масштабирование
ERDDAP™ Тяжелые нагрузки, сети, кластеры, федерации и облачные вычисления
ERDDAP :
ERDDAP™ Это веб-приложение и веб-сервис, который объединяет научные данные из различных местных и удаленных источников и предлагает простой, последовательный способ загрузки подмножеств данных в общих форматах файлов и создания графиков и карт. На этой странице обсуждаются вопросы, связанные с тяжелыми ERDDAP™ Использование загружает и исследует возможности для борьбы с чрезвычайно тяжелыми нагрузками через сети, кластеры, федерации и облачные вычисления.
Оригинальный вариант был написан в июне 2009 года. Существенных изменений не произошло. Последний раз обновлялся 2019-04-15.
Дисклеймер
Содержание этой веб-страницы является личным мнением Боба Саймонса и не обязательно отражает какую-либо позицию правительства или правительства. National Oceanic and Atmospheric Administration . Расчеты упрощены, но я думаю, что выводы верны. Я использовал неверную логику или ошибся в расчетах? Если это так, то виноват только я. Пожалуйста, отправьте электронное письмо с исправлением erd dot data at noaa dot gov .
Тяжелые грузы / ограничения
При интенсивном использовании, отдельно ERDDAP™ будет ограничен (от большинства до наименее вероятного) посредством:
Дистанционный источник Bandwidth
- Удаленная пропускная способность источника данных — даже при эффективном соединении (Например, через OPeNDAP ) Если удаленный источник данных не имеет очень высокой пропускной способности интернет-соединения, ERDDAP Ответы будут ограничены тем, насколько быстро ERDDAP™ Можно получить данные из источника данных. Решение состоит в том, чтобы скопировать набор данных на ERDDAP Жесткий диск, возможно, с EDDGrid Копия или EDDTableCopy .
ERDDAP Сервер Bandwidth
- Разве что ERDDAP Сервер имеет очень высокую пропускную способность интернет-соединения, ERDDAP Ответы будут ограничены тем, насколько быстро ERDDAP™ Как получить данные из источников и как быстро ERDDAP™ Они могут возвращать данные клиентам. Единственным решением является получение более быстрого интернет-соединения.
Память
- Если одновременно поступает много запросов, ERDDAP™ Может иссякнуть память и временно отказаться от новых запросов. ( ERDDAP™ Есть несколько механизмов, чтобы избежать этого и минимизировать последствия, если это произойдет.) Чем больше памяти на сервере, тем лучше. На 32-битном сервере 4+ ГБ действительно хороши, 2 ГБ в порядке, меньше не рекомендуется. На 64-разрядном сервере вы можете почти полностью избежать проблемы, получив много памяти. Видишь? \-Xmx и -Xms настройки для ERDDAP Томкэт. Ан ERDDAP™ Получение интенсивного использования на компьютере с 64-разрядным сервером с 8 ГБ памяти и -Xmx, установленным на 4000M, редко, если вообще когда-либо, ограничивается памятью.
Управлял Bandwidth
- Доступ к данным, хранящимся на жестком диске сервера, значительно быстрее, чем доступ к удаленным данным. Тем не менее, если ERDDAP™ Сервер имеет очень высокую пропускную способность интернет-соединения, возможно, что доступ к данным на жестком диске будет узким местом. Частичное решение — использовать быстрее. (Например, 10000 RPM) Магнитные жесткие диски или SSD диски (Если это имеет смысл с точки зрения затрат) . Другим решением является хранение различных наборов данных на разных дисках, так что совокупная пропускная способность жесткого диска намного выше.
Слишком много кэшированных файлов
- Слишком много файлов в кэш каталог - ERDDAP™ Кэширует все изображения, но только кэширует данные для определенных типов запросов данных. Возможно, что каталог кэша для набора данных временно имеет большое количество файлов. Это замедлит запросы, чтобы увидеть, находится ли файл в кэше. (Правда!) .<кэш Minutes> в Настройка.xml Позволяет установить, как долго файл может находиться в кэше, прежде чем он будет удален. Установка меньшего числа минимизирует эту проблему.
процессор
- Только две вещи занимают много времени процессора:
- NetCDF 4 и HDF 5 теперь поддерживает внутреннее сжатие данных. Декомпрессия большого сжатого NetCDF 4/ HDF 5 файлов данных могут занять 10 и более секунд. (Это не ошибка реализации. Это природа сжатия.) Таким образом, несколько одновременных запросов к наборам данных с данными, хранящимися в сжатых файлах, могут создать серьезную нагрузку на любой сервер. Если это проблема, решение состоит в том, чтобы хранить популярные наборы данных в несжатых файлах или получить сервер с процессором с большим количеством ядер.
- Изготовление графов (включая карты) : примерно 0,2 - 1 секунда на график. Так что если было много одновременных уникальных запросов на графы ( WMS Клиенты часто делают 6 одновременных запросов!) Может быть ограничение CPU. Когда несколько пользователей работают WMS Клиенты, это становится проблемой.
Несколько идентичных ERDDAP с балансировкой нагрузки?
Часто возникает вопрос: "Чтобы справиться с тяжелыми нагрузками, могу ли я установить несколько идентичных ERDDAP с балансировкой нагрузки? Это интересный вопрос, потому что он быстро доходит до сути. ERDDAP Дизайн. Быстрый ответ — «нет». Я знаю, что это неутешительный ответ, но есть несколько прямых причин и несколько более крупных фундаментальных причин, по которым я разработал эту идею. ERDDAP™ использовать другой подход (федерацией ERDDAP s, описанные в основной части настоящего документа) Я считаю, что это лучшее решение.
Некоторые прямые причины, почему вы не можете / не должны настраивать несколько идентичных ERDDAP s являются:
- данность ERDDAP™ считывает каждый файл данных, когда он впервые становится доступным, чтобы найти диапазоны данных в файле. Затем он хранит эту информацию в индексном файле. Когда пользователь запрашивает данные, ERDDAP™ использует этот индекс, чтобы выяснить, какие файлы искать запрашиваемые данные. Если бы было несколько одинаковых ERDDAP s, каждый из них будет делать эту индексацию, что является потраченным впустую усилием. С федеративной системой, описанной ниже, индексация выполняется только один раз. ERDDAP С.
- Для некоторых типов запросов пользователей (Например, для .nc .png, .pdf файлы) ERDDAP™ Вы должны сделать весь файл, прежде чем ответ будет отправлен. Так ERDDAP™ Храните эти файлы в течение короткого времени. Если идентичный запрос (Как это часто бывает, особенно для изображений, где URL встроен в веб-страницу.) , ERDDAP™ Можно повторно использовать кэшированный файл. В системе множественных идентичных ERDDAP s, эти кэшированные файлы не являются общими, поэтому каждый ERDDAP™ без необходимости и расточительного воссоздания .nc .png или .pdf файлы. С федеративной системой, описанной ниже, файлы создаются только один раз. ERDDAP s и повторно используется.
- ERDDAP Система подписки не настроена для совместного использования несколькими ERDDAP С. Например, если балансировщик нагрузки отправляет пользователя на ERDDAP™ и пользователь подписывается на набор данных, затем другой ERDDAP Вы не будете знать об этой подписке. Позже, если балансировщик нагрузки отправляет пользователя на другой ERDDAP™ и просит список его подписок, другой ERDDAP™ Скажет, что их нет (заставить его / ее сделать дубликат подписки на другой ERED DAP ) . С федеративной системой, описанной ниже, система подписки просто обрабатывается основным, общедоступным, составным. ERDDAP .
Для каждой из этих проблем я мог бы (с большим усилием) Инженерное решение (Для обмена информацией между ERDDAP s) Но я думаю, что федерация ERDDAP подход (описанных в основной части настоящего документа) Это гораздо лучшее общее решение, отчасти потому, что оно имеет дело с другими проблемами. ERDDAP Подход «s-with-a-load-balancer» даже не начинает рассматриваться, особенно децентрализованный характер источников данных в мире.
Лучше всего принять тот простой факт, что я не проектировал. ERDDAP™ развертывается как множественное идентичное ERDDAP s с балансировщиком нагрузки. Я сознательно разработал ERDDAP™ Хорошо работать в федерации ERDDAP s, которые, по моему мнению, имеют много преимуществ. В частности, федерация ERDDAP s идеально согласуется с децентрализованной распределенной системой центров обработки данных, которую мы имеем в реальном мире. (Подумайте о разных регионах IOOS, или о разных регионах CoastWatch, или о разных частях NCEI, или о 100 других центрах обработки данных в разных регионах. NOAA NASA DAAC или 1000 центров обработки данных по всему миру) . Вместо того, чтобы говорить всем дата-центрам мира, что им нужно отказаться от своих усилий и поместить все свои данные в централизованное «озеро данных». (Даже если бы это было возможно, это ужасная идея по многим причинам - см. различные анализы, показывающие многочисленные преимущества децентрализованные системы ) , ERDDAP Дизайн работает с миром таким, какой он есть. Каждый центр обработки данных, который производит данные, может продолжать поддерживать, курировать и обслуживать свои данные. (Как они должны) И все же, с ERDDAP™ Данные также могут быть мгновенно доступны из централизованного источника. ERDDAP без необходимости передачи данных централизованному ERDDAP™ или хранение дублированных копий данных. Действительно, данный набор данных может быть одновременно доступен. из одного ERDDAP™ в организации, которая производит и фактически хранит данные (Например, GoMOOS) , из одного ERDDAP™ в родительской организации (Например, IOOS Central) , от все- NOAA ERDDAP™ , Всеамериканское федеральное правительство ERDDAP™ , от глобального ERDDAP™ (ГУС) , и из специализированных ERDDAP s (Например, ERDDAP™ Институт, посвященный исследованиям HAB) , по существу мгновенно и эффективно, поскольку только метаданные передаются между ERDDAP s, а не данные. В лучшем случае после первоначального ERDDAP™ В первоначальной организации все остальные ERDDAP можно быстро настроить (Несколько часов работы) с минимальными ресурсами (один сервер, который не нуждается в каких-либо RAID для хранения данных, поскольку он не хранит данные локально) Таким образом, при действительно минимальных затратах. Сравните это со стоимостью создания и обслуживания централизованного центра обработки данных с озером данных и потребностью в действительно массовом, действительно дорогостоящем подключении к Интернету, а также сопутствующей проблемой централизованного центра обработки данных. Для меня, ERDDAP Децентрализованный, федеративный подход намного выше.
В ситуациях, когда дата-центру требуется несколько ERDDAP для удовлетворения высокого спроса, ERDDAP Конструкция полностью способна соответствовать или превышать производительность многоидентичной системы. ERDDAP s-with-a-load-balancer подход. У вас всегда есть возможность настроить многокомпонентный ERDDAP s (как обсуждалось ниже) Каждый из них получает свои данные от других. ERDDAP s, без балансировки нагрузки. В этом случае я рекомендую вам уделить внимание каждому из композитов. ERDDAP s другое имя/идентификацию и, если возможно, размещение их в разных частях мира; (Например, различные регионы AWS.) Например, ERD \US\East, ERD США, Запад, ERD \IE, ERD \_FR, ERD IT, чтобы пользователи сознательно, неоднократно, работали с конкретными ERDDAP С дополнительным преимуществом, что вы удалили риск из одной точки отказа.
Сети, кластеры и федерации
При очень интенсивном использовании один отдельный ERDDAP™ Войдет в один или несколько ограничения перечисленных выше, и даже предлагаемых решений будет недостаточно. Для таких ситуаций, ERDDAP™ имеет функции, которые позволяют легко создавать масштабируемые сетки (Также называется кластерами или федерациями.) из ERDDAP s, которые позволяют системе справляться с очень тяжелым использованием; (Например, для большого центра обработки данных) .
Я использую сеть как общий термин для обозначения типа компьютерный кластер где все части могут или не могут быть физически расположены в одном объекте и могут или не могут управляться централизованно. Преимущество совместно расположенных, централизованно принадлежащих и управляемых сетей (кластеры) Они выигрывают от экономии на масштабе. (Особенно человеческий труд) Это упрощает работу частей системы вместе. Преимущество нерасположенных сетей, не централизованно принадлежащих и управляемых (федерации) Они распределяют рабочую нагрузку и стоимость человека и могут обеспечить дополнительную отказоустойчивость. Решение, которое я предлагаю ниже, хорошо подходит для всех топографий сетки, кластера и федерации.
Основная идея разработки масштабируемой системы состоит в том, чтобы определить потенциальные узкие места, а затем спроектировать систему так, чтобы части системы могли быть воспроизведены по мере необходимости, чтобы облегчить узкие места. В идеале каждая реплицированная часть линейно увеличивает емкость этой части системы. (Эффективность масштабирования) . Система не масштабируема, если нет масштабируемого решения для каждого узкого места. масштабируемость отличается от эффективности (Как быстро можно выполнить задачу — эффективность деталей) . Масштабируемость позволяет системе расти и справляться с любым уровнем спроса. Эффективность (Скриншоты Scaling and Of The Parts) определяет, сколько серверов и т.д. потребуется для удовлетворения заданного уровня спроса. Эффективность очень важна, но всегда имеет свои пределы. Масштабируемость является единственным практическим решением для создания системы, которая может работать. очень интенсивное использование. В идеале система будет масштабируемой и эффективной.
Цели
Целями этого дизайна являются:
- Чтобы сделать масштабируемую архитектуру (который легко расширяется путем репликации любой части, которая становится перегруженной) . Создать эффективную систему, которая максимизирует доступность и пропускную способность данных с учетом имеющихся вычислительных ресурсов. (Стоимость почти всегда является проблемой.)
- Сбалансировать возможности частей системы так, чтобы одна часть системы не перегружала другую.
- Создать простую архитектуру, чтобы система была легко настроена и администрировалась.
- Чтобы создать архитектуру, которая хорошо работает со всеми топографиями сетки.
- Создать систему, которая будет грациозно и ограниченно терпеть неудачу, если какая-либо часть будет перегружена. (Время, необходимое для копирования больших наборов данных, всегда будет ограничивать способность системы справляться с внезапным увеличением спроса на конкретный набор данных.)
- (Если возможно) Создать архитектуру, которая не привязана к какой-либо конкретной облачный сервис Услуги или другие внешние услуги (Потому что они им не нужны) .
Рекомендации
Наши рекомендации являются
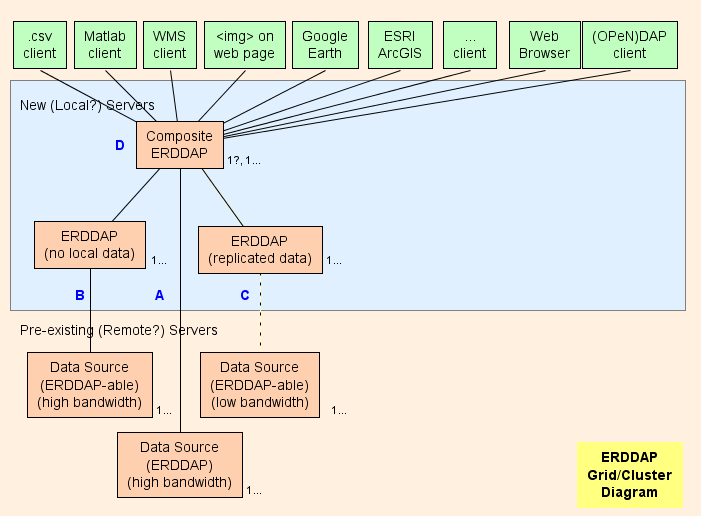
- По сути, я предлагаю создать композицию. ERDDAP™ ( D на диаграмме) которая является регулярной ERDDAP™ Кроме того, он служит только для данных из других источников. ERDDAP С. Архитектура сетки призвана сместить как можно больше работы. (Использование CPU, использование памяти, использование полосы пропускания) Из композита ERDDAP™ к другому ERDDAP С.
- ERDDAP™ имеет два специальных типа данных, EDDGrid Из Эрддапа и EDDTable FromErddap который ссылается на наборы данных на других ERDDAP С.
- Когда композитный ERDDAP™ получает запрос на данные или изображения из этих наборов данных, ERDDAP™ перенаправлять Запрос данных к другому ERDDAP™ Сервер. Результатом является:
- Это очень эффективно (CPU, память и пропускная способность) Потому что иначе
- Композитный ERDDAP™ должен отправить запрос данных другому ERDDAP .
- Другой ERDDAP™ должен получить данные, переформатировать их и передать данные в композитный ERDDAP .
- Композитный ERDDAP™ должен получать данные (Использование дополнительной полосы пропускания) Переформатировать его (Использование дополнительного времени процессора и памяти) и передавать данные пользователю (Использование дополнительной полосы пропускания) . Перенаправляя запрос данных и позволяя другому ERDDAP™ Чтобы отправить ответ непосредственно пользователю, композитный ERDDAP™ По сути, не тратит время процессора, память или пропускную способность на запросы данных.
- Перенаправление является прозрачным для пользователя независимо от клиентского программного обеспечения. (браузер или любое другое программное обеспечение или инструмент командной строки) .
- Это очень эффективно (CPU, память и пропускная способность) Потому что иначе
Сетчатые части
А. : Для каждого удаленного источника данных с высокой пропускной способностью OPeNDAP Вы можете подключиться непосредственно к удаленному серверу. Если удаленный сервер является ERDDAP™ использовать EDDGrid EDDTable FromErddap или EDDTable From ERDDAP Обслуживание данных в Композите ERDDAP . Если удаленный сервер имеет другой тип DAP сервер, например, THREDDS, Hyrax или GrADS, использовать EDDGrid От Депа.
B Для каждого ERDDAP источник данных (источник данных, из которого ERDDAP Может читать данные) Если у вас есть сервер с высокой пропускной способностью, установите другой ERDDAP™ в сети, которая отвечает за обслуживание данных из этого источника данных.
- Если несколько таких ERDDAP s не получает много запросов на данные, вы можете объединить их в один ERDDAP .
- Если ERDDAP™ Для получения данных из одного удаленного источника требуется слишком много запросов, есть соблазн добавить дополнительные. ERDDAP s для доступа к удаленному источнику данных. В особых случаях это может иметь смысл, но более вероятно, что это перегрузит удаленный источник данных. (Что саморазрушительно) Предотвращение доступа других пользователей к удаленному источнику данных (Что не очень приятно) . В таком случае рассмотрите возможность создания другого ERDDAP™ для обслуживания этого одного набора данных и копирования набора данных на этот ERDDAP жесткий диск (смотреть C ) Возможно, с EDDGrid Копия и/или EDDTableCopy .
- B Серверы должны быть общедоступными.
C Для каждого ERDDAP -мобильный источник данных, имеющий сервер с низкой пропускной способностью (медленная работа по другим причинам) Подумайте о создании другого ERDDAP™ и хранить копию набора данных об этом ERDDAP Жесткие диски, возможно, с EDDGrid Копия и/или EDDTableCopy . Если несколько таких ERDDAP s не получает много запросов на данные, вы можете объединить их в один ERDDAP . C Серверы должны быть общедоступными.
композитный ERDDAP
D : Композитный ERDDAP™ является регулярной ERDDAP™ Кроме того, он служит только для данных из других источников. ERDDAP С.
- Потому что композитный ERDDAP™ имеет информацию в памяти обо всех наборах данных, может быстро реагировать на запросы о списках наборов данных; (Полный текстовый поиск, поиск по категориям, список всех наборов данных) , а также запросы на индивидуальную форму доступа к данным, сделать графическую форму или WMS Страница информации. Все это небольшие, динамически генерируемые HTML-страницы на основе информации, хранящейся в памяти. Поэтому ответы очень быстрые.
- Поскольку запросы на фактические данные быстро перенаправляются на другие. ERDDAP s, составной ERDDAP™ Он может быстро реагировать на запросы на фактические данные без использования какого-либо времени процессора, памяти или пропускной способности.
- Перекладывая как можно больше работы (ЦП, память, пропускная способность) Из композита ERDDAP™ к другому ERDDAP s, составной ERDDAP™ Может показаться, что он обслуживает данные из всех наборов данных и все же не отстает от очень большого количества запросов данных от большого числа пользователей.
- Предварительные испытания показали, что состав ERDDAP™ Он может отвечать на большинство запросов в ~ 1 мс процессорного времени или 1000 запросов в секунду. 8-ядерный процессор должен отвечать на 8000 запросов в секунду. Хотя можно представить всплески более высокой активности, которые вызовут замедление, это большая пропускная способность. Вполне вероятно, что пропускная способность центра обработки данных будет узким местом задолго до композита. ERDDAP™ становится узким местом.
Современный max (время) ?
The EDDGrid /TableFromErddap в составе ERDDAP™ только изменяет сохраненную информацию о каждом наборе исходных данных, когда набор исходных данных "перезагрузить" и некоторые изменения метаданных (Например, переменная времени actual\_range ) , тем самым генерируя уведомление о подписке. Если исходный набор данных содержит данные, которые часто меняются (Новые данные каждую секунду) и использует "обновить" системы, чтобы замечать частые изменения базовых данных, EDDGrid /TableFromErddap не будет уведомлен об этих частых изменениях до следующей «перезагрузки» набора данных. EDDGrid Таблица FromErddap не будет полностью обновлена. Вы можете минимизировать эту проблему, изменив исходный набор данных.<ПерезагрузкаEveryNMinutes> в меньшую величину (60? 15?) Чтобы было больше уведомлений о подписке, чтобы сообщить EDDGrid /TableFromErddap обновляет свою информацию об исходном наборе данных.
Или, если ваша система управления данными знает, когда исходный набор данных имеет новые данные. (Например, через скрипт, который копирует файл данных на место) Если это не очень частое (каждые 5 минут или реже) Есть лучшее решение:
- Не используйте<ОбновлениеEveryNMillis> для обновления набора исходных данных.
- Установите исходный набор данных<ПерезагрузкаEveryNMinutes> в большее число (1440?) .
- Пусть сценарий свяжется с исходным набором данных флаг URL Сразу после этого он копирует новый файл данных на место. Это приведет к тому, что исходный набор данных будет полностью обновлен и заставит его генерировать уведомление о подписке, которое будет отправлено на веб-сайт. EDDGrid /TableFromErddap набор данных. Это приведет к EDDGrid /TableFromErddap Dataset будет полностью обновлен (В течение 5 секунд будут добавлены новые данные) . И все это будет сделано эффективно (Без ненужных перезагрузок набора данных) .
Многокомпонентный ERDDAP s
- В крайних случаях или при отказоустойчивости вы можете установить более одного композитного устройства. ERDDAP . Вполне вероятно, что другие части системы (В частности, пропускная способность центра обработки данных) Это станет проблемой задолго до появления композитного материала. ERDDAP™ становится узким местом. Таким образом, решение, вероятно, заключается в создании дополнительных, географически разнообразных центров обработки данных. (зеркала) Каждый из них с одним составным ERDDAP™ и серверов с ERDDAP s и (по крайней мере) зеркальные копии наборов данных, которые пользуются большим спросом. Такая установка также обеспечивает отказоустойчивость и резервное копирование данных (С помощью копирования) . В этом случае лучше всего, если композитный ERDDAP У них разные URL.
Если вы действительно хотите все композиты ERDDAP s, чтобы иметь тот же URL, используйте систему переднего конца, которая присваивает данному пользователю только один из составных элементов. ERDDAP s (на основе IP-адреса) , так что все запросы пользователя идут только на один из составных ERDDAP С. Есть две причины:
- При перезагрузке базового набора данных и изменении метаданных (Например, новый файл данных в сетчатом наборе данных вызывает временную переменную actual\_range меняться) Композитный состав ERDDAP s будет временно немного не синхронизирован, но с Последующая согласованность . Обычно они будут синхронизироваться в течение 5 секунд, но иногда это будет дольше. Если пользователь создает автоматизированную систему, которая опирается на ERDDAP™ подписка Это приводит к тому, что краткосрочные проблемы синхронности становятся значительными.
- Композит 2+ ERDDAP Каждый имеет свой собственный набор подписок. (из-за описанной выше проблемы синхронизации) .
Таким образом, данный пользователь должен быть направлен только на один из составных элементов. ERDDAP чтобы избежать этих проблем. Если один из составных ERDDAP s идет вниз, система переднего конца может перенаправить ERDDAP Пользователи для другого ERDDAP™ Вот так. Однако, если это проблема емкости, которая вызывает первый состав. ERDDAP™ провалиться (Чрезмерный пользователь? а атака типа "отказ в обслуживании" ?) Это делает очень вероятным, что перенаправляет своих пользователей на другие составные устройства. ERDDAP Это приведет к каскадный отказ . Таким образом, наиболее надежной установкой является композитная ERDDAP С разными URL.
Или, возможно, лучше создать несколько композитов. ERDDAP s без балансировки нагрузки. В этом случае вы должны указать на то, что каждый из ERDDAP s другое имя/идентификацию и, если возможно, размещение их в разных частях мира; (Например, различные регионы AWS.) Например, ERD \US\East, ERD США, Запад, ERD \IE, ERD \_FR, ERD IT, чтобы пользователи осознанно, неоднократно работали с конкретными ERDDAP .
- \[ Для увлекательного дизайна высокопроизводительной системы, работающей на одном сервере, см. Подробное описание Mailinator . \]
Наборы данных в очень высоком спросе
В очень необычном случае один из А. , B или C ERDDAP s не может идти в ногу с запросами из-за ограничений пропускной способности или жесткого диска, имеет смысл копировать данные (снова) На другом сервере + Hard Drive+ ERDDAP Возможно, с EDDGrid Копия и/или EDDTableCopy . Хотя может показаться идеальным иметь исходный набор данных, а скопированный набор данных отображается как один набор данных в составе. ERDDAP™ Это сложно, потому что два набора данных будут в разных состояниях в разное время. (В частности, после того, как оригинал получает новые данные, но до того, как скопированный набор данных получает свою копию.) . Поэтому я рекомендую, чтобы наборам данных давали несколько разные названия. (Например, "... (Копия #1) "и"... (Копия #2) "или, возможно," (Зеркало # n ) "или" (Сервер # n ) ") и отображаются как отдельные наборы данных в составе ERDDAP . Пользователи привыкли видеть списки зеркальные сайты на популярных сайтах загрузки файлов, поэтому это не должно удивлять или разочаровывать их. Из-за ограничений пропускной способности на данном сайте может иметь смысл разместить зеркало на другом сайте. Если зеркальная копия находится в другом центре обработки данных, доступ только к композитной копии этого центра обработки данных ERDDAP™ Различные названия (Например, "зеркало #1) В этом нет необходимости.
Рейды против обычных жестких дисков
Если большой набор данных или группа наборов данных не используются в значительной степени, может иметь смысл хранить данные на RAID, поскольку он обеспечивает отказоустойчивость и вам не нужна вычислительная мощность или пропускная способность другого сервера. Но если набор данных широко используется, может иметь смысл копировать данные на другом сервере. ERDDAP™ + жесткий диск (аналогичный Что делает Google ) Вместо того, чтобы использовать один сервер и RAID для хранения нескольких наборов данных, вы можете использовать оба сервера + жесткий диск + ERDDAP s в сетке до тех пор, пока один из них не выйдет из строя.
неудачи
Что произойдет, если...
- Существует множество запросов на один набор данных (Например, все учащиеся одновременно запрашивают аналогичные данные.) ? Только ERDDAP™ Обслуживание этого набора данных будет перегружено и замедлять или отклонять запросы. Композитный ERDDAP™ и другие ERDDAP Это не повлияет. Поскольку ограничивающим фактором для данного набора данных в системе является жесткий диск с данными. (не ERDDAP ) Единственное решение (Немедленно) сделать копию набора данных на другом сервере+hardDrive+ ERDDAP .
- Ан А. , B или C ERDDAP™ провал (Например, отказ жесткого диска) ? Только набор данных (s) обслуживаемых этим ERDDAP™ затронуты. Если набор данных (s) Отражается на другом сервере +hardDrive + ERDDAP Эффект минимальный. Если проблема заключается в отказе жесткого диска на уровне 5 или 6 RAID, вы просто замените диск и попросите RAID восстановить данные на диске.
- Композитный ERDDAP™ провал? Если вы хотите создать систему с очень высокая доступность Вы можете установить многокомпонентный ERDDAP s (Как обсуждалось выше) Используя что-то вроде NGINX или Траефик Для балансировки нагрузки. Обратите внимание, что данный состав ERDDAP™ Они могут обрабатывать большое количество запросов от большого количества пользователей. запросы на метаданные малы и обрабатываются информацией, которая находится в памяти; Запросы данных (который может быть большим) перенаправляется ребенку ERDDAP С.
Простой, масштабируемый
Эта система проста в настройке и администрировании и легко расширяется, когда любая ее часть становится перегруженной. Единственными реальными ограничениями для данного центра обработки данных являются пропускная способность центра обработки данных и стоимость системы.
Пропускная способность
Обратите внимание на примерную пропускную способность часто используемых компонентов системы:
| компонент | Приблизительная пропускная способность (GBytes/s) |
|---|---|
| Память DDR | 2,5 |
| Диск SSD | 1 1 |
| Жесткий диск SATA | 0,3 |
| Гигабитный Ethernet | 0,1 |
| ОК-12 | 0,06 |
| ОК-3 | 0,015 |
| T1 | 0,0002 |
Один жесткий диск SATA (0,3 ГБ/с) На одном сервере с одним ERDDAP™ Может насытить Gigabit Ethernet LAN (0,1 ГБ/с) . Один Gigabit Ethernet LAN (0,1 ГБ/с) Вероятно, может насытить подключение к Интернету OC-12. (0,06 ГБ/с) . И по крайней мере один источник перечисляет линии OC-12 стоимостью около 100 000 долларов в месяц. (Да, эти расчеты основаны на том, чтобы довести систему до предела, что нехорошо, потому что приводит к очень вялым реакциям. Но эти расчеты полезны для планирования и балансировки частей системы.) Очевидно, что подходящее быстрое подключение к Интернету для вашего центра обработки данных является самой дорогой частью системы. Вы можете легко и относительно дешево построить сеть с десятком серверов, работающих на десятке. ERDDAP s, который способен быстро выкачивать много данных, но достаточно быстрое подключение к Интернету будет очень и очень дорогим. Частичные решения:
- Поощряйте клиентов запрашивать подмножества данных, если это все, что необходимо. Если клиенту нужны данные только для небольшого региона или с меньшим разрешением, то он должен запросить их. Поднастройка является центральным направлением протоколов ERDDAP™ Поддержка для запроса данных.
- Поощрять передачу сжатых данных. ERDDAP™ компресс передача данных, если она находит «принятое кодирование» в HTTP GET Запросить заголовок. Все веб-браузеры используют «принять-кодирование» и автоматически декомпрессируют ответ. Другие клиенты (Например, компьютерные программы) должны использовать его явно.
- Сосредоточьте свои серверы на интернет-провайдере или другом сайте, который предлагает относительно менее дорогие расходы на пропускную способность.
- Рассредоточьте серверы вместе с ERDDAP s различным учреждениям, с тем чтобы расходы распределялись. Вы можете связать свой композит ERDDAP™ к их ERDDAP С.
Обратите внимание, что Облачные вычисления Услуги веб-хостинга предлагают всю необходимую вам пропускную способность Интернета, но не решают проблему с ценой.
Для получения общей информации о проектировании масштабируемых, высокопроизводительных, отказоустойчивых систем см. книгу Майкла Т. Нигарда. Освободить .
Как Legos
Разработчики программного обеспечения часто стараются использовать шаблоны проектирования программного обеспечения для решения проблем. Хорошие модели хороши, потому что они инкапсулируют хорошие, простые в создании и работе решения общего назначения, которые приводят к системам с хорошими свойствами. Имена шаблонов не стандартизированы, поэтому я назову шаблон, который ERDDAP™ Используется модель Lego. Каждый Lego (каждый ERDDAP ) простой, маленький, стандартный, автономный, кирпич (сервер данных) с определенным интерфейсом, который позволяет связать его с другими LEGO ( ERDDAP s) . части которых ERDDAP™ В состав этой системы входят: системы подписки и flagURL. (что позволяет осуществлять связь между ERDDAP s) В ЭДД... Система перенаправления FromErddap и система RESTful запросы на данные, которые могут генерироваться пользователями или другими ERDDAP С. Таким образом, дается два или более лего ( ERDDAP s) Вы можете создать огромное количество различных форм. (Топологии сети ERDDAP s) . Конечно, дизайн и особенности ERDDAP™ Это можно было сделать по-другому, а не по-лего, возможно, просто для того, чтобы включить и оптимизировать одну конкретную топологию. Но мы чувствуем, что ERDDAP Lego-подобный дизайн предлагает хорошее универсальное решение, которое позволяет ERDDAP™ администратор (или группы администраторов) Создание различных топологий федерации. Например, одна организация может создать три (или более) ERDDAP как показано в ERDDAP™ Сетка/кластер выше . Распределенная группа (ИУОС? Береговая охрана? НЦЭИ? НВС? NOAA ? USGS? Датаон? Днём? LTER? OOI? BODC? ONC? JRC? ВМО?) Можно установить один ERDDAP™ В каждом маленьком форпосте (Данные могут находиться рядом с источником) После чего установить состав ERDDAP™ Центральный офис с виртуальными наборами данных (которые всегда идеально актуальны) от каждого небольшого форпоста ERDDAP С. Воистину, все ERDDAP s, установленные в различных учреждениях по всему миру, которые получают данные из других ERDDAP s и/или предоставлять данные другим ERDDAP Сформировать гигантскую сеть ERDDAP С. Насколько это круто?! Так что, как и в случае с Lego, возможности бесконечны. Вот почему это хорошая модель. Вот почему это хороший дизайн для ERDDAP .
Различные типы запросов
Одним из реальных осложнений этого обсуждения топологий серверов данных является то, что существуют различные типы запросов и различные способы оптимизации для разных типов запросов. В основном это отдельный вопрос. (Как быстро может ERDDAP™ Когда данные отвечают на запрос данных?) Из топологической дискуссии (который имеет дело с отношениями между серверами данных и на каком сервере имеются фактические данные;) . ERDDAP™ Конечно, старается эффективно справляться со всеми типами запросов, но обрабатывает одни лучше других.
- Многие запросы просты. Например: Каковы метаданные для этого набора данных? Или: Каковы значения временного измерения для этого сетчатого набора данных? ERDDAP™ Они предназначены для того, чтобы работать с ними как можно быстрее (как правило, в любой точке мира).<=2 мс), сохраняя эту информацию в памяти.
- Некоторые запросы умеренно жесткие. Например: Дайте мне это подмножество набора данных (который находится в одном файле данных) . Эти запросы можно обрабатывать относительно быстро, потому что они не так сложны.
- Некоторые запросы являются сложными и, следовательно, требуют много времени. Например: Дайте мне это подмножество набора данных (который может быть в любом из 10 000+ файлов данных или может быть из сжатых файлов данных, каждый из которых занимает 10 секунд для декомпрессии) . ERDDAP™ v2.0 представил несколько новых, более быстрых способов обработки этих запросов, в частности, позволив потоку обработки запросов породить несколько рабочих потоков, которые решают различные подмножества запроса. Но есть и другой подход к этой проблеме, который ERDDAP™ Подмножества файлов данных для данного набора данных могут храниться и анализироваться на отдельных компьютерах, а затем результаты объединяются на исходном сервере. Такой подход называется MapReduce и иллюстрируется Hadoop , первый (?) Программа MapReduce с открытым исходным кодом, которая была основана на идеях из статьи Google. (Если вам нужен MapReduce ERDDAP Пожалуйста, отправьте электронный запрос на erd.data at noaa.gov .) Google BigQuery Интересно, потому что это, кажется, реализация MapReduce применяется к поднастройке табличных наборов данных, который является одним из ERDDAP Основные цели. Вполне вероятно, что вы можете создать ERDDAP™ Набор данных от BigQuery через EDDTable FromDatabase BigQuery можно получить через интерфейс JDBC.
Это мое мнение.
Да, расчеты упрощены. (Теперь немного датирован) Но я думаю, что выводы правильные. Я использовал неверную логику или ошибся в расчетах? Если это так, то виноват только я. Пожалуйста, отправьте электронное письмо с исправлением erd dot data at noaa dot gov .
Облачные вычисления
Несколько компаний предлагают услуги облачных вычислений (например, Amazon Web Services и Google Cloud Platform ) . Веб-хостинговые компании Начиная с середины 1990-х годов, «облачные» сервисы значительно расширили гибкость систем и спектр предлагаемых услуг. С тех пор ERDDAP™ Сетка состоит только из ERDDAP С и с тех пор ERDDAP s являются Java Веб-приложения, которые могут работать в Tomcat (Самый распространенный сервер приложений) или других серверов приложений, относительно легко настроить ERDDAP™ сеть на облачном сервисе или веб-хостинге. Преимуществами этих услуг являются:
- Они предлагают доступ к очень высокой пропускной способности интернет-соединений. Это само по себе может оправдать использование этих услуг.
- Они взимают плату только за услуги, которые вы используете. Например, вы получаете доступ к очень высокой пропускной способности интернет-соединения, но вы платите только за фактически переданные данные. Это позволяет создать систему, которая редко перегружается. (Даже на пике спроса) без необходимости платить за мощность, которая редко используется.
- Они легко расширяются. Вы можете изменить типы серверов или добавить столько серверов или столько памяти, сколько захотите, менее чем за минуту. Это само по себе может оправдать использование этих услуг.
- Они освобождают вас от многих административных обязанностей, связанных с управлением серверами и сетями. Это само по себе может оправдать использование этих услуг.
Недостатками этих услуг являются:
- Они платят за свои услуги, иногда много. (в абсолютном выражении; не то, что это не является хорошей ценностью) . Цены, указанные здесь, для Amazon EC2 . Эти цены (По состоянию на июнь 2015) Он спустится.
В прошлом цены были выше, но файлы данных и количество запросов были меньше.
В будущем цены будут ниже, но файлы данных и количество запросов будет больше.
Детали меняются, но ситуация остается относительно постоянной.
И дело не в том, что сервис завышен, а в том, что мы используем и покупаем большую часть сервиса.
- Передача данных — передача данных в систему теперь бесплатна (Да!) . Передача данных из системы составляет $0,09/GB. Один жесткий диск SATA (0,3 ГБ/с) На одном сервере с одним ERDDAP™ Может насытить Gigabit Ethernet LAN (0,1 ГБ/с) . Одна гигабитная Ethernet LAN (0,1 ГБ/с) Вероятно, может насытить подключение к Интернету OC-12. (0,06 ГБ/с) . Если одно соединение OC-12 может передавать ~ 150 000 ГБ / месяц, затраты на передачу данных могут составлять до 150 000 ГБ @ 0,09 / ГБ = 13 500 долларов / месяц, что является значительной стоимостью. Ясно, если у вас дюжина трудолюбивых ERDDAP Если вы используете облачный сервис, ваши ежемесячные сборы за передачу данных могут быть значительными. (до $162 000 в месяц) . (Опять же, дело не в том, что услуга завышена, а в том, что мы используем и покупаем много услуг.)
- Хранение данных — Amazon взимает 50 долларов в месяц за ТБ. (Сравните это с покупкой корпоративного диска объемом 4 ТБ за 50 долларов США / ТБ, хотя RAID добавляет административные расходы к общей стоимости.) Поэтому, если вам нужно хранить много данных в облаке, это может быть довольно дорого. (Например, 100 ТБ будет стоить 5000 долларов в месяц.) . Но если у вас нет действительно большого количества данных, это меньше, чем затраты на передачу данных. (Опять же, дело не в том, что услуга завышена, а в том, что мы используем и покупаем много услуг.)
Подстановка
- Проблема подмножества: Единственный способ эффективно распространять данные из файлов данных - это иметь программу, которая распределяет данные. (например, ERDDAP ) работает на сервере, который имеет данные, хранящиеся на локальном жестком диске (быстрый доступ к SAN или локальному рейду;) . Локальные файловые системы позволяют ERDDAP™ (и базовые библиотеки, такие как netcdf-java) Запрашивать конкретные байты из файлов и получать ответы очень быстро. Многие типы запросов данных ERDDAP™ к файлу (Особенно сетчатые запросы данных, где значение шага > 1 1) не может быть выполнена эффективно, если программа должна запросить весь файл или большие куски файла из нелокального (Следовательно, медленнее) Система хранения данных, а затем извлечение подмножества. Если облако не выдает ERDDAP™ быстрый доступ к байтовым диапазонам файлов (Как и в случае с локальными файлами) , ERDDAP Доступ к данным будет серьезным узким местом и сведет на нет другие преимущества использования облачного сервиса.
Хостинг данных
Альтернатива вышеуказанному анализу затрат (который основан на данных владельца (например, NOAA ) платить за хранение своих данных в облаке) Это произошло в 2012 году, когда Amazon (В меньшей степени это касается других облачных провайдеров.) начал размещать некоторые наборы данных в своем облаке (AWS S3) бесплатно (Вероятно, с надеждой, что они смогут возместить свои расходы, если пользователи будут арендовать экземпляры вычислений AWS EC2 для работы с этими данными.) . Очевидно, что это делает облачные вычисления гораздо более экономически эффективными, потому что время и стоимость загрузки данных и их размещения теперь равны нулю. с ERDDAP™ v2.0, есть новые функции для облегчения работы ERDDAP В облаке:
- А теперь EDDGrid Набор данных FromFiles или EDDTableFromFiles может быть создан из файлов данных, которые удалены и доступны через Интернет. (Например, ведра AWS S3) используя<CashFromUrl> и<кэшировать GB> варианты. ERDDAP™ Поддерживает локальный кэш из недавно использованных файлов данных.
- Теперь, если какие-либо исходные файлы EDDTableFromFiles сжаты (например, .tgz ) , ERDDAP™ Они автоматически декомпрессируются при их прочтении.
- Теперь, ERDDAP™ поток, отвечающий на данный запрос, будет порождать рабочие потоки для работы над подразделами запроса, если вы используете<nThreads> опции. Такая параллелизация должна позволить быстрее реагировать на сложные запросы.
Эти изменения решают проблему AWS S3, не предлагающего локальное хранилище файлов на уровне блоков. (старый) Проблема доступа к данным S3, имеющим значительное отставание. (Много лет назад (2014) Это отставание было значительным, но теперь оно намного короче и не столь существенно.) В целом, это означает, что создание ERDDAP™ Сейчас в облаке работает намного лучше.
Спасибо. — Большое спасибо Мэтью Арротту и его группе за их работу по созданию ERDDAP™ В облаке и последующее обсуждение.
Удаленная репликация наборов данных
Существует общая проблема, связанная с вышеупомянутым обсуждением сетей и федераций. ERDDAP s: удаленная репликация наборов данных. Основная проблема заключается в том, что поставщик данных поддерживает набор данных, который время от времени меняется, и пользователь хочет поддерживать актуальную локальную копию этого набора данных. (по любой из множества причин) . Очевидно, что существует огромное количество вариаций этого. С некоторыми вариациями гораздо сложнее справиться, чем с другими.
- Быстрые обновления Трудно поддерживать локальный набор данных в актуальном состоянии немедленно (Например, в течение 3 секунд) после каждого изменения источника, а не, например, в течение нескольких часов.
- Частые изменения С частыми изменениями сложнее справиться, чем с редкими. Например, с однодневными изменениями гораздо легче справиться, чем с изменениями каждые 0,1 секунды.
- Небольшие изменения С небольшими изменениями в исходном файле сложнее справиться, чем с совершенно новым. Это особенно актуально, если небольшие изменения могут быть в любом месте файла. Небольшие изменения сложнее обнаружить и затруднить изоляцию данных, которые необходимо реплицировать. Новые файлы легко обнаружить и эффективно передавать.
- Весь набор данных Сохранение всего набора данных в актуальном состоянии сложнее, чем сохранение только последних данных. Некоторым пользователям нужны свежие данные (Например, стоимость последних 8 дней) .
- Несколько копий Сохранение нескольких удаленных копий на разных сайтах сложнее, чем сохранение одной удаленной копии. Это проблема масштабирования.
Очевидно, что существует огромное количество вариаций возможных типов изменений набора исходных данных и потребностей и ожиданий пользователя. Многие из вариаций очень трудно решить. Лучшее решение для одной ситуации часто не лучшее решение для другой ситуации — еще нет универсального великого решения.
относящийся ERDDAP™ Инструменты
ERDDAP™ предлагает несколько инструментов, которые могут быть использованы как часть системы, которая стремится поддерживать удаленную копию набора данных:
- ERDDAP ? RSS (Резюме сайта Rich?) обслуживание
предлагает быстрый способ проверить, есть ли набор данных на удаленном устройстве ERDDAP™ Изменился. - ERDDAP ? подписной сервис
является более эффективным (чем RSS ) Подход: он немедленно отправит электронное письмо или свяжется с URL-адресом каждому подписчику, когда набор данных будет обновлен, и обновление приведет к изменению. Это эффективно в том, что это происходит как можно скорее, и нет никаких потраченных усилий. (Как и в случае с опросом RSS обслуживание) . Пользователи могут использовать другие инструменты (как IFTTT ) реагировать на уведомления электронной почты от системы подписки. Например, пользователь может подписаться на набор данных на удаленном устройстве. ERDDAP™ и использовать IFTTT для реагирования на уведомления о подписке по электронной почте и запуска обновления локального набора данных. - ERDDAP ? флаговая система
Предоставляет способ для ERDDAP™ администратор, чтобы сообщить набор данных о своем ERDDAP Перезагрузить как можно скорее. Форму URL флага можно легко использовать в скриптах. Форма URL флага также может использоваться в качестве действия для подписки. - ERDDAP ? "files" система
может предлагать доступ к исходным файлам для заданного набора данных, включая каталог в стиле Apache. («Веб-доступная папка») который имеет URL загрузки каждого файла, последнее измененное время и размер. Одним из недостатков использования "files" Система заключается в том, что исходные файлы могут иметь разные имена переменных и разные метаданные, чем набор данных, как он появляется в ERDDAP . Если удаленный ERDDAP™ Набор данных предлагает доступ к исходным файлам, что открывает возможность rsync-версии бедного человека: локальной системе становится легко увидеть, какие удаленные файлы изменились и их нужно загрузить. (Видишь? Опция FromUrl Ниже вы можете использовать это.)
Решения
Хотя существует огромное количество вариаций проблемы и бесконечное количество возможных решений, существует всего несколько основных подходов к решению:
Системные требования Brute Force Solutions
Очевидным решением является ручная работа с пользовательским решением, которое, следовательно, оптимизировано для данной ситуации: создать систему, которая обнаруживает / идентифицирует, какие данные изменились, и отправляет эту информацию пользователю, чтобы пользователь мог запросить измененные данные. Ну, вы можете сделать это, но есть недостатки:
- Пользовательские решения – это большая работа.
- Пользовательские решения, как правило, настолько настроены на данный набор данных и систему пользователя, что их нелегко использовать повторно.
- Пользовательские решения должны быть построены и поддерживаться вами. (Это никогда не бывает хорошей идеей. Всегда полезно избегать работы и заставлять кого-то делать работу!)
Я не рекомендую использовать этот подход, потому что почти всегда лучше искать общие решения, построенные и поддерживаемые кем-то другим, которые могут быть легко использованы в различных ситуациях.
рысь
рысь Это существующее, потрясающе хорошее решение общего назначения для хранения коллекции файлов на исходном компьютере синхронизировано на удаленном компьютере пользователя. Как это работает:
- какое-то событие (Например, ERDDAP™ Событие системы подписки) триггеры, запускающие rsync, (или, работа cron работает в определенное время каждый день на компьютере пользователя)
- который контактирует с rsync на исходном компьютере,
- который вычисляет серию хешей для кусков каждого файла и передает эти хеши на синхронизацию пользователя,
- который сравнивает эту информацию с аналогичной информацией для копии файлов пользователя,
- который затем запрашивает куски файлов, которые изменились.
Учитывая все, что он делает, rsync работает очень быстро. (10 секунд плюс время передачи данных) и очень эффективно. Существуют вариации rsync Оптимизация для различных ситуаций (Например, путем предварительного вычисления и кэширования хэшей фрагментов каждого исходного файла) .
Основными недостатками rsync являются: требуется некоторое усилие для настройки. (Вопросы безопасности) ; есть некоторые проблемы масштабирования; и это не хорошо для поддержания наборов данных NRT в актуальном состоянии (Например, неудобно использовать rsync более чем каждые 5 минут.) . Если вы можете справиться с недостатками или если они не влияют на вашу ситуацию, rsync - отличное решение общего назначения, которое любой может использовать прямо сейчас для решения многих сценариев, связанных с удаленной репликацией наборов данных.
Есть пункт на ERDDAP™ Чтобы сделать список, чтобы попытаться добавить поддержку услуг rsync ERDDAP (Вероятно, довольно сложная задача) Для того, чтобы любой клиент мог использовать (или вариант) поддерживать актуальную копию набора данных. Если кто-то хочет работать над этим, пожалуйста, по электронной почте erd.data at noaa.gov .
Есть и другие программы, которые делают больше или меньше того, что делает rsync, иногда ориентированные на репликацию набора данных. (Хотя часто на уровне копирования файлов) Например, Unidata ? IDD .
Кэш из Url
Кэш FromUrl Настройка доступна (Начиная с ERDDAP™ v2.0) Для всех ERDDAP Типы наборов данных, которые делают наборы данных из файлов (В основном, все подклассы EDDGrid Из материалов и EDDTable Из материалов ) . кэш FromUrl позволяет автоматически загружать и поддерживать локальные файлы данных, копируя их из удаленного источника через кэш. Из Урла. Удаленные файлы могут быть в папке Web Accessible Folder или каталог-подобном списке файлов, предлагаемом THREDDS. Hyrax , ведро S3 или ERDDAP ? "files" система.
Если источник удаленных файлов удален ERDDAP™ набор данных, который предлагает исходные файлы через ERDDAP™ "files" Система, тогда вы можете подписывать для удаленного набора данных и использовать флаг URL для вашего локального набора данных в качестве действия для подписки. Затем, когда удаленный набор данных изменится, он свяжется с URL-адресом флага для вашего набора данных, который сообщит ему перезагрузить ASAP, который будет обнаруживать и загружать измененные удаленные файлы данных. Все это происходит очень быстро (обычно ~5 секунд плюс время, необходимое для загрузки измененных файлов;) . Этот подход отлично работает, если изменения набора исходных данных представляют собой периодические добавления новых файлов и когда существующие файлы никогда не меняются. Этот подход не работает хорошо, если данные часто прилагаются ко всем. (или большинство) существующих исходных файлов данных, потому что тогда ваш локальный набор данных часто загружает весь удаленный набор данных. (Именно здесь необходим подход, похожий на ритм.)
Архив данных
ERDDAP™ ? Архив данных Это хорошее решение, когда данные часто добавляются в набор данных, но старые данные никогда не меняются. В основном, ан ERDDAP™ Администратор может запускать ArchiveADataset (Возможно, в сценарии, возможно, под управлением Крона.) и указать подмножество набора данных, которые они хотят извлечь (Возможно, в нескольких файлах) и упаковывается в .zip или .tgz файл, чтобы вы могли отправить файл заинтересованным людям или группам; (Например, NCEI для архивирования) или сделать его доступным для скачивания. Например, вы можете запускать ArchiveADataset каждый день в 12:10 утра. .zip из всех данных с 12:00 утра предыдущего дня до 12:00 утра сегодня. (Делайте это еженедельно, ежемесячно или ежегодно, по мере необходимости.) Поскольку упакованный файл генерируется в автономном режиме, нет опасности тайм-аута или слишком большого количества данных, как это было бы для стандарта. ERDDAP™ просьба.
ERDDAP™ Стандартная система запросов
ERDDAP™ Стандартная система запросов является альтернативным хорошим решением, когда данные часто добавляются в набор данных, но старые данные никогда не меняются. По сути, любой может использовать стандартные запросы для получения данных в течение определенного периода времени. Например, в 12:10 вы можете сделать запрос на все данные из удаленного набора данных с 12:00 предыдущего дня до 12:00 сегодня. Ограничение (По сравнению с подходом ArchiveADataset) Это риск тайм-аута или слишком много данных для одного файла. Вы можете избежать ограничений, делая более частые запросы на меньшие периоды времени.
EDDTable FromHttpGet
\[ Такой вариант пока не существует, но, кажется, его можно построить в ближайшее время. \]
Новый EDDTable FromHttpGet тип набора данных в ERDDAP™ v2.0 позволяет представить другое решение. Базовые файлы, поддерживаемые этим типом набора данных, по существу являются файлами журнала, которые записывают изменения в набор данных. Должна быть возможность создания системы, которая поддерживает локальный набор данных периодически. (или на основе триггера) запросить все изменения, внесенные в удаленный набор данных с момента последнего запроса. Это должно быть столь же эффективным (или более) Он будет работать только в том случае, если удаленные и локальные наборы данных являются EDDTableFromHttpGet.
Если кто-то хочет работать над этим, пожалуйста, свяжитесь с нами erd.data at noaa.gov .
Распределенные данные
Ни одно из вышеперечисленных решений не делает большую работу по решению сложных вариаций проблемы из-за репликации в реальном времени. (НЗТ) Наборы данных очень сложны, отчасти из-за всех возможных сценариев.
Есть отличное решение: даже не пытайтесь воспроизвести данные. Используйте авторитетный источник (Один набор данных на один ERDDAP ) поддерживается поставщиком данных (Например, региональный офис) . Все пользователи, которым нужны данные из этого набора данных, всегда получают их из источника. Например, браузерные приложения получают данные из запроса на основе URL, поэтому не имеет значения, что запрос исходный на удаленном сервере. (Не тот же сервер, который размещает ESM) . Многие люди уже давно поддерживают этот подход к распределенным данным. (Рой Мендельсон в течение последних 20+ лет) . ERDDAP Модель сетки/федерации (80% этого документа) основывается на таком подходе. Это решение похоже на меч для Гордианского узла — вся проблема уходит.
- Это решение потрясающе простое.
- Это решение потрясающе эффективно, так как не делается никакой работы для сохранения реплицированного набора данных. (s) современный.
- Пользователи могут получить последние данные в любое время. (Например, с задержкой всего ~ 0,5 секунды) .
- Он довольно хорошо масштабируется, и есть способы улучшить масштабирование. (Смотрите обсуждение в верхней части 80% этого документа.)
Нет, это не решение для всех возможных ситуаций, но это отличное решение для подавляющего большинства. Если в определенных ситуациях есть проблемы или недостатки с этим решением, часто стоит работать над решением этих проблем или жить с этими недостатками из-за потрясающих преимуществ этого решения. Если это решение действительно неприемлемо для данной ситуации, например, когда вы действительно должны иметь локальную копию данных, рассмотрите другие решения, рассмотренные выше.
Заключение
Пока нет единого, простого решения, которое идеально решает все проблемы во всех сценариях. (как rsync и распределенные данные) Мы надеемся, что есть достаточно инструментов и вариантов, чтобы вы могли найти приемлемое решение для вашей конкретной ситуации.