Login
ERDDAP™ - Beban Berat, Grid, Cluster, Federasi, dan Komputasi Cloud
ERDDAP Sitemap
ERDDAP™ adalah aplikasi web dan layanan web yang mengumpulkan data ilmiah dari berbagai sumber lokal dan jarak jauh dan menawarkan cara yang sederhana dan konsisten untuk mengunduh subset data dalam format file umum dan membuat grafik dan peta. Halaman web ini membahas masalah terkait dengan berat ERDDAP™ beban penggunaan dan mengeksplorasi kemungkinan untuk berurusan dengan beban yang sangat berat melalui grid, cluster, federasi, dan komputasi awan.
Versi asli ditulis pada Juni 2009. Tidak ada perubahan yang signifikan. Ini terakhir diperbarui 2019-04-15.
Login
Isi halaman web ini adalah pendapat pribadi Bob Simons dan tidak selalu mencerminkan posisi Pemerintah atau National Oceanic and Atmospheric Administration Sitemap Perhitungan sederhana, tetapi saya pikir kesimpulan benar. Apakah saya menggunakan logika rusak atau membuat kesalahan dalam perhitungan saya? Jika demikian, kesalahan adalah tambang sendirian. Silakan kirim email dengan koreksi ke erd dot data at noaa dot gov Sitemap
- Sitemap
Beban Berat / Kontras
Dengan penggunaan berat, berdiri sendiri ERDDAP™ akan dibatasi (dari kemungkinan besar) di:
Bandwidth Sumber Jarak Jauh
- Bandwidth sumber data jarak jauh — Bahkan dengan koneksi yang efisien (Sitemap OPeNDAP ) kecuali sumber data jarak jauh memiliki koneksi Internet bandwidth yang sangat tinggi, ERDDAP tanggapan akan dibatasi oleh seberapa cepat ERDDAP™ bisa mendapatkan data dari sumber data. Solusinya adalah untuk menyalin dataset ke ERDDAP 's hard drive, mungkin dengan Meme it EDDGrid Login Sitemap Login Sitemap
ERDDAP Web Server
- Login ERDDAP 'server memiliki koneksi Internet bandwidth yang sangat tinggi, ERDDAP tanggapan akan dibatasi oleh seberapa cepat ERDDAP™ bisa mendapatkan data dari sumber data dan bagaimana cepat ERDDAP™ dapat mengembalikan data ke klien. Satu-satunya solusi untuk mendapatkan koneksi Internet yang lebih cepat.
Login
- Jika ada banyak permintaan simultan, ERDDAP™ dapat menjalankan memori dan sementara menolak permintaan baru. ( ERDDAP™ memiliki beberapa mekanisme untuk menghindari ini dan untuk meminimalkan konsekuensi jika terjadi.) Jadi lebih banyak memori di server yang lebih baik. Pada server 32-bit, 4 + GB benar-benar bagus, 2 GB tidak direkomendasikan. Pada server 64-bit, Anda hampir sepenuhnya dapat menghindari masalah dengan mendapatkan banyak memori. Sitemap \-Xmx dan pengaturan Xms Sitemap ERDDAP Login Login ERDDAP™ mendapatkan penggunaan berat pada komputer dengan server 64-bit dengan 8GB memori dan -Xmx set ke 4000M jarang, jika pernah, dibatasi oleh memori.
Login
- Mengakses data yang disimpan di hard drive server jauh lebih cepat daripada mengakses data jarak jauh. Jadi, jika ERDDAP™ server memiliki koneksi Internet bandwidth yang sangat tinggi, dimungkinkan bahwa mengakses data pada hard drive akan menjadi bottleneck. Solusi parsial adalah untuk menggunakan lebih cepat (100 g) hard drive magnetik atau drive SSD (jika masuk akal) Sitemap Solusi lain adalah untuk menyimpan set data yang berbeda pada drive yang berbeda, sehingga bandwidth hard drive kumulatif jauh lebih tinggi.
Too Banyak File Cached
- Terlalu banyak file dalam Login Login ERDDAP™ cache semua gambar, tetapi hanya cache data untuk jenis permintaan data tertentu. Hal ini dimungkinkan untuk direktori cache untuk dataset untuk memiliki sejumlah besar file sementara. Ini akan memperlambat permintaan untuk melihat apakah file berada di cache (Sitemap) Sitemap<Login Menit & gt; dalam WordPress.org memungkinkan Anda mengatur berapa lama file dapat berada di cache sebelum dihapus. Menyiapkan nomor yang lebih kecil akan meminimalkan masalah ini.
Login
- Hanya dua hal mengambil banyak waktu CPU:
- NetCDF 4 dan HDF 5 sekarang mendukung kompresi internal data. Menghapus terkompresi besar NetCDF 4 / 100 g HDF 5 file data dapat mengambil 10 atau lebih detik. (Itu bukan kesalahan implementasi. Ini adalah sifat kompresi.) Jadi, beberapa permintaan simultan ke dataset dengan data yang disimpan dalam file terkompresi dapat menempatkan strain yang parah pada server apa pun. Jika ini adalah masalah, solusinya adalah menyimpan set data populer dalam file yang tidak terkompresi, atau mendapatkan server dengan CPU dengan lebih banyak core.
- Membuat grafik (termasuk peta) : kira-kira 0,2 - 1 detik per grafik. Jadi jika ada banyak permintaan unik simultan untuk grafik ( WMS klien sering membuat 6 permintaan simultan!) , ada keterbatasan CPU. Ketika beberapa pengguna berjalan WMS klien, ini menjadi masalah.
- Sitemap
Beberapa Identik ERDDAP s dengan Load Balancing?
Pertanyaan sering muncul: "Untuk berurusan dengan beban berat, bisakah saya mengatur beberapa identik ERDDAP s dengan balancing beban?" Ini pertanyaan yang menarik karena cepat masuk ke inti ERDDAP 's desain. Jawaban cepat adalah "tidak". Saya tahu bahwa adalah jawaban yang mengecewakan, tetapi ada beberapa alasan langsung dan beberapa alasan fundamental yang lebih besar mengapa saya merancang ERDDAP™ untuk menggunakan pendekatan yang berbeda (federasi ERDDAP s, dijelaskan dalam sebagian besar dokumen ini) yang saya percaya adalah solusi yang lebih baik. Meme it
Beberapa alasan langsung mengapa Anda tidak bisa / tidak bisa mengatur beberapa identik ERDDAP Sitemap
- Sitemap ERDDAP™ membaca setiap file data ketika pertama kali menjadi tersedia untuk menemukan berbagai data dalam file. Ini kemudian menyimpan informasi dalam file indeks. Kemudian, ketika permintaan pengguna untuk data datang, ERDDAP™ menggunakan indeks untuk mengetahui file mana yang akan terlihat untuk data yang diminta. Jika ada beberapa identik ERDDAP s, mereka masing-masing akan melakukan pengindeksan ini, yang merupakan upaya yang terbuang. Dengan sistem federasi yang dijelaskan di bawah ini, indeks hanya dilakukan sekali, oleh salah satu ERDDAP Sitemap
- Untuk beberapa jenis permintaan pengguna (Sitemap .nc .png, .pdf file) ERDDAP™ harus membuat seluruh file sebelum respons dapat dikirim. Login ERDDAP™ cache file ini untuk waktu singkat. Jika permintaan yang identik datang (seperti yang sering dilakukan, terutama untuk gambar di mana URL tertanam di halaman web) Login ERDDAP™ dapat menggunakan ulang file yang tersimpan. Dalam sistem beberapa identik ERDDAP s, file yang tersimpan tidak dibagikan, sehingga setiap ERDDAP™ tidak perlu dan membuat kembali limbah .nc .png, atau .pdf file. Dengan sistem federasi yang dijelaskan di bawah ini, file hanya dibuat sekali, oleh salah satu ERDDAP Sitemap
- ERDDAP 's sistem berlangganan tidak diatur untuk dibagikan oleh beberapa ERDDAP Sitemap Misalnya, jika load balancer mengirim pengguna ke satu ERDDAP™ dan pengguna berlangganan dataset, maka yang lain ERDDAP tidak akan menyadari bahwa berlangganan. Meme it Kemudian, jika load balancer mengirimkan pengguna ke yang berbeda ERDDAP™ dan meminta daftar berlangganannya, yang lain ERDDAP™ akan mengatakan tidak ada (memimpin dia/her untuk membuat berlangganan duplikat di ERED lainnya DAP ) Sitemap Dengan sistem federasi yang dijelaskan di bawah ini, sistem berlangganan hanya ditangani oleh utama, publik, komposit ERDDAP Sitemap
Ya, untuk setiap masalah tersebut, saya bisa (Sitemap) insinyur solusi (untuk berbagi informasi antara ERDDAP Login) tapi saya pikir Meme it Login ERDDAP pendekatan (dijelaskan dalam sebagian besar dokumen ini) adalah solusi keseluruhan yang jauh lebih baik, sebagian karena penawaran dengan masalah lain bahwa beberapa-identical- ERDDAP Pendekatan s-with-a-load-balancer bahkan tidak mulai mengatasi, terutama sifat terdesentralisasi dari sumber data di dunia.
Ini terbaik untuk menerima fakta sederhana bahwa saya tidak desain Meme it ERDDAP™ untuk digunakan sebagai beberapa identik ERDDAP s dengan load balancer. Saya dirancang secara sadar ERDDAP™ bekerja dengan baik dalam federasi ERDDAP s, yang saya percaya memiliki banyak keuntungan. Meme it Tidak dapat, federasi ERDDAP s sangat selaras dengan sistem pusat data terdesentralisasi, yang kami miliki di dunia nyata (memikirkan daerah IOOS yang berbeda, atau daerah CoastWatch yang berbeda, atau bagian yang berbeda dari NCEI, atau 100 pusat data lainnya di NOAA , atau DAAC NASA yang berbeda, atau pusat data 1000 di seluruh dunia) Sitemap Alih-alih memberitahu semua pusat data dunia yang mereka butuhkan untuk meninggalkan upaya mereka dan menempatkan semua data mereka di pusat "data danau" (bahkan jika mungkin, itu adalah ide yang mengerikan untuk banyak alasan - melihat berbagai analis menunjukkan banyak keuntungan dari sistem desentralisasi ) Login ERDDAP 's desain bekerja dengan dunia seperti itu. Meme it Setiap pusat data yang menghasilkan data dapat terus mempertahankan, menyembuhkan, dan melayani data mereka (Meme it) , dan belum, dengan ERDDAP™ data juga dapat langsung tersedia dari terpusat ERDDAP tanpa perlu untuk mentransmisikan data ke terpusat ERDDAP™ atau menyimpan salinan duplikat data. Memang, dataset yang diberikan dapat secara bersamaan tersedia Sitemap ERDDAP™ di organisasi yang diproduksi dan benar-benar menyimpan data (Login) Login Sitemap ERDDAP™ di organisasi induk (e.g., pusat IOOS) Login dari semua- NOAA ERDDAP™ Login dari pemerintah all-US-federal ERDDAP™ Login dari global ERDDAP™ (Login) Login dan dari khusus ERDDAP Login (Sitemap ERDDAP™ di lembaga yang dikhususkan untuk penelitian HAB) Login semua pada dasarnya, dan efisien karena hanya metadata ditransfer antara ERDDAP data. Terbaik dari semua, setelah awal ERDDAP™ di organisasi yang berasal, semua yang lain Meme it ERDDAP dapat diatur dengan cepat (beberapa jam kerja) , dengan sumber daya minimal (satu server yang tidak memerlukan RAID untuk penyimpanan data karena tidak menyimpan data secara lokal) , dan dengan demikian dengan biaya yang benar-benar minimal. Bandingkan bahwa dengan biaya pengaturan dan menjaga pusat data terpusat dengan danau data dan kebutuhan untuk koneksi Internet yang benar-benar besar, benar-benar mahal, ditambah masalah kehadiran pusat data terpusat menjadi satu titik kegagalan. Untuk saya, ERDDAP pendekatan terdesentralisasi, jauh lebih unggul.
Dalam situasi di mana pusat data tertentu membutuhkan beberapa ERDDAP memenuhi permintaan tinggi, ERDDAP 'desain sepenuhnya mampu pencocokan atau melebihi kinerja multiple-identical- ERDDAP pendekatan s-with-a-load-balancer. Anda selalu memiliki pilihan pengaturan beberapa komposit ERDDAP Login (seperti dibahas di bawah ini) , masing-masing yang mendapatkan semua data mereka dari yang lain ERDDAP s, tanpa balancing beban. Dalam hal ini, saya merekomendasikan bahwa Anda membuat titik memberikan setiap komposit ERDDAP s nama / identitas yang berbeda dan jika memungkinkan mereka mengaturnya di berbagai bagian dunia (e.g., berbagai daerah AWS) Sitemap ERD Login ERD Login ERD Login ERD Login ERD \_IT, sehingga pengguna sadar, berulang kali, bekerja dengan spesifik ERDDAP Dengan manfaat tambahan yang telah dihapus risiko dari satu titik kegagalan.
- Sitemap
Jaringan, Cluster, dan Federasi
Di bawah penggunaan yang sangat berat, satu standalone ERDDAP™ akan berjalan menjadi satu atau lebih dari Meme it Login tercantum di atas dan bahkan solusi yang disarankan tidak mencukupi. Untuk situasi seperti itu, ERDDAP™ memiliki fitur yang memudahkan membangun grid yang dapat diukur (juga disebut cluster atau federasi) Login ERDDAP yang memungkinkan sistem untuk menangani penggunaan yang sangat berat (e.g., untuk pusat data besar) Sitemap
Saya menggunakan Login sebagai istilah umum untuk menunjukkan jenis kluster komputer di mana semua bagian mungkin atau mungkin tidak terletak secara fisik di satu fasilitas dan mungkin atau mungkin tidak diberikan secara terpusat. Keuntungan dari co-lokasi, grid yang dimiliki secara terpusat dan diberikan (Login) adalah manfaat dari ekonomi skala (terutama beban kerja manusia) dan menyederhanakan membuat bagian dari sistem bekerja dengan baik bersama. Keuntungan dari grid non-lokasi, yang tidak dimiliki secara terpusat dan diberikan (Login) adalah bahwa mereka mendistribusikan beban kerja manusia dan biaya, dan dapat memberikan beberapa toleransi kesalahan tambahan. Solusi yang saya mengusulkan di bawah ini bekerja dengan baik untuk semua grid, cluster, dan topografi federasi.
Ide dasar merancang sistem scalable adalah untuk mengidentifikasi potensi bottleneck dan kemudian merancang sistem sehingga bagian-bagian sistem dapat direplikasi sesuai kebutuhan untuk mengurangi bottleneck. Idealnya, setiap bagian yang direplikasi meningkatkan kapasitas bagian dari sistem secara linear (efisiensi scaling) Sitemap Sistem tidak dapat diukur kecuali ada solusi yang dapat diukur untuk setiap bottleneck. Login berbeda dari efisiensi (bagaimana cepat tugas dapat dilakukan — efisiensi bagian) Sitemap Scalability memungkinkan sistem untuk tumbuh untuk menangani tingkat permintaan. Sitemap (penasaran dan bagian-bagian) menentukan berapa banyak server, dll., akan diperlukan untuk memenuhi tingkat permintaan yang diberikan. Efisiensi sangat penting, tetapi selalu memiliki batas. Scalability adalah satu-satunya solusi praktis untuk membangun sistem yang dapat menangani Sitemap penggunaan berat. Idealnya, sistem akan dapat diukur dan efisien.
Login
Tujuan desain ini adalah:
- Untuk membuat arsitektur scalable (salah satu yang mudah dipahami dengan meniru bagian yang menjadi over-burdened) Sitemap Untuk membuat sistem yang efisien yang memaksimalkan ketersediaan dan throughput data yang diberikan sumber daya komputasi yang tersedia. (Biaya hampir selalu menjadi masalah.)
- Untuk menyeimbangkan kemampuan bagian sistem sehingga satu bagian dari sistem tidak akan kewalahan bagian lain.
- Untuk membuat arsitektur sederhana sehingga sistem mudah diatur dan diberikan.
- Untuk membuat arsitektur yang bekerja dengan baik dengan semua topographies grid.
- Untuk membuat sistem yang gagal anggun dan dengan cara terbatas jika bagian apa pun menjadi over-burdened. (Waktu yang diperlukan untuk menyalin dataset besar akan selalu membatasi kemampuan sistem untuk menangani kenaikan tiba-tiba atas permintaan dataset tertentu.)
- (Sitemap) Untuk membuat arsitektur yang tidak terikat dengan setiap spesifik komputasi awan layanan atau layanan eksternal lainnya (karena tidak perlu mereka Meme it) Sitemap
Sitemap
Rekomendasi kami
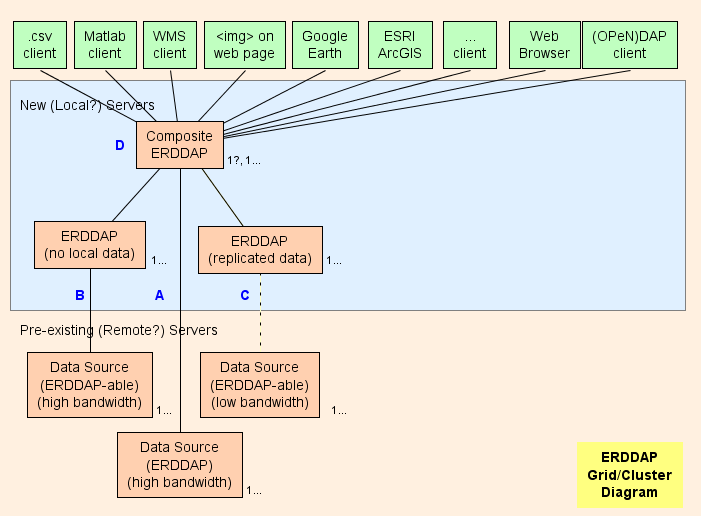
- Pada dasarnya, saya menyarankan menyiapkan Komposit ERDDAP™ ( Login di diagram) , yang biasa ERDDAP™ kecuali itu hanya melayani data dari lain Meme it ERDDAP Sitemap Arsitektur grid dirancang untuk beralih sebanyak mungkin (penggunaan CPU, penggunaan memori, penggunaan bandwidth) dari Komposit ERDDAP™ ke yang lain ERDDAP Sitemap
- ERDDAP™ memiliki dua jenis dataset khusus, EDDGrid Login Login Login , yang merujuk pada dataset di lain ERDDAP Sitemap
- Ketika komposit ERDDAP™ menerima permintaan data atau gambar dari dataset ini, komposit ERDDAP™ Login permintaan data ke yang lain ERDDAP™ Login Hasilnya:
- Ini sangat efisien (CPU, memori, dan bandwidth) karena
- Komposit ERDDAP™ harus mengirim permintaan data ke yang lain ERDDAP Sitemap
- Login ERDDAP™ harus mendapatkan data, memformatnya, dan mengirimkan data ke komposit ERDDAP Sitemap
- Komposit ERDDAP™ harus menerima data (menggunakan bandwidth tambahan) , memformatnya (menggunakan waktu CPU tambahan dan memori) dan mentransmisikan data ke pengguna (menggunakan bandwidth tambahan) Sitemap Dengan mengarahkan permintaan data dan memungkinkan yang lain ERDDAP™ untuk mengirim respons langsung ke pengguna, komposit ERDDAP™ menghabiskan pada dasarnya tidak ada waktu CPU, memori, atau bandwidth pada permintaan data.
- Redirect transparan ke pengguna terlepas dari perangkat lunak klien (browser atau perangkat lunak atau alat baris perintah lainnya) Sitemap
- Ini sangat efisien (CPU, memori, dan bandwidth) karena
Bagian Grid
Login Sitemap Untuk setiap sumber data jarak jauh yang memiliki bandwidth tinggi OPeNDAP server, Anda dapat terhubung langsung ke server jarak jauh. Jika server jarak jauh adalah ERDDAP™ Sitemap EDDGrid DariErddap atau EDDTableDari ERDDAP untuk melayani data dalam Komposit ERDDAP Sitemap Jika server jarak jauh adalah beberapa jenis lain dari DAP server, e.g., THREDDS, Hyrax , atau GrADS, penggunaan EDDGrid Login
Login : Untuk setiap ERDDAP Database (sumber data dari mana Meme it ERDDAP dapat membaca data) yang memiliki server berbanding tinggi, mendirikan yang lain ERDDAP™ di grid yang bertanggung jawab untuk melayani data dari sumber data ini.
- Jika beberapa ERDDAP tidak mendapatkan banyak permintaan untuk data, Anda dapat mengkonsolidasikan mereka menjadi satu ERDDAP Sitemap
- Sitemap ERDDAP™ didedikasikan untuk mendapatkan data dari satu sumber jarak jauh semakin banyak permintaan, ada godaan untuk menambahkan tambahan ERDDAP s untuk mengakses sumber data jarak jauh. Dalam kasus khusus ini mungkin masuk akal, tetapi lebih mungkin bahwa ini akan kewalahan sumber data jarak jauh (yang berperawatan diri) dan juga mencegah pengguna lain dari mengakses sumber data jarak jauh (yang tidak bagus) Sitemap Dalam kasus seperti itu, pertimbangkan pengaturan lain ERDDAP™ untuk melayani bahwa satu dataset dan menyalin dataset pada itu ERDDAP 's hard drive (Login Login ) , mungkin dengan EDDGrid Login dan/atau Login Sitemap
- Login server harus dapat diakses secara publik.
Login : Untuk setiap ERDDAP - Sumber data yang dapat diakses yang memiliki server berbanding rendah (atau merupakan layanan yang lambat untuk alasan lain) mempertimbangkan pengaturan lain ERDDAP™ dan menyimpan salinan dataset pada itu ERDDAP 's hard drive, mungkin dengan Meme it EDDGrid Login dan/atau Login Sitemap Jika beberapa ERDDAP tidak mendapatkan banyak permintaan untuk data, Anda dapat mengkonsolidasikan mereka menjadi satu ERDDAP Sitemap Login server harus dapat diakses secara publik.
Login ERDDAP
Login Sitemap Komposit ERDDAP™ Sitemap ERDDAP™ kecuali itu hanya melayani data dari lain Meme it ERDDAP Sitemap
- Karena komposit ERDDAP™ memiliki informasi dalam memori tentang semua dataset, dapat dengan cepat menanggapi permintaan daftar dataset (pencarian teks penuh, pencarian kategori, daftar semua dataset) , dan permintaan untuk Formulir Akses Data yang ditetapkan, Membuat bentuk Graph, atau WMS Login Ini adalah semua halaman HTML yang dihasilkan secara dinamis, berdasarkan informasi yang diadakan dalam memori. Jadi responsnya sangat cepat.
- Karena permintaan data aktual diarahkan dengan cepat ke yang lain ERDDAP s, komposit ERDDAP™ dapat dengan cepat menanggapi permintaan data aktual tanpa menggunakan waktu CPU, memori, atau bandwidth.
- Dengan beralih sebanyak mungkin pekerjaan (CPU, memori, bandwidth) dari Komposit ERDDAP™ ke yang lain ERDDAP s, komposit ERDDAP™ dapat muncul untuk melayani data dari semua dataset dan tetap menjaga dengan sejumlah besar permintaan data dari sejumlah besar pengguna.
- Tes awal menunjukkan bahwa komposit ERDDAP™ dapat menanggapi sebagian besar permintaan dalam ~ 1ms waktu CPU, atau 1000 permintaan / detik. Jadi prosesor inti 8 harus dapat menanggapi sekitar 8000 permintaan / detik. Meskipun dimungkinkan untuk merevisi durasi aktivitas yang lebih tinggi yang akan menyebabkan perlambatan, yaitu banyak throughput. Kemungkinan bandwidth pusat data akan panjang bottleneck sebelum komposit ERDDAP™ menjadi bottleneck.
Maksimum yang terbaru (Sitemap) Sitemap
Login EDDGrid /TableDariErddap di komposit ERDDAP™ hanya mengubah informasi yang disimpan tentang setiap dataset sumber ketika dataset sumber Sitemap dan beberapa bagian dari perubahan metadata (e.g., variabel waktu actual\_range ) , sehingga menghasilkan notifikasi berlangganan. Jika dataset sumber memiliki data yang sering berubah (misalnya, data baru setiap detik) dan menggunakan "update" sistem untuk melihat sering perubahan data yang mendasarinya, EDDGrid /TableFromErddap tidak akan diberitahukan tentang perubahan sering ini sampai dataset berikutnya "reload", sehingga EDDGrid /TableFromErddap tidak akan sangat up-to-date. Anda dapat meminimalkan masalah ini dengan mengubah dataset sumber<reloadEveryNMinutes> untuk nilai yang lebih kecil (60? 15?) sehingga ada lebih banyak pemberitahuan berlangganan untuk memberitahu Meme it EDDGrid /TableFromErddap untuk memperbarui informasinya tentang dataset sumber.
Atau, jika sistem manajemen data Anda tahu ketika dataset sumber memiliki data baru (e.g., melalui script yang menyalin file data ke tempat) dan jika itu tidak terlalu sering (e.g., setiap 5 menit, atau kurang sering) , ada solusi yang lebih baik:
- Jangan gunakan<updateEveryNMillis> untuk menjaga dataset sumber hingga tanggal.
- Mengatur dataset sumber<reloadEveryNMinutes> untuk jumlah yang lebih besar (1440?) Sitemap
- Memiliki skrip kontak dataset sumber URL tepat setelah menyalin file data baru ke tempat. Itu akan menyebabkan dataset sumber menjadi up-to-date sempurna dan menyebabkannya menghasilkan pemberitahuan berlangganan, yang akan dikirim ke EDDGrid /TableDariErddap dataset. Itu akan memimpin Meme it EDDGrid /TableDariErddap dataset untuk sangat up-to-date (baik, dalam 5 detik data baru ditambahkan) Sitemap Dan semua yang akan dilakukan secara efisien (tanpa reload dataset yang tidak perlu) Sitemap
Beberapa Komposit ERDDAP Login
- Dalam kasus yang sangat ekstrem, atau untuk toleransi kesalahan, Anda mungkin ingin mengatur lebih dari satu komposit ERDDAP Sitemap Mungkin bagian lain dari sistem (tidak dapat, bandwidth pusat data) akan menjadi masalah panjang sebelum komposit ERDDAP™ menjadi bottleneck. Jadi solusinya mungkin untuk mengatur tambahan, beragam geografis, pusat data (Login) , setiap dengan satu komposit ERDDAP™ dan server dengan ERDDAP Sitemap (setidaknya) salinan cermin dari dataset yang dalam permintaan tinggi. Pengaturan seperti itu juga memberikan toleransi kesalahan dan cadangan data (Login) Sitemap Dalam kasus ini, yang terbaik jika komposit ERDDAP memiliki URL yang berbeda.
Jika Anda benar-benar ingin semua komposit ERDDAP s untuk memiliki URL yang sama, gunakan sistem ujung depan yang menetapkan pengguna tertentu untuk hanya salah satu komposit ERDDAP Login (berdasarkan alamat IP) , sehingga semua permintaan pengguna pergi ke hanya salah satu komposit ERDDAP Sitemap Ada dua alasan:
- Ketika dataset yang mendasari diisi ulang dan perubahan metadata (misalnya, file data baru dalam dataset gridded menyebabkan variabel waktu actual\_range Sitemap) , komposit ERDDAP s akan sementara sedikit keluar dari sinch, tetapi dengan konsistensi acara Sitemap Biasanya, mereka akan sinkronisasi ulang dalam 5 detik, tetapi kadang-kadang akan lebih lama. Jika pengguna membuat sistem otomatis yang bergantung pada ERDDAP™ Login yang memicu tindakan, masalah sinkronisasi singkat akan menjadi signifikan.
- Komposit 2+ ERDDAP masing-masing mempertahankan set langganan mereka sendiri (karena masalah sinch dijelaskan di atas) Sitemap
Jadi pengguna yang diberikan harus diarahkan hanya satu komposit ERDDAP untuk menghindari masalah ini. Jika salah satu komposit ERDDAP s turun, sistem ujung depan dapat mengarahkan bahwa Meme it ERDDAP pengguna untuk orang lain Meme it ERDDAP™ Sitemap Namun, jika itu adalah masalah kapasitas yang menyebabkan komposit pertama ERDDAP™ gagal (pengguna yang berlebihan? Sitemap serangan denial-of-service Sitemap) , ini membuatnya sangat mungkin bahwa mengarahkan penggunanya ke komposit lain ERDDAP s akan menyebabkan Login Sitemap Dengan demikian, pengaturan yang paling kuat adalah memiliki komposit ERDDAP URL
Atau, mungkin lebih baik, atur beberapa komposit ERDDAP tanpa balancing beban. Dalam hal ini, Anda harus membuat titik memberi masing-masing Meme it ERDDAP s nama / identitas yang berbeda dan jika memungkinkan mereka mengaturnya di berbagai bagian dunia (e.g., berbagai daerah AWS) Sitemap ERD Login ERD Login ERD Login ERD Login ERD \_IT, sehingga pengguna sadar, bekerja berulang dengan spesifik ERDDAP Sitemap
- \[ Untuk desain yang menarik dari sistem kinerja tinggi yang berjalan pada satu server, lihat ini Deskripsi terperinci Mailinator Sitemap \]
Dataset dalam Demand Sangat Tinggi
Dalam kasus yang benar-benar tidak biasa bahwa salah satu Meme it Login Login Login Sitemap Login ERDDAP tidak dapat terus dengan permintaan karena bandwidth atau batasan hard drive, masuk akal untuk menyalin data (Sitemap) di server lain + hard Login ERDDAP , mungkin dengan EDDGrid Login dan/atau Login Sitemap Meskipun mungkin tampak ideal untuk memiliki dataset asli dan dataset yang disalin muncul mulus sebagai satu dataset dalam komposit ERDDAP™ , ini sulit karena dua set data akan berada dalam keadaan yang sedikit berbeda pada waktu yang berbeda (tidak dapat, setelah data baru mendapat asli, tetapi sebelum dataset yang disalin mendapat salinannya) Sitemap Oleh karena itu, saya merekomendasikan bahwa dataset diberikan judul yang sedikit berbeda (Sitemap (foto's) "dan "... (fotokopi #2) ", atau mungkin " (Login Sitemap ) " atau " (server # Sitemap ) Sitemap) dan muncul sebagai set data terpisah di komposit ERDDAP Sitemap Pengguna digunakan untuk melihat daftar situs cermin di situs unduh file populer, jadi ini tidak harus mengejutkan atau mengecewakan mereka. Karena keterbatasan bandwidth di situs tertentu, mungkin masuk akal untuk memiliki cermin yang terletak di situs lain. Jika salinan cermin berada di pusat data yang berbeda, diakses hanya oleh komposit pusat data itu ERDDAP™ , judul yang berbeda (g., "mirror #1) tidak perlu.
RAIDs versus Regular Hard Drive
Jika dataset besar atau sekelompok dataset tidak banyak digunakan, mungkin masuk akal untuk menyimpan data pada RAID karena menawarkan toleransi kesalahan dan karena Anda tidak perlu daya pemrosesan atau bandwidth server lain. Tetapi jika dataset banyak digunakan, mungkin lebih masuk akal untuk menyalin data pada server lain + ERDDAP™ + hard drive (mirip dengan Google AdSense ) daripada menggunakan satu server dan RAID untuk menyimpan beberapa set data karena Anda mendapatkan untuk menggunakan server+hardDrive+ ERDDAP di grid sampai salah satu dari mereka gagal.
Login
Apa yang terjadi jika...
- Ada banyak permintaan untuk satu dataset (e.g., semua siswa dalam kelas secara bersamaan meminta data serupa) Sitemap Sitemap ERDDAP™ melayani dataset akan kewalahan dan memperlambat atau menolak permintaan. Komposit ERDDAP™ dan lainnya ERDDAP tidak akan terpengaruh. Karena faktor pembatasan untuk dataset yang diberikan dalam sistem adalah hard drive dengan data (Login ERDDAP ) hanya solusi (Sitemap) adalah untuk membuat salinan dataset pada server yang berbeda + hardDrive + ERDDAP Sitemap
- Login Login Login Login Sitemap Login ERDDAP™ Login (e.g., kegagalan hard drive) Sitemap Hanya dataset (Login) Sitemap ERDDAP™ dipengaruhi. Jika dataset (Login) dicerminkan pada server lain + hardDrive + ERDDAP Efeknya minimal. Jika masalah adalah kegagalan hard drive di tingkat 5 atau 6 RAID, Anda hanya mengganti drive dan memiliki RAID membangun kembali data di drive.
- Komposit ERDDAP™ gagal? Jika Anda ingin membuat sistem dengan sangat ketersediaan tinggi Anda dapat mengatur beberapa komposit ERDDAP Login (seperti yang dibahas di atas) menggunakan sesuatu seperti Login Sitemap Login untuk menangani balancing beban. Perhatikan bahwa komposit yang diberikan ERDDAP™ dapat menangani sejumlah besar permintaan dari sejumlah besar pengguna karena permintaan untuk metadata kecil dan ditangani oleh informasi yang dalam memori, dan permintaan data (yang mungkin besar Meme it) diarahkan ke anak ERDDAP Sitemap
Sederhana, Scalable
Sistem ini mudah diatur dan diberikan, dan mudah dieksekusi ketika bagian dari itu menjadi over-burdened. Satu-satunya keterbatasan nyata untuk pusat data yang diberikan adalah bandwidth pusat data dan biaya sistem.
Login
Perhatikan bandwidth perkiraan komponen yang umum digunakan dari sistem:
| Sitemap | Sitemap (Login) | | Sitemap | Sitemap | | Memori DDR | S/M | | Login | 1 Artikel | | SATA hard drive | 0 Artikel | | Gigabit Ethernet | Sitemap | | G-12 | Chili | | Login | 0.005 g | | S1 | 0.00001 ATOM |
Jadi, satu hard drive SATA (0.3 g) di satu server dengan satu ERDDAP™ bisa mungkin jenuh Gigabit Ethernet LAN (0.1 g) Sitemap Gigabit Ethernet LAN (0.1 g) mungkin dapat menjenuhkan koneksi Internet OC-12 (0.06GB/s) Sitemap Dan setidaknya satu daftar sumber OC-12 baris biaya sekitar $ 100,000 per bulan. (Ya, perhitungan ini didasarkan pada mendorong sistem ke batas-batasnya, yang tidak baik karena menyebabkan respon yang sangat lambung. Tapi perhitungan ini berguna untuk perencanaan dan untuk menyeimbangkan bagian sistem.) Jelas, koneksi Internet yang sangat cepat untuk pusat data Anda sejauh bagian sistem yang paling mahal. Anda dapat dengan mudah dan relatif murah membangun grid dengan server lusin yang menjalankan lusin ERDDAP s yang mampu memompa banyak data dengan cepat, tetapi koneksi Internet yang sangat cepat akan sangat, sangat mahal. Solusi parsial adalah:
- Mendorong klien untuk meminta subset data jika itu semua yang diperlukan. Jika klien hanya membutuhkan data untuk wilayah kecil atau pada resolusi yang lebih rendah, itulah yang harus mereka minta. Subsetting adalah fokus pusat dari protokol ERDDAP™ mendukung untuk meminta data.
- Encourage mentransmisikan data terkompresi. ERDDAP™ Sitemap transmisi data jika menemukan "accept-encoding" di HTTP GET header permintaan. Semua browser web menggunakan "accept-encoding" dan secara otomatis menekan respons. Klien lain (e.g., program komputer) harus menggunakannya secara eksplisit.
- Mengalokasikan server Anda di situs ISP atau situs lain yang menawarkan biaya bandwidth yang relatif lebih murah.
- Menyiapkan server dengan ERDDAP s ke institusi yang berbeda sehingga biaya tersebar. Anda kemudian dapat menghubungkan komposit Anda ERDDAP™ mereka ERDDAP Sitemap
Login Login dan layanan hosting web menawarkan semua bandwidth Internet yang Anda butuhkan, tetapi tidak memecahkan masalah harga.
Untuk informasi umum tentang merancang sistem scalable, kapasitas tinggi, kesalahan-tolerant, lihat buku Michael T. Nygard Sitemap Sitemap
Seperti Legos
Desainer perangkat lunak sering mencoba menggunakan yang baik pola desain perangkat lunak untuk memecahkan masalah. Pola yang baik baik karena mereka merangkum baik, mudah dibuat dan bekerja dengan, solusi tujuan umum yang menyebabkan sistem dengan sifat yang baik. Nama pola tidak standar, jadi saya akan memanggil pola yang Meme it ERDDAP™ menggunakan Pola Lego. Setiap Lego (Sitemap ERDDAP ) sederhana, kecil, standar, berdiri sendiri, bata (server data) dengan antarmuka yang ditentukan yang memungkinkan untuk dihubungkan ke legos lain ( ERDDAP Login) Sitemap Bagian ERDDAP™ yang membuat sistem ini adalah: sistem berlangganan dan flagURL (yang memungkinkan komunikasi antara ERDDAP Login) EDD... Dari sistem redirect Erddap, dan sistem sistem RESTful permintaan data yang dapat dihasilkan oleh pengguna atau yang lain ERDDAP Sitemap Dengan demikian, diberikan dua atau lebih legos ( ERDDAP Login) , Anda dapat membuat sejumlah besar bentuk yang berbeda (topologi jaringan ERDDAP Login) Sitemap Tentu, desain dan fitur ERDDAP™ bisa dilakukan berbeda, tidak seperti Lego, mungkin hanya untuk mengaktifkan dan mengoptimalkan untuk satu topologi khusus. Tapi kita merasa bahwa Meme it ERDDAP 's Lego-seperti desain menawarkan solusi tujuan umum yang baik yang memungkinkan ERDDAP™ Login (atau kelompok administrator) untuk membuat semua jenis topologi federasi yang berbeda. Sebagai contoh, organisasi tunggal dapat mengatur tiga (Sitemap) ERDDAP seperti yang ditunjukkan pada Meme it ERDDAP™ Diagram Grid / Silinder di atas Sitemap Atau grup terdistribusi (Login Login Login Login NOAA Sitemap Login Login Login Login Login Login Login Login Login) dapat mengatur satu ERDDAP™ di setiap pos kecil (sehingga data dapat tetap dekat dengan sumber) dan kemudian mengatur komposit ERDDAP™ di kantor pusat dengan dataset virtual (yang selalu sempurna up-to-date) dari setiap pos kecil ERDDAP Sitemap Memang, semua Meme it ERDDAP s, dipasang di berbagai institusi di seluruh dunia, yang mendapatkan data dari yang lain ERDDAP s dan/atau menyediakan data ke data lain ERDDAP s, membentuk jaringan raksasa ERDDAP Sitemap Bagaimana keren itu?! Jadi, seperti dengan Lego, kemungkinan tidak terbatas. Itu sebabnya ini adalah pola yang baik. Itu sebabnya ini adalah desain yang baik untuk Meme it ERDDAP Sitemap
Berbagai Jenis Permintaan
Salah satu komplikasi kehidupan nyata dari diskusi ini topologi server data adalah bahwa ada berbagai jenis permintaan dan cara yang berbeda untuk mengoptimalkan untuk berbagai jenis permintaan. Ini sebagian besar masalah terpisah (Bagaimana cepat bisa ERDDAP™ dengan data menanggapi permintaan data?) dari diskusi topologi (yang berhubungan dengan hubungan antara server data dan server yang memiliki data yang sebenarnya) Sitemap ERDDAP™ Tentu saja, mencoba menangani semua jenis permintaan secara efisien, tetapi menangani beberapa lebih baik daripada yang lain.
- Banyak permintaan sederhana. Contoh: Apa metadata untuk dataset ini? Atau: Berapa nilai dimensi waktu untuk dataset gridded ini? ERDDAP™ dirancang untuk menangani ini secepat mungkin (biasanya dalam<= 2 ms) dengan menjaga informasi ini dalam memori.
- Beberapa permintaan cukup keras. Contoh: Memberikan saya subset dataset ini (yang dalam satu file data) Sitemap Permintaan ini dapat ditangani relatif cepat karena tidak sulit.
- Beberapa permintaan sulit dan dengan demikian memakan waktu. Contoh: Memberikan saya subset dataset ini (yang mungkin ada dalam file data 10.000+, atau mungkin dari file data terkompresi yang setiap mengambil 10 detik untuk depresi) Sitemap ERDDAP™ v2.0 memperkenalkan beberapa cara baru, lebih cepat untuk berurusan dengan permintaan ini, tidak dapat dengan memungkinkan benang penetapan permintaan untuk memijat beberapa benang pekerja yang menangani subset permintaan yang berbeda. Tapi ada pendekatan lain untuk masalah ini yang Meme it ERDDAP™ belum mendukung: subset file data untuk dataset yang diberikan dapat disimpan dan dianalisis pada komputer terpisah, dan kemudian hasilnya dikombinasikan pada server asli. Pendekatan ini disebut Login dan dibebaskan oleh Login , pertama (Sitemap) program MapReduce open-source, yang didasarkan pada ide dari kertas Google. (Jika Anda butuh MapReduce ERDDAP Silakan kirim permintaan email ke erd.data at noaa.gov Sitemap) Sitemap Login menarik karena tampaknya implementasi MapReduce diterapkan untuk mengatur dataset tabel, yang merupakan salah satu ERDDAP tujuan utama. Kemungkinan Anda dapat membuat Meme it ERDDAP™ dataset dari dataset BigQuery melalui Login karena BigQuery dapat diakses melalui antarmuka JDBC.
Ini adalah pendapat saya.
Ya, perhitungannya sederhana (dan sekarang sedikit tanggal) tapi saya pikir kesimpulan benar. Meme it Apakah saya menggunakan logika rusak atau membuat kesalahan dalam perhitungan saya? Jika demikian, kesalahan adalah tambang sendirian. Silakan kirim email dengan koreksi ke erd dot data at noaa dot gov Sitemap
- Sitemap
Login
Beberapa perusahaan menawarkan layanan komputasi cloud (Login Layanan Web Amazon Login Google Login ) Sitemap Web hosting perusahaan telah menawarkan layanan yang lebih sederhana karena layanan mid-1990, tetapi layanan "cloud" telah sangat memperluas fleksibilitas sistem dan berbagai layanan yang ditawarkan. Sitemap ERDDAP™ grid hanya terdiri dari ERDDAP Sitemap ERDDAP Sitemap Java aplikasi web yang dapat berjalan di Tomcat (server aplikasi yang paling umum) atau server aplikasi lainnya, harus relatif mudah untuk mengatur ERDDAP™ grid pada layanan cloud atau situs web hosting. Keuntungan dari layanan ini adalah:
- Mereka menawarkan akses ke koneksi Internet bandwidth yang sangat tinggi. Ini sendiri dapat membenarkan menggunakan layanan ini.
- Mereka hanya mengenakan biaya untuk layanan yang Anda gunakan. Misalnya, Anda mendapatkan akses ke koneksi Internet bandwidth yang sangat tinggi, tetapi Anda hanya membayar data aktual yang ditransfer. Itu memungkinkan Anda membangun sistem yang jarang mendapat kewalahan (bahkan pada permintaan puncak) tanpa harus membayar untuk kapasitas yang jarang digunakan.
- Mereka mudah dipahami. Anda dapat mengubah jenis server atau menambahkan banyak server atau penyimpanan sebanyak yang Anda inginkan, dalam waktu kurang dari satu menit. Ini sendiri dapat membenarkan menggunakan layanan ini.
- Mereka membebaskan Anda dari banyak tugas administrasi untuk menjalankan server dan jaringan. Ini sendiri dapat membenarkan menggunakan layanan ini.
Kerugian layanan ini adalah:
- Biaya untuk layanan mereka, kadang-kadang banyak (dalam istilah absolut; bukan nilai yang baik) Sitemap Harga yang tercantum di sini Brunei Sitemap Artikel (Juni 2015) akan turun.
Di masa lalu, harga lebih tinggi, tetapi file data dan jumlah permintaan lebih kecil.
Dalam masa depan, harga akan lebih rendah, tetapi file data dan jumlah permintaan akan lebih besar.
Jadi perubahan detail, tetapi situasi tetap relatif konstan.
Dan itu bukan layanan yang mahal, itu adalah bahwa kita menggunakan dan membeli banyak layanan.
- Transfer Data — Transfer data ke dalam sistem sekarang gratis (Login) Sitemap Transfer data dari sistem adalah $ 0.09/GB. Satu hard drive SATA (0.3 g) di satu server dengan satu ERDDAP™ bisa mungkin jenuh Gigabit Ethernet LAN (0.1 g) Sitemap Satu Gigabit Ethernet LAN (0.1 g) mungkin dapat menjenuhkan koneksi Internet OC-12 (0.06GB/s) Sitemap Jika satu koneksi OC-12 dapat mentransmisikan ~ 150,000 GB / bulan, biaya Transfer Data bisa sebanyak 150.000 GB @ $ 0,09 / GB = $ 13,500 / bulan, yang merupakan biaya yang signifikan. Jelas, jika Anda memiliki lusin kerja keras ERDDAP s pada layanan cloud, biaya Transfer Data bulanan Anda bisa menjadi substansial (hingga $ 162.000 / bulan) Sitemap (Sekali lagi, itu bukan layanan yang mahal, itu adalah bahwa kita menggunakan dan membeli banyak layanan.)
- Penyimpanan data — Amazon dikenakan $ 50 / bulan per TB. (Bandingkan bahwa untuk membeli perusahaan 4TB yang tepat untuk ~ $ 50 / TB, meskipun RAID untuk menempatkannya dalam dan biaya administrasi menambah total biaya.) Jadi jika Anda perlu menyimpan banyak data di cloud, mungkin cukup mahal (e.g., 100TB akan dikenakan biaya $ 5000 / bulan) Sitemap Tetapi kecuali jika Anda memiliki sejumlah besar data, ini adalah masalah yang lebih kecil daripada biaya transfer bandwidth / data. (Sekali lagi, itu bukan layanan yang mahal, itu adalah bahwa kita menggunakan dan membeli banyak layanan.)
Login
- Masalah subsetting: Satu-satunya cara untuk mendistribusikan data secara efisien dari file data adalah untuk memiliki program yang mendistribusikan data (Login ERDDAP ) menjalankan server yang memiliki data yang disimpan di hard drive lokal (atau akses yang mirip dengan SAN atau RAID lokal) Sitemap Sistem file lokal memungkinkan ERDDAP™ (dan pustaka bawah, seperti netcdf-java) untuk meminta rentang byte tertentu dari file dan mendapatkan tanggapan dengan sangat cepat. Banyak jenis permintaan data dari ERDDAP™ ke file (permintaan data yang tidak terisi di mana nilai stride adalah > 1 Artikel) tidak dapat dilakukan secara efisien jika program harus meminta seluruh file atau chunks besar file dari non-lokal (maka lebih lambat) sistem penyimpanan data dan kemudian ekstrak subset. Jika pengaturan cloud tidak memberikan ERDDAP™ akses cepat ke rentang byte file (secepat dengan file lokal) Login ERDDAP 's akses ke data akan menjadi bottleneck yang parah dan mengabaikan manfaat lain menggunakan layanan cloud.
Database
Alternatif untuk analisis manfaat biaya di atas (yang didasarkan pada pemilik data (Login NOAA ) membayar data mereka untuk disimpan di cloud) tiba di tahun 2012, ketika Amazon (dan sejauh yang lebih rendah, beberapa penyedia cloud lainnya) memulai hosting beberapa dataset di cloud mereka (AWS S3) gratis (asumsikan harapan bahwa mereka dapat memulihkan biaya mereka jika pengguna akan menyewa instance AWS EC2 untuk bekerja dengan data tersebut) Sitemap Jelas, ini membuat komputasi awan jauh lebih hemat biaya, karena waktu dan biaya meng-upload data dan hosting sekarang nol. Sitemap ERDDAP™ v2.0, ada fitur baru untuk memfasilitasi berjalan ERDDAP di cloud:
- Sitemap EDDGrid Dari Files atau EDDTableDariFiles dataset dapat dibuat dari file data yang jarak jauh dan dapat diakses melalui internet (e.g., ember AWS S3) dengan menggunakan<cacheDariUrl & gt; dan<Login GB & gt; pilihan. ERDDAP™ akan mempertahankan cache lokal dari file data yang paling baru-baru ini digunakan.
- Sekarang, jika file sumber EDDTableDariFiles dikompresi (Login .tgz ) Login ERDDAP™ akan secara otomatis menekan mereka ketika membaca mereka. Meme it
- Sekarang, ERDDAP™ thread menanggapi permintaan yang diberikan akan memijat benang pekerja untuk bekerja pada bagian permintaan jika Anda menggunakan<nThreads> pilihan. paralelisasi ini harus memungkinkan respons yang lebih cepat untuk permintaan yang sulit.
Perubahan ini memecahkan masalah AWS S3 tidak menawarkan penyimpanan file tingkat lokal dan (Login) masalah akses ke data S3 memiliki lag yang signifikan. (Tahun yang lalu (Login) , itu lag signifikan, tetapi sekarang jauh lebih pendek dan tidak begitu signifikan.) Semua dalam semua, itu berarti bahwa mengatur Meme it ERDDAP™ di cloud bekerja lebih baik sekarang. Meme it
Sitemap — Banyak berkat Matthew Arrott dan kelompoknya dalam upaya OOI asli untuk pekerjaan mereka ERDDAP™ di cloud dan diskusi yang dihasilkan.
- Sitemap
Replikasi Jarak Jauh Dataset
Ada masalah umum yang terkait dengan diskusi grid dan federasi di atas ERDDAP s: replikasi jarak jauh dataset. Masalah dasar adalah: penyedia data mempertahankan dataset yang berubah sesekali dan pengguna ingin mempertahankan salinan lokal terbaru dari dataset ini (untuk berbagai alasan) Sitemap Jelas, ada sejumlah besar variasi ini. Beberapa variasi jauh lebih sulit untuk berurusan dengan orang lain.
- Update Cepat Lebih sulit untuk menjaga dataset lokal hingga saat ini Sitemap (g., dalam 3 detik) setelah setiap perubahan pada sumber, daripada, misalnya, dalam beberapa jam.
- Perubahan Sering Perubahan yang sering lebih sulit untuk berurusan dengan perubahan yang sering terjadi. Sebagai contoh, perubahan sekali hari jauh lebih mudah untuk berurusan dengan perubahan setiap 0,1 detik.
- Perubahan kecil Perubahan kecil ke file sumber lebih sulit untuk berurusan dengan dari file yang sama sekali baru. Ini terutama berlaku jika perubahan kecil mungkin di mana saja di file. Perubahan kecil lebih sulit untuk mendeteksi dan membuatnya sulit untuk mengisolasi data yang perlu direplikasi. File baru mudah untuk mendeteksi dan efisien untuk mentransfer.
- Database Menyimpan seluruh dataset up-to-date lebih sulit daripada menjaga hanya data terbaru. Beberapa pengguna hanya perlu data terbaru (misalnya, 8 hari terakhir bernilai) Sitemap
- Beberapa Copies Mempertahankan beberapa salinan jarak jauh di situs yang berbeda lebih sulit daripada mempertahankan satu salinan jarak jauh. Ini adalah masalah scaling.
Ada sejumlah besar variasi dari kemungkinan jenis perubahan pada dataset sumber dan kebutuhan pengguna dan harapan. Banyak variasi sangat sulit untuk memecahkan. Solusi terbaik untuk satu situasi sering bukan solusi terbaik untuk situasi lain - belum ada solusi hebat universal.
Login ERDDAP™ Login
ERDDAP™ menawarkan beberapa alat yang dapat digunakan sebagai bagian dari sistem yang mencari untuk mempertahankan salinan dataset jarak jauh:
- ERDDAP Sitemap RSS (Ringkasan Situs yang kaya?) Sitemap
menawarkan cara cepat untuk memeriksa apakah dataset di remote ERDDAP™ telah berubah. - ERDDAP Sitemap Layanan berlangganan
lebih efisien (Sitemap RSS ) pendekatan: segera akan mengirim email atau menghubungi URL ke setiap pelanggan kapan pun dataset diperbarui dan pembaruan yang dihasilkan dalam perubahan. Ini efisien dalam hal itu terjadi ASAP dan tidak ada upaya yang terbuang (sebagai dengan mencemari RSS Sitemap) Sitemap Pengguna dapat menggunakan alat lain (Login Login ) untuk bereaksi terhadap pemberitahuan email dari sistem berlangganan. Misalnya, pengguna bisa berlangganan dataset di remote ERDDAP™ dan gunakan IFTTT untuk bereaksi terhadap pemberitahuan email berlangganan dan memicu memperbarui dataset lokal. - ERDDAP Sitemap sistem bendera
menyediakan cara untuk ERDDAP™ administrator untuk memberitahukan dataset pada nya/her ERDDAP untuk memuat ulang ASAP. Bentuk URL dari bendera dapat dengan mudah digunakan dalam script. Bentuk URL dari bendera juga dapat digunakan sebagai tindakan berlangganan. - ERDDAP Sitemap "files" sistem
dapat menawarkan akses ke file sumber untuk dataset tertentu, termasuk daftar direktori gaya Apache dari file ("Web Accessible Folder") yang memiliki setiap URL unduhan file, waktu modifikasi terakhir, dan ukuran. Salah satu sisi menggunakan "files" sistem adalah bahwa file sumber mungkin memiliki nama variabel yang berbeda dan metadata yang berbeda dari dataset seperti yang muncul di ERDDAP Sitemap Jika jarak jauh ERDDAP™ dataset menawarkan akses ke file sumbernya, yang membuka kemungkinan versi rsync yang buruk: menjadi mudah untuk sistem lokal untuk melihat file jarak jauh yang telah berubah dan perlu didownload. (Sitemap cacheDariUrl pilihan di bawah ini yang dapat menggunakan ini.)
Sitemap
Meskipun ada sejumlah variasi untuk masalah dan sejumlah solusi yang tak terbatas, hanya ada pendekatan dasar untuk solusi:
Solusi Brute Force
Solusi yang jelas adalah untuk kerajinan solusi kustom, yang oleh karena itu dioptimalkan untuk situasi tertentu: membuat sistem yang mendeteksi / mengidentifikasi data mana yang telah berubah, dan mengirim informasi kepada pengguna sehingga pengguna dapat meminta data yang berubah. Nah, Anda dapat melakukan ini, tetapi ada kerugian:
- Solusi kustom adalah banyak pekerjaan.
- Solusi kustom biasanya sangat disesuaikan dengan dataset yang diberikan dan diberikan sistem pengguna yang tidak mudah digunakan kembali.
- Solusi kustom harus dibangun dan dipelihara oleh Anda. (Itu tidak pernah ide yang baik. Meme it Ini selalu ide yang baik untuk menghindari pekerjaan dan mendapatkan orang lain untuk melakukan pekerjaan!)
Saya berdiskusi mengambil pendekatan ini karena hampir selalu lebih baik untuk mencari solusi umum, dibangun dan dipelihara oleh orang lain, yang dapat dengan mudah digunakan dalam situasi yang berbeda.
Login
Login adalah solusi tujuan umum yang ada dan menakjubkan untuk menjaga pengumpulan file pada komputer sumber dalam sinkronisasi pada komputer remote pengguna. Cara kerjanya adalah:
- beberapa acara (Sitemap ERDDAP™ event sistem berlangganan) memicu berjalan rsync, (atau, pekerjaan tanaman berjalan rsync pada waktu tertentu sehari-hari di komputer pengguna)
- yang menghubungi rsync pada komputer sumber,
- yang menghitung serangkaian hashes untuk chunks setiap file dan mengirimkan hashes ke rsync pengguna,
- yang membandingkan informasi tersebut dengan informasi serupa untuk salinan file pengguna,
- yang kemudian meminta chunks file yang telah berubah.
Pertimbangkan semua yang dilakukan, rsync beroperasi dengan sangat cepat (e.g., 10 detik ditambah waktu transfer data) dan sangat efisien. Sitemap variasi rsync yang mengoptimalkan situasi yang berbeda (e.g., dengan precalculating dan caching hashes dari chunks dari setiap file sumber) Sitemap
kelemahan utama rsync adalah: dibutuhkan beberapa upaya untuk mengatur (masalah keamanan) ; ada beberapa masalah scaling; dan tidak baik untuk menjaga dataset NRT benar-benar up-to-date (e.g.) Sitemap Jika Anda dapat berurusan dengan kelemahan, atau jika mereka tidak mempengaruhi situasi Anda, rsync adalah solusi tujuan umum yang dapat digunakan oleh siapa pun sekarang untuk memecahkan banyak skenario yang melibatkan replikasi dataset jarak jauh.
Ada item di Meme it ERDDAP™ Untuk Melakukan daftar untuk mencoba untuk menambahkan dukungan untuk layanan sinkronisasi untuk ERDDAP (mungkin tugas yang cukup sulit) , sehingga setiap klien dapat menggunakan rsync (atau varian) untuk mempertahankan salinan up-to-date dari dataset. Jika ada yang ingin bekerja pada ini, silakan email erd.data at noaa.gov Sitemap
Ada program lain yang melakukan lebih atau kurang apa yang disinkronkan, kadang-kadang berorientasi pada replikasi dataset (meskipun sering pada tingkat salinan file) Sitemap Unidata Sitemap Login Sitemap
Cache Dari url
CacheDariUrl pengaturan tersedia (Sitemap ERDDAP™ g) untuk semua ERDDAP Jenis dataset yang membuat dataset dari file (pada dasarnya, semua kelas EDDGrid Login Login Login ) Sitemap Login DariUrl membuatnya sepele untuk secara otomatis mengunduh dan memelihara file data lokal dengan menyalinnya dari sumber jarak jauh melalui cache Dari pengaturanUrl. File jarak jauh dapat berada di Web Accessible Folder atau daftar file seperti direktori yang ditawarkan oleh THREDDS, Hyrax ember S3, atau ERDDAP Sitemap "files" sistem.
Jika sumber file jarak jauh adalah remote ERDDAP™ dataset yang menawarkan file sumber melalui ERDDAP™ "files" sistem, maka Anda bisa Login ke dataset jarak jauh, dan gunakan URL untuk dataset lokal Anda sebagai tindakan berlangganan. Kemudian, setiap kali perubahan dataset jarak jauh, itu akan menghubungi URL bendera untuk dataset Anda, yang akan memberitahunya untuk memuat ulang ASAP, yang akan mendeteksi dan mengunduh file data jarak jauh yang berubah. Semua ini terjadi sangat cepat (biasanya ~ 5 detik ditambah waktu yang diperlukan untuk mengunduh file yang berubah) Sitemap Pendekatan ini bekerja besar jika perubahan dataset sumber adalah file baru secara berkala ditambahkan dan ketika file yang ada tidak pernah berubah. Pendekatan ini tidak bekerja dengan baik jika data sering ditujui untuk semua (atau paling) dari file data sumber yang ada, karena dataset lokal Anda sering mengunduh seluruh dataset jarak jauh. (Di sinilah pendekatan yang mirip dengan rsync diperlukan.)
Login
ERDDAP™ Sitemap Login adalah solusi yang baik ketika data ditambahkan ke dataset sering, tetapi data yang lebih tua tidak pernah berubah. Pada dasarnya, sebuah ERDDAP™ Administrator dapat menjalankan ArsipADataset (mungkin dalam skrip, mungkin dijalankan oleh tanaman) dan menentukan subset dataset yang ingin mereka ekstrak (mungkin dalam beberapa file) dan paket dalam .zip Sitemap .tgz file, sehingga Anda dapat mengirim file untuk menarik orang atau kelompok (e.g.) atau membuatnya tersedia untuk mengunduh. Sebagai contoh, Anda bisa menjalankan ArsipADataset setiap hari di 12:10 am dan memilikinya .zip dari semua data dari 12:00 pada hari sebelumnya sampai 12:00 pagi hari ini. (Atau, lakukan mingguan ini, bulanan, atau tahunan, sesuai kebutuhan.) Karena file yang dikemas dihasilkan secara offline, tidak ada bahaya waktu atau terlalu banyak data, karena akan ada standar ERDDAP™ Sitemap
ERDDAP™ Sistem permintaan standar 's
ERDDAP™ Sistem permintaan standar adalah solusi yang baik alternatif ketika data ditambahkan ke dataset sering, tetapi data yang lebih tua tidak pernah berubah. Pada dasarnya, siapa pun dapat menggunakan permintaan standar untuk mendapatkan data untuk rentang waktu tertentu. Sebagai contoh, pada 12:10 sehari-hari, Anda dapat mengajukan permintaan untuk semua data dari data jarak jauh dari 12:00 pada hari sebelumnya sampai 12:00 pagi hari ini. Batasan (dibandingkan dengan pendekatan ArsipADataset) adalah risiko waktu atau ada terlalu banyak data untuk satu file. Anda dapat menghindari pembatasan dengan membuat permintaan yang lebih sering untuk periode waktu yang lebih kecil.
Login
\[ Pilihan ini tidak ada, tetapi tampaknya mungkin untuk membangun di masa depan dekat. \]
Login Login Jenis dataset dalam ERDDAP™ v2.0 memungkinkan untuk membayangkan solusi lain. File yang mendasari dipertahankan oleh jenis dataset ini pada dasarnya adalah file log yang mencatat perubahan dataset. Harus dimungkinkan untuk membangun sistem yang mempertahankan dataset lokal secara berkala (atau berdasarkan pemicu) meminta semua perubahan yang telah dilakukan pada dataset jarak jauh karena permintaan terakhir. Itu harus seefisien (Sitemap) daripada rsync dan akan menangani banyak skenario sulit, tetapi hanya akan bekerja jika dataset jarak jauh dan lokal adalah dataset EDDTableDariHttpGet.
Jika ada yang ingin bekerja pada ini, silakan hubungi erd.data at noaa.gov Sitemap
Database
Tidak ada solusi di atas melakukan pekerjaan yang bagus untuk memecahkan variasi sulit dari masalah karena replikasi dekat waktu nyata (Login) dataset sangat keras, sebagian karena semua skenario yang mungkin.
Ada solusi yang bagus: bahkan tidak mencoba untuk meniru data. Sebagai gantinya, gunakan satu sumber otoritatif (satu dataset pada satu ERDDAP ) , dipelihara oleh penyedia data (e.g., kantor regional) Sitemap Semua pengguna yang ingin data dari dataset selalu mendapatkannya dari sumber. Misalnya, aplikasi berbasis browser mendapatkan data dari permintaan berbasis URL, sehingga tidak perlu masalah bahwa permintaan adalah sumber asli pada server jarak jauh (bukan server yang sama yang hosting ESM) Sitemap Banyak orang telah menganjurkan pendekatan Data Terdistribusi ini untuk waktu yang lama (e.g., Roy Mendelssohn untuk 20+ tahun terakhir) Sitemap ERDDAP 's grid / model federasi (80% atas dokumen ini) didasarkan pada pendekatan ini. Solusi ini seperti pedang untuk Gordian Knot — seluruh masalah hilang.
- Solusi ini sangat sederhana.
- Solusi ini sangat efisien karena tidak ada pekerjaan yang dilakukan untuk menjaga dataset yang direplikasi (Login) Sitemap
- Pengguna bisa mendapatkan data terbaru kapan saja (e.g., dengan latensi hanya ~ 0,5 detik) Sitemap
- Skalanya cukup baik dan ada cara untuk meningkatkan skala. (Lihat diskusi di 80% atas dokumen ini.)
Tidak, ini bukan solusi untuk semua situasi yang mungkin, tetapi merupakan solusi yang bagus untuk sebagian besar. Jika ada masalah/kemahan dengan solusi ini dalam situasi tertentu, seringkali layak bekerja untuk memecahkan masalah atau hidup dengan kelemahan karena keunggulan menakjubkan dari solusi ini. Jika / ketika solusi ini benar-benar tidak dapat diterima untuk situasi tertentu, misalnya, ketika Anda benar-benar harus memiliki salinan lokal data, kemudian mempertimbangkan solusi lain yang dibahas di atas.
Login
Meskipun tidak ada solusi sederhana, yang sempurna memecahkan semua masalah dalam semua skenario (sebagai sinkronisasi dan Data Terdistribusi hampir) Semoga ada alat dan pilihan yang cukup sehingga Anda dapat menemukan solusi yang dapat diterima untuk situasi tertentu Anda.