Escalada
ERDDAP™ - Cargas pesadas, Grades, Clusters, Federações e Computação em Nuvem
ERDDAP :
ERDDAP™ é um aplicativo web e um serviço web que agrega dados científicos de diversas fontes locais e remotas e oferece uma maneira simples e consistente de baixar subconjuntos dos dados em formatos de arquivo comuns e fazer gráficos e mapas. Esta página discute questões relacionadas com pesado ERDDAP™ cargas de uso e explora possibilidades para lidar com cargas extremamente pesadas através de grades, clusters, federações e computação em nuvem.
A versão original foi escrita em junho de 2009. Não houve mudanças significativas. Esta foi a última atualização 2019-04-15.
DISCLAIMER
O conteúdo desta página web são opiniões pessoais de Bob Simons e não refletem necessariamente qualquer posição do Governo ou do National Oceanic and Atmospheric Administration . Os cálculos são simplistas, mas penso que as conclusões estão correctas. Eu usei lógica defeituosa ou cometi um erro nos meus cálculos? Se assim for, a culpa é minha sozinha. Por favor envie um e-mail com a correção para erd dot data at noaa dot gov .
-
- Não.
Cargas pesadas / restrições
Com uso pesado, um standalone ERDDAP™ será restringido (da maioria a menos provável) por:
Largura de banda de origem remota
- Largura de banda de uma fonte de dados remota — Mesmo com uma conexão eficiente (por exemplo, via OPeNDAP ) , a menos que uma fonte de dados remota tenha uma conexão de Internet de largura de banda muito alta, ERDDAP As respostas serão constrangidas pelo quão rápido ERDDAP™ pode obter dados da fonte de dados. Uma solução é copiar o conjunto de dados para ERDDAP O disco rígido, talvez com EDDGrid Entendido. ou EDDTableCopy .
ERDDAP largura de banda do servidor
- A menos que ERDDAP O servidor tem uma conexão de Internet de largura de banda muito alta, ERDDAP As respostas serão constrangidas pelo quão rápido ERDDAP™ pode obter dados das fontes de dados e quão rápido ERDDAP™ pode retornar dados aos clientes. A única solução é obter uma conexão de Internet mais rápida.
Memória
- Se houver muitos pedidos simultâneos, ERDDAP™ pode ficar sem memória e recusar temporariamente novos pedidos. ( ERDDAP™ tem alguns mecanismos para evitar isso e minimizar as consequências se acontecer.) Então, quanto mais memória no servidor melhor. Em um servidor de 32 bits, 4+ GB é realmente bom, 2 GB é bom, menos não é recomendado. Em um servidor de 64 bits, você pode quase completamente evitar o problema, obtendo muita memória. Ver \-Xmx e -Xms configurações para ERDDAP /Tomcat. Um ERDDAP™ obter uso pesado em um computador com um servidor de 64 bits com 8GB de memória e -Xmx definido para 4000M é raramente, se nunca, limitado pela memória.
Tive largura de banda de unidade
- Acessar dados armazenados no disco rígido do servidor é muito mais rápido do que acessar dados remotos. Mesmo assim, se o ERDDAP™ servidor tem uma conexão de Internet de largura de banda muito alta, é possível que acessar dados no disco rígido será um gargalo. Uma solução parcial é usar mais rápido (por exemplo, 10.000 RPM) discos rígidos magnéticos ou unidades SSD (se faz sentido no sentido) . Outra solução é armazenar diferentes conjuntos de dados em diferentes unidades, de modo que a largura de banda cumulativa do disco rígido é muito maior.
Muitos arquivos Cached
- Muitos arquivos em um cache directório — ERDDAP™ cache todas as imagens, mas apenas cache os dados para certos tipos de solicitações de dados. É possível que o diretório de cache para um conjunto de dados tenha um grande número de arquivos temporariamente. Isso retardará as solicitações para ver se um arquivo está no cache (A sério!) .<cache Minutos > em setup.xml permite definir quanto tempo um arquivo pode estar no cache antes de ser excluído. Definir um número menor minimizaria esse problema.
CPU
- Apenas duas coisas levam muito tempo de CPU:
- NetCDF 4 e HDF 5 agora suporta compressão interna de dados. Decomprimir um grande comprimido NetCDF 4 / HDF 5 arquivo de dados pode levar 10 ou mais segundos. (Isso não é uma falha de implementação. É a natureza da compressão.) Assim, várias solicitações simultâneas para conjuntos de dados com dados armazenados em arquivos compactados podem colocar uma tensão grave em qualquer servidor. Se este é um problema, a solução é armazenar conjuntos de dados populares em arquivos não compactados, ou obter um servidor com uma CPU com mais núcleos.
- Fazendo gráficos (incluindo mapas) : aproximadamente 0,2 - 1 segundo por gráfico. Então, se houve muitos pedidos únicos simultâneos para gráficos ( WMS clientes muitas vezes fazem 6 pedidos simultâneos!) , pode haver uma limitação de CPU. Quando vários usuários estão executando WMS clientes, isso se torna um problema.
-
- Não.
Múltiplos Identários ERDDAP s com Balanceamento de Carga?
A pergunta muitas vezes surge: "Para lidar com cargas pesadas, posso configurar vários idênticos ERDDAP com balanceamento de carga?" É uma pergunta interessante porque rapidamente chega ao centro de ERDDAP Design. A resposta rápida é "não". Eu sei que é uma resposta decepcionante, mas há um par de razões diretas e algumas razões fundamentais maiores por que eu criei ERDDAP™ usar uma abordagem diferente (uma federação de ERDDAP s, descrito na maior parte deste documento) , que eu acredito é uma solução melhor.
Algumas razões diretas por que você não pode / não deve configurar vários idênticos ERDDAP s são:
- Um dado ERDDAP™ lê cada arquivo de dados quando ele primeiro fica disponível para encontrar os intervalos de dados no arquivo. Ele então armazena essas informações em um arquivo de índice. Mais tarde, quando um usuário solicita dados entra, ERDDAP™ usa esse índice para descobrir quais arquivos procurar os dados solicitados. Se houver vários idênticos ERDDAP s, cada um estaria fazendo esta indexação, que é desperdiçado esforço. Com o sistema federado descrito abaixo, a indexação é feita apenas uma vez, por um dos ERDDAP S.
- Para alguns tipos de solicitações de usuário (por exemplo, para .nc , .png, arquivos .pdf) ERDDAP™ tem que fazer todo o arquivo antes que a resposta possa ser enviada. Então... ERDDAP™ cache esses arquivos por um curto período de tempo. Se um pedido idêntico entrar (como muitas vezes faz, especialmente para imagens onde o URL é incorporado em uma página da web) , ERDDAP™ pode reutilizar esse arquivo em cache. Em um sistema de múltiplos idênticos ERDDAP s, esses arquivos em cache não são compartilhados, então cada ERDDAP™ desnecessariamente e desperdiçada recriar o .nc , .png, ou arquivos .pdf. Com o sistema federado descrito abaixo, os arquivos são feitos apenas uma vez, por um dos ERDDAP e reutilizado.
- ERDDAP O sistema de assinatura não está configurado para ser partilhado por vários ERDDAP S. Por exemplo, se o balanceador de carga enviar um usuário para um ERDDAP™ e o usuário assina um conjunto de dados, em seguida, o outro ERDDAP não estará ciente dessa assinatura. Mais tarde, se o balanceador de carga enviar o usuário para um diferente ERDDAP™ e pede uma lista de suas assinaturas, as outras ERDDAP™ vai dizer que não há nenhum (levando-o a fazer uma assinatura duplicada no outro ERED DAP ) . Com o sistema federado descrito abaixo, o sistema de assinatura é simplesmente tratado pelo principal, público, composto ERDDAP .
Sim, para cada um desses problemas, eu poderia (com grande esforço) projetar uma solução (para compartilhar as informações entre ERDDAP S) Mas acho que o Federação de... ERDDAP abordagem s (descrito na maior parte deste documento) é uma solução geral muito melhor, em parte porque lida com outros problemas que o múltiplo-identical- ERDDAP A abordagem do balanceador de carga nem sequer começa a abordar, nomeadamente a natureza descentralizada das fontes de dados no mundo.
É melhor aceitar o simples fato de que eu não projetar ERDDAP™ para ser implantado como múltiplos idênticos ERDDAP s com um balanceador de carga. Eu concebi conscientemente ERDDAP™ trabalhar bem dentro de uma federação de ERDDAP s, que eu acredito tem muitas vantagens. Notavelmente, uma federação de ERDDAP s está perfeitamente alinhado com o sistema descentralizado, distribuído de data centers que temos no mundo real (pense nas diferentes regiões do IOOS, ou nas diferentes regiões do CoastWatch, ou nas diferentes partes do NCEI, ou nos outros 100 centros de dados em NOAA , ou os diferentes DAACs da NASA, ou os 1000 de data centers em todo o mundo) . Em vez de dizer a todos os data centers do mundo que eles precisam abandonar seus esforços e colocar todos os seus dados em um "lago de dados" centralizado (mesmo se fosse possível, é uma ideia horrível por inúmeras razões -- veja as várias análises mostrando as inúmeras vantagens de sistemas descentralizados ) , ERDDAP 's design funciona com o mundo como é. Cada data center que produz dados pode continuar a manter, curar e servir seus dados (como eles deveriam) , e ainda, com ERDDAP™ , os dados também podem ser instantaneamente disponíveis a partir de um centralizado ERDDAP , sem a necessidade de transmitir os dados ao centralizado ERDDAP™ ou armazenar cópias duplicadas dos dados. Na verdade, um dado conjunto de dados pode estar simultaneamente disponível de um ERDDAP™ na organização que produziu e realmente armazena os dados (por exemplo, GoMOOS) , de um ERDDAP™ na organização pai (por exemplo, IOOS central) , de um tudo... NOAA ERDDAP™ , de um governo federal ERDDAP™ , de um global ERDDAP™ (GOOS) , e de especializado ERDDAP S (por exemplo, um ERDDAP™ em uma instituição dedicada à pesquisa HAB) , tudo essencialmente instantaneamente, e eficientemente porque apenas os metadados são transferidos entre ERDDAP s, não os dados. Melhor de tudo, após a inicial ERDDAP™ na organização originária, todas as outras ERDDAP s pode ser configurado rapidamente (algumas horas de trabalho) , com recursos mínimos (um servidor que não precisa de nenhum RAID para armazenamento de dados, uma vez que não armazena dados localmente) , e assim a um custo verdadeiramente mínimo. Compare isso com o custo de configuração e manutenção de um centro de dados centralizado com um lago de dados e a necessidade de uma conexão verdadeiramente maciça, verdadeiramente cara, Internet, além do problema participante do centro de dados centralizado ser um único ponto de falha. Para mim, ERDDAP a abordagem descentralizada, federada é muito, muito superior.
Em situações em que um determinado data center precisa de múltiplos ERDDAP s para atender a alta demanda, ERDDAP 's design é totalmente capaz de combinar ou superar o desempenho do múltiplo-identical- ERDDAP abordagem de equilíbrio de carga. Você sempre tem a opção de configurar múltiplos compostos ERDDAP S (como discutido abaixo) , cada um dos quais recebe todos os seus dados de outros ERDDAP s, sem balanceamento de carga. Neste caso, eu recomendo que você faça um ponto de dar cada um do composto ERDDAP s um nome diferente / identidade e se possível configurá-los em diferentes partes do mundo (por exemplo, diferentes regiões AWS) , por exemplo, ERD \_US\_East, ERD \_US\_West, ERD - Sim. ERD \_FR, ERD \_IT, de modo que os usuários conscientemente, repetidamente, trabalhar com um específico ERDDAP , com o benefício adicional que você removeu o risco de um único ponto de falha.
-
- Não.
Grades, Clusters e Federações
Sob uso muito pesado, um único standalone ERDDAP™ será executado em um ou mais dos restrições listados acima e mesmo as soluções sugeridas serão insuficientes. Para tais situações, ERDDAP™ tem recursos que facilitam a construção de grades escaláveis (também chamados clusters ou federações) de ERDDAP s que permitem que o sistema manuseie o uso muito pesado (por exemplo, para um grande data center) .
Estou a usar grade de grade como um termo geral para indicar um tipo de cluster de computador onde todas as partes podem ou não estar localizadas fisicamente em uma instalação e podem ou não ser administradas centralmente. Uma vantagem de redes co-localizadas, de propriedade central e administradas (clusters) é que eles se beneficiam de economias de escala (especialmente a carga de trabalho humana) e simplificar fazer as partes do sistema funcionar bem em conjunto. Uma vantagem de grades não-co-localizadas, não-centralmente de propriedade e administrada (federações) é que eles distribuem a carga de trabalho humana e o custo, e podem fornecer alguma tolerância adicional a falhas. A solução que proponho abaixo funciona bem para todas as topografias de grade, cluster e federação.
A ideia básica de projetar um sistema escalável é identificar os gargalos potenciais e, em seguida, projetar o sistema para que as partes do sistema possam ser replicadas conforme necessário para aliviar os gargalos. Idealmente, cada parte replicada aumenta a capacidade dessa parte do sistema linearmente (eficiência de dimensionamento) . O sistema não é escalável a menos que haja uma solução escalável para cada gargalo. Escalabilidade é diferente da eficiência (como rapidamente uma tarefa pode ser feita — eficiência das peças) . A escalabilidade permite que o sistema cresça para lidar com qualquer nível de demanda. Eficiência (de escalonamento e das peças) determina quantos servidores, etc., serão necessários para atender a um determinado nível de demanda. A eficiência é muito importante, mas sempre tem limites. A escalabilidade é a única solução prática para a construção de um sistema que possa lidar Muito bem. uso pesado. Idealmente, o sistema será escalável e eficiente.
Metas
Os objetivos deste projeto são:
- Para fazer uma arquitetura escalável (um que é facilmente extensível replicando qualquer parte que se torna over-burdened) . Para fazer um sistema eficiente que maximize a disponibilidade e a produtividade dos dados dados fornecidos aos recursos de computação disponíveis. (O custo é quase sempre um problema.)
- Para equilibrar as capacidades das partes do sistema para que uma parte do sistema não sobrecarregue outra parte.
- Fazer uma arquitetura simples para que o sistema seja fácil de configurar e administrar.
- Fazer uma arquitetura que funciona bem com todas as topografias da grade.
- Fazer um sistema que falha graciosamente e de uma forma limitada se alguma parte se torna sobrecarregado. (O tempo necessário para copiar um grande conjunto de dados sempre limitará a capacidade do sistema de lidar com aumentos repentinos na demanda por um conjunto de dados específico.)
- (Se possível) Para fazer uma arquitetura que não está ligada a nenhum específico computação em nuvem serviços ou outros serviços externos (porque não precisa deles) .
Recomendações
Nossas recomendações são
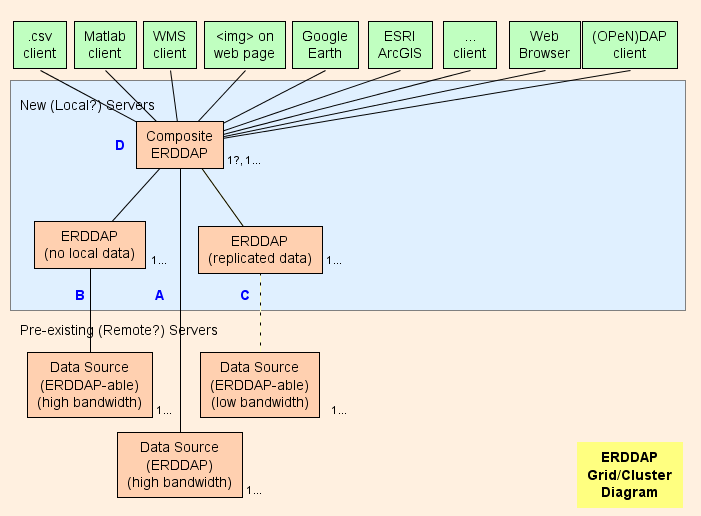
- Basicamente, sugiro configurar um Composto ERDDAP™ ( D no diagrama) , que é um regular ERDDAP™ exceto que apenas serve dados de outros ERDDAP S. A arquitetura da grade é projetada para mudar tanto trabalho quanto possível (Uso de CPU, uso de memória, uso de largura de banda) do Composto ERDDAP™ para o outro ERDDAP S.
- ERDDAP™ tem dois tipos especiais de conjuntos de dados, EDDGrid De Erddap e EDDTable FromErddap , que se referem a conjuntos de dados em outros ERDDAP S.
- Quando o composto ERDDAP™ recebe um pedido de dados ou imagens desses conjuntos de dados, o composto ERDDAP™ redirecionamentos o pedido de dados para o outro ERDDAP™ servidor. O resultado é:
- Isto é muito eficiente. (CPU, memória e largura de banda) , porque de outra forma
- O composto ERDDAP™ tem que enviar a solicitação de dados para o outro ERDDAP .
- O outro ERDDAP™ tem que obter os dados, reformatar e transmitir os dados para o composto ERDDAP .
- O composto ERDDAP™ tem de receber os dados (usando largura de banda extra) , reformatar (usando tempo e memória de CPU extra) , e transmitir os dados ao usuário (usando largura de banda extra) . Redirecionando o pedido de dados e permitindo o outro ERDDAP™ para enviar a resposta diretamente ao usuário, o composto ERDDAP™ gasta essencialmente nenhum tempo de CPU, memória ou largura de banda em solicitações de dados.
- O redirecionamento é transparente para o usuário, independentemente do software cliente (um navegador ou qualquer outro software ou ferramenta de linha de comando) .
- Isto é muito eficiente. (CPU, memória e largura de banda) , porque de outra forma
Peças de grade
A : Para cada fonte de dados remoto que tem uma largura de banda alta OPeNDAP servidor, você pode se conectar diretamente ao servidor remoto. Se o servidor remoto é um ERDDAP™ , uso EDDGrid De Erddap ou EDDTable De ERDDAP para servir os dados no Composite ERDDAP . Se o servidor remoto é outro tipo de DAP servidor, por exemplo, Hyrax , ou GrADS, use EDDGrid De Sabão.
B : Para cada ERDDAP - fonte de dados possível (uma fonte de dados a partir da qual ERDDAP pode ler dados) que tem um servidor de alta largura de banda, configure outro ERDDAP™ na grade que é responsável por servir os dados a partir desta fonte de dados.
- Se vários desses ERDDAP s não estão recebendo muitos pedidos de dados, você pode consolá-los em um ERDDAP .
- Se o ERDDAP™ dedicado a obter dados de uma fonte remota está recebendo muitos pedidos, há uma tentação de adicionar mais ERDDAP s para acessar a fonte de dados remota. Em casos especiais isso pode fazer sentido, mas é mais provável que isso irá sobrecarregar a fonte de dados remota (que é auto-destruição) e também evitar que outros usuários acessem a fonte de dados remota (que não é agradável) . Neste caso, considere a criação de outro ERDDAP™ para servir esse conjunto de dados e copiar o conjunto de dados sobre isso ERDDAP disco rígido (ver C ) , talvez com EDDGrid Entendido. e/ou EDDTableCopy .
- B servidores devem ser acessíveis publicamente.
C : Para cada ERDDAP - fonte de dados que tem um servidor de baixa largura de banda (ou é um serviço lento por outras razões) , considerar a criação de outro ERDDAP™ e armazenar uma cópia do conjunto de dados sobre isso ERDDAP discos rígidos, talvez com EDDGrid Entendido. e/ou EDDTableCopy . Se vários desses ERDDAP s não estão recebendo muitos pedidos de dados, você pode consolá-los em um ERDDAP . C servidores devem ser acessíveis publicamente.
Composto ERDDAP
D : O composto ERDDAP™ é normal ERDDAP™ exceto que apenas serve dados de outros ERDDAP S.
- Porque o composto ERDDAP™ tem informações em memória sobre todos os conjuntos de dados, ele pode responder rapidamente a pedidos de listas de conjuntos de dados (pesquisa de texto completo, pesquisa de categoria, a lista de todos os conjuntos de dados) , e solicitações para o formulário de acesso de dados de um conjunto de dados individual, Faça um formulário gráfico, ou WMS página de informações. Estas são todas as páginas HTML pequenas, dinamicamente geradas com base em informações que são mantidas em memória. Então as respostas são muito rápidas.
- Porque os pedidos de dados reais são rapidamente redirecionados para o outro ERDDAP s, o composto ERDDAP™ pode responder rapidamente a pedidos de dados reais sem usar qualquer tempo de CPU, memória ou largura de banda.
- Ao mudar tanto trabalho quanto possível (CPU, memória, largura de banda) do Composto ERDDAP™ para o outro ERDDAP s, o composto ERDDAP™ pode parecer servir dados de todos os conjuntos de dados e ainda manter-se com um grande número de pedidos de dados de um grande número de usuários.
- Os testes preliminares indicam que o composto ERDDAP™ pode responder à maioria dos pedidos em ~1ms de tempo de CPU, ou 1000 pedidos / segundo. Assim, um processador de 8 núcleos deve ser capaz de responder a cerca de 8000 pedidos/segundo. Embora seja possível prever explosões de atividade mais elevada que causaria desaceleração, isso é muito de rendimento. É provável que a largura de banda do data center seja o gargalo muito antes do composto ERDDAP™ torna-se o gargalo.
Máximo actualizado (Tempo) ?
O EDDGrid /TableFromErddap no composto ERDDAP™ apenas muda suas informações armazenadas sobre cada conjunto de dados de origem quando o conjunto de dados de origem é "recarregar" e algumas mudanças de metadados (por exemplo, a variável de tempo actual\_range ) , gerando assim uma notificação de assinatura. Se o conjunto de dados de origem tiver dados que mudam frequentemente (por exemplo, novos dados a cada segundo) e usa o "update" sistema para notar mudanças freqüentes nos dados subjacentes, o EDDGrid /TableFromErddap não será notificado sobre essas mudanças frequentes até que o próximo conjunto de dados "recarregar", de modo que o EDDGrid /TableFromErddap não estará perfeitamente atualizado. Você pode minimizar esse problema alterando o conjunto de dados de origem<reloadEveryNMinutes > a um valor menor (60? 15?) para que haja mais notificações de assinatura para dizer o EDDGrid /TableFromErddap para atualizar suas informações sobre o conjunto de dados de origem.
Ou, se o seu sistema de gerenciamento de dados souber quando o conjunto de dados de origem tem novos dados (por exemplo, através de um script que copia um arquivo de dados no lugar) , e se isso não é super frequente (por exemplo, a cada 5 minutos, ou menos frequentes) Há uma solução melhor:
- Não use<updateEveryNMillis> para manter o conjunto de dados de origem atualizado.
- Defina o conjunto de dados de origem<reloadEveryNMinutes > para um número maior (1440?) .
- Tenha o script em contato com o conjunto de dados de origem URL da bandeira logo após ele copia um novo arquivo de dados no lugar. Isso levará ao conjunto de dados de origem perfeitamente atualizado e fará com que ele gere uma notificação de assinatura, que será enviada para a EDDGrid /TableFromErddap conjunto de dados. Isso vai liderar o EDDGrid /TableFromErddap dataset para estar perfeitamente atualizado (bem, dentro de 5 segundos de novos dados sendo adicionados) . E tudo o que será feito de forma eficiente (sem recargas de dados desnecessários) .
Vários compostos ERDDAP S
- Em casos muito extremos, ou para tolerância a falhas, você pode querer configurar mais de um composto ERDDAP . É provável que outras partes do sistema (notavelmente, a largura de banda do data center) vai se tornar um problema muito antes do composto ERDDAP™ torna-se um gargalo. Assim, a solução é provavelmente para configurar centros de dados adicionais, geograficamente diversos (espelhos) , cada um com um composto ERDDAP™ e servidores com ERDDAP e (pelo menos) cópias de espelho dos conjuntos de dados que estão em alta demanda. Tal configuração também fornece tolerância a falhas e backup de dados (através da cópia) . Neste caso, é melhor se o composto ERDDAP s tem URLs diferentes.
Se você realmente quer todo o composto ERDDAP s para ter a mesma URL, use um sistema front-end que atribui um determinado usuário a apenas um dos compostos ERDDAP S (com base no endereço IP) , para que todas as solicitações do usuário ir para apenas um dos compostos ERDDAP S. Há duas razões:
- Quando um conjunto de dados subjacente é recarregado e os metadados mudam (por exemplo, um novo arquivo de dados em um conjunto de dados gradeado causa a variável de tempo actual\_range mudar) , o composto ERDDAP s será temporariamente ligeiramente fora de sincronia, mas com eventual consistência . Normalmente, eles vão re-sincronizar dentro de 5 segundos, mas às vezes será mais longo. Se um usuário fizer um sistema automatizado que depende ERDDAP™ assinaturas que desencadear ações, os breves problemas de sincronização se tornarão significativos.
- O composto 2+ ERDDAP s cada manter seu próprio conjunto de assinaturas (por causa do problema de sincronização descrito acima) .
Então um determinado usuário deve ser direcionado para apenas um dos compostos ERDDAP para evitar esses problemas. Se um dos compostos ERDDAP s vai para baixo, o sistema front-end pode redirecionar que ERDDAP Os usuários para outro ERDDAP™ Acabou. No entanto, se é um problema de capacidade que causa o primeiro composto ERDDAP™ para falhar (um usuário superzeloso? um ataque de negação de serviço ?) , isso torna muito provável que redirecionando seus usuários para outro composto ERDDAP s causará um falha em cascata . Assim, a configuração mais robusta é ter composto ERDDAP s com URLs diferentes.
Ou, talvez melhor, configurar múltiplos compostos ERDDAP s sem balanceamento de carga. Neste caso, você deve fazer um ponto de dar a cada um dos ERDDAP s um nome diferente / identidade e se possível configurá-los em diferentes partes do mundo (por exemplo, diferentes regiões AWS) , por exemplo, ERD \_US\_East, ERD \_US\_West, ERD - Sim. ERD \_FR, ERD \_IT, de modo que os usuários conscientemente, repetidamente trabalhar com um específico ERDDAP .
- \[ Para um design fascinante de um sistema de alto desempenho em execução em um servidor, consulte este descrição detalhada do Mailinator . \]
Conjuntos de dados em demanda muito alta
No caso realmente incomum que um dos A , B ou C ERDDAP s não pode acompanhar as solicitações por causa de limitações de largura de banda ou disco rígido, faz sentido copiar os dados (Outra vez.) para outro servidor+hard Drive+ ERDDAP , talvez com EDDGrid Entendido. e/ou EDDTableCopy . Embora possa parecer ideal ter o conjunto de dados original e o conjunto de dados copiado aparecer perfeitamente como um conjunto de dados no composto ERDDAP™ , isso é difícil porque os dois conjuntos de dados estarão em estados ligeiramente diferentes em diferentes momentos (notavelmente, depois que o original recebe novos dados, mas antes que o conjunto de dados copiado recebe sua cópia) . Portanto, eu recomendo que os conjuntos de dados sejam dados títulos ligeiramente diferentes (por exemplo, "... (cópia #1) "e "... (cópia #2) ", ou talvez " (espelho n ) "ou " (servidor n ) ") e aparecem como conjuntos de dados separados no composto ERDDAP . Os usuários são usados para ver listas de sites espelho em sites de download de arquivos populares, então isso não deve surpreendê-los ou decepcioná-los. Por causa das limitações de largura de banda em um determinado site, pode fazer sentido ter o espelho localizado em outro site. Se a cópia do espelho estiver em um data center diferente, acessada apenas pelo composto daquele data center ERDDAP™ , os diferentes títulos (por exemplo, "espelho #1) Não é necessário.
RAIDs versus discos rígidos regulares
Se um grande conjunto de dados ou um grupo de conjuntos de dados não forem fortemente usados, pode fazer sentido armazenar os dados em um RAID uma vez que oferece tolerância a falhas e uma vez que você não precisa do poder de processamento ou largura de banda de outro servidor. Mas se um conjunto de dados é fortemente usado, pode fazer mais sentido copiar os dados em outro servidor + ERDDAP™ + disco rígido (similar a o que o Google faz ) em vez de usar um servidor e um RAID para armazenar vários conjuntos de dados desde que você começa a usar tanto server+hardDrive+ ERDDAP está na grelha até um deles falhar.
Infracções
O que acontece se...
- Há uma explosão de pedidos para um conjunto de dados (por exemplo, todos os alunos de uma classe simultaneamente solicitam dados semelhantes) ? Só o ERDDAP™ servir esse conjunto de dados será esmagado e retardar ou recusar solicitações. O composto ERDDAP™ e outros ERDDAP Não será afectada. Como o fator limitante para um dado conjunto de dados dentro do sistema é o disco rígido com os dados (não ERDDAP ) , a única solução (não imediata) é fazer uma cópia do conjunto de dados em um servidor diferente+hardDrive+ ERDDAP .
- Um A , B ou C ERDDAP™ falha (por exemplo, falha no disco rígido) ? Apenas o conjunto de dados (S) servido por isso ERDDAP™ são afetados. Se o conjunto de dados (S) é espelhado em outro servidor+hardDrive+ ERDDAP , o efeito é mínimo. Se o problema for uma falha no disco rígido em um nível 5 ou 6 RAID, basta substituir a unidade e ter o RAID reconstruir os dados na unidade.
- O composto ERDDAP™ falha? Se você quiser fazer um sistema com muito alta disponibilidade , você pode configurar múltiplos compostos ERDDAP S (como discutido acima) usando algo como NGINX ou Traefik para lidar com balanceamento de carga. Note que um dado composto ERDDAP™ pode lidar com um grande número de pedidos de um grande número de usuários, porque pedidos de metadados são pequenos e são tratados por informações que estão em memória, e pedidos de dados (que pode ser grande) são redirecionados para a criança ERDDAP S.
Simples, escalável
Este sistema é fácil de configurar e administrar, e facilmente extensível quando qualquer parte dele se torna over-burdened. As únicas limitações reais para um dado data center são a largura de banda do data center e o custo do sistema.
Largura de banda
Note a largura de banda aproximada de componentes comumente usados do sistema:
| Componente | Largura de banda aproximada (GBytes/s) | | -... | -... | | Memória DDR | 2.5. | | unidade SSD | 1 | | Disco rígido SATA | 0 | | Gigabit Ethernet | 0.1 | | OC-12 | 0,06 | | OC-3 | 0,015 | | T1 | 0,0002 |
Então, um disco rígido SATA (0,3GB/s) em um servidor com um ERDDAP™ pode provavelmente saturar uma LAN Gigabit Ethernet (0.1GB/s) . E uma LAN Ethernet Gigabit (0.1GB/s) pode provavelmente saturar uma conexão de Internet OC-12 (0.06GB/s) . E pelo menos uma fonte lista linhas OC-12 custando cerca de $100.000 por mês. (Sim, esses cálculos são baseados em empurrar o sistema para seus limites, o que não é bom porque leva a respostas muito lentos. Mas esses cálculos são úteis para o planejamento e para equilibrar partes do sistema.) Claramente, uma conexão de Internet convenientemente rápida para o seu data center é de longe a parte mais cara do sistema. Você pode facilmente e relativamente barato construir uma grade com uma dúzia de servidores executando uma dúzia ERDDAP s que é capaz de bombear muitos dados rapidamente, mas uma conexão de Internet convenientemente rápida será muito, muito caro. As soluções parciais são:
- Encoraje os clientes a solicitar subconjuntos dos dados se isso for necessário. Se o cliente só precisa de dados para uma pequena região ou em uma resolução mais baixa, é isso que eles devem solicitar. A subconfiguração é um foco central dos protocolos ERDDAP™ suportes para solicitar dados.
- Incentivar a transmissão de dados comprimidos. ERDDAP™ Comprimentos uma transmissão de dados se ele encontrar "aceitar-codificação" no HTTP GET solicitar cabeçalho. Todos os navegadores usam "aceitar-codificação" e descomprimir automaticamente a resposta. Outros clientes (por exemplo, programas de computador) tem que usá-lo explicitamente.
- Colocar seus servidores em um ISP ou outro site que oferece custos de largura de banda relativamente menos caros.
- Disperse os servidores com o ERDDAP a diferentes instituições para que os custos sejam dispersos. Você pode ligar seu composto ERDDAP™ para a sua ERDDAP S.
Note que Computação em nuvem e serviços de hospedagem web oferecem toda a largura de banda de Internet que você precisa, mas não resolver o problema do preço.
Para obter informações gerais sobre a concepção de sistemas escaláveis, de alta capacidade, tolerantes a falhas, consulte o livro de Michael T. Nygard Solte-o. .
Como o Legos
Designers de software muitas vezes tentam usar bom padrões de design de software resolver problemas. Bons padrões são bons porque eles encapsulam boas, fáceis de criar e trabalhar com, soluções de uso geral que levam a sistemas com boas propriedades. Nomes padrão não são padronizados, então eu vou chamar o padrão que ERDDAP™ usa o padrão Lego. Cada Lego (cada um ERDDAP ) é um simples, pequeno, padrão, stand-alone, tijolo (servidor de dados) com uma interface definida que permite que ele seja ligado a outros legos ( ERDDAP S) . As partes de ERDDAP™ que compõem este sistema são: os sistemas de assinatura e bandeiraURL (que permite a comunicação entre ERDDAP S) O EDD... sistema de redirecionamento FromErddap, e o sistema de RESTful pedidos de dados que podem ser gerados por usuários ou outros ERDDAP S. Assim, dado dois ou mais legos ( ERDDAP S) , você pode criar um grande número de formas diferentes (topologias de rede ERDDAP S) . Claro, o design e as características de ERDDAP™ poderia ter sido feito de forma diferente, não como Lego, talvez apenas para permitir e otimizar para uma topologia específica. Mas nós sentimos que ERDDAP 's Lego-like design oferece uma boa, solução de uso geral que permite qualquer ERDDAP™ administrador (ou grupo de administradores) criar todos os tipos de topologias de federação diferentes. Por exemplo, uma única organização poderia criar três (ou mais) ERDDAP s como mostrado no ERDDAP™ Diagrama de grade/colaster acima . Ou um grupo distribuído (IOOS? CoastWatch? NCEI? NWS? NOAA ? USGS? DataONE? NEON? Mais tarde? OOI? BODC? ONC? JRC? WMO?) pode configurar um ERDDAP™ em cada pequeno posto avançado (para que os dados possam ficar perto da fonte) e, em seguida, configurar um composto ERDDAP™ no escritório central com conjuntos de dados virtuais (que estão sempre perfeitamente atualizados) de cada um dos pequenos postos avançados ERDDAP S. De facto, todos os ERDDAP s, instalado em várias instituições em todo o mundo, que obtém dados de outros ERDDAP s e/ou fornecer dados para outros ERDDAP s, formar uma rede gigante de ERDDAP S. Que fixe é isso?! Assim, como no Lego's, as possibilidades são infinitas. É por isso que este é um bom padrão. É por isso que este é um bom design para ERDDAP .
Diferentes tipos de pedidos
Uma das complicações da vida real desta discussão de topologias de servidores de dados é que existem diferentes tipos de pedidos e diferentes formas de otimizar para os diferentes tipos de pedidos. Esta é principalmente uma questão separada (Quão rápido pode o ERDDAP™ com os dados respondem à solicitação de dados?) da discussão de topologia (que lida com as relações entre servidores de dados e que servidor tem os dados reais) . ERDDAP™ , é claro, tenta lidar com todos os tipos de pedidos de forma eficiente, mas lida com alguns melhores do que outros.
- Muitos pedidos são simples. Por exemplo: Quais são os metadados para este conjunto de dados? Ou: Quais são os valores da dimensão do tempo para este conjunto de dados grelhados? ERDDAP™ é projetado para lidar com estes o mais rápido possível (geralmente em<= 2 ms) mantendo esta informação em memória.
- Alguns pedidos são moderadamente difíceis. Por exemplo: Dê-me este subconjunto de um conjunto de dados (que está em um arquivo de dados) . Estas solicitações podem ser tratadas relativamente rapidamente porque não são tão difíceis.
- Alguns pedidos são difíceis e, portanto, são demorados. Por exemplo: Dê-me este subconjunto de um conjunto de dados (que pode estar em qualquer um dos mais de 10.000 arquivos de dados, ou pode ser de arquivos de dados compactados que cada um leva 10 segundos para descomprimir) . ERDDAP™ O v2.0 introduziu algumas novas formas mais rápidas de lidar com esses pedidos, nomeadamente permitindo que o segmento de manuseamento de pedidos desova vários fios de trabalhadores que abordam diferentes subconjuntos do pedido. Mas há uma outra abordagem deste problema que ERDDAP™ ainda não suporta: subconjuntos dos arquivos de dados para um determinado conjunto de dados podem ser armazenados e analisados em computadores separados e, em seguida, os resultados combinados no servidor original. Esta abordagem é chamada Mapa e é exemplificado por Hadoop , o primeiro (?) open-source programa MapReduce, que foi baseado em ideias de um papel do Google. (Se você precisar MapReduce in ERDDAP , por favor envie um pedido de e-mail para erd.data at noaa.gov .) Google BigQuery. é interessante porque parece ser uma implementação do MapReduce aplicado para subconfigurar conjuntos de dados tabulares, que é um dos ERDDAP Os principais objetivos. É provável que você possa criar um ERDDAP™ dataset de um conjunto de dados BigQuery via EDDTable FromDatabase porque BigQuery pode ser acessado através de uma interface JDBC.
Estas são as minhas opiniões.
Sim, os cálculos são simplistas (e agora ligeiramente datado) , mas acho que as conclusões estão correctas. Eu usei lógica defeituosa ou cometi um erro nos meus cálculos? Se assim for, a culpa é minha sozinha. Por favor envie um e-mail com a correção para erd dot data at noaa dot gov .
-
- Não.
Computação em nuvem
Várias empresas oferecem serviços de computação em nuvem (por exemplo, Amazon Web Services e Plataforma de nuvem do Google ) . Empresas de hospedagem web ofereceram serviços mais simples desde meados da década de 1990, mas os serviços "nuvem" expandiram consideravelmente a flexibilidade dos sistemas e a gama de serviços oferecidos. Desde o ERDDAP™ grade apenas consiste em ERDDAP e desde ERDDAP s são Java aplicações web que podem ser executadas em Tomcat (o servidor de aplicativos mais comum) ou outros servidores de aplicativos, deve ser relativamente fácil configurar um ERDDAP™ grade em um serviço de nuvem ou web hosting site. As vantagens destes serviços são:
- Eles oferecem acesso a conexões de Internet de largura de banda muito alta. Só isso pode justificar a utilização destes serviços.
- Eles cobram apenas pelos serviços que você usa. Por exemplo, você tem acesso a uma conexão de Internet de largura de banda muito alta, mas você só paga por dados reais transferidos. Isso permite que você construa um sistema que raramente fica sobrecarregado (mesmo na demanda de pico) , sem ter que pagar por capacidade que raramente é usado.
- Eles são facilmente extensíveis. Você pode alterar tipos de servidor ou adicionar tantos servidores ou quanto desejar, em menos de um minuto. Só isso pode justificar a utilização destes serviços.
- Eles o libertam de muitos dos deveres administrativos de executar os servidores e redes. Só isso pode justificar a utilização destes serviços.
As desvantagens destes serviços são:
- Eles cobram por seus serviços, às vezes muito (em termos absolutos; não que não seja um bom valor) . Os preços listados aqui são para Amazon EC2 . Estes preços (a partir de junho 2015) vai descer.
No passado, os preços eram maiores, mas os arquivos de dados e o número de pedidos eram menores.
No futuro, os preços serão mais baixos, mas os arquivos de dados e o número de pedidos serão maiores.
Então os detalhes mudam, mas a situação permanece relativamente constante.
E não é que o serviço é muito caro, é que estamos usando e comprando muito do serviço.
- Transferência de dados — Transferências de dados no sistema são agora gratuitas (Sim!) . Transferências de dados fora do sistema são $0.09 / GB. Um disco rígido SATA (0,3GB/s) em um servidor com um ERDDAP™ pode provavelmente saturar uma LAN Gigabit Ethernet (0.1GB/s) . Uma LAN Ethernet Gigabit (0.1GB/s) pode provavelmente saturar uma conexão de Internet OC-12 (0.06GB/s) . Se uma conexão OC-12 puder transmitir ~ 150,000 GB / mês, os custos de transferência de dados podem ser de até 150,000 GB @ $0.09/GB = $13,500 / mês, o que é um custo significativo. Claramente, se você tem uma dúzia de trabalho duro ERDDAP s em um serviço de nuvem, suas taxas mensais de transferência de dados podem ser substanciais (até $162,000/mês) . (Novamente, não é que o serviço é super caro, é que estamos usando e comprando um monte do serviço.)
- Armazenamento de dados — Amazon cobra $50/mês por TB. (Compare isso com a compra de uma unidade empresarial 4TB diretamente por ~ $ 50 / TB, embora o RAID para colocá-lo e os custos administrativos adicionar ao custo total.) Então, se você precisa armazenar muitos dados na nuvem, pode ser bastante caro (por exemplo, 100TB custaria $5000 / mês) . Mas a menos que você tenha uma grande quantidade de dados, este é um problema menor do que os custos de transferência de largura de banda / dados. (Novamente, não é que o serviço é super caro, é que estamos usando e comprando um monte do serviço.)
Subconfiguração
- O problema de subconfiguração: A única maneira de distribuir eficientemente dados de arquivos de dados é ter o programa que está distribuindo os dados (por exemplo, ERDDAP ) executando em um servidor que tem os dados armazenados em um disco rígido local (ou acesso rápido a uma SAN ou RAID local) . Sistemas de arquivos locais permitem ERDDAP™ (e bibliotecas subjacentes, como netcdf-java) para solicitar intervalos de byte específicos dos arquivos e obter respostas muito rapidamente. Muitos tipos de solicitações de dados de ERDDAP™ para o arquivo (nomeadamente solicitações de dados em rede quando o valor do passo é > 1) não pode ser feito de forma eficiente se o programa tem que solicitar todo o arquivo ou grandes pedaços de um arquivo de um não-local (daí mais devagar) sistema de armazenamento de dados e, em seguida, extrair um subconjunto. Se a configuração da nuvem não dá ERDDAP™ acesso rápido a intervalos de byte dos arquivos (tão rápido como com arquivos locais) , ERDDAP O acesso aos dados será um gargalo grave e nega outros benefícios de usar um serviço de nuvem.
Dados hospedados
Uma alternativa à análise de benefícios de custo acima (que é baseado no proprietário de dados (por exemplo, NOAA ) pagando por seus dados a serem armazenados na nuvem) chegou em torno de 2012, quando Amazon (e em menor medida, alguns outros provedores de nuvem) começou a hospedar alguns conjuntos de dados em sua nuvem (AWS S3) de graça (presumivelmente com a esperança de que eles pudessem recuperar seus custos se os usuários alugariam instâncias de computação AWS EC2 para trabalhar com esses dados) . Claramente, isso torna a computação em nuvem muito mais rentável, porque o tempo e custo-up upload dos dados e hospedagem agora são zero. Com ERDDAP™ v2.0, existem novos recursos para facilitar a execução ERDDAP em uma nuvem:
- Agora, um EDDGrid FromFiles ou EDDTableFromFiles dataset pode ser criado a partir de arquivos de dados que são remotos e acessíveis através da internet (por exemplo, baldes AWS S3) usando o<cacheDeUrl> e<tamanho do cache GB > opções. ERDDAP™ manterá um cache local dos arquivos de dados mais usados recentemente.
- Agora, se algum arquivo de origem EDDTableFromFiles for compactado (por exemplo, .tgz ) , ERDDAP™ irá descomprimir automaticamente quando lê-los.
- Agora, o ERDDAP™ a resposta de rosca a uma determinada solicitação gerará threads para trabalhar em subseções do pedido se você usar o<nThreads > opções. Esta paralelização deve permitir respostas mais rápidas a pedidos difíceis.
Essas mudanças resolvem o problema de AWS S3 não oferecer armazenamento de arquivos local, nível de bloco e o (velho) problema de acesso a dados S3 com um atraso significativo. (Anos atrás (~ 2014) , esse atraso foi significativo, mas agora é muito mais curto e assim não tão significativo.) Tudo em tudo, significa que a configuração ERDDAP™ na nuvem funciona muito melhor agora.
Obrigado. — Muito obrigado a Matthew Arrott e seu grupo no esforço original da OOI para o seu trabalho em colocar ERDDAP™ na nuvem e as discussões resultantes.
-
- Não.
Replicação remota de conjuntos de dados
Há um problema comum relacionado com a discussão acima de grades e federações de ERDDAP s: replicação remota de conjuntos de dados. O problema básico é: um provedor de dados mantém um conjunto de dados que muda ocasionalmente e um usuário quer manter uma cópia local atualizada deste conjunto de dados (para qualquer uma das várias razões) . Claramente, há um grande número de variações disso. Algumas variações são muito mais difíceis de lidar do que outras.
- Atualizações rápidas É mais difícil manter os dados locais atualizados imediatamente imediatamente. (por exemplo, dentro de 3 segundos) depois de cada mudança para a fonte, em vez de, por exemplo, dentro de algumas horas.
- Mudanças frequentes As mudanças frequentes são mais difíceis de lidar do que as mudanças pouco frequentes. Por exemplo, uma vez por dia as mudanças são muito mais fáceis de lidar do que as mudanças a cada 0,1 segundo.
- Pequenas mudanças Pequenas mudanças em um arquivo de origem são mais difíceis de lidar do que um arquivo totalmente novo. Isso é especialmente verdade se as pequenas mudanças podem estar em qualquer lugar do arquivo. Pequenas mudanças são mais difíceis de detectar e tornar difícil isolar os dados que precisam ser replicados. Novos arquivos são fáceis de detectar e eficientes para transferir.
- Conjunto de dados completo Manter um conjunto de dados completo atualizado é mais difícil do que manter apenas dados recentes. Alguns usuários apenas precisam de dados recentes (Por exemplo, o último vale de 8 dias) .
- Múltiplas cópias Manter várias cópias remotas em diferentes sites é mais difícil do que manter uma cópia remota. Este é o problema do escalonamento.
Há, obviamente, um grande número de variações de tipos possíveis de mudanças no conjunto de dados de origem e das necessidades e expectativas do usuário. Muitas das variações são muito difíceis de resolver. A melhor solução para uma situação muitas vezes não é a melhor solução para outra situação — ainda não há uma grande solução universal.
Relevante ERDDAP™ Ferramentas
ERDDAP™ oferece várias ferramentas que podem ser usadas como parte de um sistema que busca manter uma cópia remota de um conjunto de dados:
- ERDDAP ' RSS (Rich Site Sumário?) serviço
oferece uma maneira rápida de verificar se um conjunto de dados em um remoto ERDDAP™ mudou. - ERDDAP ' serviço de assinatura
é mais eficiente (do que RSS ) abordagem: enviará imediatamente um e-mail ou entrará em contato com um URL para cada assinante sempre que o conjunto de dados for atualizado e a atualização resultou em uma mudança. É eficiente em que acontece o mais rápido possível e não há esforço desperdiçado (como com sondagem um RSS serviço) . Os usuários podem usar outras ferramentas (Tipo... IFTTT ) para reagir às notificações por e-mail do sistema de assinatura. Por exemplo, um usuário pode assinar um conjunto de dados em um remoto ERDDAP™ e use o IFTTT para reagir às notificações por e-mail de assinatura e ativar a atualização do conjunto de dados local. - ERDDAP ' sistema de bandeira
fornece uma maneira para um ERDDAP™ administrador para contar um conjunto de dados em seu / her ERDDAP para recarregar o mais rápido possível. A forma de URL de uma bandeira pode ser facilmente usada em scripts. O formulário URL de uma bandeira também pode ser usado como a ação para uma assinatura. - ERDDAP ' "files" sistema
pode oferecer acesso aos arquivos de origem para um determinado conjunto de dados, incluindo uma lista de diretórios no estilo Apache dos arquivos (um "Web Accessible Folder") que tem URL de download de cada arquivo, última vez modificada e tamanho. Uma desvantagem de usar o "files" sistema é que os arquivos de origem podem ter diferentes nomes variáveis e diferentes metadados do que o conjunto de dados como ele aparece em ERDDAP . Se um remoto ERDDAP™ dataset oferece acesso a seus arquivos de origem, que abre a possibilidade de uma versão de rsync de homem pobre: torna-se fácil para um sistema local para ver quais arquivos remotos mudaram e precisam ser baixados. (Ver opção cacheFromUrl abaixo que pode fazer uso disto.)
Soluções
Embora existam um grande número de variações para o problema e um número infinito de possíveis soluções, há apenas um punhado de abordagens básicas para soluções:
Personalizado, Brute Force Solutions
Uma solução óbvia é criar uma solução personalizada, que é, portanto, otimizada para uma determinada situação: fazer um sistema que detecta/identifica quais dados mudaram e envia essas informações ao usuário para que o usuário possa solicitar os dados alterados. Bem, você pode fazer isso, mas há desvantagens:
- Soluções personalizadas são muito trabalho.
- As soluções personalizadas são geralmente tão personalizadas para um dado conjunto de dados e dado o sistema do usuário que eles não podem facilmente ser reutilizados.
- As soluções personalizadas têm de ser construídas e mantidas por você. (Isso nunca é uma boa ideia. É sempre uma boa ideia evitar o trabalho e arranjar outra pessoa para fazer o trabalho!)
Eu desencorajo a tomar essa abordagem porque é quase sempre melhor procurar soluções gerais, construídas e mantidas por outra pessoa, que pode ser facilmente reutilizada em situações diferentes.
rsync
rsync é a solução existente, surpreendentemente boa, de propósito geral para manter uma coleção de arquivos em um computador de origem em sincronia no computador remoto de um usuário. A forma como funciona é:
- algum evento (por exemplo, um ERDDAP™ evento do sistema de assinatura) gatilhos executando rsync, (ou, um trabalho cron executa rsync em horários específicos todos os dias no computador do usuário)
- que contatos rsync no computador de origem,
- que calcula uma série de hashes para pedaços de cada arquivo e transmite esses hashes para o rsync do usuário,
- que compara essas informações com as informações semelhantes para a cópia do usuário dos arquivos,
- que então pede os pedaços de arquivos que mudaram.
Considerando tudo o que faz, o rsync opera muito rapidamente (por exemplo, 10 segundos mais tempo de transferência de dados) e muito eficiente. Há variações de rsync que otimizam para situações diferentes (por exemplo, precalculando e caching os hashes dos pedaços de cada arquivo de origem) .
As principais fraquezas do rsync são: é preciso algum esforço para configurar (questões de segurança) ; há alguns problemas de escala; e não é bom para manter os conjuntos de dados NRT realmente atualizados (por exemplo, é estranho usar o rsync mais do que a cada 5 minutos) . Se você pode lidar com as fraquezas, ou se eles não afetam sua situação, o rsync é uma excelente solução de propósito geral que qualquer pessoa pode usar agora para resolver muitos cenários envolvendo replicação remota de conjuntos de dados.
Há um item no ERDDAP™ Para fazer lista para tentar adicionar suporte para serviços rsync para ERDDAP (provavelmente uma tarefa bastante difícil) , para que qualquer cliente possa usar rsync (ou uma variante) para manter uma cópia atualizada de um conjunto de dados. Se alguém quiser trabalhar nisso, por favor envie um e-mail erd.data at noaa.gov .
Existem outros programas que fazem mais ou menos o que o rsync faz, às vezes orientado para a replicação de conjuntos de dados (embora muitas vezes em um nível de cópia de arquivo) , por exemplo, Unidata ' IDD .
Cache De Url
O cache FromUrl configuração está disponível (começar com ERDDAP™ v2.0) para todos ERDDAP Os tipos de conjuntos de dados que fazem conjuntos de dados de arquivos (basicamente, todas as subclasses de EDDGrid Dos quartos e Tabela EDD dos arquivos ) . cache FromUrl torna trivial para baixar automaticamente e manter os arquivos de dados locais copiando-os de uma fonte remota via cache Da configuração Url. Os arquivos remotos podem estar em uma Pasta Acessível Web ou uma lista de arquivos como diretório oferecida pelo THREDDS, Hyrax , um balde S3, ou ERDDAP ' "files" sistema.
Se a fonte dos arquivos remotos é um remoto ERDDAP™ dataset que oferece os arquivos de origem através do ERDDAP™ "files" sistema, então você pode Assinar para o conjunto de dados remoto, e usar o URL da bandeira para o seu conjunto de dados local como ação para a assinatura. Então, sempre que o conjunto de dados remoto mudar, ele entrará em contato com a URL da bandeira para seu conjunto de dados, o que lhe dirá para recarregar ASAP, que irá detectar e baixar os arquivos de dados remotos alterados. Tudo isso acontece muito rapidamente (geralmente ~5 segundos mais o tempo necessário para baixar os arquivos alterados) . Esta abordagem funciona muito bem se as alterações de conjunto de dados de origem são novos arquivos sendo adicionados periodicamente e quando os arquivos existentes nunca mudam. Esta abordagem não funciona bem se os dados são frequentemente anexados a todos (ou mais) dos arquivos de dados de origem existentes, porque então seu conjunto de dados local está frequentemente baixando todo o conjunto de dados remotos. (É aqui que uma abordagem semelhante a rsync é necessária.)
ArquivoADataset
ERDDAP™ ' ArquivoADataset é uma boa solução quando os dados são adicionados a um conjunto de dados com freqüência, mas os dados mais antigos nunca são alterados. Basicamente, um ERDDAP™ administrador pode executar o ArchiveADataset (talvez em um script, talvez executado por cron) e especifique um subconjunto de um conjunto de dados que eles querem extrair (talvez em vários arquivos) e pacote em um .zip ou .tgz arquivo, para que você possa enviar o arquivo para pessoas ou grupos interessados (por exemplo, NCEI para arquivamento) ou torná-lo disponível para download. Por exemplo, você poderia executar o ArchiveADataset todos os dias às 12:10 e tê-lo feito um .zip de todos os dados das 12:00h no dia anterior até as 12:00h hoje. (Ou, faça isso semanal, mensal ou anual, conforme necessário.) Como o arquivo embalado é gerado off-line, não há perigo de um timeout ou muitos dados, como haveria para um padrão ERDDAP™ pedido.
ERDDAP™ Sistema de solicitação padrão
ERDDAP™ O sistema de solicitação padrão é uma boa solução alternativa quando os dados são adicionados a um conjunto de dados com freqüência, mas os dados mais antigos nunca são alterados. Basicamente, qualquer pessoa pode usar solicitações padrão para obter dados para uma gama específica de tempo. Por exemplo, às 12:10 do dia-a-dia, você pode fazer um pedido para todos os dados de um conjunto de dados remoto das 12:00 da manhã no dia anterior até as 12:00 da manhã de hoje. A limitação (em comparação com a abordagem ArchiveADataset) é o risco de um timeout ou há muitos dados para um único arquivo. Você pode evitar a limitação, fazendo pedidos mais frequentes para períodos de tempo menores.
EDDTable FromHttpGet
\[ Esta opção ainda não existe, mas parece possível construir no futuro próximo. \]
O novo EDDTable FromHttpGet tipo de conjunto de dados em ERDDAP™ v2.0 torna possível imaginar outra solução. Os arquivos subjacentes mantidos por este tipo de conjunto de dados são essencialmente registros de arquivos que registram alterações no conjunto de dados. Deve ser possível construir um sistema que mantenha um conjunto de dados local periodicamente (ou com base em um gatilho) solicitando todas as mudanças que foram feitas no conjunto de dados remoto desde essa última solicitação. Deve ser tão eficiente (ou mais) do que rsync e lidaria com muitos cenários difíceis, mas só funcionaria se os conjuntos de dados remotos e locais fossem conjuntos de dados EDDTableFromHttpGet.
Se alguém quiser trabalhar nisto, por favor contacte erd.data at noaa.gov .
Dados distribuídos
Nenhuma das soluções acima faz um grande trabalho de resolver as variações difíceis do problema porque a replicação de quase tempo real (NRT) datasets é muito difícil, em parte por causa de todos os cenários possíveis.
Há uma ótima solução: nem tente replicar os dados. Em vez disso, use uma fonte autoritária (um conjunto de dados em um ERDDAP ) , mantido pelo provedor de dados (por exemplo, um escritório regional) . Todos os usuários que querem dados desse conjunto de dados sempre obtê-lo a partir da fonte. Por exemplo, os aplicativos baseados em navegador obtêm os dados de uma solicitação baseada em URL, por isso não importa que a solicitação seja para a fonte original em um servidor remoto (não o mesmo servidor que está hospedando o ESM) . Muitas pessoas têm defendido esta abordagem de Dados Distribuídos há muito tempo (por exemplo, Roy Mendelssohn nos últimos 20 anos) . ERDDAP Modelo de grade/federação (o top 80% deste documento) é baseado nesta abordagem. Esta solução é como uma espada para um nó Gordian — todo o problema desaparece.
- Esta solução é extremamente simples.
- Esta solução é extremamente eficiente, pois nenhum trabalho é feito para manter um conjunto de dados replicado (S) actualizado.
- Os usuários podem obter os dados mais recentes a qualquer momento (por exemplo, com uma latência de apenas ~ 0,5 segundo) .
- Ele escala muito bem e há maneiras de melhorar o escalonamento. (Veja a discussão no top 80% deste documento.)
Não, não é uma solução para todas as situações possíveis, mas é uma grande solução para a grande maioria. Se houver problemas / fraquezas com esta solução em certas situações, muitas vezes vale a pena trabalhar para resolver esses problemas ou viver com essas fraquezas por causa das vantagens deslumbrantes desta solução. Se / quando esta solução é realmente inaceitável para uma determinada situação, por exemplo, quando você realmente deve ter uma cópia local dos dados, então considere as outras soluções discutidas acima.
Conclusão
Embora não haja uma solução simples e simples que resolve perfeitamente todos os problemas em todos os cenários (como rsync e dados distribuídos quase são) , espero que haja ferramentas e opções suficientes para que você possa encontrar uma solução aceitável para sua situação particular.