Skalering
ERDDAP™ - Heavy Loads, Grids, Clusters, Federations og Cloud Computing
ERDDAP :
ERDDAP™ er en web-applikation og en webtjeneste, der samler videnskabelige data fra forskellige lokale og fjerntliggende kilder og tilbyder en enkel, konsekvent måde at downloade subsets af dataene i almindelige filformater og lave grafer og kort. Denne side diskuterer problemer relateret til tung ERDDAP™ Brug belastninger og udforsker muligheder for at håndtere ekstremt tunge belastninger via gitter, klynger, føderationer og cloud computing.
Den oprindelige version blev skrevet i juni 2009. Der er ikke sket væsentlige ændringer. Dette blev sidst opdateret 2019-04-15.
I nærheden af DISCLAIMER
Indholdet af denne hjemmeside er Bob Simons personlige meninger og afspejler ikke nødvendigvis nogen holdning til regeringen eller National Oceanic and Atmospheric Administration . Beregningerne er forenklet, men jeg tror, at konklusionerne er korrekte. Har jeg brug for fejlagtig logik eller lave en fejl i mine beregninger? Hvis det er tilfældet, er fejlen min alene. Send en e-mail med korrektionen til erd dot data at noaa dot gov .
Heavy Loads / Kontrainer
Med tung brug, en enkeltstående ERDDAP™ vil blive optaget (fra de fleste til mindst sandsynligt) af:
Fjern Source Bandbredde
- En fjern datakildes båndbredde — Selv med en effektiv forbindelse (f.eks. via OPeNDAP ) , medmindre en fjern datakilde har en meget høj båndbredde internetforbindelse, ERDDAP 's reaktioner vil blive optaget af, hvor hurtigt ERDDAP™ kan få data fra datakilden. En løsning er at kopiere datasættet til ERDDAP 's harddisk, måske med EDDGrid Kopiere Kopier eller eller eller EDDTableCopy .
ERDDAP 's Server Bandbredde
- Medmindre andet er mindre ERDDAP 's server har en meget høj båndbredde internetforbindelse, ERDDAP 's reaktioner vil blive optaget af, hvor hurtigt ERDDAP™ kan få data fra datakilderne og hvor hurtigt ERDDAP™ kan returnere data til kunderne. Den eneste løsning er at få en hurtigere internetforbindelse.
Hukommelseshukommelse
- Hvis der er mange samtidige anmodninger, ERDDAP™ kan køre ud af hukommelse og midlertidigt afvise nye anmodninger. ( ERDDAP™ har et par mekanismer til at undgå dette og for at minimere konsekvenserne, hvis det sker.) Så den mere hukommelse i serveren jo bedre. På en 32-bit server, 4+ GB er virkelig god, 2 GB er okay, mindre anbefales ikke. På en 64-bit server kan du næsten helt undgå problemet ved at få masser af hukommelse. Se billederne \-Xmx og -Xms indstillinger for for for ERDDAP /Tomcat. An An An An An ERDDAP™ At få tung brug på en computer med en 64-bit-server med 8 GB hukommelse og -Xmx sæt til 4000M er sjældent, hvis nogensinde, konuddannet af hukommelse.
Had Drive Bandbredde
- Adgang af data gemt på serverens harddisk er meget hurtigere end at få adgang til fjerndata. Selv så, hvis det ERDDAP™ serveren har en meget høj båndbredde internetforbindelse, det er muligt, at adgangsdata på harddisken vil være en flaskehals. En delvis løsning er at bruge hurtigere (f.eks. 10.000 RPM) magnetiske harddiske eller SSD-drev (hvis det giver mening omkostnings-wise) . En anden løsning er at gemme forskellige datasæt på forskellige drev, så den kumulative harddisk båndbredde er meget højere.
For mange filer cached
- For mange filer i en cache cache cache cache mappe — ERDDAP™ cacher alle billeder, men cacher kun dataene for visse typer af data anmodninger. Det er muligt for cachemappen for et datasæt at have et stort antal filer midlertidigt. Dette vil sænke anmodninger for at se, om en fil er i cachen (virkelig!) .<cache cache cache cache Referater; opsætning.xml lader dig indstille, hvor lang en fil kan være i cachen, før den slettes. Indstilling af et mindre nummer ville minimere dette problem.
CPU CPU CPU CPU
- Kun to ting tage en masse CPU tid:
- NetCDF 4 og 4 HDF 5 understøtter nu intern komprimering af data. Dekomprimering af en stor komprimeret NetCDF 4 / 4 HDF 5 datafil kan tage 10 eller flere sekunder. (Det er ikke en implementeringsfejl. Det er karakteren af kompression.) Så flere samtidige anmodninger om datasæt med data gemt i komprimerede filer kan sætte en alvorlig belastning på enhver server. Hvis dette er et problem, er løsningen at gemme populære datasæt i ukomprimerede filer, eller få en server med en CPU med flere kerner.
- At lave diagrammer (herunder kort) : groft 0,2 - 1 sekund per graf. Så hvis der var mange samtidig unikke anmodninger om grafer ( WMS klienter laver ofte 6 samtidige anmodninger!) , der kunne være en CPU-begrænsning. Når flere brugere kører WMS klienter, det bliver et problem.
Flere Identical ERDDAP s med Load Balancing?
Spørgsmålet kommer ofte op: "For at håndtere tunge belastninger, kan jeg opsætte flere identiske ERDDAP s med belastning balance? Det er et interessant spørgsmål, fordi det hurtigt bliver til kernen af ERDDAP 's design. Det hurtige svar er "no". Jeg ved, at det er et skuffende svar, men der er et par direkte grunde og nogle større grundlæggende grunde til, at jeg designede ERDDAP™ at bruge en anden tilgang (en føderation af ERDDAP s, beskrevet i mængden af dette dokument) , som jeg tror er en bedre løsning.
Nogle direkte grunde til, at du ikke kan oprette flere identiske ERDDAP s er:
- En given ERDDAP™ Læser hver datafil, når den først bliver tilgængelig for at finde dataområdet i filen. Det gemmer derefter disse oplysninger i en indeksfil. Senere, når en bruger anmoder om data kommer i, ERDDAP™ Brug dette indeks til at finde ud af, hvilke filer der skal se i de ønskede data. Hvis der var flere identiske ERDDAP s, de ville hver gøre dette indeksering, som er spildt indsats. Med det fedeste system beskrevet nedenfor, er indekseringen kun udført én gang, af en af de ERDDAP s.
- For nogle typer af brugeranmodninger (f.eks. for .nc , .png, .pdf filer) ERDDAP™ skal gøre hele filen, før svaret kan sendes. Så ERDDAP™ cacher disse filer til en kort tid. Hvis en identisk anmodning kommer i (som det ofte gør, især for billeder, hvor URL er integreret i en webside) , ERDDAP™ kan genbruge den cached-fil. I et system af flere identisk ERDDAP s, disse cached filer er ikke delt, så hver ERDDAP™ ville nålely og genløst genskabe den .nc , .png eller .pdf filer. Med det fedeste system beskrevet nedenfor, er filerne kun lavet én gang, af en af de ERDDAP s og genbrugt.
- ERDDAP 's abonnementssystem er ikke konfigureret til at blive delt af flere ERDDAP s. Hvis belastningsbalanceren f.eks. sender en bruger til én ERDDAP™ og brugeren abonnerer på et datasæt, derefter den anden ERDDAP s vil ikke være opmærksom på dette abonnement. Senere, hvis belastningsbalanceren sender brugeren til en anden ERDDAP™ og beder om en liste over sine abonnementer, den anden ERDDAP™ vil sige der er ingen (førende ham/hen for at foretage et duplikeret abonnement på den anden ERED DAP ) . Med det fedeste system beskrevet nedenfor, er abonnementssystemet simpelthen håndteret af den vigtigste, offentlige, komposit ERDDAP .
Ja, for hver af disse problemer, jeg kunne (med stor indsats) Motorer en løsning (at dele oplysningerne mellem ERDDAP s s s) , men jeg tror på Produktions-of- ERDDAP s tilgang (beskrevet i hovedparten af dette dokument) er en meget bedre overordnet løsning, dels fordi det beskæftiger sig med andre problemer, som multitrocal- ERDDAP s-med-a-load-balancer tilgang begynder ikke engang at adressere, især decentraliseret karakter af datakilderne i verden.
Det er bedst at acceptere det enkle faktum, at jeg ikke designede ERDDAP™ at blive indsat som flere identisk ERDDAP s med en belastningsbalancer. Jeg er bevidst designet ERDDAP™ at arbejde godt inden for en føderation af ERDDAP s, som jeg tror har mange fordele. Især en føderation af ERDDAP s er perfekt afstemt med decentraliseret, distribueret system af datacentre, som vi har i den virkelige verden (Tænk på de forskellige IOOS-regioner, eller de forskellige CoastWatch-regioner, eller de forskellige dele af NCEI, eller de 100 andre datacentre i NOAA , eller de forskellige NASA DAAC'er eller 1000's datacentre over hele verden) . I stedet for at fortælle alle datacentre i verden, at de skal opgive deres indsats og sætte alle deres data i en centraliseret "datasø" (selvom det var muligt, er det en frygtelig idé af mange grunde - se de forskellige analyser, der viser de mange fordele ved decentrale systemer ) , ERDDAP 's design arbejder med verden, som det er. Hvert datacenter, der producerer data, kan fortsætte med at vedligeholde, kuratere og tjene deres data (som de bør) , og endnu, med ERDDAP™ , dataene kan også umiddelbart fås fra en centraliseret ERDDAP , uden behov for at overføre data til centraliseret ERDDAP™ eller lagring af duplikerede kopier af dataene. Faktisk kan et givet datasæt samtidig være tilgængeligt fra en ERDDAP™ i den organisation, der producerede og rent faktisk gemmer data (f.eks. GoMOOS) , fra en ERDDAP™ på forældreorganisationen (f.eks. IOOS central) , fra en alt- NOAA ERDDAP™ , fra en all-US-federal regering ERDDAP™ , fra en global ERDDAP™ (GOOS) , og fra specialiseret ERDDAP s s s (f.eks. en a. ERDDAP™ på en institution dedikeret til HAB-forskning) , alle væsentlige øjeblikkelige, og effektivt, fordi kun metadata overføres mellem ERDDAP s, ikke dataene. Bedste af alt, efter den første ERDDAP™ på den oprindelige organisation, alle af den anden ERDDAP s kan opsættes hurtigt (et par timer arbejde) med minimale ressourcer (en server, der ikke behøver nogen RAID'er til datalagring, da den ikke gemmer data lokalt) , og dermed til virkelig minimale omkostninger. Sammenlign, at omkostningerne ved at oprette og vedligeholde et centraliseret datacenter med en datasø og behovet for en virkelig massiv, virkelig dyrt, internetforbindelse, plus det ledende problem i det centraliserede datacenter er et enkelt punkt for fiasko. Til mig, ERDDAP dencentrale, fedeste tilgang er langt, langt overlegen.
I situationer, hvor et givet datacenter har brug for flere ERDDAP s til at imødekomme høj efterspørgsel, ERDDAP 's design er fuldt ud i stand til at matche eller overskride ydelsen af multitrocal- ERDDAP s-med-a-load-balancer tilgang. Du har altid mulighed for at opsætte multikomposit ERDDAP s s s (som diskuteret nedenfor) , hver af dem får alle deres data fra andre ERDDAP s, uden belastning balance. I dette tilfælde anbefaler jeg, at du laver et punkt for at give hver af kompositten ERDDAP s et andet navn / identitet og hvis det er muligt at indstille dem i forskellige dele af verden (f.eks. forskellige AWS regioner) f.eks. ERD \_US\_East, ERD \_US\_West, ERD \_IE, ERD \_FR, ERD \_IT, så brugerne bevidst, gentagne gange, arbejde med en bestemt ERDDAP , med den ekstra fordel, at du har fjernet risikoen fra et enkelt punkt af fiasko.
Gitter, Clusters og føderationer
Under meget tung brug, en enkelt standalone ERDDAP™ vil løbe ind i en eller flere af Begrænsninger anført ovenfor, og selv de foreslåede løsninger vil være utilstrækkelig. Til sådanne situationer, ERDDAP™ har funktioner, der gør det nemt at konstruere skalerbare gitter (også kaldet klynger eller føderationer) af ERDDAP s, som tillader systemet at håndtere meget tung brug (f.eks. for et stort datacenter) .
Jeg bruger gittergitter som en generel betegnelse for at angive en type af Computer klynge hvor alle dele kan eller ikke kan være fysisk placeret i et anlæg og kan eller ikke være centralt administreret. En fordel ved co-located, centralt ejede og administrerede gitter (klynger) er, at de drager fordel af storskalaens økonomi (især den menneskelige arbejdsbelastning) og forenkle dele af systemet fungerer godt sammen. En fordel ved ikke-co-located gitter, ikke-centralt ejede og administreret (Produktioner) er, at de distribuerer den menneskelige arbejdsbelastning og omkostningerne, og kan give nogle ekstra fejltolerance. Den løsning jeg foreslår nedenfor fungerer godt for alle gitter, klynge og federation topografier.
Den grundlæggende idé om at designe et skalérbart system er at identificere de potentielle flaskehalse og derefter designe systemet, så dele af systemet kan kopieres efter behov for at lindre flaskehalsene. Ideelt set øger hver kopierede del kapaciteten af den del af systemet lineært (effektivitet af skalerbarhed) . Systemet er ikke skalérbart, medmindre der er en skalérbar løsning til hver flaskehals. Skalerbarhed er forskellig fra effektivitet (hvor hurtigt en opgave kan gøres — effektiviteten af de dele) . Skalabilitet giver systemet mulighed for at vokse til at håndtere ethvert kravsniveau. Effektivitetseffektivitet (afskalling og af dele) bestemmer, hvor mange servere osv., vil være nødvendigt for at opfylde et givet niveau af efterspørgslen. Effektivitet er meget vigtig, men altid har grænser. Skalbarhed er den eneste praktiske løsning til at bygge et system, der kan håndtere meget meget meget tung brug. Ideelt set vil systemet være skalerbar og effektiv.
Mål mål
Målet for dette design er:
- At lave en skalérbar arkitektur (en, der er let at udvide ved at kopiere en del, der bliver overburdened) . At gøre et effektivt system, der maksimerer tilgængeligheden og overensstemmelsen af de data, der gives de tilgængelige computer ressourcer. (Omkostningerne er næsten altid et problem.)
- For at afbalancere systemets dele, så den ene del af systemet ikke vælter en anden del.
- For at gøre en enkel arkitektur, så systemet er let at oprette og administrere.
- At lave en arkitektur, der fungerer godt med alle gitter topgrafer.
- At gøre et system, der fejler yndefuldt og på en begrænset måde, hvis nogen del bliver overburet. (Den tid, der kræves for at kopiere en stor datasæt, vil altid begrænse systemets evne til at håndtere pludselige stigninger i efterspørgslen efter et bestemt datasæt.)
- (Hvis muligt) At lave en arkitektur, der ikke er bundet til nogen specifik cloud computing service eller andre eksterne tjenester (fordi det ikke behøver dem) .
Anbefalinger
Vores anbefalinger er
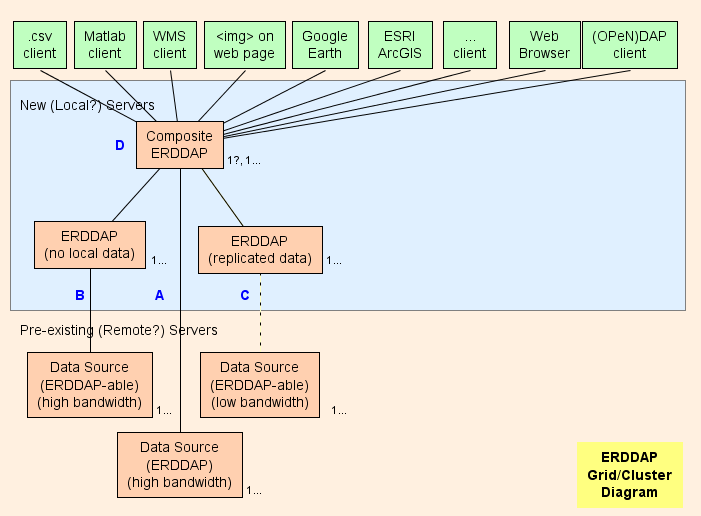
- Dybest set foreslår jeg at oprette en Composite ERDDAP™ ( D D D D i diagrammet) , som er en regelmæssig ERDDAP™ bortset fra at det kun tjener data fra andre ERDDAP s. Gittens arkitektur er designet til at skifte så meget arbejde som muligt (CPU brug, hukommelse forbrug, båndbredde forbrug) fra Composite ERDDAP™ til den anden ERDDAP s.
- ERDDAP™ har to særlige datasæt typer, EDDGrid FraErddap og og og EDDTableFraErddap , som henviser til Datasæt på andre ERDDAP s.
- Når kompositten ERDDAP™ modtager en anmodning om data eller billeder fra disse datasæt, kompositten ERDDAP™ omdirigeringer den anden anmodning om data ERDDAP™ server. Resultatet er:
- Dette er meget effektivt (CPU, hukommelse og båndbredde) , fordi ellers
- Sammensætningen ERDDAP™ skal sende dataanmodningen til den anden ERDDAP .
- Den anden ERDDAP™ skal få dataene, omformatere dem og overføre dataene til kompositten ERDDAP .
- Sammensætningen ERDDAP™ skal modtage oplysningerne (med ekstra båndbredde) , omformatere det (Brug ekstra CPU tid og hukommelse) , og transmittere data til brugeren (med ekstra båndbredde) . Ved at omdirigere dataanmodningen og tillade den anden ERDDAP™ at sende svaret direkte til brugeren, kompositten ERDDAP™ bruger stort set ingen CPU-tid, hukommelse eller båndbredde på dataanmodninger.
- omdirigeringen er gennemsigtig til brugeren uanset klientsoftwaren (en browser eller enhver anden software eller kommandolinjeværktøj) .
- Dette er meget effektivt (CPU, hukommelse og båndbredde) , fordi ellers
Gitterdele
A A A A A A : Til hver fjerndatakilde, der har en højbåndbredde OPeNDAP serveren kan du oprette forbindelse direkte til fjernserveren. Hvis fjernserveren er en ERDDAP™ , brug EDDGrid Fra Erddap eller EDDTableFra ERDDAP til at tjene dataene i Composite ERDDAP . Hvis fjernserveren er en anden type af DAP server, f.eks. THREDDS, Hyrax , eller GrADS, brug EDDGrid FraDap.
B B B B : Til alle ERDDAP -able datakilder (en datakilde, hvorfra ERDDAP kan læse data) der har en high-bandbredde-server, opsætter en anden ERDDAP™ i nettet, som er ansvarlig for at betjene dataene fra denne datakilde.
- Hvis flere sådanne ERDDAP s ikke få mange anmodninger om data, kan du konsolidere dem i én ERDDAP .
- Hvis det er tilfældet ERDDAP™ dedikeret til at få data fra en fjernkilde får for mange anmodninger, der er en fristelse til at tilføje ekstra ERDDAP s til at få adgang til fjerndatakilden. I særlige tilfælde kan det give mening, men det er mere sandsynligt, at dette vil overhænge fjerndatakilden (som er selvforsvar) og forhindre også andre brugere i at få adgang til fjerndatakilden (som ikke er rart) . I så fald overveje at opsætte en anden ERDDAP™ til at tjene den ene datasæt og kopiere datasættet på det ERDDAP 's harddisk (Se se C ) måske med EDDGrid Kopiere Kopier og/eller EDDTableCopy .
- B B B B servere skal være offentligt tilgængelige.
C : Til alle ERDDAP -able datakilde, der har en lav båndbreddeserver (eller er en langsom service af andre årsager) , overveje at oprette en anden ERDDAP™ og lagring af en kopi af datasættet på det ERDDAP 's harddiske, måske med EDDGrid Kopiere Kopier og/eller EDDTableCopy . Hvis flere sådanne ERDDAP s ikke få mange anmodninger om data, kan du konsolidere dem i én ERDDAP . C servere skal være offentligt tilgængelige.
Komponenter ERDDAP
D D D D : Sammensætningen ERDDAP™ er en regelmæssig ERDDAP™ bortset fra at det kun tjener data fra andre ERDDAP s.
- Fordi kompositten ERDDAP™ har oplysninger om alle datasæt, det kan hurtigt svare på anmodninger om lister over datasæt (fuld tekst søgninger, kategori søgninger, listen over alle datasæt) , og anmodninger om en individuel datasæts data Access Form, Make A Graph-formular eller WMS info side. Disse er alle små, dynamisk genereret, HTML-sider baseret på oplysninger, der holdes i hukommelse. Så reaktionerne er meget hurtige.
- Fordi anmodninger om faktiske data hurtigt bliver omdirigeret til den anden ERDDAP s, komposit ERDDAP™ kan hurtigt reagere på anmodninger om faktiske data uden at bruge nogen CPU-tid, hukommelse eller båndbredde.
- Ved at skifte så meget arbejde som muligt (CPU, hukommelse, båndbredde) fra Composite ERDDAP™ til den anden ERDDAP s, komposit ERDDAP™ kan forekomme at tjene data fra alle datasæt og stadig holde op med meget store antal data anmodninger fra et stort antal brugere.
- Preliminære tests indikerer, at kompositten ERDDAP™ kan svare på de fleste anmodninger i ~1ms af CPU tid, eller 1000 anmodninger / sekunder. Så en 8 kerneprocessor skal kunne reagere på omkring 8000 anmodninger / sekunder. Selv om det er muligt at forestille udbrud af højere aktivitet, som ville forårsage nedsænkninger, det er en masse gennemløb. Det er sandsynligt, at data center båndbredde vil være flaskehals længe før kompositten ERDDAP™ bliver flaskehalsen.
Maksimum max (tidstid) ?
The The The The The The The EDDGrid /TableFraErddap i komposit ERDDAP™ ændrer kun de lagrede oplysninger om hver kildedatasæt, når kildedatasættet er "reload"ed og et stykke metadata ændringer (f.eks. tidsvariablens tid actual\_range ) , og dermed generere en abonnementsmeddelelse. Hvis kildedatasættet har data, der ofte ændres (for eksempel nye data hvert sekund) og brug af "update" system til at bemærke hyppige ændringer i de underliggende data, EDDGrid /TableFraErddap vil ikke blive underrettet om disse hyppige ændringer, indtil næste datasæt "reload", så den EDDGrid /TableFraErddap vil ikke være perfekt opdateret. Du kan minimere dette problem ved at ændre kildedataset's<reloadEveryNMinutes> til en mindre værdi (60? 15?) så der er flere abonnementsmeddelelser for at fortælle de EDDGrid /TableFraErddap for at opdatere sine oplysninger om kildedatasættet.
Eller hvis dit datastyringssystem kender, når kildedatasættet har nye data (f.eks. via et script, der kopierer en datafil på plads) , og hvis det ikke er super hyppig (f.eks. hver 5 minutter eller mindre hyppig) , der er en bedre løsning:
- Brug ikke<opdateringEveryNMillis> for at holde kildedatasættet opdaterede.
- Angiv kildedatasæt's<reloadEveryNMinutes> til et større antal (1440?) .
- Har scriptet kontakt kildedataset's flag URL højre efter det kopierer en ny datafil på plads. Det vil føre til, at kildedatasættet er helt up-to-date og forårsage, at den genererer en abonnementsmeddelelse, der sendes til kilden. EDDGrid /TableFraErddap datasæt. Det vil føre EDDGrid /TableFraErddap datasæt til at være perfekt opdateret (Inden for 5 sekunder tilføjes nye data) . Og alt, hvad der sker effektivt (uden unødvendige datasæt reloads) .
Multiple Composite ERDDAP s s s
- I meget ekstreme tilfælde, eller for fejltolerance, kan du muligvis konfigurere mere end én komposit ERDDAP . Det er sandsynligt, at andre dele af systemet (Især datacentrets båndbredde) vil blive et problem længe, før kompositten ERDDAP™ bliver en flaskehals. Så løsningen er sandsynligvis at opsætte yderligere, geografisk forskelligartede datacentre (spejle spejle) , hver med én komposit ERDDAP™ og servere med ERDDAP s og s (mindst mindst) Spejl kopier af de datasæt, der er i høj efterspørgsel. Sådan en opsætning giver også fejltolerance og backup af data (via kopiering) . I dette tilfælde er det bedst, hvis kompositten ERDDAP s har forskellige webadresser.
Hvis du virkelig ønsker alle de komposit ERDDAP s til at have den samme URL, bruge et front endesystem, der tildeler en given bruger til blot en af kompositten ERDDAP s s s (baseret på IP-adressen) , så alle brugerens ønsker går til blot en af kompositten ERDDAP s. Der er to grunde:
- Når et underliggende datasæt indlæses, og metadataændringerne ændres (f.eks. en ny datafil i en gitterded datasæt forårsager tidsvariablens tidsvariable actual\_range for at ændre) , komposit ERDDAP s vil være midlertidigt lidt ud af synkronisering, men med eventuelt konsistens . Normalt vil de re-synch inden for 5 sekunder, men nogle gange vil det være længere. Hvis en bruger gør et automatiseret system, der er afhængig af ERDDAP™ Abonnementer at udløse handlinger, vil de korte synkroniseringsproblemer blive betydelige.
- 2+ komposit ERDDAP s hver fastholder deres eget sæt abonnementer (på grund af synkroniseringsproblemet beskrevet ovenfor) .
Så en given bruger skal rettes til blot en af kompositten ERDDAP s for at undgå disse problemer. Hvis en af kompositten ERDDAP s går ned, front endesystemet kan omdirigere, at ERDDAP 's brugere til en anden ERDDAP™ det er op. Men hvis det er et kapacitet problem, der forårsager den første komposit ERDDAP™ at undlade (en overtrolig bruger? a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a a detial-of-service angreb ?) , det gør det meget sandsynligt, at omdirigere sine brugere til andre komposit ERDDAP s vil forårsage en kaskeding fejl . Således er den mest robuste opsætning at have komposit ERDDAP s med forskellige webadresser.
Eller måske bedre, sætte flere komposit ERDDAP s uden belastning balance. I dette tilfælde skal du gøre et punkt for at give hver af de ERDDAP s et andet navn / identitet og hvis det er muligt at indstille dem i forskellige dele af verden (f.eks. forskellige AWS regioner) f.eks. ERD \_US\_East, ERD \_US\_West, ERD \_IE, ERD \_FR, ERD \_IT, så brugerne bevidst, gentagne gange arbejder med en bestemt ERDDAP .
- \[ For et fascinerende design af et højtydende system, der kører på en server, se dette detaljeret beskrivelse af Mailinator . \]
Datasets i meget høj efterspørgsel
I den virkelig usædvanlige sag, at en af de A A A A A A , B B B B eller C ERDDAP s kan ikke holde op med anmodninger på grund af båndbredde eller harddisk begrænsninger, det giver mening at kopiere dataene (igen igen igen) på en anden server+hard Drive+ ERDDAP måske med EDDGrid Kopiere Kopier og/eller EDDTableCopy . Mens det kan synes ideelt at have den oprindelige datasæt, og den kopierede datasæt vises problemfrit som et datasæt i komposit ERDDAP™ , dette er svært, fordi de to datasæt vil være i lidt forskellige stater på forskellige tidspunkter (Især efter originalen får nye data, men før den kopierede datasæt får sin kopi) . Derfor anbefaler jeg, at datasætene får lidt forskellige titler (f.eks. "... (Kopier #1) " og "... (kopi #2) " eller måske " (Spejl # n n n n ) " eller " (server # n n n n ) " " " ") og vises som separate datasæt i komposit ERDDAP . Brugere bruges til at se lister over Spejle steder på populære fildownload sites, så dette bør ikke overraske eller skuffe dem. På grund af båndbredde begrænsninger på et givet websted, kan det give mening at have spejlet placeret på et andet websted. Hvis spejlkopien er på et andet datacenter, tilgås lige ved, at datacenterets komposit ERDDAP™ , de forskellige titler (f.eks. "mirror #1) er ikke nødvendigt.
RAID'er mod almindelige harddiske
Hvis en stor datasæt eller en gruppe datasæt ikke er stærkt brugt, kan det give mening at gemme dataene på en RAID, da det tilbyder fejltolerance og da du ikke behøver behandlingseffekt eller båndbredde af en anden server. Men hvis et datasæt er stærkt brugt, kan det give mere mening at kopiere dataene på en anden server + ERDDAP™ + harddisk (lignende til hvad Google gør ) snarere end at bruge en server og en RAID til at gemme flere datasæt, da du kommer til at bruge både server+hardDrive+ ERDDAP s i gitteret, indtil en af dem fejler.
Undladelse
Hvad sker der, hvis...
- Der er et glimt af anmodninger om et datasæt (f.eks. alle studerende i en klasse samtidig anmode om lignende data) ? Kun den eneste ERDDAP™ der tjener, at datasæt vil blive overvældet og langsom eller nægte anmodninger. Sammensætningen ERDDAP™ og andre ERDDAP s vil ikke blive påvirket. Da den begrænsende faktor for et givent datasæt i systemet er harddisken med data (Ikke ikke ERDDAP ) , den eneste løsning (Ikke umiddelbart) er at lave en kopi af datasættet på en anden server+hardDrive+ ERDDAP .
- An An An An An A A A A A A , B B B B eller C ERDDAP™ fejl (f.eks. harddiskfejl) ? Kun datasættet (s s s) serveret af det ERDDAP™ påvirkes. Hvis datasættet (s s s) spejles på en anden server+hardDrive+ ERDDAP , effekten er minimal. Hvis problemet er en harddiskfejl i et niveau 5 eller 6 RAID, skal du blot udskifte drevet og have RAID genopbygge dataene på drevet.
- Sammensætningen ERDDAP™ fejl? Hvis du ønsker at gøre et system med meget høj tilgængelighed , du kan oprette multikomposit ERDDAP s s s (som diskuteret ovenfor) , ved hjælp af noget lignende NGINX eller eller eller Traefik at håndtere belastningsbalance. Bemærk, at en given komposit ERDDAP™ kan håndtere et meget stort antal anmodninger fra et stort antal brugere, fordi anmodninger om metadata er små og håndteres af oplysninger, der er i hukommelse og anmodninger om data (som kan være stor) bliver viderestillet til barnet ERDDAP s.
Enkel, Skalabel
Dette system er nemt at oprette og administrere, og let at udvide, når en del af det bliver overburdened. De eneste reelle begrænsninger for et givet datacenter er datacentrets båndbredde og omkostningerne ved systemet.
Bandbredde
Bemærk den omtrentlige båndbredde af almindeligt anvendte komponenter i systemet:
| Komponenter | Cirkel Bandbredde (GBytes/s) |
|---|---|
| DDR hukommelse | 2,5 |
| SSD-drev | 1 1 1 1 |
| SATA harddisk | 0,3 |
| Gigabit Ethernet | 0,1 0,1 |
| OC-12 | 0.06 |
| OC-3 | 0.015 |
| T1 | 0.0002 |
Så en SATA harddisk (0.3 GB/s) på én server med én ERDDAP™ kan sandsynligvis tilfredsstille et Gigabit Ethernet LAN (0.1 GB/s) . Og én Gigabit Ethernet LAN (0.1 GB/s) kan sandsynligvis tilfredsstille en OC-12 internetforbindelse (0.06 GB/s) . Og mindst én kildelister OC-12 linjer koster omkring $100.000 pr. måned. (Ja, disse beregninger er baseret på at skubbe systemet til dens grænser, hvilket ikke er godt, fordi det fører til meget snedige svar. Men disse beregninger er nyttige til planlægning og til balancering af dele af systemet.) En praktisk hurtig internetforbindelse til dit datacenter er langt den dyreste del af systemet. Du kan nemt og relativt billigt opbygge et gitter med en snesevis servere, der kører en snesevis ERDDAP s som er i stand til at pumpe masser af data hurtigt, men en passende hurtig internetforbindelse vil være meget, meget dyrt. De delvise løsninger er:
- Opfordre klienter til at anmode undersæt af dataene, hvis det er alt, hvad der er nødvendigt. Hvis klienten kun har brug for data til en lille region eller ved en lavere opløsning, er det, de skal anmode. Subsetting er et centralt fokus på protokollerne ERDDAP™ understøtter til at anmode om data.
- Opfordrer komprimerede data. ERDDAP™ komprimerer en dataoverførsel, hvis den finder "accept-kodning" i HTTP GET anmodning header. Alle webbrowsere bruger "accept-encoding" og automatisk undertrykke svaret. Andre kunder (f.eks. computerprogrammer) skal bruge det udtrykkeligt.
- Øg dine servere på en internetudbyder eller et andet websted, der tilbyder relativt billigere båndbredde omkostninger.
- Disperse serverne med serveren ERDDAP s til forskellige institutioner, så omkostningerne spredes. Du kan derefter forbinde din komposit ERDDAP™ til deres ERDDAP s.
Bemærk, at Cloud Computing og webhosting tjenester tilbyder alle den internet båndbredde, du har brug for, men ikke løse prisproblemet.
For generel information om at designe skalerbare, høj kapacitet, fejlbehæftede systemer, se Michael T. Nygards bog Udgivelse af det .
Ligesom Legos
Softwaredesignere forsøger ofte at bruge gode software design mønstre at løse problemer. Gode mønstre er gode, fordi de isolerer godt, nemt at skabe og arbejde med, generelle løsninger, der fører til systemer med gode egenskaber. Mønsternavne er ikke standardiseret, så jeg vil kalde det mønster, som ERDDAP™ Brug Lego Mønster. Hver Lego (hver hver ERDDAP ) er en simpel, lille, standard, stand-alone, mursten (Dataserver) med en defineret grænseflade, der gør det muligt at forbinde til andre benos ( ERDDAP s s s) . Dele af ERDDAP™ der udgør dette system: abonnement og flagURL-systemer (som giver mulighed for kommunikation mellem ERDDAP s s s) , EDD... FraErddap redirect system, og systemet af RESTful anmodninger om data, der kan genereres af brugere eller andre ERDDAP s. Således, givet to eller flere benos ( ERDDAP s s s) , du kan oprette et stort antal forskellige former (netværks topologier af ERDDAP s s s) . Sikker, design og funktioner af ERDDAP™ kunne være gjort anderledes, ikke Lego-lignende, måske bare for at aktivere og optimere for en bestemt topologi. Men vi føler, at ERDDAP 's Lego-lignende design tilbyder en god, generel løsning, der gør det muligt for enhver ERDDAP™ Administrator (eller gruppe af administratorer) for at skabe alle former for forskellige federation topologier. For eksempel kunne en enkelt organisation oprette tre (eller mere) ERDDAP s som vist i ERDDAP™ Grid/Cluster Diagram ovenfor . Eller en distribueret gruppe (Hvad er jeg? Er du interesseret i CoastWatch? NCEI? Hvad er NWS? NOAA ? Amerikanske? DataONE? Er du klar? LTER? OOI? Hvad er BODC? ONC? JRC? WMO?) kan opsætte én ERDDAP™ i hver lille udpost (så dataene kan forblive tæt på kilden) og derefter opsætte en komposit ERDDAP™ i det centrale kontor med virtuelle datasæt (som altid er perfekt opdateret) fra hver af de små udpost ERDDAP s. Faktisk, alle af ERDDAP s, installeret på forskellige institutioner over hele verden, som får data fra andre ERDDAP s og/eller give data til andre ERDDAP s, form et kæmpe netværk af ERDDAP s. Hvor cool er det?! Så som med Lego's, mulighederne er uendelige. Derfor er dette et godt mønster. Derfor er dette et godt design til et godt design ERDDAP .
Forskellige anmodninger
En af de virkelige komplikationer af denne diskussion af dataserver topologier er, at der er forskellige typer anmodninger og forskellige måder at optimere for de forskellige typer anmodninger. Dette er for det meste et separat problem (Hvor hurtigt kan det ERDDAP™ med dataene svarer til anmodning om data?) fra topologi diskussion (som beskæftiger sig med relationer mellem dataservere og hvilken server har de faktiske data) . ERDDAP™ , selvfølgelig, forsøger at håndtere alle typer anmodninger effektivt, men håndterer nogle bedre end andre.
- Mange anmodninger er enkle. For eksempel: Hvad er metadata for denne datasæt? Eller: Hvad er værdien af tidsdimensionen for denne gitterded datasæt? ERDDAP™ er designet til at håndtere disse så hurtigt som muligt (normalt i<=2 ms) ved at holde disse oplysninger i hukommelsen.
- Nogle anmodninger er moderat svært. For eksempel: Giv mig denne del af et datasæt (som er i én datafil) . Disse anmodninger kan håndteres relativt hurtigt, fordi de ikke er så svært.
- Nogle anmodninger er hårde og dermed er tidskrævende. For eksempel: Giv mig denne del af et datasæt (som kan være i nogen af de 10.000+ datafiler, eller kan være fra komprimerede datafiler, der hver tager 10 sekunder for at dekomprimere) . ERDDAP™ v2.0 indførte nogle nye, hurtigere måder at håndtere disse anmodninger, især ved at tillade anmodning-håndteringstråd til at spawn flere arbejdstråde, der tackler forskellige underser af anmodningen. Men der er en anden tilgang til dette problem, som ERDDAP™ understøtter ikke endnu: undersæt af datafiler til en given datasæt kan gemmes og analyseres på separate computere, og derefter resultaterne kombineret på den oprindelige server. Denne tilgang kaldes Billeder afReduce og er eksemplificeret af Hadoop , den første (?) Open-source MapReduce program, som var baseret på ideer fra et Google-papir. (Hvis du har brug for MapReduce i ERDDAP , send en e-mail anmodning til erd.data at noaa.gov .) Googles BigQuery er interessant, fordi det ser ud til at være en implementering af MapReduce, der anvendes til at underbygge tabulerede datasæt, som er en af ERDDAP 's vigtigste mål. Det er sandsynligt, at du kan oprette en ERDDAP™ datasæt fra et BigQuery datasæt via EDDTableFraDatabase fordi BigQuery kan tilgås via en JDBC interface.
Det er mine meninger.
Ja, beregningerne er forenklet (og nu lidt dateret) , men jeg tror, at konklusionerne er korrekte. Har jeg brug for fejlagtig logik eller lave en fejl i mine beregninger? Hvis det er tilfældet, er fejlen min alene. Send en e-mail med korrektionen til erd dot data at noaa dot gov .
Cloud Computing
Flere virksomheder tilbyder cloud computing-tjenester (fx, Amazon Web Services og og og Google Cloud Platform ) . Web hostingfirmaer Siden midten af1990'erne har "cloud"-tjenesterne udvidet fleksibiliteten ved systemerne og de tjenester, der tilbydes. Siden ERDDAP™ gitter består kun af ERDDAP s og siden ERDDAP s er Java webapplikationer, der kan køre i Tomcat (den mest almindelige programserver) eller andre applikationsservere, bør det være relativt nemt at oprette en ERDDAP™ gitter på en cloud-tjeneste eller webhosting site. Fordelene ved disse tjenester er:
- De tilbyder adgang til meget høje båndbredde internetforbindelser. Dette alene kan begrunde brugen af disse tjenester.
- De opkræver kun de tjenester, du bruger. For eksempel får du adgang til en meget høj båndbredde internetforbindelse, men du betaler kun for faktiske data overført. Det lader dig opbygge et system, der sjældent bliver overvældet (selv ved høj efterspørgsel) , uden at skulle betale for kapacitet, der sjældent bruges.
- De er nemme at udvide. Du kan ændre servertyper eller tilføje så mange servere eller så meget lagerplads, som du ønsker, i mindre end et minut. Dette alene kan begrunde brugen af disse tjenester.
- De frigør dig fra mange af de administrative opgaver ved at køre servere og netværk. Dette alene kan begrunde brugen af disse tjenester.
Ulempen af disse tjenester er:
- De opkræver for deres tjenester, nogle gange en masse (i absolutte termer; ikke at det ikke er en god værdi) . De priser, der er anført her, er for Amazon EC2 . Disse priser (af juni 2015) vil komme ned.
I fortiden var priserne højere, men datafiler og antallet af anmodninger var mindre.
I fremtiden vil priserne være lavere, men datafiler og antallet af anmodninger vil være større.
Så oplysningerne ændres, men situationen forbliver relativt konstant.
Og det er ikke, at tjenesten er overpriset, det er, at vi bruger og køber en masse af tjenesten.
- Dataoverførsel – Dataoverførsler i systemet er nu gratis (Hej!) . Dataoverførsler ud af systemet er $0.09/GB. En SATA harddisk (0.3 GB/s) på én server med én ERDDAP™ kan sandsynligvis tilfredsstille et Gigabit Ethernet LAN (0.1 GB/s) . Et Gigabit Ethernet LAN (0.1 GB/s) kan sandsynligvis tilfredsstille en OC-12 internetforbindelse (0.06 GB/s) . Hvis en OC-12-forbindelse kan overføre ~150.000 GB/måned, kan dataoverførselsomkostningerne være så meget som 150.000 GB @ $0.09/GB = $13,500/måned, som er en betydelig omkostning. klart, hvis du har et dusin hårdtarbejdende arbejde ERDDAP s på en cloudtjeneste, kan dine månedlige dataoverførsel gebyrer være betydelige (op til $162.000/måned) . (Igen er det ikke, at tjenesten er overpriset, det er, at vi bruger og køber en masse af tjenesten.)
- Datalagring – Amazon opkræver $50/måned pr. TB. (Sammenlign, at at købe en 4TB-virksomhed drev til højre for ~ $ 50/TB, selvom RAID til at sætte det i og administrative omkostninger til den samlede pris.) Så hvis du har brug for at gemme masser af data i skyen, kan det være temmelig dyrt (f.eks. vil 100TB koste $5000/måned) . Men med mindre du har en virkelig stor mængde data, er dette et mindre problem end båndbredde / dataoverførsel omkostninger. (Igen er det ikke, at tjenesten er overpriset, det er, at vi bruger og køber en masse af tjenesten.)
Subsetting
- Fejlproblemet: Den eneste måde at distribuere data fra datafiler er at have det program, der distribuerer dataene (fx, ERDDAP ) kører på en server, som har de data, der er gemt på en lokal harddisk (eller lignende hurtig adgang til en SAN eller lokal RAID) . Lokal filsystemer tillader ERDDAP™ (og underliggende biblioteker, såsom netcdf-java) for at anmode specifikke byte spænder fra filerne og få svar meget hurtigt. Mange typer af data anmodninger fra ERDDAP™ til filen (Især gitterede data anmodninger, hvor skridtværdien er > 1 1 1 1) kan ikke gøres effektivt, hvis programmet skal anmode hele filen eller store stykker af en fil fra en ikke-lokal (Derfor langsommere) Datalagringssystem og derefter udtrække en subset. Hvis skyopsætningen ikke giver ERDDAP™ hurtig adgang til byte intervaller af filer (så hurtigt som med lokale filer) , ERDDAP 's adgang til dataene vil være en alvorlig flaskehals og udnytte andre fordele ved at bruge en skytjeneste.
Virksomhedsdata
Et alternativ til ovenstående omkostningsfordele analyse (som er baseret på dataejeren (fx, NOAA ) at betale for deres data, der skal gemmes i skyen) ankom omkring 2012, når Amazon (og i mindre grad, nogle andre cloududbydere) Begynd at hoste nogle datasæt i deres cloud (AWS S3) gratis (formodentlig med håb om, at de kunne genvinde deres omkostninger, hvis brugerne ville leje AWS EC2 beregne forekomster for at arbejde med disse data) . Dette gør cloud computing langt mere omkostningseffektivt, fordi tiden og omkostningerne ved at uploade data og hosting det er nu nul. Med ERDDAP™ v2.0, der er nye funktioner til at lette kørsel ERDDAP i en sky:
- Nu, en EDDGrid FraFiles eller EDDTableFraFiles dataset kan oprettes fra datafiler, der er fjernt og tilgængeligt via internettet (f.eks. AWS S3 skovle) ved brug af<cacheFraUrl> og<cachestørrelse GB> muligheder. ERDDAP™ vil opretholde en lokal cache af de mest brugte datafiler.
- Nu, hvis nogen EDDTableFraFiles kildefiler er komprimeret (fx, .tgz ) , ERDDAP™ vil automatisk dekomprimere dem, når den læser dem.
- Nu, den ERDDAP™ tråd, der reagerer på en given anmodning, vil spawn arbejdstagertråde til at arbejde på underafsnit af anmodningen, hvis du bruger anmodningen<nThreads> muligheder. Denne parallelisering skal give hurtigere svar på vanskelige anmodninger.
Disse ændringer løser problemet med AWS S3 ikke tilbyder lokale, blok-niveau fillagring og problemet (gammel gammel gammel gammel) problem med adgang til S3 data har en betydelig forsinkelse. (Forår siden (~2014) , at lag var betydelig, men er nu meget kortere og så ikke så signifikant.) Alt i alt betyder det, at opsætningen af ERDDAP™ i skyen arbejder meget bedre nu.
Tak – Mange tak til Matthew Arrott og hans gruppe i den oprindelige OOI indsats for deres arbejde på at sætte ERDDAP™ i skyen og de resulterende diskussioner.
Fjern Replication af Datasets
Der er et fælles problem, der er relateret til ovenstående diskussion af gitter og føderationer af ERDDAP s: fjernreplikering af datasæt. Det grundlæggende problem er: en dataudbyder opretholder et datasæt, der ændrer sig lejlighedsvis, og en bruger ønsker at opretholde en opdateret lokal kopi af disse datasæt (af en række grunde) . Der er klart et stort antal variationer af dette. Nogle variationer er meget sværere at håndtere end andre.
- Hurtige opdateringer Det er sværere at holde de lokale datasæt up-to-date straks med det samme (f.eks. inden for 3 sekunder) efter hver ændring til kilden, snarere end for eksempel inden for et par timer.
- Hyppige ændringer Hyppige ændringer er sværere at håndtere end infrequent ændringer. For eksempel, en gang-en-dag ændringer er meget lettere at håndtere end ændringer hver 0,1 sekund.
- Små ændringer Små ændringer til en kildefil er sværere at håndtere end en helt ny fil. Dette er især sandt, hvis de små ændringer kan være overalt i filen. Små ændringer er sværere at opdage og gøre det svært at isolere de data, der skal kopieres. Nye filer er nemme at opdage og effektive til at overføre.
- Hele datasæt At holde en hel datasæt up-to-date er sværere end at opretholde de seneste data. Nogle brugere har lige brug for nylige data (f.eks. den sidste 8 dages værd) .
- Flere Copies Vedligeholdelse af flere fjernkopier på forskellige websteder er sværere end at opretholde en ekstern kopi. Dette er scaling problem.
Der er naturligvis et stort antal variationer af mulige typer ændringer til kildedatasættet og brugerens behov og forventninger. Mange af variationerne er meget vanskelige at løse. Den bedste løsning til én situation er ofte ikke den bedste løsning til en anden situation - der er endnu ikke en universel god løsning.
Relevante oplysninger ERDDAP™ Værktøjsværktøjer
ERDDAP™ tilbyder flere værktøjer, der kan bruges som en del af et system, der søger at vedligeholde en ekstern kopi af et datasæt:
- ERDDAP 's RSS (Oversigt over Rich Site?) Serviceservice
Tilbyder en hurtig måde at kontrollere, om et datasæt på en fjern ERDDAP™ har ændret sig. - ERDDAP 's abonnementsservice
er en mere effektiv (end RSS ) tilgang: Det vil straks sende en e-mail eller kontakte en URL til hver abonnent, når datasættet er opdateret, og opdateringen resulterede i en ændring. Det er effektivt i, at det sker ASAP, og der er ingen spildt indsats (som med afstemning RSS Serviceservice) . Brugere kan bruge andre værktøjer (kan lide IFTTT ) at reagere på e-mail-meddelelser fra abonnementssystemet. For eksempel kan en bruger abonnere på et datasæt på en fjernbetjening ERDDAP™ og brug IFTTT til at reagere på abonnementsmail-meddelelser og udløse opdatering af det lokale datasæt. - ERDDAP 's flagsystem
Giver en måde til en ERDDAP™ administrator for at fortælle et datasæt på hans / hendes ERDDAP at indlæse ASAP. URL-formularen for et flag kan nemt bruges i scripts. URL-formularen for et flag kan også bruges som handlingen for et abonnement. - ERDDAP 's "files" systemsystem
kan tilbyde adgang til kildefiler til et givet datasæt, herunder en Apache-style mappe notering af filerne (En "Web hand mappe") som har hver fils download-URL, senest ændret tid og størrelse. En ulempe ved brug af "files" systemet er, at kildefiler kan have forskellige variable navne og forskellige metadata end datasættet, da det vises i ERDDAP . Hvis en fjernbetjening ERDDAP™ Dataset giver adgang til sine kildefiler, der åbner mulighed for en fattigmands version af rsync: Det bliver nemt for et lokalt system at se, hvilke fjernfiler har ændret sig og skal downloades. (Se billederne cacheFraUrl mulighed nedenfor, som kan gøre brug af dette.)
Løsninger til løsninger
Selvom der er et stort antal variationer til problemet og et uendeligt antal mulige løsninger, er der kun en håndfuld grundlæggende tilgange til løsninger:
Tilpasset, Brute Force Solutions
En oplagt løsning er at bruge en brugerdefineret løsning, som derfor er optimeret til en given situation: gør et system, der registrerer/identificer hvilke data har ændret sig, og sender disse oplysninger til brugeren, så brugeren kan anmode om de ændrede data. Nå, du kan gøre dette, men der er ulemper:
- Tilpassede løsninger er en masse arbejde.
- Brugerdefinerede løsninger er normalt så tilpasset til et givet datasæt og givet brugerens system, som de ikke nemt kan genbruges.
- Brugerdefinerede løsninger skal bygges og vedligeholdes af dig. (Det er aldrig en god ide. Det er altid en god ide at undgå arbejde og få en anden til at gøre arbejdet!)
Jeg tager denne tilgang, fordi det næsten altid er bedre at se efter generelle løsninger, bygget og vedligeholdt af en anden, som nemt kan genbruges i forskellige situationer.
rsync
rsync er den eksisterende, fantastisk god, generelle formål løsning til at holde en samling af filer på en kildecomputer i synkronisering på en brugers fjerncomputer. Den måde, det virker er:
- nogle begivenheder (f.eks. en a. ERDDAP™ abonnementsordning) udløsere, der kører rsync (eller, et cron job kører rsync på specifikke tidspunkter hver dag på brugerens computer)
- som kontakter rsync på kildecomputeren,
- som beregner en række hashes til bidder af hver fil og sender disse hashes til brugerens rsync,
- som sammenligner disse oplysninger til den lignende information for brugerens kopi af filerne,
- som derefter anmoder om bundterne af filer, der har ændret sig.
I betragtning af alt, hvad det gør, rsync fungerer hurtigt (f.eks. 10 sekunder plus overførselstid) og meget effektivt. Der er der variationer af rsync at optimere til forskellige situationer (f.eks. ved præcalculating og kaching hashes af bidderne af hver kildefil) .
De vigtigste svagheder ved rsync er: det tager nogle bestræbelser på at opsætte (sikkerhedsproblemer) ; der er nogle scaling problemer; og det er ikke godt at holde NRT-datasæt virkelig opdateret (f.eks. er det akavet at bruge rsync mere end ca. 5 minutter) . Hvis du kan håndtere svaghederne, eller hvis de ikke påvirker din situation, er rsync en fremragende, generelle formålsløsning, som alle kan bruge lige nu for at løse mange scenarier, der involverer fjernreplikering af datasæt.
Der er et element på produktet ERDDAP™ Du kan tilføje support til rsync-tjenester til listen ERDDAP (sandsynligvis en temmelig vanskelig opgave) , så enhver klient kan bruge rsync (eller en variant) for at opretholde en opdateret kopi af et datasæt. Hvis nogen ønsker at arbejde på dette, bedes du email erd.data at noaa.gov .
Der er andre programmer, der gør mere eller mindre, hvad rsync gør, nogle gange orienteret mod datasæt replikering (selvom ofte på et fil-copy-niveau) f.eks. Unidata 's Alle badeværelser er udstyrede med et badekar, en bruser og en hårtørrer. .
Cache fra Url
CacheFraUrl indstilling er tilgængelig (begyndende med ERDDAP™ v2.0) for alle ERDDAP 's datasæt typer, der gør datasæt fra filer (Dybest set alle underklasser af EDDGrid FraFiles og og og EDDTableFraFiles ) . cache cache cache cache FraUrl gør det trivial til automatisk at downloade og vedligeholde de lokale datafiler ved at kopiere dem fra en fjernkilde via cachen FraUrl indstilling. Fjernfiler kan findes i en webbaseret mappe eller en mappe, der er tilgængelig af THREDDS, Hyrax , en S3 spand eller ERDDAP 's "files" system.
Hvis kilden til fjernfiler er en fjernbetjening ERDDAP™ datasæt, der tilbyder kildefiler via ERDDAP™ "files" system, så kan du abonnere til fjerndatasættet, og brug den flag URL for dit lokale datasæt som handlingen for abonnementet. Så, når fjerndatasættet ændres, vil den kontakte flag URL for dit datasæt, som vil fortælle det til at indlæse ASAP, som vil opdage og downloade de ændrede fjerndatafiler. Alt dette sker meget hurtigt (normalt ~5 sekunder plus den tid, der er nødvendig for at downloade de ændrede filer) . Denne tilgang fungerer fantastisk, hvis kildedatasættet ændres er nye filer bliver periodisk tilføjet, og når de eksisterende filer aldrig ændres. Denne tilgang virker ikke godt, hvis data ofte føjes til alle (eller mest) af de eksisterende kildedatafiler, fordi så din lokale datasæt ofte downloader hele fjerndatasættet. (Det er her en rsync-lignende tilgang er nødvendig.)
ArchiveADataset
ERDDAP™ 's ArchiveADataset er en god løsning, når data tilføjes til et datasæt ofte, men ældre data ændres aldrig. Dybest set, en ERDDAP™ Administrator kan køre ArkivADataset (måske i et script, måske løber af cron) og angive en del af et datasæt, som de ønsker at udtrække (måske i flere filer) og pakke i en .zip eller eller eller .tgz fil, så du kan sende filen til interesserede personer eller grupper (f.eks. NCEI til arkivering) eller gør det tilgængeligt for download. Du kan f.eks. køre ArkivADataset hver dag på 12:10 am og få det til at gøre et .zip af alle data fra 12:00 er den foregående dag, indtil 12:00 er i dag. (Eller gør denne ugentlige, månedlige eller årlige, efter behov.) Fordi pakkefilen er genereret offline, er der ingen fare for en timeout eller for meget data, da der ville være for en standard ERDDAP™ anmodning.
ERDDAP™ 's standardforespørgselssystem
ERDDAP™ 's standardforespørgselssystem er en alternativ god løsning, når data tilføjes til et datasæt ofte, men ældre data ændres aldrig. Dybest set kan alle bruge standardanmodninger til at få data til en bestemt række tid. Du kan f.eks. foretage en anmodning om alle data fra et fjerndatasæt fra 12:00 er den foregående dag, indtil 12:00 er i dag. Begrænsninger (sammenlignet med ArchiveADataset-tilgangen) er risikoen for en timeout, eller der er for meget data til en enkelt fil. Du kan undgå begrænsning ved at gøre hyppige forespørgsler til mindre tidsperioder.
EDDTableFraHttpGet
\[ Denne mulighed eksisterer ikke endnu, men synes muligt at bygge i den nærmeste fremtid. \]
Den nye EDDTableFraHttpGet datasæt type i ERDDAP™ v2.0 gør det muligt at forestille en anden løsning. De underliggende filer, der vedligeholdes af denne type datasæt, er væsentlige log filer, der registrerer ændringer i datasættet. Det bør være muligt at opbygge et system, der opretholder et lokalt datasæt med jævne mellemrum (eller baseret på en udløser) anmode om alle de ændringer, der er foretaget til fjerndatasættet, siden den sidste anmodning. Det bør være så effektivt (eller mere) end rsync og ville håndtere mange vanskelige scenarier, men ville kun arbejde, hvis fjernbetjeningen og de lokale datasæt er EDDTableFraHttpGet datasets.
Hvis nogen ønsker at arbejde på dette, bedes du kontakte erd.data at noaa.gov .
Distribuerede data
Ingen af løsningerne ovenfor gør et godt job med at løse de hårde variationer af problemet, fordi replikering af nær realtid (NRT) Datasets er meget hårdt, dels på grund af alle de mulige scenarier.
Der er en stor løsning: Forsøg ikke engang at kopiere dataene. Brug i stedet den ene forfatteritativ kilde (en datasæt på én ERDDAP ) , vedligeholdt af dataudbyderen (f.eks. et regionalkontor) . Alle brugere, der ønsker data fra den datasæt altid får den fra kilden. For eksempel får browserbaserede apps data fra en URL-baseret anmodning, så det ikke bør være, at anmodningen er til den oprindelige kilde på en fjernserver (ikke den samme server, der er vært for ESM) . Mange mennesker har været med til at provokere denne Distributed Data-tilgang i lang tid (f.eks. Roy Mendelssohn for de sidste 20+ år) . ERDDAP 's gitter/federation model (top 80% af dette dokument) er baseret på denne tilgang. Denne løsning er som et sværd til en Gordian Knot — hele problemet går væk.
- Denne løsning er fantastisk enkel.
- Denne løsning er fantastisk effektiv, da der ikke sker arbejde for at holde en kopieret datasæt (s s s) opdateret.
- Brugere kan få de seneste data til enhver tid (f.eks. med en latency af kun ~ 0,5 sekund) .
- Det er ret godt, og der er måder at forbedre skalerbarhed. (Se diskussionen på de øverste 80% af dette dokument.)
Nej, det er ikke en løsning til alle mulige situationer, men det er en stor løsning for det store flertal. Hvis der er problemer/viaknesses med denne løsning i visse situationer, er det ofte værd at arbejde for at løse disse problemer eller leve med disse svagheder på grund af de fantastiske fordele ved denne løsning. Hvis / når denne løsning er virkelig uacceptabel for en given situation, f.eks. når du virkelig skal have en lokal kopi af dataene, skal du overveje de andre løsninger, der er diskuteret ovenfor.
Konklusion
Mens der ikke er nogen enkelt, enkel løsning, der perfekt løser alle problemerne i alle scenarier (som rsync og Distributed Data næsten er) Forhåbentlig er der tilstrækkelige værktøjer og muligheder, så du kan finde en acceptabel løsning til din særlige situation.