Stříkání
ERDDAP™ - Heavy Loads, Grids, Clusters, Federations, and Cloud Computing
ERDDAP :
ERDDAP™ je webová aplikace a webová služba, která shromažďuje vědecká data z různých místních a vzdálených zdrojů a nabízí jednoduchý a konzistentní způsob, jak stáhnout podmnožiny dat ve společných formátech souborů a vytvářet grafy a mapy. Tato webová stránka pojednává o otázkách souvisejících s těžkým ERDDAP™ používání zatížení a zkoumá možnosti řešení extrémně těžkých zatížení prostřednictvím sítí, klastrů, federací a cloud computingu.
Původní verze byla napsána v červnu 2009. Nedošlo k žádným významným změnám. Toto bylo naposledy aktualizováno 2019-04-15.
ZDŮVODNĚNÍ
Obsah této webové stránky jsou Bob Simons osobní názory a nemusí nutně odrážet žádné postavení vlády nebo National Oceanic and Atmospheric Administration . Výpočty jsou zjednodušené, ale myslím, že závěry jsou správné. Použil jsem chybnou logiku nebo jsem udělal chybu ve svých výpočtech? Pokud ano, je to jen moje chyba. Prosím, pošlete e-mail s opravou erd dot data at noaa dot gov .
Těžké zatížení / omezení
S těžkým použitím, samostatný ERDDAP™ budou omezeny (od nejvíce do nejméně pravděpodobné) podle:
Šířka pásma vzdáleného zdroje
- Vzdálený zdroj dat je šířka pásma i s efektivním připojením (např. prostřednictvím OPeNDAP ) , pokud vzdálený zdroj dat nemá velmi vysoké připojení k internetu, ERDDAP 's reakce budou omezeny tím, jak rychle ERDDAP™ může získat data ze zdroje dat. Řešením je zkopírovat soubor dat na ERDDAP 's pevným diskem, možná s EDDGrid Kopírovat nebo EDDtableCopy .
ERDDAP 's šířka pásma serveru
- Pokud ERDDAP 's serverem má velmi velké připojení k internetu, ERDDAP 's reakce budou omezeny tím, jak rychle ERDDAP™ může získat data ze zdrojů dat a jak rychle ERDDAP™ může klientům vrátit data. Jediným řešením je získat rychlejší internetové připojení.
paměť
- Pokud existuje mnoho současných žádostí, ERDDAP™ může dojít paměti a dočasně odmítnout nové požadavky. ( ERDDAP™ má několik mechanismů, jak se tomu vyhnout a minimalizovat důsledky, pokud k tomu dojde.) Čím více paměti na serveru, tím lépe. Na 32bitovém serveru je 4+ GB opravdu dobrá, 2 GB je v pořádku, méně se nedoporučuje. Na 64-bitovém serveru se můžete téměř zcela vyhnout problému tím, že získáte spoustu paměti. Viz Nastavení \-Xmx a -Xms místo ERDDAP Tomcat. An ERDDAP™ získání těžkého použití na počítači s 64-bitovým serverem s 8GB paměti a -Xmx nastaven na 4000M je zřídka, pokud vůbec, omezena pamětí.
Had Drive Bandwidth
- Přístup k datům uloženým na pevném disku serveru je mnohem rychlejší než přístup k vzdáleným datům. I tak, pokud ERDDAP™ server má velmi vysokou šířku pásma připojení k internetu, je možné, že přístup k datům na pevném disku bude zablokovat. Částečný roztok je rychlejší (např. 10 000 otáček za minutu) magnetické pevné disky nebo SSD disky (Jestli to dává smysl.) . Dalším řešením je ukládat různé soubory dat na různých diskech, takže kumulativní šířka pásma pevného disku je mnohem vyšší.
Příliš mnoho souborů zachycených
- Příliš mnoho souborů v cache adresář ERDDAP™ caches všechny obrázky, ale pouze caches data pro některé typy požadavků na data. Je možné, aby adresář cache pro datový soubor měl dočasně velký počet souborů. To zpomalí požadavky, zda je soubor v cache (Opravdu!) .<cache Minuty setup.xml umožňuje nastavit, jak dlouho může být soubor v cache před jeho odstraněním. Nastavení menšího čísla by tento problém minimalizovalo.
CPU
- Jen dvě věci zaberou spoustu času CPU:
- NetCDF 4 a HDF 5 nyní podporuje vnitřní komprese dat. Dekompresní velký komprimovaný NetCDF 4 / HDF 5 datových souborů může trvat 10 nebo více sekund. (To není chyba při realizaci. Je to povaha komprese.) Takže více simultánních žádostí o datové soubory s daty uloženými v komprimovaných souborech může způsobit vážné napětí na jakémkoli serveru. Pokud jde o problém, řešením je ukládat populární data v nestlačených souborech nebo získat server s procesorem s více jádry.
- Výroba grafů (včetně map) : přibližně 0,2 - 1 sekunda na graf. Takže pokud existuje mnoho současných unikátních žádostí o grafy ( WMS klienti často požadují 6 současně!) Mohlo by dojít k omezení CPU. Když běží více uživatelů WMS Klienti, tohle je problém.
Víceznačné ERDDAP S Load Balancing?
Často přichází otázka: "Můžu se vypořádat s těžkými břemeny, a tak vytvořit více stejných ERDDAP s vyvažováním nákladu?" Je to zajímavá otázka, protože se rychle dostane do jádra ERDDAP Je to design. Rychlá odpověď je "ne." Vím, že je to neuspokojivá odpověď, ale existuje několik přímých důvodů a některé větší základní důvody, proč jsem navrhl ERDDAP™ používat jiný přístup (federace ERDDAP s, popsaná ve velké části tohoto dokumentu) Což je podle mě lepší řešení.
Některé přímé důvody, proč nemůžete / by neměl nastavit více stejných ERDDAP jsou:
- Zadáno ERDDAP™ čte každý datový soubor, jakmile je poprvé k dispozici, aby bylo možné najít rozsah dat v souboru. Pak tyto informace uloží do indexu. Později, když přijde žádost uživatele o data, ERDDAP™ pomocí tohoto indexu zjistit, které soubory hledat požadované údaje. Pokud by bylo více stejných ERDDAP S, každý by dělal toto indexování, což je promarněné úsilí. S federovaným systémem popsaným níže, indexování se provádí pouze jednou, jedním z ERDDAP s.
- Pro některé typy žádostí o uživatele (např. pro .nc , .png, .pdf soubory) ERDDAP™ musí provést celý soubor před odesláním odpovědi. Takže... ERDDAP™ na krátkou dobu ukládá tyto soubory. Pokud přijde stejná žádost (jako často, zejména pro obrázky, kde je URL vložena do webové stránky) , ERDDAP™ může znovu použít ten cachovaný soubor. V systému více identických ERDDAP s, tyto cachované soubory nejsou sdíleny, takže každý ERDDAP™ by zbytečně a zbytečně znovu vytvořit .nc , .png, nebo .pdf soubory. S federovaným systémem popsaným níže, soubory jsou vyrobeny pouze jednou, jedním z ERDDAP s a znovu použít.
- ERDDAP 's systém předplatného není nastaven tak, aby byl sdílen více ERDDAP s. Například pokud vyvažovač zatížení pošle uživateli jednu ERDDAP™ a uživatel se přihlásí k datovému souboru, pak k druhému ERDDAP Nebude si toho předplatného vědom. Později, pokud vyvažovač zatížení pošle uživatele jinému ERDDAP™ a žádá o seznam jeho předplatného, druhý ERDDAP™ řekne, že žádné nejsou. (vede ho k dvojímu předplatnému na druhé ERED DAP ) . S federovaným systémem popsaným níže je systém předplatného jednoduše řešen hlavním, veřejným, kompozitem ERDDAP .
Ano, pro každý z těchto problémů bych mohl (s velkým úsilím) vytvořit řešení (sdílet informace mezi ERDDAP án) , ale myslím, že Federace-of- ERDDAP s přiblížení (popisovaný ve velké části tohoto dokumentu) je mnohem lepší celkové řešení, částečně proto, že se zabývá jinými problémy, které více-identické- ERDDAP s-s-a-ta-balancer přístup ani nezačne řešit, zejména decentralizované povahy zdrojů dat ve světě.
Nejlepší je přijmout prostý fakt, že jsem nenavrhoval ERDDAP™ rozmístěno jako vícenásobná identická ERDDAP s vyvažovačem zatížení. I vědomě navržen ERDDAP™ pracovat dobře v rámci federace ERDDAP Myslím, že má mnoho výhod. Federace ERDDAP s je dokonale sladěno s decentralizovaným, distribuovaným systémem datových center, která máme v reálném světě (Myslete na různé regiony IOOS, nebo různé regiony CoastWatch, nebo různé části NCEI, nebo 100 dalších datových center v NOAA , nebo různé NASA DAAC, nebo 1000's datových center po celém světě) . Místo toho, aby řekli všem datacentrům světa, že musí opustit své úsilí a dát všechna data do centralizovaného "data lake" (i kdyby to bylo možné, je to hrozný nápad z mnoha důvodů - viz různé analýzy ukazující četné výhody decentralizované systémy ) , ERDDAP Design pracuje se světem tak, jak je. Každé datové centrum, které vytváří data, může i nadále udržovat, kurovat a sloužit svým údajům (jak by měly) , a přesto, s ERDDAP™ , data mohou být také okamžitě k dispozici z centralizované ERDDAP , bez nutnosti přenosu dat do centralizované ERDDAP™ nebo uchovávání duplikátních kopií údajů. Vskutku, daný soubor údajů může být současně k dispozici z ERDDAP™ v organizaci, která vytvořila a skutečně uchovává údaje (např. GoMOOS) , z ERDDAP™ v mateřské organizaci (např. IOOS central) , ze všech- NOAA ERDDAP™ , od americké federální vlády ERDDAP™ , z globálního ERDDAP™ (Goos) , a ze specializovaných ERDDAP án (např. ERDDAP™ v instituci věnované výzkumu HAB) , všechny v podstatě okamžitě a efektivně, protože pouze metadata jsou přenesena mezi ERDDAP S, ne data. Nejlepší ze všeho, po iniciálu ERDDAP™ v původní organizaci, všechny ostatní ERDDAP s lze nastavit rychle (Pár hodin práce) , s minimálními zdroji (jeden server, který nepotřebuje RAID pro ukládání dat, protože neukládá žádná data lokálně) , a tedy za skutečně minimální cenu. Porovnejte to s náklady na zřízení a udržování centralizovaného datového centra s datovým jezerem a nutností skutečně masivního, skutečně drahého připojení k internetu, plus s doprovodem problému centralizovaného datového centra je jediným místem selhání. Pro mě, ERDDAP Decentralizovaný přístup je daleko lepší.
V situacích, kdy dané datové centrum potřebuje více ERDDAP s k uspokojení vysoké poptávky, ERDDAP 's designem je plně schopen sladit nebo překročit výkon víceidentického-- ERDDAP s-s-a-balancer přístup. Vždycky máš možnost nastavit vícesložkové ERDDAP án (jak je uvedeno níže) , každý z nich dostane všechny své údaje od ostatních ERDDAP s, bez vyvažování zatížení. V tomto případě doporučuji vám, abyste dali každému z kompozitů ERDDAP s odlišným jménem / identitou a pokud možno nastavením v různých částech světa (např. různé oblasti AWS) např. ERD \_US\_Východ, ERD \_US\_West, ERD \_IE, ERD \_FR, ERD \_IT, takže uživatelé vědomě, opakovaně, pracovat s konkrétní ERDDAP , s přidaným přínosem, že jste odstranili riziko z jediného bodu selhání.
Mřížky, hvězdokupy a federace
Při velmi těžkém použití, jediný samostatný ERDDAP™ narazí na jednu nebo více z omezení uvedené výše a dokonce i navrhované řešení budou nedostatečné. V takových situacích ERDDAP™ má vlastnosti, které usnadňují konstrukci škálovatelných sítí (také nazývané klastry nebo federace) z ERDDAP s, které umožňují systému zvládnout velmi těžké použití (např. pro velké datové centrum) .
Používám mřížka jako obecný výraz pro označení typu počítačový klastr kde všechny části mohou nebo nemusí být fyzicky umístěny v jednom zařízení a mohou nebo nemusí být centrálně spravovány. Výhoda společných, centrálně vlastněných a regulovaných sítí (klastry) že mají prospěch z úspor z rozsahu (zejména pracovní zátěž) a zjednodušit fungování částí systému. Výhoda nelokovaných sítí, které nejsou centrálně vlastněny a spravovány (federace) je to, že distribuují lidskou pracovní zátěž a náklady a mohou poskytnout dodatečnou chybovou toleranci. Řešení, které navrhuji níže, funguje dobře pro všechny topografie sítě, clusteru a federace.
Základní myšlenkou návrhu škálovatelného systému je určit potenciální překážky a navrhnout systém tak, aby části systému mohly být replikovány podle potřeby ke zmírnění překážek. V ideálním případě každá replikovaná část zvyšuje kapacitu této části systému lineárně (účinnost škálování) . Systém není škálovatelný, pokud neexistuje škálovatelné řešení pro každý výběžek. Skalovatelnost se liší od účinnosti (jak rychle je možné provést úkol - účinnost dílů) . Škálovatelnost umožňuje, aby systém rostl a zvládl jakoukoli úroveň poptávky. Účinnost (o rozměrech a částech) určuje, kolik serverů, atd. bude potřeba k uspokojení dané úrovně poptávky. Účinnost je velmi důležitá, ale vždy má limity. Škálovatelnost je jediným praktickým řešením budování systému, který dokáže zvládnout velmi těžké využití. V ideálním případě bude systém škálovatelný a efektivní.
Cíle
Cílem tohoto návrhu jsou:
- Vytvořit škálovatelnou architekturu (ten, který je snadno extenzovatelný replikací jakékoliv části, která se stane přetížený) . Pro vytvoření efektivního systému, který maximalizuje dostupnost a průchodnost dat za předpokladu dostupných výpočetních zdrojů. (Cena je téměř vždy problém.)
- Vyvážit schopnosti částí systému tak, aby jedna část systému nepřemohla další část.
- Vytvořit jednoduchou architekturu tak, aby systém bylo snadné nastavit a spravovat.
- Vytvořit architekturu, která dobře funguje se všemi topografiemi.
- Vytvořit systém, který elegantně a omezeně selže, pokud se nějaká část přetíží. (Čas potřebný k kopírování velkých souborů dat vždy omezí schopnost systému vypořádat se s náhlým zvýšením poptávky po určitém datovém souboru.)
- (Pokud je to možné) Vytvořit architekturu, která není vázána na žádné konkrétní cloud computing služby nebo jiné externí služby (Protože je nepotřebuje.) .
Doporučení
Naše doporučení jsou
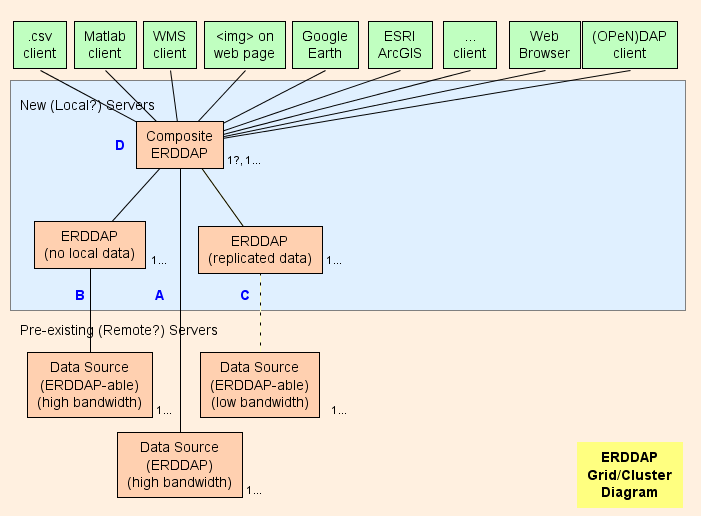
- V podstatě navrhuji vytvořit kompozit. ERDDAP™ ( D v diagramu) , který je pravidelný ERDDAP™ kromě toho, že slouží pouze údaje z jiných ERDDAP s. Architektura sítě je navržena tak, aby co nejvíce pracovala (Využití CPU, využití paměti, využití šířky pásma) z kompozitu ERDDAP™ na druhou ERDDAP s.
- ERDDAP™ má dva speciální typy souborů údajů, EDDGrid FromErddap a EDDTableFromErddap , které odkazují na Údaje o ostatních datech ERDDAP s.
- Při kompozitu ERDDAP™ obdrží žádost o údaje nebo obrázky z těchto souborů souborů, složené ERDDAP™ přesměrování žádost o údaje pro ostatní ERDDAP™ server. Výsledkem je:
- Tohle je velmi efektivní. (CPU, paměť a šířka pásma) , protože jinak
- Kompozit ERDDAP™ musí zaslat žádost o údaje druhé osobě ERDDAP .
- Druhý ERDDAP™ musí získat data, přeformátovat je a předat data kompozitu. ERDDAP .
- Kompozit ERDDAP™ musí přijímat údaje (pomocí extra šířky pásma) , přeformátovat ji (pomocí extra CPU času a paměti) , a předat data uživateli (pomocí extra šířky pásma) . Přesměrováním požadavku na údaje a umožněním druhé ERDDAP™ zaslat odpověď přímo uživateli, složenému ERDDAP™ Netráví v podstatě žádný čas CPU, paměť, nebo šířku pásma na požadavky dat.
- Přesměrování je transparentní pro uživatele bez ohledu na klientský software (prohlížeč nebo jiný software nebo nástroj příkazového řádku) .
- Tohle je velmi efektivní. (CPU, paměť a šířka pásma) , protože jinak
Části mřížky
A : Pro každý vzdálený zdroj dat, který má vysokou šířku pásma OPeNDAP server, můžete se připojit přímo na vzdálený server. Pokud je vzdálený server ERDDAP™ , použití EDDGrid FromErddap nebo EddtableFrom ERDDAP sloužit údajům v kompozitu ERDDAP . Pokud je vzdálený server jiným typem DAP server, např. THREDDS, Hyrax , nebo GRADS, použití EDDGrid FromDap.
B : Pro každý ERDDAP -ovatelný zdroj dat (zdroj dat, z něhož ERDDAP může číst data) který má vysokopásmový server, nastavit další ERDDAP™ v síti, která je odpovědná za poskytování údajů z tohoto zdroje dat.
- Pokud několik takových ERDDAP s nedostává mnoho žádostí o data, můžete je konsolidovat do jedné ERDDAP .
- Pokud ERDDAP™ věnované získání dat z jednoho vzdáleného zdroje je dostat příliš mnoho požadavků, tam je pokušení přidat další ERDDAP s přístup ke vzdálenému zdroji dat. Ve zvláštních případech to možná dává smysl, ale je pravděpodobnější, že to přemůže vzdálený zdroj dat. (která se sama porazí) a také zabránit ostatním uživatelům v přístupu ke vzdálenému zdroji dat (Což není hezké.) . V takovém případě zvažte zřízení jiného ERDDAP™ sloužit tomuto datovému souboru a zkopírovat datový soubor na něm ERDDAP 's pevným diskem (viz C ) , snad s EDDGrid Kopírovat nebo EDDtableCopy .
- B servery musí být veřejně přístupné.
C : Pro každý ERDDAP -schopný zdroj dat, který má nízkopásmový server (nebo je pomalý servis z jiných důvodů) , Zvažte zřízení jiného ERDDAP™ a uložení kopie souboru údajů na něm ERDDAP 's pevnými disky, možná s EDDGrid Kopírovat nebo EDDtableCopy . Pokud několik takových ERDDAP s nedostává mnoho žádostí o data, můžete je konsolidovat do jedné ERDDAP . C servery musí být veřejně přístupné.
Kompozitní ERDDAP
D : Kompozit ERDDAP™ je pravidelná ERDDAP™ kromě toho, že slouží pouze údaje z jiných ERDDAP s.
- Protože ta kompozice ERDDAP™ má v paměti informace o všech datových souborech, může rychle reagovat na žádosti o seznamy datových souborů (úplné vyhledávání textů, vyhledávání kategorií, seznam všech souborů údajů) , a žádosti o individuální formulář pro přístup k datům datového souboru, vytvořit graf nebo WMS Informační stránka. To vše jsou malé, dynamicky generované HTML stránky založené na informacích, které jsou uloženy v paměti. Takže odpovědi jsou velmi rychlé.
- Protože žádosti o aktuální data jsou rychle přesměrovány na druhou ERDDAP s, složené ERDDAP™ může rychle reagovat na žádosti o aktuální data bez použití CPU času, paměti nebo šířky pásma.
- Přesouváním co nejvíce práce (CPU, paměť, šířka pásma) z kompozitu ERDDAP™ na druhou ERDDAP s, složené ERDDAP™ může se zdát, že slouží data ze všech souborů údajů a přesto stále drží krok s velkým počtem žádostí o údaje od velkého počtu uživatelů.
- Předběžné zkoušky ukazují, že směs ERDDAP™ může reagovat na většinu žádostí v ~1ms času procesoru, nebo 1000 požadavků/sekundu. Takže 8 jádrový procesor by měl být schopen reagovat na asi 8000 požadavků za sekundu. I když je možné si představit výbuchy vyšší aktivity, které by způsobily zpomalení, to je hodně průniku. Je pravděpodobné, že šířka datového centra bude těsnícím výklenem dlouho před kompozitem ERDDAP™ Stane se zákoutí.
Aktuální max (čas) ?
The EDDGrid /TableFromErddap v kompozitu ERDDAP™ změní své uložené informace o každém zdrojovém souboru pouze tehdy, pokud zdrojový soubor je "reloaded"ed a některé změny metadat (např. časová proměnná actual\_range ) , čímž vzniká oznámení o předplatném. Pokud má zdrojový soubor data, která se často mění (například nová data každou sekundu) a používá "aktualizace" systém pro zjištění častých změn základních údajů, EDDGrid /TableFromErddap nebude informován o těchto častých změnách až do dalšího souboru souborů "načíst," takže EDDGrid /TableFromErddap nebude dokonale aktuální. Tento problém lze minimalizovat změnou zdrojového souboru<Načíst každý NMinutes na menší hodnotu (60, 15?) takže existuje více oznámení o předplatném říct EDDGrid /TableFromErddap aktualizovat své informace o zdrojovém souboru.
Nebo pokud váš systém správy dat ví, kdy má zdrojový soubor nová data (např. prostřednictvím skriptu, který kopíruje datový soubor na místo) , a pokud to není super časté (např. každých 5 minut nebo méně často) Existuje lepší řešení:
- Nepoužívejte<aktualizovatEveryNMillis> udržovat zdrojový soubor aktuální.
- Nastavit zdrojový soubor<Načíst každý NMinutes na větší číslo (1440?) .
- Ať skript kontaktuje zdrojový soubor URL vlajky Hned poté, co kopíruje nový datový soubor. To povede k tomu, že zdrojový soubor bude dokonale aktualizován a způsobí, že vytvoří oznámení o předplatném, které bude zasláno EDDGrid /TableFromErddap data data. To povede EDDGrid /TableFromErddap database to be perfectly up-to-date (No, do 5 sekund po přidání nových údajů) . A vše, co bude provedeno efektivně (bez zbytečného opětovného načítání dat) .
Vícesložkové ERDDAP án
- Ve velmi extrémních případech, nebo pro chybovou toleranci, můžete chtít nastavit více než jeden kompozitní ERDDAP . Je pravděpodobné, že ostatní části systému (zejména šířka pásma datového centra) se stane problémem dlouho před složením ERDDAP™ Stane se z toho blázen. Takže řešení je pravděpodobně vytvořit další, geograficky různorodá, data centra (zrcadla) , každý s jedním složených ERDDAP™ a servery s ERDDAP s a (alespoň) zrcadlové kopie souborů údajů, které jsou ve vysoké poptávce. Takové nastavení také poskytuje chybovou toleranci a zálohování dat (prostřednictvím kopírování) . V tomto případě je nejlepší, pokud kompozit ERDDAP s mají různé URL adresy.
Pokud opravdu chcete všechny kompozity ERDDAP s mít stejnou URL, použijte přední koncový systém, který přiřadí daného uživatele jen jednomu z kompozitů ERDDAP án (na základě IP adresy) , aby všechny požadavky uživatele jít jen na jeden z kompozitů ERDDAP s. Existují dva důvody:
- Při opětovném načtení podkladového datového souboru a změně metadat (Například nový datový soubor v mřížkovaném souboru způsobuje časovou proměnnou actual\_range změnit) , složené ERDDAP s bude dočasně mírně mimo synchronizaci, ale s případný soulad . Normálně se do 5 sekund znovu sesynchronizují, ale někdy to bude delší. Pokud uživatel vytvoří automatizovaný systém, který spoléhá na ERDDAP™ předplatné že spouštěcí akce, krátké problémy synchronity se stanou významným.
- 2+ kompozit ERDDAP Každý si udržuje svůj vlastní soubor předplatnéch (protože synchronizace problém popsané výše) .
Takže daný uživatel by měl být nasměrován pouze na jeden z kompozitů. ERDDAP s, aby se zabránilo těmto problémům. Pokud jeden z kompozitů ERDDAP S jde dolů, přední konec systému může přesměrovat, že ERDDAP 's uživateli jiného ERDDAP™ To je ono. Pokud se však jedná o problém s kapacitou, který způsobuje první kompozit ERDDAP™ selhat (příliš horlivý uživatel? a Popírání služebního útoku ?) , To je velmi pravděpodobné, že přesměrování svých uživatelů na jiné složené ERDDAP s Kaskádové selhání . Nej robustější nastavení je tedy mít složené ERDDAP s různými URL adresami.
Nebo snad lépe, nastavit více kompozitů ERDDAP s bez vyvažování zatížení. V tomto případě byste měli mít bod dát každý z ERDDAP s odlišným jménem / identitou a pokud možno nastavením v různých částech světa (např. různé oblasti AWS) např. ERD \_US\_Východ, ERD \_US\_West, ERD \_IE, ERD \_FR, ERD \_IT, takže uživatelé vědomě, opakovaně pracovat s konkrétní ERDDAP .
- \[ Pro fascinující návrh vysoce výkonného systému běžícího na jednom serveru viz tento podrobný popis Mailinatora . \]
Datové soubory ve velmi vysoké poptávce
V opravdu neobvyklém případě, že jeden z A , B nebo C ERDDAP s nemůže udržet krok s požadavky z důvodu šířky pásma nebo omezení pevného disku, to dává smysl kopírovat data (znovu) na jiný server+hard Disk+ ERDDAP , snad s EDDGrid Kopírovat nebo EDDtableCopy . I když se může zdát ideální mít původní datový soubor a zkopírovaný datový soubor se bez problémů objeví jako jeden datový soubor v kompozitu ERDDAP™ , To je obtížné, protože dva soubory souborů budou v trochu různých státech v různých časech (zejména poté, co originál získá nová data, ale předtím, než zkopírovaný soubor dostane svou kopii) . Proto doporučuji, aby byly datové soubory opatřeny mírně odlišnými názvy (Například, "... (kopie #1) "a... (kopie #2) "nebo možná " (zrcadlo # n ) "nebo " (server # n ) ") a zobrazí se jako samostatné soubory údajů v kompozitu ERDDAP . Uživatelé se používají k zobrazení seznamů zrcadlová místa na oblíbených stránkách stahování souborů, takže by je to nemělo překvapit nebo zklamat. Vzhledem k omezení šířky pásma na daném místě, to může mít smysl mít zrcadlo umístěné na jiném místě. Pokud je zrcadlová kopie v jiném datovém centru, je přístupná jen kompozitem datového centra. ERDDAP™ , různé tituly (např. "zrcadlo č.1) nejsou nutné.
RAID versus pravidelné pevné disky
Pokud velký datový soubor nebo skupina souborů dat nejsou silně používány, může mít smysl ukládat data na RAID, protože nabízí chybovou toleranci a protože nepotřebujete procesní výkon nebo šířku pásma jiného serveru. Ale pokud je soubor dat silně používán, může mít větší smysl zkopírovat data na jiném serveru + ERDDAP™ + pevný disk (podobné co dělá Google ) namísto použití jednoho serveru a RAID k ukládání více souborů dat, protože můžete použít oba servery+hardDrive+ ERDDAP Je v síti, dokud jeden z nich nezklame.
Selhání
Co se stane, když...
- Je tu výbuch žádostí o jeden datový soubor (Například všichni studenti ve třídě současně požadují podobná data) ? Pouze ERDDAP™ pokud bude tento soubor údajů přemožen a zpomalen nebo odmítne žádosti. Kompozit ERDDAP™ a další ERDDAP Nebude to ovlivněno. Jelikož mezním faktorem pro daný datový soubor uvnitř systému je pevný disk s daty (ne ERDDAP ) , jediné řešení (není okamžité) je vytvořit kopii datového souboru na jiném serveru+hardDrive+ ERDDAP .
- An A , B nebo C ERDDAP™ selhání (např. selhání pevného disku) ? Pouze datový soubor (án) Sloužil tím ERDDAP™ jsou ovlivněny. Pokud soubor údajů (án) je zrcadlena na jiném serveru+hardDrive+ ERDDAP , Účinek je minimální. Pokud je problémem selhání pevného disku v úrovni 5 nebo 6 RAID, stačí vyměnit disk a nechat RAID obnovit data na disku.
- Kompozit ERDDAP™ Selhává? Pokud chcete vytvořit systém s velmi vysoká dostupnost , můžete připravit vícesložkové ERDDAP án (jak je uvedeno výše) , pomocí něčeho jako NGINX nebo Traefik zvládnout vyvážení nákladu. Poznámka: ERDDAP™ může zvládnout velmi velký počet žádostí od velkého počtu uživatelů, protože žádosti o metadata jsou malé a jsou zpracovávány informacemi, které jsou v paměti, a žádosti o údaje (který může být velký) jsou přesměrovány na dítě ERDDAP s.
Jednoduché, škálovatelné
Tento systém se snadno nastavuje a spravuje a snadno se rozšiřuje, když se jeho část přetíží. Jediná reálná omezení pro dané datové centrum jsou šířka pásma datového centra a cena systému.
Šířka pásma
Všimněte si přibližné šířky pásma běžně používaných součástí systému:
| Složka | Přibližná šířka pásma (GByty/s) |
|---|---|
| DDR paměť | 2. 5 |
| SSD disk | 1 |
| SATA pevný disk | 0, 3 |
| Gigabit Ethernet | 0, 1 |
| OC-12 | 0, 06 |
| OC-3 | 0, 015 |
| T1 | 0, 0002 |
Takže jeden pevný disk SATA. (0, 3GB/ s) na jednom serveru s jedním ERDDAP™ může pravděpodobně nasytit Gigabit Ethernet LAN (0, 1 GB/ s) . A jeden Gigabit Ethernet LAN (0, 1 GB/ s) může pravděpodobně nasytit OC-12 připojení k internetu (0, 06GB/s) . A nejméně jeden zdrojový seznam linek OC-12 stojí asi 100 000 dolarů měsíčně. (Ano, tyto výpočty jsou založeny na posunu systému na jeho limity, což není dobré, protože vede k velmi pomalým reakcím. Tyto výpočty jsou však užitečné pro plánování a vyvážení částí systému.) Je zřejmé, že vhodné rychlé připojení k internetu pro vaše datové centrum je zdaleka nejdražší část systému. Můžete snadno a relativně levně postavit mřížku s tuctem serverů běžící tucet ERDDAP s, který je schopen pumpovat spoustu dat rychle, ale vhodně rychlé připojení k internetu bude velmi, velmi drahé. Částečné roztoky jsou:
- Povzbuzovat klienty, aby požadovali podmnožiny dat, pokud je to vše, co je potřeba. Pokud klient potřebuje pouze údaje pro malý region nebo v menším rozlišení, měli by o to požádat. Subsetting je ústředním zaměřením protokolů ERDDAP™ podporuje žádost o údaje.
- Podporujte přenos komprimovaných dat. ERDDAP™ obklady přenos dat, pokud nalezne "přijímací kódování" v HTTP GET Žádám hlavičku. Všechny webové prohlížeče používají "accept-encoding" a automaticky dekompresují odpověď. Ostatní klienti (Například počítačové programy) musím to použít explicitně.
- Najdi servery na ISP nebo jiné stránce, která nabízí relativně nižší náklady na šířku pásma.
- Rozptylte servery pomocí ERDDAP S různými institucemi tak, aby náklady byly rozptýleny. Pak můžete spojit kompozit ERDDAP™ k jejich ERDDAP s.
Všimněte si, že Cloud Computing a webhostingové služby nabízejí veškerou šířku pásma, kterou potřebujete, ale nevyřešte problém s cenou.
Obecné informace o návrhu škálovatelných, vysoce kapacitních, systémů tolerantních k poruchám viz kniha Michaela T. Nygarda Uvolněte ji. .
Jako Lego.
Software designéři se často snaží používat dobré vzory návrhu softwaru řešit problémy. Dobré vzory jsou dobré, protože zapoutají dobré, snadno vytvořit a pracovat s, univerzální řešení, která vedou k systémům s dobrými vlastnostmi. Vzor jména nejsou standardizována, takže nazvu vzor, že ERDDAP™ používá Lego vzor. Každé Lego (každý ERDDAP ) je jednoduchý, malý, standardní, samostatný, cihlový (datový server) s definovaným rozhraním, které umožňuje připojení k jiným legos ( ERDDAP án) . Části ERDDAP™ které tvoří tento systém jsou: předplatné a flagURL systémy (která umožňuje komunikaci mezi ERDDAP án) EDD... FromErddap přesměrování systém, a systém RESTful žádosti o údaje, které mohou získat uživatelé nebo jiní ERDDAP s. Takže, vzhledem k dvěma nebo více legos ( ERDDAP án) , můžete vytvořit obrovské množství různých tvarů (topologie sítě ERDDAP án) . Jistě, design a vlastnosti ERDDAP™ mohlo být provedeno jinak, ne jako Lego, možná jen proto, aby bylo možné a optimalizováno pro jednu konkrétní topologii. Ale cítíme, že ERDDAP 's Lego-jako design nabízí dobré, univerzální řešení, které umožňuje ERDDAP™ Správce (nebo skupina správců) vytvořit různé druhy topologie federace. Například jedna organizace by mohla vytvořit tři (nebo více) ERDDAP s, jak je uvedeno v ERDDAP™ Nákres mřížky/Cluster výše . Nebo distribuovaná skupina (IOOS? Pobřežní hlídka? NCEI? NWS? NOAA ? USS? Dataone? Neon? LTERe? OOI? BODC? Onc? SVS? WMO?) může nastavit jeden ERDDAP™ v každé malé základně (takže data mohou zůstat blízko zdroje) a pak nastavit složené ERDDAP™ v centrální kanceláři s virtuálními soubory dat (které jsou vždy dokonale aktuální) z každé malé základny ERDDAP s. Vskutku, všechny ERDDAP s, instalován v různých institucích po celém světě, které získávají data od jiných ERDDAP s a/nebo poskytovat údaje jiným ERDDAP s, tvoří obrovskou síť ERDDAP s. Není to super? Takže stejně jako u Lega jsou možnosti nekonečné. Proto je to dobrý vzor. Proto je to dobrý design. ERDDAP .
Různé typy žádostí
Jednou z reálných komplikací této diskuse o topologii datového serveru je to, že existují různé typy žádostí a různé způsoby optimalizace pro různé typy žádostí. Tohle je většinou samostatná otázka. (Jak rychle může ERDDAP™ pokud údaje odpovídají na žádost o údaje?) z diskuse o topologii (který se zabývá vztahy mezi datovými servery a který server má aktuální data) . ERDDAP™ , samozřejmě, snaží vypořádat se se všemi typy žádostí efektivně, ale zachází s některými lepšími než ostatní.
- Mnoho žádostí je jednoduchých. Například: Jaké jsou metadata pro tento datový soubor? Nebo: Jaké jsou hodnoty časového rozměru tohoto mřížkovaného souboru? ERDDAP™ je navržen tak, aby s nimi manipuloval co nejrychleji (obvykle v<=2 ms) udržováním této informace v paměti.
- Některé požadavky jsou mírně těžké. Například: Dejte mi tuto podmnožinu datového souboru. (který je v jednom datovém souboru) . Tyto požadavky lze řešit poměrně rychle, protože nejsou tak těžké.
- Některé požadavky jsou těžké, a proto jsou časově náročné. Například: Dejte mi tuto podmnožinu datového souboru. (který může být v některém z 10 000+ datových souborů, nebo by mohl být z komprimovaných datových souborů, které každý trvá 10 sekund na dekompresi) . ERDDAP™ v2.0 uvedl některé nové, rychlejší způsoby, jak se s těmito požadavky vypořádat, zejména tím, že umožnil, aby nit pro zpracování žádostí rozmnožila několik pracovních nití, které řeší různé podskupiny žádosti. Ale existuje jiný přístup k tomuto problému, který ERDDAP™ dosud nepodporuje: podmnožiny datových souborů pro daný datový soubor by mohly být uloženy a analyzovány na samostatných počítačích, a pak výsledky kombinované na původním serveru. Tento přístup se nazývá MapReduce a je příkladem Hadoop předseda , první (?) open-source MapReduce program, který byl založen na nápadech z Google papíru. (Pokud potřebujete MapReduce ERDDAP , prosím pošlete e-mailovou žádost na erd.data at noaa.gov .) Google Velká škola je zajímavé, protože se zdá, že se jedná o implementaci MapReduce aplikované na subsetting tabulkových dat, která je jedním z ERDDAP 's hlavními cíli. Je pravděpodobné, že můžete vytvořit ERDDAP™ Soubor dat z souboru BigQuery přes EDDtableFromDatabase protože k BigQuery lze přistupovat přes rozhraní JDBC.
To jsou moje názory.
Ano, výpočty jsou zjednodušené. (a nyní mírně datovaný) Ale myslím, že závěry jsou správné. Použil jsem chybnou logiku nebo jsem udělal chybu ve svých výpočtech? Pokud ano, je to jen moje chyba. Prosím, pošlete e-mail s opravou erd dot data at noaa dot gov .
Cloud Computing
Několik společností nabízí cloud computing služby (např. Amazon Webové služby a Google Cloud Platform ) . Web hostingové společnosti nabízejí jednodušší služby od poloviny 90. let, ale služby "cloud" značně rozšířily flexibilitu systémů a nabídku služeb. Od ERDDAP™ mřížka se skládá z ERDDAP s a od ERDDAP s jsou Java webové aplikace, které mohou běžet v Tomcat (nejčastější server aplikace) nebo jiné servery aplikace by mělo být relativně snadné nastavit ERDDAP™ mřížka na cloudové službě nebo web hosting stránky. Výhody těchto služeb jsou:
- Nabízejí přístup k velmi vysoké šířce pásma připojení k internetu. To samo o sobě může ospravedlnit používání těchto služeb.
- Platí jen za služby, které používáte. Například získáte přístup k velmi vysokému připojení k internetu, ale platíte pouze za skutečně přenášená data. To vám umožní vybudovat systém, který se zřídkakdy přemůže (i při nejvyšší poptávce) , aniž by museli platit za kapacitu, která je zřídka používaná.
- Jsou snadno rozšiřitelné. Můžete změnit typy serverů nebo přidat tolik serverů nebo tolik úložišť, kolik chcete, za méně než minutu. To samo o sobě může ospravedlnit používání těchto služeb.
- Osvobodí vás od mnoha administrativních povinností provozování serverů a sítí. To samo o sobě může ospravedlnit používání těchto služeb.
Nevýhodou těchto služeb jsou:
- Za své služby si někdy účtují hodně. (v absolutních hodnotách, ne že by to nebyla dobrá hodnota) . Ceny uvedené zde jsou pro Amazon EC2 . Tyto ceny (od června 2015) Sleze dolů.
V minulosti byly ceny vyšší, ale datové soubory a počet žádostí byly menší.
V budoucnu budou ceny nižší, ale datové soubory a počet žádostí budou větší.
Detaily se mění, ale situace zůstává relativně konstantní.
A není to tím, že služba je předražená, ale že používáme a kupujeme mnoho služeb.
- Přenos dat do systému je nyní zdarma (Jo!) . Přenosy dat ze systému jsou 0,09 $/GB. Jeden pevný disk SATA (0, 3GB/ s) na jednom serveru s jedním ERDDAP™ může pravděpodobně nasytit Gigabit Ethernet LAN (0, 1 GB/ s) . One Gigabit Ethernet LAN (0, 1 GB/ s) může pravděpodobně nasytit OC-12 připojení k internetu (0, 06GB/s) . Pokud jedno připojení OC-12 může přenášet ~150.000 GB/měsíc, náklady na přenos dat by mohly být až 150.000 GB @ $0.09/GB = $13.500/měsíc, což je významná cena. Očividně, pokud máte tucet těžce pracujících ERDDAP s v cloudové službě, vaše měsíční poplatky za přenos dat by mohly být podstatné (až do 162 000 dolarů za měsíc) . (Opět, není to tím, že služba je předražená, je to, že používáme a kupujeme mnoho služeb.)
- Úložiště dat Amazon účtuje 50 dolarů za měsíc na TB. (Srovnejte to s nákupem podniku 4TB přímo za ~50 dolarů/TB, i když RAID připočte k celkovým nákladům.) Takže pokud potřebujete uložit spoustu dat do cloudu, mohlo by to být dost drahé. (např. 100 TB by stálo 5000 dolarů za měsíc) . Ale pokud nemáte opravdu velké množství dat, jedná se o menší problém, než je šířka pásma / přenos dat náklady. (Opět, není to tím, že služba je předražená, je to, že používáme a kupujeme mnoho služeb.)
Subsetting
- Problém s posouváním: Jediný způsob, jak efektivně šířit data z datových souborů, je mít program, který distribuuje data (např. ERDDAP ) běžící na serveru, který má data uložená na místním pevném disku (nebo podobně rychlý přístup k SAN nebo místní RAID) . Místní souborové systémy umožňují ERDDAP™ (a základní knihovny, jako je netcdf-java) požadovat konkrétní byte se pohybuje od souborů a získat odpovědi velmi rychle. Mnoho typů žádostí o údaje od ERDDAP™ do souboru (zejména žádosti o mřížku údajů, pokud je hodnota kroku > 1) nelze provést efektivně, pokud program vyžaduje celý soubor nebo velké kusy souboru z nelokálního (proto pomaleji) systém ukládání dat a pak extrahovat podmnožinu. Pokud cloud nastavení nedává ERDDAP™ rychlý přístup k byte rozsahy souborů (stejně rychle jako u místních souborů) , ERDDAP 's přístupem k datům bude těžké zablokovat a potlačit další výhody využívání cloudové služby.
Hostované údaje
Alternativa k výše uvedené analýze přínosů nákladů (která je založena na majiteli údajů (např. NOAA ) platby za uložení jejich dat v cloudu) Dorazila kolem roku 2012, kdy Amazon (a v menší míře i někteří další poskytovatelé cloudů) začal hostovat některé soubory v jejich cloudu (AWS S3) zdarma (pravděpodobně s nadějí, že by mohli získat zpět své náklady, pokud by uživatelé pronajali AWS EC2 Comput instance pro práci s těmito údaji) . Je zřejmé, že díky tomu je cloud computing mnohem dražší, protože čas a náklady nahrávají data a hosting jsou nyní nulové. S ERDDAP™ v2.0, existují nové funkce pro usnadnění provozu ERDDAP v mraku:
- Takže... EDDGrid FromFiles nebo EDDTableFromFoles lze vytvořit z datových souborů, které jsou vzdálené a přístupné přes internet (např. kbelíky AWS S3) použitím<cacheFromUrl> a<cacheSize Možnosti. ERDDAP™ bude udržovat místní cache nejpoužívanějších datových souborů.
- Nyní, pokud jsou komprimovány některé EDDTableFromFoles zdrojové soubory (např. .tgz ) , ERDDAP™ automaticky je dekompresuje, když je čte.
- Takže... ERDDAP™ vlákno reagující na danou žádost bude plodit pracovní vlákno pracovat na pododdílech žádosti, pokud používáte<NThreads> Možnosti. Tato paralela by měla umožnit rychlejší reakci na náročné požadavky.
Tyto změny řeší problém AWS S3 nenabízí lokální úložiště souborů na úrovni bloku a (starý) problém přístupu k údajům S3 s významným zpožděním. (Před lety (~2014) , že tato prodleva byla významná, ale nyní je mnohem kratší a tak není tak významná.) Celkem to znamená, že nastavení ERDDAP™ V oblacích teď funguje mnohem lépe.
Díky. Mnohokrát děkuji Matthew Arrottovi a jeho skupině v původním OOI úsilí za jejich práci na uvedení ERDDAP™ v cloudu a výsledná diskuse.
Vzdálená replikace datových souborů
Existuje společný problém, který souvisí s výše uvedenými diskusemi o sítích a federacích ERDDAP s: vzdálená replikace souborů dat. Základním problémem je: poskytovatel údajů udržuje datový soubor, který se občas mění a uživatel chce udržovat aktuální místní kopii tohoto datového souboru. (z různých důvodů) . Je zřejmé, že je zde obrovské množství variant. Některé varianty jsou mnohem těžší než jiné.
- Rychlé aktualizace Je těžší udržet místní data aktuální. okamžitě (např. do 3 sekund) po každé změně zdroje, spíše než například během několika hodin.
- Časté změny Časté změny je těžší řešit než časté změny. Například změny jednou denně jsou mnohem jednodušší než změny každé 0,1 sekundy.
- Malé změny Malé změny zdrojového souboru je těžší řešit než zcela nový soubor. To platí zejména v případě, že malé změny mohou být kdekoliv v souboru. Malé změny se obtížněji detekují a ztěžují izolaci dat, která je třeba replikovat. Nové soubory lze snadno detekovat a efektivně přenášet.
- Celý soubor dat Udržování celého souboru aktuálních dat je těžší než uchovávání dat z poslední doby. Někteří uživatelé jen potřebují aktuální údaje (např. hodnota posledních 8 dnů) .
- Mnohonásobné kopie Udržování více vzdálených kopií na různých místech je těžší než udržování jedné vzdálené kopie. Tohle je problém se škálováním.
Samozřejmě existuje velké množství variant možných typů změn zdrojového souboru a potřeb a očekávání uživatele. Mnohé varianty je velmi obtížné vyřešit. Nejlepším řešením pro jednu situaci je často není nejlepší řešení pro jinou situaci.
Příslušná ERDDAP™ Nástroje
ERDDAP™ nabízí několik nástrojů, které lze použít jako součást systému, který usiluje o udržení vzdálené kopie datového souboru:
- ERDDAP 's RSS (Přehled bohatých stránek?) služba
nabízí rychlý způsob, jak zkontrolovat, zda soubor dat na vzdáleném ERDDAP™ se změnil. - ERDDAP 's služba předplatného
je efektivnější (než RSS ) přístup: okamžitě zašle e-mail nebo kontakt na URL každému účastníkovi, kdykoli je soubor dat aktualizován a aktualizace vedla ke změně. Je efektivní v tom, že se to stane ASAP a neexistuje žádné zbytečné úsilí (jako při hlasování RSS služba) . Uživatelé mohou používat jiné nástroje (jako IFTTT ) reagovat na e-mailové oznámení ze systému předplatného. Například uživatel by se mohl přihlásit k datovému souboru na vzdáleném ERDDAP™ a pomocí IFTTT reagovat na oznámení o předplatném a spustit aktualizaci místního datového souboru. - ERDDAP 's Systém vlajky
poskytuje způsob pro ERDDAP™ správce, aby na svém/jejím účtu oznámil soubor údajů ERDDAP Nabít co nejdřív. URL forma vlajky lze snadno použít ve skriptech. URL forma vlajky může být také použita jako akce pro předplatné. - ERDDAP 's "files" systém
může nabídnout přístup ke zdrojovým souborům pro daný datový soubor, včetně seznamu adresářů ve stylu Apache ("Web přístupná složka") který má každý soubor stáhnout URL, naposledy upravený čas a velikost. Jedna nevýhoda použití "files" systém je, že zdrojové soubory mohou mít různé názvy proměnných a různá metadata než datový soubor, jak se objeví v ERDDAP . Pokud je ovladač ERDDAP™ Databáze nabízí přístup ke zdrojovým souborům, které otevírají možnost verze rsyncu chudého člověka: pro místní systém je snadné zjistit, které vzdálené soubory se změnily a které je třeba stáhnout. (Viz cacheFromUrl volba pod kterým to může využít.)
Řešení
Přestože existuje obrovské množství variant problému a nekonečný počet možných řešení, existuje jen hrstka základních přístupů k řešení:
Vlastní, Brute Force Solutions
Zjevným řešením je ručně vyrobit vlastní řešení, které je proto pro danou situaci optimalizováno: vytvořit systém, který detekuje/identifikuje, která data se změnila, a odeslat tyto informace uživateli, aby uživatel mohl požádat o změněná data. Můžeš to udělat, ale jsou tu nevýhody:
- Vlastní řešení jsou hodně práce.
- Vlastní řešení jsou obvykle tak přizpůsobená danému datovému souboru a danému systému uživatele, že je nelze snadno znovu použít.
- Vlastní řešení musí být postavena a udržována vámi. (To není nikdy dobrý nápad. Vždycky je dobrý nápad vyhnout se práci a přimět někoho jiného, aby tu práci odvedl!)
Odradím se tohoto přístupu, protože je téměř vždy lepší hledat obecná řešení, postavená a udržovaná někým jiným, která lze snadno znovu použít v různých situacích.
rsync
rsync je existující, ohromně dobré, obecné řešení pro udržení sběru souborů na zdrojovém počítači synchronizovat na vzdáleném počítači uživatele. Funguje to takhle:
- nějaká událost (např. ERDDAP™ událost systému předplatného) spouštěče běžící rsync, (nebo cron práce běží rsync v určité době každý den na počítači uživatele)
- který kontaktuje Rsync na zdrojovém počítači,
- který počítá sérii hashů pro jednotlivé kusy každého souboru a přenáší tyto hashy na rsync uživatele,
- která tyto informace porovnává s podobnými informacemi pro uživatelskou kopii souborů,
- který pak požaduje kousky souborů, které se změnily.
Vzhledem k tomu, co dělá, Rsync pracuje velmi rychle. (např. 10 sekund plus čas přenosu dat) a velmi efektivně. Jsou. Variace rsync které optimalizují různé situace (např. předčíslením a cachováním hashů jednotlivých zdrojových souborů) .
Hlavní slabiny rsynchronizace jsou: je třeba vyvinout určité úsilí (bezpečnostní otázky) ; tam jsou některé problémy škálování; a to není dobré pro udržení NRT soubory opravdu aktuální (Například je trapné používat Rsync více než každých 5 minut) . Pokud se můžete vypořádat se slabostmi, nebo pokud nemají vliv na vaši situaci, rsync je vynikající, obecný účel řešení, které může každý použít k řešení mnoha scénářů zahrnujících vzdálené replikace dat.
Tam je položka na ERDDAP™ Do seznamu se pokusit přidat podporu služeb rsync do ERDDAP (Asi dost těžký úkol.) , aby každý klient mohl použít rsync (nebo varianta) udržovat aktuální kopii datového souboru. Jestli na tom chce někdo pracovat, pošlete prosím e-mail. erd.data at noaa.gov .
Existují i jiné programy, které dělají víceméně to, co dělá rsync, někdy orientované na replikaci dat (i když často na úrovni kopírování souborů) např. Unidata 's IDD .
Cache z Urlu
CacheFromUrl nastavení je k dispozici (Začneme s ERDDAP™ v2. 0) pro všechny ERDDAP 's typy souborů, které vytvářejí soubory dat ze souborů (v podstatě všechny podtřídy EDDGrid FromFiles a EDDTableFromFoles ) . cache FromUrl je triviální automaticky stahovat a udržovat místní datové soubory kopírováním ze vzdáleného zdroje přes cache FromUrl nastavení. Vzdálené soubory mohou být v Web Accessible Složka nebo adresářový seznam souborů nabízených THREDDS, Hyrax , kbelík S3 nebo ERDDAP 's "files" systém.
Pokud je zdroj vzdálených souborů vzdálený ERDDAP™ soubor, který nabízí zdrojové soubory prostřednictvím ERDDAP™ "files" systém, pak můžete upsat do vzdáleného datového souboru a použijte URL vlajky pro váš místní datový soubor jako akci pro předplatné. Pokaždé, když se vzdálený datový soubor změní, kontaktuje pro váš datový soubor URL vlajky, která mu řekne, aby co nejdříve znovu nahrál, což detekuje a stáhne změněné vzdálené datové soubory. Všechno se to děje velmi rychle. (obvykle ~5 sekund plus čas potřebný ke stažení změněné soubory) . Tento přístup funguje skvěle, pokud jsou změny zdrojového souboru pravidelně přidávány nové soubory a pokud se stávající soubory nikdy nezmění. Tento přístup nefunguje dobře, pokud jsou údaje často připojeny ke všem (nebo většina) ze stávajících zdrojových datových souborů, protože pak váš místní datový soubor často stahuje celý vzdálený datový soubor. (To je místo, kde je zapotřebí rsync-jako přístup.)
ArchiveADataset
ERDDAP™ 's ArchiveADataset je dobrým řešením, když jsou data často přidávány do datového souboru, ale starší data se nikdy nemění. V podstatě ERDDAP™ správce může spustit ArchiveADataset (možná ve scénáři, možná běží Cron) a uveďte podmnožinu datového souboru, který chtějí extrahovat (možná v několika souborech) a balení v .zip nebo .tgz soubor, takže soubor můžete poslat zájemcům nebo skupinám (např. NCEI pro archivaci) nebo je k dispozici ke stažení. Například, můžete spustit ArchiveADataset každý den ve 12:10 a nechat to udělat .zip ze všech dat od 12:00 hodin předchozího dne do 12:00 dnes. (Nebo to dělejte každý týden, měsíčně nebo ročně, podle potřeby.) Vzhledem k tomu, že zabalený soubor je generován offline, neexistuje žádné nebezpečí timeout nebo příliš mnoho dat, jak by bylo pro standard ERDDAP™ žádost.
ERDDAP™ 's standardním systémem žádosti
ERDDAP™ 's standardním systémem požadavku je alternativním dobrým řešením, když jsou data často přidávány do souboru dat, ale starší data se nikdy nemění. V podstatě, každý může použít standardní požadavky získat data pro konkrétní rozsah času. Například každý den ve 12:10 si můžete vyžádat všechna data ze vzdáleného datového souboru od 12:00 do 12:00. Omezení (ve srovnání s přístupem ArchiveADataset) je riziko timeout nebo je příliš mnoho dat pro jeden soubor. Můžete se vyhnout omezení tím, že častěji žádosti o menší časové období.
EDDTableFromHttpGet
\[ Tato možnost ještě neexistuje, ale zdá se, že je možné stavět v blízké budoucnosti. \]
Nový EDDTableFromHttpGet Typ souboru v ERDDAP™ v2.0 umožňuje představit si jiné řešení. Základní soubory vedené tímto typem datového souboru jsou v podstatě soubory záznamu, které zaznamenávají změny datového souboru. Mělo by být možné vytvořit systém, který pravidelně udržuje místní datový soubor (nebo na bázi spouštěče) požadovat od této poslední žádosti všechny změny, které byly provedeny ve vzdáleném datovém souboru. To by mělo být stejně účinné. (nebo více) než rsync a bude řešit mnoho složitých scénářů, ale bude fungovat pouze v případě, že vzdálené a místní soubory jsou EDDTableFromHttpGet soubory.
Pokud na tom chce někdo pracovat, kontaktujte prosím erd.data at noaa.gov .
Distribuované údaje
Žádné z výše uvedených řešení nedělá velkou práci při řešení tvrdých variant problému, protože replikace téměř reálného času (NRT) Soubory dat jsou velmi těžké, částečně kvůli všem možným scénářům.
Existuje skvělé řešení: ani se nesnažte replikovat data. Místo toho použijte jediný autoritativní zdroj (jeden datový soubor na jednom ERDDAP ) , vedené poskytovatelem údajů (Např. regionální úřad) . Všichni uživatelé, kteří chtějí data z tohoto souboru, je vždy dostanou ze zdroje. Například aplikace založené na prohlížeči získávají data z URL požadavku, takže by nemělo záležet na tom, aby požadavek byl na původním zdroji na vzdáleném serveru (není stejný server, který hostí ESM) . Mnoho lidí obhajuje tento distribuovaný přístup k datům už dlouho. (např. Roy Mendelssohn za posledních 20 let) . ERDDAP "model mřížky/federace (horní 80% tohoto dokumentu) je založen na tomto přístupu. Toto řešení je jako meč pro Gordian Knot, celý problém zmizí.
- Toto řešení je neuvěřitelně jednoduché.
- Toto řešení je úžasně efektivní, protože se nedělá žádná práce na uchovávání replikovaného souboru dat (án) aktuální.
- Uživatelé mohou získat nejnovější data kdykoliv (např. s latencí pouze ~0,5 sekundy) .
- Docela dobře se měří a existují způsoby, jak zlepšit škálování. (Podívejte se na diskuzi v horní 80% tohoto dokumentu.)
Ne, tohle není řešení pro všechny možné situace, ale je to skvělé řešení pro drtivou většinu. Existují-li problémy/slabosti s tímto řešením v určitých situacích, často stojí za to pracovat na řešení těchto problémů nebo žít s těmito slabostmi kvůli ohromujícím výhodám tohoto řešení. Pokud je toto řešení pro danou situaci skutečně nepřijatelné, např. pokud skutečně musíte mít místní kopii údajů, pak se zamyslete nad ostatními řešeními uvedenými výše.
Závěr
I když neexistuje jediné, jednoduché řešení, které dokonale řeší všechny problémy ve všech scénářích (jako Rsync a Distributed Data jsou téměř) , Doufejme, že existuje dostatek nástrojů a možností, takže můžete najít přijatelné řešení pro vaši konkrétní situaci.