Skalierung
ERDDAP™ - Schwere Lasten, Gitter, Cluster, Föderationen und Cloud Computing
ERDDAP :
ERDDAP™ ist eine Web-Anwendung und ein Web-Service, der wissenschaftliche Daten aus verschiedenen lokalen und Remote-Quellen aggregiert und bietet eine einfache, konsequente Möglichkeit, Untermengen der Daten in gemeinsamen Dateiformaten herunterzuladen und Grafiken und Karten zu erstellen. Diese Seite diskutiert Probleme im Zusammenhang mit schwer ERDDAP™ Nutzungslasten und erforscht Möglichkeiten für den Umgang mit extrem schweren Lasten über Netze, Cluster, Verbände und Cloud Computing.
Die Originalversion wurde im Juni 2009 geschrieben. Es gab keine signifikanten Änderungen. Dies wurde zuletzt aktualisiert 2019-04-15.
DISCLAIMER
Die Inhalte dieser Seite sind Bob Simons persönliche Meinungen und spiegeln nicht unbedingt jede Position der Regierung oder der National Oceanic and Atmospheric Administration . Die Berechnungen sind simplistisch, aber ich denke, die Schlussfolgerungen sind korrekt. Habe ich Fehler bei meinen Berechnungen gemacht? Wenn ja, ist die Schuld meine allein. Bitte senden Sie eine E-Mail mit der Korrektur an erd dot data at noaa dot gov .
-
- Ja.
Schwere Lasten / Einschränkungen
Mit schwerem Einsatz, Standalone ERDDAP™ wird eingeschränkt werden (von höchster Wahrscheinlichkeit) von:
Remote Source Bandwidth
- Bandbreite einer Remote-Datenquelle — Auch mit einer effizienten Verbindung (z.B. über OPeNDAP ) , es sei denn, eine Remote-Datenquelle hat eine sehr hohe Bandbreite Internet-Verbindung, ERDDAP 's Antworten werden dadurch eingeschränkt, wie schnell ERDDAP™ kann Daten von der Datenquelle erhalten. Eine Lösung ist das Kopieren des Datensatzes auf ERDDAP 's Festplatte, vielleicht mit EDDGrid Kopie oder EDDTableCopy .
ERDDAP Serverbandbreite
- es sei denn, ERDDAP 's Server hat eine sehr hohe Bandbreite Internet-Verbindung, ERDDAP 's Antworten werden dadurch eingeschränkt, wie schnell ERDDAP™ Daten aus den Datenquellen erhalten und wie schnell ERDDAP™ kann Daten an die Kunden zurückgeben. Die einzige Lösung ist, eine schnellere Internetverbindung zu bekommen.
Speichermedien
- Wenn es viele gleichzeitige Anfragen gibt, ERDDAP™ kann aus dem Speicher laufen und neue Anfragen zeitweise verweigern. ( ERDDAP™ hat ein paar Mechanismen, um dies zu vermeiden und die Konsequenzen zu minimieren, wenn es passiert.) Je mehr Speicher im Server desto besser. Auf einem 32-Bit-Server ist 4+ GB wirklich gut, 2 GB ist okay, weniger wird nicht empfohlen. Auf einem 64-Bit-Server können Sie das Problem fast vollständig vermeiden, indem Sie viel Speicher. Siehe \-Xmx und -Xms Einstellungen für ERDDAP -Tomcat. Eine ERDDAP™ Schwere Nutzung auf einem Computer mit einem 64-Bit-Server mit 8 GB Speicher und -Xmx auf 4000M eingestellt ist selten, wenn überhaupt, durch Speicher eingeschränkt.
Had Drive Bandwidth
- Der Zugriff auf Daten, die auf der Festplatte des Servers gespeichert sind, ist weitaus schneller als der Zugriff auf Remote-Daten. Auch wenn ERDDAP™ Server hat eine sehr hohe Bandbreite Internet-Verbindung, es ist möglich, dass der Zugriff auf Daten auf der Festplatte ein Engpass sein wird. Eine Teillösung ist schneller zu bedienen (z.B. 10.000 RPM) magnetische Festplatten oder SSD-Laufwerke (wenn es kostenmäßig Sinn macht) . Eine weitere Lösung besteht darin, verschiedene Datensätze auf verschiedenen Laufwerken zu speichern, so dass die kumulative Festplattenbandbreite viel höher ist.
Zu viele Dateien Cached
- Zu viele Dateien in einem Cache Verzeichnis — ERDDAP™ Cache alle Bilder, aber nur Cache die Daten für bestimmte Arten von Datenanforderungen. Es ist möglich, dass das Cache-Verzeichnis für einen Datensatz eine große Anzahl von Dateien vorübergehend hat. Dies verlangsamt Anfragen zu sehen, ob eine Datei im Cache ist (wirklich!) .<Cache Protokolle Setup.xml lässt Sie festlegen, wie lange eine Datei im Cache sein kann, bevor sie gelöscht wird. Eine kleinere Zahl zu setzen würde dieses Problem minimieren.
CPU
- Nur zwei Dinge nehmen viel CPU-Zeit:
- NetCDF 4 und HDF 5 unterstützt nun die interne Komprimierung von Daten. Dekomprimieren eines großen komprimierten NetCDF 4 / HDF 5 Datendatei kann 10 oder mehr Sekunden dauern. (Das ist kein Implementierungsfehler. Es ist die Natur der Kompression.) So können mehrere gleichzeitige Anfragen an Datensätze mit in komprimierten Dateien gespeicherten Daten auf jedem Server einen starken Stamm setzen. Wenn dies ein Problem ist, ist die Lösung, beliebte Datensätze in unkomprimierten Dateien zu speichern, oder einen Server mit einer CPU mit mehr Kernen zu erhalten.
- Diagramme erstellen (einschließlich Karten) : etwa 0,2 - 1 Sekunde pro Graph. Also, wenn es viele gleichzeitig einzigartige Anfragen für Graphen ( WMS Kunden stellen oft 6 gleichzeitige Anfragen!) Es könnte eine CPU-Beschränkung geben. Wenn mehrere Benutzer laufen WMS Kunden, das wird ein Problem.
-
- Ja.
Mehrere Iden ERDDAP s mit Lastausgleich?
Die Frage kommt oft auf: "Um mit schweren Lasten umzugehen, kann ich mehrere identische ERDDAP s mit Lastausgleich?" Es ist eine interessante Frage, weil es schnell zum Kern von ERDDAP Design. Die schnelle Antwort ist "Nein". Ich weiß, das ist eine enttäuschende Antwort, aber es gibt ein paar direkte Gründe und einige größere grundlegende Gründe, warum ich entworfen habe ERDDAP™ einen anderen Ansatz verwenden (eine Föderation von ERDDAP s, in der Masse dieses Dokuments beschrieben) , was ich glaube, ist eine bessere Lösung.
Einige direkte Gründe, warum Sie nicht/shouldn nicht mehrere identisch ERDDAP s sind:
- A gegeben ERDDAP™ liest jede Datendatei, wenn sie zuerst verfügbar wird, um die Datenbereiche in der Datei zu finden. Es speichert diese Informationen dann in einer Indexdatei. Später, wenn eine Benutzeranfrage für Daten eingeht, ERDDAP™ verwendet diesen Index, um herauszufinden, welche Dateien nach den gewünschten Daten suchen. Wenn es mehrere identische ERDDAP s, sie würden jeweils diese Indexierung tun, die verschwendet Anstrengung. Bei dem weiter unten beschriebenen föderierten System wird die Indexierung nur einmal durch eine der ERDDAP S.
- Für einige Arten von Benutzeranfragen (z.B. für .nc , .png, .pdf Dateien) ERDDAP™ muss die gesamte Datei machen, bevor die Antwort gesendet werden kann. So. ERDDAP™ Cache diese Dateien für eine kurze Zeit. Wenn eine identische Anfrage kommt (wie es oft tut, vor allem für Bilder, bei denen die URL in eine Webseite eingebettet ist) , ERDDAP™ kann diese Cache-Datei wiederverwenden. In einem System mit mehreren identischen ERDDAP s, diese Cache-Dateien werden nicht geteilt, so dass jeder ERDDAP™ würde unnötig und mühelos die .nc , .png oder .pdf Dateien. Mit dem unten beschriebenen föderierten System werden die Dateien nur einmal gemacht, von einer der ERDDAP s, und wiederverwendet.
- ERDDAP Das Abonnementsystem ist nicht eingerichtet, um von mehreren geteilt zu werden ERDDAP S. Zum Beispiel, wenn der Load Balancer einen Benutzer an einen sendet ERDDAP™ und der Benutzer abonniert einen Datensatz, dann der andere ERDDAP s wird sich dieses Abonnement nicht bewusst sein. Später, wenn der Load Balancer den Benutzer zu einem anderen sendet ERDDAP™ und fordert eine Liste seiner Abonnements, die andere ERDDAP™ würde sagen, es gibt keine (führt ihn/sie zu einem doppelten Abonnement auf dem anderen ERED DAP ) . Mit dem weiter unten beschriebenen föderierten System wird das Abonnementsystem einfach von der Haupt-, öffentlichen, zusammengesetzten ERDDAP .
Ja, für jedes dieser Probleme könnte ich (mit großem Aufwand) eine Lösung entwickeln (die Informationen zwischen ERDDAP S) , aber ich glaube, Fütterung von ERDDAP s Ansatz (in der Masse dieses Dokuments beschrieben) ist eine viel bessere Gesamtlösung, zum Teil, weil es sich um andere Probleme handelt, die die multiple-identisch- ERDDAP Der s-with-a-load-balancer-Ansatz beginnt nicht einmal, insbesondere die dezentrale Natur der Datenquellen in der Welt anzusprechen.
Es ist am besten, die einfache Tatsache zu akzeptieren, dass ich nicht designte ERDDAP™ als mehrfach identisch eingesetzt werden ERDDAP s mit Lastausgleich. Ich habe bewusst entworfen ERDDAP™ gut in einem Verband zu arbeiten ERDDAP s, was ich glaube, hat viele Vorteile. Besonders ein Verband ERDDAP s ist perfekt mit dem dezentralen, verteilten System von Rechenzentren ausgerichtet, die wir in der realen Welt haben (die verschiedenen IOOS-Regionen oder die verschiedenen Küstenwach-Regionen oder die verschiedenen Teile von NCEI oder die 100 anderen Rechenzentren in NOAA , oder die verschiedenen NASA DAACs, oder die 1000er Rechenzentren auf der ganzen Welt) . Anstatt allen Rechenzentren der Welt zu sagen, dass sie ihre Anstrengungen aufgeben und alle ihre Daten in einen zentralen "Datensee" setzen müssen. (selbst wenn es möglich wäre, ist es aus zahlreichen Gründen eine schreckliche Idee -- siehe die verschiedenen Analysen, die die zahlreichen Vorteile der dezentrale Systeme ) , ERDDAP 's Design arbeitet mit der Welt, wie es ist. Jedes Rechenzentrum, das Daten erzeugt, kann weiterhin aufrecht erhalten, kuratieren und ihren Daten dienen (sie sollten) , und doch, mit ERDDAP™ , die Daten können auch sofort von einer zentralen ERDDAP , ohne dass die Daten an die Zentralisierung übertragen werden müssen ERDDAP™ oder doppelte Kopien der Daten speichern. In der Tat kann ein bestimmter Datensatz gleichzeitig verfügbar sein von ERDDAP™ bei der Organisation, die produziert und tatsächlich speichert die Daten (z.B. GoMOOS) , von ERDDAP™ bei der Elternorganisation (z.B. IOOS Zentral) , aus einem ganzen... NOAA ERDDAP™ , aus einer all-US-föderalen Regierung ERDDAP™ , aus einer Welt ERDDAP™ (ZUSAMMENFASSUNG) , und von spezialisierten ERDDAP S (z.B. ein ERDDAP™ an einer Einrichtung zur HAB-Forschung) , alle im Wesentlichen sofort und effizient, da nur die Metadaten zwischen ERDDAP s, nicht die Daten. Am besten, nach der ersten ERDDAP™ bei der Ursprungsorganisation, alle anderen ERDDAP s kann schnell aufgebaut werden (ein paar Stunden Arbeit) , mit minimalen Ressourcen (einen Server, der keine RAIDs für die Datenspeicherung benötigt, da er keine Daten lokal speichert) , und damit zu wirklich minimalen Kosten. Vergleichen Sie das mit den Kosten der Einrichtung und Aufrechterhaltung eines zentralisierten Rechenzentrums mit einem Datensee und der Notwendigkeit einer wirklich massiven, wirklich teuren, Internetverbindung, plus das damit verbundene Problem des zentralisierten Rechenzentrums ist ein einziger Fehlerpunkt. Für mich, ERDDAP s dezentrale, föderierte Ansatz ist weit, weit überlegen.
In Situationen, in denen ein vorgegebenes Rechenzentrum mehrere benötigt ERDDAP die hohe Nachfrage zu erfüllen, ERDDAP 's Design ist voll in der Lage, die Leistung des Multiple-Identtical- ERDDAP s-with-a-load-balancer Ansatz. Sie haben immer die Möglichkeit der Einrichtung Vielschichtiger Verbund ERDDAP S (wie unten diskutiert) , von denen jede ihre Daten von anderen erhält ERDDAP s, ohne Lastausgleich. In diesem Fall empfehle ich, dass Sie einen Punkt zu geben jedem der zusammengesetzten ERDDAP s ein anderer Name / Identität und wenn möglich sie in verschiedenen Teilen der Welt einrichten (z.B. verschiedene AWS-Regionen) , z. ERD \_US\_Ost, ERD \_US\_West, ERD \_IE, ERD \_FR, ERD \_IT, so dass Benutzer bewusst, wiederholt, mit einem bestimmten ERDDAP , mit dem zusätzlichen Vorteil, dass Sie das Risiko von einem einzigen Punkt des Ausfalls entfernt haben.
-
- Ja.
Gitter, Cluster und Föderationen
Unter sehr schweren Einsatz, ein einziges Standalone ERDDAP™ wird in ein oder mehrere der Einschränkungen und sogar die vorgeschlagenen Lösungen werden nicht ausreichen. Für solche Situationen ERDDAP™ verfügt über Funktionen, die es einfach machen skalierbare Gitter zu konstruieren (auch Cluster oder Verbände genannt) von ERDDAP s, die es erlauben, das System sehr schwer zu handhaben (z.B. für ein großes Rechenzentrum) .
Ich benutze Gitter als allgemeiner Begriff zur Angabe einer Art Computer-Cluster wenn alle Teile in einer Einrichtung physikalisch oder nicht angeordnet sein können und nicht zentral appliziert werden können. Ein Vorteil von ko-lokierten, zentralbesitzenden und verwalteten Gittern (Cluster) ist, dass sie von Skalenwirtschaften profitieren (besonders die menschliche Arbeitsbelastung) und vereinfachen, die Teile des Systems gut zusammenzuarbeiten. Ein Vorteil von nicht-ko-lokierten Gittern, nicht-zentralen und verwalteten (Föderationen) ist, dass sie die menschliche Arbeitsbelastung und die Kosten verteilen und zusätzliche Fehlertoleranz bieten können. Die Lösung, die ich unten vorschlage, funktioniert gut für alle Raster-, Cluster- und Föderationstopographien.
Der Grundgedanke eines skalierbaren Systems besteht darin, die potenziellen Engpässe zu identifizieren und das System so zu gestalten, dass Teile des Systems nach Bedarf repliziert werden können, um die Engpässe zu lindern. Idealerweise erhöht jeder replizierte Teil die Kapazität des Teils des Systems linear (Effizienz der Skalierung) . Das System ist nicht skalierbar, es sei denn, es gibt eine skalierbare Lösung für jeden Engpass. Skalierbarkeit unterscheidet sich von der Effizienz (wie schnell eine Aufgabe erledigt werden kann — Effizienz der Teile) . Skalierbarkeit ermöglicht es dem System zu wachsen, um jedes Niveau der Nachfrage zu bewältigen. Effizienz (der Skalierung und der Teile) bestimmt, wie viele Server, etc., benötigt werden, um eine bestimmte Nachfrage zu erfüllen. Effizienz ist sehr wichtig, hat aber immer Grenzen. Skalierbarkeit ist die einzige praktische Lösung, um ein System zu bauen, das handhaben kann sehr schwerer Einsatz. Idealerweise wird das System skalierbar und effizient sein.
Ziele
Die Ziele dieses Designs sind:
- Eine skalierbare Architektur zu machen (eine, die leicht erweiterbar ist, indem sie jedes Teil, das übergebürdet wird) . Um ein effizientes System zu schaffen, das die Verfügbarkeit und den Durchsatz der Daten bei den verfügbaren Rechenressourcen maximiert. (Kosten sind fast immer ein Problem.)
- Um die Fähigkeiten der Teile des Systems auszugleichen, so dass ein Teil des Systems keinen anderen Teil überfordert.
- Um eine einfache Architektur zu machen, so dass das System einfach aufgebaut und verwaltet werden kann.
- Eine Architektur, die mit allen Rastertopographien gut funktioniert.
- Um ein System zu schaffen, das anmutig und in begrenzter Weise ausfällt, wenn ein Teil überbezahlt wird. (Die Zeit, die erforderlich ist, um eine große Datensätze zu kopieren, wird die Fähigkeit des Systems, mit plötzlichen Anstiegen der Nachfrage nach einem bestimmten Datensatz zu umgehen, immer begrenzen.)
- (Falls möglich) Um eine Architektur zu machen, die nicht an eine bestimmte gebunden ist Cloud Computing Service oder andere externe Dienste (weil es sie nicht braucht) .
Empfehlungen
Unsere Empfehlungen sind
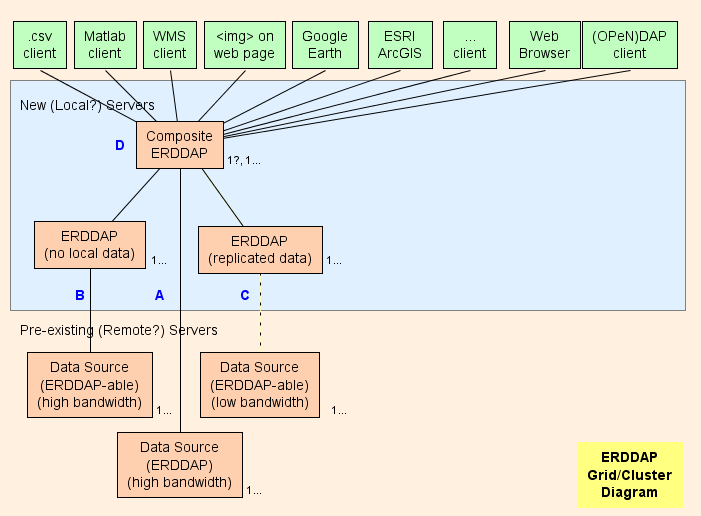
- Grundsätzlich schlage ich vor, einen Verbund aufzubauen ERDDAP™ ( D im Diagramm) , die regelmäßig ist ERDDAP™ außer, es dient nur Daten von anderen ERDDAP S. Die Architektur des Rasters soll so viel Arbeit wie möglich verschieben (CPU-Nutzung, Speichernutzung, Bandbreitennutzung) aus dem Verbund ERDDAP™ zum anderen ERDDAP S.
- ERDDAP™ hat zwei spezielle Datensatztypen, EDDGrid Von Erddap und EDDTableFromErddap , die sich auf Datensätze auf anderen ERDDAP S.
- Wenn der Verbund ERDDAP™ von diesen Datensätzen eine Anforderung an Daten oder Bilder erhält, ERDDAP™ Umleitungen die Datenanforderung zum anderen ERDDAP™ Server. Das Ergebnis ist:
- Dies ist sehr effizient (CPU, Speicher und Bandbreite) , weil sonst
- Der Verbund ERDDAP™ muss die Datenanforderung an den anderen senden ERDDAP .
- Der andere ERDDAP™ die Daten zu erhalten, zu reformieren und die Daten an den Verbund zu übermitteln ERDDAP .
- Der Verbund ERDDAP™ muss die Daten empfangen (mit extra Bandbreite) , reformieren (mit extra CPU-Zeit und Speicher) , und die Daten an den Benutzer übertragen (mit extra Bandbreite) . Durch Umleitung der Datenanforderung und Genehmigung des anderen ERDDAP™ die Antwort direkt an den Benutzer zu senden, den Verbund ERDDAP™ verbringt im Wesentlichen keine CPU-Zeit, Speicher oder Bandbreite auf Datenanforderungen.
- Die Umleitung ist für den Benutzer unabhängig von der Client-Software transparent (ein Browser oder ein anderes Software- oder Befehlszeilentool) .
- Dies ist sehr effizient (CPU, Speicher und Bandbreite) , weil sonst
Netzteile
A : Für jede Remote-Datenquelle mit hoher Bandbreite OPeNDAP Server, Sie können direkt mit dem Remote-Server verbinden. Wenn der Remoteserver ein ERDDAP™ , Verwendung EDDGrid VonErddap oder EDDTableFrom ERDDAP die Daten im Verbund dienen ERDDAP . Wenn der Remote-Server eine andere Art von DAP Server, z.B. THREDDS, Hyrax , oder GrADS verwenden EDDGrid FromDap.
B. : Für jeden ERDDAP -fähige Datenquelle (eine Datenquelle, aus der ERDDAP kann Daten lesen) der einen High-Bandbreite-Server hat, einen anderen einrichten ERDDAP™ im Netz, das für die Verwendung der Daten aus dieser Datenquelle verantwortlich ist.
- Wenn mehrere solcher ERDDAP s werden nicht viele Anfragen für Daten erhalten, Sie können sie zu einem konsolidieren ERDDAP .
- Wenn ERDDAP™ gewidmet, um Daten von einer Remote-Quelle zu viele Anfragen zu bekommen, gibt es eine Versuchung, zusätzliche ERDDAP s auf die entfernte Datenquelle zugreifen. In speziellen Fällen kann dies sinnvoll sein, aber es ist wahrscheinlicher, dass dies die entfernte Datenquelle überfordert. (die sich selbst entziehen) und auch verhindern, dass andere Benutzer auf die entfernte Datenquelle zugreifen (was nicht schön ist) . In einem solchen Fall ist die Einrichtung eines anderen ERDDAP™ zu dienen, dass ein Datensatz und kopieren Sie den Datensatz darauf ERDDAP 's Festplatte (siehe C ) , vielleicht mit EDDGrid Kopie und/oder EDDTableCopy .
- B. Server müssen öffentlich zugänglich sein.
C : Für jeden ERDDAP -fähige Datenquelle, die einen Low-Bandbreite-Server hat (oder ist ein langsamer Service aus anderen Gründen) , in Erwägung ziehen, einen anderen zu schaffen ERDDAP™ und Speichern einer Kopie des Datensatzes darauf ERDDAP 's Festplatten, vielleicht mit EDDGrid Kopie und/oder EDDTableCopy . Wenn mehrere solcher ERDDAP s werden nicht viele Anfragen für Daten erhalten, Sie können sie zu einem konsolidieren ERDDAP . C Server müssen öffentlich zugänglich sein.
Verbundwerkstoffe ERDDAP
D : Der Verbund ERDDAP™ ist ein Stamm ERDDAP™ außer, es dient nur Daten von anderen ERDDAP S.
- Weil der Verbund ERDDAP™ hat Informationen im Speicher über alle Datensätze, es kann schnell auf Anfragen für Listen von Datensätzen reagieren (Volltextsuche, Kategoriesuche, die Liste aller Datensätze) , und Anfragen für das Data Access-Formular eines einzelnen Datensatzes, Erstellen eines Graph-Formulars oder WMS Infoseite. Dies sind alle kleinen, dynamisch generierten HTML-Seiten basierend auf Informationen, die im Speicher gespeichert werden. Die Antworten sind also sehr schnell.
- Da Anfragen an aktuelle Daten schnell auf den anderen umgeleitet werden ERDDAP s, der Verbund ERDDAP™ kann schnell auf Anfragen für aktuelle Daten reagieren, ohne CPU-Zeit, Speicher oder Bandbreite zu verwenden.
- Durch Verschieben so viel Arbeit wie möglich (CPU, Speicher, Bandbreite) aus dem Verbund ERDDAP™ zum anderen ERDDAP s, der Verbund ERDDAP™ kann erscheinen, um Daten von allen Datensätzen zu bedienen und dennoch mit sehr vielen Datenanforderungen von einer Vielzahl von Benutzern aufrechtzuerhalten.
- Vorversuche zeigen, dass der Verbund ERDDAP™ kann auf die meisten Anfragen in ~1ms CPU-Zeit oder 1000 Anfragen/Sekunde antworten. So sollte ein 8-Kernprozessor in der Lage sein, auf etwa 8000 Anfragen/Sekunde zu reagieren. Obwohl es möglich ist, Bursts höherer Aktivität vorzustellen, die Verlangsamungen verursachen würden, das ist viel Durchsatz. Es ist wahrscheinlich, dass Datenzentrum Bandbreite wird der Engpass lange vor dem Verbund ERDDAP™ wird der Engpass.
Aktuelles max (Zeit) ?
Die EDDGrid /TableFromErddap im Verbund ERDDAP™ nur seine gespeicherte Information über jeden Quelldatensatz ändert, wenn der Quelldatensatz "Reload" und einige Metadatenänderungen (z.B. die Zeitvariable actual\_range ) , wodurch eine Abonnement-Benachrichtigung erzeugt wird. Hat der Quelldatensatz Daten, die sich häufig ändern (zum Beispiel neue Daten jede Sekunde) und nutzt die "update" System, um häufige Änderungen der zugrunde liegenden Daten zu bemerken, EDDGrid /TableFromErddap wird nicht über diese häufigen Änderungen informiert, bis der nächste Datensatz "Reload", also die EDDGrid /TableFromErddap wird nicht perfekt auf dem neuesten Stand sein. Sie können dieses Problem durch Änderung des Quelldatensatzes minimieren<reloadEveryNMinutes> auf einen kleineren Wert (60? 15?) so dass es mehr Abonnement-Benachrichtigungen, um die EDDGrid /TableFromErddap, um seine Informationen über den Quelldatensatz zu aktualisieren.
Oder wenn Ihr Datenmanagementsystem weiß, wann der Quelldatensatz neue Daten hat (z.B. über ein Skript, das eine Datendatei kopiert) , und wenn das nicht super häufig ist (z.B. alle 5 Minuten oder weniger häufig) Es gibt eine bessere Lösung:
- Nicht verwenden<updateEveryNMillis> um den Quelldatensatz aktuell zu halten.
- Den Quelldatensatz festlegen<reloadEveryNMinutes> zu einer größeren Anzahl (1440?) .
- Lassen Sie das Skript den Quelldatensatz kontaktieren Zurück zur Übersicht rechts nachdem es eine neue Datendatei kopiert. Dies führt dazu, dass der Quelldatensatz perfekt aktuell ist und dazu führt, dass er eine Abonnement-Benachrichtigung generiert, die an die EDDGrid /TableFromErddap Datensatz. Das führt EDDGrid /TableFromErddap-Datensatz ist perfekt auf dem neuesten Stand (gut, innerhalb von 5 Sekunden neue Daten hinzugefügt) . Und alles, was effizient getan wird (ohne unnötige Datensatz-Reloads) .
Mehrfachkomposit ERDDAP S
- In sehr extremen Fällen, oder für Fehlertoleranz, können Sie mehr als einen zusammengesetzten ERDDAP . Es ist wahrscheinlich, dass andere Teile des Systems (insbesondere die Bandbreite des Rechenzentrums) wird ein Problem lange vor dem Verbund ERDDAP™ wird ein Engpass. So ist die Lösung wahrscheinlich, zusätzliche, geografisch vielfältige, Rechenzentren einzurichten (Spiegel) , jeweils mit einem Verbund ERDDAP™ und Server mit ERDDAP s und (mindestens) Spiegelkopien der Datensätze, die in hoher Nachfrage sind. Ein solches Setup bietet auch Fehlertoleranz und Datensicherung (über Kopieren) . In diesem Fall ist es am besten, wenn der Verbund ERDDAP s haben verschiedene URLs.
Wenn Sie wirklich wollen alle Composites ERDDAP s die gleiche URL haben, verwenden Sie ein vorderes Endsystem, das einem bestimmten Benutzer nur einem der zusammengesetzten zuordnet ERDDAP S (basierend auf der IP-Adresse) , so dass alle Anfragen des Benutzers gehen zu nur einem der zusammengesetzten ERDDAP S. Es gibt zwei Gründe:
- Wenn ein zugrunde liegender Datensatz neu geladen wird und die Metadaten sich ändern (z.B. eine neue Datendatei in einem netzgebundenen Datensatz verursacht die Zeitvariable actual\_range zu ändern) , der Verbund ERDDAP s wird zeitweise leicht aus dem Synch, aber mit eventuelle Konsistenz . Normalerweise werden sie innerhalb von 5 Sekunden wieder synchronisiert, aber manchmal wird es länger sein. Wenn ein Benutzer ein automatisiertes System macht, das auf ERDDAP™ Abonnements die Aktionen auslösen, die kurzen Synchronitätsprobleme werden signifikant.
- Der 2+ Verbund ERDDAP s jede ihre eigene Satz von Abonnements (wegen des oben beschriebenen Synchproblems) .
So sollte ein bestimmter Benutzer auf nur einen der zusammengesetzten ERDDAP s, um diese Probleme zu vermeiden. Wenn einer der Verbundwerkstoffe ERDDAP s geht nach unten, das vordere Endsystem kann umleiten, dass ERDDAP Benutzer zum anderen ERDDAP™ Das ist vorbei. Ist es jedoch ein Kapazitätsproblem, das den ersten Verbund verursacht ERDDAP™ zu scheitern (einen überzesslichen Benutzer? eine Denial-of-Service-Angriff ?) , dies macht es sehr wahrscheinlich, dass die Weiterleitung seiner Benutzer zu anderen zusammengesetzten ERDDAP s wird verursachen Kaskadenversagen . So ist das robusteste Setup, zusammengesetzt zu haben ERDDAP s mit verschiedenen URLs.
Oder vielleicht besser, mehrere zusammengesetzte ERDDAP s ohne Lastausgleich. In diesem Fall sollten Sie einen Punkt zu geben, jedem der ERDDAP s ein anderer Name / Identität und wenn möglich sie in verschiedenen Teilen der Welt einrichten (z.B. verschiedene AWS-Regionen) , z. ERD \_US\_Ost, ERD \_US\_West, ERD \_IE, ERD \_FR, ERD \_IT, so dass Benutzer bewusst, wiederholt mit einem bestimmten ERDDAP .
- \[ Für ein faszinierendes Design eines Hochleistungssystems, das auf einem Server läuft, siehe dies ausführliche Beschreibung von Mailinator . \]
Datensätze in sehr hoher Nachfrage
Im wirklich ungewöhnlichen Fall, dass einer der A , B. , oder C ERDDAP s kann aufgrund von Bandbreiten- oder Festplattenbeschränkungen nicht mit den Anfragen aufrecht erhalten, es macht Sinn, die Daten zu kopieren (wieder) auf einen anderen Server+hard Fahren Sie fort ERDDAP , vielleicht mit EDDGrid Kopie und/oder EDDTableCopy . Während es vielleicht ideal erscheint, den ursprünglichen Datensatz und den kopierten Datensatz nahtlos als ein Datensatz im Verbund erscheinen zu lassen ERDDAP™ , dies ist schwierig, weil die beiden Datensätze zu unterschiedlichen Zeiten in leicht unterschiedlichen Zuständen liegen (insbesondere, nachdem das Original neue Daten erhält, aber bevor der kopierte Datensatz seine Kopie erhält) . Daher empfehle ich, dass die Datensätze leicht unterschiedliche Titel gegeben werden (z.B.: "... (Nummer 1) " und "... (Nummer 2) ", oder vielleicht " (Spiegel # n ) " oder " (Server n ) ") und erscheinen als separate Datensätze im Verbund ERDDAP . Benutzer werden verwendet, um Listen von Spiegelseiten auf beliebten Datei-Download-Seiten, so sollte dies nicht überraschen oder enttäuscht sie. Aufgrund der Bandbreitenbegrenzungen an einer bestimmten Stelle kann es sinnvoll sein, den Spiegel an einer anderen Stelle zu haben. Wenn die Spiegelkopie in einem anderen Rechenzentrum ist, nur von dem Composite des Rechenzentrums aufgerufen ERDDAP™ , die verschiedenen Titel (z.B. "Spiegel #1) sind nicht notwendig.
RAIDs gegen normale Festplatten
Wenn ein großer Datensatz oder eine Gruppe von Datensätzen nicht stark verwendet werden, kann es sinnvoll sein, die Daten auf einem RAID zu speichern, da es Fehlertoleranz bietet und da Sie nicht die Verarbeitungsleistung oder Bandbreite eines anderen Servers benötigen. Aber wenn ein Datensatz stark verwendet wird, kann es sinnvoller sein, die Daten auf einem anderen Server zu kopieren + ERDDAP™ + Festplatte (ähnlich was Google tut ) anstatt einen Server und eine RAID zu verwenden, um mehrere Datensätze zu speichern, da Sie beide Server+hardDrive+ verwenden ERDDAP s im Raster, bis einer von ihnen ausfällt.
Ausfälle
Was passiert, wenn...
- Es gibt einen Burst von Anfragen für einen Datensatz (z.B. alle Schüler in einer Klasse gleichzeitig ähnliche Daten anfordern) ? Nur die ERDDAP™ die Verwendung dieses Datensatzes wird überwältigt und verlangsamt oder abgelehnt Anträge. Der Verbund ERDDAP™ und andere ERDDAP werden nicht betroffen sein. Da der Grenzwert für einen bestimmten Datensatz innerhalb des Systems die Festplatte mit den Daten ist (nicht ERDDAP ) , die einzige Lösung (nicht unmittelbar) eine Kopie des Datensatzes auf einem anderen Server+hardDrive+ erstellen ERDDAP .
- Eine A , B. , oder C ERDDAP™ fehlschlägt (z.B. Festplattenausfall) ? Nur der Datensatz (S) von der ERDDAP™ sind betroffen. Wenn der Datensatz (S) wird auf einem anderen Server +hardDrive+ gespiegelt ERDDAP , der Effekt ist minimal. Wenn das Problem ein Festplattenausfall in einem Level 5 oder 6 RAID ist, ersetzen Sie einfach das Laufwerk und haben die RAID wieder aufbauen die Daten auf dem Laufwerk.
- Der Verbund ERDDAP™ scheitert? Wenn Sie ein System mit sehr hohe Verfügbarkeit , Sie können einrichten Vielschichtiger Verbund ERDDAP S (wie oben beschrieben) , mit etwas wie NGINX oder Traefik zum Lastausgleich. Anmerkung: ERDDAP™ kann eine sehr große Anzahl von Anfragen von einer großen Anzahl von Benutzern behandeln, weil Anträge auf Metadaten sind klein und werden von Informationen behandelt, die im Speicher liegen, und Anfragen an Daten (die groß sein können) werden dem Kind umgeleitet ERDDAP S.
Einfach, skalierbar
Dieses System ist einfach einzurichten und zu verwalten, und leicht ausfahrbar, wenn ein Teil davon überlastet wird. Die einzigen realen Einschränkungen für ein bestimmtes Rechenzentrum sind die Bandbreite des Rechenzentrums und die Kosten des Systems.
Bandbreite
Beachten Sie die ungefähre Bandbreite der häufig verwendeten Komponenten des Systems:
| Komponente | Angemeldet bleiben (GB) |
|---|---|
| DDR-Speicher | ANHANG |
| SSD Laufwerk | 1 |
| SATA Festplatte | 0,3% |
| Gigabit Ethernet | 0,1 mg/kg |
| OC-12 | 0,06 |
| OC-3 | 0,015 |
| T1 | 0,0002 |
Also, eine SATA Festplatte (0,3 GB/s) auf einem Server mit einem ERDDAP™ kann wahrscheinlich ein Gigabit Ethernet LAN sättigen (0,1 GB/s) . Und ein Gigabit Ethernet LAN (0,1 GB/s) kann wahrscheinlich eine OC-12 Internet-Verbindung sättigen (0,06GB/s) . Und mindestens eine Quelle listet OC-12 Linien kostet etwa $100.000 pro Monat. (Ja, diese Berechnungen basieren darauf, das System auf seine Grenzen zu schieben, was nicht gut ist, weil es zu sehr trägen Antworten führt. Diese Berechnungen sind jedoch für die Planung und den Ausgleich von Teilen des Systems nützlich.) Eine entsprechend schnelle Internetverbindung für Ihr Rechenzentrum ist bei weitem der teuerste Teil des Systems. Sie können einfach und relativ günstig ein Raster mit einem Dutzend Servern bauen, die ein Dutzend laufen ERDDAP s, die in der Lage ist, viele Daten schnell auszupumpen, aber eine entsprechend schnelle Internetverbindung wird sehr, sehr teuer sein. Die Teillösungen sind:
- Ermutigen Sie Kunden, Teilmengen der Daten anzufordern, wenn dies alles ist, was erforderlich ist. Wenn der Client nur Daten für eine kleine Region oder eine geringere Auflösung benötigt, sollten sie das anfordern. Subsetting ist ein zentraler Schwerpunkt der Protokolle ERDDAP™ unterstützt die Anforderung von Daten.
- Ermutigen Sie die Übertragung von komprimierten Daten. ERDDAP™ Pressen eine Datenübertragung, wenn sie in der HTTP GET Bitte Header. Alle Webbrowser verwenden "accept-encoding" und dekomprimieren die Antwort automatisch. Sonstige Kunden (z.B. Computerprogramme) müssen sie explizit verwenden.
- Koordinieren Sie Ihre Server auf einer ISP oder einer anderen Website, die relativ kostengünstigere Bandbreitenkosten bietet.
- Die Server mit der ERDDAP s an verschiedene Institutionen, so daß die Kosten verteilt werden. Sie können dann Ihren Verbund verlinken ERDDAP™ ihr ERDDAP S.
Anmerkung: Cloud Computing und Web-Hosting-Dienste bieten alle Internet-Bandbreite, die Sie benötigen, aber lösen Sie nicht das Preisproblem.
Allgemeine Informationen zur Gestaltung skalierbarer, hoher Kapazität, fehlertoleranter Systeme siehe Michael T. Nygards Buch Veröffentlichung .
Wie Legos
Software-Designer versuchen oft gut zu verwenden Software Design Muster Probleme zu lösen. Gute Muster sind gut, weil sie gute, einfach zu erstellen und zu arbeiten, allgemeine Lösungen, die zu Systemen mit guten Eigenschaften führen. Musternamen sind nicht standardisiert, also rufe ich das Muster an, dass ERDDAP™ verwendet das Lego Pattern. Jedes Lego (jeweils ERDDAP ) ist ein einfacher, kleiner, Standard, Stand-alone, Ziegel (Datenserver) mit einer definierten Schnittstelle, die es ermöglicht, mit anderen Legos verbunden zu werden ( ERDDAP S) . Die Teile ERDDAP™ die dieses System ausmachen sind: das Abonnement und die FlagURL-Systeme (die die Kommunikation zwischen ERDDAP S) Die EDD... FromErdddap Umleitung System und das System von RESTful Anfragen an Daten, die von Nutzern oder anderen generiert werden können ERDDAP S. Bei zwei oder mehr Legos ( ERDDAP S) , Sie können eine große Anzahl von verschiedenen Formen erstellen (Netzwerktopologien von ERDDAP S) . Sicher, das Design und die Features von ERDDAP™ hätte anders gemacht werden können, nicht Lego-ähnlich, vielleicht nur um eine bestimmte Topologie zu ermöglichen und zu optimieren. Aber wir fühlen uns ERDDAP 's Lego-ähnliches Design bietet eine gute, allgemeine Lösung, die jede ERDDAP™ Administrator (oder Gruppe von Administratoren) alle Arten von verschiedenen Föderationstopologien zu erstellen. So könnte beispielsweise eine einzige Organisation drei (oder mehr) ERDDAP s wie in der ERDDAP™ Grid/Cluster Diagramm oben . Oder eine verteilte Gruppe (IOOS? CoastWatch? NCEI? NWS? NOAA ? USGS? DataONE? NEON? LTER? OOI? BODC? ONC? JRC? WMO?) kann ein ERDDAP™ in jedem kleinen Außenposten (so dass die Daten in der Nähe der Quelle bleiben können) und dann einen Verbund einrichten ERDDAP™ im Zentralbüro mit virtuellen Datensätzen (die immer perfekt aktuell sind) aus jedem der kleinen Außenposten ERDDAP S. In der Tat, alle ERDDAP s, an verschiedenen Institutionen auf der ganzen Welt installiert, die Daten von anderen erhalten ERDDAP s und/oder Daten an andere ERDDAP s, bilden ein riesiges Netz von ERDDAP S. Wie cool ist das?! So, wie bei Legos, sind die Möglichkeiten endlos. Deshalb ist das ein gutes Muster. Deshalb ist das ein gutes Design für ERDDAP .
Verschiedene Arten von Anfragen
Eine der realen Komplikationen dieser Diskussion von Datenserver-Topologien ist, dass es verschiedene Arten von Anfragen und verschiedene Möglichkeiten gibt, um für die verschiedenen Arten von Anfragen zu optimieren. Dies ist meist ein separates Problem (Wie schnell kann das ERDDAP™ die Daten auf die Anforderung von Daten reagieren?) aus der Topologie Diskussion (die sich mit den Beziehungen zwischen Datenservern befasst und welchen Server die tatsächlichen Daten hat) . ERDDAP™ , natürlich versucht, alle Arten von Anträgen effizient zu behandeln, aber behandelt einige besser als andere.
- Viele Anfragen sind einfach. Zum Beispiel: Was sind die Metadaten für diesen Datensatz? Oder: Was sind die Werte der Zeitdimension für diesen Datensatz? ERDDAP™ entwickelt, um diese möglichst schnell zu handhaben (in der Regel<= 2 ms), indem diese Informationen im Speicher gespeichert werden.
- Einige Anträge sind mäßig schwer. Zum Beispiel: Geben Sie mir diese Untermenge eines Datensatzes (die in einer Datendatei) . Diese Anträge können relativ schnell bearbeitet werden, weil sie nicht so schwierig sind.
- Einige Anfragen sind hart und damit zeitraubend. Zum Beispiel: Geben Sie mir diese Untermenge eines Datensatzes (die in einem der 10.000+ Datendateien liegen oder aus komprimierten Datendateien stammen können, die jeweils 10 Sekunden dauern, um zu dekomprimieren) . ERDDAP™ v2.0 führte einige neue, schnellere Wege ein, um mit diesen Anfragen zu umgehen, insbesondere indem der Anfrage-Handling Faden mehrere Arbeitsfäden, die verschiedene Teilmengen der Anfrage anpacken, spawn. Aber es gibt einen anderen Ansatz dieses Problems, ERDDAP™ noch nicht unterstützt: Untermengen der Datendateien für einen bestimmten Datensatz können auf separaten Computern gespeichert und analysiert werden, und dann die Ergebnisse auf dem ursprünglichen Server zusammengefasst werden. Dieser Ansatz wird aufgerufen KarteReduzieren und wird von Hadoop , die erste (?) open-source MapReduce Programm, das auf Ideen aus einem Google-Papier basiert. (Wenn Sie MapReduce benötigen ERDDAP , bitte senden Sie eine E-Mail-Anfrage an erd.data at noaa.gov .) Google Großes Angebot ist interessant, weil es scheint eine Implementierung von MapReduce angewendet, um tabellarische Datensätze zu unterbinden, die einer von ERDDAP Hauptziele. Es ist wahrscheinlich, dass Sie eine ERDDAP™ Datensatz von einem BigQuery Datensatz über EDDTableFromDatabase weil BigQuery über eine JDBC-Schnittstelle aufgerufen werden kann.
Das sind meine Meinungen.
Ja, die Berechnungen sind vereinfacht (und jetzt leicht datiert) , aber ich denke, die Schlussfolgerungen sind korrekt. Habe ich Fehler bei meinen Berechnungen gemacht? Wenn ja, ist die Schuld meine allein. Bitte senden Sie eine E-Mail mit der Korrektur an erd dot data at noaa dot gov .
-
- Ja.
Cloud Computing
Mehrere Unternehmen bieten Cloud Computing Services (z.B., Amazon Web Services und Google Cloud Platform ) . Webhosting-Unternehmen Seit Mitte der 1990er Jahre haben einfachere Dienstleistungen angeboten, aber die "Cloud"-Dienste haben die Flexibilität der Systeme und das Angebotsspektrum erheblich erweitert. Seit ERDDAP™ Gitter besteht nur aus ERDDAP s und seit ERDDAP s Java Web-Anwendungen, die in Tomcat laufen können (der häufigsten Anwendungsserver) oder andere Anwendungsserver, sollte es relativ einfach sein, eine ERDDAP™ auf einem Cloud-Service oder Webhosting-Site. Die Vorteile dieser Dienste sind:
- Sie bieten Zugriff auf sehr hohe Bandbreite Internet-Verbindungen. Dies allein kann die Nutzung dieser Dienste rechtfertigen.
- Sie berechnen nur für die Dienste, die Sie nutzen. Zum Beispiel erhalten Sie Zugriff auf eine sehr hohe Bandbreite Internetverbindung, aber Sie zahlen nur für tatsächlich übertragene Daten. Das lässt Sie ein System bauen, das selten überwältigt wird (sogar bei Spitzennachfrage) , ohne für die Kapazität zu zahlen, die selten verwendet wird.
- Sie sind leicht erweiterbar. Sie können Servertypen ändern oder so viele Server oder so viel Speicher wie Sie wollen, in weniger als einer Minute hinzufügen. Dies allein kann die Nutzung dieser Dienste rechtfertigen.
- Sie befreien Sie von vielen administrativen Aufgaben der Verwaltung der Server und Netzwerke. Dies allein kann die Nutzung dieser Dienste rechtfertigen.
Die Nachteile dieser Dienste sind:
- Sie berechnen für ihre Dienste, manchmal viel (in absoluten Begriffen; nicht, dass es kein guter Wert ist) . Die hier aufgeführten Preise sind für Amazon EC2 . Diese Preise (ab Juni 2015) kommt runter.
In der Vergangenheit waren die Preise höher, aber Datendateien und die Anzahl der Anfragen waren kleiner.
In Zukunft werden die Preise niedriger sein, aber Datendateien und die Anzahl der Anfragen wird größer sein.
So ändern sich die Details, aber die Situation bleibt relativ konstant.
Und es ist nicht, dass der Service überteuert ist, es ist, dass wir eine Menge des Dienstes verwenden und kaufen.
- Datenübermittlung – Datenübermittlungen in das System sind jetzt kostenlos (Ja!) . Datentransfers aus dem System sind $0.09/GB. Eine SATA Festplatte (0,3 GB/s) auf einem Server mit einem ERDDAP™ kann wahrscheinlich ein Gigabit Ethernet LAN sättigen (0,1 GB/s) . Ein Gigabit Ethernet-LAN (0,1 GB/s) kann wahrscheinlich eine OC-12 Internet-Verbindung sättigen (0,06GB/s) . Wenn eine OC-12-Verbindung ~150.000 GB/Monat übertragen kann, könnten die Kosten für die Datenübermittlung bis zu 150.000 GB @ $0.09/GB = $13,500/Monat betragen, was eine erhebliche Kosten ist. Offensichtlich, wenn Sie ein Dutzend hart arbeiten ERDDAP s auf einem Cloud-Service, Ihre monatlichen Datentransfer Gebühren könnten beträchtlich sein (bis zu $162.000/Monat) . (Wieder ist es nicht, dass der Service überteuert ist, es ist, dass wir eine Menge des Dienstes verwenden und kaufen.)
- Datenspeicherung — Amazon berechnet $50/Monat pro TB. (Verglichen mit dem Kauf eines 4TB-Unternehmens-Laufwerks für ~$50/TB, obwohl die RAID, um es in setzen und Verwaltungskosten hinzufügen, um die Gesamtkosten.) Wenn Sie also viele Daten in der Cloud speichern müssen, könnte es ziemlich teuer sein (z.B. würde 100TB $5000/Monat kosten) . Aber es sei denn, Sie haben eine wirklich große Anzahl von Daten, ist dies ein kleineres Problem als die Bandbreite / Datentransferkosten. (Wieder ist es nicht, dass der Service überteuert ist, es ist, dass wir eine Menge des Dienstes verwenden und kaufen.)
Substitution
- Das Subset Problem: Die einzige Möglichkeit, Daten aus Datendateien effizient zu verteilen, ist das Programm zu haben, das die Daten verteilt (z.B., ERDDAP ) Betrieb auf einem Server, der die auf einer lokalen Festplatte gespeicherten Daten aufweist (oder ähnlich schnell Zugriff auf eine SAN oder lokale RAID) . Lokale Dateisysteme ermöglichen ERDDAP™ (und zugrunde liegende Bibliotheken wie netcdf-java) um bestimmte Byte-Bereiche aus den Dateien zu verlangen und Antworten sehr schnell zu erhalten. Viele Arten von Datenanfragen von ERDDAP™ in der Datei (insbesondere netzgebundene Datenanforderungen, wenn der Stridewert > 1) kann nicht effizient durchgeführt werden, wenn das Programm die gesamte Datei oder große Stücke einer Datei von einem Nicht-lokal anfordern muss (also langsamer) Datenspeichersystem und dann eine Teilmenge extrahieren. Wenn das Cloud-Setup nicht gibt ERDDAP™ schnellen Zugriff auf Byte-Bereiche der Dateien (so schnell wie mit lokalen Dateien) , ERDDAP 's Zugriff auf die Daten wird ein schwerer Engpass und negieren andere Vorteile der Verwendung eines Cloud-Service.
Gehostete Daten
Eine Alternative zur oben genannten Kostenleistungsanalyse (die auf dem Dateninhaber basiert (z.B., NOAA ) für die Speicherung ihrer Daten in der Cloud) kam um 2012, als Amazon (und in geringerem Maße einige andere Cloud-Anbieter) begann, einige Datensätze in ihrer Cloud zu hosten (AWS S3) kostenlos (vermutlich mit der Hoffnung, dass sie ihre Kosten erholen könnten, wenn Benutzer AWS EC2 Berechnungsinstanzen mieten würden, um mit diesen Daten zu arbeiten) . Dies macht das Cloud Computing deutlich kostengünstiger, denn die Zeit und die Kosten für das Upload der Daten und das Hosting sind jetzt Null. mit ERDDAP™ v2.0 gibt es neue Features, um das Laufen zu erleichtern ERDDAP in einer Wolke:
- Jetzt, a EDDGrid FromFiles oder EDDTableFromFiles Datensatz kann aus Datendateien erstellt werden, die remote und über das Internet zugänglich sind (z.B. AWS S3 Eimer) durch die Verwendung<ccheFromUrl> und<CacheSize GB> Optionen. ERDDAP™ wird einen lokalen Cache der zuletzt verwendeten Datendateien erhalten.
- Nun, wenn alle EDDTableFromFiles Quelldateien komprimiert werden (z.B., .tgz ) , ERDDAP™ wird sie automatisch dekomprimieren, wenn es sie liest.
- Jetzt, die ERDDAP™ Thread, der auf eine bestimmte Anfrage reagiert, wird die Arbeitsfäden an Unterabschnitten des Antrags auslaufen, wenn Sie die<nThreads> Optionen. Diese Parallelisierung sollte schnellere Antworten auf schwierige Anfragen ermöglichen.
Diese Änderungen lösen das Problem von AWS S3 nicht mit lokalen, block-level-Dateispeicher und die (alt) Problem des Zugangs zu S3-Daten mit einer signifikanten Verzögerung. (Vor Jahren (~2014 ~) , die Lag war signifikant, aber ist jetzt viel kürzer und so nicht so signifikant.) Alles in allem bedeutet das die Einrichtung ERDDAP™ in der Cloud funktioniert jetzt viel besser.
Danke. — Vielen Dank an Matthew Arrott und seine Gruppe im ursprünglichen OOI-Anstrengung für ihre Arbeit an der Umsetzung ERDDAP™ in der Cloud und den daraus resultierenden Diskussionen.
-
- Ja.
Remote Replikation von Datensätzen
Es gibt ein gemeinsames Problem, das mit der obigen Diskussion von Netzen und Verbänden von ERDDAP s: Fernreplikation von Datensätzen. Das grundlegende Problem ist: Ein Datenanbieter hält einen Datensatz aufrecht, der sich gelegentlich ändert und ein Benutzer eine aktuelle lokale Kopie dieses Datensatzes aufrechterhält (aus einer Vielzahl von Gründen) . Offensichtlich gibt es eine große Anzahl von Variationen. Einige Variationen sind viel schwieriger zu behandeln als andere.
- Schnelle Updates Es ist schwieriger, den lokalen Datensatz aktuell zu halten sofort (z.B. innerhalb von 3 Sekunden) nach jeder Änderung der Quelle, anstatt beispielsweise innerhalb weniger Stunden.
- Häufige Änderungen Häufige Änderungen sind schwerer zu behandeln als seltene Änderungen. Zum Beispiel sind einmal-a-day-Änderungen viel einfacher zu behandeln als Änderungen alle 0,1 Sekunden.
- Kleine Veränderungen Kleine Änderungen in einer Quelldatei sind schwerer zu behandeln als eine völlig neue Datei. Dies gilt insbesondere, wenn die kleinen Änderungen irgendwo in der Datei sein können. Kleine Veränderungen sind schwerer zu erkennen und es schwer zu machen, die Daten zu isolieren, die repliziert werden müssen. Neue Dateien sind einfach zu erkennen und effizient zu übertragen.
- Gesamter Datensatz Einen ganzen Datensatz auf dem Laufenden zu halten, ist schwieriger, als gerade aktuelle Daten zu erhalten. Einige Benutzer brauchen nur aktuelle Daten (z.B. die letzten 8 Tage wert) .
- Mehrere Kopien Mehrere Fernkopien an verschiedenen Standorten zu erhalten, ist härter als die Aufrechterhaltung einer Fernkopie. Das ist das Skalierungsproblem.
Es gibt offensichtlich eine Vielzahl von Variationen möglicher Arten von Änderungen am Quelldatensatz und der Bedürfnisse und Erwartungen des Benutzers. Viele der Variationen sind sehr schwer zu lösen. Die beste Lösung für eine Situation ist oft nicht die beste Lösung für eine andere Situation - es gibt noch keine universelle große Lösung.
Relevante ERDDAP™ Werkzeuge
ERDDAP™ bietet mehrere Tools, die als Teil eines Systems verwendet werden können, das eine Fernkopie eines Datensatzes aufrechtzuerhalten versucht:
- ERDDAP ' RSS (Rich Site Zusammenfassung?) Service
bietet einen schnellen Weg, um zu überprüfen, ob ein Datensatz auf einer Fernbedienung ERDDAP™ hat sich geändert. - ERDDAP ' Abonnement Service
ist ein effizienter (als RSS ) Herangehen: Es wird sofort eine E-Mail senden oder an jeden Teilnehmer eine URL kontaktieren, wenn der Datensatz aktualisiert wird und das Update zu einer Änderung führte. Es ist effizient, dass es ASAP passiert und es gibt keine verschwendeten Anstrengungen (wie bei der Abstimmung eines RSS Service) . Benutzer können andere Werkzeuge verwenden (wie IFT ) auf die E-Mail-Benachrichtigungen aus dem Abonnement-System reagieren. Beispielsweise könnte ein Benutzer einen Datensatz auf einem Remote abonnieren ERDDAP™ und IFTTT verwenden, um auf die Abonnement-E-Mail-Benachrichtigungen zu reagieren und die Aktualisierung des lokalen Datensatzes auszulösen. - ERDDAP ' Flaggensystem
einen Weg für ein ERDDAP™ Administrator, um einen Datensatz auf seinem/ihr zu sagen ERDDAP um ASAP neu zu laden. Die URL-Form eines Flags kann einfach in Skripten verwendet werden. Die URL-Form einer Flagge kann auch als Aktion für ein Abonnement verwendet werden. - ERDDAP ' "files" System
kann Zugriff auf die Quelldateien für einen bestimmten Datensatz bieten, einschließlich einer Apache-style-Verzeichnisliste der Dateien (ein "Web Accessible Folder") die die Download-URL jeder Datei hat, zuletzt geänderte Zeit und Größe. Ein Nachteil der Verwendung "files" System ist, dass die Quelldateien verschiedene Variablennamen und verschiedene Metadaten haben können als der Datensatz, wie er in ERDDAP . Wenn eine Fernbedienung ERDDAP™ dataset bietet Zugriff auf seine Quelldateien, die die Möglichkeit einer armen Version von rsync eröffnet: es wird für ein lokales System leicht zu sehen, welche Remote-Dateien geändert und heruntergeladen werden müssen. (Siehe cacheFromUrl Option darunter, die dies nutzen können.)
Lösungen
Obwohl es eine große Anzahl von Variationen des Problems und eine unendliche Anzahl von möglichen Lösungen gibt, gibt es nur eine Handvoll von grundlegenden Lösungen:
Individuelle Brute Force Solutions
Eine offensichtliche Lösung besteht darin, eine benutzerdefinierte Lösung zu handhaben, die daher für eine gegebene Situation optimiert ist: ein System zu erstellen, das ermittelt/ identifiziert, welche Daten geändert haben, und diese Informationen an den Benutzer sendet, damit der Benutzer die geänderten Daten anfordern kann. Nun, Sie können das tun, aber es gibt Nachteile:
- Benutzerdefinierte Lösungen sind viel Arbeit.
- Benutzerdefinierte Lösungen sind in der Regel so auf einen bestimmten Datensatz und gegebenen Benutzer-System, dass sie nicht einfach wiederverwendet werden können.
- Benutzerdefinierte Lösungen müssen von Ihnen gebaut und gepflegt werden. (Das ist nie eine gute Idee. Es ist immer eine gute Idee, Arbeit zu vermeiden und jemand anderes zu bekommen, um die Arbeit zu tun!)
Ich entmutige diesen Ansatz, weil es fast immer besser ist, nach allgemeinen Lösungen zu suchen, die von jemand anderem gebaut und gepflegt werden, die in verschiedenen Situationen leicht wiederverwendet werden können.
rsync
rsync ist die bestehende, atemberaubend gute, allgemeine Ziellösung, um eine Sammlung von Dateien auf einem Quellcomputer in Synchronisierung auf dem Remotecomputer eines Benutzers zu halten. So funktioniert es:
- eine Veranstaltung (z.B. ein ERDDAP™ Veranstaltung des Abonnements) löst rsync aus, (oder, ein Cron Job läuft rsync zu bestimmten Zeiten jeden Tag auf dem Computer des Benutzers)
- die rsync auf dem Quellcomputer kontaktiert,
- die eine Reihe von Hashes für Stücke jeder Datei berechnet und diese Hashes an den Rsync des Benutzers übermittelt,
- die diese Informationen mit den ähnlichen Informationen für die Kopie der Dateien des Benutzers vergleicht,
- die dann die Stücke von Dateien, die sich geändert haben.
In Anbetracht dessen, was es tut, arbeitet rsync sehr schnell (z.B. 10 Sekunden plus Datentransferzeit) und sehr effizient. Es gibt Variationen von rsync die für verschiedene Situationen optimieren (z.B. durch Vorkalkulation und Cache der Hashes der Stücke jeder Quelldatei) .
Die wichtigsten Schwächen von rsync sind: es braucht einige Anstrengungen, um einzurichten (Sicherheitsfragen) ; es gibt einige Skalierungsprobleme; und es ist nicht gut, NRT-Datensätze wirklich aktuell zu halten (z.B. ist es unangenehm, rsync mehr als alle 5 Minuten zu verwenden) . Wenn Sie mit den Schwächen umgehen können, oder wenn sie Ihre Situation nicht beeinflussen, ist rsync eine ausgezeichnete, allgemeine Ziellösung, die jeder sofort verwenden kann, um viele Szenarien mit Remote-Replikation von Datensätzen zu lösen.
Es gibt einen Artikel auf der ERDDAP™ Zu Do-Liste, um zu versuchen, Unterstützung für rsync-Dienste hinzuzufügen ERDDAP (wahrscheinlich eine ziemlich schwierige Aufgabe) , so dass jeder Kunde rsync verwenden kann (oder eine Variante) eine aktuelle Kopie eines Datensatzes aufrechtzuerhalten. Wenn jemand daran arbeiten will, bitte E-Mail erd.data at noaa.gov .
Es gibt andere Programme, die mehr oder weniger tun, was rsync tut, manchmal orientiert an dataset Replikation (obwohl oft auf einem Datei-Copy-Level) , z. Unidata ' IDD .
Cache aus Url
Der CacheFromUrl Einstellung ist verfügbar (beginnend mit ERDDAP™ V2.0) für alle ERDDAP 's Dataset-Typen, die Datensätze aus Dateien machen (grundsätzlich alle Unterklassen von EDDGrid VonFiles und EDDTableFromFiles ) . Cache FromUrl macht es trivial, die lokalen Datendateien automatisch herunterzuladen und aufrechtzuerhalten, indem sie über den Cache aus einer entfernten Quelle kopiert werden AusUrl. Die Remote-Dateien können in einem Web Accessible Folder oder einer von THREDDS angebotenen verzeichnisartigen Dateiliste liegen, Hyrax , ein S3-Bucket, oder ERDDAP ' "files" System.
Wenn die Quelle der Remote-Dateien eine Fernbedienung ist ERDDAP™ Datensatz, der die Quelldateien über die ERDDAP™ "files" System, dann können Sie abonnieren zum Remote-Datensatz und Zurück zur Übersicht für Ihren lokalen Datensatz als Aktion für das Abonnement. Dann, wenn sich der Remote-Datensatz ändert, wird er die Flaggen-URL für Ihren Datensatz kontaktieren, was ihm sagen wird, ASAP neu zu laden, die die geänderten Remote-Datendateien erkennen und herunterladen wird. All dies geschieht sehr schnell (in der Regel ~5 Sekunden plus die Zeit, die benötigt wird, um die geänderten Dateien herunterzuladen) . Dieser Ansatz funktioniert großartig, wenn der Quelldatensatz Änderungen sind neue Dateien, die periodisch hinzugefügt werden und wenn sich die vorhandenen Dateien nie ändern. Dieser Ansatz funktioniert nicht gut, wenn Daten häufig an alle angepasst werden (oder höchstens) der vorhandenen Quelldatendateien, weil dann Ihr lokaler Datensatz häufig den gesamten Remote-Datensatz herunterlädt. (Hier wird ein rsync-ähnlicher Ansatz benötigt.)
ArchivADataset
ERDDAP™ ' ArchivADataset ist eine gute Lösung, wenn Daten zu einem Datensatz häufig hinzugefügt werden, aber ältere Daten werden nie geändert. Im Grunde, ein ERDDAP™ Administrator kann ArchiveADataset ausführen (vielleicht in einem Skript, vielleicht von cron) und eine Untermenge eines Datensatzes angeben, die sie extrahieren möchten (vielleicht in mehreren Dateien) und Paket in einem .zip oder .tgz Datei, so dass Sie die Datei an interessierte Personen oder Gruppen senden können (z.B. NCEI zur Archivierung) oder sie zum Download zur Verfügung stellen. Zum Beispiel könnten Sie ArchiveADataset jeden Tag um 12:10 Uhr laufen und haben es eine .zip von allen Daten von 12:00 Uhr der Vortag bis 12:00 Uhr heute. (Oder, tun Sie diese wöchentlich, monatlich oder jährlich, je nach Bedarf.) Da die verpackte Datei offline erzeugt wird, besteht keine Gefahr eines Timeouts oder zu viel Daten, wie es für einen Standard gäbe. ERDDAP™ Bitte.
ERDDAP™ Standard-Anforderungssystem
ERDDAP™ 's Standard-Anforderungssystem ist eine alternative gute Lösung, wenn Daten zu einem Datensatz häufig hinzugefügt werden, aber ältere Daten werden nie geändert. Grundsätzlich kann jeder Standardanfragen verwenden, um Daten für einen bestimmten Zeitraum zu erhalten. Zum Beispiel, um 12:10 Uhr jeden Tag, können Sie eine Anfrage für alle Daten aus einem Remote-Datensatz von 12:00 Uhr am Vortag bis 12:00 Uhr heute. Die Einschränkung (im Vergleich zum ArchivADataset Ansatz) ist das Risiko eines Timeouts oder es gibt zu viele Daten für eine einzelne Datei. Sie können die Einschränkung vermeiden, indem Sie häufigere Anfragen für kleinere Zeiträume stellen.
EDDTableFromHtpGet
\[ Diese Option existiert noch nicht, scheint aber in naher Zukunft zu bauen. \]
Der neue EDDTableFromHtpGet Datensatztyp in ERDDAP™ v2.0 ermöglicht eine weitere Lösung. Die zugrunde liegenden Dateien, die durch diese Art von Datensatz gehalten werden, sind im Wesentlichen Logdateien, die Änderungen am Datensatz erfassen. Es sollte möglich sein, ein System aufzubauen, das einen lokalen Datensatz durch periodische (oder basierend auf einem Trigger) alle Änderungen anfordern, die seit dieser letzten Anfrage an den Remote-Datensatz vorgenommen wurden. Das sollte so effizient sein (oder mehr) als rsync und würde viele schwierige Szenarien behandeln, aber würde nur funktionieren, wenn die entfernten und lokalen Datensätze EDDTableFromHtpGet-Datensätze sind.
Wenn jemand daran arbeiten will, kontaktieren Sie bitte erd.data at noaa.gov .
Verteilte Daten
Keine der oben genannten Lösungen hat eine große Aufgabe, die harten Variationen des Problems zu lösen, weil Replikation der nahen Echtzeit (NRT) Datensätze sind sehr hart, zum Teil wegen aller möglichen Szenarien.
Es gibt eine großartige Lösung: Versuchen Sie nicht einmal, die Daten zu replizieren. Verwenden Sie stattdessen die eine maßgebliche Quelle (ein Datensatz auf einem ERDDAP ) , aufrechterhalten durch den Datenanbieter (z.B. ein Regionalbüro) . Alle Benutzer, die Daten von diesem Datensatz wünschen, erhalten es immer von der Quelle. So erhalten z.B. browserbasierte Apps die Daten von einer URL-basierten Anfrage, so dass es nicht darauf ankommt, dass die Anfrage an die ursprüngliche Quelle auf einem Remoteserver liegt. (nicht der gleiche Server, der die ESM hostet) . Viele Menschen haben diesen Distributed Data Ansatz seit langem befürwortet (z.B. Roy Mendelssohn für die letzten 20+ Jahre) . ERDDAP Modell für Netz/Föderation (die oberen 80% dieses Dokuments) basiert auf diesem Ansatz. Diese Lösung ist wie ein Schwert für einen Gordischen Knoten — das ganze Problem geht weg.
- Diese Lösung ist atemberaubend einfach.
- Diese Lösung ist erstaunlich effizient, da keine Arbeit getan wird, um einen replizierten Datensatz zu halten (S) aktuell.
- Benutzer können jederzeit die neuesten Daten erhalten (z.B. mit einer Latenz von nur ~0,5 Sekunden) .
- Es skaliert ziemlich gut und es gibt Möglichkeiten, Skalierung zu verbessern. (Siehe die Diskussion in den Top 80% dieses Dokuments.)
Nein, das ist keine Lösung für alle möglichen Situationen, aber es ist eine große Lösung für die große Mehrheit. Wenn es Probleme/Schwachstellen mit dieser Lösung in bestimmten Situationen gibt, lohnt es sich oft, diese Probleme zu lösen oder mit diesen Schwächen zu leben, weil die erstaunlichen Vorteile dieser Lösung. Wenn/wenn diese Lösung für eine bestimmte Situation wirklich inakzeptabel ist, z.B. wenn Sie wirklich eine lokale Kopie der Daten haben müssen, dann betrachten Sie die anderen oben diskutierten Lösungen.
Schlussfolgerung
Während es keine einzige, einfache Lösung gibt, die alle Probleme in allen Szenarien perfekt löst (als rsync und verteilte Daten fast) , hoffentlich gibt es genügend Werkzeuge und Optionen, damit Sie eine akzeptable Lösung für Ihre besondere Situation finden können.