관련 상품
ERDDAP™ - 무거운 짐, 격자, 클러스터, 연맹 및 클라우드 컴퓨팅
ERDDAP ::
ERDDAP™ 웹 응용 프로그램 및 다양한 로컬 및 원격 소스에서 과학 데이터를 수집하는 웹 서비스이며 일반적인 파일 형식의 데이터의 하위 세트를 다운로드하고 그래프와지도를 만듭니다. 이 웹 페이지는 무거운 관련 문제 논의 ERDDAP™ 사용 하중 및 그리드, 클러스터, 페더레이션 및 클라우드 컴퓨팅을 통해 매우 무거운 하중을 처리 할 수있는 가능성을 탐구합니다.
원래 버전은 2009 년 6 월에 작성되었습니다. 중요한 변화가 없습니다. 마지막으로 업데이트 된 2019-04-15.
관련 상품
이 웹 페이지의 내용은 Bob Simons 개인 의견이며 반드시 정부 또는 정부의 어떤 위치를 반영하지 않습니다. National Oceanic and Atmospheric Administration · 계산은 단순하지만 결론이 정확하다고 생각합니다. 잘못된 논리를 사용 했거나 계산에서 실수를 만들었습니까? 그래서, 결함은 내 혼자. 보정으로 이메일을 보내주세요. erd dot data at noaa dot gov ·
무거운 짐/Contraints
무거운 사용으로, 독립 ERDDAP™ 제약 될 것 이다 (대부분의 경우) 에 의해:
먼 근원 대역폭
- 원격 데이터 소스의 대역폭 — 심지어 효율적인 연결 (e.g.를 통해 OPeNDAP ) 원격 데이터 소스가 매우 높은 대역폭 인터넷 연결이 없는 경우 ERDDAP 's 응답은 빠른 방법으로 제약 될 것입니다 ERDDAP™ 데이터 소스에서 데이터를 얻을 수 있습니다. 해결책은 dataset를 위에 복사하기 위한 것입니다 ERDDAP 's hard drive, 아마도 와 EDDGrid 이름 * 또는 EDDTable코피 ·
ERDDAP 서버 대역폭
- 지원하다 ERDDAP 's 서버는 매우 높은 대역폭 인터넷 연결, ERDDAP 's 응답은 빠른 방법으로 제약 될 것입니다 ERDDAP™ 데이터 소스에서 데이터를 얻을 수 있으며 빠른 방법 ERDDAP™ 고객에게 데이터를 반환할 수 있습니다. 유일한 해결책은 빠른 인터넷 연결을 얻는 것입니다.
기억하기
- 많은 동시 요청이 있다면, ERDDAP™ 메모리를 실행하고 일시적으로 새로운 요청을 거부 할 수 있습니다. ( ERDDAP™ 이를 피하기 위해 메커니즘의 몇 가지가 있으며 발생하면 결과를 최소화합니다.) 그래서 더 많은 메모리 서버에서 더 나은. 32 비트 서버에서, 4+ GB는 진짜로 좋습니다, 2 GB는 좋습니다, 더 적은 추천되지 않습니다. 64 비트 서버에서, 당신은 거의 완전히 기억의 제비를 얻기에 의하여 문제를 피할 수 있습니다. 이름 * \-Xmx 및 -Xms 설정 제품정보 ERDDAP ·Tomcat. 이름 * ERDDAP™ 메모리 8GB 및 -Xmx 세트에서 4000M로 64 비트 서버를 가진 컴퓨터에 무거운 사용법은 기억에 의해 제한되는 경우에, 드물게 입니다.
구동 대역폭
- 서버의 하드 드라이브에 저장된 데이터 액세스는 원격 데이터에 액세스하는 것보다 광대하게 빠릅니다. 그래서, ERDDAP™ 서버는 매우 높은 대역폭 인터넷 연결이있어 하드 드라이브에 데이터에 액세스 할 수 있습니다. 부분적인 해결책은 더 빠른 사용 입니다 (e.g., 10,000 분당 회전수) 자기 하드 드라이브 또는 SSD 드라이브 (그것이 의미가 있다면) · 다른 해결책은 다른 드라이브에 다른 datasets를 저장하기 위한 것입니다, 그래서 cumulative 단단한 드라이브 대역폭은 매우 더 높습니다.
너무 많은 파일들
- 너무 많은 파일에 뚱 베어 디렉토리 — ERDDAP™ 모든 이미지를 캐시하지만 특정 유형의 데이터 요청에 대한 데이터를 캐시합니다. 데이터셋에 대한 캐시 디렉토리를 사용할 수 있습니다. 파일이 캐시에 있는지 확인하려면 아래 요청을 느리게합니다. (정말!) ·<뚱 베어 분 & gt;에서 설정.xml 삭제되기 전에 파일이 캐시에 어떻게 될 수 있는지 설정할 수 있습니다. 더 작은 번호를 설정하면이 문제를 최소화합니다.
CPU의
- 두 가지는 많은 CPU 시간을 가지고:
- NetCDF 4와 HDF 5 이제 데이터의 내부 압축을 지원합니다. 큰 압축을 제거 NetCDF 1 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 / 4 HDF 5개의 자료 파일은 10 이상 초를 가지고 갈 수 있습니다. (구현 오류가 없습니다. 압축의 본질입니다.) 따라서, 압축 파일에 저장된 데이터 세트에 여러 동시 요청은 서버에서 심각한 변형을 넣을 수 있습니다. 이 문제가 있다면, 솔루션은 압축되지 않은 파일에서 인기있는 데이터 세트를 저장하거나 더 많은 코어와 CPU를 사용하여 서버를 얻을 수 있습니다.
- 그래프 만들기 (지도 포함) : 대략 0.2 - 그래프당 1초. 그래서 그래프에 대한 많은 동시 독특한 요청이 있다면 ( WMS 고객은 종종 6 개의 동시 요청을 만듭니다!) , 거기 CPU 한계일 수 있었습니다. 여러 사용자가 실행할 때 WMS 클라이언트, 이것은 문제가된다.
다수 ID ERDDAP 로드밸런싱과 함께?
자주 나오는 질문 : "중량 부하를 처리하려면 여러 동일한 설정할 수 있습니다. ERDDAP 로드 밸런싱과 함께? 그것은 신속하게 핵심에 도착하기 때문에 흥미로운 질문입니다. ERDDAP 's 디자인. 빠른 대답은 "no". 나는 실망한 대답이다는 것을 알고, 그러나 직접적인 이유의 몇몇이 있고 왜 나는 디자인했습니다 ERDDAP™ 다른 접근법 (자주 묻는 질문 ERDDAP s, 이 문서의 대량에 설명) 나는 더 나은 해결책이라고 믿는다.
몇몇 직접적인 이유 당신이 할 수 없는/shouldn't는 다수 동일을 설치하지 않습니다 ERDDAP s는:
- 이름 * ERDDAP™ 먼저 파일에 있는 데이터의 범위를 찾을 수 있을 때 각 데이터 파일을 읽습니다. 그런 다음 인덱스 파일에 대한 정보를 저장합니다. 나중에, 데이터에 대한 사용자 요청이 올 때, ERDDAP™ 요청된 데이터에 대해 볼 수 있는 파일을 파악하기 위해 인덱스를 사용합니다. 복수가 있는 경우 ERDDAP s, 그들은 각각이 색인을 붙일 것입니다, 이는 노력이었다. 아래에 설명된 federated 체계로, 색인은 단지 한 번만 행해집니다,의 한으로 ERDDAP ₢ 킹
- 몇몇 유형의 사용자 요구 (예를 들어, .nc , .png, .pdf 파일) ERDDAP™ 응답의 앞에 전체 파일을 보낼 수 있습니다. 이름 * ERDDAP™ 이 파일을 짧은 시간 동안 캐시합니다. 동일한 요청이 있는 경우 (그것은 종종, 특히 웹 페이지에 URL이 내장 된 이미지에 대한) · ERDDAP™ 파일을 캐시 할 수 있습니다. 여러 동일한 시스템에서 ERDDAP s, 그 캐시 된 파일은 공유되지 않습니다, 그래서 각 ERDDAP™ 필요하고 낭비하게 recreate .nc , .png, 또는 .pdf 파일. 아래에 설명된 federated 체계로, 파일은 한 번만, 한 번만 만듭니다 ERDDAP s 및 재사용.
- ERDDAP 's 구독 시스템은 다중에 의해 공유되지 않습니다 ERDDAP · 예를 들어, load balancer가 user를 1로 보냅니다. ERDDAP™ 그리고 사용자는 dataset에, 그 후에 다른 것을 구독합니다 ERDDAP s는 그 구독을 인식하지 않습니다. 나중에, load balancer가 다른 사용자에게 보내는 경우 ERDDAP™ 그리고 그의 구독 목록을 요청, 기타 ERDDAP™ 아무도 말을 (그를 이끌고 / 다른 ERED에 중복 가입을 DAP ) · 아래에 설명된 federated 체계로, 구독 체계는 단순히 주요, 공중, 합성에 의해 취급됩니다 ERDDAP ·
그렇습니다, 그 문제의 각각을 위해, 나는 할 수 있었습니다 (좋은 노력) 기술연구소 (정보 공유 ERDDAP ₢ 킹) ,하지만 난 생각 Federation-of-의 ERDDAP s 접근 (이 문서의 대량에 설명) 매우 더 나은 전반적인 솔루션, 일부는 다른 문제로 거래하기 때문에 다중 ID- ERDDAP s-with-a-load-balancer 접근은 세상의 데이터 소스의 분산 된 자연을 해결하기 시작할 수 없습니다.
디자인하지 않은 간단한 사실을 수용하는 것이 가장 좋습니다. ERDDAP™ 여러 동일한 배포 ERDDAP 짐 밸런서로 s. 나는 의식적으로 디자인 ERDDAP™ 자주 묻는 질문 ERDDAP 나는 많은 이점을 믿는 s. 그렇지만, 불멸의 ERDDAP s는 우리가 진짜 세계에 있는 데이터 센터의 분산된 체계로 완벽하게 맞춥니다 (다른 IOOS 지역의 생각, 또는 다른 CoastWatch 지역, 또는 NCEI의 다른 부분, 또는 100 다른 데이터 센터에 NOAA , 또는 다른 NASA DAACs, 또는 세계에서 1000의 데이터 센터) · 이 세상의 모든 데이터 센터를 알리는 대신 그들은 그들의 노력을 포기하고 중앙 집중식 "data lake"의 모든 데이터를 넣어해야합니다 (가능한 경우에도, 그것은 수많은 이유에 대한 끔찍한 아이디어입니다 -- 의 수많은 장점을 보여주는 다양한 분석보기 분산 시스템 ) · ERDDAP 's 디자인은 세계와 함께 작동합니다. Data를 생성하는 각 데이터 센터는 유지, 큐레이트 및 데이터를 제공합니다 (그들은) , 아직, ERDDAP™ , 자료는 또한 집중된에서 즉시 유효할 수 있습니다 ERDDAP , 중앙화된 자료 전달을 위한 필요 없이 ERDDAP™ 또는 데이터의 중복 사본 저장. 실제로 주어진 데이터 세트는 동시에 사용할 수 있습니다. 이름 * ERDDAP™ 생성하고 실제로 데이터를 저장하는 조직 (예, GoMOOS) · 이름 * ERDDAP™ 부모 조직에서 (e.g., IOOS 중앙) · 모두에서 NOAA ERDDAP™ · 미국 정부에서 ERDDAP™ · 글로벌 ERDDAP™ (공지사항) · 관련 상품 ERDDAP ₢ 킹 (예, ERDDAP™ HAB 연구기관) · 모든 근본적으로 즉시, 그리고 능률적으로 metadata만 사이 이동하기 때문에 ERDDAP s, 데이터가 아닙니다. 가장 좋은, 초기 후 ERDDAP™ 시작 조직에서, 다른 모든 ERDDAP s는 빨리 설치될 수 있습니다 (몇 시간 일) , 최소 자원과 (데이터 저장을 위해 RAID를 필요로 하지 않는 한 서버는 로컬로 저장하지 않기 때문에) , 그리고 따라서 진짜로 최소한도 비용. 데이터 호수와 중앙화 된 데이터 센터를 유지하고 진정한 대규모, 진정한 비싸고 인터넷 연결, 중앙화 된 데이터 센터의 출석 문제와 비교하여 실패의 단일 지점입니다. 나를 위해, ERDDAP 분산 된, federated 접근은 멀리, 훨씬 우수합니다.
주어진 데이터 센터가 여러 가지를 필요로 하는 상황에서 ERDDAP 높은 수요를 충족시키기 위해 s, ERDDAP 's 디자인은 완벽하게 일치하거나 다중 ID를 초과 할 수 있습니다. ERDDAP s-with-a-load-balancer 접근. 항상 설정 옵션이 있습니다. 다수 합성 ERDDAP ₢ 킹 (아래에서 논의) , 다른 모든 데이터를 얻는 각 ERDDAP 짐 균형 없이 s. 이 경우, 나는 당신이 복합 재료의 각을주는 지점을 만드는 것이 좋습니다 ERDDAP 다른 이름 / 정체성 및 세계의 다른 부분에 설정할 수 있다면 (e.g., 다른 AWS 지구) , 예를들면 ERD \_US\_동부, ERD \_US\_웨스트, ERD \_IE, ERD \_FR, ERD \_IT, 그래서 사용자가 의식적으로, 반복적으로, 특정 작업 ERDDAP , 당신이 실패의 단일 지점에서 위험을 제거 한 추가 이득.
그리드, 클러스터 및 연맹
매우 무거운 사용 하 여, 단일 독립 ERDDAP™ 하나 이상으로 실행됩니다 관련 기사 위에서 나열하고 제안 된 솔루션은 충분합니다. 그런 상황을 위해, ERDDAP™ 확장 가능한 그리드를 구성하기 쉬운 기능을 가지고 (또한 클러스터 또는 federations 호출) 이름 * ERDDAP 매우 무거운 사용을 처리하는 시스템을 허용하는 s (e.g., 대용량 데이터 센터) ·
이용안내 제품정보 일반적인 용어로서의 유형을 나타내는 컴퓨터 클러스터 모든 부품은 물리적으로 한 시설에 위치 할 수 없으며 중앙 관리 할 수 없습니다. 공동 위치, 중앙 소유 및 관리 그리드의 장점 (클러스터) 그들은 가늠자의 economies에서 이득 (특히 인간적인 workload) 시스템의 부품을 쉽게 만들기. non-co-located 그리드의 장점, 비-centrally 소유 및 관리 (한국어) 그들은 인간적인 workload와 비용을 배부하고, 몇몇 추가 결함 포용력을 제공할지도 모릅니다. 아래의 솔루션은 모든 그리드, 클러스터 및 퓨딩 스토그래피에 잘 작동합니다.
확장 가능한 시스템을 설계하는 기본 아이디어는 잠재적 인 병목을 식별하고 시스템을 설계하기 위해 병목을 완화하는 데 필요한대로 시스템을 복제 할 수 있습니다. 이상적으로, 각 복제 부분은 체계의 그 부분의 수용량을 선형으로 증가합니다 (사기의 효율성) · 시스템은 모든 병목에 대한 확장 가능한 솔루션이 없는 확장이 아닙니다. 확장성 효율성에서 다릅니다 (작업이 어떻게 수행 할 수 있는지 — 부품의 효율성) · Scalability는 시스템에서 어떤 수준의 수요를 처리할 수 있습니다. 제품정보 (사기 및 부품의) 많은 서버를 결정, 등, 수요의 주어진 수준에 맞게 필요. 효율성은 아주 중요합니다, 그러나 항상 한계가 있습니다. Scalability는 처리 할 수있는 시스템을 구축하는 유일한 실용적인 솔루션입니다. **이름 *** 무거운 사용. 이상적으로, 체계는 확장하고 능률일 것입니다.
이름 *
이 디자인의 목표는:
- 확장 가능한 건축 만들기 (더 이상 burdened되는 어떤 부분을 복제하여 쉽게 확장) · 데이터의 가용성 및 처리량을 극대화하는 효율적인 시스템을 만들기 위해 가능한 컴퓨팅 리소스를 부여합니다. (비용은 거의 항상 문제입니다.)
- 시스템의 부품의 기능을 균형을 위해 시스템의 한 부분이 다른 부분을 압도하지 않을 것입니다.
- 시스템 설정 및 관리가 쉽습니다.
- 모든 격자 토폴로그래피와 잘 작동하는 건축물을 만들기 위해.
- 은밀하게 실패하는 시스템을 만들기 위해 어떤 부분이 지나치게되면 제한된 방법으로. (대용량 데이터셋을 복사하는 데 필요한 시간은 항상 특정 데이터셋에 대한 수요가 급격히 증가하는 시스템의 능력을 제한합니다.)
- (가능한 한) 어떤 특정에 묶지 않는 건축 만들기 클라우드 컴퓨팅 서비스 또는 기타 외부 서비스 (그것을 필요로 하지 않기 때문에) ·
Recommend
우리의 추천은
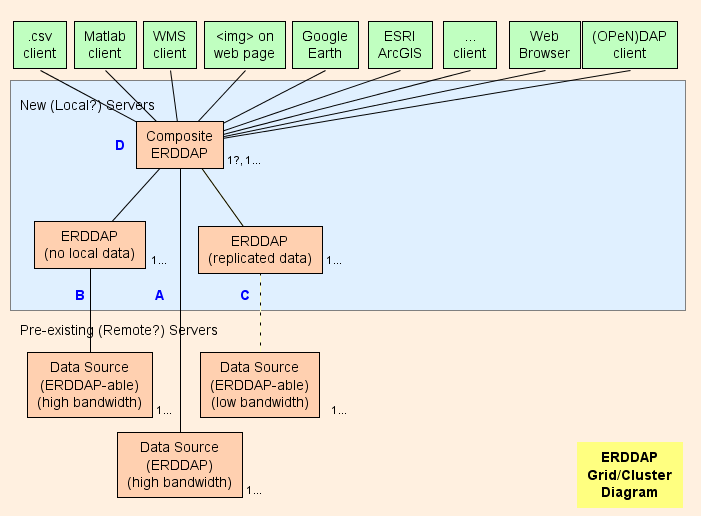
- 기본적으로, 나는 컴포지트 설정 제안 ERDDAP™ ( 사이트맵 도표에서) , 이는 일반 ERDDAP™ 그 외에는 다른 데이터도 ERDDAP · 그리드의 아키텍처는 가능한 한 많은 작업으로 이동하도록 설계되었습니다. (CPU 사용, 메모리 사용, 대역폭 사용) 합성 ERDDAP™ 다른 것 ERDDAP ₢ 킹
- ERDDAP™ 2개의 특별한 dataset 유형이 있습니다, EDDGrid 언어: en 이름 * EDDTableErddap에서 , 참조 기타 데이터셋 ERDDAP ₢ 킹
- 합성 ERDDAP™ 이 datasets에서 데이터 또는 이미지에 대한 요청을받습니다. ERDDAP™ 관련 기사 다른 데이터 요청 ERDDAP™ 서버. 결과는:
- 이것은 아주 능률적입니다 (CPU, 메모리 및 대역폭) , 그렇지 않으면
- 합성 ERDDAP™ 다른 데이터 요청을 보낼 수 있습니다 ERDDAP ·
- 기타 ERDDAP™ 데이터를 얻기 위해, reformat it, and send the data to the Composite ERDDAP ·
- 합성 ERDDAP™ 데이터 수신 (추가 대역폭 사용) , reformat 그것 (추가 CPU 시간 및 메모리 사용) , 사용자가 데이터를 전송 (추가 대역폭 사용) · 데이터 요청을 리디렉션하고 다른 것을 허용 ERDDAP™ 사용자에 직접 응답을 보내기 위해, 합성 ERDDAP™ CPU 시간, 메모리, 또는 데이터 요청에 대역폭을 사용하지 않습니다.
- 리디렉션은 클라이언트 소프트웨어에 상관없이 사용자에게 투명합니다. (브라우저 또는 다른 소프트웨어 또는 명령 줄 도구) ·
- 이것은 아주 능률적입니다 (CPU, 메모리 및 대역폭) , 그렇지 않으면
격자 부속
· :: 모든 원격 데이터 소스에 대 한 높은 대역폭 OPeNDAP 서버, 원격 서버에 직접 연결할 수 있습니다. 원격 서버가 있는 경우 ERDDAP™ , 사용 EDDGrid 보낸 사람Erddap 또는 EDDTableFrom ERDDAP 컴포지트의 데이터를 제공합니다. ERDDAP · 원격 서버가 다른 유형이라면 DAP 서버, 예를들면, THREDDS, Hyrax , 또는 GrADS의 사용 EDDGrid 팟캐스트
₢ 킹 : 모든 것 ERDDAP -able 자료 근원 (데이터 소스에서 ERDDAP 데이터 읽기) high-bandwidth 서버를 가지고, 다른 설정 ERDDAP™ 이 데이터 소스에서 데이터를 제공 할 책임있는 그리드.
- 몇 가지 경우 ERDDAP s는 데이터에 대한 많은 요청을 얻지 못합니다. ERDDAP ·
- 만약에 ERDDAP™ 하나의 원격 소스에서 데이터를 얻기 위해 전용 너무 많은 요청, 추가하기 위해 유혹이 ERDDAP 원격 데이터 소스에 액세스하는 s. 특별한 경우 이것은 감각을 만들 수 있지만, 이것은 원격 데이터 소스를 압도 할 가능성이 더 높습니다. (자기 패배) 원격 데이터 소스에 액세스하여 다른 사용자를 방지 (좋은) · 그런 경우, 다른 설정 ERDDAP™ 데이터셋을 제공하고 데이터셋을 복사하기 위해 ERDDAP 하드 드라이브 (이름 * ₢ 킹 ) , 아마 EDDGrid 이름 * 및/또는 EDDTable코피 ·
- ₢ 킹 서버는 공개적으로 접근해야 합니다.
₢ 킹 : 모든 것 ERDDAP -Low-bandwidth 서버가 있는 데이터 소스 (또는 다른 이유로 느린 서비스입니다.) , 다른 설정 고려 ERDDAP™ dataset의 복사본을 저장합니다. ERDDAP 's hard drives, 아마도 와 EDDGrid 이름 * 및/또는 EDDTable코피 · 몇 가지 경우 ERDDAP s는 데이터에 대한 많은 요청을 얻지 못합니다. ERDDAP · ₢ 킹 서버는 공개적으로 접근해야 합니다.
제품 정보 ERDDAP
사이트맵 :: 합성 ERDDAP™ 자주 묻는 질문 ERDDAP™ 그 외에는 다른 데이터도 ERDDAP ₢ 킹
- 합성 ERDDAP™ datasets의 모든 것에 대한 메모리에 대한 정보는 신속하게 datasets 목록 요청에 응답 할 수 있습니다. (전체 텍스트 검색, 범주 검색, 모든 datasets의 목록) , 개별 데이터셋의 데이터 액세스 양식에 대한 요청, 그래프 양식을 만들거나 WMS 정보 페이지. 이것은 모든 작고 역동적으로 생성 된 HTML 페이지입니다. 그래서 응답은 매우 빠릅니다.
- 실제 데이터에 대한 요청은 신속하게 다른 사람에게 리디렉션됩니다. ERDDAP s의 합성 ERDDAP™ 어떤 CPU 시간, 기억, 또는 대역폭을 사용하지 않고 실제 데이터를 요청할 수 있습니다.
- 가능한 한 많은 작업으로 이동 (CPU의 기억, 대역폭) 합성 ERDDAP™ 다른 것 ERDDAP s의 합성 ERDDAP™ 데이터셋의 모든 데이터를 제공 할 수 있지만 여전히 많은 사용자로부터 데이터 요청의 매우 큰 숫자로 유지 할 수 있습니다.
- Preliminary 시험은 합성물을 나타냅니다 ERDDAP™ CPU 시간의 ~1ms에 있는 대부분의 요구에, 또는 1000의 요구/둘째로 반응할 수 있습니다. 따라서 8개의 핵심 가공업자는 8000의 요구/둘째에 관하여 반응할 수 있어야 합니다. 더 높은 활동의 파열이 발생할 수 있지만, 많은 처리량입니다. 데이터 센터 대역폭이 합성하기 전에 Bottleneck이 될 가능성이 있습니다. ERDDAP™ 병목이 됩니다.
최대 최신 (시간 :) ·
더 보기 EDDGrid /TableErddap에서 합성 ERDDAP™ 소스 데이터셋이 있을 때 각 소스 데이터셋에 대한 저장된 정보를 변경합니다. "부속" 그리고 metadata의 몇몇 조각 변화 (e.g., 시간 변수의 actual\_range ) , 구독 알림 생성. 소스 데이터셋이 자주 변경되는 데이터가 있는 경우 (예를 들면, 새로운 자료 매 초) 그리고 사용 "업데이트" 아래 데이터로 빈번한 변경을 통지하는 시스템, EDDGrid /TableFromErddap은 다음 dataset "reload"까지 이러한 빈번한 변경 사항에 대해 통보하지 않습니다. EDDGrid /TableFromErddap은 완벽하게 업데이트되지 않습니다. 이 문제를 최소화하여 소스 데이터셋의 변경<reloadEveryNMinutes> 더 작은 가치에 (60? 15?) 더 많은 구독 알림이 있음을 알려드립니다. EDDGrid /TableFromErddap 소스 데이터셋에 대한 정보를 업데이트합니다.
또는 데이터 관리 시스템이 소스 데이터셋이 새로운 데이터가 있는지 알고 있다면 (e.g., 데이터 파일을 배치하는 스크립트를 통해) , 그리고 그것이 슈퍼 빈번하지 않는 경우 (e.g., 매 5 분, 또는 덜 자주) , 더 나은 해결책이 있습니다:
- 이용안내<updateEveryNMillis> 소스 데이터셋을 최신 상태로 유지하십시오.
- 소스 dataset의 설정<reloadEveryNMinutes> 더 큰 수에 (1440년?) ·
- 스크립트는 소스 dataset의 접촉 플래그 URL 새 데이터 파일을 배치 한 후 오른쪽. 그것은 소스 데이터셋이 완벽하게 최신 상태로 이어지고 구독 알림을 생성하는 원인이 될 것입니다. EDDGrid /TableFromErddap 데이터 세트. 그대는 EDDGrid /TableFromErddap dataset은 완벽하게 업데이트됩니다. (잘, 추가되는 새로운 자료의 5 초 안에) · 그리고 모든 것이 효율적으로 수행됩니다. (불필요한 dataset reloads 없이) ·
다수 합성 ERDDAP ₢ 킹
- 매우 극단적인 경우에, 또는 결함 포용력을 위해, 당신은 1개 이상 합성을 설치하고 싶을지도 모릅니다 ERDDAP · 시스템의 다른 부분이 될 가능성이 (notably, 데이터 센터의 대역폭) 합성하기 전에 긴 문제가 될 것입니다 ERDDAP™ 병목이 됩니다. 이 솔루션은 아마도 추가 설정, 지리적으로 다양한 데이터 센터 (기타 제품) , 1개의 합성에 각각 ERDDAP™ 서버와 ERDDAP s와 (더 보기) 높은 수요에 있는 datasets의 거울 사본. 이러한 설정은 결함 공차 및 데이터 백업을 제공합니다. (복사를 통해) · 이 경우에, 그것은 합성 경우에 최상 입니다 ERDDAP s에는 다른 URL이 있습니다.
당신이 진짜로 합성의 모두를 원하면 ERDDAP 동일한 URL을 가지고 있는 s는, 주어진 사용자를 합성의 다만 하나에 할당하는 정면 끝 체계를 이용합니다 ERDDAP ₢ 킹 (IP 주소를 기반으로) , 그래서 모든 사용자의 요청은 단지 복합체 중 하나에 간다 ERDDAP ₢ 킹 두 가지 이유가 있습니다.
- dataset가 재로드되고 metadata가 변경되면 (e.g., gridded dataset의 새로운 데이터 파일은 시간 변수를 발생합니다. actual\_range 수정하기) , 합성 ERDDAP s는 일시적으로 synch에서 약간, 그러나 협력업체 · 정상적으로, 그들은 5 초 안에 re-synch, 그러나 때때로 더 길 것입니다. 사용자가 자동화된 시스템을 만드는 경우 ERDDAP™ 구독하기 그 트리거 작업, 간단한 동기화 문제는 크게 될 것입니다.
- 2+ 합성물 ERDDAP s 각 구독의 자신의 세트를 유지 (위에서 설명한 synch 문제 때문에) ·
그래서 주어진 사용자는 단지 합성의 하나에 지시되어야 합니다 ERDDAP 이 문제를 피하기 위해 s. 합성물 중 하나 ERDDAP s는 아래로, 정면 끝 체계는 그것을 리디렉션할 수 있습니다 ERDDAP 다른 사용자 ERDDAP™ 그것은. 그러나, 첫 번째 합성을 일으키는 용량 문제입니다. ERDDAP™ 실패 (overzealous 사용자? 한국어 denial-of-service 공격 ·) , 이것은 매우 가능성이 그 사용자를 다른 합성으로 리디렉션 ERDDAP s는 원인 공급 업체 · 따라서, 가장 강력한 설정은 복합적인 ERDDAP 다른 URL과 s.
또는, 아마도 더 나은, 여러 복합체 설정 ERDDAP 짐 균형 없이 s. 이 경우에, 당신은 각을주는 지점을해야합니다 ERDDAP 다른 이름 / 정체성 및 세계의 다른 부분에 설정할 수 있다면 (e.g., 다른 AWS 지구) , 예를들면 ERD \_US\_동부, ERD \_US\_웨스트, ERD \_IE, ERD \_FR, ERD \_IT, 그래서 사용자 의식적으로, 반복적으로 특정 작업 ERDDAP ·
- \[ 한 서버에서 실행되는 고성능 시스템의 매혹적인 디자인을 위해, 이것을 보십시오 Mailinator의 상세한 설명 · \]
매우 높은 수요의 데이터 세트
정말 특이한 경우 중 하나 · · ₢ 킹 , 또는 ₢ 킹 ERDDAP s는 대역폭 또는 하드 드라이브 제한 때문에 요청을 계속할 수 없습니다, 그것은 데이터를 복사하는 감각 (이름 *) 다른 server+hard에 드라이브 + ERDDAP , 아마 EDDGrid 이름 * 및/또는 EDDTable코피 · 원본 데이터셋을 가지고 있지만, 복사된 데이터셋은 복합물에 1개의 데이터셋으로 완벽하게 나타납니다. ERDDAP™ , 이것은 2개의 datasets가 다른 시간에 경미하게 다른 국가에서 있을 것이기 때문에 어렵습니다 (그렇지만, 원본이 새로운 데이터를 얻은 후에, 그러나 copied dataset는 그것의 사본을 얻습니다) · 따라서 데이터셋이 약간 다른 타이틀을 부여하는 것이 좋습니다. (예, "... (복사 #1) "과"... (복사 #2) ", 또는 아마도 " (미러 # ₢ 킹 ) " 또는 " (서버 # ₢ 킹 ) ·) 합성물에 별도의 datasets로 표시 ERDDAP · 사용자는 목록보기에 사용됩니다. 미러 사이트 인기있는 파일 다운로드 사이트에서,그래서이 놀라지 않거나 실망. 주어진 위치에 대역폭 제한 때문에 다른 사이트에서 거울을 가질 수 있습니다. 미러 복사가 다른 데이터 센터에 있다면, 그 데이터 센터의 복합체에 접근 ERDDAP™ , 다른 제목 (예, "mirror #1) 필수입니다.
RAID versus 일반 하드 드라이브
대용량 데이터셋 또는 데이터셋 그룹이 크게 사용되지 않는 경우, 오류 허용 오차를 제공하므로 RAID에 데이터를 저장하는 것을 의미하며 다른 서버의 처리 전력 또는 대역폭이 필요하지 않습니다. 그러나 dataset가 크게 사용되면 다른 서버에서 데이터를 복사하는 것이 더 많은 의미를 만들 수 있습니다 + ERDDAP™ + 하드 드라이브 (관련 기사 Google은 ) 서버와 RAID를 사용하므로 서버+hardDrive+를 사용하여 여러 데이터셋을 저장할 수 있습니다. ERDDAP 그들 중 하나가 실패할 때까지 그리드에서 s.
실패
어떻게 ...
- 하나의 dataset에 대한 요청의 파열이 있습니다. (e.g., 클래스의 모든 학생들은 동시에 유사한 데이터를 요청) · 한국어 ERDDAP™ 데이터셋이 압도적이고 느리게 되거나 요청을 거부할 수 있음을 알려드립니다. 합성 ERDDAP™ 기타 ERDDAP s는 영향을받지 않습니다. 시스템 내에서 주어진 dataset에 대한 제한 요인이 데이터와 하드 드라이브이기 때문에 (아니다. ERDDAP ) , 유일한 해결책 (로그인) 다른 server+hardDrive+에 dataset의 복사본을 만들려면 ERDDAP ·
- 이름 * · · ₢ 킹 , 또는 ₢ 킹 ERDDAP™ 실패하다 (e.g., 하드 드라이브 실패) · dataset만 (₢ 킹) 에 의해 제공 ERDDAP™ 영향을 미칩니다. dataset의 경우 (₢ 킹) 다른 server+hardDrive+에 미러링 ERDDAP , 효력은 최소한입니다. 문제가 레벨 5 또는 6 RAID의 하드 드라이브 실패라면 드라이브를 교체하고 드라이브에 데이터를 다시 구축 할 수 있습니다.
- 합성 ERDDAP™ 실패? 시스템을 매우 만들려면 높은 가용성 , 당신은 설정할 수 있습니다 다수 합성 ERDDAP ₢ 킹 (위에서 논의) , 뭔가 좋아 사용 NGINX 소개 또는 팟캐스트 로드 밸런싱을 처리하기 위해. 주어진 합성물 주의 ERDDAP™ 많은 사용자로부터 많은 요청을 처리할 수 있습니다. metadata의 요청은 작고 메모리에 있는 정보로 처리됩니다. 데이터 요청 (큰 수 있습니다) 아이들에게 리디렉션 ERDDAP ₢ 킹
단순하고 확장 가능
이 시스템은 설정 및 관리가 용이하며, 어떤 부분이 겹칠 때 쉽게 확장 할 수 있습니다. 주어진 데이터 센터의 유일한 실제 제한은 데이터 센터의 대역폭과 시스템 비용입니다.
대역폭
시스템의 일반적으로 사용되는 구성품의 대략적인 대역폭을 참고하십시오:
| 회사연혁 | 대역폭 (GBytes / s의) | | --- --- | --- --- | | DDR 메모리 | 2.5 마일 | | SSD 드라이브 | 1개 | | SATA 하드 드라이브 | 1. 명세 | | Gigabit 이더네트 | 0.10%년 | | 10월 12 | 0.06(수) | | 10월 3일 | 0.015의 | | 사이트맵 | 0.0002 원 |
그래서, 하나의 SATA 하드 드라이브 (0.3GB/s의) 1개의 서버에서 하나 ERDDAP™ Gigabit Ethernet LAN을 사용할 수 있습니다. (0.1GB/s의) · 그리고 1개의 기가비트 이더네트 랜 (0.1GB/s의) 아마 OC-12 인터넷 연결을 포화할 수 있습니다 (0.06GB/s의) · 그리고 적어도 1개의 근원 명부 OC-12 선은 달 당 대략 $100,000를 요했습니다. (예, 이러한 계산은 시스템의 한계에 밀어, 그것은 매우 슬러지 응답에 리드 때문에 좋지 않다. 그러나 이러한 계산은 계획 및 시스템의 균형을 위해 유용합니다.) 명확하게, 당신의 자료 센터를 위한 적당한 빠른 인터넷 연결은 체계의 가장 비싼 부분까지 입니다. 쉽고 상대적으로 저렴하게 수십 개의 서버와 그리드를 구축 할 수 있습니다. ERDDAP 데이터의 대부분을 신속하게 펌핑 할 수있는 s,하지만 적절하게 빠른 인터넷 연결은 매우 비싸다. 부분적인 해결책은:
- 고객이 필요한 모든 경우 데이터의 하위 설정을 요청할 수 있습니다. 클라이언트가 작은 지역 또는 낮은 해상도의 데이터 만 필요로한다면, 요청해야 할 것입니다. Subsetting은 프로토콜의 중심 초점입니다. ERDDAP™ 요청 데이터에 대한 지원
- 압축 데이터를 전송하는 Encourage. ERDDAP™ 압축 "accept-encoding"을 찾을 경우 데이터 전송 HTTP GET 요청 헤더. 모든 웹 브라우저는 "accept-encoding"을 사용하고 자동으로 응답을 삭제합니다. 기타 고객 (e.g., 컴퓨터 프로그램) 그것을 명시적으로 사용해야합니다.
- ISP 또는 기타 사이트에서 서버가 상대적으로 덜 비싼 대역폭 비용을 제공합니다.
- 서버에 분산 ERDDAP 다른 기관에 s는 비용이 분산되어 있습니다. 당신은 그 후에 당신의 합성을 연결할 수 있습니다 ERDDAP™ 그들의 ERDDAP ₢ 킹
이름 * 클라우드 컴퓨팅 웹 호스팅 서비스는 필요한 모든 인터넷 대역폭을 제공하지만 가격 문제를 해결할 수 없습니다.
확장 가능, 고용량, 결함 허용 시스템에 대한 일반적인 정보는 Michael T. Nygard의 책을 참조하십시오. 다운로드 ·
레깅스
Software Designers는 종종 좋은 사용하려고합니다. 소프트웨어 디자인 패턴 문제 해결. 좋은 본은 좋은 특성을 가진 체계에 지도하는 다목적 해결책, 창조하고 일하기 쉬운 좋은 캡슐화하기 때문에 좋습니다. 패턴 이름은 표준화되지 않습니다. 그래서 나는 패턴을 호출합니다. ERDDAP™ Lego 패턴을 사용합니다. 각 레고 (각 각 ERDDAP ) 단순, 작고, 표준, 독립, 벽돌 (데이터 서버) 정의된 인터페이스로 다른 레로스에 연결할 수 있습니다. ( ERDDAP ₢ 킹) · 부품의 ERDDAP™ 이 시스템은 다음과 같습니다: 구독 및 flagURL 시스템 (통신할 수 있는 ERDDAP ₢ 킹) , EDD ... FromErddap 리디렉션 시스템 및 시스템 RESTful 사용자 또는 기타에 의해 생성 될 수있는 데이터 요청 ERDDAP ₢ 킹 따라서, 주어진 2개 또는 다리 ( ERDDAP ₢ 킹) , 당신은 다른 모양의 거대한 수를 창조할 수 있습니다 (네트워크 토폴로지 ERDDAP ₢ 킹) · 물론 디자인과 특징 ERDDAP™ Lego-like가 아닌 다른 작업을 수행 할 수 있습니다. 그러나 우리는 그 느낌 ERDDAP 's Lego-like 디자인은 모든 것을 가능하게 하는 좋은 다목적 솔루션을 제공합니다. ERDDAP™ 관련 기사 (또는 관리자 그룹) 다른 federation topologies의 모든 종류를 만들려면. 예를 들어, 단일 조직은 세 가지를 설정할 수 있습니다. (더 보기) ERDDAP s 에 표시된 ERDDAP™ 그리드 / 클러스터 다이어그램 위 · 또는 분산 그룹 (IOOS? CoastWatch는? 한국어 사이트맵 NOAA · 미국? 데이터원? 이름 * 사이트맵 한국어 BODC? 로그인 JRC? 사이트맵) 설정할 수 있습니다 ERDDAP™ 각 작은 outpost (그래서 데이터는 소스에 가깝습니다) 그리고 그 후에 합성을 설치하십시오 ERDDAP™ 가상 datasets를 가진 중앙 사무실에서 (항상 완벽하게 최신) 작은 outpost의 각각에서 ERDDAP ₢ 킹 모든 것 ERDDAP s, 세계의 다양한 기관에 설치, 다른 곳에서 데이터를 얻을 ERDDAP s 및/또는 다른 데이터 제공 ERDDAP s, 거대한 네트워크를 형성 ERDDAP · 얼마나 멋진가?! 그래서 Lego의 가능성은 끝이 없습니다. 그것은 왜이 좋은 패턴입니다. 그것은 왜 이것은 좋은 디자인을 위한 입니다 ERDDAP ·
다른 유형의 요청
Data Server topologies의 이 토론의 현실적 합병 중 하나는 다른 유형의 요청과 다른 방법을 최적화하는 것입니다. 이것은 주로 별도의 문제입니다. (빠른 방법 ERDDAP™ 데이터는 데이터 요청에 응답합니까?) topology 토론에서 (데이터 서버와 서버 간의 관계에 대한 거래는 실제 데이터) · ERDDAP™ , 물론, 모든 유형의 요청을 효율적으로 처리하는 것은, 하지만 다른 것보다 더 잘 처리.
- 많은 요청은 간단합니다. 예를 들면: 이 데이터셋의 메타데이터는 무엇인가요? 또는: 이 gridded dataset를 위한 시간 차원의 가치는 무엇입니까? ERDDAP™ 가능한 한 빨리 처리하도록 설계되었습니다 (보통적으로<기억에 이 정보를 유지해서 =2 ms).
- 몇몇 요구는 온건하게 단단합니다. 예를 들면: dataset의이 하위 세트를 (하나의 데이터 파일에) · 이 요청은 어렵지 않다 때문에 상대적으로 신속하게 처리 될 수 있습니다.
- 몇몇 요구는 열심히이고 따라서 시간 consuming입니다. 예를 들면: dataset의이 하위 세트를 (10,000+ 데이터 파일 중 하나일 수도 있고, 압축된 데이터 파일에서 각각 10초를 decompress로 변환할 수 있습니다.) · ERDDAP™ v2.0은 이러한 요청을 처리하는 데 몇 가지 새로운, 빠른 방법을 도입했습니다. 요청의 다른 하위 세트를 촉발하는 여러 노동자 스레드에 대한 요청 핸들을 허용. 그러나이 문제에 대한 또 다른 접근이 있습니다. ERDDAP™ 아직 지원하지 않음: 주어진 dataset를 위한 자료 파일의 subsets는 분리된 컴퓨터에 저장되고 해석될 수 있고, 그 후에 본래 서버에 결합된 결과. 이 접근법은 지도Reduce 그리고는 exemplified 뚱 베어 , 첫번째 (·) 오픈 소스 MapReduce 프로그램은 Google 종이에서 아이디어를 기반으로했습니다. (MapReduce가 필요한 경우 ERDDAP , 이메일을 보내 주시기 바랍니다 erd.data at noaa.gov ·) 구글의 큰 쿼리 MapReduce의 구현이 될 것 같기 때문에 흥미 진진한 tabular datasets에 적용 ERDDAP 's 주요 목표. 당신이 만들 수있는 가능성이 ERDDAP™ BigQuery dataset의 데이터 세트 EDDTable데이터베이스 BigQuery가 JDBC 인터페이스를 통해 액세스 할 수 있기 때문에.
이것은 내 의견입니다.
예, 계산은 단순하다 (지금 약간의 날짜) , 그러나 나는 결론이 정확하다고 생각합니다. 잘못된 논리를 사용 했거나 계산에서 실수를 만들었습니까? 그래서, 결함은 내 혼자. 보정으로 이메일을 보내주세요. erd dot data at noaa dot gov ·
클라우드 컴퓨팅
몇몇 회사는 클라우드 컴퓨팅 서비스를 제공합니다 (₢ 킹 Amazon 웹 서비스 이름 * Google 클라우드 플랫폼 ) · 웹 호스팅 회사 1990년대 중반부터 간단한 서비스를 제공했지만, "클라우드"서비스는 시스템의 유연성과 제공되는 서비스의 범위를 크게 확장했습니다. 이름 * ERDDAP™ grid는 다만 이루어져 있습니다 ERDDAP s 및 이후 ERDDAP s는 Java Tomcat에서 실행할 수있는 웹 응용 (가장 일반적인 애플리케이션 서버) 또는 다른 응용 프로그램 서버, 그것은 비교적 쉽게 설정하기 위해 ERDDAP™ 클라우드 서비스 또는 웹 호스팅 사이트에 그리드. 이 서비스의 이점은:
- 그들은 매우 높은 대역폭 인터넷 연결을 제공합니다. 이 개인은 이러한 서비스를 사용하여 단화 할 수 있습니다.
- 그들은 당신이 사용하는 서비스에 대한 책임을. 예를 들어, 매우 높은 대역폭 인터넷 연결에 액세스 할 수 있지만 실제 데이터 전송에만 지불합니다. 그것은 당신이 거의 압도적 인 시스템을 구축 할 수 (심지어 피크 수요) , 드물게 사용 되는 수용량을 지불하지 않고.
- 그들은 쉽게 확장 할 수 있습니다. 서버 유형을 변경하거나 많은 서버로 추가하거나 원하는만큼 저장 할 수 있습니다. 이 개인은 이러한 서비스를 사용하여 단화 할 수 있습니다.
- 그들은 서버와 네트워크를 실행하는 관리 의무의 많은에서 무료. 이 개인은 이러한 서비스를 사용하여 단화 할 수 있습니다.
이 서비스의 단점은 다음과 같습니다.
- 그들은 그들의 서비스를 담당, 때때로 많은 (절대적인 측면에서; 그것은 좋은 가치는 아닙니다) · 여기에 나열된 가격은 아마존 EC2 · 이 가격 (2015년 6월) 내려오다.
과거에, 가격은 더 높았지만 데이터 파일과 요청의 수는 작았습니다.
미래에, 가격은 낮을 것입니다, 그러나 데이터 파일 및 요청의 수는 더 큽니다.
그래서 세부 사항 변경, 그러나 상황은 상대적으로 상수.
그리고 서비스가 과도하다는 것은 아닙니다, 우리가 사용하고 많은 서비스를 구입하는 것입니다.
- Data Transfer — 데이터 전송 시스템은 이제 무료 (예아!) · 시스템에서 데이터 전송은 $0.09/GB입니다. SATA 하드 드라이브 (0.3GB/s의) 1개의 서버에서 하나 ERDDAP™ Gigabit Ethernet LAN을 사용할 수 있습니다. (0.1GB/s의) · 1 기가비트 이더넷 LAN (0.1GB/s의) 아마 OC-12 인터넷 연결을 포화할 수 있습니다 (0.06GB/s의) · 1개의 OC-12 연결이 ~150,000 GB/month를 전달할 수 있는 경우에, 자료 이동 비용은 150,000 GB @ $0.09/GB = $13,500/month로, 뜻깊은 비용입니다. 분명히, 당신은 수십 개의 열심히 일하는 경우 ERDDAP 클라우드 서비스에서 월간 데이터 전송 수수료가 실질적일 수 있습니다. (최대 $162,000/월) · (다시, 그것은 서비스가 과도하다는 것은 아닙니다, 그것은 우리가 사용하고 많은 서비스를 구입하는 것입니다.)
- 데이터 저장 - TB 당 아마존 요금 $ 50 / 월. (4TB 엔터프라이즈 드라이브를 구입하는 비교 ~ $ 50 / TB, RAID에 넣어 및 관리 비용 총 비용에 추가.) 클라우드에서 데이터를 많이 저장해야하는 경우 상당히 비쌉니다. (e.g., 100TB는 $5000/month를 요할 것입니다) · 하지만 정말 큰 금액의 데이터가 없다면 대역폭/데이터 전송 비용보다 작은 문제입니다. (다시, 그것은 서비스가 과도하다는 것은 아닙니다, 그것은 우리가 사용하고 많은 서비스를 구입하는 것입니다.)
기타 제품
- 설정된 문제: 데이터 파일에서 데이터를 효율적으로 배포하는 유일한 방법은 데이터를 배포하는 프로그램입니다 (₢ 킹 ERDDAP ) 로컬 하드 드라이브에 저장된 데이터가 있는 서버에서 실행 (또는 SAN 또는 로컬 RAID에 매우 빠른 액세스) · 로컬 파일 시스템 ERDDAP™ (그리고 netcdf-java와 같은 라이브러리) 파일에서 특정 바이트 범위를 요청하고 신속하게 응답을 얻을 수 있습니다. 많은 유형의 데이터 요청 ERDDAP™ 파일로 (stride 값이 있는 데이터 요청을 믿을 수 없습니다 > 1개) 프로그램 전체 파일을 요청하거나 비현지에서 파일의 큰 펑크를 효율적으로 수행 할 수 없습니다 (그래서 더) 데이터 저장 시스템 그리고 그 후에 subset를 추출. 클라우드 설정이 제공하지 않는 경우 ERDDAP™ 파일의 바이트 범위에 빠른 액세스 (로컬 파일로 빠른) · ERDDAP 데이터에 액세스하는 것은 심각한 병목과 클라우드 서비스를 사용하여 다른 이점을 negate 것입니다.
Hosted 데이터
위의 비용 혜택 분석에 대한 대안 (데이터 소유자에 근거 (₢ 킹 NOAA ) 클라우드에 저장하기 위해 데이터를 지불) 2012년, 아마존에 도착 (그리고 더 적은 범위, 다른 클라우드 공급자) 클라우드에서 일부 datasets를 호스팅 시작 (사이트맵) 무료 (사용자가 AWS EC2 compute 인스턴스를 빌릴 경우 비용을 복구 할 수있는 희망과 함께 그 데이터로 작업 할 수) · Clearly, 이것은 클라우드 컴퓨팅을 광대하게 더 비용 효과적인, 시간 및 비용으로 데이터를 업로드하고 호스팅 지금 0. 이름 * ERDDAP™ v2.0, 실행을 촉진하는 새로운 기능 ERDDAP 구름에서:
- 지금, EDDGrid fromFiles 또는 EDDTableFromFiles dataset은 인터넷을 통해 원격 및 액세스 할 수있는 데이터 파일에서 생성 할 수 있습니다 (e.g., AWS S3 물통) 으로<cacheFromUrl> 그리고<캐시 크기 GB> 선택권. ERDDAP™ 가장 최근에 사용되는 데이터 파일의 로컬 캐시를 유지합니다.
- 이제 EDDTableFromFiles 소스 파일이 압축되면 (₢ 킹 .tgz ) · ERDDAP™ 그들을 읽을 때 자동으로 삭제합니다.
- 지금, ERDDAP™ 주어진 요청에 응답하는 실은 당신이 사용하는 경우에 요구의 subsections에 일하기 위하여 노동자 실을 spawn 할 것입니다<nThreads> 옵션. 이 병렬화는 어려운 요청에 빠른 응답을 허용해야합니다.
이 변경은 로컬, 블록 레벨 파일 저장 및 AWS S3의 문제를 해결하지 (뚱 베어) S3 데이터에 대한 액세스의 문제는 상당한 지연을 가지고. (1 년 전 (~2014년) , 그 래그는 뜻 이었지만 지금은 훨씬 더 짧고 너무 중요하지 않습니다.) 모든 것에서, 그것은 그 설정 ERDDAP™ 클라우드에서 훨씬 더 잘 작동합니다.
**이름 *** — Matthew Arrott와 그의 그룹 덕분에 원래의 OOI 노력에 대한 그들의 작업에 대한 ERDDAP™ 구름과 결과 토론에서.
Datasets의 원격 복제
그리드와 federations의 위의 토론과 관련된 일반적인 문제가있다 ERDDAP s: datasets의 먼 복제. 기본 문제는 다음과 같습니다. 데이터 공급자는 때때로 변경되는 데이터 세트를 유지하고 사용자가이 데이터 세트의 최신 로컬 복사를 유지하려는 (다양한 이유로) · 분명히, 이것의 거대한 숫자가있다. 몇몇 변화는 다른 사람 보다는 취급하는 훨씬 더 어렵습니다.
- 빠른 업데이트 로컬 dataset up-to-date를 유지하기 위해 더 어렵습니다. 현재 위치 (e.g., 3 초 안에) 소스에 모든 변경 후, 오히려 예를 들어, 몇 시간 이내에.
- 자주 묻는 질문 자주 묻는 질문 예를 들어, 하루에 한 번 변경은 0.1 초마다 변경 사항을 처리하는 것이 훨씬 쉽습니다.
- 작은 변화 소스 파일에 작은 변화는 완전히 새로운 파일보다 처리하기 어렵습니다. 작은 변화가 파일에 어디에서나 있을 수 있는지 특히 사실입니다. 작은 변화는 검출하고 복제해야 할 데이터를 격리하기 어렵습니다. 새로운 파일은 쉽게 감지하고 효율적으로 전송합니다.
- 전체 Dataset 전체 dataset up-to-date를 유지하면 최근 데이터 유지보다 어렵습니다. 몇몇 사용자는 다만 최근 자료를 필요로 합니다 (예, 마지막 8 일의 가치) ·
- 다수 Copies 다른 사이트에서 여러 개의 원격 사본을 유지하는 것은 하나의 원격 복사를 유지보다 어렵습니다. 이것은 사기 문제입니다.
소스 데이터 세트와 사용자의 요구와 기대에 대한 변화의 엄청난 수의 변화가 있습니다. 많은 변화는 해결하기가 매우 어렵습니다. 한 상황을위한 최고의 솔루션은 종종 다른 상황에 가장 적합한 솔루션이 아닙니다. 그러나 보편적 인 훌륭한 솔루션이 아닙니다.
관련 기사 ERDDAP™ 제품정보
ERDDAP™ Dataset의 원격 복사를 유지하기 위해 추구하는 시스템의 일부로 사용될 수있는 여러 도구를 제공합니다.
- ERDDAP 이름 * RSS (리치 사이트 개요?) 제품정보
리모트에 dataset가 있는지 확인하는 빠른 방법 ERDDAP™ 수정되었습니다. - ERDDAP 이름 * 구독 서비스
더 효율적인 (더 보기 RSS ) 접근: 그것은 즉시 전자 우편을 보내거나 dataset가 업데이트될 때마다 각 가입자에 URL을 접촉하고 변화에서 유래된 갱신. ASAP가 발생하고 그 노력이 없다. (설문 조사 RSS 제품정보) · 사용자는 다른 도구를 사용할 수 있습니다 (이름 * 다운로드 ) 구독 시스템의 이메일 알림에 반응합니다. 예를 들어, 사용자는 원격에서 dataset에 가입 할 수 있습니다. ERDDAP™ IFTTT를 사용하여 구독 이메일 알림에 반응하고 로컬 데이터셋을 업데이트합니다. - ERDDAP 이름 * 주력 시스템
오시는 길 ERDDAP™ 관리자는 데이터셋을 그의/her에 알려줍니다. ERDDAP ASAP를 다시로드합니다. 플래그의 URL 형태는 스크립트에서 쉽게 사용할 수 있습니다. flag의 URL 형태는 구독에 대한 행동으로도 사용될 수 있습니다. - ERDDAP 이름 * "files" 시스템
파일의 Apache-style 디렉토리 목록을 포함하여 주어진 데이터셋에 대한 소스 파일에 액세스할 수 있습니다. ("웹 액세스 가능한 폴더") 각 파일 다운로드 URL, 마지막으로 수정된 시간, 크기가 있습니다. 사용의 한쪽 "files" 시스템은 소스 파일이 다른 변수 이름과 다른 메타데이터를 가질 수 있다는 것입니다. dataset보다 ERDDAP · 원격으로 ERDDAP™ dataset는 소스 파일에 대한 액세스를 제공합니다, 그것은 rsync의 가난한 사람의 버전의 가능성을 엽니 다: 그것은 원격 파일이 변경되고 다운로드해야합니다 로컬 시스템에 쉽게됩니다. (이름 * cacheFromUrl 옵션 이것의 사용을 만들 수 있는 아래에.)
제품정보
문제와 무한한 수의 솔루션에 대한 엄청난 변화가 있지만, 솔루션에 대한 기본적인 접근 방식은 다음과 같습니다.
사용자 정의, Brute Force Solutions
특정 솔루션은 주어진 상황에 최적화 된 사용자 정의 솔루션을 수공하는 것입니다. 데이터가 변경되고 사용자가 변경 된 데이터를 요청할 수 있도록 데이터가 변경 된 데이터를 감지 / 식별하는 시스템을 만들 수 있습니다. 글쎄, 당신은 이것을 할 수 있지만 단점이 있습니다.
- 사용자 정의 솔루션은 많은 작업입니다.
- 사용자 정의 솔루션은 일반적으로 주어진 데이터 세트에 사용자 정의되어 사용자가 쉽게 재사용 할 수 없습니다.
- 사용자 정의 솔루션은 구축하고 유지해야합니다. (그것은 좋은 아이디어가 없다. 그것은 항상 좋은 아이디어는 일을 피하고 다른 사람이 일을 할 수 있습니다!)
다른 상황에서 쉽게 재사용 할 수있는 다른 사람에 의해 구축 및 유지되는 일반적인 솔루션에 대해 거의 항상 더 나은이기 때문에이 접근 방식을 활용합니다.
rsync의
rsync의 사용자의 원격 컴퓨터에서 소스 컴퓨터에서 파일의 수집을 유지하는 기존의, 근사하게 좋은 범용 솔루션입니다. 그것이 작동하는 방법:
- 몇몇 사건 (예, ERDDAP™ 구독 시스템) rsync를 실행하는 방아쇠, (또는, cron 작업은 사용자의 컴퓨터에서 매일 특정 시간에 rsync를 실행)
- 소스 컴퓨터에 rsync를 접촉,
- 각 파일의 펑크에 대한 해시 시리즈를 계산하고 사용자의 rsync에 그 해시를 전달합니다.
- 파일의 사용자의 복사에 대한 유사한 정보와 비교,
- 그런 다음 변경된 파일의 펑크를 요청합니다.
그게 전부 고려, rsync는 아주 빨리 작동합니다 (e.g., 10 초 플러스 데이터 전송 시간) 매우 효율적입니다. 있음 rsync의 변화 다른 상황을 최적화 (e.g., precalculating에 의해 각 소스 파일의 펑크의 해시) ·
rsync의 주요 약점은: 그것을 설치하기 위하여 몇몇 노력이 걸립니다 (보안 문제) ; 몇몇 사기 문제점이 있습니다; 그리고 그것은 NRT datasets 진짜로 최신을 지키기를 위해 좋지 않습니다 (e.g., 그것은 각 5 분에 관하여 rsync를 더 사용하는 awkward입니다) · 약점을 처리할 수 있는 경우, 또는 상황에 영향을 주지 않는 경우, rsync는 이제 데이터셋의 원격 복제를 포함하는 많은 시나리오를 해결하기 위해 지금 사용할 수있는 우수한 범용 솔루션입니다.
상품이 있습니다. ERDDAP™ rsync 서비스에 대한 지원을 추가하려고 할 목록 ERDDAP (꽤 어려운 작업) , 그래서 어떤 클라이언트는 rsync를 사용할 수 있다 (또는 변형) dataset의 최신 사본을 유지하기 위해. 누군가가 이것을 일하고 싶은 경우에, 이메일을 보내십시오 erd.data at noaa.gov ·
rsync가 더 적은 것을 하는 다른 프로그램은, 때때로 dataset 복제에 동쪽으로 향합니다 (파일 복사 수준에서 종종) , 예를들면 Unidata 이름 * 사이트맵 ·
Url에서 캐시
캐시FromUrl 설정 가능 (시작하기 ERDDAP™ v2.0의) 모든 것 ERDDAP 파일에서 datasets를 만드는 dataset 유형 (기본적으로, 모든 subclasses의 EDDGrid 파일 형식 이름 * EDDTable파일 ) · 뚱 베어 FromUrl은 자동으로 다운로드하고 캐시를 통해 원격 소스에서 복사하여 로컬 데이터 파일을 유지합니다. FromUrl 설정. 원격 파일은 Web Accessible Folder 또는 THREDDS가 제공하는 디렉토리 같은 파일 목록에서 할 수 있습니다. Hyrax S3 물통, 또는 ERDDAP 이름 * "files" 시스템.
원격 파일의 소스가 원격이라면 ERDDAP™ 소스 파일을 제공하는 dataset ERDDAP™ "files" 체계, 그 후에 당신은 할 수 있습니다 이름 * 먼 dataset에, 그리고 사용 플래그 URL 귀하의 로컬 데이터셋을 구독하기 위해. 그런 다음 원격 데이터셋이 변경 될 때마다 데이터셋의 플래그 URL에 연락할 것입니다. 이는 ASAP를 다시로드하고 변경된 원격 데이터 파일을 다운로드합니다. 이 모든 것은 아주 빨리 일어납니다 (보통 ~5 초 플러스 변경된 파일을 다운로드해야 하는 시간) · 이 접근법은 소스 데이터셋 변경이 주기적으로 추가되는 새로운 파일이며 기존 파일이 결코 변경되지 않을 때 잘 작동합니다. 이 접근법은 모든 데이터가 자주 부과되면 잘 작동하지 않습니다. (또는 대부분의) 기존 소스 데이터 파일의 경우 로컬 데이터셋이 자주 전체 원격 데이터셋을 다운로드하기 때문입니다. (이것은 rsync-like 접근이 필요합니다.)
아카이브ADataset
ERDDAP™ 이름 * 아카이브ADataset 데이터가 dataset에 자주 추가될 때 좋은 해결책이지만, 오래된 자료는 결코 바뀌지 않습니다. 기본적으로, ERDDAP™ 관리자는 ArchiveADataset을 실행할 수 있습니다. (아마 스크립트에서, 아마 cron에 의해 실행) 추출하고 싶은 dataset의 subset를 지정합니다. (여러 파일에서) 및 패키지 .zip 또는 .tgz 파일, 그래서 당신은 흥미있는 사람들 또는 그룹에 파일을 보낼 수 있습니다 (e.g., 아카이브 NCEI) 또는 다운로드 할 수 있습니다. 예를 들어, 12시 10분에서 매일 ArchiveADataset을 실행할 수 있으며, .zip 모든 데이터의 12 : 00의 이전 날까지 12:00 오늘. (또는,이 주간, 월, 또는 년, 필요에 따라.) 패키지 된 파일이 오프라인으로 생성되기 때문에 타임 아웃 또는 너무 많은 데이터의 위험이 없습니다. 표준 ERDDAP™ 이름 *
ERDDAP™ 's 표준 요청 시스템
ERDDAP™ 's 표준 요청 시스템은 데이터가 dataset에 자주 추가될 때 대체 좋은 솔루션이지만, 이전 데이터는 결코 변경되지 않습니다. 기본적으로, 누구든지 특정한 범위를 위한 자료를 얻는 표준 요구를 사용할 수 있습니다. 예를 들어, 12 : 10에서 매일 오전 12 시부 터 오후 12 시까 지 원격 데이터 세트에서 모든 데이터를 요청할 수 있습니다. 제한 사항 (ArchiveADataset 방식과 비교) timeout의 위험 또는 단일 파일에 대한 너무 많은 데이터가 있습니다. 더 빈번한 요청에 따라 제한을 피할 수 있습니다.
다운로드
\[ 이 옵션은 아직 존재하지 않지만 가까운 미래에 구축 할 수 있습니다. \]
새로운 다운로드 dataset 유형 ERDDAP™ v2.0은 또 다른 솔루션을 설정할 수 있습니다. 이 유형의 dataset에 의해 유지되는 underlying 파일은 기본적으로 dataset에 변화를 기록하는 파일입니다. 정기적으로 로컬 데이터셋을 유지하는 시스템을 구축할 수 있어야 합니다. (또는 트리거를 기반으로) 마지막 요청 이후 원격 데이터셋으로 만든 모든 변경 사항을 요청합니다. 그것은 능률이어야 합니다 (더 보기) rsync보다 많은 어려운 시나리오를 처리하지만 원격 및 로컬 데이터 세트가 EDDTableFromHttpGet 데이터 세트 인 경우에만 작동합니다.
누군가가 이것을 일하고 싶은 경우에, 접촉하십시오 erd.data at noaa.gov ·
분산 데이터
위의 솔루션의 아무도는 실제 시간의 복제 때문에 문제의 어려운 변화를 해결하는 훌륭한 작업입니다. (사이트맵) datasets는 모든 가능한 시나리오 때문에 매우 어렵습니다.
좋은 해결책이 있습니다: 자료를 복제하는 것을 시도하지 마십시오. 대신, 1개의 권한 근원을 사용하십시오 (1개의 dataset에 ERDDAP ) , 데이터 공급자에 의해 유지 (e.g., 지역 사무실) · dataset에서 데이터를 원하는 모든 사용자는 항상 소스에서 얻을. 예를 들어, 브라우저 기반 앱은 URL 기반 요청에서 데이터를 얻을 수 있으므로 요청이 원격 서버의 원본 소스에 있다는 것이 중요하지 않습니다. (ESM을 호스팅하는 동일한 서버가 아닙니다.) · 많은 사람들이 오랜 시간 동안이 분산 된 데이터 접근법을 조언했습니다. (e.g., 지난 20 년 동안 로이 Mendelssohn) · ERDDAP 그리드 / 패딩 모델 (이 문서의 상위 80%) 이 접근법에 근거합니다. 이 솔루션은 Gordian Knot에 칼처럼 - 전체 문제는 멀리 간다.
- 이 솔루션은 매우 간단합니다.
- 이 솔루션은 복제 된 데이터셋을 유지하기 위해 수행되지 않고도 매우 효율적입니다. (₢ 킹) 업데이트
- 사용자는 언제든지 최신 데이터를 얻을 수 있습니다. (e.g., 만 ~0.5 초의 지연) ·
- 그것은 꽤 잘 스케일링을 개선하는 방법이 있습니다. (이 문서의 상위 80 %의 토론을 참조하십시오.)
아니, 이것은 가능한 모든 상황에 대 한 솔루션이 아닙니다, 하지만 그것은 광대 한 대다수에 대 한 훌륭한 솔루션입니다. 문제 / 문제가있는 경우 특정 상황에서이 솔루션이 문제가 발생하면이 솔루션의 멋진 장점 때문에 이러한 문제를 해결하거나 그 약점과 생활하는 데 종종 가치가 있습니다. 이 해결책이 주어진 상황을 위해 진짜로 unacceptable 인 경우에, 예를들면, 당신이 진짜로 자료의 국부적으로 사본이 있어야 할 때, 그 후에 위에 토론된 다른 해결책을 고려하십시오.
이름 *
단일, 완벽하게 모든 시나리오에서 모든 문제를 해결하는 간단한 솔루션이 없습니다. (rsync와 Distributed Data는 거의 입니다) , 희망적으로 당신이 당신의 특정한 상황을 위한 수락가능한 해결책을 찾아낼 수 있는 충분한 공구 및 선택권이 있습니다.