Escalada
ERDDAP™ - Carga pesada, rejas, racimos, federaciones y computación en la nube
ERDDAP :
ERDDAP™ es una aplicación web y un servicio web que agrega datos científicos de diversas fuentes locales y remotas y ofrece una manera sencilla y consistente de descargar subconjuntos de los datos en formatos de archivos comunes y hacer gráficos y mapas. Esta página web discute temas relacionados con pesados ERDDAP™ cargas de uso y explora posibilidades para lidiar con cargas extremadamente pesadas a través de rejillas, racimos, federaciones y computación en la nube.
La versión original fue escrita en junio de 2009. No ha habido cambios significativos. Esto fue actualizado por última vez 2019-04-15.
DISCLAIMER
Los contenidos de esta página web son las opiniones personales de Bob Simons y no reflejan necesariamente ninguna posición del Gobierno o del Gobierno National Oceanic and Atmospheric Administration . Los cálculos son simplistas, pero creo que las conclusiones son correctas. ¿Usé lógica defectuosa o cometí un error en mis cálculos? Si es así, la culpa es mía sola. Por favor envíe un correo electrónico con la corrección erd dot data at noaa dot gov .
Carga pesada / Limitaciones
Con mucho uso, un standalone ERDDAP™ se verá limitado (de lo más a lo menos probable) por:
Ancho de banda remoto
- Ancho de banda de una fuente remota de datos — incluso con una conexión eficiente (por ejemplo, via OPeNDAP ) , a menos que una fuente de datos remota tenga una conexión a Internet de banda muy alta, ERDDAP 's respuestas serán limitadas por lo rápido ERDDAP™ puede obtener datos de la fuente de datos. Una solución es copiar el conjunto de datos sobre ERDDAP Es disco duro, quizás con EDDGrid Copiado o EDDTableCopy .
ERDDAP 's Server Bandwidth
- A menos ERDDAP 's servidor tiene una conexión a Internet muy alta ancho de banda, ERDDAP 's respuestas serán limitadas por lo rápido ERDDAP™ puede obtener datos de las fuentes de datos y cuán rápido ERDDAP™ puede devolver datos a los clientes. La única solución es conseguir una conexión a Internet más rápida.
Memoria
- Si hay muchas solicitudes simultáneas, ERDDAP™ puede quedar sin memoria y rechazar temporalmente nuevas solicitudes. ( ERDDAP™ tiene un par de mecanismos para evitar esto y minimizar las consecuencias si sucede.) Así que cuanto más memoria en el servidor mejor. En un servidor de 32 bits, 4+ GB es realmente bueno, 2 GB está bien, menos no se recomienda. En un servidor de 64 bits, casi completamente puede evitar el problema consiguiendo mucha memoria. Ver el Ajustes \-Xmx y -Xms para ERDDAP -Tomcat. An ERDDAP™ conseguir un uso pesado en un ordenador con un servidor de 64 bits con 8 GB de memoria y -Xmx fijado a 4000M es rara vez, si alguna vez, limitado por la memoria.
Tenía un ancho de banda
- El acceso a los datos almacenados en el disco duro del servidor es mucho más rápido que el acceso a datos remotos. Incluso así, si el ERDDAP™ servidor tiene una conexión a Internet muy alta ancho de banda, es posible que acceder a los datos en el disco duro será un cuello de botella. Una solución parcial es usar más rápido (por ejemplo, 10.000 RPM) discos duros magnéticos o unidades SSD (si tiene sentido costo-sabio) . Otra solución es almacenar diferentes conjuntos de datos en diferentes unidades, por lo que el ancho de banda del disco duro acumulativo es mucho más alto.
Demasiados archivos grabados
- Demasiados archivos en un cache directorio — ERDDAP™ encaje todas las imágenes, pero sólo encaje los datos para ciertos tipos de solicitudes de datos. Es posible que el directorio cache para un conjunto de datos tenga un gran número de archivos temporalmente. Esto reducirá las solicitudes para ver si un archivo está en el caché (¡En serio!) .<cache Minutos afectados; in setup.xml le permite establecer cuánto tiempo un archivo puede estar en el caché antes de que se elimina. Establecer un número más pequeño minimizaría este problema.
CPU
- Sólo dos cosas tardan mucho tiempo en la CPU:
- NetCDF 4 y 4 HDF 5 ahora soportan la compresión interna de datos. Descomprimir un gran comprimido NetCDF 4 / HDF El archivo de 5 datos puede tardar 10 o más segundos. (Eso no es culpa de la implementación. Es la naturaleza de la compresión.) Por lo tanto, múltiples solicitudes simultáneas a conjuntos de datos con datos almacenados en archivos comprimidos pueden poner una tensión severa en cualquier servidor. Si esto es un problema, la solución es almacenar conjuntos de datos populares en archivos no comprimidos, o conseguir un servidor con una CPU con más núcleos.
- Haciendo gráficos (incluyendo mapas) : aproximadamente 0,2 - 1 segundo por gráfico. Así que si hubo muchas solicitudes únicas simultáneas para gráficos ( WMS clientes a menudo hacen 6 solicitudes simultáneas!) Podría haber una limitación de la CPU. Cuando se ejecutan múltiples usuarios WMS clientes, esto se convierte en un problema.
Múltiple Identical ERDDAP ¿Con el Equilibrio de la Carga?
La pregunta a menudo surge: "Para lidiar con cargas pesadas, puedo configurar múltiples idénticas ERDDAP s con balanceo de carga?" Es una pregunta interesante porque rápidamente llega al núcleo de ERDDAP Es diseño. La respuesta rápida es "no". Sé que es una respuesta decepcionante, pero hay un par de razones directas y algunas razones fundamentales más grandes por las que diseñé ERDDAP™ utilizar un enfoque diferente (una federación de ERDDAP s, descrita en la mayor parte de este documento) , que creo que es una mejor solución.
Algunas razones directas por las que no puedes / no debe configurar múltiples idénticos ERDDAP s son:
- A given ERDDAP™ lee cada archivo de datos cuando se pone a disposición para encontrar los rangos de datos en el archivo. Luego almacena esa información en un archivo índice. Más tarde, cuando un usuario solicita datos, ERDDAP™ usa ese índice para averiguar qué archivos buscar en los datos solicitados. Si hubiera múltiples idénticos ERDDAP s, cada uno estaría haciendo esta indexación, que es esfuerzo perdido. Con el sistema federado descrito a continuación, la indexación sólo se hace una vez, por una de las ERDDAP s.
- Para algunos tipos de solicitudes de usuario (por ejemplo, para .nc , .png, archivos .pdf) ERDDAP™ tiene que hacer todo el archivo antes de que se pueda enviar la respuesta. Así que... ERDDAP™ ancla estos archivos por un corto tiempo. Si una solicitud idéntica entra (como suele hacerlo, especialmente para las imágenes donde la URL está incrustada en una página web) , ERDDAP™ puede reutilizar ese archivo caché. En un sistema de múltiples idénticos ERDDAP s, esos archivos caché no son compartidos, así que cada ERDDAP™ sin necesidad y desperdiciado recrear el .nc , .png, o archivos .pdf. Con el sistema federado descrito a continuación, los archivos sólo se hacen una vez, por uno de los ERDDAP s, y reutilizado.
- ERDDAP 's sistema de suscripción no se establece para ser compartido por múltiples ERDDAP s. Por ejemplo, si el balanceador de carga envía un usuario a uno ERDDAP™ y el usuario se suscribe a un conjunto de datos, luego el otro ERDDAP s no será consciente de esa suscripción. Más tarde, si el balanceador de carga envía al usuario a otro ERDDAP™ y pide una lista de sus suscripciones, la otra ERDDAP™ dirá que no hay ninguno (lo lleva a hacer una suscripción duplicada en el otro ERED DAP ) . Con el sistema federado descrito a continuación, el sistema de suscripción se maneja simplemente por el principal, público, compuesto ERDDAP .
Sí, por cada uno de esos problemas, podría (con gran esfuerzo) ingeniero una solución (compartir la información entre ERDDAP s) , pero creo que federación de... ERDDAP enfoque (descrito en la mayor parte de este documento) es una solución global mucho mejor, en parte porque se ocupa de otros problemas que el multi-identical- ERDDAP s-with-a-load-balancer approach does not even start to address, notably the decentralized nature of the data sources in the world.
Es mejor aceptar el simple hecho de que no diseñé ERDDAP™ a ser desplegados como múltiples idénticos ERDDAP con un balanceador de carga. Concientemente diseñé ERDDAP™ trabajar bien dentro de una federación de ERDDAP s, que creo que tiene muchas ventajas. Notablemente, una federación de ERDDAP s está perfectamente alineado con el sistema descentralizado y distribuido de centros de datos que tenemos en el mundo real (pensar en las diferentes regiones de IOOS, o las diferentes regiones de CoastWatch, o las diferentes partes de NCEI, o los otros 100 centros de datos en NOAA , o los diferentes DAAC de la NASA, o los 1000 de centros de datos en todo el mundo) . En lugar de decirle a todos los centros de datos del mundo que necesitan abandonar sus esfuerzos y poner todos sus datos en un "lagos de datos" centralizado (incluso si fuera posible, es una idea horrible por numerosas razones - ver los diversos análisis que muestran las numerosas ventajas de sistemas descentralizados ) , ERDDAP 's diseño funciona con el mundo como es. Cada centro de datos que produce datos puede continuar manteniendo, comisariando y sirviendo sus datos (como deberían) , y sin embargo, con ERDDAP™ , los datos también pueden estar disponibles instantáneamente desde un centralizado ERDDAP , sin necesidad de transmitir los datos a la centralizada ERDDAP™ o almacenar copias duplicadas de los datos. De hecho, un conjunto de datos puede estar disponible simultáneamente de un ERDDAP™ en la organización que produjo y almacena los datos (por ejemplo, GoMOOS) , de un ERDDAP™ en la organización matriz (por ejemplo, IOOS central) , de un todo... NOAA ERDDAP™ , de un gobierno federal ERDDAP™ , de un mundo ERDDAP™ (GOOS) , y de especialistas ERDDAP s (por ejemplo, un ERDDAP™ en una institución dedicada a la investigación HAB) , todo esencialmente instantáneamente, y eficientemente porque sólo los metadatos se transfieren entre ERDDAP s, no los datos. Lo mejor de todo, después de la inicial ERDDAP™ en la organización originaria, todo el otro ERDDAP s se puede configurar rápidamente (unas horas de trabajo) , con recursos mínimos (un servidor que no necesita ningún RAID para almacenamiento de datos ya que no almacena datos localmente) , y por lo tanto a un costo realmente mínimo. Compare eso con el costo de establecer y mantener un centro de datos centralizado con un lago de datos y la necesidad de una conexión a Internet realmente masiva, realmente costosa, además del problema adjunto del centro de datos centralizado siendo un solo punto de fracaso. Para mí, ERDDAP s decentralized, federated approach is far, far superior.
En situaciones donde un centro de datos dado necesita múltiples ERDDAP para satisfacer la alta demanda, ERDDAP 's diseño es totalmente capaz de combinar o superar el rendimiento de la multi-identical- ERDDAP s-with-a-load-balancer approach. Siempre tienes la opción de configurar múltiple compuesto ERDDAP s (como se examina a continuación) , cada uno de los cuales obtiene todos sus datos de otros ERDDAP s, sin equilibrio de carga. En este caso, recomiendo que usted haga un punto de dar cada uno de los compuestos ERDDAP s un nombre / identidad diferente y si es posible establecerlos en diferentes partes del mundo (e.g., different AWS regions) , por ejemplo, ERD Este, ERD \_US\_West, ERD \_IE, ERD \_FR, ERD \_IT, para que los usuarios conscientemente, repetidamente, trabajen con un específico ERDDAP , con el beneficio añadido que ha eliminado el riesgo de un solo punto de fracaso.
Grids, Clusters, and Federations
Bajo un uso muy pesado, una sola independiente ERDDAP™ se encontrará con uno o más de los limitaciones lista arriba e incluso las soluciones sugeridas serán insuficientes. Para tales situaciones, ERDDAP™ tiene características que hacen fácil construir redes escalables (también llamados grupos o federaciones) de ERDDAP s que permite al sistema manejar un uso muy pesado (por ejemplo, para un gran centro de datos) .
Estoy usando cuadrícula como término general para indicar un tipo de Grupo de computadora donde todas las partes pueden o no estar físicamente ubicadas en una instalación y pueden o no ser administradas centralmente. Una ventaja de las redes colocadas, de propiedad central y administradas (clusters) es que se benefician de economías de escala (especialmente el volumen de trabajo humano) y simplificar haciendo que las partes del sistema funcionen bien juntas. Una ventaja de las redes no localizadas, no de propiedad central y administradas (federaciones) es que distribuyen el volumen de trabajo humano y el costo, y pueden proporcionar cierta tolerancia de falla adicional. La solución que propongo a continuación funciona bien para todas las topografías de rejilla, racimo y federación.
La idea básica de diseñar un sistema escalable es identificar los posibles cuellos de botella y luego diseñar el sistema para que partes del sistema puedan ser replicadas según sea necesario para aliviar los cuellos de botella. Idealmente, cada parte replicada aumenta la capacidad de esa parte del sistema linealmente (eficiencia del escalado) . El sistema no es escalable a menos que haya una solución escalable para cada cuello de botella. Escalabilidad es diferente de la eficiencia (lo rápido que se puede hacer una tarea: eficiencia de las partes) . La escalabilidad permite que el sistema crezca para manejar cualquier nivel de demanda. Eficiencia (de escalada y de las partes) determina cuántos servidores, etc., serán necesarios para satisfacer un determinado nivel de demanda. La eficiencia es muy importante, pero siempre tiene límites. La escalabilidad es la única solución práctica para construir un sistema que pueda manejar muy bien. uso pesado. Idealmente, el sistema será escalable y eficiente.
Objetivos
Los objetivos de este diseño son:
- Para hacer una arquitectura escalable (uno que es fácilmente extensible replicando cualquier parte que se vuelve sobrecargado) . Realizar un sistema eficiente que maximice la disponibilidad y el rendimiento de los datos dados los recursos informáticos disponibles. (El costo es casi siempre un problema.)
- Para equilibrar las capacidades de las partes del sistema de manera que una parte del sistema no abrumará otra parte.
- Para hacer una arquitectura sencilla para que el sistema sea fácil de configurar y administrar.
- Para hacer una arquitectura que funciona bien con todas las topografías de la red.
- Hacer un sistema que falla con gracia y de forma limitada si alguna parte se vuelve sobrecargada. (El tiempo necesario para copiar grandes conjuntos de datos siempre limitará la capacidad del sistema para hacer frente a los aumentos repentinos de la demanda de un conjunto de datos específico.)
- (Si es posible) Para hacer una arquitectura que no esté ligada a ninguna cloud computing servicios u otros servicios externos (porque no los necesita) .
Recomendaciones
Nuestras recomendaciones son
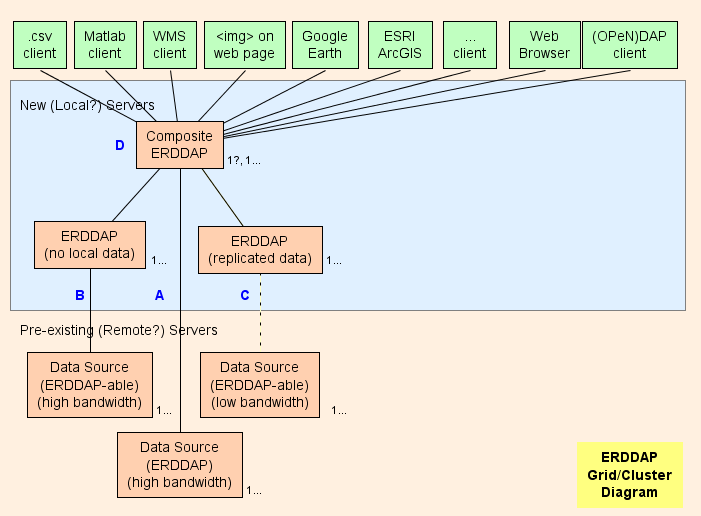
- Básicamente, sugiero establecer un Composite ERDDAP™ ( D en el diagrama) , que es un regular ERDDAP™ excepto que solo sirve datos de otros ERDDAP s. La arquitectura de la red está diseñada para cambiar tanto trabajo como sea posible (Uso de CPU, uso de memoria, uso de ancho de banda) del Composite ERDDAP™ al otro ERDDAP s.
- ERDDAP™ tiene dos tipos especiales de conjunto de datos, EDDGrid FromErddap y EDDTableDeErddap , que se refieren a datasets on other ERDDAP s.
- Cuando el composite ERDDAP™ recibe una solicitud de datos o imágenes de estos conjuntos de datos, el composite ERDDAP™ redirecciona la solicitud de datos al otro ERDDAP™ servidor. El resultado es:
- Esto es muy eficiente (CPU, memoria y ancho de banda) , porque de otro modo
- El compuesto ERDDAP™ tiene que enviar la solicitud de datos a la otra ERDDAP .
- El otro ERDDAP™ tiene que conseguir los datos, reformarlo, y transmitir los datos al composite ERDDAP .
- El compuesto ERDDAP™ tiene que recibir los datos (usando ancho de banda extra) , reformat it (usando tiempo extra de CPU y memoria) , y transmitir los datos al usuario (usando ancho de banda extra) . Dirigiendo la solicitud de datos y permitiendo al otro ERDDAP™ para enviar la respuesta directamente al usuario, el composite ERDDAP™ gasta esencialmente no CPU tiempo, memoria o ancho de banda en solicitudes de datos.
- La redireccion es transparente para el usuario independientemente del software cliente (un navegador o cualquier otro software o herramienta de línea de comando) .
- Esto es muy eficiente (CPU, memoria y ancho de banda) , porque de otro modo
Piezas de rejilla
A : Para cada fuente de datos remota que tenga un ancho de banda alto OPeNDAP servidor, puede conectarse directamente al servidor remoto. Si el servidor remoto es un ERDDAP™ , uso EDDGrid FromErddap o EDDTable ERDDAP para servir los datos en el Composite ERDDAP . Si el servidor remoto es otro tipo de DAP servidor, por ejemplo, THREDDS, Hyrax , o GrADS, uso EDDGrid FromDap.
B Por todos ERDDAP - Fuente de datos (a data source from which ERDDAP puede leer datos) que tiene un servidor de ancho de banda alta, establecer otro ERDDAP™ en la red que es responsable de servir los datos de esta fuente de datos.
- Si varios de esos ERDDAP s no están recibiendo muchas solicitudes de datos, usted puede consolidarlos en uno ERDDAP .
- Si ERDDAP™ dedicado a obtener datos de una fuente remota está recibiendo demasiadas peticiones, hay una tentación de añadir más ERDDAP s para acceder a la fuente de datos remota. En casos especiales esto puede tener sentido, pero es más probable que esto abrumará a la fuente remota de datos (que es auto-defetador) y también evitar que otros usuarios accedan a la fuente remota de datos (que no es agradable) . En tal caso, considere la posibilidad de establecer otro ERDDAP™ para servir ese conjunto de datos y copiar el conjunto de datos en ese ERDDAP Es disco duro (ver C ) , quizás con EDDGrid Copiado y/o EDDTableCopy .
- B Los servidores deben ser accesibles públicamente.
C Por todos ERDDAP - fuente de datos que tiene un servidor de ancho de banda baja (o es un servicio lento por otras razones) , considerar la creación de otro ERDDAP™ y almacenar una copia del conjunto de datos en ese ERDDAP 's discos duros, quizás con EDDGrid Copiado y/o EDDTableCopy . Si varios de esos ERDDAP s no están recibiendo muchas solicitudes de datos, usted puede consolidarlos en uno ERDDAP . C Los servidores deben ser accesibles públicamente.
Compuesto ERDDAP
D : El compuesto ERDDAP™ es un regular ERDDAP™ excepto que solo sirve datos de otros ERDDAP s.
- Porque el composite ERDDAP™ tiene información en memoria sobre todos los conjuntos de datos, puede responder rápidamente a las solicitudes de listas de conjuntos de datos (búsquedas completas de texto, búsquedas de categoría, lista de todos los conjuntos de datos) , y solicitudes para el formulario de acceso de datos de un conjunto de datos individual, hacer un formulario de gráfico, o WMS info página. Estas son todas pequeñas, generadas dinámicamente, páginas HTML basadas en información que se mantiene en memoria. Así que las respuestas son muy rápidas.
- Debido a que las solicitudes de datos reales se redireccionan rápidamente al otro ERDDAP s, el compuesto ERDDAP™ puede responder rápidamente a solicitudes de datos reales sin utilizar ningún tiempo de CPU, memoria o ancho de banda.
- Al cambiar tanto trabajo como sea posible (CPU, memoria, ancho de banda) del Composite ERDDAP™ al otro ERDDAP s, el compuesto ERDDAP™ puede parecer servir datos de todos los conjuntos de datos y aún así mantenerse al día con un gran número de solicitudes de datos de un gran número de usuarios.
- Las pruebas preliminares indican que el compuesto ERDDAP™ puede responder a la mayoría de las solicitudes en ~1ms de tiempo CPU, o 1000 solicitudes/segundo. Así que un procesador de 8 núcleos debe ser capaz de responder a unas 8000 solicitudes/segundo. Aunque es posible imaginar ráfagas de actividad superior que causarían desaceleraciones, eso es mucho rendimiento. Es probable que el ancho de banda del centro de datos sea el cuello de botella mucho antes de la composición ERDDAP™ se convierte en el cuello de botella.
Max actualizado (tiempo) ?
El EDDGrid /TablaDeErddap en el composite ERDDAP™ sólo cambia su información almacenada sobre cada conjunto de datos fuente cuando el conjunto de datos de la fuente es "reload"ed y algunos cambios de metadatos (por ejemplo, la variable de tiempo actual\_range ) , generando así una notificación de suscripción. Si el conjunto de datos fuente tiene datos que cambian con frecuencia (por ejemplo, nuevos datos cada segundo) y utiliza el "actualizar" sistema para notar cambios frecuentes en los datos subyacentes, EDDGrid /TablaDeErddap no se notificará acerca de estos cambios frecuentes hasta el siguiente conjunto de datos "recargar", por lo que el EDDGrid /TablaDeErddap no será perfectamente actualizado. Puede minimizar este problema cambiando el conjunto de datos fuente<reload EveryNMinutes bulbgt; a un valor más pequeño (¿60?) para que haya más notificaciones de suscripción para indicar EDDGrid /TablaDeErddap para actualizar su información sobre el conjunto de datos fuente.
O, si su sistema de gestión de datos sabe cuándo el conjunto de datos fuente tiene nuevos datos (por ejemplo, a través de un script que copia un archivo de datos) , y si eso no es súper frecuente (por ejemplo, cada 5 minutos o menos frecuente) , hay una mejor solución:
- No uso<Actualizar EveryNMillis frecuentemente; mantener el conjunto de datos fuente actualizado.
- Establecer el conjunto de datos fuente<reload EveryNMinutes igualesgt; a un número mayor (¿1440?) .
- Que el script contacte con el conjunto de datos fuente Bandera URL justo después de que copia un nuevo archivo de datos en su lugar. Esto llevará a que el conjunto de datos fuente sea perfectamente actualizado y que genere una notificación de suscripción, que se enviará a la EDDGrid /TablaDesde el conjunto de datos de Eddap. Eso conducirá a la EDDGrid /TablaDeErddap dataset para estar perfectamente actualizado (bien, dentro de 5 segundos de nuevos datos añadiendo) . Y todo lo que se hará eficientemente (sin recargas innecesarias de conjunto de datos) .
Composite múltiple ERDDAP s
- En casos muy extremos, o para la tolerancia a la falla, es posible que desee configurar más de un compuesto ERDDAP . Es probable que otras partes del sistema (notablemente, el ancho de banda del centro de datos) se convertirá en un problema mucho antes de la composición ERDDAP™ se convierte en un cuello de botella. Así que la solución es probablemente establecer centros de datos adicionales, geográficamente diversos, (espejos) , cada uno con un compuesto ERDDAP™ y servidores con ERDDAP s y (al menos) copias de espejo de los conjuntos de datos que están en alta demanda. Tal configuración también proporciona tolerancia a la falla y copia de seguridad de datos (mediante copia) . En este caso, es mejor si el compuesto ERDDAP s tienen diferentes URLs.
Si realmente quieres todo el composite ERDDAP s para tener la misma URL, utilizar un sistema de extremo frontal que asigna a un usuario dado a sólo uno de los compuestos ERDDAP s (basado en la dirección IP) , para que todas las solicitudes del usuario vayan a una de las composiciones ERDDAP s. Hay dos razones:
- Cuando se recarga un conjunto de datos subyacente y los metadatos cambian (por ejemplo, un nuevo archivo de datos en un conjunto de datos redondeado causa la variable de tiempo actual\_range cambio) , el compuesto ERDDAP s estará temporalmente fuera de sincronía, pero con eventual coherencia . Normalmente, volverán a sentarse en 5 segundos, pero a veces será más largo. Si un usuario hace un sistema automatizado que se basa en ERDDAP™ suscripciones que desencadena acciones, los breves problemas de sincronización serán significativos.
- El 2+ composite ERDDAP s cada uno mantiene su propio conjunto de suscripciones (debido al problema de sincronía descrito anteriormente) .
Así que un usuario dado debe ser dirigido a sólo uno de los compuestos ERDDAP s para evitar estos problemas. Si uno de los compuestos ERDDAP s va abajo, el sistema frontal puede redirigir que ERDDAP 's usuarios a otro ERDDAP™ Eso es todo. Sin embargo, si es un problema de capacidad que causa el primer compuesto ERDDAP™ fracasar (¿Un usuario demasiado celoso? a denegación de servicio ?) , esto hace muy probable que redireccionar a sus usuarios a otros compuestos ERDDAP s causará una Fallo en cascada . Así, la configuración más robusta es tener compuesto ERDDAP s con diferentes URLs.
O, quizás mejor, configurar múltiples compuestos ERDDAP sin equilibrio de carga. En este caso, usted debe hacer un punto de dar cada uno de los ERDDAP s un nombre / identidad diferente y si es posible establecerlos en diferentes partes del mundo (e.g., different AWS regions) , por ejemplo, ERD Este, ERD \_US\_West, ERD \_IE, ERD \_FR, ERD \_IT, para que los usuarios conscientemente, trabajen repetidamente con un ERDDAP .
- \[ Para un diseño fascinante de un sistema de alto rendimiento que funciona en un servidor, vea esto descripción detallada de Mailinator . \]
Datasets in Very High Demand
En el caso realmente inusual que uno de los A , B o C ERDDAP s no puede mantenerse al día con las peticiones debido a limitaciones de ancho de banda o disco duro, tiene sentido copiar los datos (otra vez) en otro servidor+hard Drive+ ERDDAP , quizás con EDDGrid Copiado y/o EDDTableCopy . Aunque puede parecer ideal tener el conjunto de datos original y el conjunto de datos copiado aparecen sin problemas como un conjunto de datos en el composite ERDDAP™ , esto es difícil porque los dos conjuntos de datos estarán en estados ligeramente diferentes en diferentes momentos (notablemente, después de que el original obtenga nuevos datos, pero antes de que el conjunto de datos copiado obtenga su copia) . Por lo tanto, recomiendo que los conjuntos de datos reciban títulos ligeramente diferentes (Por ejemplo, "... (#1) "y "... (#2) ", o tal vez " (espejo n ) "o" (servidor n ) ") y aparecen como conjuntos de datos separados en el composite ERDDAP . Los usuarios se utilizan para ver listas de Sitios de espejo en sitios populares de descarga de archivos, por lo que esto no debe sorprender o decepcionarlos. Debido a limitaciones de ancho de banda en un sitio dado, puede tener sentido tener el espejo situado en otro sitio. Si la copia del espejo está en un centro de datos diferente, accedido justo por la composición del centro de datos ERDDAP™ , los diferentes títulos (por ejemplo, "mirante #1) No son necesarios.
RAIDs versus discos duros regulares
Si un conjunto de datos grande o un grupo de conjuntos de datos no se utilizan considerablemente, puede tener sentido almacenar los datos en un RAID ya que ofrece tolerancia a la falla y ya que no necesita la potencia de procesamiento o ancho de banda de otro servidor. Pero si un conjunto de datos es muy utilizado, puede tener más sentido copiar los datos en otro servidor + ERDDAP™ + disco duro (similar a lo que Google hace ) en lugar de utilizar un servidor y un RAID para almacenar múltiples conjuntos de datos desde que se puede utilizar tanto server+hardDrive+ ERDDAP s en la cuadrícula hasta que uno de ellos falla.
Fallos
¿Qué pasa si...
- Hay una explosión de solicitudes para un conjunto de datos (por ejemplo, todos los estudiantes de una clase solicitan simultáneamente datos similares) ? Sólo el ERDDAP™ servir ese conjunto de datos será abrumado y desacelerado o solicitudes de rechazo. El compuesto ERDDAP™ y otros ERDDAP No se verá afectado. Puesto que el factor limitante para un conjunto de datos dado dentro del sistema es el disco duro con los datos (no ERDDAP ) , la única solución (no inmediata) es hacer una copia del conjunto de datos en un servidor diferente+hardDrive+ ERDDAP .
- An A , B o C ERDDAP™ fallas (por ejemplo, fallo del disco duro) ? Sólo el conjunto de datos (s) servido por el ERDDAP™ se ven afectados. Si el conjunto de datos (s) se refleja en otro servidor+hardDrive+ ERDDAP , el efecto es mínimo. Si el problema es un fallo en el disco duro en un nivel 5 o 6 RAID, simplemente reemplaza la unidad y tiene el RAID reconstruir los datos en la unidad.
- El compuesto ERDDAP™ ¿ falla? Si quieres hacer un sistema con mucho alta disponibilidad , puedes configurar múltiple compuesto ERDDAP s (como se examinó anteriormente) , usando algo como NGINX o Traefik para manejar el equilibrio de carga. Note que un determinado composite ERDDAP™ puede manejar un gran número de solicitudes de un gran número de usuarios porque solicitudes de metadatos son pequeñas y son manejadas por información que está en memoria, y Solicitudes de datos (que puede ser grande) son redirigidos al niño ERDDAP s.
Simple, escalable
Este sistema es fácil de configurar y administrar, y fácilmente extensible cuando cualquier parte de él se vuelve sobrecargada. Las únicas limitaciones reales para un centro de datos dado son el ancho de banda del centro de datos y el costo del sistema.
Ancho de banda
Observe el ancho de banda aproximado de componentes comúnmente utilizados del sistema:
| Componente | ancho de banda aproximado (GBytes/s) | | -... | -... | | DDR memoria | 2.5 | | Unidad SSD | 1 | | SATA disco duro | 0.3 | | Gigabit Ethernet | 0.1 | | OC-12 | 0,06 | | OC-3 | 0,015 | | T1 | 0,0002 |
Entonces, un disco duro SATA (0,3GB/s) en un servidor con uno ERDDAP™ puede probablemente saturar un Gigabit Ethernet LAN (0.1GB/s) . Y un Gigabit Ethernet LAN (0.1GB/s) puede saturar probablemente una conexión de Internet OC-12 (0,06GB/s) . Y al menos una fuente enumera líneas OC-12 que cuestan alrededor de 100.000 dólares al mes. (Sí, estos cálculos se basan en empujar el sistema a sus límites, lo que no es bueno porque conduce a respuestas muy lentas. Pero estos cálculos son útiles para la planificación y para equilibrar partes del sistema.) Claramente, una conexión de Internet convenientemente rápida para su centro de datos es por lejos la parte más cara del sistema. Usted puede fácilmente y relativamente barato construir una red con una docena de servidores que ejecutan una docena ERDDAP s que es capaz de bombear muchos datos rápidamente, pero una conexión de Internet convenientemente rápida será muy, muy caro. Las soluciones parciales son:
- Alentar a los clientes a solicitar subconjuntos de los datos si eso es todo lo que se necesita. Si el cliente sólo necesita datos para una pequeña región o una resolución inferior, es lo que debe solicitar. Subsetting es un enfoque central de los protocolos ERDDAP™ soportes para solicitar datos.
- Anime la transmisión de datos comprimidos. ERDDAP™ compresas una transmisión de datos si encuentra "accept-encoding" en el HTTP GET solicitar encabezado. Todos los navegadores web utilizan "acept-encoding" y descomprimen automáticamente la respuesta. Otros clientes (por ejemplo, programas informáticos) tiene que usarlo explícitamente.
- Coloca tus servidores en un ISP u otro sitio que ofrezca costos de ancho de banda relativamente menos costosos.
- Desactivar los servidores con los ERDDAP s a diferentes instituciones para que los costos estén dispersos. Entonces puedes unir tu composite ERDDAP™ a sus ERDDAP s.
Note que Cloud Computing y los servicios de alojamiento web ofrecen todo el ancho de banda de Internet que usted necesita, pero no solucione el problema de precios.
Para obtener información general sobre el diseño de sistemas escalables, de alta capacidad, tolerantes a fallos, véase el libro de Michael T. Nygard Liberarlo .
Como Legos
Los diseñadores de software a menudo tratan de utilizar el bien patrones de diseño de software para resolver problemas. Los buenos patrones son buenos porque encapsulan buenas, fáciles de crear y trabajar con soluciones de uso general que conducen a sistemas con buenas propiedades. Los nombres de los patrones no están estandarizados, así que llamaré al patrón que ERDDAP™ usa el Patrón de Lego. Cada Lego (cada uno ERDDAP ) es un simple, pequeño, estándar, independiente, ladrillo (servidor de datos) con una interfaz definida que le permite estar vinculada a otros legos ( ERDDAP s) . Las partes de ERDDAP™ que componen este sistema son: los sistemas de suscripción y flagURL (que permite la comunicación entre ERDDAP s) , el EDD... FromErddap sistema de redireccion, y el sistema de RESTful solicitudes de datos que pueden generar usuarios u otros ERDDAP s. Así, dado dos o más legos ( ERDDAP s) , usted puede crear un gran número de formas diferentes (topologías de red ERDDAP s) . Claro, el diseño y las características de ERDDAP™ podría haber sido hecho diferente, no como Lego, tal vez sólo para habilitar y optimizar una topología específica. Pero sentimos que ERDDAP 's Lego-like design ofrece una buena solución general que permite cualquier ERDDAP™ administrador (o grupo de administradores) crear todo tipo de topologías federación diferentes. Por ejemplo, una sola organización podría establecer tres (o más) ERDDAP s como se muestra en ERDDAP™ Diagrama de agarre/clase arriba . O un grupo distribuido (¿IOOS? CoastWatch? ¿NCEI? ¿NWS? NOAA ? ¿SGA? DataONE? ¿Neon? ¿LTER? OOI? ¿BoDC? ¿OnC? ¿JRC? ¿OMM?) puede configurar uno ERDDAP™ en cada pequeño puesto (para que los datos puedan permanecer cerca de la fuente) y luego establecer un composite ERDDAP™ en la oficina central con datasets virtuales (que son siempre perfectamente actualizados) de cada uno de los pequeños puestos ERDDAP s. De hecho, todo el mundo ERDDAP s, instalado en varias instituciones de todo el mundo, que obtienen datos de otros ERDDAP s y/o proporcionar datos a otros ERDDAP s, formar una red gigante de ERDDAP s. ¿Qué tan genial es eso? Así que, como con Lego, las posibilidades son infinitas. Por eso es un buen patrón. Por eso es un buen diseño para ERDDAP .
Diferentes tipos de solicitudes
Una de las complicaciones en la vida real de esta discusión de topologías del servidor de datos es que hay diferentes tipos de solicitudes y diferentes maneras de optimizar para los diferentes tipos de solicitudes. Esto es sobre todo una cuestión separada. (Qué rápido puede ser ERDDAP™ con los datos responder a la solicitud de datos?) de la discusión topológica (que trata de las relaciones entre servidores de datos y que servidor tiene los datos reales) . ERDDAP™ , por supuesto, trata de tratar con todo tipo de solicitudes eficientemente, pero maneja algo mejor que otros.
- Muchas solicitudes son sencillas. Por ejemplo: ¿Cuáles son los metadatos para este conjunto de datos? O: ¿Cuáles son los valores de la dimensión del tiempo para este conjunto de datos redondeados? ERDDAP™ está diseñado para manejar esto lo más rápido posible (generalmente en<=2 ms) manteniendo esta información en memoria.
- Algunas solicitudes son moderadamente difíciles. Por ejemplo: Dame este subconjunto de un conjunto de datos (que está en un archivo de datos) . Estas solicitudes se pueden manejar con relativa rapidez porque no son tan difíciles.
- Algunas solicitudes son difíciles y por lo tanto consumen mucho tiempo. Por ejemplo: Dame este subconjunto de un conjunto de datos (que puede estar en cualquiera de los archivos de datos de 10.000+, o puede ser de archivos de datos comprimidos que cada uno toma 10 segundos para descomprimir) . ERDDAP™ v2.0 introdujo algunas nuevas formas más rápidas de hacer frente a estas solicitudes, en particular permitiendo que el hilo de manipulación de solicitudes desperdiciara varios hilos de trabajadores que abordan diferentes subconjuntos de la solicitud. Pero hay otro enfoque de este problema que ERDDAP™ no soporta todavía: subconjuntos de los archivos de datos para un conjunto de datos dado podrían almacenarse y analizarse en computadoras separadas, y luego los resultados combinados en el servidor original. Este enfoque se denomina MapReduce y es ejemplar por Hadoop , el primero (?) open-source MapReduce programa, basado en ideas de un papel de Google. (Si necesita MapReducir in ERDDAP , por favor envíe una solicitud de correo electrónico erd.data at noaa.gov .) Google's BigQuery es interesante porque parece ser una implementación de MapReduce aplicado a los conjuntos de datos tabulares subsetting, que es uno de los ERDDAP 's objetivos principales. Es probable que pueda crear un ERDDAP™ dataset desde un conjunto de datos BigQuery EDDTableDesde la base de datos porque BigQuery se puede acceder a través de una interfaz JDBC.
Estas son mis opiniones.
Sí, los cálculos son simplistas (y ahora ligeramente fechada) Pero creo que las conclusiones son correctas. ¿Usé lógica defectuosa o cometí un error en mis cálculos? Si es así, la culpa es mía sola. Por favor envíe un correo electrónico con la corrección erd dot data at noaa dot gov .
Cloud Computing
Varias empresas ofrecen servicios de informática en la nube (por ejemplo, Amazon Web Services y Google Cloud Platform ) . Web hosting companies han ofrecido servicios más sencillos desde mediados de los años 90, pero los servicios de "cloud" han ampliado considerablemente la flexibilidad de los sistemas y la gama de servicios ofrecidos. Desde ERDDAP™ sólo consta de ERDDAP s and since ERDDAP s Java aplicaciones web que pueden ejecutarse en Tomcat (el servidor de aplicaciones más común) u otros servidores de aplicaciones, debe ser relativamente fácil configurar un ERDDAP™ cuadrícula en un servicio de nube o sitio de alojamiento web. Las ventajas de estos servicios son:
- Ofrecen acceso a conexiones de Internet de ancho de banda muy alta. Esto solo puede justificar el uso de estos servicios.
- Sólo cobran por los servicios que utiliza. Por ejemplo, tiene acceso a una conexión a Internet de ancho de banda muy alta, pero sólo paga los datos reales transferidos. Eso te permite construir un sistema que rara vez se abruma (incluso a la demanda máxima) , sin tener que pagar por la capacidad que rara vez se utiliza.
- Son fácilmente extensibles. Puede cambiar tipos de servidor o añadir tantos servidores o tanto almacenamiento como desee, en menos de un minuto. Esto solo puede justificar el uso de estos servicios.
- Le liberan de muchos de los deberes administrativos de ejecutar los servidores y redes. Esto solo puede justificar el uso de estos servicios.
Las desventajas de estos servicios son:
- Ellos cobran por sus servicios, a veces mucho (en términos absolutos; no es que no sea un buen valor) . Los precios que figuran aquí son para Amazon EC2 . Estos precios (en junio de 2015) bajará.
En el pasado, los precios eran más altos, pero los archivos de datos y el número de solicitudes eran menores.
En el futuro, los precios serán más bajos, pero los archivos de datos y el número de solicitudes serán mayores.
Así que los detalles cambian, pero la situación permanece relativamente constante.
Y no es que el servicio sea sobrevalorado, es que estamos usando y comprando mucho del servicio.
- Transferencia de datos — Las transferencias de datos al sistema ahora son gratuitas (¡Sí!) . Las transferencias de datos fuera del sistema son $0.09/GB. Un disco duro SATA (0,3GB/s) en un servidor con uno ERDDAP™ puede probablemente saturar un Gigabit Ethernet LAN (0.1GB/s) . Un Gigabit Ethernet LAN (0.1GB/s) puede saturar probablemente una conexión de Internet OC-12 (0,06GB/s) . Si una conexión OC-12 puede transmitir ~150.000 GB/mes, los costos de transferencia de datos podrían ser de hasta 150.000 GB @ $0.09/GB = $13,500/mes, que es un costo significativo. Claramente, si tienes una docena de trabajo duro ERDDAP s en un servicio de nube, sus cuotas mensuales de Transferencia de Datos podrían ser sustanciales (hasta 162.000 dólares/mes) . (Una vez más, no es que el servicio sea sobrevalorado, es que estamos usando y comprando mucho del servicio.)
- Almacenamiento de datos — Amazon cobra $50/mes por TB. (Compare eso para comprar una unidad de empresa 4TB por ~$50/TB, aunque el RAID para ponerlo en y los costos administrativos añaden al costo total.) Así que si necesita almacenar muchos datos en la nube, podría ser bastante caro (por ejemplo, 100TB costaría 5.000 dólares al mes) . Pero a menos que tenga una gran cantidad de datos, este es un tema más pequeño que los costos de transferencia de ancho de banda/datos. (Una vez más, no es que el servicio sea sobrevalorado, es que estamos usando y comprando mucho del servicio.)
Subsetting
- El problema de subsetting: La única manera de distribuir eficientemente datos de los archivos de datos es tener el programa que está distribuyendo los datos (por ejemplo, ERDDAP ) se ejecuta en un servidor que tiene los datos almacenados en un disco duro local (o acceso similarmente rápido a un SAN o RAID local) . Los sistemas de archivos locales permiten ERDDAP™ (y bibliotecas subyacentes, como netcdf-java) para solicitar rangos de byte específicos de los archivos y obtener respuestas muy rápidamente. Muchos tipos de solicitudes de datos ERDDAP™ al archivo (notablemente las solicitudes de datos redondeados donde el valor de zancada es 1) no se puede hacer eficientemente si el programa tiene que solicitar todo el archivo o grandes trozos de un archivo de un no local (por lo tanto más lento) sistema de almacenamiento de datos y luego extraer un subconjunto. Si la configuración de la nube no da ERDDAP™ acceso rápido a los rangos byte de los archivos (tan rápido como con archivos locales) , ERDDAP 's acceso a los datos será un cuello de botella severo y negar otros beneficios de usar un servicio en la nube.
Datos hospedados
Una alternativa al análisis de los beneficios de los gastos antes mencionado (que se basa en el propietario de datos (por ejemplo, NOAA ) pagar sus datos para ser almacenados en la nube) llegó alrededor de 2012, cuando Amazon (y en menor medida, algunos otros proveedores de nube) comenzó a albergar algunos conjuntos de datos en su nube (AWS S3) gratis (presumiblemente con la esperanza de que puedan recuperar sus costos si los usuarios alquilan instancias informáticas AWS EC2 para trabajar con esos datos) . Claramente, esto hace que la informática de la nube sea mucho más rentable, porque el tiempo y el costo subiendo los datos y hospedándolo ahora son cero. Con ERDDAP™ v2.0, hay nuevas características para facilitar el funcionamiento ERDDAP en una nube:
- Ahora, un EDDGrid DesdeFiles o EDDTableDesde el conjunto de datos de Files se pueden crear desde archivos de datos remotos y accesibles a través de Internet (por ejemplo, cubos AWS S3) utilizando el<cacheDesde el punto de vista; y<cacheSize GB de opciones. ERDDAP™ mantendrá un caché local de los archivos de datos más utilizados recientemente.
- Ahora, si los archivos fuente EDDTableDesdeFiles son comprimidos (por ejemplo, .tgz ) , ERDDAP™ automáticamente los descomprimirá cuando los lea.
- Ahora, el ERDDAP™ hilo respondiendo a una petición dada, despachará los hilos de los trabajadores para trabajar en subsecciones de la solicitud si utiliza el<nTecleo; opciones. Esta paralelización debería permitir respuestas más rápidas a solicitudes difíciles.
Estos cambios resuelven el problema de AWS S3 que no ofrece almacenamiento local de archivos a nivel de bloques y el (viejo) problema de acceso a datos S3 que tienen un retraso significativo. (Hace años (~2014) , ese lag era significativo, pero ahora es mucho más corto y no tan significativo.) Todo en absoluto, significa que establecer ERDDAP™ en la nube funciona mucho mejor ahora.
Gracias. — Muchas gracias a Matthew Arrott y su grupo en el esfuerzo original de OOI por su trabajo en poner ERDDAP™ en la nube y las discusiones resultantes.
Replicación remota de conjuntos de datos
Hay un problema común relacionado con la discusión anterior de las redes y federaciones de ERDDAP s: réplica remota de conjuntos de datos. El problema básico es: un proveedor de datos mantiene un conjunto de datos que cambia ocasionalmente y un usuario quiere mantener una copia local actualizada de este conjunto de datos (por una variedad de razones) . Claramente, hay un gran número de variaciones de esto. Algunas variaciones son mucho más difíciles de tratar que otras.
- Actualizaciones rápidas Es más difícil mantener el conjunto de datos local actualizado inmediatamente (por ejemplo, dentro de 3 segundos) después de cada cambio a la fuente, en lugar de, por ejemplo, dentro de unas pocas horas.
- Cambios frecuentes Los cambios frecuentes son más difíciles de afrontar que los cambios frecuentes. Por ejemplo, los cambios una vez al día son mucho más fáciles de manejar que los cambios cada 0.1 segundo.
- Cambios pequeños Los pequeños cambios en un archivo fuente son más difíciles de manejar que un archivo completamente nuevo. Esto es especialmente cierto si los pequeños cambios pueden estar en cualquier lugar del archivo. Los pequeños cambios son más difíciles de detectar y hacer difícil aislar los datos que necesitan ser replicados. Los nuevos archivos son fáciles de detectar y eficientes de transferir.
- Intire Dataset Mantener un conjunto completo de datos actualizado es más difícil que mantener datos recientes. Algunos usuarios solo necesitan datos recientes (Por ejemplo, el último día vale la pena) .
- Múltiples copias Mantener múltiples copias remotas en diferentes sitios es más difícil que mantener una copia remota. Este es el problema de escalar.
Obviamente hay un gran número de variaciones de posibles tipos de cambios en el conjunto de datos fuente y de las necesidades y expectativas del usuario. Muchas de las variaciones son muy difíciles de resolver. La mejor solución para una situación a menudo no es la mejor solución para otra situación: todavía no hay una gran solución universal.
Relevant ERDDAP™ Herramientas
ERDDAP™ ofrece varias herramientas que se pueden utilizar como parte de un sistema que busca mantener una copia remota de un conjunto de datos:
- ERDDAP 's RSS (Rich Site Summary?) servicio
ofrece una manera rápida de comprobar si un conjunto de datos en un remoto ERDDAP™ ha cambiado. - ERDDAP 's servicio de suscripción
es más eficiente (que RSS ) acercamiento: enviará inmediatamente un correo electrónico o contactar una URL a cada suscriptor cuando se actualice el conjunto de datos y la actualización resulte en un cambio. Es eficiente ya que sucede lo antes posible y no hay esfuerzo perdido (como con una encuesta RSS servicio) . Los usuarios pueden utilizar otras herramientas (como IFTTT ) para reaccionar a las notificaciones de correo electrónico del sistema de suscripción. Por ejemplo, un usuario puede suscribirse a un conjunto de datos en un remoto ERDDAP™ y utilizar IFTTT para reaccionar a las notificaciones de email de suscripción y activar la actualización del conjunto de datos local. - ERDDAP 's Sistema de bandera
proporciona una manera para un ERDDAP™ administrador para contar un conjunto de datos en su/ella ERDDAP para recargar lo antes posible. La forma URL de una bandera se puede utilizar fácilmente en scripts. La forma URL de una bandera también se puede utilizar como la acción para una suscripción. - ERDDAP 's "files" sistema
puede ofrecer acceso a los archivos fuente para un conjunto de datos dado, incluyendo una lista de directorios de estilo Apache de los archivos (una "Carpeta accesible web") que tiene la URL de descarga de cada archivo, última hora modificada y tamaño. Una desventaja de usar el "files" sistema es que los archivos fuente pueden tener diferentes nombres variables y diferentes metadatos que el conjunto de datos como aparece en ERDDAP . Si un remoto ERDDAP™ dataset ofrece acceso a sus archivos fuente, que abre la posibilidad de la versión de rsync de un hombre pobre: se hace fácil para un sistema local ver qué archivos remotos han cambiado y necesitan ser descargados. (Ver el cacheDesde el aeropuerto opción abajo que puede hacer uso de esto.)
Soluciones
Aunque hay un gran número de variaciones en el problema y un número infinito de posibles soluciones, sólo hay un puñado de enfoques básicos para las soluciones:
Custom, Brute Force Solutions
Una solución obvia es llevar a cabo una solución personalizada, que por lo tanto se optimiza para una situación determinada: hacer un sistema que detecte/identifique qué datos ha cambiado, y envía esa información al usuario para que el usuario pueda solicitar los datos cambiados. Bueno, puedes hacer esto, pero hay desventajas:
- Las soluciones personalizadas son mucho trabajo.
- Las soluciones personalizadas son generalmente tan personalizadas a un conjunto de datos dado y al sistema del usuario dado que no se pueden reutilizar fácilmente.
- Usted debe construir y mantener soluciones personalizadas. (Esa nunca es una buena idea. ¡Siempre es buena idea evitar el trabajo y conseguir que alguien más haga el trabajo!)
Me desaliento de tomar este enfoque porque es casi siempre mejor buscar soluciones generales, construidas y mantenidas por otra persona, que se puede reutilizar fácilmente en situaciones diferentes.
rsync
rsync es la solución existente, impresionantemente buena, de propósito general para mantener una colección de archivos en un ordenador fuente en sincronización en el equipo remoto del usuario. La forma en que funciona es:
- algún evento (por ejemplo, un ERDDAP™ sistema de suscripción) dispara rsync corriendo, (o, un trabajo de cron funciona rsync en momentos específicos todos los días en la computadora del usuario)
- que contactos rsync en el ordenador fuente,
- que calcula una serie de hashes para trozos de cada archivo y transmite esos hashes al rsync del usuario,
- que compara esa información con la información similar para la copia del usuario de los archivos,
- que luego solicita los trozos de archivos que han cambiado.
Considerando todo lo que hace, rsync opera muy rápidamente (por ejemplo, 10 segundos más tiempo de transferencia de datos) y muy eficiente. Hay variaciones de rsync que optimizan para diferentes situaciones (por ejemplo, precalculando y cacheando los hashes de los trozos de cada archivo fuente) .
Las principales debilidades de rsync son: se necesita un poco de esfuerzo para establecer (cuestiones de seguridad) ; hay algunos problemas de escalada; y no es bueno mantener los conjuntos de datos de NRT realmente actualizados (Por ejemplo, es incómodo usar rsync más que cada 5 minutos) . Si usted puede tratar con las debilidades, o si no afectan su situación, rsync es una solución de propósito general excelente que cualquiera puede utilizar ahora mismo para resolver muchos escenarios que implican la replicación remota de conjuntos de datos.
Hay un artículo en el ERDDAP™ To Do lista para intentar añadir soporte para servicios rsync a ERDDAP (probablemente una tarea bastante difícil) , para que cualquier cliente pueda utilizar rsync (o una variante) para mantener una copia actualizada de un conjunto de datos. Si alguien quiere trabajar en esto, por favor email erd.data at noaa.gov .
Hay otros programas que hacen más o menos lo que hace rsync, a veces orientados a la replicación de conjuntos de datos (aunque a menudo a nivel de copia de archivo) , por ejemplo, Unidata 's IDD .
Caché de Url
El cacheDesde Url configuración disponible (empezar con ERDDAP™ v2.0) para todos ERDDAP 's tipos de conjunto de datos que hacen datasets de archivos (básicamente, todas las subclases de EDDGrid DeFiles y EDDTableDeFiles ) . cache FromUrl hace que sea trivial descargar y mantener automáticamente los archivos de datos locales copiandolos de una fuente remota a través del cache De Url. Los archivos remotos pueden estar en una carpeta de acceso web o en una lista de archivos tipo directorio ofrecida por THREDDS, Hyrax , un cubo S3, o ERDDAP 's "files" sistema.
Si la fuente de los archivos remotos es un remoto ERDDAP™ dataset que ofrece los archivos fuente a través del ERDDAP™ "files" sistema, entonces usted puede Suscríbete al conjunto de datos remoto, y utilizar el Bandera URL para su conjunto de datos local como la acción para la suscripción. Luego, cuando el conjunto de datos remoto cambie, se pondrá en contacto con la URL de la bandera para su conjunto de datos, que le dirá que vuelva a cargar ASAP, que detectará y descargará los archivos de datos remotos cambiados. Todo esto sucede muy rápidamente (generalmente ~5 segundos más el tiempo necesario para descargar los archivos cambiados) . Este enfoque funciona muy bien si los cambios de conjunto de datos fuente son nuevos archivos que se agregan periódicamente y cuando los archivos existentes nunca cambian. Este enfoque no funciona bien si los datos son frecuentemente utilizados para todos (o la mayoría) de los archivos de datos fuente existentes, porque entonces su conjunto de datos local se descarga con frecuencia todo el conjunto de datos remoto. (Aquí es donde se necesita un enfoque similar al rsync.)
ArchiveADataset
ERDDAP™ 's ArchiveADataset es una buena solución cuando los datos se agregan a un conjunto de datos con frecuencia, pero los datos más antiguos nunca se cambian. Básicamente, un ERDDAP™ administrador puede ejecutar ArchiveADataset (tal vez en un guión, tal vez corre por cron) y especificar un subconjunto de un conjunto de datos que quieren extraer (tal vez en múltiples archivos) y paquete en un .zip o .tgz archivo, para que pueda enviar el archivo a personas o grupos interesados (por ejemplo, NCEI para archivar) o hacerlo disponible para descargar. Por ejemplo, podría ejecutar ArchiveADataset todos los días a las 12:10 am y tener que hacer un .zip de todos los datos de 12:00 am el día anterior hasta las 12:00 am hoy. (O hacer esto semanal, mensual o anual, según sea necesario.) Debido a que el archivo empaquetado se genera fuera de línea, no hay peligro de un timeout o demasiados datos, ya que habría para un estándar ERDDAP™ petición.
ERDDAP™ 's sistema de solicitud estándar
ERDDAP™ 's sistema de solicitud estándar es una buena solución alternativa cuando los datos se agregan a un conjunto de datos con frecuencia, pero los datos más antiguos nunca se cambian. Básicamente, cualquiera puede usar solicitudes estándar para obtener datos para un rango específico de tiempo. Por ejemplo, a las 12:10 am todos los días, usted podría hacer una solicitud para todos los datos desde un conjunto de datos remoto desde las 12:00 am del día anterior hasta las 12:00 am hoy. La limitación (comparado con el enfoque ArchiveADataset) es el riesgo de un timeout o hay demasiados datos para un solo archivo. Puede evitar la limitación haciendo solicitudes más frecuentes para períodos de tiempo más pequeños.
EDDTableDesdeHtpGet
\[ Esta opción aún no existe, pero parece posible construir en un futuro cercano. \]
El nuevo EDDTableDesdeHtpGet Tipo de conjunto de datos ERDDAP™ v2.0 permite visualizar otra solución. Los archivos subyacentes mantenidos por este tipo de conjunto de datos son esencialmente archivos de registro que registran cambios en el conjunto de datos. Debe ser posible construir un sistema que mantenga periódicamente un conjunto de datos local (o basado en un gatillo) solicitando todos los cambios que se han realizado en el conjunto de datos remoto desde esa última solicitud. Eso debería ser tan eficiente (o más) que rsync y manejaría muchos escenarios difíciles, pero sólo funcionaría si los conjuntos de datos remotos y locales son EDDTableDesdeHttpGet conjuntos de datos.
Si alguien quiere trabajar en esto, por favor contacte erd.data at noaa.gov .
Datos distribuidos
Ninguna de las soluciones anteriores hace un gran trabajo de resolver las duras variaciones del problema porque la replicación de tiempo casi real (NRT) datasets es muy duro, en parte debido a todos los escenarios posibles.
Hay una gran solución: ni siquiera trate de replicar los datos. En su lugar, utilice la única fuente autorizada (un conjunto de datos en uno ERDDAP ) , mantenido por el proveedor de datos (por ejemplo, una oficina regional) . Todos los usuarios que quieren datos de ese conjunto de datos siempre lo obtienen de la fuente. Por ejemplo, las aplicaciones basadas en el navegador obtienen los datos de una solicitud basada en URL, por lo que no debe importar que la solicitud sea a la fuente original en un servidor remoto (no es el mismo servidor que alberga el ESM) . Mucha gente ha estado abogando por este enfoque de Datos Distribuidos durante mucho tiempo (por ejemplo, Roy Mendelssohn durante los últimos 20 años) . ERDDAP 's grid/federation model (el 80% superior de este documento) se basa en este enfoque. Esta solución es como una espada a un nudo gordiano — todo el problema desaparece.
- Esta solución es impresionantemente simple.
- Esta solución es impresionantemente eficiente ya que no se hace ningún trabajo para mantener un conjunto de datos replicado (s) actualizado.
- Los usuarios pueden obtener los últimos datos en cualquier momento (por ejemplo, con una latencia de sólo ~0.5 segundos) .
- Escala bastante bien y hay maneras de mejorar el escalado. (Vea la discusión en el 80% superior de este documento.)
No, esta no es una solución para todas las situaciones posibles, pero es una gran solución para la gran mayoría. Si hay problemas/debilidades con esta solución en ciertas situaciones, a menudo vale la pena trabajar para resolver esos problemas o vivir con esas debilidades debido a las ventajas impresionantes de esta solución. Si/cuando esta solución es realmente inaceptable para una situación determinada, por ejemplo, cuando realmente debe tener una copia local de los datos, entonces considere las otras soluciones discutidas anteriormente.
Conclusión
Aunque no hay una solución simple y sencilla que resuelve perfectamente todos los problemas en todos los escenarios (como rsync y datos distribuidos casi son) , espero que haya suficientes herramientas y opciones para que pueda encontrar una solución aceptable para su situación particular.