Skaling
ERDDAP™ - Heavy Loads, Grids, Klaszterek, Föderációk és Cloud Computing
ERDDAP :
ERDDAP™ egy webes alkalmazás és egy webes szolgáltatás, amely összegyűjti a különböző helyi és távoli forrásokból származó tudományos adatokat, és egyszerű, következetes módot kínál arra, hogy letöltse az adatokat a közös fájlformátumokban, és grafikákat és térképeket készítsen. Ez a weboldal megvitatja a nehéz kérdésekkel kapcsolatos kérdéseket ERDDAP™ Használja a terheléseket és felfedezi a rendkívül nehéz terhek kezelésének lehetőségeit hálózatokon, klasztereken, szövetségeken és felhőalapú számításon keresztül.
Az eredeti változatot 2009 júniusában írták. Nem voltak jelentős változások. Ez volt a legutóbbi frissített 2019-04-15.
DISCLAIMER
A weboldal tartalma a Bob Simons személyes véleménye, és nem feltétlenül tükrözi a kormány vagy a National Oceanic and Atmospheric Administration ... A számítások egyszerűek, de szerintem a következtetések helyesek. Használtam hibás logikát, vagy hibáztam a számításaimban? Ha igen, a hiba egyedül az enyém. Kérjük, küldjön e-mailt a korrekcióval erd dot data at noaa dot gov ...
Nehéz terhek / korlátok
Nehéz használat esetén egy önálló ERDDAP™ lesz korlátozva (a legkevésbé valószínű) :
Távoli forrás Bandwidth
- Egy távoli adatforrás sávszélessége - Még hatékony kapcsolattal (pl.: OPeNDAP ) hacsak egy távoli adatforrásnak nagyon magas sávszélességű internetkapcsolata van, ERDDAP A válaszokat az fogja korlátozni, hogy milyen gyorsan ERDDAP™ adatokat szerezhet az adatforrásból. A megoldás az adatkészlet másolása onto ERDDAP "A kemény meghajtó, talán EDDGrid Másolás vagy EDDTableCopy ...
ERDDAP Szerver Bandwidth
- Hacsak nem ERDDAP "A szervernek nagyon magas sávszélességű internetkapcsolata van, ERDDAP A válaszokat az fogja korlátozni, hogy milyen gyorsan ERDDAP™ adatokat szerezhet az adatforrásokból, és milyen gyorsan ERDDAP™ visszaadhatja az adatokat az ügyfeleknek. Az egyetlen megoldás, hogy gyorsabb internetkapcsolatot kapjunk.
Memory
- Ha sok egyidejű kérés van, ERDDAP™ memóriából indulhat ki, és ideiglenesen visszautasíthatja az új kérelmeket. ( ERDDAP™ van néhány mechanizmus, hogy elkerülje ezt, és minimalizálja a következményeket, ha ez történik.) Tehát a nagyobb memória a kiszolgálóban jobb. Egy 32 bites kiszolgálón a 4+ GB nagyon jó, 2 GB rendben van, kevésbé ajánlott. Egy 64 bites szerveren szinte teljesen elkerülheti a problémát sok memória megszerzésével. Lásd: \-Xmx és -Xms beállítások Mert ERDDAP /Tomcat. Egy ERDDAP™ Nehéz használat egy számítógépen egy 64 bites kiszolgálóval, 8GB memóriával és -Xmx 4000M-re van beállítva, ha valaha is, a memória korlátozza.
Had Drive Bandwidth
- A szerver merevlemezén tárolt adatokhoz való hozzáférés sokkal gyorsabb, mint a távoli adatokhoz való hozzáférés. Még akkor is, ha ERDDAP™ szerver nagyon magas sávszélességű internetkapcsolattal rendelkezik, lehetséges, hogy a merevlemezen lévő adatokhoz való hozzáférés egy palackneck lesz. A részleges megoldás gyorsabban használható (pl. 10 000 RPM) mágneses merevlemezek vagy SSD meghajtók (ha van értelme költséges) ... Egy másik megoldás az, hogy különböző adatkészleteket tároljon különböző meghajtókon, hogy a kumulatív merevlemez sávszélessége sokkal magasabb legyen.
Túl sok Files Cached
- Túl sok fájl egy Húsvét rendező - ERDDAP™ minden képet lemásol, de csak bizonyos típusú adatkérelmekre szorítja az adatokat. Lehetséges, hogy a cache könyvtár egy adatkészlet, hogy egy nagy számú fájl ideiglenesen. Ez lelassítja a kéréseket, hogy lássa, van-e egy fájl a csészében (Tényleg!) ...<Húsvét Minutes> in setup.xml Hagyja, hogy beállítsa, mennyi ideig lehet egy fájl a cache-ban, mielőtt törlődik. Egy kisebb szám beállítása minimalizálná ezt a problémát.
CPU
- Csak két dolog vesz egy csomó CPU időt:
- NetCDF 4 és HDF Jelenleg 5 támogatja az adatok belső tömörítését. Nagy tömörítés NetCDF 4 / 4 / HDF 5 adatfájl 10 vagy több másodpercig tarthat. (Ez nem egy végrehajtási hiba. Ez a tömörítés jellege.) Tehát több egyidejű kérés az adatkészletekhez a tömörített fájlokban tárolt adatokkal, súlyos törést tehet bármely szerverre. Ha ez problémát jelent, a megoldás az, hogy népszerű adatkészleteket tároljon a nem kompresszált fájlokban, vagy kapjon kiszolgálót egy CPU-val több kukoricával.
- grafikonok készítése (beleértve a térképeket) : durván 0,2 - 1 másodperc grafikonononként. Tehát, ha sok egyidejű egyedi kérés volt a grafikonokra ( WMS Az ügyfelek gyakran 6 egyidejű kérést tesznek!) CPU korlátozás lehet. Amikor több felhasználó fut WMS Az ügyfelek, ez problémát jelent.
Többszörös identikus ERDDAP Load Balancing?
Gyakran felmerül a kérdés: "A nehéz terheléssel foglalkozni, többszörös identikát hozhatok létre ERDDAP S terheléskiegyensúlyozással?” Érdekes kérdés, mert gyorsan eljut a maghoz ERDDAP Tervezés. A gyors válasz "nem". Tudom, hogy csalódást okozó válasz, de van néhány közvetlen oka, és néhány nagyobb alapvető oka annak, hogy miért terveztem ERDDAP™ más megközelítés alkalmazása (egy szövetség ERDDAP s, e dokumentum ömlében leírva) Azt hiszem, ez egy jobb megoldás.
Néhány közvetlen ok, amiért nem tudsz/nem hozhatsz létre több azonosságot ERDDAP S:
- Egy adott ERDDAP™ olvassa el az egyes adatfájlokat, amikor először elérhetővé válik, hogy megtalálja az adatmennyiséget a fájlban. Ezután tárolja ezt az információt indexfájlban. Később, amikor az adatok felhasználói kérelme érkezik, ERDDAP™ használja ezt az indexet, hogy kitalálja, mely fájlokat keres a kért adatokra. Ha több azonos ERDDAP S, mindegyikük ezt az indexálást végezné, ami elpazarolt erőfeszítés. Az alább leírt szövetségi rendszerrel az indexálás csak egyszer történik, az egyik ERDDAP S.
- Bizonyos típusú felhasználói kérések (pl.: .nc , .png, .pdf fájlok) ERDDAP™ meg kell tennie az egész fájlt, mielőtt a válasz elküldhető. Szóval ERDDAP™ gyorsítja ezeket a fájlokat rövid ideig. Ha azonos kérés érkezik (ahogy gyakran teszi, különösen olyan képek esetében, ahol az URL egy weboldalon van beágyazva) , ERDDAP™ újrahasznosíthatja ezt a csésze fájlt. Több azonos rendszerben ERDDAP s, ezek a csípett fájlok nem megosztottak, így mindegyik ERDDAP™ szükségtelenül és szennyesen újrateremteni .nc , .png vagy .pdf fájlok. Az alább leírt szövetségi rendszerrel a fájlokat csak egyszer készítik el, az egyik ERDDAP és újrahasznosított.
- ERDDAP „Az előfizetési rendszert nem kell megosztani többszörösen ERDDAP S. Például, ha a terhelési egyenlegező egy felhasználót küld egy személynek ERDDAP™ és a felhasználó feliratkozik egy adatkészletre, majd a másik ERDDAP S nem lesz tudatában ennek az előfizetésnek. Később, ha a terhelési egyensúlyozó a felhasználót másra küldi ERDDAP™ és kéri az előfizetéseinek listáját, a másikat ERDDAP™ Azt mondják, nincs senki (vezetni őt / ő, hogy egy duplikált előfizetés a másik ERED DAP ) ... Az alább leírt szövetségi rendszerrel az előfizetési rendszert egyszerűen a fő, nyilvános, kompozit kezeli. ERDDAP ...
Igen, minden problémára, tudtam (nagy erőfeszítéssel) mérnök egy megoldás (az információ megosztása a között ERDDAP s) De azt hiszem, Föderáció ERDDAP S megközelítés (e dokumentum tömegében ismertetett) egy sokkal jobb általános megoldás, részben azért, mert más problémákkal foglalkozik, hogy a többszörös-identikus ERDDAP A s-feltöltés-kiegyensúlyozó megközelítés még a világ adatforrásainak decentralizált jellegét sem kezdi el kezelni.
A legjobb, ha elfogadom az egyszerű tényt, hogy nem terveztem ERDDAP™ többszörös azonosnak kell lennie ERDDAP rakománymérlegelővel. Tudatosan terveztem ERDDAP™ jól működni egy szövetségben ERDDAP s, amit hiszem, sok előnye van. Nevezetesen egy szövetség ERDDAP s tökéletesen igazodik az adatközpontok decentralizált, elosztott rendszeréhez, amelyekkel a való világban rendelkezünk. (a különböző IOOS régiókra, vagy a különböző CoastWatch régiókra, vagy a NCEI különböző részeire, vagy a 100 másik adatközpontra. NOAA , vagy a különböző NASA DAAC, vagy az 1000 adatközpontok szerte a világon) ... Ahelyett, hogy elmondanák a világ összes adatközpontját, hogy fel kell hagyniuk erőfeszítéseiket, és az összes adatot központi "adattó tavába" helyezik. (még akkor is, ha lehetséges, ez egy szörnyű ötlet számos okból - lásd a különböző elemzések mutatják a számos előnye a decentralizált rendszerek ) , ERDDAP A design a világgal működik, mint az. Minden adatközpont, amely adatokat termel, továbbra is fenntarthatja, gyógyíthatja és szolgálhatja az adatait (ahogy kellene) És mégis, ERDDAP™ , az adatok azonnal elérhetők egy centralizált ERDDAP , anélkül, hogy szükség lenne az adatok centralizált továbbítására ERDDAP™ vagy az adatok kettős másolatának tárolása. Valójában egy adott adatkészlet egyszerre elérhető egy ERDDAP™ olyan szervezetnél, amely elkészítette és ténylegesen tárolja az adatokat (pl. GoMOOS) , egy ERDDAP™ a szülői szervezetben (IOOS központi) , egy egésztől NOAA ERDDAP™ , egy amerikai-szövetségi kormánytól ERDDAP™ , globális ERDDAP™ (GOOS) , és szakosodott ERDDAP s (pl. egy ERDDAP™ a HAB kutatásának szentelt intézménynél) , minden lényegében azonnal és hatékonyan, mert csak a metadata kerül átadásra ERDDAP S, nem az adatok. Legjobb, a kezdet után ERDDAP™ az eredő szervezetnél, az összes másik ERDDAP S gyorsan felállítható (néhány óra munka) minimális erőforrásokkal (egy olyan kiszolgáló, amely nem igényel semmilyen RAID-t az adattároláshoz, mivel helyben nem tárol adatokat) és így valóban minimális költséggel. Hasonlítsa össze, hogy a központosított adatközpont létrehozásának és fenntartásának költsége egy adattóval, és az igazán masszív, valóban drága, internetkapcsolat szükségessége, plusz a központosított adatközpont részvételi problémája egyetlen hibapont. Számomra, ERDDAP a decentralizált, föderált megközelítés messze, sokkal magasabb rendű.
Olyan helyzetekben, ahol egy adott adatközpontnak többre van szüksége ERDDAP S hogy megfeleljen a nagy keresletnek, ERDDAP "A design teljes mértékben képes megfelelni vagy meghaladni a többszörös-identikus teljesítményét ERDDAP S-A-load-balancer megközelítés. Mindig lehetősége van felállítani több kompozit ERDDAP s (az alábbiakban tárgyalt) Mindegyikük megkapja az összes adatot a többitől ERDDAP S, terheléskiegyensúlyozás nélkül. Ebben az esetben azt javaslom, hogy tegyen egy pontot, hogy mindegyik kompozit ERDDAP más név / személyazonosság, és ha lehetséges, a világ különböző részein hozza létre őket (pl. különböző AWS régiók) pl.: ERD \_US\_East, ERD \_US\_West, ERD \_IE, ERD \_FR, ERD \_IT, hogy a felhasználók tudatosan, ismételten dolgozzanak egy adott ERDDAP A hozzáadott előnyökkel, hogy egyetlen hibapontból eltávolította a kockázatot.
Hálók, klaszterek és szövetségek
Nagyon nehéz használat alatt egyetlen önálló ERDDAP™ befut egy vagy több korlátok A fent felsorolt és még a javasolt megoldások is elégtelenek lesznek. Ilyen helyzetekben, ERDDAP™ olyan tulajdonságokkal rendelkezik, amelyek megkönnyítik a skálázható rácsok felépítését (is úgynevezett klaszterek vagy szövetségek) a ERDDAP s amelyek lehetővé teszik a rendszer kezelését nagyon nehéz használat (pl. egy nagy adatközpont számára) ...
Én használok háló mint általános kifejezés, hogy jelezze egyfajta számítógépes klaszter ahol az összes alkatrész fizikailag nem található egy létesítményben, és lehet, vagy nem lehet központilag beadni. Előnye az összekapcsolt, központi tulajdonú és kezelt hálózatoknak (klaszterek) az, hogy profitálnak a méretgazdaságból (különösen az emberi munkaterhelés) és egyszerűsítse, hogy a rendszer részei jól működjenek együtt. Előnye a nem társult hálózatoknak, nem központilag tulajdonolt és bevezetett hálózatoknak (szövetségek) az, hogy elosztják az emberi munkaterhelést és a költségeket, és további hibatűrést biztosíthatnak. Az alábbi megoldás jól működik minden rács, klaszter és szövetségi topográfiához.
A skálázható rendszer megtervezésének alapvető ötlete az, hogy azonosítsa a potenciális palackneckeket, majd megtervezze a rendszert, hogy a rendszer részei megismételhetők legyenek a palackneckek enyhítéséhez. Ideális esetben minden replikált rész növeli a rendszer ezen részének képességét lineárisan (A skálázás hatékonysága) ... A rendszer nem skálázható, kivéve, ha van egy skálázható megoldás minden palackneck számára. Képesség különbözik a hatékonyságtól (milyen gyorsan elvégezhető egy feladat - az alkatrészek hatékonysága) ... A stabilitás lehetővé teszi, hogy a rendszer növekedjen a kereslet bármilyen szintjének kezelésére. Hatékonyság (skálázás és alkatrészek) meghatározza, hogy hány szerverre, stb. szükség lesz egy adott szintű kereslet kielégítésére. A hatékonyság nagyon fontos, de mindig korlátozza. A stabilitás az egyetlen gyakorlati megoldás egy olyan rendszer létrehozására, amely képes kezelni nagyon nehéz használat. Ideális esetben a rendszer skálázható és hatékony lesz.
Célok
Ennek a tervezésnek a céljai:
- Skálázható architektúra létrehozása (az egyik, amely könnyen kibővíthető bármilyen rész megismétlésével, amely túlterhelté válik) ... Annak érdekében, hogy egy hatékony rendszer, amely maximalizálja a rendelkezésre álló és átvitele az adatok adott a rendelkezésre álló számítási források. (A költség szinte mindig probléma.)
- A rendszer alkatrészeinek képességeinek kiegyensúlyozása érdekében, hogy a rendszer egyik része ne legyen túlterhelt egy másik rész.
- Egy egyszerű architektúra kialakításához, hogy a rendszer könnyen felállítható és adminisztrálható legyen.
- Annak érdekében, hogy egy architektúrát, amely jól működik minden rácsos topográfiával.
- Annak érdekében, hogy egy rendszer, amely meghiúsítja a kegyelmet, és korlátozott módon, ha bármely rész túlterhelt. (A nagy adatkészletek másolásához szükséges idő mindig korlátozza a rendszer azon képességét, hogy hirtelen növekedjen egy adott adatkészlet iránti kereslet.)
- (Ha lehetséges) Hogy egy architektúra, amely nem kötődik semmilyen konkrét felhő számítás szolgáltatás vagy egyéb külső szolgáltatások (mert nem kell nekik) ...
Ajánlások
Ajánlásaink
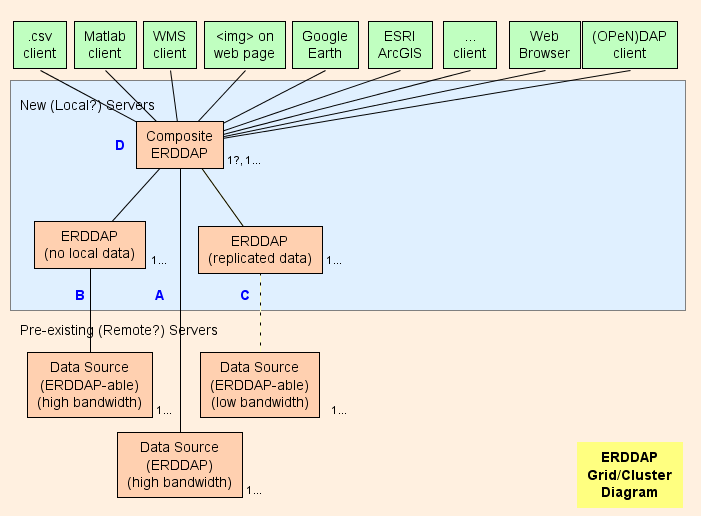
- Alapvetően azt javaslom, hogy egy kompozitot állítsak fel ERDDAP™ ( D a diagramban) - ami rendszeres ERDDAP™ kivéve, hogy csak az adatokat szolgáltatja mástól ERDDAP S. A rács architektúráját úgy tervezték, hogy a lehető legtöbb munkát változtassák (CPU használat, memóriahasználat, sávszélesség használat) a kompozitból ERDDAP™ a másik ERDDAP S.
- ERDDAP™ két speciális adatkészlettípussal rendelkezik, EDDGrid FromErdap és EDDTableFromErddap , amely utal adatkészletek más ERDDAP S.
- Amikor a kompozit ERDDAP™ kérelmet kap ezekből az adatkészletekből származó adatokról vagy képekről, a kompozit ERDDAP™ átirányítás a másik adatkérés ERDDAP™ szerver. Az eredmény:
- Ez nagyon hatékony (CPU, memória és sávszélesség) mert egyébként
- A kompozit ERDDAP™ meg kell küldeni az adatkérést a másiknak ERDDAP ...
- A másik ERDDAP™ meg kell szereznie az adatokat, meg kell reformálnia, és továbbítja az adatokat az összetettnek ERDDAP ...
- A kompozit ERDDAP™ meg kell kapni az adatokat (extra sávszélesség használatával) megreformálja (extra CPU időt és memóriát használ) és továbbítja az adatokat a felhasználónak (extra sávszélesség használatával) ... Az adatkérés átirányításával és a másik lehetővé tételével ERDDAP™ a válasz közvetlenül a felhasználóra, az összetett ERDDAP™ lényegében nincs CPU-idő, memória vagy sávszélesség az adatkéréseknél.
- Az átirányítás átlátható a felhasználó számára az ügyfélszoftvertől függetlenül (böngésző vagy más szoftver vagy parancssor eszköz) ...
- Ez nagyon hatékony (CPU, memória és sávszélesség) mert egyébként
Grid alkatrészek
A : Minden távoli adatforrás, amely magas sávszélességű OPeNDAP szerver, közvetlenül kapcsolódhat a távoli szerverhez. Ha a távoli szerver egy ERDDAP™ Használat EDDGrid FromErddap vagy EDDTableFrom ERDDAP hogy szolgálja az adatokat a kompozit ERDDAP ... Ha a távoli szerver más típusú DAP szerver, pl. THREDDS, Hyrax vagy GrADS, használat EDDGrid FromDap.
B Minden ERDDAP - lehetséges adatforrás (olyan adatforrás, amelyből ERDDAP olvasható adatok) ez egy magas sávú szerverrel rendelkezik, létrehozva egy másikat ERDDAP™ az adatforrásból származó adatok kiszolgálásáért felelős hálózatban.
- Ha több ilyen ERDDAP s nem kap sok adatkérést, megszilárdíthatja őket egy ERDDAP ...
- Ha ERDDAP™ az egyik távoli forrásból származó adatok túl sok kérést kapnak, van egy kísértés, hogy további ERDDAP s a távoli adatforráshoz való hozzáférés. Különleges esetekben ez értelmet jelenthet, de valószínűbb, hogy ez túlnyomja a távoli adatforrást (amely az önvédelem) és megakadályozza a többi felhasználót a távoli adatforráshoz való hozzáféréstől (ami nem szép) ... Ilyen esetben fontolja meg egy másik beállítást ERDDAP™ hogy szolgálja ezt az adatkészletet, és másolja az adatkészletet. ERDDAP "A kemény meghajtó (lásd: C ) talán EDDGrid Másolás vagy EDDTableCopy ...
- B A szervereknek nyilvánosan hozzáférhetőnek kell lenniük.
C Minden ERDDAP - olyan adatforrás, amely alacsony sávszélességű szerverrel rendelkezik (vagy lassú szolgáltatás más okokból) fontolja meg egy másik beállítást ERDDAP™ az adatkészlet másolatának tárolása ezen ERDDAP "A kemény meghajtók, talán EDDGrid Másolás vagy EDDTableCopy ... Ha több ilyen ERDDAP s nem kap sok adatkérést, megszilárdíthatja őket egy ERDDAP ... C A szervereknek nyilvánosan hozzáférhetőnek kell lenniük.
Kompozit ERDDAP
D : A kompozit ERDDAP™ rendszeres ERDDAP™ kivéve, hogy csak az adatokat szolgáltatja mástól ERDDAP S.
- Mert a kompozit ERDDAP™ az összes adatkészlet memóriájában van információ, gyorsan reagálhat az adatkészletek listáira vonatkozó kérelmekre (teljes szöveges keresések, kategóriakeresések, az összes adatkészlet listája) és kéri az egyes adatkészletek adathozzáférési formáját, Készítsen egy grafikus formát vagy WMS Info oldal. Ezek mind kicsi, dinamikusan generált, HTML oldalak az emlékezetben tartott információk alapján. Tehát a válaszok nagyon gyorsak.
- Mivel a tényleges adatok iránti kérelmeket gyorsan átirányítják a másiknak ERDDAP S, a kompozit ERDDAP™ gyorsan válaszolhat a tényleges adatok kérésére anélkül, hogy bármilyen CPU-időt, memóriát vagy sávszélességet használna.
- A lehető legtöbb munkát átváltva (CPU, emlékezet, sávszélesség) a kompozitból ERDDAP™ a másik ERDDAP S, a kompozit ERDDAP™ tűnhet úgy, hogy adatokat szolgáltat az összes adatkészletből, és még mindig nagyszámú adatkérést tart fenn számos felhasználótól.
- Előzetes vizsgálatok azt mutatják, hogy a kompozit ERDDAP™ válaszolhat a legtöbb kérésre ~1ms CPU idő, vagy 1000 kérés / másodperc. Tehát egy 8 fő processzornak képesnek kell lennie arra, hogy körülbelül 8000 kérésre / másodpercre válaszoljon. Bár lehetséges elképzelni a magasabb aktivitás eltemetését, ami lassulást okozna, ez sok átmenet. Valószínű, hogy az adatközpont sávszélessége lesz a palackneck, mielőtt a kompozit ERDDAP™ lesz a palackneck.
up-to-date max (Idő) ?
A EDDGrid /TableFromErddap a kompozitban ERDDAP™ csak az egyes forrásadatokkal kapcsolatos tárolt információkat módosítja, ha a forrásadatkészlet "Reload" és néhány metaadat megváltozik (pl. az idő változója actual\_range ) Ezáltal előfizetési értesítést generál. Ha a forrásadatlap olyan adatokkal rendelkezik, amelyek gyakran változnak (például minden második új adat) és használja a "frissítés" rendszer, hogy észrevegyük a gyakori változásokat az alapul szolgáló adatok, EDDGrid /TableFromErddap nem értesíti ezeket a gyakori változásokat, amíg a következő adatkészlet "reload", így a EDDGrid /TableFromErddap nem lesz tökéletesen naprakész. Ezt a problémát minimalizálhatja a forrásadatlap megváltoztatásával<ReloadEveryNMinutes & Gt; kisebb értékre (60? 15?) hogy több előfizetési értesítést kapjon, hogy elmondja a EDDGrid /TableFromErddap, hogy frissítse az információt a forrás adatkészlet.
Vagy ha az adatkezelő rendszere tudja, hogy a forrásadatbázisnak új adatai vannak (pl. egy olyan forgatókönyven keresztül, amely másol egy adatfájl helyére) És ha ez nem szuper gyakori (pl. minden 5 percben, vagy kevésbé gyakori) Van egy jobb megoldás:
- Ne használja<frissítésEveryNMillis & gt; a forrásadat naprakész tárolása.
- Állítsa be a forrásadatkészletet<ReloadEveryNMinutes & Gt; egy nagyobb számra (1440?) ...
- Vedd fel a forgatókönyvet a forrásadatkészlettel zászló URL közvetlenül, miután másol egy új adatfájl helyére. Ez vezet a forrásadathoz, hogy tökéletesen naprakész legyen, és azt eredményezi, hogy előfizetési értesítést generáljon, amelyet elküldnek EDDGrid /TableFromErddap adatkészlet. Ez vezetni fog EDDGrid /TableFromErddap adatkészlet, hogy tökéletesen naprakész (jól, 5 másodpercen belül az új adatok hozzáadása) ... És mindez hatékonyan fog történni (felesleges adatkészlet-reloads nélkül) ...
Több kompozit ERDDAP s
- Nagyon szélsőséges esetekben, vagy hibás toleranciák esetén több kompozitot szeretne létrehozni ERDDAP ... Valószínű, hogy a rendszer más részei (nevezetesen az adatközpont sávszélessége) hosszú problémává válik a kompozit előtt ERDDAP™ lesz egy palackneck. Tehát a megoldás valószínűleg további, földrajzilag változatos, adatközpontokat hoz létre (tükör) Mindegyik összetett ERDDAP™ szerverekkel ERDDAP és (legalább) a nagy keresletben lévő adatkészletek tükörmásolatai. Egy ilyen beállítás hibás toleranciát és adatmentést is biztosít (másoláson keresztül) ... Ebben az esetben a legjobb, ha a kompozit ERDDAP S vannak különböző URL-ek.
Ha igazán akarja az összes kompozitot ERDDAP s, hogy ugyanazt az URL-t használja, használjon olyan frontvégzeti rendszert, amely egy adott felhasználót hozzárendel a kompozithoz ERDDAP s (az IP-cím alapján) , hogy az összes felhasználó kérése csak az egyik kompozit ERDDAP S. Két oka van:
- Amikor egy mögöttes adatkészletet újratöltenek, és a metaadat megváltozik (pl. egy új adatfájl egy rácsos adatkészletben az idő változója actual\_range változás) , a kompozit ERDDAP a szinkronból időnként kissé kimaradnak, de esetleges következetesség ... Általában 5 másodpercen belül újra szinkronizálnak, de néha hosszabb lesz. Ha egy felhasználó automatizált rendszert készít, amely támaszkodik ERDDAP™ Előfizetések a kiváltó intézkedések, a rövid szinkronicitási problémák jelentőssé válnak.
- A 2+ kompozit ERDDAP S mindegyik fenntartja saját előfizetési készletét (a fent leírt szinkron probléma miatt) ...
Tehát egy adott felhasználót csak az egyik kompozitra kell irányítani ERDDAP hogy elkerüljék ezeket a problémákat. Ha az egyik kompozit ERDDAP lemegy, az elülső végrendszer átirányíthatja azt ERDDAP A felhasználók egy másik ERDDAP™ Ez felfelé. Ha azonban kapacitásproblémáról van szó, ami az első kompozitot okozza ERDDAP™ kudarcot vall (túlzott felhasználó? egy Denial-of-service támadás ?) , ez nagyon valószínű, hogy átirányítja a felhasználók más kompozit ERDDAP S fogja okozni Cascading kudarc ... Így a legerősebb beállítás az, hogy kompozit ERDDAP S különböző URL-ekkel.
Vagy talán jobb, több kompozit létrehozása ERDDAP S terheléskiegyensúlyozás nélkül. Ebben az esetben meg kell tennie egy pontot, hogy mindegyiket megadja ERDDAP más név / személyazonosság, és ha lehetséges, a világ különböző részein hozza létre őket (pl. különböző AWS régiók) pl.: ERD \_US\_East, ERD \_US\_West, ERD \_IE, ERD \_FR, ERD \_IT, hogy a felhasználók tudatosan, ismételten dolgozzon egy adott ERDDAP ...
- \[ A nagy teljesítményű rendszer lenyűgöző kialakítása egy szerveren, lásd ezt részletes leírása Mailinator ... \]
Adatkészletek a nagyon magas keresletben
Az igazán szokatlan esetben az egyik a A , B vagy C ERDDAP s nem tud lépést tartani a sávszélesség vagy a merevlemez-korlátozások miatt, értelme van az adatok másolására (újra) egy másik szerver+hard Drive+ ERDDAP talán EDDGrid Másolás vagy EDDTableCopy ... Bár ideálisnak tűnhet az eredeti adatkészlet és a másolt adatkészlet zökkenőmentesen jelenik meg, mint az egyik adatkészlet a kompozitban ERDDAP™ Ez nehéz, mert a két adatkészlet kissé különböző állapotokban lesz (nevezetesen, miután az eredeti kap új adatokat, de mielőtt a másolt adatkészlet megkapja a másolatot) ... Ezért azt javaslom, hogy az adatkészletek kissé eltérő címeket kapjanak (pl.: „... (Másolat #1) "és "..." (Másolat #2) ", vagy talán " (tükör # n ) " vagy " (szerver # n ) "...") és külön adatkészletként jelennek meg a kompozitban ERDDAP ... A felhasználókat használják a listák megtekintésére tükör oldalak népszerű fájl letöltési oldalak, így ez nem meglepő, vagy csalódás őket. Mivel a sávszélesség korlátozások egy adott oldalon, lehet, hogy van értelme, hogy a tükör található egy másik oldalon. Ha a tükör másolata más adatközpontban van, akkor az adott adatközpont kompozitja hozzáfér ERDDAP™ A különböző címek (pl.: "mirror #1) nem szükséges.
RAIDs versus rendszeres merevlemezek
Ha egy nagy adatkészletet vagy adatkészletek egy csoportját nem használják, akkor értelme lehet az adatok tárolására egy RAID-on, mivel hibás toleranciát kínál, és mivel nincs szüksége egy másik szerver feldolgozóerejére vagy sávszélességére. De ha egy adatkészletet erősen használják, akkor több értelme lehet másolni az adatokat egy másik szerveren + ERDDAP™ + merevlemez (hasonló mit csinál a Google ) ahelyett, hogy egy kiszolgálót és egy RAID-t használna több adatkészlet tárolására, mivel mindkét szerver + hardDrive + ERDDAP s a rácsban, amíg egyikük nem sikerül.
Hibák
Mi történik, ha...
- Egy adatkészlet iránti kérelmek eltemetése (pl. az osztály minden diákja egyszerre kéri a hasonló adatokat) ? Csak a ERDDAP™ az adatkészlet kiszolgálása túlterhelt és lassú lesz, vagy elutasítja a kéréseket. A kompozit ERDDAP™ más ERDDAP nem érintik. Mivel az adott adatkészlet korlátozó tényezője a rendszeren belül a merevlemez az adatokkal (nem ERDDAP ) Az egyetlen megoldás (nem azonnal) az adatkészlet másolata egy másik szerveren + hardDrive + ERDDAP ...
- Egy A , B vagy C ERDDAP™ kudarc (pl. a merevlemez kudarca) ? Csak az adatkészlet (s) ezt szolgálja ERDDAP™ befolyásolják. Ha az adatkészlet (s) egy másik kiszolgáló + hardDrive + ERDDAP A hatás minimális. Ha a probléma merevlemezhiány az 5. vagy 6. szinten, akkor csak a meghajtót helyettesíti, és az RAID újraépíti az adatokat a meghajtón.
- A kompozit ERDDAP™ Nem? Ha azt szeretné, hogy egy rendszer nagyon magas rendelkezésre állás , hozhat létre több kompozit ERDDAP s (a fentebb tárgyalt) használjon valami hasonlót NGINX vagy Traefik kezelni a terhelési egyensúlyt. Vegye figyelembe, hogy egy adott kompozit ERDDAP™ nagyszámú felhasználó kérését kezelheti, mert a metaadat iránti kérelmek kicsik, és azokat az információkat kezelik, amelyek emlékezetben vannak, és adatok kérése (melyik lehet nagy) átirányítják a gyermeket ERDDAP S.
Egyszerű, skálázható
Ez a rendszer könnyen felállítható és kezelhető, és könnyen kibővíthető, ha bármely része túlterhelt. Az adott adatközpont egyetlen valódi korlátozása az adatközpont sávszélessége és a rendszer költsége.
Bandwidth
Vegye figyelembe a rendszer közösen használt összetevőinek közelgő sávszélességét:
| Összehasonlítás | Körülbelül Bandwidth (GBytes/s) |
|---|---|
| DDR memória | 2.5 |
| SSD meghajtó | 1 |
| SATA merevlemez | 0.3 |
| Gigabit Ethernet | 0.1 |
| OC-12 | 0.06 |
| OC-3 | 0.015 |
| T1 | 0.0002 |
Tehát egy SATA merevlemez (0,3GB/s) egy kiszolgálóval egy ERDDAP™ valószínűleg telített egy Gigabit Ethernet LAN (0,1GB/s) ... Egy Gigabit Ethernet LAN (0,1GB/s) valószínűleg telített OC-12 internetkapcsolatot (0,06GB/s) ... És legalább egy forrás felsorolja az OC-12 sorokat, amelyek havonta körülbelül 100 000 dollárba kerülnek. (Igen, ezek a számítások azon alapulnak, hogy a rendszert korlátozza, ami nem jó, mert nagyon súlyos válaszokat eredményez. De ezek a számítások hasznosak a rendszer alkatrészeinek tervezéséhez és kiegyensúlyozásához.) Nyilvánvaló, hogy az adatközpont megfelelő gyors internetkapcsolata messze a rendszer legdrágább része. Könnyen és viszonylag olcsón építhet egy hálózatot egy tucat szerverrel, amely tucatot futtat. ERDDAP s amely képes gyorsan kiszivattyúzni sok adatot, de egy megfelelően gyors internetkapcsolat nagyon drága lesz. A részleges megoldások:
- Ösztönözze az ügyfeleket, hogy kérjék az adatokat, ha ez minden szükséges. Ha az ügyfélnek csak egy kis régióra vagy egy alacsonyabb állásfoglalásra van szüksége, az az, amit kérnie kell. A helyettesítés központi fókusza a protokolloknak ERDDAP™ az adatok kérésére nyújtott támogatások.
- Ösztönözze a tömörített adatokat. ERDDAP™ kompresszorok adatátvitel, ha "elfogadást" talál HTTP GET kérjen vezetőt. Minden webes böngésző "elfogadást" használ, és automatikusan lenyomja a választ. Egyéb ügyfelek (pl. számítógépes programok) kifejezetten használni kell.
- Indítsa el szervereit egy ISP vagy más webhelyen, amely viszonylag olcsó sávszélességi költségeket kínál.
- Fedezze fel a szervereket a ERDDAP különböző intézményekre, hogy a költségek szétoszlanak. Ezután kapcsolhatja össze a kompozitját ERDDAP™ az ő ERDDAP S.
Vegyük észre, hogy Cloud számítás és a web hosting szolgáltatások kínálnak minden internet sávszélességet, amire szüksége van, de ne oldja meg az ár problémát.
Általános információk a skálázható, nagy kapacitású, hibás toleráns rendszerek tervezéséről, lásd Michael T. Nygard könyvét Elengedni ...
Mint a Legos
A szoftvertervezők gyakran próbálnak jót használni szoftver tervezési minták problémák megoldására. A jó minták jók, mert jó, könnyű létrehozni és dolgozni, általános célú megoldásokkal, amelyek jó tulajdonságokkal rendelkező rendszerekhez vezetnek. A minta nevek nem szabványosítva vannak, ezért felhívom a mintát, amit ERDDAP™ használja a Lego Pattern. Minden láb (Minden ERDDAP ) egy egyszerű, kicsi, szabványos, önálló, tégla (Data szerver) egy meghatározott felülettel, amely lehetővé teszi, hogy más jogokhoz kapcsolódjon ( ERDDAP s) ... A részei ERDDAP™ a rendszer létrehozása: az előfizetés és a zászlóURL rendszerek (amely lehetővé teszi a kommunikációt ERDDAP s) Az EDD... FromErddap átirányítási rendszer és a rendszer RESTful olyan adatok iránti kérelmek, amelyeket a felhasználók vagy más ERDDAP S. Így két vagy több legóra ( ERDDAP s) hatalmas számú különböző formát hozhat létre (hálózati topológiák ERDDAP s) ... Persze, a tervezés és jellemzői ERDDAP™ lehetett volna másképp, nem Lego-szerű, talán csak, hogy lehetővé tegye és optimalizálja egy adott topológia. De úgy érezzük, hogy ERDDAP A Lego-szerű design jó, általános célú megoldást kínál, amely lehetővé teszi bármelyiket ERDDAP™ adminisztrátor (vagy adminisztrátorok csoportja) létrehozni mindenféle különböző szövetségi topológiát. Például egy egyetlen szervezet létrehozhatna háromat (vagy többet) ERDDAP S mint amilyen mutatott ERDDAP™ Grid/Cluster diagram felett ... Vagy elosztott csoport (IOOS? CoastWatch? NCEI? NWS? NOAA ? USGS? Adatok? NEON? LTER? OOI? BODC? ONC? JRC? WMO?) létrehozhat egyet ERDDAP™ minden kis kitétben (így az adatok a forráshoz közel maradhatnak) Ezután állítson összetettet ERDDAP™ a központi irodában virtuális adatkészletekkel (amelyek mindig tökéletesen naprakészek) minden kis kitűből ERDDAP S. Valóban, az összes ERDDAP s, telepítve különböző intézmények szerte a világon, amely adatokat kap más ERDDAP s és/vagy adatokat szolgáltat másnak ERDDAP s, képezzen egy hatalmas hálózatot ERDDAP S. Milyen jó ez?! Tehát, mint a Lego, a lehetőségek végtelenek. Ezért ez egy jó minta. Ezért ez egy jó design ERDDAP ...
Különböző típusú kérések
Az adatkiszolgáló topológiák megvitatásának egyik valós szövődménye, hogy különböző típusú kérések és különböző módszerek vannak a különböző típusú kérések optimalizálására. Ez többnyire külön kérdés (Milyen gyors lehet ERDDAP™ az adatok válaszolnak az adatok kérésére?) a topológia beszélgetésből (amely az adatkiszolgálók közötti kapcsolatokkal foglalkozik, és amely szerver rendelkezik a tényleges adatokkal) ... ERDDAP™ Természetesen megpróbál minden típusú kérelmet hatékonyan kezelni, de jobban kezeli, mint mások.
- Sok kérés egyszerű. Például: Mi a metaadata ennek az adatkészletnek? Vagy: Melyek az idő dimenziójának értékei ennek a rácsos adatkészletnek? ERDDAP™ úgy tervezték, hogy ezeket a lehető leggyorsabban kezeljék (általában a<=2 ms) azáltal, hogy ezt az információt memóriában tartja.
- Néhány kérés mérsékelten nehéz. Például: Adj nekem egy adatkészletet (amely egy adatfájlban van) ... Ezek a kérések viszonylag gyorsan kezelhetők, mert nem olyan nehézkesek.
- Néhány kérés kemény, így az időfogyasztás. Például: Adj nekem egy adatkészletet (amely a 10 000+ adatfájl bármelyikében lehet, vagy olyan tömörített adatfájlokból származhat, amelyek mindegyike 10 másodpercet vesz igénybe a depresszióhoz) ... ERDDAP™ v2.0 bevezetett néhány új, gyorsabb módszert, hogy kezelje ezeket a kéréseket, különösen azáltal, hogy lehetővé teszi a kéréskezelő szál több munkavállalói szálak leküzdését, amelyek a kérés különböző alkészleteit kezelik. De van egy másik megközelítése ennek a problémának, amely ERDDAP™ még nem támogatja: az adatfájlok egy adott adathalmazra vonatkozó alkészleteit külön számítógépekre lehet tárolni és elemezni, majd az eredeti kiszolgálón kombinált eredményeket. Ezt a megközelítést nevezik MapReduce és felrobbant Hadoop Az első (?) nyílt forráskódú MapReduce program, amely a Google papír ötletei alapján készült. (Ha szüksége van a MapReducre in ERDDAP Kérjük, küldjön e-mail kérést erd.data at noaa.gov ...) Google BigQuery érdekes, mert úgy tűnik, hogy a MapReduce alkalmazása a tambuláris adatkészletek leállítására vonatkozik, ami az egyik ERDDAP Fő célok. Valószínű, hogy létrehozhatsz egy ERDDAP™ adatkészlet a BigQuery adatkészletből keresztül EDDTableFromDatabase mert a BigQuery egy JDBC felületen keresztül érhető el.
Ezek az én véleményem.
Igen, a számítások egyszerűbbek (és most enyhén dátumozott) De szerintem a következtetések helyesek. Használtam hibás logikát, vagy hibáztam a számításaimban? Ha igen, a hiba egyedül az enyém. Kérjük, küldjön e-mailt a korrekcióval erd dot data at noaa dot gov ...
Cloud számítás
Számos vállalat kínál felhő számítási szolgáltatásokat (pl.: Amazon Web Services és Google Cloud platform ) ... Web hosting cégek Az 1990-es évek közepe óta egyszerűbb szolgáltatásokat kínáltak, de a „zárt” szolgáltatások nagymértékben bővítették a rendszerek rugalmasságát és a kínált szolgáltatások körét. óta ERDDAP™ A hálózat csak a ERDDAP és azóta ERDDAP S. Java webes alkalmazások, amelyek Tomcatban futhatnak (a leggyakoribb alkalmazásszerver) vagy más alkalmazásszervereknek, viszonylag könnyűnek kell lennie létrehozni egy ERDDAP™ Hálózati szolgáltatás vagy web hosting oldal. Ezeknek a szolgáltatásoknak az előnyei:
- Nagyon magas sávszélességű internetkapcsolatokhoz biztosítanak hozzáférést. Ez önmagában igazolhatja ezeket a szolgáltatásokat.
- Csak az általad használt szolgáltatásokért felelősek. Például hozzáférhet egy nagyon magas sávszélességű internetkapcsolathoz, de csak a tényleges adatátvitelért fizet. Ez lehetővé teszi egy olyan rendszer építését, amely ritkán túlterhelt (még a csúcs keresletnél is) anélkül, hogy fizetnie kell a ritkán használt kapacitásért.
- Könnyen kimeríthetőek. A szervertípusokat megváltoztathatja, vagy hozzáadhat annyi szervert vagy annyi tárolót, amennyit csak akar, kevesebb, mint egy perc alatt. Ez önmagában igazolhatja ezeket a szolgáltatásokat.
- Megszabadítanak a szerverek és hálózatok működtetésének számos adminisztratív feladatától. Ez önmagában igazolhatja ezeket a szolgáltatásokat.
E szolgáltatások hátrányai:
- Felszámolnak szolgáltatásaikért, néha sokat (abszolút értelemben; nem az, hogy nem jó érték) ... Az itt felsorolt árak a Amazon EC2 ... Ezek az árak (2015 júniusától) le fog jönni.
A múltban az árak magasabbak voltak, de az adatfájlok és a kérések száma kisebb volt.
A jövőben az árak alacsonyabbak lesznek, de az adatfájlok és a kérések száma nagyobb lesz.
Tehát a részletek megváltoznak, de a helyzet viszonylag állandó marad.
És nem az, hogy a szolgáltatás túláramlik, hanem az, hogy sok szolgáltatást használunk és vásárolunk.
- Adatátvitel - Az adatátvitel a rendszerbe most ingyenes (Igen!) ... Az adatátvitel a rendszerből 0,09/GB dollár. Egy SATA merevlemez (0,3GB/s) egy kiszolgálóval egy ERDDAP™ valószínűleg telített egy Gigabit Ethernet LAN (0,1GB/s) ... Gigabit Ethernet LAN (0,1GB/s) valószínűleg telített OC-12 internetkapcsolatot (0,06GB/s) ... Ha egy OC-12 kapcsolat továbbíthatja a ~ 150 000 GB / hónapot, az adatátviteli költségek akár 150 000 GB @ $0.09 / GB = 13 500 $ / hónap, ami jelentős költség. Nyilvánvalóan, ha tucat keményen dolgozik ERDDAP felhő szolgáltatás, havi adatátviteli díjak jelentősek lehetnek (akár $ 162,000 / hónap) ... (Ismét nem az, hogy a szolgáltatás túláramlik, az az, hogy sok szolgáltatást használunk és vásárolunk.)
- Adattárolás - Az Amazon TB-nként 50 dollárt számít fel. (Hasonlítsd össze, hogy egy 4TB-vállalatot vásárolj meg egyenesen ~ $ 50 / TB-ért, bár a RAID a teljes költséghez hozzáadott és adminisztratív költségeket.) Tehát, ha sok adatot kell tárolnia a felhőben, meglehetősen drága lehet (pl. a 100TB 5000 dollárba kerülne) ... De ha nincs igazán nagy mennyiségű adat, ez egy kisebb probléma, mint a sávszélesség / adatátviteli költségek. (Ismét nem az, hogy a szolgáltatás túláramlik, az az, hogy sok szolgáltatást használunk és vásárolunk.)
Beállítás
- A helyettesítő probléma: Az egyetlen módja annak, hogy hatékonyan eloszthassuk az adatfájlok adatait, hogy rendelkezzenek olyan programmal, amely elosztja az adatokat (pl.: ERDDAP ) fut egy olyan szerveren, amely rendelkezik a helyi merevlemezen tárolt adatokkal (vagy hasonlóan gyors hozzáférés egy SAN-hoz vagy helyi RAID-hoz) ... A helyi fájlrendszerek lehetővé teszik ERDDAP™ (a könyvtárak, például a netcdf-java) konkrét byte-tartományok kérésére a fájlokból, és nagyon gyorsan választ kap. Számos adatkérés a ERDDAP™ a fájlba (nevezetesen rácsos adatkérelmek, ahol a merev érték > 1) nem lehet hatékonyan elvégezni, ha a programnak meg kell kérnie egy nem helyi fájl teljes fájlját vagy nagy darabját (így lassabb) adattároló rendszer, majd kivonat egy alkatrészt. Ha a felhő beállítás nem ad ERDDAP™ gyors hozzáférés a fájlok byte tartományaihoz (olyan gyors, mint a helyi fájlok) , ERDDAP "Az adatokhoz való hozzáférés súlyos palackneck lesz, és más előnyökkel jár a felhőszolgáltatás használata.
Hosted Data
A fenti költséges haszonelemzés alternatívája (amely az adattulajdonoson alapul (pl.: NOAA ) fizetni az adataikat a felhőben tárolni) 2012 körül érkezett, amikor az Amazon (és kisebb mértékben, néhány más felhő szolgáltató) elkezdett tárolni néhány adatkészletet a felhőben (AWS S3) ingyenesen (feltehetően abban a reményben, hogy visszaszerezhetik a költségeket, ha a felhasználók az AWS EC2 kompute példákat bérelnének az adatokkal való együttműködésre.) ... Nyilvánvaló, hogy ez teszi a felhő számítás jelentősen költséghatékonyabb, mert az idő és a költségek feltöltése az adatokat, és host ez most nulla. Ezzel ERDDAP™ v2.0, vannak új funkciók a futás megkönnyítésére ERDDAP felhőben:
- Most, egy EDDGrid FromFiles vagy EDDTableFromFiles adatkészlet létrehozható olyan adatfájlokból, amelyek távoli és hozzáférhetőek az interneten keresztül (pl.: AWS S3 vödör) használatával<cacheFromUrl> és<cacheSize GB> opciók. ERDDAP™ fenntartja a legutóbb használt adatfájlok helyi gyorsítótárát.
- Most, ha az EDDTableFromFiles forrásfájlok tömörülnek (pl.: .tgz ) , ERDDAP™ automatikusan elnyomja őket, amikor elolvassa őket.
- Most, a ERDDAP™ egy adott kérésre adott szál reagálása meg fogja szüntetni a munkavállalói szálakat, hogy dolgozzanak a kérelem alszakaszán, ha használja a<nThreads & gt; opciók. Ez a párhuzamosság lehetővé kell tennie a gyorsabb válaszokat a nehéz kérésekre.
Ezek a változások megoldják az AWS S3 problémáját, nem helyi, blokkszintű fájltárolást és (öreg) az S3 adatokhoz való hozzáférés problémája jelentős laggal. (Évekkel ezelőtt (~2014) Ez a lag jelentős volt, de most sokkal rövidebb, és nem olyan jelentős.) Összességében ez azt jelenti, hogy felállítjuk ERDDAP™ A felhőben most sokkal jobban működik.
Köszönöm - Sok köszönet Matthew Arrottnak és csoportjának az eredeti OOI erőfeszítésében, hogy munkájukat helyezték ERDDAP™ a felhőben és az ebből eredő vitákban.
Az adatkészletek eltávolítása
Van egy közös probléma, amely kapcsolódik a fent említett tárgyalás a rácsok és szövetségek ERDDAP s: az adatkészletek távoli replikációja. Az alapvető probléma az, hogy az adatszolgáltató fenntart egy olyan adatkészletet, amely időnként változik, és a felhasználó fenntartani akarja az adatkészlet naprakész helyi másolatát. (bármilyen különböző okok miatt) ... Nyilvánvaló, hogy ennek számos változata létezik. Néhány variáció sokkal nehezebb kezelni, mint mások.
- Gyors frissítések Nehéz naprakészen tartani a helyi adatkészletet azonnal (pl. 3 másodpercen belül) a forrás minden változása után, nem pedig néhány órán belül.
- Gyakori változások A gyakori változások nehezebbek kezelni, mint a gyakori változások. Például az egyszeri változások sokkal könnyebben kezelhetők, mint a 0,1 másodpercnél.
- Kis változások A forrásfájl kis változásai nehezebbek kezelni, mint egy teljesen új fájl. Ez különösen igaz, ha a kis változások bárhol lehetnek a fájlban. A kis változások nehezebbek felismerni és nehezen elszigetelni azokat az adatokat, amelyeket meg kell replikálni. Az új fájlok könnyen felismerhetők és hatékonyak az átvitelhez.
- Entire Dataset A teljes adatállomány naprakész tartása nehezebb, mint a közelmúltbeli adatok fenntartása. Néhány felhasználónak csak a legújabb adatokra van szüksége (pl. az utolsó 8 napos érték) ...
- Több másolat A különböző webhelyeken több távoli másolat fenntartása nehezebb, mint egy távoli másolat fenntartása. Ez a skálázó probléma.
Nyilvánvalóan számos változata lehetséges változások a forrás adatkészlet és a felhasználó igényeinek és elvárásainak. Sok variáció nagyon nehéz megoldani. Az egyik helyzet legjobb megoldása gyakran nem a legjobb megoldás egy másik helyzetre - még nincs univerzális megoldás.
Relevant ERDDAP™ Eszközök
ERDDAP™ számos eszközt kínál, amelyeket egy olyan rendszer részeként lehet használni, amely egy adatkészlet távoli másolatának fenntartására törekszik:
- ERDDAP A RSS (Rich Site összefoglaló?) szolgáltatás
gyors módja annak, hogy ellenőrizze, ha egy adatkészlet távolról ERDDAP™ megváltozott. - ERDDAP A előfizetési szolgáltatás
hatékonyabb (mint RSS ) megközelítés: azonnal küld egy e-mailt, vagy lépjen kapcsolatba egy URL-t minden előfizetővel, amikor az adatkészlet frissül, és a frissítés változást eredményezett. Hatékony abban, hogy az ASAP megtörténjen, és nincs pazarlási erőfeszítés (mint a polling egy RSS szolgáltatás) ... A felhasználók más eszközöket használhatnak (mint IFTTT ) reagálni az előfizetési rendszer e-mail értesítéseire. Például egy felhasználó feliratkozhat egy távoli adatkészletre ERDDAP™ és használja az IFTTT-t, hogy reagáljon az előfizetési e-mail értesítésekre, és indítsa el a helyi adatkészlet frissítését. - ERDDAP A zászlórendszer
utat biztosít egy ERDDAP™ adminisztrátor, hogy elmondjon egy adatkészletet az ő / ő ERDDAP az ASAP újratöltéséhez. A zászló URL formája könnyen használható a forgatókönyvekben. A zászló URL formáját is fel lehet használni, mint az előfizetés fellépését. - ERDDAP A "files" rendszerrendszer
hozzáférést biztosíthat a forrásfájlokhoz egy adott adatkészlethez, beleértve a fájlok Apache-style könyvtárát is (Web Accessible Folder) amely minden fájl letöltése URL, utolsó módosított idő és méret. Az egyik hátránya a használat "files" a rendszer az, hogy a forrásfájlok különböző változó nevekkel és különböző metaadatokkal rendelkeznek, mint az adatkészlet, ahogy megjelenik ERDDAP ... Ha egy távoli ERDDAP™ Az adatkészlet hozzáférést biztosít a forrásfájlokhoz, amely megnyitja a rossz ember rsync verziójának lehetőségét: könnyűvé válik egy helyi rendszer számára, hogy megnézze, mely távoli fájlok változtak és letölthetők. (Lásd: cacheFromUrl opció alább, amely felhasználhatja ezt.)
Megoldások
Bár számos variáció van a probléma és a végtelen számú lehetséges megoldás, csak egy maroknyi alapvető megközelítések megoldások:
Custom, Brute Force megoldások
Egy nyilvánvaló megoldás, hogy egy egyedi megoldást kezeljünk, amelyet ezért egy adott helyzetre optimalizálunk: olyan rendszert készítsünk, amely észleli / azonosítja, hogy mely adatok megváltoztak, és elküldi ezt az információt a felhasználónak, így a felhasználó kérheti a módosított adatokat. Nos, ezt megteheti, de vannak hátrányok:
- Az egyedi megoldások sok munka.
- Az egyedi megoldások általában annyira testreszabottak egy adott adatkészletre, és a felhasználó rendszerére, amelyet nem lehet könnyen újra felhasználni.
- Az egyedi megoldásokat az Ön számára kell megépíteni és fenntartani. (Ez soha nem jó ötlet. Mindig jó ötlet, hogy elkerülje a munkát, és kap valaki mást, hogy a munkát!)
Elriasztom ezt a megközelítést, mert szinte mindig jobb, ha olyan általános megoldásokat keresünk, amelyeket valaki más épített és fenntart, amely könnyen újrahasznosítható különböző helyzetekben.
rsync
rsync a meglévő, lenyűgözően jó, általános célú megoldás a fájlok gyűjteményének megtartására egy felhasználó távoli számítógépén. Így működik:
- Néhány esemény (pl. egy ERDDAP™ előfizetési rendszer esemény) rsync futtatása, (vagy egy krónikus munka rsync-et futtat naponta a felhasználó számítógépén)
- amely kapcsolat rsync a forrás számítógépén,
- amely kiszámítja az egyes fájlok zsákmányainak egy sor hashát, és továbbítja azokat a hashokat a felhasználó rsyncjéhez,
- amely összehasonlítja ezt az információt a felhasználó fájlok másolatára vonatkozó hasonló információkhoz,
- amely aztán megkívánja azokat a fájlokat, amelyek megváltoztak.
Figyelembe véve mindazt, amit csinál, a rsync nagyon gyorsan működik (pl. 10 másodperc, plusz adatátviteli idő) és nagyon hatékonyan. Vannak Rsync variációi ez optimalizálja a különböző helyzeteket (pl. az egyes forrásfájlok zsákmányainak kiszámítása és kiürítése révén) ...
A rsync fő gyengeségei: némi erőfeszítést igényel a felépítéshez (biztonsági kérdések) ; van néhány ijesztő kérdés; és nem jó az NRT adatkészletek fenntartásához valóban naprakész (pl. kínos, hogy használja rsync többet, mint minden 5 perc) ... Ha kezelni tudja a gyengeségeket, vagy ha nem befolyásolja a helyzetet, a rsync kiváló, általános célú megoldás, amelyet bárki használhat most, hogy megoldja az adatkészletek távoli replikációját.
Van egy elem a ERDDAP™ Csatlakozzon a listához, hogy megpróbáljon támogatást nyújtani a rsync szolgáltatásokhoz ERDDAP (valószínűleg egy nagyon nehéz feladat) , hogy minden ügyfél használja rsync (vagy változat) egy adatkészlet naprakész másolatának fenntartása. Ha valaki dolgozni akar ezen, kérlek e-mailt erd.data at noaa.gov ...
Vannak más programok, amelyek többé-kevésbé azt teszik, amit a rsync csinál, néha orientált adatállomány-replikáció (bár gyakran egy fájl másolat szintjén) pl.: Unidata A IDD ...
Cache From Url
A cacheFromUrl beállítás elérhető (Kezdőlap ERDDAP™ v2.0) mindenki számára ERDDAP Olyan adatkészlettípusok, amelyek adatkészleteket hoznak a fájlokból (alapvetően az összes alosztály EDDGrid Fájlok és EDDTableFromFiles ) ... Húsvét FromUrl megpróbálja automatikusan letölteni és fenntartani a helyi adatfájlokat azáltal, hogy távoli forrásból másolja őket a gyorsítótáron keresztül FromUrl beállítás. A távoli fájlok egy Web Accessible Folderben vagy a THREDDS által kínált könyvtár-szerű fájllistában találhatók, Hyrax S3 vödör, vagy ERDDAP A "files" rendszer.
Ha a távoli fájlok forrása egy távoli ERDDAP™ adatkészlet, amely a forrásfájlokat a forrásfájlokon keresztül kínálja ERDDAP™ "files" rendszer, akkor lehet alá: beadás távoli adatkészletre, és használja a zászló URL a helyi adatkészlet, mint az előfizetés fellépése. Ezután, amikor a távoli adatkészlet megváltozik, kapcsolatba lép a zászló URL-rel az adatkészletéhez, amely megmondja az ASAP újratöltéséről, amely feltárja és letölti a módosított távoli adatfájlokat. Mindez nagyon gyorsan történik (általában 5 másodperc, plusz az idő, hogy letöltse a módosított fájlokat) ... Ez a megközelítés nagyszerűen működik, ha a forrásadatváltozások az új fájlokat rendszeresen hozzáadják, és amikor a meglévő fájlok soha nem változnak. Ez a megközelítés nem működik jól, ha az adatokat gyakran hozzák létre mindenhez (vagy a legtöbb) a meglévő forrásadat fájlok, mert akkor a helyi adatkészlet gyakran letölti az egész távoli adatkészletet. (Itt van szükség egy rsync-szerű megközelítésre.)
ArchiveADataset
ERDDAP™ A ArchiveADataset jó megoldás, ha az adatgyűjtés gyakran hozzáadódik, de az idősebb adatok soha nem változnak. Alapvetően, egy ERDDAP™ adminisztrátor futhat ArchiveADataset (talán egy forgatókönyvben, talán a krón) és határozza meg az adatkészlet alkészletét, amelyet ki akarnak vonni (Talán több fájlban) csomag egy .zip vagy .tgz fájl, így elküldheti a fájlt az érdekelt embereknek vagy csoportoknak (NCEI az archiváláshoz) vagy letölthetővé teszi. Például, akkor futtatni ArchiveADataset minden nap 12:10 am és van, hogy egy .zip az összes adat 12:00 órakor az előző nap 12:00-ig. (Vagy tegyük ezt a heti, havi vagy évente, szükség szerint.) Mivel a csomagolt fájl offline keletkezik, nincs veszélye az időzítésre vagy túl sok adatra, mivel lenne egy szabvány ERDDAP™ kérés.
ERDDAP™ „Szabványos kérési rendszer
ERDDAP™ A standard kérési rendszer alternatív jó megoldás, ha az adatok gyakran hozzáadódik egy adatkészlethez, de az idősebb adatok soha nem változnak. Alapvetően bárki használhat szabványos kéréseket, hogy adatokat szerezzenek egy adott időre. Például 12:10-kor minden nap kérheti az összes adatot egy távoli adatkészletből 12:00-tól az előző napig 12:00-ig. A korlátozás (az ArchiveADataset megközelítéshez képest) az időzítés kockázata, vagy túl sok adat van egyetlen fájlhoz. Elkerülheted a korlátozást azáltal, hogy gyakoribb kéréseket teszel kisebb időszakokra.
EDDTableFromHttpGet
\[ Ez az opció még nem létezik, de úgy tűnik, a közeljövőben építhető. \]
Az új EDDTableFromHttpGet adatkészlet típusa ERDDAP™ A v2.0 lehetővé teszi egy másik megoldás bevezetését. Az ilyen típusú adathalmaz által fenntartott mögöttes fájlok alapvetően naplófájlok, amelyek rögzítik az adathalmaz változásait. Lehetővé kell tenni egy olyan rendszer létrehozását, amely rendszeresen fenntartja a helyi adatkészletet (vagy egy trigger alapján) a távoli adatkészlethez tett összes módosítás kérése az utolsó kérelem óta. Olyan hatékonynak kell lennie (vagy többet) mint rsync, és kezelni sok nehéz forgatókönyv, de csak akkor működne, ha a távoli és helyi adatkészletek EDDTableFromHttpGet adatkészletek.
Ha valaki dolgozni akar ezen, lépjen kapcsolatba erd.data at noaa.gov ...
Elosztott adatok
A fenti megoldások egyike sem nagyszerű munkát végez a probléma kemény variációinak megoldásában, mert a közel valós idő replikációja (NRT) Az adatkészletek nagyon kemények, részben az összes lehetséges forgatókönyv miatt.
Van egy nagyszerű megoldás: ne próbálja megismételni az adatokat. Ehelyett használja az egy autoritatív forrást (Egy adatkészlet egyen ERDDAP ) az adatszolgáltató fenntartása (pl. regionális iroda) ... Azok a felhasználók, akik adatokat akarnak az adatkészletből, mindig a forrásból kapják. Például a böngésző-alapú alkalmazások az adatokat egy URL-alapú kérelemből kapják, így nem számít, hogy a kérelem az eredeti forráshoz egy távoli szerveren (nem ugyanaz a szerver, amely az ESM-et tárja) ... Sokan régóta támogatták ezt a Distributed Data megközelítést (Roy Mendelssohn az elmúlt 20 évben) ... ERDDAP Háló/szövetségi modell (a dokumentum legfelső 80% -a) ezen megközelítésen alapul. Ez a megoldás olyan, mint egy kard egy Gordian Knot-hoz - az egész probléma eltűnik.
- Ez a megoldás nagyon egyszerű.
- Ez a megoldás lenyűgözően hatékony, mivel nem végeznek munkát egy replikált adatkészlet megtartása érdekében (s) up-to-date.
- A felhasználók bármikor megkaphatják a legújabb adatokat (pl. csak ~0,5 másodperces késleltetéssel) ...
- Jól mérlegeli, és vannak módok a skálázás javítására. (Lásd a vita a dokumentum legfelső 80% -ában.)
Nem, ez nem megoldás minden lehetséges helyzetre, de ez egy nagyszerű megoldás a hatalmas többség számára. Ha bizonyos helyzetekben problémák/gyengeségek merülnek fel ezzel a megoldással, gyakran érdemes megoldani ezeket a problémákat, vagy azokkal a gyengeségekkel élni, mert a megoldás lenyűgöző előnyei vannak. Ha/ha ez a megoldás valóban elfogadhatatlan egy adott helyzetben, pl. amikor valóban rendelkeznie kell az adatok helyi másolatával, akkor fontolja meg a fent említett egyéb megoldásokat.
Következtetés
Bár nincs egyetlen, egyszerű megoldás, amely tökéletesen megoldja az összes problémát minden forgatókönyvben (mint rsync és elosztott adatok szinte) Remélhetőleg elegendő eszköz és lehetőség van arra, hogy elfogadható megoldást találhasson az adott helyzetre.