スケーリング
ERDDAP™ - 重負荷、グリッド、クラスタ、フェデレーション、クラウドコンピューティング
ERDDAP : : :
ERDDAP™ さまざまなローカルおよびリモートソースから科学データを集約し、一般的なファイル形式でデータのサブセットをダウンロードし、グラフやマップを作成するためのシンプルで一貫した方法を提供するWebアプリケーションとWebサービスです。 このページでは、重い問題について議論しています ERDDAP™ 使用は、グリッド、クラスター、フェデレーション、クラウドコンピューティングを介して非常に重い負荷に対処するための可能性をロードし、探索します。
オリジナル版は2009年6月より作成されました。 重要な変更はありません。 2019年4月15日更新
免責事項
このページの内容は、ボブ・サイモンの個人的な意見であり、必ずしも政府や政府のいかなる位置を反映していない National Oceanic and Atmospheric Administration お問い合わせ 計算は単純ですが、結論は正しいと思います。 障害のあるロジックを使用していたり、自分の計算で間違いを犯したりしましたか? そうなら、欠陥は一人で鉱山です。 メールでのお問い合わせ erd dot data at noaa dot gov お問い合わせ
重負荷/制約
重い使用を使って、スタンドアロン ERDDAP™ 制約される (ほとんどの場合から少なくとも可能性) によって:
遠隔源の帯域幅
- リモートデータソースの帯域幅 — 効率的な接続でも (例) OPeNDAP ) リモートデータソースが非常に高い帯域幅のインターネット接続を持っている場合を除き、 ERDDAP 's の応答は速度によって制約されます ERDDAP™ データソースからデータを取得できます。 データセットをコピーするソリューション ERDDAP 's ハードドライブ, おそらくと EDDGrid コピー または EDDTableコピー お問い合わせ
ERDDAP 'サーバー帯域幅
- なし ERDDAP 's サーバーは非常に高い帯域幅のインターネット接続を持っています、 ERDDAP 's の応答は速度によって制約されます ERDDAP™ データソースからデータを取得することができ、高速化 ERDDAP™ クライアントにデータを返すことができます。 唯一のソリューションは、より高速なインターネット接続を取得することです。
メモリ
- 同時リクエストが多い場合、 ERDDAP™ メモリを外して一時的に新しいリクエストを拒否することができます。 ( ERDDAP™ これを回避し、それが起こるならば、結果を最小限に抑えるメカニズムのカップルを持っています。) つまり、サーバのメモリが向上します。 32ビットサーバーでは、4GBは本当に良いです、2 GBは大丈夫です、あまりお勧めしません。 64ビットサーバーでは、メモリの多くを取得することで、ほぼ完全に問題を回避できます。 詳細はこちら \-Xmx と -Xms の設定 お問い合わせ ERDDAP /Tomcat。 ログイン ERDDAP™ メモリの8GBと-Xmxセットを4000Mに設定した64ビットサーバーでコンピュータ上で重く使用することはまれに、メモリによって制約される。
ハイドドライブ帯域幅
- サーバーのハードドライブに保存されたデータへのアクセスは、リモートデータにアクセスするよりも大幅に高速です。 でも、そうなら、 ERDDAP™ サーバは帯域幅が非常に高く、ハードドライブ上のデータにアクセスすることはボトルネックになります。 部分的な解決策は、より速く使うことです (例:10,000RPM) 磁気ハードドライブまたはSSDドライブ (センスのコストを賢くするなら) お問い合わせ 別のソリューションは、異なるドライブ上の異なるデータセットを保存することです。
Too 多くのファイルキャッシュ
- たくさんのファイルをtoo キャッシュ ディレクトリ — ERDDAP™ すべての画像をキャッシュしますが、特定の種類のデータリクエストのデータをキャッシュするだけです。 一時的に複数のファイルを持つデータセット用のキャッシュディレクトリに可能です。 これは、ファイルがキャッシュにあるかどうかを確認するリクエストを遅くします (本当に!) お問い合わせ<キャッシュ Minutes> で セットアップ。xml ファイルが削除される前にキャッシュにどのくらいの期間を設定できます。 小さな番号を設定すると、この問題を最小限に抑えます。
ログイン
- 2 回のみ CPU 時間を多く取る:
- NetCDF 4と4 HDF データの内部圧縮をサポートできるようになりました。 大きい圧縮された分解 NetCDF 4 / HDF 5つのデータファイルが10秒以上かかります。 (実装障害ではありません。 圧縮の性質です。) そのため、圧縮されたファイルに保存されたデータでデータセットへの複数の同時リクエストは、任意のサーバーに厳しい負担をかけることができます。 これが問題の場合、このソリューションは、非圧縮ファイルで人気のあるデータセットを保存したり、複数のコアを持つCPUでサーバーを取得することです。
- グラフの作成 (地図を含む) : グラフごとの約0.2〜1秒 そのため、グラフの同時固有のリクエストが多かった場合 ( WMS クライアントは、多くの場合、6つの同時リクエストを作る!) CPUの制限があるかもしれません。 複数のユーザーが実行しているとき WMS クライアントは問題になります。
複数のIdentical ERDDAP s の負荷分散?
質問はしばしば出てくる: "重負荷に対処するため、複数の同一を設定できます ERDDAP s の負荷分散? それはすぐにの中心に得るのでそれは興味深い質問です ERDDAP デザイン。 迅速な回答は「いいえ」です。 答えを失望していることは知っていますが、直接的な理由のカップルと私が設計したいくつかの大きな根本的な理由があります ERDDAP™ 異なるアプローチを使用する (の連盟の ERDDAP s、この文書のバルクで説明) 私はより良いソリューションであると信じている、。
複数の同一の設定ができない直接的な理由 ERDDAP s は:
- 与えられた ERDDAP™ ファイル内のデータ範囲を見つけるために最初に利用可能なときに各データファイルを読み込みます。 その情報をインデックスファイルに保存します。 後で、データに対するリクエストが来るとき、 ERDDAP™ そのインデックスを使用して、要求されたデータを参照するファイルを確認します。 複数の同一であった場合 ERDDAP s, 彼らはそれぞれ、このインデックス作成を行うだろう, これは、努力を浪費. 以下に説明したフェデレーションシステムでは、インデックス作成は一度だけ行われます。 ERDDAP お問い合わせ
- ユーザーのリクエストの種類 (例) .nc 、.png、.pdfファイル) ERDDAP™ 応答が送信される前にファイル全体を作る必要があります。 お問い合わせ ERDDAP™ これらのファイルを短時間でキャッシュします。 同一リクエストがない場合 (多くの場合、特にURLがWebページに埋め込まれている画像の場合) , ERDDAP™ キャッシュされたファイルを再利用することができます。 複数の同一のシステム ERDDAP s、これらのキャッシュされたファイルは共有されていないので、それぞれ ERDDAP™ 不要で無駄に再創造する .nc 、.png、または.pdfファイル。 以下に示すフェデレーションされたシステムによって、ファイルは一度だけ作られます、 ERDDAP s、再使用。
- ERDDAP 's サブスクリプションシステムが複数で共有されるように設定されていない ERDDAP お問い合わせ 例えば、ロードバランサーが1つにユーザーを送信します ERDDAP™ ユーザはデータセットを購読します。 ERDDAP s はそのサブスクリプションを認識しません。 その後、ロードバランサーが異なるユーザーに送信する場合 ERDDAP™ サブスクリプションのリストを要求し、その他 ERDDAP™ 何もないと言う (他の ERED で重複サブスクリプションを作成するために彼/彼女をリード DAP ) お問い合わせ 以下に示すフェデレーションシステムでは、サブスクリプションシステムは、単にメイン、パブリック、コンポジットによって処理されます ERDDAP お問い合わせ
はい、それぞれの問題に対して、私はできる (素晴らしい努力で) ソリューションを設計 (情報を共有する ERDDAP ツイート) 、しかし私は思う フィードバック ERDDAP s アプローチ (この文書の一括で記述) それは複数の代表的な他の問題に対処するので、はるかに優れた全体的なソリューションです。 ERDDAP s-with-a-load-balancer アプローチは、世界におけるデータソースの分散性ではなく、アドレスに開始しません。
私は設計しなかった単純な事実を受け入れるのが最善です ERDDAP™ 複数の同一として展開する ERDDAP s の負荷バランサ。 私は意識的に設計しました ERDDAP™ 連盟内でうまくいく ERDDAP 私は多くの利点があると信じているs。 確かに、連盟 ERDDAP sは、私たちが現実世界で持っているデータセンターの分散型分散システムと完全に整列されます (異なるIOOS領域、または異なるコーストウォッチ領域、またはNCEIの異なる部分、または100の他のデータセンターの思考 NOAA , または異なる NASA DAACs, または 1000 の世界のデータセンター) お問い合わせ 彼らが彼らの努力を放棄し、一元化された「データ湖」にすべてのデータを置く必要がある世界のすべてのデータセンターを言う代わりに (可能であった場合でも、多くの理由で恐ろしい考えです。さまざまな分析では、多くの利点を示す 分散型システム ) , ERDDAP 's design は、世界とつながるデザインです。 データを生成する各データセンターは、データの維持、キュレーション、および提供を継続できます。 (彼らが) とまだ、 ERDDAP™ 、データは一元化からすぐに利用できます ERDDAP 、集中化にデータを送信する必要性なしで ERDDAP™ データの重複コピーを格納する。 確かに、与えられたデータセットは同時に利用できます から ERDDAP™ 実際にデータを格納する組織で (例:GoMOOS) , から ERDDAP™ 親組織で (例:IOOS セントラル) , 全てから NOAA ERDDAP™ , 全米連邦政府から ERDDAP™ , グローバルから ERDDAP™ (ログイン) , 専門分野 ERDDAP ツイート (例) ERDDAP™ HAB研究に専念する機関) , メタデータのみが間で転送されるため、すべての本質的に瞬時に効率的に ERDDAP s、データではなく。 最初から、すべてのベスト ERDDAP™ 原発組織で、他者全員 ERDDAP sはすぐにセットアップすることができます (数時間勤務) 最小限のリソースで (ローカルのデータを保存しないため、データストレージの RAID を必要としない 1 つのサーバー) 、そして従って偽りなく最低の費用。 集中型データセンターの設定と維持のコストと、データ湖と本当に巨大で、本当に高価な、インターネット接続、および集中型データセンターの参加者の問題は、故障の1つのポイントです。 お問い合わせ ERDDAP s の分散化、フェデレーションされたアプローチは遠く、はるかに優れています。
特定のデータセンターが複数のニーズを必要とする状況 ERDDAP sは高需要を満たすために、 ERDDAP 's design は複数の代表的な性能を一致するか、または超過する十分に可能です- ERDDAP s-with-a-load-balancer アプローチ。 常に設定するオプションがあります 多岐コンポジット ERDDAP ツイート (下記の通り) 、それぞれが他のデータからすべてのデータを取得する ERDDAP sの負荷バランス無し。 この場合、各コンポジットを付与するポイントを作ることをお勧めします ERDDAP s は別の名前/アイデンティティおよび可能であれば世界の異なった部分でそれらをセットアップします (例:AWS の異なる領域) 、例えば、 ERD \_US\_イースト、 ERD \_US\_西, ERD \_IE, ERD \_FR, ERD \_IT, ユーザが意識的に, 繰り返し, 特定の作業 ERDDAP 、失敗の1つのポイントからリスクを削除した利点が追加されました。
グリッド、クラスタ、およびフェデレーション
非常に重い使用の下で、単一のスタンドアローン ERDDAP™ 1 つ以上で実行される 制約 上記および提案されたソリューションも不十分です。 そのような状況のために、 ERDDAP™ スケーラブルグリッドを簡単に構築できる機能 (クラスターやフェデレーションとも呼ばれる) インフォメーション ERDDAP システムが非常に重い使用を処理することを可能にするs (大型データセンター向けなど) お問い合わせ
お問い合わせ グリッド 型を示すための一般的な用語として コンピュータクラスター すべての部品が1つの施設に物理的に配置されていない、または集中的に管理されない場合があります。 共同配置された、集中的に所有し、管理された格子の利点 (クラスター) スケールの経済性から恩恵を受ける (特に人間のワークロード) システムの部品を一緒に働かせ、簡素化して下さい。 非連結格子、非中央の所有および管理の利点 (フェデレーション) 人間のワークロードおよび費用を配り、付加的な欠陥の許容を提供するかもしれないことです。 以下に提案するソリューションは、すべてのグリッド、クラスター、およびフェデレーションのトポグラフィに適しています。
スケーラブルなシステムの設計の基本的な考え方は、潜在的なボトルネックを特定し、システムの一部がボトルネックを軽減するために必要なように複製することができるように、システムの設計することです。 理想的には、各レプリカ部品は、システムのその部分の能力を線形に増加させます (スケールの効率) お問い合わせ 全てのボトルネックのスケーラブルなソリューションがなければ、システムはスケーラブルではありません。 スケーラビリティ 効率とは異なる (タスクを素早く実行する方法 — パーツの効率性) お問い合わせ スケーラビリティは、システムがあらゆるレベルの要求に対応できるようにします。 ソリューション (スケールと部品) 特定のレベルの要求に応じるために、サーバーなど、必要なサーバーの数を決定します。 効率は非常に重要ですが、常に限界があります。 スケーラビリティは、処理できるシステムを構築する唯一の実用的なソリューションです。 お問い合わせ 重い使用。 理想的には、システムがスケーラブルで効率的になります。
ゴール
このデザインの目標は次のとおりです。
- 拡張可能なアーキテクチャを作成する (過負荷になる部分を複製することで簡単に拡張できるもの) お問い合わせ 利用可能なコンピューティングリソースに与えられたデータの可用性とスループットを最大限に活用する効率的なシステムを作る。 (コストはほぼ常に問題です。)
- システムの1つの部分が別の部分を圧倒しないように、システムの一部の機能のバランスをとるため。
- システムがセットアップし、管理すること容易であるように簡単な建築を作るため。
- すべてのグリッドのトポグラフィーでうまく機能するアーキテクチャを作る。
- どの部分が過負荷になったら優雅で、限られた方法で失敗するシステムを作るため。 (大規模なデータセットをコピーするために必要な時間は、特定のデータセットに対する要求の急激な増加に対処するためのシステムの能力を常に制限します。)
- (可能であれば) 特定の条件に縛られていないアーキテクチャを作るため クラウドコンピューティング サービスまたはその他の外部サービス (それを必要としないので) お問い合わせ
推奨事項
当社の推奨事項は
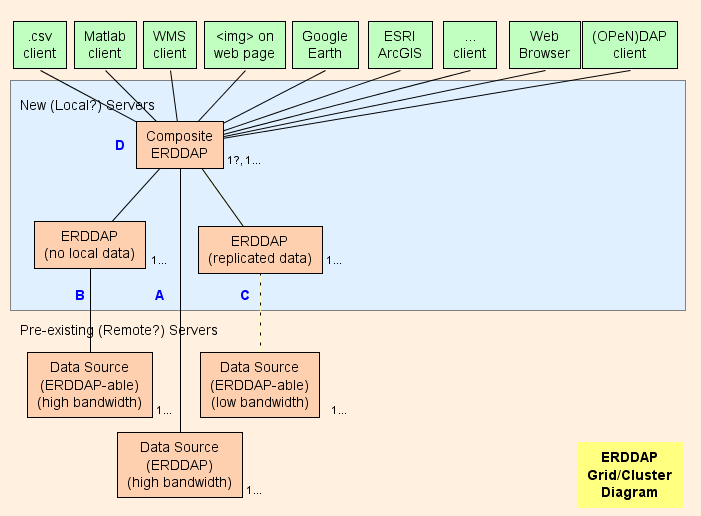
- 基本的にはコンポジットの設定をおすすめします ERDDAP™ ( ダイバーシティ ダイアグラム) 、それは規則的です ERDDAP™ それ以外は、単に他のデータを扱う ERDDAP お問い合わせ グリッドのアーキテクチャは、できるだけ多くの仕事をシフトするように設計されている (CPU使用量、メモリ使用量、帯域幅使用量) コンポジットから ERDDAP™ その他へ ERDDAP お問い合わせ
- ERDDAP™ 2つの特別なデータセットのタイプがあります、 EDDGrid Erddapから そして、 EDDTableFromErddapの特長 , 参照する 他のデータセット ERDDAP お問い合わせ
- コンポジット時 ERDDAP™ これらのデータセット、コンポジットからのデータや画像のリクエストを受け取る ERDDAP™ リダイレクト 他のデータを要求する ERDDAP™ サーバ。 結果は:
- これは非常に有効です (CPU、メモリ、帯域幅) , その他
- コンポジット ERDDAP™ データを他のユーザーに送信する ERDDAP お問い合わせ
- その他 ERDDAP™ データを取得し、それを再フォーマットし、データをコンポジットに送信します ERDDAP お問い合わせ
- コンポジット ERDDAP™ データの受け取り (追加の帯域幅を使用する) 、それを再フォーマットして下さい (余分 CPU 時間および記憶を使用して) データをユーザに送信する (追加の帯域幅を使用する) お問い合わせ データのリクエストをリダイレクトし、他のデータを許可することで ERDDAP™ ユーザーに直接応答を送信するには、コンポジット ERDDAP™ データリクエストのCPU時間、メモリ、または帯域幅を一切使用しません。
- リダイレクトは、クライアントソフトウェアに関係なくユーザーに透明です (ブラウザまたはその他のソフトウェアまたはコマンドラインツール) お問い合わせ
- これは非常に有効です (CPU、メモリ、帯域幅) , その他
グリッド部品
ツイート : : : 高帯域幅を持つすべてのリモートデータソース OPeNDAP リモートサーバに直接接続できます。 リモートサーバが ERDDAP™ 、使用して下さい EDDGrid FromErddap または EDDTableFrom から ERDDAP コンポジットのデータを扱うため ERDDAP お問い合わせ リモートサーバが他のタイプである場合 DAP サーバ、例えば、THREDDS、 Hyrax 、または GrADS の使用 EDDGrid FromDapから。
ツイート : すべて ERDDAP -ableデータソース (データソースから ERDDAP データを読むことができます) 高帯域幅のサーバーを持っている、別の設定 ERDDAP™ このデータソースからデータを扱う責任があるグリッドで。
- こんな場合 ERDDAP s は、データに対する多くの要求を得ることができません。1 つにそれらを統合できます。 ERDDAP お問い合わせ
- もし、 ERDDAP™ 1つのリモートソースからデータを取得することに専念して、あまりにも多くの要求を得ています, 追加を追加するためのテンプテーションがあります ERDDAP s はリモートデータソースにアクセスします。 特別なケースでは、これは理にかなっているかもしれませんが、これはリモートデータソースを圧倒する可能性が高い (これは、自己啓発です) また、他のユーザーがリモートデータソースにアクセスしないようにする (それは素晴らしいではありません) お問い合わせ そのような場合は、別の設定を検討してください ERDDAP™ データセットを1つ提供し、そのデータセットをコピーする ERDDAP ハードドライブ (詳しくはこちら ツイート ) , 多分と EDDGrid コピー および/または EDDTableコピー お問い合わせ
- ツイート サーバは一般にアクセス可能です。
ツイート : すべて ERDDAP - 帯域幅の低いサーバを持つデータソース (または他の理由で遅いサービスである) 別の設定を検討する ERDDAP™ データセットのコピーを格納する ERDDAP 's ハードドライブ, おそらくと EDDGrid コピー および/または EDDTableコピー お問い合わせ こんな場合 ERDDAP s は、データに対する多くの要求を得ることができません。1 つにそれらを統合できます。 ERDDAP お問い合わせ ツイート サーバは一般にアクセス可能です。
コンポジット ERDDAP
ダイバーシティ : : : コンポジット ERDDAP™ 定番です ERDDAP™ それ以外は、単に他のデータを扱う ERDDAP お問い合わせ
- コンポジットのため ERDDAP™ すべてのデータセットに関するメモリに情報があり、データセットのリストのリクエストに迅速に対応できます。 (完全なテキスト検索、カテゴリ検索、すべてのデータセットのリスト) 個々のデータセットのデータアクセスフォーム、グラフフォームの作成、または WMS サイトマップ これらは、メモリ内で保持される情報に基づいて、すべての小さく、動的に生成されたHTMLページです。 そのため、応答は非常に高速です。
- 実際のデータへのリクエストはすぐに他のデータにリダイレクトされるため ERDDAP s、合成 ERDDAP™ CPU時間、メモリ、帯域幅を使わずに、実際のデータへのリクエストに迅速に対応できます。
- できるだけ多くの仕事をシフトすることで (CPU、メモリ、帯域幅) コンポジットから ERDDAP™ その他へ ERDDAP s、合成 ERDDAP™ すべてのデータセットからデータを提供するように見えますが、大量のユーザーからの大量のデータリクエストを引き続き維持できます。
- 予備テストはコンポジットを示しています ERDDAP™ CPU時間の~1ms、1000リクエスト/秒でほとんどのリクエストに対応できます。 そのため、8つのコアプロセッサは、約8000のリクエスト/秒に対応する必要があります。 スローダウンの原因となるより高い活動の破裂を想定することは可能ですが、多くのスループットです。 複合体の前にデータセンターの帯域幅がネックになる可能性が高い ERDDAP™ ボトルネックになります。
最新最大 (タイムタイム) お問い合わせ
ザ・オブ・ザ・ EDDGrid /TableFromErddap のコンポジット ERDDAP™ ソース・データセットがあるとき、各ソース・データセットに関する保存された情報のみを変更します。 「リロード」 メタデータの変更の一部 (例:変数の時刻 actual\_range ) サブスクリプション通知を生成します。 ソースデータセットに頻繁に変更するデータがある場合 (例えば、毎秒新しいデータ) そして使用して下さい 「更新」 基礎データへの頻繁な変化に気づくシステム、 EDDGrid /TableFromErddapは、次のデータセット「リロード」まで、これらの頻繁な変更について通知されません。 EDDGrid /TableFromErddap は最新ではありません。 ソースデータセットを変更することで、この問題を最小限に抑えることができます<reloadEveryNMinutes> より小さい値へ (60? 15?) より多くのサブスクリプション通知があるように、 EDDGrid /TableFromErddap は、ソースデータセットに関する情報を更新します。
または、ソースのデータセットが新しいデータを持っているときにデータ管理システムが知っている場合 (例えば、データファイルをコピーするスクリプトを使って、) 、そしてそれが極度の頻繁でなければ (例:5分ごとに、または頻度が少ない) 、よりよい解決があります:
- 使用しないでください<updateEveryNMillis> ソースデータを最新の状態に保つ
- ソースデータセットの設定<reloadEveryNMinutes> より大きい数へ (1440?) お問い合わせ
- スクリプトがソースのデータセットに問い合わせる フラグ URL 新しいデータファイルをコピーして配置する直後に。 これにより、ソースデータセットが完全に最新になり、サブスクリプション通知を生成し、それに送信されるようになります。 EDDGrid /TableFromErddap データセット。 それは導きます EDDGrid /TableFromErddap のデータセットを完全に更新する (5秒以内に新しいデータを追加) お問い合わせ そして、そのすべてが効率的に行われる (不要なデータセットリロードなし) お問い合わせ
多数の合成物 ERDDAP ツイート
- 非常に極端な場合、または欠陥の許容のために、あなたは1つの複合体以上を設定したいかもしれません ERDDAP お問い合わせ システムの他の部分は、 (同様に、データセンターの帯域幅) コンポジットの前に問題になります ERDDAP™ ボトルネックになります。 ソリューションは、おそらく追加、地理的に多様な、データセンターを設定する (ミラー) 1つの合成物が付いているそれぞれ ERDDAP™ サーバ ERDDAP s と (少なくとも) 需要が高いデータセットのミラーコピー。 このようなセットアップは、障害耐性とデータのバックアップも提供します (コピー) お問い合わせ この場合、コンポジットなら最適です ERDDAP s には異なる URL があります。
本当にすべてのコンポジットを望むなら ERDDAP 同じ URL を持つ s は、指定したユーザをコンポジットの 1 つに割り当てるフロントエンド システムを使用します。 ERDDAP ツイート (IPアドレスに基づく) つまり、すべてのユーザーの要求がコンポジットの1つだけに行くように ERDDAP お問い合わせ 2つの理由があります。
- 根本的なデータセットがリロードされ、メタデータが変更されるとき (例えば、グリッドされたデータセット内の新しいデータファイルが、時刻変数の時刻を引き起こします。 actual\_range 変更する) 、コンポジット ERDDAP sは、同期から少しずつ外されますが、 イベントの一貫性 お問い合わせ 通常は5秒以内に再同期しますが、時間が長くなります。 ユーザーが自動システムを作る場合 ERDDAP™ サブスクリプション アクションをトリガーすると、簡単な同期の問題が重要になります。
- 2+コンポジット ERDDAP それぞれが独自のサブスクリプションのセットを維持 (上記の同期の問題のため) お問い合わせ
そのため、特定のユーザーはコンポジットの1つに向けるべきです。 ERDDAP これらの問題を避けるためにs。 複合体の場合 ERDDAP s がダウンし、フロントエンドシステムはそれをリダイレクトすることができます ERDDAP 'ユーザーを別のユーザーに ERDDAP™ です。 しかし、最初のコンポジットを引き起こす能力問題である場合 ERDDAP™ 失敗する (圧倒的なユーザー? は、 サービスの拒否攻撃 お問い合わせ) これにより、ユーザーは他のコンポジットにリダイレクトする可能性が非常に高い ERDDAP s は、 カスケーディング障害 お問い合わせ したがって、最も堅牢なセットアップはコンポジットを持っていることです ERDDAP s は異なる URL を使用します。
または、多分よりよい、複数の合成物をセットアップして下さい ERDDAP s 負荷分散なし。 この場合、各点をそれぞれ与える点を作る必要があります ERDDAP s は別の名前/アイデンティティおよび可能であれば世界の異なった部分でそれらをセットアップします (例:AWS の異なる領域) 、例えば、 ERD \_US\_イースト、 ERD \_US\_西, ERD \_IE, ERD \_FR, ERD \_IT, ユーザが意識的に, 繰り返し特定の操作をするように ERDDAP お問い合わせ
- \[ 1つのサーバーで実行される高性能システムの魅力的な設計については、これを参照してください Mailinatorの詳細な説明 お問い合わせ \]
非常に高い需要のデータセット
本当に珍しいケースでは、 ツイート , ツイート または ツイート ERDDAP s は、帯域幅やハードドライブの制限が制限されているため、要求に追いつくことはできません。 (お問い合わせ) 別のサーバー+hardに ドライブ+ ERDDAP , 多分と EDDGrid コピー および/または EDDTableコピー お問い合わせ 元のデータセットとコピーされたデータセットが合成の1つのデータセットとしてシームレスに表示されるのは理想的なかもしれませんが ERDDAP™ 2つのデータセットが異なる時の状態になるので、これは困難です (当然のことながら、元が新しいデータを取得した後、コピーしたデータセットがコピーされる前に) お問い合わせ そのため、データセットが若干異なるタイトルを付与されることをお勧めしています。 (例:「... (コピー #1) お問い合わせ (コピー #2) "、または" (ミラー # ログイン ) または " (サーバ # ログイン ) ツイート) コンポジットに別々のデータセットとして表示 ERDDAP お問い合わせ ユーザーの一覧を表示するために使用 ミラーサイト 一般的なファイルのダウンロードサイトでは、驚きや失望するべきではありません。 特定の場所での帯域幅制限が制限されているため、別のサイトにある鏡を持っていることは意味があるかもしれません。 ミラーのコピーが異なるデータセンターにある場合、データセンターのコンポジットだけでアクセス ERDDAP™ 、別のタイトル (例:「ミラー#1」) 必須ではありません。
RAIDs 対定期的なハードドライブ
大量のデータセットやデータセットのグループが使用されていない場合は、障害の許容範囲を提供し、別のサーバーの処理能力や帯域幅を必要としないため、RAIDにデータを保存する感覚を作ることができます。 しかし、データセットが重く使用されている場合、別のサーバーにデータをコピーする方が意味があるかもしれません+ ERDDAP™ + ハードドライブ (と同様 Googleが何をしているのか ) 1つのサーバーと RAID を使用して、複数のデータセットを保存します。 ERDDAP それらが失敗するまでグリッド内のs。
失敗
もし...
- 1つのデータセットの要求の破烈があります (例えば、クラス内のすべての生徒が同じデータを同時にリクエストする) お問い合わせ あなただけの ERDDAP™ データセットが圧倒的に遅くなり、リクエストを拒否するようになります。 コンポジット ERDDAP™ その他 ERDDAP s は影響しません。 システム内の特定のデータセットの制限要因は、データとのハードドライブであるため (コメントはありません ERDDAP ) 、唯一の解決 (即時ではありません) 別のサーバー+hardDrive+でデータセットのコピーを作ることです ERDDAP お問い合わせ
- ログイン ツイート , ツイート または ツイート ERDDAP™ 失敗 (例えば、ハードドライブの故障) お問い合わせ データセットのみ (ツイート) によって提供される ERDDAP™ 影響を受ける。 データセットの場合 (ツイート) 別のサーバー+hardDrive+でミラーリングされます ERDDAP 効果は最小限です。 問題がレベル5または6 RAIDでハードドライブの故障の場合、ドライブを交換し、RAIDがドライブにデータを再構築するだけです。
- コンポジット ERDDAP™ 失敗? 非常にシステムを作りたいと思うなら 高可用性 、セットアップできます 多岐コンポジット ERDDAP ツイート (上記の議論として) 、のような何かを使用して下さい ガンインックス または ログイン 負荷分散を処理するため。 特定のコンポジットに注意してください。 ERDDAP™ 多数のユーザーからのリクエストを扱います。 メタデータの要求は小さく、メモリ内の情報によって処理され、 データのリクエスト (大きいかもしれない) 子にリダイレクトされる ERDDAP お問い合わせ
シンプルでスケーラブル
このシステムは、任意の部分が過給されると簡単にセットアップと管理が容易です。 特定のデータセンターの唯一の本当の制限は、データセンターの帯域幅とシステムコストです。
バンド幅
システムの一般的なコンポーネントの約帯域幅に注意:
| コンポーネント | 近接帯域幅 (GBytes/sの) | | お問い合わせ | お問い合わせ | | DDRメモリ | 2.5マイル | | SSDドライブ | 1 | | SATAハードドライブ | 0.3 トン | | ギガビットのイーサネット | ツイート | | OC-12の特長 | 0.06の | | OC-3の特長 | 0.015の | | ツイート | 0.0002の |
なので、1つのSATAハードドライブ (0.3GB/sの) 1つのサーバーに1つずつ ERDDAP™ ギガビットのイーサネットLANを飽和させることができる (0.1GB/秒) お問い合わせ 1つのギガビットのイーサネットLAN (0.1GB/秒) おそらくOC-12インターネット接続を飽和させることができます (0.06GB/s) お問い合わせ 少なくとも 1 つのソースリスト OC-12 行は、約コスト $100,000 月. (はい、これらの計算は、システムを制限に押し込むことに基づいており、それは非常に厳しい応答につながるので良いではありません。 しかし、これらの計算は、システムの部品をバランス良くするための計画と役立ちます。) 明らかに、データセンターの適切な高速インターネット接続は、システムの最も高価な部分までです。 数十台のサーバーで簡単に、比較的安価にグリッドを構築できます。 ERDDAP 大量のデータを素早く汲み出すことができるが、適切なインターネット接続は非常に高価です。 部分的なソリューションは次のとおりです。
- 必要なデータがすべてであれば、クライアントがデータのサブセットを要求するように奨励します。 クライアントが小さな領域や低解像度のデータのみを必要とする場合、それは彼らが要求すべきことです。 サブセットはプロトコルの中央焦点です ERDDAP™ リクエストデータのサポート
- 圧縮されたデータを送信する奨励。 ERDDAP™ 圧縮 「アクセプトエンコーディング」が見つからればデータ伝送 HTTP GET リクエストヘッダー。 すべてのWebブラウザは「アクセプトエンコーディング」を使用し、応答を自動的に解凍します。 その他のお客様 (例:コンピュータプログラム) 明示的に使用する必要があります。
- サーバをISPまたは他のサイトに配置し、比較的高価な帯域幅コストを削減します。
- サーバを分散させる ERDDAP 費用が分散されるように、異なる機関へのs。 あなたのコンポジットをリンクすることができます ERDDAP™ 彼らの ERDDAP お問い合わせ
注意: クラウドコンピューティング ウェブホスティングサービスは、必要なすべてのインターネット帯域幅を提供しますが、価格の問題は解決しません。
拡張性、高容量、障害耐性システムの設計に関する一般的な情報については、Michael T. Nygardの書籍を参照してください。 リリース お問い合わせ
レゴスのような
ソフトウェア デザイナーはよくよくよい使用しようとします ソフトウェア設計パターン 問題を解決するため。 よいパターンはよい特性が付いているシステムに導く、作成し、働くこと容易よい、汎用性解決をカプセル化するのでよいです。 パターン名が標準化されていないので、パターンを呼び出します。 ERDDAP™ Lego パターンを使用します。 各レゴ (それぞれ ERDDAP ) 簡単で、小さい、標準、スタンドアローン、レンガです (データサーバ) 定義されたインターフェイスで、他のレゴスにリンクすることができます ( ERDDAP ツイート) お問い合わせ パーツの ERDDAP™ このシステムを構成するのは、サブスクリプションとフラグ URL システムです。 (間のコミュニケーションを可能にする ERDDAP ツイート) , 追加... FromErddapリダイレクトシステムとシステム RESTful ユーザーが生成できるデータ等のリクエスト ERDDAP お問い合わせ したがって、2つ以上のレポスを与えられた ( ERDDAP ツイート) 、多数の異なった形の作成できます (ネットワークのトポロジー ERDDAP ツイート) お問い合わせ 確かに、設計および特徴の ERDDAP™ Lego のようなものではなく、特定のトポロジーを有効化し、最適化するために異なる方法で実行できます。 しかし、私たちは、 ERDDAP 's Lego-like デザインは、どんなものでも使える、汎用性の高いソリューションを提供しています ERDDAP™ 管理者権限 (または管理者のグループ) あらゆる種類の異なるフェデレーショントポロジーを作成する。 例えば、単一の組織は3つを設定できる (以上) ERDDAP s に示すように ERDDAP™ 上記グリッド/クラスター図 お問い合わせ または分散グループ (IOOSとは? コーストウォッチ? NCEIとは? NWSとは? NOAA お問い合わせ アメリカ? データワン? ネオン? フリガナ お問い合わせ BODCとは? ONCとは? JRC? WMOとは?) 1 つを置くことができます ERDDAP™ それぞれの小さなアウトポスト (従ってデータは源に近くとどまることができます) コンポジットの設定 ERDDAP™ 仮想データセットを備えた中央オフィス (常に最新である) それぞれの小さなアウトポストから ERDDAP お問い合わせ 確かに、すべてが ERDDAP sは、世界中のさまざまな機関に設置され、他の機関からデータを収集します。 ERDDAP s および/または他のデータを提供して下さい ERDDAP s、巨大なネットワークを形成する ERDDAP お問い合わせ いかがですか? ということで、ルゴの持つ可能性は無限です。 だからこそ良いパターンです。 だからこそ、これは良いデザインです ERDDAP お問い合わせ
異なる種類のリクエスト
データサーバのトポロジーのこの議論の現実的な合併症の1つは、さまざまな種類の要求と異なる種類のリクエストを最適化するためのさまざまな方法があることです。 これは主に別々の問題です (どのように高速は、 ERDDAP™ データのリクエストに対して、データが応答しますか?) トポロジーのディスカッションから (データサーバーとサーバーが実際のデータを持つ関係を扱います) お問い合わせ ERDDAP™ , もちろん, 効率的にすべてのタイプのリクエストに対処するしようとします, しかし、他の人よりもいくつかのより良い処理.
- 多くのリクエストは簡単です。 例えば: このデータセットのメタデータとは? または:この格子されたデータセットのための時間次元の価値は何ですか。 ERDDAP™ 可能な限り迅速に対応するように設計されている(通常は<=2 ms) この情報を記憶に保つことによって。
- 一部のリクエストは適度に困難です。 例えば: データセットのこのサブセット (1つのデータファイル) お問い合わせ 難しくないため、比較的迅速に対応できます。
- 一部のリクエストは難しく、時間がかかります。 例えば: データセットのこのサブセット (1万以上のデータファイルであっても、圧縮されたデータファイルから10秒単位で解凍する場合があります。) お問い合わせ ERDDAP™ v2.0は、要求ハンドリングスレッドが異なるサブセットに取り組む複数のワーカースレッドをスポーンできるようにすることで、これらの要求に対処するための新しい、より高速な方法を導入しました。 しかし、この問題に対する別のアプローチがあります。 ERDDAP™ まだサポートしていません: 特定のデータセットのデータファイルのサブセットは、別のコンピュータに保存して分析することができ、元のサーバーに組み込まれた結果。 このアプローチは、 サイトマップ によって実行され、 ハドープ , 最初の (お問い合わせ) オープンソースのMapReduceプログラムで、Googleの紙のアイデアに基づいていました。 (MapReduceが必要な場合 ERDDAP メールでのお問い合わせ erd.data at noaa.gov お問い合わせ) Googleの ビッグクエリ MapReduceの実装がタブラーデータセットのサブセットに適用されるのではないかと思われるので、それは興味深いです ERDDAP 主な目標 あなたが作ることができる可能性があります ERDDAP™ BigQuery データセットからのデータセット EDDTableFromデータベース BigQuery は JDBC インターフェイス経由でアクセスできるためです。
これらは私の意見です。
はい、計算はシンプルです (そして今は少し日付を置いて下さい) ですが、結論が正しいと思います。 障害のあるロジックを使用していたり、自分の計算で間違いを犯したりしましたか? そうなら、欠陥は一人で鉱山です。 メールでのお問い合わせ erd dot data at noaa dot gov お問い合わせ
クラウドコンピューティング
クラウドコンピューティングサービス (例: Amazon Webサービス そして、 Googleクラウドプラットフォーム ) お問い合わせ ウェブホスティング会社 クラウドサービスは、1990年代半ばからシンプルなサービスを提供してきましたが、クラウドサービスは、システムの柔軟性と提供サービスの範囲を大幅に拡大しました。 以来、 ERDDAP™ グリッドだけで構成 ERDDAP s と以来 ERDDAP s は Java Tomcatで実行できるWebアプリケーション (最も一般的なアプリケーションサーバ) またはその他のアプリケーションサーバーは、セットアップが比較的簡単です。 ERDDAP™ クラウドサービスやWebホスティングサイトのグリッド。 これらのサービスの利点は次のとおりです。
- 非常に高い帯域幅のインターネット接続へのアクセスを提供します。 本サービスを利用するだけでは正当化できます。
- ご利用いただいたサービスのみの料金となります。 例えば、非常に高い帯域幅のインターネット接続にアクセスできますが、実際のデータのみが転送されます。 ひどく圧倒されるシステムを構築できる (ピーク需要でも) , ほとんど使用されていない容量を支払う必要はありません。.
- 彼らは簡単に拡張可能です。 サーバタイプを変更したり、複数のサーバーやストレージを1分未満で変更したりすることができます。 本サービスを利用するだけでは正当化できます。
- サーバやネットワークを実行している管理業務の多くからあなたを解放します。 本サービスを利用するだけでは正当化できます。
これらのサービスの欠点は次のとおりです。
- 彼らは彼らのサービスのために、時にはたくさん請求します (絶対的な言葉で; それは良い値ではないことではありません) お問い合わせ ここに記載されている価格は、 アマゾンEC2 お問い合わせ これらの価格 (2015年6月現在) 降ります。
過去には価格が高かったが、データファイルやリクエスト数が小さくなっていた。
将来的には価格が下がりますが、データファイルとリクエストの件数が大きくなります。
そのため、詳細が変化しますが、状況は比較的一定にとどまります。
また、サービスが高価であるというわけではなく、多くのサービスを利用し購入しているということです。
- データ転送 — システムへのデータ転送が無料になりました (ユア!) お問い合わせ システムからのデータ転送は $0.09/GB です。 1つのSATAのハードドライブ (0.3GB/sの) 1つのサーバーに1つずつ ERDDAP™ ギガビットのイーサネットLANを飽和させることができる (0.1GB/秒) お問い合わせ 1つのギガビットのイーサネットLAN (0.1GB/秒) おそらくOC-12インターネット接続を飽和させることができます (0.06GB/s) お問い合わせ 1 OC-12 接続が ~150,000 GB/月を送信できる場合、データ転送コストは 150,000 GB @ $0.09/GB = $13,500/月 かなりのコストです。 あなたがダースハードワークを持っている場合は、明確に、 ERDDAP クラウドサービスでは、月間データ転送手数料が相当 (最大$ 162,000 /月) お問い合わせ (繰り返しますが、サービスが過価であるというわけではなく、多くのサービスを利用し購入しているということです。)
- データストレージ — Amazon は TB ごとに $50/月 課金されます。 (RAID がそれを置くと、管理コストが合計コストに追加するが、 ~$50/TB の 4TB 企業ドライブを購入することと比較してください。) クラウドに大量のデータを保存する必要がある場合は、かなり高価かもしれません (例:100TBは$5000/月を要します) お問い合わせ しかし、本当に大量のデータがなければ、これは帯域幅/データ転送コストよりも小さい問題です。 (繰り返しますが、サービスが過価であるというわけではなく、多くのサービスを利用し購入しているということです。)
サブセット
- サブセットの問題: データファイルからデータを効率的に配信する唯一の方法は、データを配信するプログラムを持っていることです (例: ERDDAP ) ローカルハードドライブに保存されたデータを持つサーバー上で実行 (または同様に、SANまたはローカルRAIDへの高速アクセス) お問い合わせ ローカルファイルシステムにより、 ERDDAP™ (netcdf-java などのライブラリ) 特定の バイト へのリクエストは、ファイルから出力され、応答を素早く取得できます。 多くの種類のデータリクエスト ERDDAP™ ファイルへ (固定値が > であるデータの要求をグリッド化 1) プログラムが非ローカルからファイルのファイル全体または大きなチャンクを要求する必要がある場合は、効率的に行うことはできません (より遅い) データストレージシステムでサブセットを抽出します。 クラウドの設定がない場合 ERDDAP™ ファイルのバイト範囲への高速アクセス (ローカルファイルと同じくらい高速) , ERDDAP データへのアクセスは、深刻なボトルネックであり、クラウドサービスを利用する他の利点を無視します。
ホストされたデータ
上記の費用対効果分析の代替 (データ所有者に基づくもの (例: NOAA ) クラウドに保存されるデータの支払い) Amazonで2012年頃到着 (ほかのクラウドプロバイダーも少ない) クラウドでデータセットをホスティング開始 (AWS S3の特長) 無料で (ユーザがAWS EC2の計算インスタンスをレンタルし、そのデータを扱う場合、コストを回復できるという希望を想定して) お問い合わせ 明らかに、これによりクラウドコンピューティングが大幅に費用対効果が高まります。なぜなら、データアップロードとホスティングのコストがゼロになるからです。 と ERDDAP™ v2.0, 実行を容易にするための新機能があります。 ERDDAP クラウドで:
- 今、 EDDGrid FromFiles または EDDTableFromFiles データセットは、インターネット経由でリモートでアクセスできるデータファイルから作成できます。 (例:AWS S3 バケット) 利用することで<cacheFromUrl> と<キャッシュサイズ GB>オプション。 ERDDAP™ 最近使用したデータファイルのローカルキャッシュを保持します。
- これで、EDDTableFromFiles ソースファイルが圧縮されている場合 (例: .tgz ) , ERDDAP™ 読み込み時に自動的に解凍します。
- 今、 ERDDAP™ 与えられた要求に応答するスレッドは、使用する場合の要求のサブセクションで動作するように作業者のスレッドをスポーンします<nThreads>オプション。 この並列化は、難易度の高い要求に対してより迅速に対応できるようにします。
これらの変更は、ローカル、ブロックレベルのファイルストレージ、およびAWS S3の問題を解決しません。 (古い投稿) 重要な遅延を持つS3データへのアクセスの問題。 (昨日 (~2014年~) , そのラグは重要だった, しかし、今、はるかに短く、それほど重要ではありません.) すべてで、それは設定することを意味します ERDDAP™ クラウドでは、今よりもはるかに優れています。
お問い合わせ — マタイ・アリロットと彼のグループのおかげで、元のOOIの努力は、パッティングに取り組む ERDDAP™ クラウドとその結果のディスカッション。
データセットのリモートレプリケーション
グリッドとフェデレーションの上記の議論に関連する一般的な問題があります ERDDAP s: データセットのリモートレプリケーション。 基本的な問題は次のとおりです。データプロバイダは、時折変化するデータセットを維持し、このデータセットの最新のローカルコピーを維持したいです。 (様々な理由で) お問い合わせ 明らかに、このバリエーションの膨大な数があります。 いくつかのバリエーションは、他のものよりも扱いにくいです。
- 高速アップデート ローカルデータセットを最新の状態に保つことは困難です すぐに (例 3秒以内) ソースへの変更後、例えば、数時間以内に。
- 頻繁な変更 頻繁な変更は、不頻繁な変更よりもに対処するのは困難です。 たとえば、0.1秒ごとに変更を扱いやすくなります。
- 小さな変化 ソースファイルへの小さな変更は、まったく新しいファイルよりも扱いにくいです。 小さな変更がファイル内の場所にある場合、これは特に当てはまります。 小さな変更は、複製する必要があるデータを識別し、発行しにくいです。 新しいファイルは、転送するために検出し、効率的です。
- データセット データセットを最新の状態に保つことは、単なる最近のデータを維持するよりも困難です。 一部のユーザーは、最近のデータを必要とする (例えば、最後の 8 日の価値) お問い合わせ
- 複数のコピ 異なるサイトの複数のリモートコピーを維持することは、1つのリモートコピーを維持するよりも困難です。 これはスケーリングの問題です。
ソースデータセットとユーザーのニーズや期待に、可能なタイプの変更の膨大な数のバリエーションがあります。 バリエーションの多くは解決するのが非常に困難です。 1つの状況に最適なソリューションは、多くの場合、他の状況に最適なソリューションではありません。まだ普遍的な素晴らしいソリューションはありません。
関連する ERDDAP™ ツール
ERDDAP™ データセットのリモートコピーを維持しようとするシステムの一部として使用できるツールを提供しています。
- ERDDAP お問い合わせ RSS (豊富なサイトの概要?) サービス
リモートでデータセットかどうかを確認する簡単な方法 ERDDAP™ 変更しました。 - ERDDAP お問い合わせ サブスクリプションサービス
より効率的な (以上 RSS ) アプローチ: データセットが更新され、更新が変更されたとき、電子メールまたは各購読者にURLをすぐに送信するか、または更新が結果的に通知します。 それは、それがASAPと無駄な努力がないことで効率的です (ポーリングとして RSS サービス) お問い合わせ ユーザーは他のツールを使うことができます (お問い合わせ IFTTTについて ) サブスクリプションシステムからメール通知に反応します。 たとえば、リモートでデータセットを購読できます。 ERDDAP™ IFTTT を使用してサブスクリプションメール通知に反応し、ローカルデータセットを更新します。 - ERDDAP お問い合わせ フラグシステム
方法を提供する ERDDAP™ 管理者は、彼/彼女にデータセットを伝えます ERDDAP ASAPをリロードする。 フラグの URL フォームはスクリプトで簡単に使用できます。 フラグの URL フォームは、サブスクリプションのアクションとして使用できます。 - ERDDAP お問い合わせ "files" システム
指定したデータセットのソースファイルへ、Apache-style ディレクトリリストを含むファイル (「Webアクセス可能なフォルダ」) 各ファイルのダウンロードURL、最終変更時間、サイズがそれぞれあります。 使い方の片側 "files" システムとは、ソースファイルがデータセットよりも異なる変数名と異なるメタデータを持つ可能性があることです。 ERDDAP お問い合わせ リモートの場合 ERDDAP™ データセットは、そのソースファイルへのアクセスを提供しています, これは、非人のバージョンのrsyncの可能性を開きます: それは、リモートファイルが変更され、ダウンロードする必要があることを確認するために、ローカルシステムのために簡単になります. (詳細はこちら cacheFromUrl オプション 以下は、この使用をすることができます。)
ソリューション
問題と無限数の解決策に多大なバリエーションがありますが、解決策への基本的なアプローチはわずかに役立ちます。
カスタム、ブルートフォースソリューション
明らかな解決策は、特定の状況のために最適化されているカスタムソリューションを手作りすることです。データが変更されたことを検知/識別し、ユーザーが変更されたデータを要求できるように、その情報をユーザーに送信するシステムを作ります。 まあ、これを行うことができますが、欠点があります。
- カスタムソリューションは多くの仕事です。
- カスタムソリューションは通常、特定のデータセットにカスタマイズされ、ユーザーが簡単に再利用できないシステムを提供します。
- カスタムソリューションは、あなたによって構築され、維持する必要があります。 (それは決して良い考えではありません。 仕事を回避し、仕事を行うために他の人を得るのは、常に良い考えです!)
私はこのアプローチを取ることは、他の誰かによって構築され、維持されている一般的なソリューションを見ることはほとんど常に良いので、異なる状況で簡単に再利用することができます。
ログイン
ログイン 既存の、驚くほど良い、一般的な目的のソリューションで、ユーザーのリモートコンピュータ上で同期してソースコンピュータにファイルを収集します。 それが動作する方法は次のとおりです。
- イベント (例) ERDDAP™ サブスクリプションシステムイベント) rsync を実行しているトリガー, (または、 cron ジョブは、ユーザのコンピューターで日常的に rsync を実行します。)
- ソースコンピュータ上でrsyncに連絡する
- 各ファイルのチャンク用の一連のハッシュを計算し、それらのハッシュをユーザのrsyncに送信します。
- ユーザーのファイルのコピーに類似した情報を比較する。
- その後、変更したファイルのチャンクを要求します。
つまり、rsync は素早く動作します。 (例:10秒+データ転送時間) そして非常に効率的に。 あります rsyncのバリエーション 異なる状況を最適化する (例えば、各ソースファイルのチャンクのハッシュをあらかじめ計算してキャッシュすることで) お問い合わせ
rsyncの主な弱点は次のとおりです。 セットアップにいくつかの努力が必要です (セキュリティの問題) ; いくつかのスケーリングの問題があります。NRT データセットを本当に最新の状態に保つことは良いではありません (例えば、rsyncを5分以内に使うのは、) お問い合わせ 弱点に対処することができる、またはあなたの状況に影響を与えない場合、rsyncは、誰もがデータセットのリモートレプリケーションを伴う多くのシナリオを解決するために今使用できる優れた汎用ソリューションです。
アイテムは、 ERDDAP™ rsyncサービスのサポートを追加しようとするリストを作成する ERDDAP (おそらくかなり難しい仕事) rsync を使用できるクライアント (または variant) データセットの最新のコピーを維持する。 誰がこれで仕事をしたいのなら、メール erd.data at noaa.gov お問い合わせ
rsyncが何をしているか、データセットのレプリケーションに向いているプログラムがいくつかあります。 (多くの場合、ファイルコピーレベルで) 、例えば、 Unidata お問い合わせ ダイヤルイン お問い合わせ
ウルからキャッシュ
キャッシュFromUrl 設定可能 (まずは ERDDAP™ バージョン2.0) すべてについて ERDDAP 'ファイルからデータセットを作成するデータセット型 (基本的には、すべてのサブクラス EDDGrid ファイルから そして、 EDDTableFromFiles (EDDTableFromFiles) は、 ) お問い合わせ キャッシュ FromUrl は、キャッシュを介してリモートソースからそれらをコピーすることにより、自動的にローカルデータファイルをダウンロードして維持しようとします FromUrlの設定。 リモートファイルは、WebアクセシブルフォルダまたはTHREDDSが提供するディレクトリのようなファイルリストにすることができます。 Hyrax 、S3 バケツ、または ERDDAP お問い合わせ "files" システム。
リモートファイルのソースがリモートの場合 ERDDAP™ ソースファイルを提供するデータセット ERDDAP™ "files" システム、それからできます サインアップ リモートデータセットに、そして使用して下さい フラグ URL ローカルデータセットをサブスクリプションのアクションとして使用します。 リモートデータセットが変更されると、データセットのフラグ URL に連絡し、変更されたリモートデータファイルを検出してダウンロードする ASAP を再ロードするように指示します。 このすべてが非常に迅速に起こる (通常〜5秒+変更されたファイルをダウンロードするために必要な時間) お問い合わせ このアプローチは、ソースのデータセットの変更が定期的に追加され、既存のファイルが変更されていない場合に有効です。 すべてのデータが頻繁に追加されると、このアプローチはうまく機能しません (またはほとんど) 既存のソースデータファイルでは、ローカルデータセットが頻繁にリモートデータセット全体をダウンロードしているためです。 (rsync のようなアプローチが必要なところです。)
アーカイブAデータセット
ERDDAP™ お問い合わせ アーカイブAデータセット データが頻繁にデータセットに追加されると良いソリューションですが、古いデータは変更されません。 基本的には、 ERDDAP™ 管理者はアーカイブADatasetを実行できます (おそらくスクリプトで、おそらくcronによって実行) 抽出したいデータセットのサブセットを指定します (おそらく複数のファイルで) パッケージ .zip または .tgz ファイル、興味ある人やグループにファイルを送信できるように (例:NCEIのアーカイブ) またはダウンロードのために利用できるようにして下さい。 たとえば、毎日12:10にアーカイブADatasetを実行して、それを作ることができます。 .zip 昨日の12時からの最終日は12:00までです。 (または、必要に応じて、今週、月、または年単位で行います。) オフラインでパッケージされたファイルが生成されるため、標準の場合と同様に、タイムアウトやデータが多すぎるという危険はありません。 ERDDAP™ リクエスト
ERDDAP™ '標準要求システム
ERDDAP™ '標準リクエストシステムは、データが頻繁にデータセットに追加される場合の代替良いソリューションですが、古いデータは変更されません。 基本的には、特定の期間のデータを取得するために、標準のリクエストを使用することができます。 たとえば、毎日12:10で、あなたは12時00分から以前の日の12:00からのリモートデータセットからすべてのデータをリクエストすることができます。 制限事項 (アーカイブADatasetアプローチと比較して) タイムアウトの危険性や、1つのファイルに対してあまりにも多くのデータが存在します。 より短い期間の要求を頻繁に要求することによって制限を回避できます。
EDDTableFromHttpGetの特長
\[ このオプションはまだ存在しませんが、近い将来にビルドできるようです。 \]
新着情報 EDDTableFromHttpGetの特長 データセットのタイプ ERDDAP™ v2.0 では、別のソリューションを実装することができます。 このタイプのデータセットによって維持される基礎ファイルは、基本的にデータセットの変更を記録するファイルです。 定期的にローカルデータセットを維持するシステムの構築が可能 (またはトリガーに基づく) 最後のリクエスト以来、リモートデータセットに行われたすべての変更のリクエスト。 効率的である (以上) rsync よりも、多くの困難なシナリオを処理するが、リモートとローカルのデータセットが EDDTableFromHttpGet のデータセットの場合のみ動作します。
誰がこの上で仕事をしたいか、連絡してください erd.data at noaa.gov お問い合わせ
分散データ
上記の解決策のどれも、問題のハードな変化を解決する素晴らしい仕事をしています。 (NRTの) すべての可能なシナリオのために、データセットは非常に困難です。
素晴らしい解決策があります:データを複製しようとしないでください。 代わりに、1つのauthoritativeソースを使用します (1つのデータセット ERDDAP ) 、データ提供者によって維持される (地域事務所等) お問い合わせ そのデータセットからデータを望むすべてのユーザーは、常にソースから取得します。 たとえば、ブラウザベースのアプリは URL ベースのリクエストからデータを取得するので、リクエストはリモートサーバ上の元のソースにない (ESM をホスティングしているサーバーは同じではありません) お問い合わせ 多くの人がこの分散型データアプローチを長い間提唱してきた (例:20年以上続くロイ・メンデルスゾーン) お問い合わせ ERDDAP 's グリッド/フェデレーションモデル (この文書の最上位80%) このアプローチに基づいています。 このソリューションはゴーディアン・ノットに剣のようなものです。
- このソリューションは驚くほど簡単です。
- このソリューションは、複製されたデータセットを維持するために作業が行われるので、驚くほど効率的です (ツイート) 最新情報
- ユーザーはいつでも最新のデータを取得できます (例えば, 唯一のレイテンシーで〜0.5秒) お問い合わせ
- それはかなりよくスケールアップし、スケーリングを改善する方法があります。 (本ドキュメントの最上位80%の議論をご覧ください。)
いいえ、これはすべての可能な状況のためのソリューションではありませんが、大半のための素晴らしいソリューションです。 特定の状況でこのソリューションに問題/弱点がある場合は、このソリューションの素晴らしい利点のために、これらの問題を解決したり、それらの弱点で生活するために働くことがしばしば価値があります。 このソリューションが与えられた状況に本当に受け入れられない場合、たとえば、データをローカルコピーする必要がある場合は、上記の他のソリューションを検討してください。
コンテンツ
すべてのシナリオのすべての問題を完全に解決する単一の、簡単なソリューションはありませんが (rsyncと分散型データとしてほとんどは) 、できればあなたの特定の状態のための受諾可能な解決を見つけることができるように十分な用具および選択があります。