pour ERDDAP .
Types de demandes
L'une des complications réelles de cette discussion des topologies des serveurs de données est qu'il existe différents types de requêtes et différentes façons d'optimiser les différents types de requêtes. Il s'agit essentiellement d'une question distincte. (Combien de temps le ERDDAP™ avec les données répondre à la demande de données?) de la discussion topologique (qui traite des relations entre les serveurs de données et quel serveur possède les données réelles) . ERDDAP™ , bien sûr, essaie de traiter tous les types de demandes efficacement, mais traite certaines mieux que d'autres.
- De nombreuses demandes sont simples. Par exemple: Quelles sont les métadonnées de cet ensemble de données? Ou : Quelles sont les valeurs de la dimension temporelle de cet ensemble de données maillées ? ERDDAP™ est conçu pour les manipuler le plus rapidement possible (habituellement dans<=2 ms) en conservant cette information en mémoire.
- Certaines demandes sont modérément difficiles. Par exemple: Donnez-moi ce sous-ensemble de données (qui est dans un fichier de données) . Ces demandes peuvent être traitées relativement rapidement parce qu'elles ne sont pas si difficiles.
- Certaines demandes sont difficiles et exigent donc beaucoup de temps. Par exemple: Donnez-moi ce sous-ensemble de données (qui pourrait être dans l'un des 10 000 fichiers de données, ou pourrait être à partir de fichiers de données compressés qui prennent chacun 10 secondes pour décompresser) . ERDDAP™ v2.0 a introduit de nouvelles façons plus rapides de traiter ces demandes, notamment en permettant au thread de traitement des requêtes de générer plusieurs threads de travailleurs qui abordent différents sous-ensembles de la demande. Mais il y a une autre approche de ce problème qui ERDDAP™ ne supporte pas encore : des sous-ensembles de fichiers de données pour un ensemble de données donné pourraient être stockés et analysés sur des ordinateurs séparés, puis les résultats combinés sur le serveur original. Cette approche s'appelle CarteRéduire et est illustré par Hadoop , le premier (?) open-source MapReduce programme, qui était basé sur des idées d'un papier Google. (Si vous avez besoin de MapReduce dans ERDDAP , merci d'envoyer une demande par e-mail à erd.data at noaa.gov .) Google BigQuery est intéressant parce qu'il semble être une mise en œuvre de MapReduce appliquée à des ensembles de données tabulaires subsetting, qui est l'un des ERDDAP Les principaux objectifs. Il est probable que vous pouvez créer un ERDDAP™ dataset d'un jeu de données BigQuery via EDDTableFromDatabase car BigQuery est accessible via une interface JDBC.
Ce sont mes opinions.
Oui, les calculs sont simplistes. (et maintenant légèrement daté) , mais je pense que les conclusions sont correctes. Ai-je utilisé une logique erronée ou fait une erreur dans mes calculs? Si oui, la faute est la mienne seule. Veuillez envoyer un email avec la correction erd dot data at noaa dot gov .
-
- Oui.
Informatique en nuage
Plusieurs entreprises offrent des services de cloud computing (Par exemple, Services Web Amazon et Plateforme Google Cloud ) . Entreprises d'hébergement Web ont offert des services plus simples depuis le milieu des années 1990, mais les services «cloud» ont considérablement élargi la flexibilité des systèmes et la gamme de services offerts. Depuis le ERDDAP™ quadrillage se compose de ERDDAP s et depuis ERDDAP s sont Java applications web qui peuvent fonctionner dans Tomcat (le serveur d'applications le plus courant) ou d'autres serveurs d'application, il devrait être relativement facile de configurer un ERDDAP™ réseau sur un service cloud ou un site web d'hébergement. Les avantages de ces services sont les suivants:
- Ils offrent un accès à des connexions Internet à très haute bande passante. Cela seul peut justifier l'utilisation de ces services.
- Ils ne facturent que les services que vous utilisez. Par exemple, vous avez accès à une connexion Internet à bande passante très élevée, mais vous ne payez que pour les données réellement transférées. Cela vous permet de construire un système qui est rarement submergé (même à la demande maximale) , sans devoir payer pour une capacité rarement utilisée.
- Ils sont facilement extensibles. Vous pouvez modifier les types de serveurs ou ajouter autant de serveurs ou de stockage que vous le souhaitez, en moins d'une minute. Cela seul peut justifier l'utilisation de ces services.
- Ils vous libèrent de nombreuses tâches administratives de l'exploitation des serveurs et des réseaux. Cela seul peut justifier l'utilisation de ces services.
Les inconvénients de ces services sont les suivants:
- Ils facturent pour leurs services, parfois beaucoup (en termes absolus; pas qu'il ne soit pas une bonne valeur) . Les prix indiqués ici sont pour Amazone CE2 . Ces prix (en juin 2015) Je vais descendre.
Dans le passé, les prix étaient plus élevés, mais les fichiers de données et le nombre de demandes étaient plus faibles.
À l'avenir, les prix seront plus bas, mais les fichiers de données et le nombre de demandes seront plus importants.
Donc les détails changent, mais la situation reste relativement constante.
Et ce n'est pas que le service est trop cher, c'est que nous utilisons et achetons beaucoup de service.
- Transfert de données — Les transferts de données dans le système sont désormais gratuits (Ouais !) . Les transferts de données hors du système sont $0.09/GB. Un disque dur SATA (0,3 Go/s) sur un serveur avec un ERDDAP™ peut probablement saturer un LAN Ethernet Gigabit (0,1 Go/s) . Un réseau local Ethernet Gigabit (0,1 Go/s) peut probablement saturer une connexion Internet OC-12 (0,06 Go/s) . Si une connexion OC-12 peut transmettre environ 150 000 Go/mois, les coûts de transfert de données pourraient atteindre 150 000 Go @ 0,09/ Go = 13 500 $/mois, ce qui représente un coût important. De toute évidence, si vous avez une douzaine de travailleurs ERDDAP s sur un service cloud, vos frais mensuels de transfert de données pourraient être importants (jusqu ' à 162 000 dollars par mois) . (Encore une fois, ce n'est pas que le service est surévalué, c'est que nous utilisons et achetons beaucoup de service.)
- Stockage des données — Amazon facture 50 $ par mois par TB. (Comparez cela à l'achat d'une entreprise de 4TB conduire carrément pour ~50$/TB, bien que le RAID de mettre dans et les coûts administratifs ajoutent au coût total.) Donc, si vous avez besoin de stocker beaucoup de données dans le cloud, il pourrait être assez cher (100 TB coûterait 5 000 $ par mois.) . Mais à moins d'avoir une grande quantité de données, il s'agit d'un problème plus petit que les coûts de transfert de bande passante/données. (Encore une fois, ce n'est pas que le service est surévalué, c'est que nous utilisons et achetons beaucoup de service.)
Sous-position
- Le problème de subsistance: La seule façon de distribuer efficacement les données des fichiers de données est d'avoir le programme qui distribue les données (Par exemple, ERDDAP ) exécuter sur un serveur qui a les données stockées sur un disque dur local (ou un accès aussi rapide à un RAID local ou SAN) . Les systèmes de fichiers locaux permettent ERDDAP™ (et bibliothèques sous-jacentes, comme netcdf-java) pour demander des octets spécifiques vont des fichiers et obtenir des réponses très rapidement. De nombreux types de demandes de données ERDDAP™ dans le fichier (notamment les demandes de données maillées où la valeur de la marche est > 1) ne peut pas être fait efficacement si le programme doit demander le fichier entier ou gros morceaux d'un fichier à partir d'un non-local (donc plus lentement) système de stockage de données, puis extraire un sous-ensemble. Si la configuration du cloud ne donne pas ERDDAP™ accès rapide aux gammes d'octets des fichiers (aussi vite qu'avec les fichiers locaux) , ERDDAP 'l'accès aux données sera un goulot d'étranglement sévère et de nier d'autres avantages de l'utilisation d'un service cloud.
Données hébergées
Une alternative à l'analyse coûts-avantages ci-dessus (qui est basé sur le propriétaire des données (Par exemple, NOAA ) payer pour que leurs données soient stockées dans le cloud) est arrivé vers 2012, quand Amazon (et dans une moindre mesure, certains autres fournisseurs de cloud) a commencé à héberger certains ensembles de données dans leur cloud (AWS S3) gratuitement (probablement avec l'espoir qu'ils pourraient récupérer leurs coûts si les utilisateurs louaient des instances de calcul AWS EC2 pour travailler avec ces données) . De toute évidence, cela rend l'informatique en nuage beaucoup plus rentable, car le temps et les coûts de téléchargement des données et d'hébergement sont désormais nuls. Avec ERDDAP™ v2.0, il existe de nouvelles fonctionnalités pour faciliter l'exécution ERDDAP dans un nuage:
- Maintenant, un EDDGrid FromFiles ou EDDTableFromFiles peuvent être créés à partir de fichiers de données qui sont distants et accessibles via Internet (Par exemple, les seaux AWS S3) en utilisant<cacheFromUrl> et<Taille du cache GB> options. ERDDAP™ conservera un cache local des fichiers de données les plus récemment utilisés.
- Maintenant, si les fichiers sources EDDTableFromFiles sont compressés (Par exemple, .tgz ) , ERDDAP™ va automatiquement les décompresser quand il les lit.
- Maintenant, les ERDDAP™ le fil répondant à une demande donnée créera des fils de travail pour travailler sur les sous-sections de la demande si vous utilisez le<nThreads> options. Cette parallélisation devrait permettre de répondre plus rapidement aux demandes difficiles.
Ces changements résolvent le problème de AWS S3 n'offrant pas de stockage de fichiers local, de niveau bloc et le (vieux) problème d'accès aux données S3 avec un décalage important. (Il y a des années (~2014) , ce décalage était significatif, mais il est maintenant beaucoup plus court et n'est pas aussi significatif.) Dans l'ensemble, cela signifie que la mise en place ERDDAP™ dans le nuage fonctionne beaucoup mieux maintenant.
Je vous remercie. — Merci beaucoup à Matthew Arrott et à son groupe dans l'effort original OOI pour leur travail sur la mise ERDDAP™ dans le nuage et les discussions qui en résultent.
-
- Oui.
Réplication à distance des ensembles de données
Il y a un problème commun qui est lié à la discussion ci-dessus des grilles et fédérations de ERDDAP s: réplication à distance des ensembles de données. Le problème de base est : un fournisseur de données maintient un ensemble de données qui change occasionnellement et un utilisateur veut maintenir une copie locale à jour de cet ensemble de données (pour une variété de raisons) . De toute évidence, il y a un grand nombre de variations. Certaines variations sont beaucoup plus difficiles à gérer que d'autres.
- Mises à jour rapides C'est plus difficile de tenir les données locales à jour immédiatement (Par exemple, dans les 3 secondes) après chaque changement de la source, plutôt que, par exemple, en quelques heures.
- Changements fréquents Les changements fréquents sont plus difficiles à gérer que les changements peu fréquents. Par exemple, les changements une fois par jour sont beaucoup plus faciles à gérer que les changements toutes les 0,1 seconde.
- Petits changements Les petites modifications apportées à un fichier source sont plus difficiles à traiter qu'un fichier entièrement nouveau. Ceci est particulièrement vrai si les petits changements peuvent être n'importe où dans le fichier. De petits changements sont plus difficiles à détecter et rendent difficile l'isolement des données à reproduire. De nouveaux fichiers sont faciles à détecter et efficaces à transférer.
- Ensemble de données Il est plus difficile de tenir un ensemble de données à jour que de maintenir des données récentes. Certains utilisateurs ont juste besoin de données récentes (Par exemple, la valeur des 8 derniers jours) .
- Copies multiples Il est plus difficile de conserver plusieurs copies distantes à différents sites que de conserver une copie distante. C'est le problème de l'échelle.
Il y a évidemment un grand nombre de variations des types possibles de modifications de l'ensemble de données source et des besoins et attentes de l'utilisateur. Beaucoup de ces variations sont très difficiles à résoudre. La meilleure solution pour une situation n'est souvent pas la meilleure solution pour une autre situation — il n'y a pas encore une grande solution universelle.
Objet ERDDAP™ Outils
ERDDAP™ offre plusieurs outils qui peuvent être utilisés dans le cadre d'un système qui cherche à maintenir une copie à distance d'un ensemble de données:
- ERDDAP 's RSS (Sommaire du site riche?) service
offre un moyen rapide de vérifier si un jeu de données sur une télécommande ERDDAP™ a changé. - ERDDAP 's service d'abonnement
est plus efficace (que RSS ) approche : elle enverra immédiatement un courriel ou contactera une URL à chaque abonné chaque fois que l'ensemble de données est mis à jour et que la mise à jour entraîne un changement. Il est efficace dans la mesure où il se produit au plus vite et il n'y a pas d'effort gaspillé (comme pour le scrutin RSS service) . Les utilisateurs peuvent utiliser d'autres outils (comme IFTTT ) réagir aux notifications par courriel du système d'abonnement. Par exemple, un utilisateur pourrait s'abonner à un jeu de données sur une télécommande ERDDAP™ et utiliser IFTTT pour réagir aux notifications par e-mail d'abonnement et déclencher la mise à jour de l'ensemble de données locales. - ERDDAP 's Système de drapeau
fournit un moyen pour ERDDAP™ administrateur de dire un ensemble de données sur son/sa ERDDAP pour recharger au plus vite. La forme URL d'un drapeau peut facilement être utilisée dans les scripts. La forme URL d'un drapeau peut également être utilisée comme action pour un abonnement. - ERDDAP 's "files" système
peut offrir un accès aux fichiers sources pour un ensemble de données donné, y compris une liste de répertoires de style Apache des fichiers (un "dossier accessible au Web") qui a l'URL de téléchargement de chaque fichier, la dernière heure modifiée, et la taille. Un inconvénient de l'utilisation de "files" système est que les fichiers source peuvent avoir des noms de variables et des métadonnées différentes de l'ensemble de données tel qu'il apparaît dans ERDDAP . Si une télécommande ERDDAP™ dataset offre un accès à ses fichiers sources, qui ouvre la possibilité d'une version de rsync d'un pauvre homme: il devient facile pour un système local de voir quels fichiers distants ont changé et doivent être téléchargés. (Voir option cacheFromUrl ci-dessous qui peut faire usage de ceci.)
Solutions
Bien qu'il y ait un grand nombre de variations au problème et un nombre infini de solutions possibles, il n'y a qu'une poignée d'approches de base pour les solutions:
Solutions personnalisées, Brute Force
Une solution évidente est de fabriquer à la main une solution personnalisée, qui est donc optimisée pour une situation donnée: faire un système qui détecte/identifie quelles données ont changé, et envoyer ces informations à l'utilisateur afin que l'utilisateur puisse demander les données modifiées. Vous pouvez le faire, mais il y a des inconvénients :
- Les solutions personnalisées sont beaucoup de travail.
- Les solutions personnalisées sont généralement si personnalisées à un ensemble de données donné et au système de l'utilisateur qu'elles ne peuvent pas être facilement réutilisées.
- Des solutions personnalisées doivent être construites et entretenues par vous. (Ce n'est jamais une bonne idée. C'est toujours une bonne idée d'éviter le travail et d'amener quelqu'un d'autre à faire le travail!)
Je déconseille cette approche parce qu'il est presque toujours préférable de chercher des solutions générales, construites et entretenues par quelqu'un d'autre, qui peuvent être facilement réutilisées dans différentes situations.
Rsync
Rsync est la solution existante, étonnamment bonne, d'usage général pour garder une collection de fichiers sur un ordinateur source en synchronisation sur l'ordinateur distant d'un utilisateur. Son fonctionnement est le suivant :
- un événement (Par exemple, ERDDAP™ événement du système d'abonnement) déclenche rsync, (ou, un travail cron exécute rsync à des moments spécifiques tous les jours sur l'ordinateur de l'utilisateur)
- qui contacte rsync sur l'ordinateur source,
- qui calcule une série de haches pour des morceaux de chaque fichier et transmet ces haches au rsync de l'utilisateur,
- qui compare ces informations aux informations similaires pour la copie des fichiers par l'utilisateur,
- qui demande ensuite les morceaux de fichiers qui ont changé.
Considérant tout ce qu'il fait, rsync fonctionne très rapidement (Par exemple, 10 secondes plus le temps de transfert de données) et très efficace. Il y a variations de rsync qui optimisent pour différentes situations (Par exemple, en précalculant et en tachant les haches des morceaux de chaque fichier source) .
Les principales faiblesses de rsync sont les suivantes: (questions de sécurité) ; il y a des problèmes d'échelle; et ce n'est pas bon pour garder les ensembles de données NRT vraiment à jour (Par exemple, il est gênant d'utiliser Rsync plus d'environ toutes les 5 minutes) . Si vous pouvez faire face aux faiblesses, ou si elles n'affectent pas votre situation, rsync est une excellente solution à usage général que tout le monde peut utiliser dès maintenant pour résoudre de nombreux scénarios impliquant la réplication à distance des ensembles de données.
Il y a un article sur le ERDDAP™ Pour faire la liste pour essayer d'ajouter le support des services rsync à ERDDAP (probablement une tâche assez difficile) , afin que tout client puisse utiliser rsync (ou une variante) maintenir une copie à jour d'un ensemble de données. Si quelqu'un veut travailler dessus, s'il vous plaît email erd.data at noaa.gov .
Il y a d'autres programmes qui font plus ou moins ce que rsync fait, parfois orientés vers la réplication des ensembles de données (bien que souvent au niveau de la copie de fichiers) , par exemple, Unidata 's DJA .
Cache de Url
Le cacheFromUrl réglage est disponible (commençant par ERDDAP™ v2.0) pour tous les ERDDAP les types de données qui font des ensembles de données à partir de fichiers (fondamentalement, toutes les sous-classes EDDGrid Fichiers et EDDTableFromFiles ) . cache FromUrl rend trivial de télécharger automatiquement et de maintenir les fichiers de données locales en les copiant à partir d'une source distante via le cache De la configuration d'Url. Les fichiers distants peuvent être dans un dossier Web Accessible ou une liste de fichiers de type répertoire proposée par THREDDS, Hyrax , un seau S3, ou ERDDAP 's "files" système.
Si la source des fichiers distants est une télécommande ERDDAP™ dataset qui offre les fichiers source via le ERDDAP™ "files" système, alors vous pouvez abonnement à l'ensemble de données distant, et utiliser URL du drapeau pour votre ensemble de données local comme action pour l'abonnement. Ensuite, chaque fois que l'ensemble de données à distance change, il contactera l'URL du drapeau pour votre ensemble de données, qui lui dira de recharger ASAP, qui détectera et téléchargera les fichiers de données à distance modifiés. Tout cela arrive très rapidement (habituellement ~5 secondes plus le temps nécessaire pour télécharger les fichiers modifiés) . Cette approche fonctionne bien si les modifications de l'ensemble de données source sont de nouveaux fichiers étant ajoutés périodiquement et lorsque les fichiers existants ne changent jamais. Cette approche ne fonctionne pas bien si les données sont fréquemment jointes à tous (ou plus) des fichiers de données source existants, parce que votre ensemble de données local est fréquemment télécharger l'ensemble des données distantes. (C'est là qu'une approche de type rsync est nécessaire.)
ArchiveADataset
ERDDAP™ 's ArchiveADataset est une bonne solution lorsque les données sont ajoutées fréquemment à un ensemble de données, mais les données plus anciennes ne sont jamais modifiées. En gros, ERDDAP™ administrateur peut exécuter ArchiveADataset (Peut-être dans un script, peut-être dirigé par cron) et spécifier un sous-ensemble de données qu'ils veulent extraire (Peut-être dans plusieurs fichiers) et emballage .zip ou .tgz fichier, afin que vous puissiez envoyer le fichier aux personnes ou groupes intéressés (Par exemple, l'INCE pour l'archivage) ou le rendre disponible pour téléchargement. Par exemple, vous pouvez exécuter ArchiveADataset tous les jours à 12h10 et le faire faire une .zip de toutes les données de 12h00 la veille jusqu'à 12h00 aujourd'hui. (Ou, faites cela chaque semaine, chaque mois ou chaque année, au besoin.) Parce que le fichier est généré hors ligne, il n'y a aucun danger de délai ou trop de données, comme il y aurait pour une norme ERDDAP™ demande.
ERDDAP™ Le système de demande standard
ERDDAP™ Le système standard de demande est une solution alternative quand les données sont ajoutées fréquemment à un ensemble de données, mais les données plus anciennes ne sont jamais modifiées. Fondamentalement, n'importe qui peut utiliser des demandes standard pour obtenir des données pour une plage de temps spécifique. Par exemple, à 12h10 tous les jours, vous pouvez faire une demande pour toutes les données d'un ensemble de données distant de 12h00 à 12h00 aujourd'hui. La limitation (par rapport à l'approche ArchiveADataset) est le risque d'un délai ou il y a trop de données pour un seul fichier. Vous pouvez éviter la limitation en faisant des demandes plus fréquentes pour des périodes plus courtes.
EDDTableFromHttpGet
\[ Cette option n'existe pas encore, mais semble possible à construire dans un avenir proche. \]
La nouvelle EDDTableFromHttpGet type d'ensemble de données ERDDAP™ v2.0 permet d'envisager une autre solution. Les fichiers sous-jacents maintenus par ce type d'ensemble de données sont essentiellement des fichiers journaux qui enregistrent les changements à l'ensemble de données. Il devrait être possible de construire un système qui maintient un ensemble de données (ou sur la base d'un déclencheur) demander toutes les modifications qui ont été apportées à l'ensemble de données distant depuis cette dernière demande. Cela devrait être aussi efficace (ou plus) que rsync et gérerait de nombreux scénarios difficiles, mais ne fonctionnerait que si les ensembles de données distants et locaux sont EDDTableFromHttpGet datasets.
Si quelqu'un veut travailler dessus, veuillez contacter erd.data at noaa.gov .
Données distribuées
Aucune des solutions ci-dessus ne fait un grand travail de résoudre les variations difficiles du problème parce que la réplication de temps quasi réel (NRT) Les ensembles de données sont très difficiles, en partie à cause de tous les scénarios possibles.
Il y a une excellente solution : n'essayez même pas de reproduire les données. Utiliser plutôt la seule source faisant autorité (un ensemble de données sur un ERDDAP ) , tenue par le fournisseur de données (Par exemple, un bureau régional) . Tous les utilisateurs qui veulent des données de cet ensemble de données les obtiennent toujours de la source. Par exemple, les applications basées sur le navigateur obtiennent les données d'une requête basée sur l'URL, donc il ne devrait pas importe que la requête soit à la source originale sur un serveur distant (pas le même serveur qui héberge le MES) . Beaucoup de gens défendent cette approche des données distribuées depuis longtemps (Par exemple, Roy Mendelssohn depuis plus de 20 ans) . ERDDAP Le modèle de grille/fédération (le plus haut 80% de ce document) est basé sur cette approche. Cette solution est comme une épée pour un noeud gordien — tout le problème disparaît.
- Cette solution est étonnamment simple.
- Cette solution est étonnamment efficace car aucun travail n'est fait pour conserver un ensemble de données répliquées (s) à jour.
- Les utilisateurs peuvent obtenir les dernières données à tout moment (Par exemple, avec une latence de seulement ~0,5 seconde) .
- Il s'échelle assez bien et il y a des moyens d'améliorer l'échelle. (Voir la discussion au sommet de 80% de ce document.)
Non, ce n'est pas une solution pour toutes les situations possibles, mais c'est une excellente solution pour la grande majorité. S'il y a des problèmes ou des faiblesses avec cette solution dans certaines situations, il est souvent utile de travailler pour résoudre ces problèmes ou vivre avec ces faiblesses en raison des avantages étonnants de cette solution. Si/lorsque cette solution est vraiment inacceptable pour une situation donnée, par exemple quand vous devez vraiment avoir une copie locale des données, alors considérez les autres solutions discutées ci-dessus.
Conclusion
Bien qu'il n'y ait pas de solution simple et unique qui résout parfaitement tous les problèmes dans tous les scénarios (comme rsync et les données distribuées sont presque) , espérons qu'il y a suffisamment d'outils et d'options pour que vous puissiez trouver une solution acceptable pour votre situation particulière.