Scaling
ERDDAP™ Heavy Loads, Grids, Clusters, Federations och Cloud Computing
ERDDAP Från:
ERDDAP™ är en webbapplikation och en webbtjänst som samlar vetenskapliga data från olika lokala och avlägsna källor och erbjuder ett enkelt, konsekvent sätt att ladda ner delmängder av data i vanliga filformat och göra grafer och kartor. Denna webbsida diskuterar frågor som rör tunga ERDDAP™ användning laster och utforskar möjligheter för att hantera extremt tunga laster via nät, kluster, federationer och cloud computing.
Den ursprungliga versionen skrevs i juni 2009. Det har inte skett några betydande förändringar. Detta uppdaterades senast 2019-04-15.
Disclaier
Innehållet på denna webbsida är Bob Simons personliga åsikter och reflekterar inte nödvändigtvis någon ställning för regeringen eller National Oceanic and Atmospheric Administration . Beräkningarna är förenklade, men jag tror att slutsatserna är korrekta. Har jag använt felaktig logik eller gjort ett misstag i mina beräkningar? Om så är fallet är felet min ensam. Skicka ett e-postmeddelande med rättelsen till erd dot data at noaa dot gov .
Tunga laster / begränsningar
Med tung användning, en fristående ERDDAP™ kommer att begränsas (från de flesta till minst sannolikt) av:
Fjärrkälla bandbredd
- En fjärrdatakälla bandbredd - Även med en effektiv anslutning (t.ex. via OPeNDAP ) om inte en fjärrdatakälla har en mycket hög bandbredd Internetanslutning, ERDDAP svaren kommer att begränsas av hur snabbt ERDDAP™ kan få data från datakällan. En lösning är att kopiera datasetet till ERDDAP hårddisk, kanske med EDDGrid Kopiera eller EDDTableCopy .
ERDDAP Server Bandwidth
- Om inte ERDDAP server har en mycket hög bandbredd Internet-anslutning, ERDDAP svaren kommer att begränsas av hur snabbt ERDDAP™ kan få data från datakällorna och hur snabbt ERDDAP™ kan returnera data till kunderna. Den enda lösningen är att få en snabbare internetanslutning.
Minne
- Om det finns många samtidiga förfrågningar, ERDDAP™ kan komma ur minnet och tillfälligt vägra nya förfrågningar. ( ERDDAP™ har ett par mekanismer för att undvika detta och minimera konsekvenserna om det händer.) Ju mer minne i servern desto bättre. På en 32-bitars server är 4 + GB riktigt bra, 2 GB är okej, mindre rekommenderas inte. På en 64-bitars server kan du nästan helt undvika problemet genom att få massor av minne. Se Xmx och -Xms inställningar För ERDDAP /Tomcat. Ett ERDDAP™ Att få tung användning på en dator med en 64-bitars server med 8 GB minne och -Xmx inställd på 4000M är sällan, om någonsin, begränsas av minnet.
Had Drive Bandwidth
- Att komma åt data som lagras på serverns hårddisk är mycket snabbare än att komma åt fjärrdata. Även så, om ERDDAP™ Servern har en mycket hög bandbredd Internetanslutning, det är möjligt att komma åt data på hårddisken kommer att vara en flaskhals. En partiell lösning är att använda snabbare (Till exempel 10 000 RPM) magnetiska hårddiskar eller SSD-enheter (Om det är meningsfullt kostnadsmässigt) . En annan lösning är att lagra olika datamängder på olika enheter, så att den kumulativa hårddisk bandbredd är mycket högre.
För många filer cachade
- För många filer i en Cache katalog - ERDDAP™ cachar alla bilder, men bara cachar data för vissa typer av dataförfrågningar. Det är möjligt för cache-katalogen för en datamängd att ha ett stort antal filer tillfälligt. Detta kommer att sakta ner förfrågningar för att se om en fil är i cache (verkligen!) .<Cache Minutes & gt; i setup.xml låter dig ange hur länge en fil kan vara i cachen innan den raderas. Att ställa in ett mindre antal skulle minimera detta problem.
CPU
- Endast två saker tar mycket CPU-tid:
- NetCDF 4 och HDF 5 stöder nu intern komprimering av data. Dekomprimera en stor komprimerad NetCDF 4/ HDF 5 datafil kan ta 10 eller fler sekunder. (Det är inte ett genomförande fel. Det är komprimeringens natur.) Så flera samtidiga förfrågningar till datamängder med data som lagras i komprimerade filer kan sätta en allvarlig belastning på någon server. Om detta är ett problem är lösningen att lagra populära datamängder i okomprimerade filer, eller få en server med en CPU med fler kärnor.
- Göra grafer (inklusive kartor) Ungefär 0,2 - 1 sekund per graf. Så om det fanns många samtidiga unika förfrågningar om grafer ( WMS Kunder gör ofta 6 samtidiga förfrågningar!) Det kan finnas en CPU-begränsning. När flera användare kör WMS kunder, detta blir ett problem.
Multipel identisk ERDDAP med lastbalansering?
Frågan kommer ofta upp: "Att hantera tunga laster, kan jag ställa in flera identiska ERDDAP med lastbalansering?" Det är en intressant fråga eftersom det snabbt kommer till kärnan i ERDDAP "S design. Det snabba svaret är "nej". Jag vet att det är ett besvikande svar, men det finns ett par direkta skäl och några större grundläggande skäl till varför jag designade. ERDDAP™ att använda en annan metod (en federation av ERDDAP s, beskrivs i huvuddelen av detta dokument) Som jag tror är en bättre lösning.
Några direkta anledningar till att du inte / borde inte ställa in flera identiska ERDDAP s är:
- En given ERDDAP™ läser varje datafil när den först blir tillgänglig för att hitta raderna av data i filen. Den lagrar sedan den informationen i en indexfil. Senare när en användares begäran om data kommer in, ERDDAP™ använder det indexet för att räkna ut vilka filer som ska titta in för de begärda uppgifterna. Om det fanns flera identiska ERDDAP De skulle var och en göra detta indexering, vilket är bortkastad ansträngning. Med det federerade systemet som beskrivs nedan görs indexeringen endast en gång, av en av ERDDAP s.
- För vissa typer av användarförfrågningar (t.ex. för .nc .png, .pdf-filer) ERDDAP™ måste göra hela filen innan svaret kan skickas. Så ERDDAP™ caches dessa filer under en kort tid. Om en identisk begäran kommer in (som det ofta gör, särskilt för bilder där webbadressen är inbäddad på en webbsida) , ERDDAP™ kan återanvända den cachade filen. I ett system med flera identiska ERDDAP Dessa cachade filer delas inte, så var och en ERDDAP™ skulle onödigt och slösaktigt återskapa .nc , .png eller .pdf filer. Med det federerade systemet som beskrivs nedan görs filerna endast en gång, av en av ERDDAP och återanvänd.
- ERDDAP abonnemangssystemet är inte inställt för att delas av flera ERDDAP s. Till exempel, om lastbalansen skickar en användare till en ERDDAP™ och användaren prenumererar på en dataset, sedan den andra ERDDAP s kommer inte att vara medveten om den prenumerationen. Senare, om lastbalansen skickar användaren till en annan ERDDAP™ och ber om en lista över hans/hennes prenumerationer, den andra ERDDAP™ säger att det inte finns någon (leda honom/henne att göra en dubbel prenumeration på den andra ERED DAP ) . Med det federerade systemet som beskrivs nedan hanteras abonnemangssystemet helt enkelt av den huvudsakliga, offentliga, sammansatta ERDDAP .
Ja, för var och en av dessa problem kunde jag (med stor ansträngning) ingenjör en lösning (att dela informationen mellan ERDDAP s) Men jag tror Federation-of- ERDDAP s approach (beskrivs i huvuddelen av detta dokument) är en mycket bättre helhetslösning, dels för att den hanterar andra problem som multi-identiska ERDDAP s-med-a-load-balancer strategi inte ens börja ta itu med, särskilt den decentraliserade naturen av datakällor i världen.
Det är bäst att acceptera det enkla faktum att jag inte designade ERDDAP™ att distribueras som flera identiska ERDDAP med en lastbalanser. Jag designade medvetet ERDDAP™ att arbeta bra inom en federation av ERDDAP Som jag tror har många fördelar. I synnerhet en federation av ERDDAP s är helt i linje med det decentraliserade, distribuerade datacenter som vi har i den verkliga världen. (Tänk på de olika IOOS-regionerna, eller de olika regionerna CoastWatch, eller de olika delarna av NCEI, eller de 100 andra datacentren i NOAA , eller de olika NASA DAACs, eller 1000-talets datacenter över hela världen) . Istället för att berätta för alla datacenter i världen att de måste överge sina ansträngningar och lägga all sin data i en centraliserad datasjön. (Även om det var möjligt, är det en hemsk idé av många skäl - se de olika analyserna som visar de många fördelarna med Decentraliserade system ) , ERDDAP "S design fungerar med världen som den är. Varje datacenter som producerar data kan fortsätta att behålla, kurera och tjäna sina data (som de borde) Och ändå, med ERDDAP™ Uppgifterna kan också vara direkt tillgängliga från en centraliserad ERDDAP utan behov av att överföra data till centraliserade ERDDAP™ eller lagra duplicerade kopior av data. Faktum är att en viss dataset kan vara tillgänglig samtidigt från en ERDDAP™ i den organisation som producerade och faktiskt lagrar data (t.ex. GoMOOS) , från en ERDDAP™ på moderorganisationen (t.ex. IOOS central) , från en all- NOAA ERDDAP™ , från en all-US-federal regering ERDDAP™ , från en global ERDDAP™ (GOOS) , och från specialiserade ERDDAP s (t.ex. en ERDDAP™ på en institution som ägnas åt HAB-forskning) , i huvudsak omedelbart och effektivt eftersom endast metadata överförs mellan ERDDAP s, inte data. Bäst av allt, efter den första ERDDAP™ i den ursprungliga organisationen, alla andra ERDDAP Kan ställas in snabbt (Några timmars arbete) med minimala resurser (En server som inte behöver några RAID för datalagring eftersom den lagrar inga data lokalt) och därmed till verkligt minimal kostnad. Jämför det med kostnaden för att ställa in och upprätthålla ett centraliserat datacenter med en data sjö och behovet av en verkligt massiv, verkligt dyr, Internetanslutning, plus deltagarnas problem med det centraliserade datacentret är en enda punkt av misslyckande. För mig, ERDDAP Decentraliserat, federerat tillvägagångssätt är långt, långt överlägset.
I situationer där ett visst datacenter behöver flera ERDDAP för att möta hög efterfrågan, ERDDAP design är fullt kapabel att matcha eller överträffa prestandan hos multi-identiska ERDDAP s-med-a-load-balancer strategi. Du har alltid möjlighet att ställa in multipel komposit ERDDAP s (som diskuteras nedan) Var och en får all sin data från andra ERDDAP utan lastbalansering. I det här fallet rekommenderar jag att du gör en punkt för att ge var och en av kompositen. ERDDAP ett annat namn/identitet och om möjligt sätta upp dem i olika delar av världen (till exempel olika AWS-regioner) t.ex., ERD \_US\_Öst, ERD \_US\_Väst, ERD IE, ERD FR, ERD \_IT, så att användare medvetet, upprepade gånger, arbetar med en specifik ERDDAP , med den extra fördelen att du har tagit bort risken från en enda felpunkt.
Gridar, kluster och federationer
Under mycket tung användning, en enda fristående ERDDAP™ kommer att bli en eller flera av begränsningar listade ovan och även de föreslagna lösningarna kommer att vara otillräckliga. För sådana situationer, ERDDAP™ har funktioner som gör det enkelt att bygga skalbara nät (även kallade kluster eller federationer) av ERDDAP s som gör att systemet kan hantera mycket tung användning (till exempel för ett stort datacenter) .
Jag använder Nät som en allmän term för att ange en typ av Datorkluster där alla delar kan eller inte kan vara fysiskt placerade i en anläggning och kan eller inte kan administreras centralt. En fördel med samlokaliserade, centralt ägda och administrerade nät (Kluster) De gynnas av stordriftsfördelar (Särskilt mänsklig arbetsbelastning) Förenkla att göra delar av systemet fungerar bra tillsammans. En fördel med icke-kolokaliserade nät, icke-centralt ägda och administrerade (Federationer) är att de distribuerar den mänskliga arbetsbelastningen och kostnaden, och kan ge ytterligare feltolerans. Lösningen jag föreslår nedan fungerar bra för alla rutnät, kluster och federationstopografer.
Den grundläggande idén att utforma ett skalbart system är att identifiera de potentiella flaskhalsarna och sedan utforma systemet så att delar av systemet kan replikeras efter behov för att lindra flaskhalsarna. Idealiskt ökar varje replikerad del kapaciteten hos den delen av systemet linjärt (effektivitet av skalning) . Systemet är inte skalbart om det inte finns en skalbar lösning för varje flaskhals. Skalbarhet skiljer sig från effektivitet (hur snabbt en uppgift kan göras – effektiviteten i delarna) . Skalbarhet gör det möjligt för systemet att växa för att hantera alla nivåer av efterfrågan. Effektiv (av skalning och av delar) avgör hur många servrar, etc., som behövs för att möta en viss efterfrågan. Effektivitet är mycket viktigt, men har alltid gränser. Skalbarhet är den enda praktiska lösningen för att bygga ett system som kan hantera väldigt mycket väldigt mycket tung användning. Helst kommer systemet att vara skalbart och effektivt.
Mål
Målen för denna design är:
- För att göra en skalbar arkitektur (En som lätt kan förlängas genom att replikera någon del som blir överbelastad) . För att göra ett effektivt system som maximerar tillgängligheten och genomströmningen av de data som ges tillgängliga datorresurser. (Kostnaden är nästan alltid ett problem.)
- Att balansera kapaciteten hos delar av systemet så att en del av systemet inte kommer att överväldiga en annan del.
- För att göra en enkel arkitektur så att systemet är lätt att installera och administrera.
- För att göra en arkitektur som fungerar bra med alla rutnät.
- För att göra ett system som misslyckas graciöst och på ett begränsat sätt om någon del blir överbelastad. (Den tid som krävs för att kopiera en stor datamängd kommer alltid att begränsa systemets förmåga att hantera plötsliga ökningar av efterfrågan på en viss datamängd.)
- (Om möjligt) För att göra en arkitektur som inte är knuten till någon specifik cloud computing Tjänster eller andra externa tjänster (eftersom det inte behöver dem) .
rekommendationer
Våra rekommendationer är
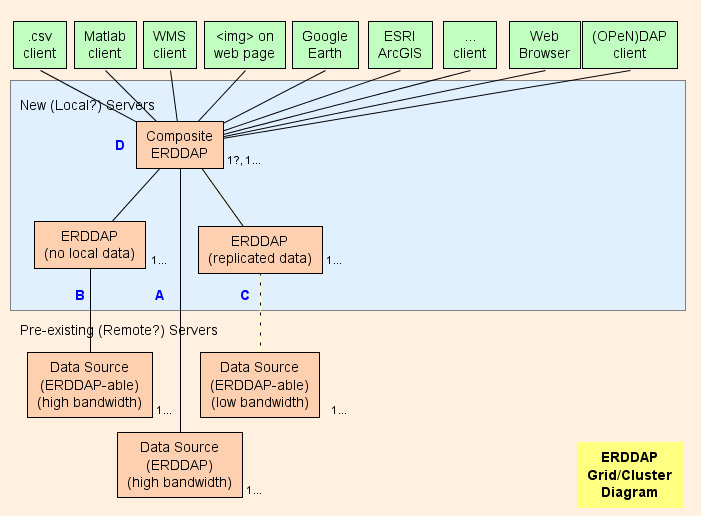
- I grund och botten föreslår jag att du ställer in en komposit ERDDAP™ ( D D D D D i diagrammet) , vilket är en vanlig ERDDAP™ förutom att det bara tjänar data från andra ERDDAP s. Nätets arkitektur är utformad för att flytta så mycket arbete som möjligt (CPU användning, minnesanvändning, bandbredd användning) från kompositen ERDDAP™ till den andra ERDDAP s.
- ERDDAP™ har två särskilda datasettyper, EDDGrid FrånErddap och EDDTableFromErddap som hänvisar till Dataset på andra ERDDAP s.
- När kompositen ERDDAP™ får en begäran om data eller bilder från dessa datamängder, kompositen ERDDAP™ omdirigeringar Databegäran till den andra ERDDAP™ Server. Resultatet är:
- Detta är mycket effektivt (CPU, minne och bandbredd) för annars
- Kompositör ERDDAP™ måste skicka databegäran till den andra ERDDAP .
- Den andra ERDDAP™ måste få data, reformera den och överföra data till kompositen ERDDAP .
- Kompositör ERDDAP™ måste ta emot data (med extra bandbredd) Reformatera den (Använd extra CPU tid och minne) och överföra data till användaren (med extra bandbredd) . Genom att omdirigera databegäran och tillåta den andra ERDDAP™ att skicka svaret direkt till användaren, kompositen ERDDAP™ spenderar i huvudsak ingen CPU-tid, minne eller bandbredd på dataförfrågningar.
- Omdirigeringen är transparent för användaren oavsett kundens programvara (en webbläsare eller annan programvara eller kommandorad verktyg) .
- Detta är mycket effektivt (CPU, minne och bandbredd) för annars
Grid Parts
Ett Från: För varje fjärrdatakälla som har en hög bandbredd OPeNDAP Server, du kan ansluta direkt till fjärrservern. Om fjärrservern är en ERDDAP™ Använd EDDGrid FromErddap eller EDDTableFrom ERDDAP att betjäna data i kompositen ERDDAP . Om fjärrservern är någon annan typ av DAP server, t.ex. TREDDS, Hyrax eller GrADS, använd EDDGrid FrånDap.
B För varje ERDDAP -able data source (en datakälla från vilken ERDDAP kan läsa data) som har en hög bandbreddserver, skapa en annan ERDDAP™ i det nät som ansvarar för att betjäna data från denna datakälla.
- Om flera sådana ERDDAP s får inte många förfrågningar om data, du kan konsolidera dem till en ERDDAP .
- Om ERDDAP™ dedikerad till att få data från en fjärrkälla får för många förfrågningar, det finns en frestelse att lägga till ytterligare ERDDAP s för att komma åt fjärrdatakällan. I särskilda fall kan detta vara meningsfullt, men det är mer troligt att detta kommer att överväldiga fjärrdatakällan. (som är självdefeating) och även hindra andra användare från att komma åt fjärrdatakällan (Det är inte trevligt) . I ett sådant fall, överväga att inrätta en annan ERDDAP™ att tjäna den ena dataset och kopiera datasetet på det ERDDAP Hårddisk (se C ) kanske med EDDGrid Kopiera och/eller EDDTableCopy .
- B Servrar måste vara allmänt tillgängliga.
C För varje ERDDAP -able datakälla som har en låg bandbreddsserver (eller är en långsam tjänst av andra skäl) överväga att inrätta en annan ERDDAP™ och lagra en kopia av datasetet på det ERDDAP hårddiskar, kanske med EDDGrid Kopiera och/eller EDDTableCopy . Om flera sådana ERDDAP s får inte många förfrågningar om data, du kan konsolidera dem till en ERDDAP . C Servrar måste vara allmänt tillgängliga.
Komposit ERDDAP
D D D D D Från: Kompositör ERDDAP™ är en vanlig ERDDAP™ förutom att det bara tjänar data från andra ERDDAP s.
- För kompositen ERDDAP™ har information i minnet om alla datamängder, det kan snabbt svara på förfrågningar om listor över datamängder (fullständiga textsökningar, kategorisökningar, listan över alla dataset) , och förfrågningar om en enskild dataset’s Data Access Form, Gör en Graph-formulär, eller WMS info page. Dessa är alla små, dynamiskt genererade, HTML-sidor baserade på information som hålls i minnet. Så svaren är mycket snabba.
- Eftersom begäran om faktiska data snabbt omdirigeras till den andra ERDDAP s, komposit ERDDAP™ kan snabbt svara på förfrågningar om faktiska data utan att använda någon CPU-tid, minne eller bandbredd.
- Genom att flytta så mycket arbete som möjligt (CPU, minne, bandbredd) från kompositen ERDDAP™ till den andra ERDDAP s, komposit ERDDAP™ kan visas för att tjäna data från alla datamängder och ändå hålla jämna steg med ett stort antal dataförfrågningar från ett stort antal användare.
- Preliminära tester indikerar att kompositen ERDDAP™ kan svara på de flesta förfrågningar i ~1ms CPU tid, eller 1000 förfrågningar / sekund. En 8-kärnprocessor ska kunna svara på cirka 8000 förfrågningar/sekunder. Även om det är möjligt att föreställa sig brister av högre aktivitet som skulle orsaka avmattningar, är det mycket genomströmning. Det är troligt att datacenterbandbredd kommer att vara flaskhalsen långt före kompositen. ERDDAP™ Blir flaskhalsen.
Upp-to-date max (Tid) ??
och EDDGrid /TableFromErddap i kompositen ERDDAP™ endast ändrar lagrad information om varje källdatamängd när källdatamängden är "Reload" och en del metadataförändringar (t.ex. tidsvariabelns actual\_range ) och därigenom skapa en abonnemangsanmälan. Om källdatamängden har data som ändras ofta (Till exempel nya data varje sekund) och använder "Uppdatering" system för att märka frekventa ändringar av de underliggande uppgifterna, EDDGrid /TableFromErddap kommer inte att meddelas om dessa frekventa ändringar tills nästa dataset "reload", så EDDGrid /TableFromErddap kommer inte att vara helt uppdaterad. Du kan minimera detta problem genom att ändra källdatasättets<reloadEveryNMinutes & gt; till ett mindre värde (60? 15?) så att det finns fler abonnemangsmeddelanden för att berätta för EDDGrid /TableFromErddap för att uppdatera sin information om källdatamängden.
Eller om ditt datahanteringssystem vet när källdatamängden har nya data (t.ex. via ett skript som kopierar en datafil på plats) Och om det inte är super frekvent (t.ex. var 5:e minut eller mindre frekvent) Det finns en bättre lösning:
- Använd inte<updateEveryNMillis & gt; att hålla källdatauppsättningen uppdaterad.
- Ställ in källdatasetets<reloadEveryNMinutes & gt; till ett större antal (1440?) .
- Har manuset kontakta källdatasetets Flagga URL strax efter det kopierar en ny datafil på plats. Det kommer att leda till att källdatamängden är helt uppdaterad och orsakar att den genererar en abonnemangsmeddelande, som kommer att skickas till källdatamängden. EDDGrid /TableFromErddap dataset. Detta leder EDDGrid /TableFromErddap dataset för att vara helt uppdaterad (inom 5 sekunder efter att nya data läggs till) . Allt som kommer att göras effektivt (utan onödiga datamängder) .
Multipel komposit ERDDAP s
- I extrema fall, eller för feltolerans, kanske du vill ställa in mer än en komposit. ERDDAP . Det är troligt att andra delar av systemet (I synnerhet datacentrets bandbredd) blir ett problem långt innan kompositen ERDDAP™ Blir en flaskhals. Lösningen är förmodligen att skapa ytterligare geografiskt olika datacenter. (Speglar) Var och en med en komposit ERDDAP™ och servrar med ERDDAP s och (åtminstone) spegelkopior av datamängderna som är i hög efterfrågan. En sådan inställning ger också feltolerans och databackup (via kopiering) . I det här fallet är det bäst om kompositen ERDDAP s har olika URL.
Om du verkligen vill ha all komposit ERDDAP s att ha samma URL, använd ett främre ändsystem som tilldelar en viss användare till bara en av kompositen ERDDAP s (baserat på IP-adressen) så att alla användarens förfrågningar går till bara en av kompositen ERDDAP s. Det finns två skäl:
- När en underliggande dataset laddas om och metadata ändras (t.ex. en ny datafil i ett ruttet dataset orsakar tidsvariabelns actual\_range att förändra) Kompositör ERDDAP s kommer att vara tillfälligt något ur synkronisering, men med Eventuell konsekvens . Normalt kommer de att synkronisera inom 5 sekunder, men ibland blir det längre. Om en användare gör ett automatiserat system som bygger på ERDDAP™ Prenumerationer som utlöser åtgärder kommer de korta synkronicitetsproblemen att bli betydande.
- 2+ komposit ERDDAP Var och en upprätthåller sin egen uppsättning abonnemang (på grund av synkroniseringsproblemet som beskrivs ovan) .
Så en viss användare bör riktas till bara en av kompositen ERDDAP För att undvika dessa problem. Om en av kompositen ERDDAP s går ner, det främre ändsystemet kan omdirigera att ERDDAP Användare till en annan ERDDAP™ Det är upp. Men om det är ett kapacitetsproblem som orsakar den första kompositen ERDDAP™ att misslyckas (en överdriven användare? en Denial-of-service attack ??) Detta gör det mycket troligt att omdirigera sina användare till annan komposit ERDDAP S kommer att orsaka en Cascading misslyckande . Således är den mest robusta inställningen att ha komposit ERDDAP s med olika URL.
Eller kanske bättre, skapa flera kompositer ERDDAP utan lastbalansering. I det här fallet bör du göra en punkt för att ge var och en av de ERDDAP ett annat namn/identitet och om möjligt sätta upp dem i olika delar av världen (till exempel olika AWS-regioner) t.ex., ERD \_US\_Öst, ERD \_US\_Väst, ERD IE, ERD FR, ERD \_IT, så att användarna medvetet arbetar upprepade gånger med en specifik ERDDAP .
- \[ För en fascinerande design av ett högt prestandasystem som körs på en server, se detta detaljerad beskrivning av Mailinator . \]
Dataset i mycket hög efterfrågan
I det riktigt ovanliga fallet är det en av Ett , B eller C ERDDAP s kan inte hålla jämna steg med förfrågningarna på grund av bandbredd eller hårddiskbegränsningar, det är vettigt att kopiera data (igen igen) till en annan server+hård Drive+ ERDDAP kanske med EDDGrid Kopiera och/eller EDDTableCopy . Även om det kan verka idealiskt att ha den ursprungliga datamängden och kopierade datamängden visas sömlöst som en datamängd i kompositen. ERDDAP™ Detta är svårt eftersom de två datamängderna kommer att vara i något olika tillstånd vid olika tidpunkter. (Speciellt efter att originalet får nya data, men innan den kopierade datamängden får sin kopia) . Därför rekommenderar jag att datamängderna ges något olika titlar. (t.ex. ”... (Kopiera #1) Och "... (Kopiera #2) Eller kanske " (Spegel # n ) "eller" (Server # n ) ") och visas som separata datamängder i kompositen ERDDAP . Användare används för att se listor över Spegelplatser på populära filnedladdningswebbplatser, så detta borde inte överraska eller göra dem besvikna. På grund av bandbredd begränsningar på en viss plats, kan det vara meningsfullt att ha spegeln ligger på en annan plats. Om spegelkopian är på ett annat datacenter, nås bara av datacentrets komposit ERDDAP™ De olika titlarna (”Fel #1) är inte nödvändigt.
Raids kontra regelbundna hårddiskar
Om en stor datamängd eller en grupp datamängder inte används kraftigt kan det vara meningsfullt att lagra data på en RAID eftersom det erbjuder feltolerans och eftersom du inte behöver bearbetningskraft eller bandbredd på en annan server. Men om en dataset används kraftigt kan det vara mer meningsfullt att kopiera data på en annan server + ERDDAP™ + hårddisk (liknar Vad Google gör ) I stället för att använda en server och en RAID för att lagra flera datamängder eftersom du får använda både server+hardDrive+ ERDDAP s i nätet tills en av dem misslyckas.
Misslyckanden
Vad händer om...
- Det finns en brist på förfrågningar om en dataset (Alla elever i en klass begär samtidigt liknande data) ?? Endast ERDDAP™ Att betjäna datamängden kommer att överväldigas och sakta ner eller vägra förfrågningar. Kompositör ERDDAP™ och andra ERDDAP S kommer inte att påverkas. Eftersom den begränsande faktorn för en viss datamängd inom systemet är hårddisken med data (Inte inte ERDDAP ) Den enda lösningen (Inte omedelbar) är att göra en kopia av datasetet på en annan server+hardDrive+ ERDDAP .
- Ett Ett , B eller C ERDDAP™ misslyckas (t.ex. hårddiskfel) ?? Endast dataset (s) tjänat av det ERDDAP™ påverkas. Om dataset (s) Speglas på en annan server+hardDrive+ ERDDAP Effekten är minimal. Om problemet är ett hårddiskfel på en nivå 5 eller 6 RAID, byter du bara enheten och har RAID återuppbygga data på enheten.
- Kompositör ERDDAP™ misslyckas? Om du vill göra ett system med mycket hög tillgänglighet Du kan ställa in multipel komposit ERDDAP s (som diskuterats ovan) Använda något liknande NGINX eller Traefik för att hantera lastbalansering. Observera att en given komposit ERDDAP™ kan hantera ett stort antal förfrågningar från ett stort antal användare eftersom förfrågningar om metadata är små och hanteras av information som är i minnet, och Förfrågningar om data (som kan vara stor) omdirigeras till barnet ERDDAP s.
Enkel, skalbar
Detta system är lätt att ställa in och administrera, och lätt uttömmande när någon del av det blir överbelastad. De enda verkliga begränsningarna för ett visst datacenter är datacentrets bandbredd och kostnaden för systemet.
Bandbredd
Notera den ungefärliga bandbredd av vanliga komponenter i systemet:
| Komponent | Cirka bandbredd (GBytes/s) |
|---|---|
| DDR minne | 2,5 |
| SSD-enhet | 1 1 |
| SATA hårddisk | 0.3 |
| Gigabit Ethernet | 0.1 |
| OC-12 | 0,06 |
| OC-3 | 0,015 |
| T1 | 0.0002 |
Så en SATA hårddisk (0,3 GB/s) på en server med en ERDDAP™ Kan nog mätta en Gigabit Ethernet LAN (0,1 GB/s) . En Gigabit Ethernet LAN (0,1 GB/s) Kan förmodligen mätta en OC-12 Internetanslutning (0,06 GB/s) . Och minst en källa listar OC-12 linjer kostar ca $ 100.000 per månad. (Ja, dessa beräkningar är baserade på att driva systemet till dess gränser, vilket inte är bra eftersom det leder till mycket tröga svar. Men dessa beräkningar är användbara för planering och balansering av delar av systemet.) Det är uppenbart att en lämpligt snabb internetanslutning för ditt datacenter är den överlägset dyraste delen av systemet. Du kan enkelt och relativt billigt bygga ett nät med ett dussin servrar som kör ett dussin ERDDAP s som kan pumpa ut massor av data snabbt, men en lämpligt snabb internetanslutning kommer att vara mycket, mycket dyrt. De partiella lösningarna är:
- Uppmuntra kunder att begära delmängder av data om det är allt som behövs. Om kunden bara behöver data för en liten region eller en lägre upplösning, är det vad de ska begära. Subsetting är ett centralt fokus för protokollen ERDDAP™ stöd för att begära data.
- Uppmuntra överföring av komprimerade data. ERDDAP™ Kompressorer en dataöverföring om den finner "accept-kodning" i HTTP GET Förfråga header. Alla webbläsare använder "accept-kodning" och dekomprimerar automatiskt svaret. Andra kunder (t.ex. datorprogram) måste använda den explicit.
- Kolla dina servrar på en ISP eller annan webbplats som erbjuder relativt billigare bandbreddskostnader.
- Sprid servrarna med ERDDAP s till olika institutioner så att kostnaderna sprids. Du kan sedan länka din komposit ERDDAP™ till deras ERDDAP s.
Observera att Cloud Computing och webbhotelltjänster erbjuder all Internet bandbredd du behöver, men lös inte prisproblemet.
För allmän information om utformning av skalbar, hög kapacitet, feltolerantsystem, se Michael T. Nygards bok Släpp det .
Som Legos
Programvarudesigners försöker ofta använda bra mjukvarudesignmönster För att lösa problem. Bra mönster är bra eftersom de inkapslar bra, lätt att skapa och arbeta med generella lösningar som leder till system med bra egenskaper. Mönsternamn är inte standardiserade, så jag kallar det mönster som ERDDAP™ använder Lego Pattern. Varje Lego (var och en ERDDAP ) är en enkel, liten, standard, fristående, tegel (Dataserver) med ett definierat gränssnitt som gör att det kan kopplas till andra legos ( ERDDAP s) . De delar av ERDDAP™ som utgör detta system är: abonnemangs- och flagURL-system (som möjliggör kommunikation mellan ERDDAP s) EDD... FromErddap omdirigeringssystem och systemet för RESTful förfrågningar om data som kan genereras av användare eller andra ERDDAP s. Med två eller fler legos ( ERDDAP s) Du kan skapa ett stort antal olika former (Nätverk topologier av ERDDAP s) . Visst, designen och funktionerna i ERDDAP™ kunde ha gjorts annorlunda, inte Lego-liknande, kanske bara för att möjliggöra och optimera för en specifik topologi. Men vi känner att ERDDAP Lego-liknande design erbjuder en bra, allmän lösning som möjliggör alla ERDDAP™ Administratör (eller grupp av administratörer) skapa alla typer av olika federation topologier. Till exempel kan en enskild organisation inrätta tre (eller mer) ERDDAP Som visas i ERDDAP™ Grid/Cluster Diagram ovan . Eller en distribuerad grupp (IOOS? CoastWatch? NCEI? NWS? NOAA ?? USGS? Dataone? NEON? Senare? OOI? BODC? ONC? JRC? WMO?) kan ställa in en ERDDAP™ i varje liten utpost (Så data kan stanna nära källan) och sedan skapa en komposit ERDDAP™ i det centrala kontoret med virtuella dataset (som alltid är helt uppdaterade) från var och en av de små ERDDAP s. Alla ERDDAP installerad på olika institutioner runt om i världen, som får data från andra ERDDAP och/eller tillhandahålla data till andra ERDDAP bildar ett gigantiskt nätverk av ERDDAP s. Hur cool är det?! Som med Legos är möjligheterna oändliga. Det är därför detta är ett bra mönster. Därför är detta en bra design för ERDDAP .
Olika typer av begäran
En av de verkliga komplikationerna av denna diskussion av dataserver topologier är att det finns olika typer av förfrågningar och olika sätt att optimera för olika typer av förfrågningar. Detta är oftast en separat fråga (Hur snabbt kan ERDDAP™ med uppgifterna svara på begäran om data?) från topologidebatten (som handlar om relationerna mellan dataservrar och vilken server som har den faktiska datan) . ERDDAP™ Självklart försöker man hantera alla typer av förfrågningar effektivt, men hanterar några bättre än andra.
- Många förfrågningar är enkla. Till exempel: Vad är metadata för denna dataset? Eller: Vad är värdena på tidsdimensionen för detta rutnätverk? ERDDAP™ är utformad för att hantera dessa så snabbt som möjligt (vanligtvis i<= 2 ms) genom att hålla denna information i minnet.
- Vissa förfrågningar är måttligt svåra. Till exempel: Ge mig denna delmängd av en dataset (som finns i en datafil) . Dessa förfrågningar kan hanteras relativt snabbt eftersom de inte är så svåra.
- Vissa förfrågningar är svåra och därför är tidskrävande. Till exempel: Ge mig denna delmängd av en dataset (som kan vara i någon av de 10 000 + datafilerna, eller kan vara från komprimerade datafiler som varje tar 10 sekunder att dekomprimera.) . ERDDAP™ v2.0 introducerade några nya, snabbare sätt att hantera dessa förfrågningar, särskilt genom att låta begära hantering tråd att leka flera arbetartrådar som hanterar olika delmängder av begäran. Men det finns en annan inställning till detta problem som ERDDAP™ Stöd ännu inte: delmängder av datafilerna för en viss datamängd kan lagras och analyseras på separata datorer, och sedan kombineras resultaten på den ursprungliga servern. Denna metod kallas MapReduce och exemplifieras av Hadoop Den första (??) Open-source MapReduce-programmet, som var baserat på idéer från ett Google-papper. (Om du behöver MapReduce i ERDDAP , skicka en e-postbegäran till erd.data at noaa.gov .) Googles BigQuery är intressant eftersom det verkar vara ett genomförande av MapReduce som tillämpas på subsetting tabular dataset, som är en av ERDDAP Huvudmål. Det är troligt att du kan skapa en ERDDAP™ dataset från en BigQuery dataset via EDDTableFromDatabase Eftersom BigQuery kan nås via ett JDBC-gränssnitt.
Detta är mina åsikter.
Ja, beräkningarna är förenklade (och nu lite daterad) Men jag tror att slutsatserna är korrekta. Har jag använt felaktig logik eller gjort ett misstag i mina beräkningar? Om så är fallet är felet min ensam. Skicka ett e-postmeddelande med rättelsen till erd dot data at noaa dot gov .
Cloud Computing
Flera företag erbjuder molntjänster (t.ex., Amazon Web Services och Google Cloud Platform ) . Web hosting företag har erbjudit enklare tjänster sedan mitten av 1990-talet, men "moln" tjänster har kraftigt utökat flexibiliteten i systemen och utbudet av tjänster som erbjuds. Sedan dess ERDDAP™ nät består bara av ERDDAP och sedan ERDDAP är Java webbapplikationer som kan köras i Tomcat (Den vanligaste programservern) eller andra applikationsservrar, bör det vara relativt lätt att ställa in en ERDDAP™ rutnät på en molntjänst eller webbhotell. Fördelarna med dessa tjänster är:
- De erbjuder tillgång till mycket hög bandbredd Internetanslutningar. Detta ensam kan motivera att använda dessa tjänster.
- De tar bara ut för de tjänster du använder. Till exempel får du tillgång till en mycket hög bandbreddsinternetanslutning, men du betalar bara för faktiska data som överförs. Det låter dig bygga ett system som sällan blir överväldigad (även på topp efterfrågan) utan att behöva betala för kapacitet som sällan används.
- De är lätt uthålliga. Du kan ändra servertyper eller lägga till så många servrar eller så mycket lagring som du vill, på mindre än en minut. Detta ensam kan motivera att använda dessa tjänster.
- De frigör dig från många av de administrativa uppgifterna för att köra servrar och nätverk. Detta ensam kan motivera att använda dessa tjänster.
Nackdelarna med dessa tjänster är:
- De tar betalt för sina tjänster, ibland mycket (i absoluta termer; inte att det inte är ett bra värde) . Priserna som anges här är för Amazon EC2 . Dessa priser (från och med juni 2015) kommer ner.
Tidigare var priserna högre, men datafiler och antalet förfrågningar var mindre.
I framtiden blir priserna lägre, men datafiler och antalet förfrågningar blir större.
Så detaljerna förändras, men situationen förblir relativt konstant.
Och det är inte att tjänsten är övervärderad, det är att vi använder och köper mycket av tjänsten.
- Dataöverföring – Dataöverföringar till systemet är nu gratis (Ja!) . Dataöverföringar från systemet är $ 0,09/GB. En SATA hårddisk (0,3 GB/s) på en server med en ERDDAP™ Kan nog mätta en Gigabit Ethernet LAN (0,1 GB/s) . En Gigabit Ethernet LAN (0,1 GB/s) Kan förmodligen mätta en OC-12 Internetanslutning (0,06 GB/s) . Om en OC-12-anslutning kan överföra ~ 150.000 GB / månad, kan dataöverföringskostnaderna vara så mycket som 150.000 GB @ $ 0,09 / GB = $ 13,500 / månad, vilket är en betydande kostnad. Tydligt, om du har ett dussin hårt arbetande ERDDAP s på en molntjänst, dina månatliga dataöverföringsavgifter kan vara betydande (upp till $162 000/månad) . (Återigen är det inte att tjänsten är övervärderad, det är att vi använder och köper mycket av tjänsten.)
- Datalagring – Amazon tar ut $ 50/månad per TB. (Jämför det med att köpa en 4TB företag köra direkt för ~ $ 50 / TB, även om RAID att sätta in och administrativa kostnader lägga till den totala kostnaden.) Så om du behöver lagra massor av data i molnet kan det vara ganska dyrt (100TB skulle kosta 5000 USD/månad) . Men om du inte har en riktigt stor mängd data, är detta en mindre fråga än bandbredd / dataöverföringskostnader. (Återigen är det inte att tjänsten är övervärderad, det är att vi använder och köper mycket av tjänsten.)
Subsetting
- Subsettingproblemet: Det enda sättet att effektivt distribuera data från datafiler är att ha programmet som distribuerar data. (t.ex., ERDDAP ) kör på en server som har data lagrad på en lokal hårddisk (eller liknande snabb tillgång till en SAN eller lokal RAID) . Lokala filsystem tillåter ERDDAP™ (och underliggande bibliotek, såsom netcdf-java) att begära specifika bytesintervall från filerna och få svar mycket snabbt. Många typer av dataförfrågningar från ERDDAP™ till filen (särskilt ruttna dataförfrågningar där stegvärdet är > 1 1) Kan inte göras effektivt om programmet måste begära hela filen eller stora bitar av en fil från en icke-lokal (Därför långsammare) datalagringssystem och sedan extrahera en delmängd. Om molninställningen inte ger ERDDAP™ snabb åtkomst till bytesintervall av filerna (Så fort som med lokala filer) , ERDDAP "Tillgång till data kommer att vara en svår flaskhals och negera andra fördelar med att använda en molntjänst.
Hosted Data
Ett alternativ till ovanstående kostnadsförmånsanalys (som är baserat på dataägaren (t.ex., NOAA ) betala för att deras data ska lagras i molnet) kom runt 2012, när Amazon (och i mindre utsträckning andra molnleverantörer) började hosting några dataset i deras moln (AWS S3) gratis gratis (antagligen med förhoppningen att de skulle kunna återhämta sina kostnader om användarna skulle hyra AWS EC2-beräkningsinstanser för att arbeta med dessa data) . Det gör klart att cloud computing mycket mer kostnadseffektivt, eftersom tiden och kostnaden för att ladda upp data och hosting det är nu noll. Med ERDDAP™ v2.0, det finns nya funktioner för att underlätta körning ERDDAP I ett moln:
- Nu, en EDDGrid FrånFiles eller EDDTableFromFiles dataset kan skapas från datafiler som är avlägsna och tillgängliga via internet (t.ex. AWS S3 hink) genom att använda<cacheFromUrl> och<CacheSize GB> alternativ. ERDDAP™ kommer att behålla en lokal cache av de senast använda datafilerna.
- Nu, om någon EDDTableFromFiles källfiler komprimeras (t.ex., .tgz ) , ERDDAP™ Dekomprimera dem automatiskt när de läser dem.
- Nu, den ERDDAP™ tråd som svarar på en viss begäran kommer att leka arbetstagare trådar för att arbeta på underavsnitt av begäran om du använder<nThreads & gt; alternativ. Denna parallellisering bör möjliggöra snabbare svar på svåra önskemål.
Dessa ändringar löser problemet med AWS S3 som inte erbjuder lokal, block-nivå fillagring och (gamla gamla) problem med tillgång till S3-data som har en betydande fördröjning. (För år sedan (~2014) Denna fördröjning var betydande, men är nu mycket kortare och så inte lika betydande.) Sammantaget betyder det att inrätta ERDDAP™ i molnet fungerar mycket bättre nu.
Tack Många tack vare Matthew Arrott och hans grupp i den ursprungliga OOI-insatsen för deras arbete med att sätta ERDDAP™ i molnet och de resulterande diskussionerna.
Fjärrreplikering av datamängder
Det finns ett vanligt problem som är relaterat till ovanstående diskussion om nät och federationer. ERDDAP s: fjärrreplikering av dataset. Det grundläggande problemet är: en dataleverantör upprätthåller en datamängd som ändras ibland och en användare vill behålla en aktuell lokal kopia av denna datamängd (av någon av olika skäl) . Det är uppenbart att det finns ett stort antal variationer av detta. Vissa variationer är mycket svårare att hantera än andra.
- Snabba uppdateringar Det är svårare att hålla den lokala datamängden uppdaterad omedelbart (t ex inom 3 sekunder) efter varje ändring av källan, snarare än till exempel inom några timmar.
- Frekventa förändringar Ofta är förändringar svårare att hantera än sällan förändringar. Till exempel, en gång per dag förändringar är mycket lättare att hantera än förändringar var 0,1 sekund.
- Små förändringar Små ändringar i en källfil är svårare att hantera än en helt ny fil. Detta gäller särskilt om de små ändringarna kan vara någonstans i filen. Små förändringar är svårare att upptäcka och göra det svårt att isolera data som måste replikeras. Nya filer är lätta att upptäcka och effektiva att överföra.
- Hela dataset Att hålla en hel dataset up-to-date är svårare än att upprätthålla ny data. Vissa användare behöver bara senaste data (t.ex. den sista 8 dagens värde) .
- Flera kopior Att upprätthålla flera fjärrkopior på olika platser är svårare än att upprätthålla en fjärrkopia. Detta är skalproblemet.
Det finns uppenbarligen ett stort antal variationer av möjliga typer av förändringar i källdataset och användarens behov och förväntningar. Många av variationerna är mycket svåra att lösa. Den bästa lösningen för en situation är ofta inte den bästa lösningen för en annan situation - det finns inte en universell bra lösning.
Relevant ERDDAP™ Verktyg
ERDDAP™ erbjuder flera verktyg som kan användas som en del av ett system som syftar till att upprätthålla en fjärrkopia av ett dataset:
- ERDDAP "S RSS (Rich Site Sammanfattning?) Serviceservice
erbjuder ett snabbt sätt att kontrollera om en dataset på en fjärrkontroll ERDDAP™ har förändrats. - ERDDAP "S Prenumerationstjänst
är en effektivare (än RSS ) tillvägagångssätt: det kommer omedelbart att skicka ett e-postmeddelande eller kontakta en URL till varje abonnent när datamängden uppdateras och uppdateringen resulterade i en förändring. Det är effektivt genom att det händer ASAP och det finns ingen bortkastad ansträngning. (som med polling en RSS Serviceservice) . Användare kan använda andra verktyg (som liknar IFTTT ) att reagera på e-postmeddelanden från prenumerationssystemet. Till exempel kan en användare prenumerera på en dataset på en fjärrkontroll ERDDAP™ och använda IFTTT för att reagera på abonnemanget e-postmeddelanden och utlösa uppdatering av den lokala datamängden. - ERDDAP "S Flagga system
ger ett sätt för en ERDDAP™ administratör för att berätta en dataset på hans/hennes ERDDAP för att ladda om ASAP. URL-formen för en flagga kan enkelt användas i skript. URL-formen för en flagga kan också användas som åtgärd för en prenumeration. - ERDDAP "S "files" Systemsystem
kan erbjuda åtkomst till källfilerna för en viss dataset, inklusive en Apache-stil katalog notering av filerna (En "Web Accessible Folder") som har varje fils nedladdningsadress, senast ändrad tid och storlek. En nackdel med att använda "files" system är att källfilerna kan ha olika variabla namn och olika metadata än datamängden som visas i ERDDAP . Om en fjärrkontroll ERDDAP™ dataset erbjuder tillgång till sina källfiler, som öppnar upp möjligheten av en fattig-man version av rsync: det blir lätt för ett lokalt system att se vilka fjärrfiler som har ändrats och behöver laddas ner. (Se cacheFromUrl alternativet nedan som kan använda detta.)
Lösningar
Även om det finns ett stort antal variationer i problemet och ett oändligt antal möjliga lösningar finns det bara en handfull grundläggande lösningar på lösningar:
Anpassade, Brute Force Solutions
En uppenbar lösning är att skapa en anpassad lösning som därför är optimerad för en given situation: göra ett system som upptäcker/identifierar vilka data som har ändrats och skickar den informationen till användaren så att användaren kan begära ändrade data. Du kan göra detta, men det finns nackdelar:
- Anpassade lösningar är mycket arbete.
- Anpassade lösningar är vanligtvis så anpassade till en viss datamängd och givet användarens system att de inte lätt kan återanvändas.
- Anpassade lösningar måste byggas och underhållas av dig. (Det är aldrig en bra idé. Det är alltid en bra idé att undvika arbete och få någon annan att göra jobbet!)
Jag avskräcker att ta detta tillvägagångssätt eftersom det nästan alltid är bättre att leta efter allmänna lösningar, byggda och underhållna av någon annan, som lätt kan återanvändas i olika situationer.
Rsync
Rsync är den befintliga, fantastiskt bra, allmänt ändamål lösning för att hålla en samling filer på en källdator synkroniseras på en användares fjärrdator. Hur det fungerar är:
- Några event (t.ex. en ERDDAP™ abonnemangssystem händelse) utlösare som kör rsync, (eller ett cronjobb körs rsync vid specifika tidpunkter varje dag på användarens dator)
- som kontaktar rsync på källdatorn,
- som beräknar en serie hashes för bitar av varje fil och överför dessa hashes till användarens rsync,
- som jämför denna information med liknande information för användarens kopia av filerna,
- som sedan begär bitar av filer som har ändrats.
Med tanke på allt det gör fungerar rsync mycket snabbt (t.ex. 10 sekunder plus dataöverföringstid) och mycket effektivt. Det finns variationer av rsync som optimerar för olika situationer (t.ex. genom att precalculating och caching hashes av bitarna i varje källfil) .
De viktigaste svagheterna i rsync är: det krävs lite ansträngning att inrätta (Säkerhetsfrågor) ; Det finns några skalproblem; och det är inte bra för att hålla NRT-datamängder verkligen uppdaterade (t.ex. är det besvärligt att använda rsync mer än ca var 5: e minut) . Om du kan hantera svagheterna, eller om de inte påverkar din situation, är rsync en utmärkt, allmän lösning som alla kan använda just nu för att lösa många scenarier som involverar fjärrreplikering av datamängder.
Det finns ett objekt på ERDDAP™ För att göra lista för att försöka lägga till stöd för rsync-tjänster till ERDDAP (förmodligen en ganska svår uppgift) Så att varje klient kan använda rsync (eller en variant) för att upprätthålla en uppdaterad kopia av en dataset. Om någon vill arbeta på detta, vänligen e-post erd.data at noaa.gov .
Det finns andra program som gör mer eller mindre vad rsync gör, ibland inriktad på dataset replikering (men ofta på en filkopieringsnivå) t.ex., Unidata "S IDD .
Cache från Url
CacheFromUrl Inställningen är tillgänglig (Börja med ERDDAP™ v2.0) för alla ERDDAP "S dataset typer som gör dataset från filer (i princip alla underklasser av EDDGrid FrånFiles och EDDTableFromFiles ) . Cache FromUrl gör det trivialt att automatiskt ladda ner och behålla de lokala datafilerna genom att kopiera dem från en fjärrkälla via cache FrånUrl inställning. Fjärrfilerna kan vara i en Web Accessible Folder eller en katalogliknande fillista som erbjuds av THREDDS, Hyrax en S3 hink, eller ERDDAP "S "files" system.
Om källan till fjärrfilerna är en fjärrkontroll ERDDAP™ dataset som erbjuder källfilerna via ERDDAP™ "files" system, då kan du Prenumerera till fjärrdataset och använd Flagga URL för din lokala dataset som åtgärd för prenumerationen. När fjärrdatamängden ändras kommer den att kontakta flagg-URL för din datamängd, som kommer att berätta för den att ladda om ASAP, som kommer att upptäcka och ladda ner de ändrade fjärrdatafilerna. Allt detta händer mycket snabbt (vanligtvis ~ 5 sekunder plus den tid som behövs för att ladda ner de ändrade filerna) . Detta tillvägagångssätt fungerar bra om källdatamängden ändras är nya filer som regelbundet läggs till och när de befintliga filerna aldrig ändras. Detta tillvägagångssätt fungerar inte bra om data ofta läggs till alla (eller de flesta) av de befintliga källdatafilerna, eftersom din lokala dataset ofta laddar ner hela fjärrdatasetet. (Det är här ett rsync-liknande tillvägagångssätt behövs.)
ArchiveADataset
ERDDAP™ "S ArchiveADataset är en bra lösning när data läggs till i en datamängd ofta, men äldre data ändras aldrig. I grund och botten, en ERDDAP™ Administratör kan köra ArchiveADataset (Kanske i ett manus, kanske springa av cron) och ange en delmängd av en datamängd som de vill extrahera (Kanske i flera filer) och paket i en .zip eller .tgz fil, så att du kan skicka filen till intresserade personer eller grupper (t.ex. NCEI för arkivering) eller göra den tillgänglig för nedladdning. Till exempel kan du köra ArchiveADataset varje dag kl 12:10 och få det att göra en .zip av alla data från 12:00 är föregående dag fram till kl 12:00 idag. (Eller, gör denna veckovisa, månatliga eller årliga, efter behov.) Eftersom den förpackade filen genereras offline finns det ingen risk för en timeout eller för mycket data, eftersom det skulle finnas för en standard. ERDDAP™ begäran.
ERDDAP™ Standardförfråganssystem
ERDDAP™ Standardförfråganssystem är en alternativ bra lösning när data läggs till ofta, men äldre data ändras aldrig. I grund och botten kan vem som helst använda standardförfrågningar för att få data för en viss tid. Till exempel, kl 12:10 varje dag, kan du göra en begäran om alla data från en fjärrdatamängd från 12:00 är föregående dag fram till kl 12:00 idag. Begränsningen (jämfört med ArchiveADataset-metoden) är risken för en timeout eller det finns för mycket data för en enda fil. Du kan undvika begränsningen genom att göra mer frekventa förfrågningar för mindre tidsperioder.
EDDTableFromHttpGet
\[ Det här alternativet finns ännu inte, men verkar möjligt att bygga inom en snar framtid. \]
Den nya EDDTableFromHttpGet Datasettyp i ERDDAP™ v2.0 gör det möjligt att förutse en annan lösning. De underliggande filer som upprätthålls av denna typ av datamängd är i huvudsak loggfiler som registrerar ändringar i datamängden. Det bör vara möjligt att bygga ett system som upprätthåller en lokal datamängd per periodiskt (eller baserat på en trigger) begära alla ändringar som har gjorts till fjärrdataset sedan den senaste begäran. Det bör vara lika effektivt (eller mer) än rsync och skulle hantera många svåra scenarier, men skulle bara fungera om fjärr- och lokala datamängder är EDDTableFromHttpGet datamängder.
Om någon vill arbeta på detta, vänligen kontakta erd.data at noaa.gov .
Distribuerade data
Ingen av lösningarna ovan gör ett bra jobb med att lösa de hårda variationerna av problemet eftersom replikering av nästan realtid. (NRT) Dataset är mycket svårt, dels på grund av alla möjliga scenarier.
Det finns en bra lösning: försök inte ens att replikera data. Använd istället en auktoritativ källa (En dataset på en ERDDAP ) upprätthålls av dataleverantören (t.ex. ett regionalt kontor) . Alla användare som vill ha data från datamängden får alltid det från källan. Till exempel, webbläsarbaserade appar får data från en URL-baserad begäran, så det bör inte spela någon roll att begäran är till den ursprungliga källan på en fjärrserver. (inte samma server som är värd för ESM) . Många har länge förespråkat detta distribuerade datatillvägagångssätt. (Roy Mendelssohn de senaste 20+ åren) . ERDDAP Grid/federationsmodell (Topp 80% av detta dokument) bygger på detta tillvägagångssätt. Denna lösning är som ett svärd till en Gordian Knot – hela problemet försvinner.
- Denna lösning är fantastiskt enkel.
- Denna lösning är fantastiskt effektiv eftersom inget arbete görs för att hålla en replikerad dataset (s) up-to-date.
- Användare kan få de senaste uppgifterna när som helst (t.ex. med en latens på endast 0,5 sekunder) .
- Det skalar ganska bra och det finns sätt att förbättra skalning. (Se diskussionen på topp 80% av detta dokument.)
Nej, det här är inte en lösning för alla möjliga situationer, men det är en bra lösning för de allra flesta. Om det finns problem/svagheter med denna lösning i vissa situationer, är det ofta värt att arbeta för att lösa dessa problem eller leva med dessa svagheter på grund av de fantastiska fördelarna med denna lösning. Om/när den här lösningen verkligen är oacceptabel för en viss situation, t.ex. när du verkligen måste ha en lokal kopia av data, överväga de andra lösningarna som diskuteras ovan.
Slutsats
Det finns ingen enkel lösning som löser alla problem i alla scenarier. (som rsync och distribuerade data nästan är) Förhoppningsvis finns det tillräckliga verktyg och alternativ så att du kan hitta en acceptabel lösning för din situation.