Scalare
ERDDAP™ - Încărcături grele, grile, clustere, federații și cloud computing
ERDDAP :
ERDDAP™ este o aplicație web și un serviciu web care agregate date științifice din diverse surse locale și de la distanță și oferă o modalitate simplă, coerentă de a descărca subseturi de date în formate de fișiere comune și de a face grafice și hărți. Această pagină web discută probleme legate de grele ERDDAP™ utilizarea sarcinilor și explorează posibilitățile de a face față sarcinilor extrem de grele prin rețele, clustere, federații și cloud computing.
Versiunea originală a fost scrisă în iunie 2009. Nu au existat schimbări semnificative. Acest lucru a fost actualizat ultima dată 2019-04-15.
DISCLICATOR
Conţinutul acestei pagini web sunt opiniile personale ale lui Bob Simons şi nu reflectă neapărat nici o poziţie a Guvernului sau National Oceanic and Atmospheric Administration . Calculele sunt simpliste, dar cred că concluziile sunt corecte. Am folosit logica greşită sau am greşit în calculele mele? Dacă da, vina este numai a mea. Vă rugăm să trimiteți un e-mail cu corectarea erd dot data at noaa dot gov .
Încărcături grele / Constrângeri
Cu o utilizare grea, un standalone ERDDAP™ va fi constrâns (cel mai probabil) prin:
Lăţimea de bandă a sursei la distanţă
- Lungime de bandă a unei surse de date de la distanță (de exemplu, prin intermediul OPeNDAP ) , cu excepția cazului în o sursă de date la distanță are o conexiune la internet foarte mare lățime de bandă, ERDDAP răspunsurile vor fi constrânse de cât de repede ERDDAP™ poate obține date de la sursa de date. O soluție este de a copia setul de date pe ERDDAP E hard disk, poate cu EDDGrid Copiază sau EDDCommentCopy .
ERDDAP Lăţimea benzii serverului
- Doar dacă ERDDAP Serverul are o conexiune la internet foarte mare, ERDDAP răspunsurile vor fi constrânse de cât de repede ERDDAP™ poate obține date de la sursele de date și cât de repede ERDDAP™ poate returna datele clienților. Singura soluţie este o conexiune mai rapidă la internet.
Memorie
- Dacă există mai multe cereri simultane, ERDDAP™ poate rămâne fără memorie şi poate refuza temporar noi cereri. ( ERDDAP™ are câteva mecanisme pentru a evita acest lucru și pentru a minimiza consecințele dacă se întâmplă.) Cu cât mai multe amintiri în server cu atât mai bine. Pe un server de 32 de biți, 4+ GB este foarte bun, 2 GB este în regulă, mai puțin nu este recomandat. Pe un server de 64 de biți, puteți evita aproape în întregime problema prin obținerea de o mulțime de memorie. Vezi Setări \-Xmx și -Xms pentru ERDDAP / Tomcat. An ERDDAP™ obtinerea de utilizare grele pe un calculator cu un server de 64 de biți cu 8GB de memorie și -Xmx setat la 4000M este rareori, dacă vreodată, constrâns de memorie.
A avut drive Bandwide
- Accesarea datelor stocate pe hard disk-ul serverului este mult mai rapidă decât accesarea datelor de la distanță. Chiar şi aşa, dacă ERDDAP™ serverul are o conexiune foarte mare la internet, este posibil ca accesarea datelor de pe hard disk să fie un blocaj. O soluţie parţială este utilizarea mai rapidă (de exemplu, 10000 RPM) hard disk-uri magnetice sau unități SSD (în cazul în care are sens de cost) . O altă soluție este de a stoca seturi de date diferite pe diferite unități, astfel încât banda de bandă hard disk cumulativă este mult mai mare.
Prea multe fișiere cached
- Prea multe fișiere într-o cache Dosarul ERDDAP™ capturează toate imaginile, dar capturează doar datele pentru anumite tipuri de cereri de date. Este posibil ca directorul cache pentru un set de date să aibă un număr mare de fișiere temporar. Acest lucru va încetini cererile pentru a vedea dacă un fișier este în cache (Serios!) .<cache Minute> in setup.xml vă permite să setați cât timp un fișier poate fi în cache înainte de a fi șters. Stabilirea unui număr mai mic ar reduce această problemă.
CPU
- Doar două lucruri necesită mult timp de procesor:
- NetCDF 4 și HDF 5 sprijină acum compresia internă a datelor. Decompresie comprimată mare NetCDF 4 / 4 HDF 5 fișier de date poate dura 10 sau mai multe secunde. (Asta nu e o greşeală de implementare. Este natura compresiei.) Astfel, cererile multiple simultane către seturi de date stocate în fișiere comprimate pot pune o presiune severă pe orice server. Dacă aceasta este o problemă, soluția este de a stoca seturi de date populare în fișiere necomprimate, sau de a obține un server cu un procesor cu mai multe nuclee.
- Realizarea graficelor (inclusiv hărți) : aproximativ 0,2 - 1 secundă per grafic. Deci, dacă au existat multe cereri simultan unice pentru grafice ( WMS Clienţii fac adesea 6 cereri simultane!) , ar putea exista o limitare CPU. Când mai mulți utilizatori sunt difuzate WMS Clienţi, asta devine o problemă.
Identice multiple ERDDAP S cu Load Balance?
Întrebarea apare adesea: "Pentru a face faţă sarcinilor grele, pot stabili mai multe identice ERDDAP s cu echilibrarea sarcinii?" Este o întrebare interesantă pentru că ajunge rapid la miezul ERDDAP Designul lui. Răspunsul rapid este "nu." Știu că este un răspuns dezamăgitor, dar există câteva motive directe și unele motive fundamentale mai mari de ce am proiectat ERDDAP™ utilizarea unei abordări diferite (o federaţie de ERDDAP s, descris în cea mai mare parte a prezentului document) Cred că e o soluţie mai bună.
Unele motive directe de ce nu se poate / nu ar trebui să configurați mai multe identice ERDDAP s sunt:
- O dată ERDDAP™ citește fiecare fișier de date atunci când devine disponibil pentru prima dată pentru a găsi intervalele de date din fișier. Apoi stochează informaţiile într-un fişier index. Mai târziu, când un utilizator solicită date, ERDDAP™ utilizează acest indice pentru a afla ce fișiere să caute datele solicitate. Dacă ar exista mai multe identice ERDDAP S, ei ar face fiecare acest indexare, care este efort irosit. Cu sistemul federal descris mai jos, indexarea se face doar o singură dată, de către unul dintre ERDDAP c.
- Pentru unele tipuri de cereri de utilizator (de exemplu, pentru .nc , .png, fișiere .pdf) ERDDAP™ trebuie să facă întregul fișier înainte de a putea fi trimis răspunsul. Deci... ERDDAP™ Caches aceste fișiere pentru o perioadă scurtă de timp. Dacă apare o cerere identică (așa cum face de multe ori, în special pentru imagini în cazul în care URL-ul este încorporat într-o pagină web) , ERDDAP™ poate refolosi acel fişier. Într-un sistem de mai multe identice ERDDAP S, aceste fișiere cache nu sunt partajate, astfel încât fiecare ERDDAP™ ar fi inutil și de deșeuri recrea .nc , .png, sau fișiere .pdf. Cu sistemul federat descris mai jos, fișierele sunt făcute doar o singură dată, de către unul dintre ERDDAP s şi reutilizat.
- ERDDAP Sistemul de abonamente nu este configurat pentru a fi partajat de mai multe ERDDAP c. De exemplu, dacă balansul de sarcină trimite un utilizator la unul ERDDAP™ iar utilizatorul subscrie la un set de date, apoi celălalt ERDDAP S nu va fi conștient de acest abonament. Mai târziu, dacă balansul de sarcină trimite utilizatorul la un alt ERDDAP™ și cere o listă cu abonamentele sale, cealaltă ERDDAP™ va spune că nu există (care să-l conducă să facă un abonament duplicat pe celălalt ERED DAP ) . Cu sistemul federat descris mai jos, sistemul de abonament este pur și simplu manipulat de către principalul, public, compozit ERDDAP .
Da, pentru fiecare dintre aceste probleme, am putea (cu mare efort) inginer o soluţie (să împărtășească informațiile între ERDDAP s) , dar cred că Federaţia... ERDDAP Abordarea s (descris în cea mai mare parte a prezentului document) este o soluţie globală mult mai bună, parţial pentru că se ocupă de alte probleme pe care multiplele identităţi... ERDDAP S-cu-a-load-echilibrul abordare nici măcar nu începe să abordeze, în special natura descentralizată a surselor de date din lume.
E mai bine să accepţi simplul fapt că nu am proiectat ERDDAP™ care urmează să fie implementate ca identice multiple ERDDAP s cu balansator de sarcină. Am proiectat conştient ERDDAP™ să lucreze bine în cadrul unei federații de ERDDAP S, care cred că are multe avantaje. În special, o federaţie de ERDDAP S este perfect aliniat cu sistemul descentralizat, distribuit de centre de date pe care le avem în lumea reală (Gândiți-vă la diferite regiuni IOOS, sau diferite regiuni CoastWatch, sau diferite părți ale NCEI, sau alte 100 de centre de date în NOAA , sau diferite NASA DAACs, sau 1000 de centre de date din întreaga lume) . În loc să spună tuturor centrelor de date ale lumii că trebuie să-şi abandoneze eforturile şi să-şi pună toate datele într-un "lac de date" centralizat (chiar dacă ar fi posibil, este o idee oribilă din numeroase motive -- vezi diversele analize care arată numeroasele avantaje ale sisteme descentralizate ) , ERDDAP Design-ul lui funcționează cu lumea așa cum este. Fiecare centru de date care produce date poate continua să mențină, să curețe și să servească datele lor (cum ar trebui) , și totuși, cu ERDDAP™ , datele pot fi, de asemenea, instantaneu disponibile de la un centralizat ERDDAP , fara a fi necesara transmiterea datelor catre centralizat ERDDAP™ sau stocarea de copii duplicate ale datelor. Într-adevăr, un anumit set de date poate fi disponibil simultan de la ERDDAP™ la organizația care a produs și de fapt stochează datele (De exemplu, Gomoos) , de la ERDDAP™ la organizația-mamă (de exemplu, centrul IOOS) , De la un... NOAA ERDDAP™ , de la un guvern federal al SUA ERDDAP™ , dintr-o lume ERDDAP™ (GOOS) , și de la specializate ERDDAP s (de exemplu, o ERDDAP™ la o instituție dedicată cercetării HAB) , toate în esență instantaneu, și eficient, deoarece numai metadatele sunt transferate între ERDDAP S, nu datele. Cel mai bun dintre toate, după inițial ERDDAP™ la organizația originară, toate celelalte ERDDAP S poate fi înființat rapid (câteva ore de muncă) , cu resurse minime (un server care nu are nevoie de RAID pentru stocarea datelor deoarece nu stochează date la nivel local) , și astfel, la costuri cu adevărat minime. Compară asta cu costul înfiinţării şi menţinerii unui centru centralizat de date cu un lac de date şi nevoia unei conexiuni cu adevărat masive, cu adevărat costisitoare, Internet, plus problema însoţitoare a centrului centralizat de date fiind un singur punct de eşec. Pentru mine, ERDDAP abordarea descentralizată, federalizată este mult, mult superioară.
În situațiile în care un anumit centru de date are nevoie de mai multe ERDDAP s pentru a satisface cererea ridicată; ERDDAP "design-ul este pe deplin capabil de potrivire sau depăşire a performanţei multiple-identical- ERDDAP S-cu-o-sarcină-echilibrare abordare. Întotdeauna ai opţiunea de a te instala. compozit multiplu ERDDAP s (după cum s-a discutat mai jos) , fiecare dintre care devine toate datele lor de la alte ERDDAP s, fără echilibrarea sarcinii. În acest caz, vă recomandăm să faceți un punct de a da fiecare dintre compozit ERDDAP s un nume diferit / identitate și, dacă este posibil, crearea lor în diferite părți ale lumii (De exemplu, diferite regiuni AWS) , de exemplu, ERD \_US\_Est, ERD West, ERD \_IE, ERD \_FR, ERD \_IT, astfel încât utilizatorii conştient, în mod repetat, lucrează cu un anumit ERDDAP , cu beneficiul suplimentar că ați eliminat riscul dintr-un singur punct de eșec.
Grile, clustere şi Federaţii
Sub o utilizare foarte grea, un singur independent ERDDAP™ va rula în una sau mai multe dintre constrângeri enumerate mai sus și chiar soluțiile sugerate vor fi insuficiente. Pentru astfel de situații, ERDDAP™ are caracteristici care fac ușor pentru a construi grile scalabile (De asemenea, numite clustere sau federații) din ERDDAP s care permit sistemului să se ocupe de o utilizare foarte grea (de exemplu, pentru un centru mare de date) .
Folosesc grilă ca termen general pentru indicarea unui tip de grup de calculatoare în cazul în care toate părțile pot sau nu pot fi situate fizic într-o singură instalație și pot fi administrate la nivel central. Un avantaj al rețelelor co-locate, deținute la nivel central și administrate (grupuri) este că acestea beneficiază de economii de scară (în special volumul de muncă uman) şi simplificarea funcţionării părţilor sistemului. Un avantaj al rețelelor nelocuite, neproporționate și administrate la nivel central (federații) este că ei distribuie volumul de muncă uman și costul, și poate oferi o toleranță la defecte suplimentare. Soluţia pe care o propun de mai jos funcţionează bine pentru toate topografiile de reţea, grup şi federaţie.
Ideea de bază de proiectare a unui sistem scalabil este de a identifica blocajele potențiale și apoi de a proiecta sistemul astfel încât părțile sistemului să poată fi replicate după cum este necesar pentru a atenua blocajele. În mod ideal, fiecare parte replicată crește capacitatea acelei părți a sistemului liniar (eficiența scalarii) . Sistemul nu este scalabil decât dacă există o soluţie scalabilă pentru fiecare gât. Scalabilitate este diferită de eficiență (cât de repede se poate face o sarcină ) . Scalabilitatea permite sistemului să crească pentru a gestiona orice nivel de cerere. Eficiență (de scalare și a părților) determină câte servere etc. vor fi necesare pentru a satisface un anumit nivel de cerere. Eficiența este foarte importantă, dar are întotdeauna limite. Scalabilitatea este singura soluție practică pentru construirea unui sistem care se poate descurca foarte utilizare grea. În mod ideal, sistemul va fi scalabil și eficient.
Obiective
Obiectivele acestui design sunt:
- Pentru a face o arhitectură scalabilă (unul care este ușor extensibil prin replicarea oricărei părți care devine supraîncărcată) . Pentru a face un sistem eficient, care maximizează disponibilitatea și transputul datelor date date având în vedere resursele informatice disponibile. (Costul este aproape întotdeauna o problemă.)
- Pentru a echilibra capacitățile părților sistemului astfel încât o parte a sistemului să nu copleșească o altă parte.
- Pentru a face o arhitectura simpla astfel incat sistemul este usor de instalat si administrat.
- Pentru a face o arhitectură care funcționează bine cu toate topografiile de rețea.
- Pentru a face un sistem care eşuează graţios şi într-un mod limitat dacă orice parte devine supraîncărcată. (Timpul necesar pentru a copia un set de date de dimensiuni mari va limita întotdeauna capacitatea sistemului de a face față unor creșteri bruște ale cererii pentru un set de date specific.)
- (Dacă este posibil) Pentru a face o arhitectura care nu este legat de orice specific cloud computing servicii sau alte servicii externe (Pentru că nu are nevoie de ele.) .
Recomandări
Recomandările noastre sunt:
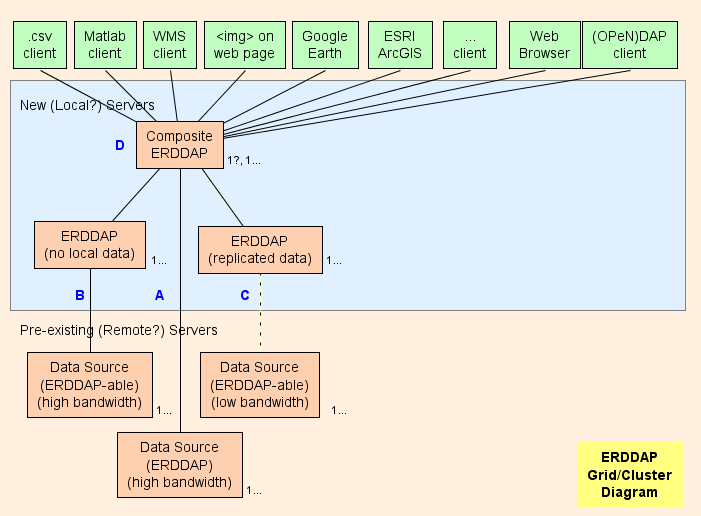
- Practic, sugerez crearea unui compus ERDDAP™ ( D în diagramă) , care este un regulat ERDDAP™ Doar că serveşte date de la alţii. ERDDAP c. Arhitectura grilei este proiectata sa schimbe cat mai multa munca (Utilizarea procesorului, utilizarea memoriei, utilizarea benzii de bandă) din compozit ERDDAP™ la celălalt ERDDAP c.
- ERDDAP™ are două tipuri speciale de seturi de date; EDDGrid FromErddap şi Tabel EDD FromErddap , care se referă la Seturi de date privind altele ERDDAP c.
- Când compozitul ERDDAP™ primește o cerere de date sau imagini din aceste seturi de date, compusul ERDDAP™ redirecționări cererea de date către cealaltă ERDDAP™ server. Rezultatul este:
- Acest lucru este foarte eficient (CPU, memorie și lățime de bandă) , pentru că altfel
- Compozitul ERDDAP™ trebuie să trimită cererea de date celeilalte ERDDAP .
- Celălalt. ERDDAP™ trebuie să obţină datele, să le reformuleze şi să transmită datele compozitului ERDDAP .
- Compozitul ERDDAP™ trebuie să primească datele (folosind banda de bandă suplimentară) , reformat-o (folosind timp suplimentar de procesor și memorie) , și transmite datele către utilizator (folosind banda de bandă suplimentară) . Redirecționând cererea de date și permițându-le celuilalt ERDDAP™ pentru a trimite răspunsul direct către utilizator, compozit ERDDAP™ nu petrece în esență nici timp CPU, memorie, sau lățime de bandă pe cereri de date.
- Redirecţionarea este transparentă pentru utilizator indiferent de software-ul client (un browser sau orice alt software sau instrument de linie de comandă) .
- Acest lucru este foarte eficient (CPU, memorie și lățime de bandă) , pentru că altfel
Piese de rețea
A : Pentru fiecare sursă de date la distanță care are o lățime mare de bandă OPeNDAP server, vă puteți conecta direct la serverul de la distanță. Dacă serverul de la distanță este un ERDDAP™ , utilizare EDDGrid FromErddap sau EDDtableFrom ERDDAP pentru a servi datele din compozit ERDDAP . Dacă serverul de la distanță este un alt tip de DAP server, de exemplu, THREDS; Hyrax , sau GRADS, utilizați EDDGrid De la tata.
B : Pentru fiecare ERDDAP -sursă de date realizabilă (o sursă de date din care ERDDAP poate citi date) care are un server de înaltă bandă, înființat un alt ERDDAP™ în rețeaua responsabilă cu furnizarea datelor din această sursă de date.
- Dacă mai multe ERDDAP s nu primesc multe cereri de date, le puteți consolida într-o singură ERDDAP .
- Dacă ERDDAP™ dedicat obtinerea de date de la o sursă de la distanță este obtinerea prea multe cereri, există o tentație de a adăuga suplimentare ERDDAP s pentru a accesa sursa de date la distanță. În cazuri speciale acest lucru poate avea sens, dar este mai probabil ca acest lucru să copleşească sursa de date la distanţă (care este auto-apărare) și, de asemenea, împiedică alți utilizatori să acceseze sursa de date la distanță (Care nu este frumos) . Într - un astfel de caz, să ne gândim să înfiinţăm alta ERDDAP™ să servească acel set de date și să copieze setul de date pe acesta ERDDAP Hard disk-ul lui (Vezi? C ) , poate cu EDDGrid Copiază și/sau EDDCommentCopy .
- B serverele trebuie să fie accesibile publicului.
C : Pentru fiecare ERDDAP -sursa de date care are un server cu banda mica (sau este un serviciu lent din alte motive) , ia în considerare crearea unui alt ERDDAP™ și stocarea unei copii a setului de date pe acesta ERDDAP hard disk-uri, poate cu EDDGrid Copiază și/sau EDDCommentCopy . Dacă mai multe ERDDAP s nu primesc multe cereri de date, le puteți consolida într-o singură ERDDAP . C serverele trebuie să fie accesibile publicului.
Compus ERDDAP
D : Compozitul ERDDAP™ este un regulat ERDDAP™ Doar că serveşte date de la alţii. ERDDAP c.
- Pentru că compozitul ERDDAP™ are în memorie informații despre toate setările de date, poate răspunde rapid cererilor de liste de seturi de date (căutări de text complete, căutări de categorii, lista tuturor seturilor de date) , și cererile pentru un formular individual de acces la date al unui set de date, să facă un formular grafic sau WMS pagina info. Acestea sunt pagini mici, generate dinamic, HTML bazate pe informații care sunt păstrate în memorie. Deci răspunsurile sunt foarte rapide.
- Deoarece cererile de date reale sunt redirecționate rapid către celelalte ERDDAP s, compozitul ERDDAP™ poate răspunde rapid la cererile de date reale fără a utiliza orice timp CPU, memorie, sau lățime de bandă.
- Prin mutarea cât mai mult de lucru posibil (CPU, memorie, lățime de bandă) din compozit ERDDAP™ la celălalt ERDDAP s, compozitul ERDDAP™ pot părea să servească date de la toate seturile de date și totuși să țină pasul cu un număr foarte mare de cereri de date de la un număr mare de utilizatori.
- Testele preliminare indică faptul că compozitul ERDDAP™ poate răspunde la majoritatea cererilor în ~1ms de timp CPU, sau 1000 de cereri/secundă. Astfel, un procesor de 8 nuclee ar trebui să poată răspunde la aproximativ 8000 de cereri/secundă. Deși este posibil să se prevadă izbucniri de activitate mai mare care ar provoca încetiniri, care este o mulțime de trecere. Este probabil ca latimea de banda a centrului de date sa fie blocajul cu mult inainte de compozit ERDDAP™ devine gât de sticlă.
max. actualizat (timp) ?
ă EDDGrid /TableFromErddap in the compound ERDDAP™ modifică informațiile stocate privind fiecare set de date sursă numai atunci când setul de date sursă este "reîncărcat" şi unele modificări de metadate (De exemplu, variabila timpului actual\_range ) , generând astfel o notificare de subscriere. Dacă setul de date sursă conține date care se modifică frecvent (de exemplu, date noi în fiecare secundă) și utilizează "actualizare" sistemul de notificare a modificărilor frecvente ale datelor subiacente; EDDGrid /TabelFromErddap nu va fi notificat cu privire la aceste modificări frecvente până la următorul set de date "reîncărcare," astfel încât EDDGrid /Table FromErddap nu va fi perfect actualizat. Puteți minimiza această problemă prin modificarea setului de date sursă<reîncărcareEveryNMinutes> la o valoare mai mică (60? 15?) astfel încât să existe mai multe notificări de abonament pentru a spune EDDGrid /TableFromErddap pentru a actualiza informațiile sale despre setul de date sursă.
Sau, în cazul în care sistemul de gestionare a datelor știe când setul de date sursă are date noi (de exemplu, prin intermediul unui script care copiază un fișier de date în loc) , și în cazul în care nu este foarte frecvent (de exemplu, la fiecare 5 minute sau mai puțin frecvente) , există o soluție mai bună:
- Nu folosi<updateEveryNMillis> pentru a menține setul de date sursă actualizat.
- Setează setul de date sursă<reîncarcăEveryNMinutes> la un număr mai mare (1440?) .
- Pune scriptul să contacteze setul de date sursă URL- ul steagului imediat după ce copiază un nou fișier de date în loc. Acest lucru va duce la actualizarea perfectă a setului de date sursă și va determina generarea unei notificări de subscriere, care va fi trimisă către EDDGrid /Table FromErddap Set de date. Asta va conduce EDDGrid Set de date pentru a fi perfect actualizat (în termen de 5 secunde de la adăugarea de date noi) . Și tot ce se va face eficient (fără reîncărcari inutile de seturi de date) .
Compus multiplu ERDDAP s
- În cazuri foarte extreme, sau pentru toleranţa la defecte, poate doriţi să configuraţi mai multe compozite ERDDAP . Este probabil ca alte părți ale sistemului (în special, banda de bandă a centrului de date) va deveni o problemă cu mult înainte de compozit ERDDAP™ devine un blocaj. Deci, solutia este, probabil, de a configura centre de date suplimentare, diverse geografic, (oglinzi) , fiecare cu câte un compozit ERDDAP™ și servere cu ERDDAP s şi (cel puțin) copii în oglindă ale seturilor de date care sunt în cerere mare. O astfel de configurare oferă, de asemenea, toleranţă la defect şi rezervă de date (prin copiere) . În acest caz, este cel mai bine dacă compozitul ERDDAP s au URL- uri diferite.
Dacă vrei cu adevărat toate compozit ERDDAP s să aibă același URL, utilizați un sistem frontal care atribuie un anumit utilizator doar unuia dintre compozit ERDDAP s (pe baza adresei IP) , astfel încât toate cererile utilizatorului merge la doar unul dintre compozit ERDDAP c. Există două motive:
- Atunci când un set de date suport este reîncărcat și metadatele se modifică (De exemplu, un nou fișier de date într-un set de date în rețea cauzează variabila temporală actual\_range să se schimbe) , compozitul ERDDAP s va fi temporar ușor de sincronizare, dar cu eventual coerenţă . În mod normal, vor re-sinch în 5 secunde, dar uneori va fi mai lung. Dacă un utilizator face un sistem automat care se bazează pe ERDDAP™ Abonamente care declanşează acţiuni, problemele scurte de sincronizare vor deveni semnificative.
- Compusul 2+ ERDDAP s fiecare își păstrează propriul set de abonamente (din cauza problemei de sincronizare descrise mai sus) .
Deci, un anumit utilizator ar trebui să fie direcționat către doar unul dintre compozit ERDDAP s pentru a evita aceste probleme. Dacă unul dintre compozit ERDDAP S merge în jos, sistemul frontal poate redirecționa că ERDDAP "s utilizatori la un alt ERDDAP™ Asta e tot. Cu toate acestea, dacă este o problemă de capacitate care cauzează primul compus ERDDAP™ să eșueze (un utilizator prea zelos? a atac de negare a serviciului ?) , acest lucru face foarte probabil ca redirecționarea utilizatorilor săi la alte compozit ERDDAP s va provoca esec de cascadă . Astfel, cea mai robustă configurare este să aibă compozit ERDDAP s cu URL- uri diferite.
Sau, poate mai bine, setați mai multe compozit ERDDAP s fără echilibrarea sarcinii. În acest caz, ar trebui să faci un punct de a da fiecare dintre ERDDAP s un nume diferit / identitate și, dacă este posibil, crearea lor în diferite părți ale lumii (De exemplu, diferite regiuni AWS) , de exemplu, ERD \_US\_Est, ERD West, ERD \_IE, ERD \_FR, ERD \_IT, astfel încât utilizatorii să lucreze în mod conștient, în mod repetat cu un anumit ERDDAP .
- \[ Pentru un design fascinant al unui sistem de inalta performanta care functioneaza pe un server, vezi asta descrierea detaliată a Mailinatorului . \]
Setări de date în cerere foarte mare
În cazul într-adevăr neobișnuit că unul dintre A , B , sau C ERDDAP s nu pot ține pasul cu cererile din cauza lățimii de bandă sau limitări ale hard disk-ului, este logic să se copieze datele (Din nou.) pe alt server+hard Condu. ERDDAP , poate cu EDDGrid Copiază și/sau EDDCommentCopy . În timp ce poate părea ideal pentru a avea setul de date original și setul de date copiat apar fără probleme ca un set de date în compozit ERDDAP™ , acest lucru este dificil deoarece cele două seturi de date vor fi în state ușor diferite în momente diferite (în special, după ce originalul primește date noi, dar înainte ca setul de date copiat să primească copia) . Prin urmare, recomand ca seturile de date să primească titluri ușor diferite (De exemplu, ..." (Copie # 1) "şi..." (copie # 2) "sau poate " (Oglindă # n ) "sau " (server # n ) ") și să apară ca seturi de date separate în compozit ERDDAP . Utilizatorii sunt utilizați pentru a vedea liste de site-uri oglindă la site-uri de descărcare de fișiere populare, astfel încât acest lucru nu ar trebui să le surprindă sau să le dezamăgească. Din cauza limitărilor de lățime de bandă într-un anumit loc, poate avea sens să aibă oglinda situat într-un alt loc. În cazul în care copia în oglindă este la un alt centru de date, accesat doar de compozit acel centru de date ERDDAP™ , diferite titluri (de exemplu, "oglindă # 1) Nu sunt necesare.
RAIDES versus Hard Drive-uri regulate
În cazul în care un set de date mare sau un grup de seturi de date nu sunt utilizate puternic, ar putea avea sens să stocheze datele pe un RAID, deoarece oferă toleranță de eroare și din moment ce nu aveți nevoie de puterea de procesare sau banda de bandă a unui alt server. Dar dacă un set de date este utilizat puternic, poate fi mai logic să copiem datele pe un alt server + ERDDAP™ + hard disk (similar cu ce face Google ) mai degrabă decât să utilizați un server și un RAID pentru a stoca mai multe seturi de date din moment ce ajungeți să utilizați ambele server+hardDrive+ ERDDAP S în reţea până când unul dintre ei eşuează.
Eșecuri
Ce se întâmplă dacă...
- Există o explozie de cereri pentru un set de date (De exemplu, toți studenții dintr-o clasă solicită simultan date similare) ? Doar ERDDAP™ deservirea setului de date respectiv va fi copleșită și va încetini sau va refuza cererile. Compozitul ERDDAP™ şi altele ERDDAP S nu va fi afectat. Deoarece factorul de limitare pentru un anumit set de date în cadrul sistemului este hard disk-ul cu datele (nu ERDDAP ) , singura soluţie (nu imediat) este de a face o copie a setului de date pe un server diferit+hardDrive+ ERDDAP .
- An A , B , sau C ERDDAP™ eșuează (de exemplu, eșec la hard disk) ? Numai setul de date (s) servit de asta ERDDAP™ sunt afectate. Dacă setul de date (s) este oglindită pe un alt server+hardDrive+ ERDDAP Efectul este minim. Dacă problema este un eșec hard disk într-un nivel 5 sau 6 RAID, doar înlocuiți unitatea și aveți RAID reconstrui datele de pe unitatea.
- Compozitul ERDDAP™ Eşec? Dacă doriţi să faceţi un sistem cu foarte disponibilitate ridicată , puteți configura compozit multiplu ERDDAP s (după cum s-a discutat mai sus) , folosind ceva de genul NGINX sau Traefik să se ocupe de echilibrarea sarcinii. Rețineți că un compus dat ERDDAP™ se pot ocupa de un număr foarte mare de cereri de la un număr mare de utilizatori, deoarece cererile de metadate sunt mici și sunt gestionate prin informații care sunt în memorie; și cereri de date (care poate fi mare) sunt redirecționate către copil ERDDAP c.
Simplu, scalabil
Acest sistem este ușor de instalat și administrat, și ușor extensibil atunci când orice parte a acestuia devine supraîncărcată. Singurele limitări reale pentru un anumit centru de date sunt lățimea de bandă a centrului de date și costul sistemului.
Lăţimea benzii
Se observă lățimea de bandă aproximativă a componentelor utilizate în mod obișnuit ale sistemului:
| Componentă | Lăţimea aproximativă a benzii (GBytes/s) |
|---|---|
| Memorie DDR | 2, 5 |
| Unitate SSD | 1 |
| SATA hard disk | 0, 3 |
| Gigabit Ethernet | 0, 1 |
| OC-12 | 0, 06 |
| OC-3 | 0, 015 |
| T1 | 0, 0001 |
Deci, un hard disk SATA (0.3GB/s) pe un server cu unul ERDDAP™ poate satura un Gigabit Ethernet LAN (0.1GB/s) . Şi un Gigabit Ethernet LAN (0.1GB/s) poate satura, probabil, o conexiune la internet OC-12 (0, 06GB/ s) . Și cel puțin o sursă liste OC-12 linii costa aproximativ 100.000 dolari pe lună. (Da, aceste calcule se bazează pe împingerea sistemului la limitele sale, ceea ce nu este bine, deoarece duce la răspunsuri foarte lente. Dar aceste calcule sunt utile pentru planificarea și echilibrarea părților sistemului.) În mod evident, o conexiune la internet adecvată rapid pentru centrul de date este de departe cea mai scumpă parte a sistemului. Puteți construi ușor și relativ ieftin o rețea cu o duzină de servere care rulează o duzină ERDDAP s care este capabil să pompeze o mulțime de date rapid, dar o conexiune la internet adecvat rapid va fi foarte, foarte scump. Soluţiile parţiale sunt:
- Încurajați clienții să solicite subseturi de date, dacă este necesar. Dacă clientul are nevoie doar de date pentru o regiune mică sau la o rezoluție inferioară, aceasta este ceea ce ar trebui să solicite. Subsetarea este un punct central al protocoalelor ERDDAP™ sprijină solicitarea de date.
- Încurajaţi transmiterea datelor comprimate. ERDDAP™ comprese o transmisie de date în cazul în care se găsește "accept-encoding" în HTTP GET Cere antetul. Toate browserele web folosesc "accept-encoding" și decomprimă automat răspunsul. Alți clienți (De exemplu, programe pentru calculator) trebuie să-l folosească în mod explicit.
- Colocați serverele dvs. la un ISP sau alt site care oferă costuri de lățime de bandă relativ mai puțin costisitoare.
- Dispersaţi serverele cu ERDDAP s pentru diferite instituţii, astfel încât costurile să fie dispersate. Apoi puteți lega compozit dvs. ERDDAP™ lor ERDDAP c.
Notă: Calculare nori și servicii de găzduire web oferă toate banda de internet de care aveți nevoie, dar nu rezolva problema prețurilor.
Pentru informaţii generale privind proiectarea sistemelor scalabile, de înaltă capacitate, tolerante la defecte, consultaţi cartea lui Michael T. Nygard Eliberează .
Ca Lego
Designerii de software încearcă adesea să folosească bine modele de proiectare software pentru a rezolva probleme. Modelele bune sunt bune pentru că încapsulează bine, uşor de creat şi de lucrat cu soluţii generale care duc la sisteme cu proprietăţi bune. Numele de model nu sunt standardizate, așa că voi numi modelul care ERDDAP™ foloseşte modelul Lego. Fiecare Lego (fiecare ERDDAP ) este un simplu, mic, standard, stand-alone, caramida (server de date) cu o interfață definită care permite conectarea la alte legouri ( ERDDAP s) . Părţile ERDDAP™ care alcătuiesc acest sistem sunt: sistemele de abonament și flagURL (care permite comunicarea între ERDDAP s) , EDD ... De la sistemul de redirecționare Erddap, și sistemul de RESTful cereri de date care pot fi generate de utilizatori sau de alte persoane ERDDAP c. Astfel, dat două sau mai multe legouri ( ERDDAP s) , puteți crea un număr imens de forme diferite (scuze ale rețelei ERDDAP s) . Sigur, designul și caracteristicile ERDDAP™ ar fi putut fi făcut diferit, nu Lego-ca, poate doar pentru a permite și optimiza pentru o anumită topologie. Dar simţim că ERDDAP Design-ul Lego oferă o soluţie bună, generală, care permite orice ERDDAP™ administrator (sau grup de administratori) pentru a crea tot felul de scuze diferite ale federaţiei. De exemplu, o singură organizație ar putea înființa trei (sau mai mult) ERDDAP es aşa cum este indicat în ERDDAP™ Diagrama grilă/cluster de mai sus . Sau un grup distribuit (IOOS? CoastWatch? NCEI? NWS? NOAA ? USGS? Dataone? NEON? LTER? OOI? BODC? ONC? JRC? WMO?) poate configura unul ERDDAP™ în fiecare avanpost mic (astfel încât datele să poată rămâne aproape de sursă) și apoi a înființat un compus ERDDAP™ în biroul central cu seturi de date virtuale (care sunt întotdeauna perfect actualizate) din fiecare avanpost mic ERDDAP c. Într-adevăr, toate ERDDAP s, instalate la diferite instituții din întreaga lume, care obține date de la alte ERDDAP s și/sau furnizează date altor persoane ERDDAP s, formează o rețea uriașă de ERDDAP c. Cât de tare e asta?! Deci, ca şi cu Lego, posibilităţile sunt nelimitate. De aceea, acesta este un model bun. De aceea, acesta este un design bun pentru ERDDAP .
Diferite tipuri de cereri
Una dintre complicațiile din viața reală ale acestei discuții a topologiilor serverului de date este că există diferite tipuri de cereri și diferite modalități de optimizare a diferitelor tipuri de cereri. Aceasta este cea mai mare parte o problemă separată (Cât de repede poate ERDDAP™ cu datele care răspund cererii de date?) din discuţia despre topologie (care se ocupă cu relațiile dintre serverele de date și care server are datele reale) . ERDDAP™ Desigur, încearcă să se ocupe de toate tipurile de cereri în mod eficient, dar se ocupă unele mai bine decât altele.
- Multe cereri sunt simple. De exemplu: Care sunt metadatele pentru acest set de date? Sau: Care sunt valorile dimensiunii timpului pentru acest set de date grilat? ERDDAP™ este conceput să se ocupe de acestea cât mai repede posibil (de obicei în<=2 ms) prin păstrarea acestor informații în memorie.
- Unele cereri sunt moderat grele. De exemplu: Dă-mi acest subset de un set de date (care este într-un fișier de date) . Aceste cereri pot fi tratate relativ repede pentru că nu sunt atât de dificile.
- Unele cereri sunt greu și, prin urmare, sunt consumatoare de timp. De exemplu: Dă-mi acest subset de un set de date (care ar putea fi în oricare dintre cele 10.000 de fișiere de date +, sau ar putea fi de la fișiere de date comprimate care durează fiecare 10 secunde pentru a decomprima) . ERDDAP™ v2.0 a introdus unele modalități noi și mai rapide de a face față acestor cereri, în special prin faptul că permite firului de manipulare a cererilor să producă mai multe fire de lucrător care abordează diferite subseturi ale cererii. Dar există o altă abordare a acestei probleme care ERDDAP™ nu suportă încă: subseturile fișierelor de date pentru un anumit set de date ar putea fi stocate și analizate pe computere separate, iar apoi rezultatele combinate pe serverul original. Această abordare se numeşte Reduce harta şi este exemplificat de Hadoop , primul (?) open-source MapReduce program, care a fost bazat pe idei dintr-o lucrare Google. (Dacă aveţi nevoie de MapReduceţi ERDDAP , vă rugăm să trimiteți o cerere de e-mail la erd.data at noaa.gov .) Google's BigQuery este interesant, deoarece pare a fi o implementare a MapReduce aplicat la subsetarea seturilor de date tabulare, care este unul dintre ERDDAP Principalele scopuri. Este probabil că puteți crea un ERDDAP™ Set de date dintr-un set de date BigQuery prin intermediul Tabel EDD din baza de date deoarece BigQuery poate fi accesat prin intermediul unei interfețe JDBC.
Acestea sunt opiniile mele.
Da, calculele sunt simpliste (şi acum uşor datat) Dar cred că concluziile sunt corecte. Am folosit logica greşită sau am greşit la calcule? Dacă da, vina este numai a mea. Vă rugăm să trimiteți un e-mail cu corectarea erd dot data at noaa dot gov .
Calculare nori
Mai multe companii oferă servicii de cloud computing (de exemplu, Amazon Web Services şi Platforma Google Cloud ) . Societăţi de găzduire web au oferit servicii mai simple de la mijlocul anilor '90, dar serviciile "cloud" au extins considerabil flexibilitatea sistemelor și gama de servicii oferite. Din moment ce ERDDAP™ grilă doar constă din ERDDAP s şi din ERDDAP au Java aplicații web care pot rula în Tomcat (cel mai frecvent server de aplicații) sau alte servere de aplicații, ar trebui să fie relativ ușor pentru a configura un ERDDAP™ grilă pe un serviciu de cloud sau site-ul de găzduire web. Avantajele acestor servicii sunt:
- Acestea oferă acces la conexiuni Internet foarte mari de bandă. Numai acest lucru poate justifica utilizarea acestor servicii.
- Se taxează doar pentru serviciile pe care le folosiţi. De exemplu, obţii acces la o conexiune foarte mare la internet, dar plăteşti doar pentru datele reale transferate. Asta îţi permite să construieşti un sistem care rareori e copleşit. (chiar și la cererea maximă) , fără a fi nevoie să plătească pentru capacitatea care este rar utilizat.
- Ele sunt ușor extensibile. Puteți schimba tipuri de servere sau adăuga cât mai multe servere sau cât de mult de stocare doriți, în mai puțin de un minut. Numai acest lucru poate justifica utilizarea acestor servicii.
- Ei te eliberează de multe dintre sarcinile administrative de funcționare a serverelor și rețelelor. Numai acest lucru poate justifica utilizarea acestor servicii.
Dezavantajele acestor servicii sunt:
- Ei taxează pentru serviciile lor, uneori foarte mult (în termeni absoluti; nu că nu ar fi o valoare bună) . Prețurile enumerate aici sunt pentru Amazon EC2 . Aceste prețuri (din iunie 2015) va veni în jos.
În trecut, prețurile au fost mai mari, dar fișierele de date și numărul de cereri au fost mai mici.
În viitor, prețurile vor fi mai mici, dar fișierele de date și numărul de cereri vor fi mai mari.
Deci detaliile se schimbă, dar situaţia rămâne relativ constantă.
Și nu este faptul că serviciul este prea scump, este că noi folosim și cumpărăm o mulțime de servicii.
- Transferurile de date în sistem sunt acum gratuite (Da!) . Transferurile de date din sistem sunt de 0.09 dolari GB. Un hard disk SATA (0.3GB/s) pe un server cu unul ERDDAP™ poate satura un Gigabit Ethernet LAN (0.1GB/s) . Un Gigabit Ethernet LAN (0.1GB/s) poate satura, probabil, o conexiune la internet OC-12 (0, 06GB/ s) . În cazul în care o conexiune OC-12 poate transmite ~150.000 GB/luna, costurile de transfer de date ar putea fi la fel de mult ca 150.000 GB @ 0.09 $GB = 13.500 dolari/luna, care este un cost semnificativ. Evident, dacă ai o duzină de muncitori ERDDAP S pe un serviciu cloud, taxele lunare de transfer de date ar putea fi substanțiale (până la 62.000 $/lună) . (Din nou, nu este faptul că serviciul este prea scump, este că suntem folosind și de cumpărare o mulțime de servicii.)
- Stocarea datelor (Comparați că pentru a cumpăra o unitate 4TB pur și simplu pentru ~50 $/TB, deși RAID pentru a pune în și costurile administrative adaugă la costul total.) Deci, dacă aveți nevoie pentru a stoca o mulțime de date în nor, ar putea fi destul de scump (De exemplu, 100TB ar costa 5000$/luna) . Dar dacă nu aveți o cantitate foarte mare de date, aceasta este o problemă mai mică decât costurile de transfer de bandă/date. (Din nou, nu este faptul că serviciul este prea scump, este că suntem folosind și de cumpărare o mulțime de servicii.)
Subsetare
- Problema subsetarea: Singura modalitate de a distribui eficient date din fișiere de date este de a avea programul care este distribuirea datelor (de exemplu, ERDDAP ) rulează pe un server care are datele stocate pe un hard disk local (sau acces rapid la un SAN sau RAID local) . Sistemele de fișiere locale permit ERDDAP™ (și bibliotecile subiacente, cum ar fi netcdf-java) pentru a solicita intervale de octeți specifice din fișiere și de a obține răspunsuri foarte repede. Multe tipuri de cereri de date ERDDAP™ la dosar (în special cererile de date grupate în cazul în care valoarea pasului este > 1) nu se poate face eficient dacă programul trebuie să solicite întregul fișier sau bucăți mari dintr-un fișier dintr-un non-local (Prin urmare, mai lent) sistem de stocare a datelor și apoi extrage un subset. În cazul în care configurarea norului nu dă ERDDAP™ acces rapid la intervale octet ale fișierelor (la fel de repede ca și cu fișierele locale) , ERDDAP Accesul la date va fi un blocaj sever și va nega alte beneficii ale utilizării unui serviciu cloud.
Date găzduite
O alternativă la analiza costurilor de mai sus (care se bazează pe proprietarul de date (de exemplu, NOAA ) de plată pentru stocarea datelor lor în cloud) a sosit în jurul anului 2012, când Amazon (și într-o măsură mai mică, alți furnizori de cloud) a început să găzduiască unele seturi de date în nor lor (AWS S3) gratuit (cu speranţa că şi-ar putea recupera costurile dacă utilizatorii ar închiria instanţe de calcul AWS EC2 pentru a lucra cu aceste date) . În mod evident, acest lucru face ca cloud computing-ul să fie mult mai eficient din punct de vedere al costurilor, deoarece timpul și costurile de încărcare a datelor și de găzduire sunt acum zero. Cu ERDDAP™ v2.0, există noi caracteristici pentru a facilita rularea ERDDAP în nori:
- Acum... EDDGrid Setul de date "FromFiles" sau "EDDTabelFromFiles" pot fi create din fișiere de date care sunt la distanță și accesibile prin internet (De exemplu, găleți AWS S3) prin utilizarea<CacheFromurl> și<cacheSize GB> opțiuni. ERDDAP™ va menține o cache locală a celor mai recent utilizate fișiere de date.
- Acum, în cazul în care orice EDDtableFromFiles fișiere sursă sunt comprimate (de exemplu, .tgz ) , ERDDAP™ le va decomprima automat atunci când le citește.
- Acum, ERDDAP™ firul care răspunde la o cerere dată va crea fire de lucrător pentru a lucra la subsecțiunile cererii dacă utilizați<nThreads> opțiuni. Această paralelizare ar trebui să permită răspunsuri mai rapide la cererile dificile.
Aceste modificări rezolva problema AWS S3 nu oferă locale, nivel de stocare fișiere și (vechi) problema accesului la datele S3 având un decalaj semnificativ. (Cu ani în urmă (~2014) , acel decalaj a fost semnificativ, dar este acum mult mai scurt și astfel nu la fel de semnificativ.) Toate în toate, înseamnă că înființarea ERDDAP™ în nor funcționează mult mai bine acum.
Mulţumesc. Multe mulţumiri lui Matthew Arrott şi grupului său în efortul iniţial OOI pentru munca lor de a pune ERDDAP™ în cloud și discuțiile rezultate.
Replicarea datelor la distanță
Există o problemă comună legată de discuţia de mai sus a reţelelor şi federaţiilor de ERDDAP s: replicarea la distanță a seturilor de date. Problema de bază este: un furnizor de date menține un set de date care se modifică ocazional și un utilizator dorește să mențină o copie locală actualizată a acestui set de date (dintr-o varietate de motive) . În mod evident, există un număr imens de variații ale acestui lucru. Unele variaţii sunt mult mai greu de suportat decât altele.
- Actualizări rapide E mai greu să ţii setul local la curent. imediat (de exemplu, în termen de 3 secunde) după fiecare schimbare la sursă, mai degrabă decât, de exemplu, în câteva ore.
- Modificări frecvente Schimbările frecvente sunt mai greu de suportat decât schimbările rare. De exemplu, schimbările de o dată pe zi sunt mult mai ușor de suportat decât modificările la fiecare 0.1 secunde.
- Modificări minore Mici modificări la un fișier sursă sunt mai greu de a face cu decât un fișier cu totul nou. Acest lucru este valabil mai ales dacă micile schimbări pot fi oriunde în dosar. Mici modificări sunt mai greu de detectat și de făcut greu de izolat datele care trebuie să fie replicate. Fişierele noi sunt uşor de detectat şi eficiente pentru transfer.
- Întregul set de date Menținerea la zi a unui întreg set de date este mai greu decât menținerea unor date recente. Unii utilizatori au nevoie doar de date recente (De exemplu, valoarea ultimelor 8 zile) .
- Copii multiple Menținerea mai multor copii la distanță la diferite site-uri este mai greu decât menținerea unei copii la distanță. Aceasta este problema de scalare.
Evident, există un număr uriaş de variaţii ale posibilelor tipuri de modificări ale setului de date sursă şi ale nevoilor şi aşteptărilor utilizatorului. Multe dintre variante sunt foarte greu de rezolvat. Cea mai bună soluţie pentru o situaţie nu este de multe ori cea mai bună soluţie pentru o altă situaţie
Relevant ERDDAP™ Unelte
ERDDAP™ oferă mai multe instrumente care pot fi utilizate ca parte a unui sistem care caută să mențină o copie la distanță a unui set de date:
- ERDDAP 's RSS (Sinteza site-ului bogat?) serviciu
oferă o modalitate rapidă de a verifica dacă un set de date pe o distanță ERDDAP™ s-a schimbat. - ERDDAP 's serviciu de abonament
e mai eficient (decât RSS ) abordare: va trimite imediat un e-mail sau va contacta un URL fiecărui abonat ori de câte ori setul de date este actualizat și actualizarea a dus la o schimbare. Este eficient prin faptul că se întâmplă ASAP și nu există nici un efort irosit (la fel ca în cazul sondajului RSS serviciu) . Utilizatorii pot folosi alte instrumente (ca IFTTT ) să reacționeze la notificările prin e-mail din sistemul de abonamente. De exemplu, un utilizator ar putea subscrie la un set de date la distanță ERDDAP™ și să utilizeze IFTTT pentru a reacționa la notificările prin e-mail și pentru a declanșa actualizarea setului de date local. - ERDDAP 's Sistemul de pavilion
oferă o cale pentru o ERDDAP™ administrator pentru a spune un set de date pe lui / ei ERDDAP Pentru a reîncărca ASAP. Forma URL a unui steag poate fi ușor de utilizat în scripturi. Formularul URL al unui steag poate fi folosit și ca acțiune pentru un abonament. - ERDDAP 's "files" sistem
poate oferi acces la fişierele sursă pentru un set de date dat, inclusiv o listă de dosare în stil Apache a fişierelor (un "Web Accesibil Folder") care are URL-ul de descărcare al fiecărui fișier, ultima dată modificată, și dimensiunea. Un dezavantaj al utilizării "files" sistemul este că fișierele sursă pot avea nume variabile diferite și metadate diferite față de setul de date așa cum apare în ERDDAP . Dacă o telecomandă ERDDAP™ Setul de date oferă acces la fișierele sale sursă, care deschide posibilitatea unei versiuni de rsync a unui om sărac: devine ușor pentru un sistem local să vadă ce fișiere de la distanță s-au schimbat și trebuie să fie descărcate. (Vezi cacheFromUrl opțiune sub care se poate folosi acest lucru.)
Soluţii
Deși există un număr imens de variații ale problemei și un număr infinit de soluții posibile, există doar o mână de abordări de bază pentru soluții:
Soluţii de forţă brută personalizate
O solutie evidenta este de a handcraft o solutie personalizata, care este, prin urmare, optimizat pentru o situatie data: face un sistem care detecteaza/identifica ce date s-au schimbat, si trimite aceste informatii utilizatorului astfel incat utilizatorul sa poata solicita datele modificate. Poţi face asta, dar există dezavantaje:
- Soluţiile personalizate sunt o mulţime de muncă.
- Soluţiile personalizate sunt, de obicei, atât de personalizate la un set de date dat şi dat sistemul utilizatorului, încât acestea nu pot fi reutilizate cu uşurinţă.
- Soluţiile personalizate trebuie construite şi întreţinute de dumneavoastră. (Niciodată nu e o idee bună. Întotdeauna e o idee bună să eviţi munca şi să faci pe altcineva să muncească!)
Te descurajez să iei această abordare deoarece este aproape întotdeauna mai bine să cauţi soluţii generale, construite şi întreţinute de altcineva, care pot fi reutilizate cu uşurinţă în diferite situaţii.
rsync
rsync este soluția existentă, uimitor de bună, cu scop general pentru păstrarea unei colecții de fișiere pe un computer sursă în sincronizare pe calculatorul de la distanță al unui utilizator. Modul în care funcționează este:
- unele evenimente (de exemplu, o ERDDAP™ Evenimentul sistemului de abonament) declanşatoare rsync; (sau, un loc de muncă Cron rsync la anumite momente în fiecare zi pe computerul utilizatorului)
- care contactează rsync pe computerul sursă;
- care calculează o serie de hașișuri pentru bucăți din fiecare fișier și transmite aceste hashes la rsync utilizatorului,
- care compară aceste informații cu informațiile similare pentru copia de fișiere a utilizatorului;
- care apoi solicită bucăți de fișiere care s-au schimbat.
Având în vedere tot ce face, rsync funcționează foarte repede (De exemplu, 10 secunde plus timpul de transfer de date) şi foarte eficient. Există variaţii ale rsync care optimizează pentru diferite situații (de exemplu, prin precalcularea și cachearea hașilor bucăților fiecărui fișier sursă) .
Principalele puncte slabe ale rsync sunt: este nevoie de un efort pentru a configura (probleme de securitate) ; există unele probleme de scalare; și nu este bun pentru păstrarea seturilor de date INRT într-adevăr actualizate (De exemplu, e ciudat să foloseşti rsync mai mult decât la fiecare 5 minute.) . Dacă puteți face față slăbiciunilor, sau în cazul în care acestea nu afectează situația dumneavoastră, rsync este o soluție excelentă, scop general pe care oricine poate folosi chiar acum pentru a rezolva multe scenarii care implică replicarea la distanță a seturilor de date.
Există un element pe ERDDAP™ Pentru a face lista pentru a încerca să adăugați sprijin pentru servicii rsync ERDDAP (Probabil o sarcină destul de dificilă.) , astfel încât orice client poate folosi rsync (sau o variantă) să mențină o copie actualizată a unui set de date. Dacă cineva vrea să lucreze la acest lucru, vă rugăm să e-mail erd.data at noaa.gov .
Există alte programe care fac mai mult sau mai puțin ceea ce face rsync, uneori orientate spre replicarea setului de date (desi adesea la nivel de fisier-copie) , de exemplu, Unidata 's IDD .
Cache din Url
Cache FromUrl setarea este disponibilă (începând cu ERDDAP™ v2. 0) pentru toate ERDDAP tipurile de seturi de date care fac seturi de date din fișiere (Practic, toate subclasele de EDDGrid Din dosare şi Tabel EDD din dosare ) . cache De la Url face trivial pentru a descărca și menține automat fișierele de date locale prin copierea acestora de la o sursă de la distanță prin intermediul cache-ului Din setarea Url. Fișierele de la distanță pot fi într-un dosar accesibil Web sau o listă de fișiere asemănătoare unui director oferit de THREDS, Hyrax , o găleată S3, sau ERDDAP 's "files" sistem.
Dacă sursa fișierelor la distanță este o distanță ERDDAP™ Set de date care oferă fișierele sursă prin intermediul ERDDAP™ "files" sistem, atunci puteți subscrie setului de date la distanță și se utilizează URL- ul steagului pentru setul de date local ca acțiune pentru abonament. Apoi, ori de câte ori se modifică setul de date de la distanță, acesta va contacta URL-ul de pavilion pentru setul de date, care îi va spune să reîncărcați ASAP, care va detecta și descărca fișierele de date de la distanță modificate. Toate acestea se întâmplă foarte repede. (de obicei ~5 secunde plus timpul necesar pentru a descărca fișierele modificate) . Această abordare funcționează foarte bine dacă modificările setului de date sursă sunt fișiere noi adăugate periodic și atunci când fișierele existente nu se schimbă niciodată. Această abordare nu funcționează bine dacă datele sunt frecvent anexate tuturor (sau mai mult) a fișierelor sursă existente, deoarece apoi setul local de date este frecvent descărcarea întregului set de date la distanță. (Aici este nevoie de o abordare asemănătoare rsync.)
ArchiveADataset
ERDDAP™ 's ArchiveADataset este o soluție bună atunci când datele sunt adăugate la un set de date frecvent, dar datele mai vechi nu sunt niciodată modificate. Practic, o ERDDAP™ Administratorul poate rula ArchiveADataset (Poate într-un scenariu, poate condus de cron) și să specifice un subset de seturi de date pe care doresc să le extragă (poate în mai multe fișiere) şi ambalaj în .zip sau .tgz fișier, astfel încât să puteți trimite fișierul persoanelor sau grupurilor interesate (De exemplu, NCEI pentru arhivare) sau să fie disponibil pentru descărcare. De exemplu, ai putea rula ArchiveADataset în fiecare zi la 12:10 am și să-l facă un .zip dintre toate datele de la 12:00 am ziua anterioară până la 12:00 am astăzi. (Sau să facem acest lucru săptămânal, lunar sau anual, după cum este necesar.) Deoarece fișierul ambalat este generat offline, nu există nici un pericol de o pauză sau prea multe date, așa cum ar fi pentru un standard ERDDAP™ cerere.
ERDDAP™ Sistemul standard de solicitare
ERDDAP™ Sistemul standard de solicitare este o soluţie alternativă bună atunci când datele sunt adăugate la un set de date frecvent, dar datele vechi nu se schimbă niciodată. Practic, oricine poate folosi cereri standard pentru a obține date pentru o anumită gamă de timp. De exemplu, la 12:10 am în fiecare zi, ai putea face o cerere pentru toate datele dintr-un set de date de la distanță de la 12:00 am ziua anterioară până la 12:00 am astăzi. Limita (comparativ cu abordarea ArchiveADataset) este riscul unei pauze sau există prea multe date pentru un singur fișier. Puteți evita limitarea prin efectuarea de cereri mai frecvente pentru perioade de timp mai mici.
Tabel EDD de la HttpGet
\[ Această opțiune nu există încă, dar pare posibilă pentru a construi în viitorul apropiat. \]
Noul Tabel EDD de la HttpGet Tipul setului de date în ERDDAP™ v2.0 face posibilă vizualizarea unei alte soluţii. Fișierele subiacente menținute de acest tip de set de date sunt, în esență, fișiere log care înregistrează modificări ale setului de date. Ar trebui să fie posibilă construirea unui sistem care să mențină periodic un set de date local (sau pe baza unui declanșator) solicitarea tuturor modificărilor aduse setului de date la distanță de la ultima solicitare. Asta ar trebui să fie la fel de eficient (sau mai mult) decât rsync și s-ar ocupa de multe scenarii dificile, dar ar funcționa numai în cazul în care seturile de date de la distanță și locale sunt tabelul EDDFromHttpGet seturi de date.
Dacă cineva vrea să lucreze la asta, vă rugăm să contactați erd.data at noaa.gov .
Date distribuite
Niciuna dintre soluţiile de mai sus nu face o treabă excelentă de rezolvare a variaţiilor dificile ale problemei deoarece replicarea timpului aproape real (INRT) Seturile de date sunt foarte dificile, în parte din cauza tuturor scenariilor posibile.
Există o mare soluție: nici măcar nu încercați să reproduceți datele. În schimb, utilizaţi singura sursă autoritară (un set de date pe unul ERDDAP ) , întreținute de furnizorul de date (De exemplu, un birou regional) . Toți utilizatorii care doresc date din acel set de date le primesc întotdeauna de la sursă. De exemplu, aplicațiile bazate pe browser obțin datele dintr-o cerere bazată pe URL, deci nu ar trebui să conteze că cererea este către sursa originală de pe un server la distanță (nu același server care găzduiește MES) . Multă lume susţine această abordare a datelor distribuite de mult timp. (De exemplu, Roy Mendelssohn în ultimii 20 de ani) . ERDDAP Modelul grilei/federaţiei (80% din acest document) se bazează pe această abordare. Această soluţie este ca o sabie pentru un Knot Gordian toată problema dispare.
- Această soluție este uimitor de simplu.
- Această soluție este extrem de eficientă, deoarece nu se face nicio lucrare pentru a menține un set de date replicat (s) la zi.
- Utilizatorii pot obține cele mai recente date în orice moment (de exemplu, cu o latență de numai ~0,5 secunde) .
- Acesta cânta destul de bine și există modalități de a îmbunătăți scalarea. (A se vedea dezbaterea din partea de sus 80% a prezentului document.)
Nu, aceasta nu este o soluție pentru toate situațiile posibile, dar este o soluție mare pentru marea majoritate. În cazul în care există probleme/slăbiciuni cu această soluție în anumite situații, este adesea în valoare de lucru pentru a rezolva aceste probleme sau de viață cu aceste puncte slabe din cauza avantajelor uimitoare ale acestei soluții. Dacă / atunci când această soluție este cu adevărat inacceptabilă pentru o anumită situație, de exemplu, atunci când într-adevăr trebuie să aveți o copie locală a datelor, atunci ia în considerare celelalte soluții discutate mai sus.
Concluzie
Deși nu există o singură soluție simplă care să rezolve perfect toate problemele din toate scenariile (ca Rsync și date distribuite aproape sunt) , sperăm că există suficiente instrumente și opțiuni, astfel încât să puteți găsi o soluție acceptabilă pentru situația dumneavoastră.