NCCSV - 国家妇女研究中心
页:1NetCDF- 兼容的 ASCII CSV 文件规格, 第1.10号版本
鲍勃·西蒙斯和史蒂夫·汉金 鲍勃·西蒙斯的"NCCSV"和史蒂夫·汉金的执照CC BY 4.0 (英语).
导言
此文档指定 ASCII CSV 文本文件格式, 其中可以包含全部信息 (元数据和数据) 可见于NetCDF .nc包含类似 CSV 文件的数据表格的文件。 遵循此规格的 ASCII CSV 文本文件的文件扩展名必须是 .csv , 这样它就可以轻松和正确地读入Excel 和 Google 工作表等电子表格程序. Bob Simons将编写软件,将 NCCSV 文件转换为NetCDF- 3号 (也许还有NetCDF-4号) .nc文档,反之,不丢失信息。 鲍勃・西蒙斯已经修改了ERDDAP™支持读写此类型文件。
NCCSV格式的设计使得Excel和Google Sheets等电子表格软件能够将NCCSV文件导入为csv文件,电子表格单元格中的所有信息都准备好进行编辑. 或者,可以在NCCSV公约之后从零开始创建电子表格. 无论电子表格的来源如何,如果它随后作为.csv文件导出,它将符合NCCSV的规格,不会丢失任何信息。 NCCSV文件与遵循这些惯例的类似电子表格文件之间唯一的区别是:
- NCCSV文件在以逗号分隔的行上有值. 电子表格在相邻单元格的一行中有值。
- NCCSV文件中的字符串经常被双引号包围. 电子表格中的字符串从未被双引号包围 。
- 内部双引号 (" , ") 在NCCSV文件中的字符串中,以2个双引号出现。 电子表格中的内部双引号为1双引号.
见电子表格详情见下文。
可流性
像一般的CSV文件一样,NCCSV文件是可流的. 因此,如果NCSV由数据服务器在飞行中生成,例如:ERDDAP™,服务器可以在全部数据采集到之前开始将数据流到请求者. 这是一个有益和可取的特点。NetCDF相对地,文件是不可流的。
ERDDAP™
这个规格的设计是为了让 NCCSV 文件及.nc从它们可以创建的文件可以被一个ERDDAP™数据服务器 (通过来自 Nccsv 文件的 EDD 表格和来自 NcFiles 的 EDD 表格数据集类型) ,但此规格是外部ERDDAP。 。 。 。ERDDAP™具有若干必要的全球属性和许多推荐的全球性和可变属性,大多基于CF和ACDD属性(见 /docs/server-admin/数据集#全球属性) (中文(简体) ).
余额
NCCSV格式的设计是几项要求的平衡:
- 文件必须包含表格中的所有数据和元数据NetCDF文件,包括具体的数据类型。
- 文件必须能够读入并写出电子表格,而不丢失信息。
- 文件必须便于人类创建,编辑,阅读和理解.
- 文件必须能够由计算机程序清晰地解析.
如果本文件中的某些要求似乎奇怪或挑剔,可能需要满足其中的一项要求。
其他规格
这个规格是指它设计用来配合的几个其他规格和库,但是这个规格不是其他规格的一部分,也不需要修改,也不与它们冲突. 如果此处没有具体说明与这些标准之一有关的细节,请参见相关规格。 特别是,这包括:
- 数据集发现属性公约 (APDD) 元数据标准 : https://wiki.esipfed.org/Attribute\_Convention\_for\_Data\_Discovery\_1-3 。 。 。 。
- 气候与预测 (CF 数字) 元数据标准 : https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html 。 。 。 。
- 那个NetCDF用户指南 (努格语) 数字 : https:///docs.unidata.ucar.edu/netcdf-java/current/userguide/index.html 。 。 。 。
- 那个NetCDF软件库NetCDF-贾瓦和NetCDF-c: (英语). https://www.unidata.ucar.edu/software/netcdf/ 。 。 。 这些库不能读取 NCCSV 文件, 但可以读取.nc从 NCCSV 文件创建的文件。
- 乔森: https://www.json.org/
标记
在这一规格中,括号中,\[ \],表示可选项目。
文件结构
一个完整的NCCSV文件包含两个部分:元数据部分,然后是数据部分.
NCCSV文件只必须包含7位的ASCII字符. 因此,用于写入和读取文件的字符集或编码可能是任何与7位的ASCII字符集兼容的字符集或编码,例如ISO-8859-1.ERDDAP™用 ISO-8859-1 字符集读写 NCCSV 文件。
NCCSV 文件可能使用新线 (\n) (这在 Linux 和 Mac OS X 计算机上很常见) 或车厢 返回加新线 (\r\n) (这在 Windows 计算机上很常见) 作为终点标记,但不是两者兼有。
.nccsv元数据
当创建者和读者都期待它时,对仅包含元数据的NCCSV文件做一个变体也是可能的,有时也是有用的. (包括项目\*厄立特里亚\*线条) 。 。 。 结果是完整描述文件的属性,可变名称,和数据类型,因此与.das加.dds的响应具有相同的目的.das.OPeNDAP服务器。ERDDAP™如果您请求文件, 将返回此变量 类型=.nccsv元数据来源于 aERDDAP™数据集。
元数据科
在NCCSV文件中,元数据段的每行使用格式
变量 名称, (中文).属性 名称, (中文).数值1\[值2\]\[值3\]\[值 4\]\[. . ....\]
不允许在项目之前或之后设置空格,因为它们在将文件导入电子表格程序时造成问题。
公约
NCCSV文件的第一行是元数据的第一行,必须有一个\全球\公约将列出文件中用作字符串的所有公约,其中包含CSV列表,例如: \*全球\*公约,"COARDS页:1 所列公约之一必须是NCCSV-1.1,它指的是这一规格的现有版本。
END_气象卫星
NCCSV 文件的元数据部分的结尾必须用只包含 \厄立特里亚\
建议但不要求某一变量的所有属性出现在元数据部分的相邻线上。 如果将 NCCSV 文件转换为NetCDF文件,变量名称在元数据部分中首次出现的顺序将是变量在NetCDF文档。
元数据区间允许在所要求的第一行之后使用可选的空白行\全球\ 公约资料 (见下文) ,在所需的最后一行与\厄立特里亚\。 。 。 。
如果从NCCSV文件中创建电子表格,则元数据部分将会出现A栏的变量名称,B栏的属性名称,C栏的值.
如果这些常规之后的电子表格被保存为 CSV 文件,那么元数据部分的行尾往往会有额外的逗号. 将 NCCSV 文件转换为.nc文件会忽略额外的逗号 。
变量 名称
变量 名称 是数据文件中变量的大小写名称。 所有可变名称都必须从一个7位的ASCII字母或下划线开始,并由7位的ASCII字母,下划线,和7位的ASCII数字组成.
全球
特殊变量Name\全球\用于表示全球元数据。
属性 名称
属性 名称 是一个变量或\全球\。 。 。 ��所有属性名称都必须从一个7位的ASCII字母或下划线开始,并由7位的ASCII字母,下划线,和7位的ASCII数字组成.
索马里
特殊属性 名称\*索马里\*可用于创建scalar数据变量并定义其值. 数据类型\*索马里\*定义变量的数据类型,所以不指定\*数据类型\*参数。 注意NCCSV文件中的数据部分中一定没有关于scalar变量的数据.
例如,要创建一个名为"船"的Scalar变量,其值为"Okeanos Explorer"和cf\_role属性,使用: 飞船,\索马里\"奥基亚诺斯探险家" 飞船,cf\_role,弹射\_id 当一个刻度数据变量读入ERDDAP™中,将标定值转换成数据表中每行数值相同的一列。
价值
价值 是元数据属性的值,必须是一个数组,其中一个或多个字节、ubyte、short、ushort、int、uint、Long、ulong、fload、nople、String或char。 不支持其他数据类型。 无值属性将被忽略 。 如果有多个子值,则子值必须全部为同一个数据类型,并以逗号分隔,例如: sst, (中文).actual\_range.0.17f,23.58f (单位:千美元) 如果有多个字符串值,请使用一个字符串\n (新线) 字符分隔子字符串。
属性数据类型的定义是:
字节
- 字节属性值 (8 位, 已签名) 必须使用后缀“b”来写,例如,-7b、0b、7b。 有效字节值的范围为 -128 到 127. 看起来像字节但无效的数字 (例如,128b) 将转换为缺失值或�生成错误消息。
字节
- ubyte 属性值 (8 位, 未签名) 必须用后缀“ub”来写,例如:0ub、7ub、250ub。 有效字节值的范围为0至255. 一个看起来像字节但无效的数字 (例如,256ub) 将转换为缺失值或生成错误消息。 可能时使用字节而不是ubyte, 因为许多系统不支持未签名的字节 (例如,属性NetCDF-3个文件) 。 。 。 。
简称
- 短属性值 (16 位, 已签名) 必须用后缀's'来写,例如 -30000s, 0s, 30000s. 有效短值的范围为-32768至32767. 一个看起来很短但无效的数字 (例如,32768个) 将转换为缺失值或生成错误消息。
超时速
- ushort 属性值 (16 位, 未签名) 必须用后缀“us”来写,例如,0us、30000us、60000us。 有效短值的范围为0-65535. 一个看起来像我们迷路但无效的数字 (例如,第65536条) 将转换为缺失值或生成错误消息。 如果可能的话, 请使用简短的字节来代替我们, 因为许多系统不支持未签名的字节 (例如,属性NetCDF-3个文件) 。 。 。 。
单位
- int 属性值 (32 位, 已签名) 必须写成JSON ints,没有小数点或缩写,但带有后缀'i',例如 -120679785i, 0i,120679778i. 有效英寸值的范围为-2147483648至2147483647. 一个看起��来像点但无效的数字 (例如,2147483648i) 将转换为缺失值或生成错误消息。
宾特
- uint 属性值 (32 位, 未签名) 必须写成JSON ints,没有小数点或缩写,但带有后缀"ui",例如:0ui,12067978ui,4123456789ui. 有效英寸值的范围为0至4294967295. 一个看起来像金特但无效的数字 (例如,2147483648ui) 将转换为缺失值或生成错误消息。 可能时使用 int 而不是 uint , 因为许多系统不支持未签名的字节 (例如,属性NetCDF-3个文件) 。 。 。 。
长
- 长属性值 (64位,签名,目前由NUG和ERDDAP™但尚未获得 CF 支持) 必须在没有小数点的情况下写出,并带有后缀“L”,例如: -12345678987654321L, 0L, 12345678987654321L。 如果使用转换软件将长值的 NCCSV 文件转换为NetCDF-3文件,任何长的值都会转换成双倍值. 有效长值范围为-922337203685475808至922337203685475807. 一个看起来长但无效的号码 (例如,922337203685475808 L) 将转换为缺失值或生成错误消息。 如果可能,使用双倍而不是乌龙,因为许多系统不支持长 (例如,NetCDF-3个文件) 。 。 。 。
乌龙
- 乌龙属性值 (64位,未签名,目前由NUG和ERDDAP™但尚未获得 CF 支持) 必须在无小数点的情况下写出,并带有后缀“uL”,例如,0uL,12345678987654321uL,9007199254740992uL。 如果使用转换软件将长值的 NCCSV 文件转换为NetCDF-3文件,任何长的值都会转换成双倍值. 有效长�值范围为0至1844644073709551615. 一个看起来像乌龙但无效的号码 (例如,184467447095516uL) 将转换为缺失值或生成错误消息。 在可能的情况下,使用双倍而不是乌龙,因为许多系统不支持签名或未签名长 (例如,NetCDF-3个文件) 。 。 。 。
浮动
- 浮点属性值 (32 位数) 必须使用后缀“f”来写,并可能有一个小数点和/或一个符号,例如,0f,1f,12.34f,1e12f,1.23e+12f,1.23e12f,1.87E-7f。 将NaNf用于浮动的NaN (缺少) 数值。 浮标范围约为+/-3.40282347E+38f. (~7 个小数) 。 。 。 看起来像浮点数但无效 (例如,1.0e39f) 将转换为缺失值或生成错误消息。
双
- 双属性值 (64 位数) 必须使用后缀“d”来写,并可能有一个小数点和/或一个缩写,例如,0d,1d,12.34d,1e12d,1.23e+12d,1.23e12d,1.87E-7d。 将 NaNd 用于双 NN (缺少) 数值。 双打范围约为+/-1.79769313486231570E+308d. (~15位小数) 。 。 。 一个看起来是双倍但无效的数字 (例如,1.0e309d) 将转换为缺失值或生成错误消息。
字符串
- 字符串属性值是 UCS-2 字符序列 (即2字节Unicode字符,如:Java) ,必须写成 7-bit ASCII, JSON 类似字符串,这样可以指定非 ASCII 字符。
- 双引号 (" , ") 必须编码为两个双引号 (""(")) 。 。 。 这就是电子表格程序在读取.csv文件时需要的. 当你将电子表格保存为.csv文件时,�电子表格程序就是这样写的.
- 特殊 JSON 反斜码字符必须像 JSON 一样编码( 特别是)\n(新线),但也有(背斜),\f(形式fed),\t(tab),\r(返回)或与\u 嘘 语法. 在电子表格中,不要使用 Alt Enter 在文本单元格中指定新行;而是使用\n (2个字符:反斜和n ') 以表示新行。
uhhhh
- \u hhh - 所有字符均小于字符 #32 或大于字符 #126, 而非以其他方式编码, 必须用语法\\u 编码 hhh*,其中hhh是字符的4位十六进制数字,例如,欧元符号为\u20AC. 参见引用于 https://en.wikipedia.org/wiki/Unicode 查找与特定 Unicode 字符相关的十六进制数字,或使用软件库。
- 如果字符串在开头或结尾有空格,或包括 " (双引号) 或 逗号,或含有否则会被解释为其他数据类型的数值 (例如,一个整数) ,或者是"null"一词,整个字符串必须用双引号封装;否则,与JSON不同的是,附件的双引号是可选的. 我们建议:当怀疑时,请将整条弦用双引号附上。 字符串开头或结尾的空格被强烈抑制.
- 目前不鼓励使用大于255的字符. NCCSV支持它们.ERDDAP™在内部支持它们。 一些输出文件类型支持它们 (例如,.json和.nccsv) 。 。 。 但许多输出文件类型并不支持它们. 举例来说,NetCDF-3文件不支持这样的字符,因为NetCDF文件使用 1字节字符, CF 目前没有指定 Unicode 字符如何编码的系统NetCDF字符串 (例如,UTF-8) 。 。 。 随着时间的推移,这种情况可能有所改善。
字符
- 字符属性值是一个单一的 UCS-2 字符 (即2字节Unicode字符,如:Java) ,必须写成 7 位 ASCII, JSON 类似字符,以便指定其他字符 (参见上面关于特殊字符编码的字符串定义,并添加一个引用的编码为\\ ') 。 。 。 字符属性值必须在单引号中附加 (内在引用) 双引号 (外引号) ,例如"'a'","''". (双引号字符) ,“\'” (单个引用字符) ,"'\t'" (标签) ,“'\u20AC'” (a 欧元字符) 。 。 。 这种使用单引和双引的系统既奇怪又繁琐,但它是用电子表格的方法区分字符串值和字符串的方法. 看起来像字符但无效的值会生成错误消息 。 与 Strings 一样,目前不鼓励使用大于 # 255 的字符 。
后缀
注意在 NCCSV 文件的属性部分中,所有数字属性值必须有一个后缀字母 (例如,“b”) 以识别数字数据类型 (例如,字节) 。 。 。 但在NCCSV文件的数据部分,数字数据值决不能有这些后缀字母 (长整数和长整数的“ L” 除外) - 数据类型由\*数据类型\*变量属性。
数据类型(_T)
每个非 数据类型斜线变量必须用\*数据类型\*属性,其值可以是字节、ubyte、short、ushort、int、uint、long、浮点、双重、字符串或字符 (大小写不敏感) 。 。 。 。 举例来说, qc\_flag, (法语).\*数据类型\*字节 警告:指定正确的\*数据类型\*是你的责任 指定错误的数据类型 (例如,当您指定浮点时输入) 将不会生成错误消�息,并可能导致信息丢失 (例如,浮点值将四舍五入为整数) 当 NCCSV 文件被读取时ERDDAP™或转换为aNetCDF文档。
失败字符
由于字符数据值在其他文件类型中没有得到广泛支持,因此不鼓励使用字符数据值. 字符值可能作为单个字符或字符串写入数据段 (特别是,如果你需要写一个特殊字符) 。 。 。 如果找到字符串,字符串的第一个字符将被用作字符的值. 0 长度字符串和缺失值将被转换为字符\ uFFFF 。 请注意:NetCDF文件只支持单个字节字符, 因此比字符 # 255 更大的字符会在写入时转换为“ ? ”NetCDF文档。 除非使用字符集属性为字符变量指定不同的字符集,否则将使用ISO-8859-1字符集.
长和未签名的失望
尽管有许多文件类型 (例如,NetCDF- 4号和Json号) 和ERDDAP™支持长且未签名 (ubyte, ushort, uint, ulong (乌比特语)) 值,目前在 NCCSV 文件中使用长和无符号值目前被劝阻,因为这些值目前没有 Excel、CF 和NetCDF-3个文件 如果您要在 NCCSV 文件内指定长值或未签名值 (或相应的Excel电子表格) ,您必须使用“L”的后缀,这样Excel就不会以较低的精度将数字视为浮动点数。 目前,如果将 NCCSV 文件转换为NetCDF- 3号.nc文件,长和乌龙数据值将被转换成双倍值,造成非常大值的精度损失 (长小于 -2^53,长小于 2^53 和乌龙) 。 。 。 。 内NetCDF- 3号.nc文件、 ubyte、 ushort 和 uint 变量以字节、 短节和 QQUUnsigne= true 元数据属性�显示。 内NetCDF- 3号.nc文件、 ubyte 、 ushort 和 uint 属性以字节、 短和 int 属性显示, 包含相应的两个属性的构成值 (例如,255ub作为 -1b 出现) 。 。 。 这显然是个麻烦,所以只要可能,就应该使用签名的数据类型,而不是未签名的数据类型.
CF、ACDD、以及ERDDAP™元数据
由于设想大多数NCCSV文件,或.nc从它们创建的文件,将被读入ERDDAP,强烈建议NCCSV文件包含需要或推荐的元数据属性.ERDDAP™(见 /docs/server-admin/数据集#全球属性) (中文(简体) ). 属性几乎都来自CF和ACDD元数据标准,有助于正确描述数据集 (谁,什么,何时,在哪里,为什么,如何) 给一个不知道数据集的人 尤其重要的是,几乎所有的数值变量都应有一个单位属性和一个单位属性。UDUNITS- 兼容价值,例如, sst单位,C级
将非来自CF或ACDD标准或来自ERDDAP。 。 。 。
数据科
结构
数据段第一行必须有一个对大小写敏感,逗号分隔的变量名称列表. 本列表中的所有变量必须在元数据部分描述,反之亦然 (除外\全球\属性和\索马里\变量) 。 。 。 。
第二行�通过数据段倒数第二行必须有一个逗号分隔的数值列表. 每行数据必须具有与逗号分隔的变量名称列表相同的数值. 不允许值之前或之后的空格,因为它们在将文件导入电子表格程序时造成问题. 本节中的每栏必须只包含\*数据类型\*为该变量指定\*数据类型\*该变量的属性。 与属性部分不同的是,数据部分的数值决不能有后缀字母来表示数据类型. 与属性部分不同的是,数据部分的字符值如果不需要用于混淆,可能会省略附件单引号 (因此,“、”和“\”必须引文如下:) 。 。 。 在 NCCSV 文件里可能存在这类数据行的任何编号, 但目前ERDDAP™只能读取最多可达20亿行的NCCSV文件. 一般来说,建议您将大型数据集分成多个NCCSV数据文件,每个数据文件不到100万行.
结束(_D)
数据部分的结尾必须用只有 \续)\
如果在 NCCSV 文件之后有额外内容\*续)\*中,当 NCCSV 文件转换为.nc文档。 因此,这种内容令人沮丧。
在这些惯例之后的电子表格中,可变名称和数据值将分多个栏目。 见下文实例。
缺少值
数字缺失值可被写入为一个数字missing\_value或该变量的 QQFillValue 属性。 例如,参见此数据行的第二个值: Bell M. Shimada, 99,123.4 贝尔·岛田先生 这是处理字节,ubyte,短,ushort,int,uint,长,和乌龙变量的缺失值的建议方法.
浮点值或双NaN值可写为NaN. 例如,参见此数据行的第二个值: Bell M. Shimada, NAN, 123.4 (美国英语).
字符串和数字缺失值可以用空字段表示。 例如,参见此数据行的第二个值: Bell M. Shimada, 第123.4段。
对于字节,ubyte,短, ushort, int, uint, 长, 和乌龙变量, NCCSV 转换器工具以及ERDDAP™将空字段转换为该数据类型的最大允许值 (例如, 127 字节) 。 。 。 如果你这样做,一定要增加一个missing\_value或 QQFillValue 属性用于该变量以识别该值,例如, 变量 名称 ,================================================== 对于浮点和双变量,一个空域会转换成NaN.
日期时间值
时间值 (包括没有时间组件的日期值) 可以在NCCSV文件中以数字或字符串表示。 给定的日期时变量可能只有字符串值或只有数值,而不是两者。 NCCSV 软件将把 String 日期转换为数字日期 创建时的时间值.nc文件 (按照CF的要求) 。 。 。 字符串日期 Time值的优点是容易被人类读取.
以数值表示的日期时间值必须有一个单位属性,指定 " 单位 自此以来 日期 时间 " 根据CF的要求和CF的规定UDUNITS例如, 时间,单位,自1970-01-01T00:00Z
以字符串值表示的日期时间值必须有一个字符串\*数据类型\*属性和一个指定日期的单位属性 时间模式Java日期时间格式类 ( https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html ) 。 。 。 。 举例来说, 时间,单位,yyyy-MM-dd'T'HH:mm:sZ (英语). 给定数据变量的所有日期时间值必须使用相同的格式。 在大多数情况下,您需要的单位属性日期时间模式将是其中一��种格式的变化:
- yyyy-MM-dd'T'HH:mm:s:s. (英语). SSSZ——即ISO 8601:2004 (英) 日期 时间格式. 您可能需要缩短版本, 例如,yyyy-MM-dd'T'HH:mm:sZ (英语). (唯一建议的格式) 或yyyy-MM-dd。 。 。 如果您正在更改日期时间值的格式, NCCSV 强烈建议您更改此格式 (可能缩短) 。 。 。 。 这是格式ERDDAP™将使用它写入 NCCSV 文件。
- yyyMMddHmms.SSS——ISO 8601:2004 日期的紧凑版本 时间格式. 您可能需要缩短版本, 例如 YyyMMdd 。
- 妇女/青年 H:mm:s(英语:s. SSS——它处理美国式的日期和日期Times如"3/23/2017 16:22:03.000". 您可能需要缩短版本, 例如 M/d/yyyy 。
- yyyDDH HmmsSS——一年加零加法日 (例如,001 = Jan 1, 365 = Dec 31 在非 Leap年;这有时被错误地称为Julian日期) 。 。 。 您可能需要缩短版本, 例如 YyyDDD 。
精确度
当软件库转换一个.nc文件输入 NCCSV 文件,全部日期 时间值将用 ISO 8601: 2004 写入字符串 (英) 日期 时间格式,如1970-01-01T00:00Z. 您可以用ERDDAP- 特定属性time\_precision。 。 。 。 见 /docs/server-admin/数据集#time\_precision。 。 。 。
时区
日期的默认时区 时间值是Zulu (或格林尼治标准时) 时区,没有节日时间。 如果一个日期 时间变量有不同时区的日期 时间值,您必须用ERDDAP- 特定属性time\_zone。 。 。 。 这是要求ERDDAP™(见 /docs/server-admin/数据集#time\_zone) (中文(简体) ).
度值
根据CF的要求,所有学位值 (例如,经度和纬度) 字符串必须指定为小数级的双倍值,而不是度数°min'sec”字符串,或者作为度数、分数、秒数的单独变量。 方向设计器N,S,E,和W不允许使用. 对西经和南纬使用负值。
副秘书长 特性类型
NCCSV 文件可能包含 CF Discrete 抽样几何 ( https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html#discrete-sampling-geometries ) 数据。 正是这些特性使这项工作得以进行:
- 按照CF的要求,NCCSV文件必须在元数据部分包含一行,以识别\全球\ featureType属性,例如, \全球\, (中文).featureType弹射器
- 用于ERDDAP™,NCCSV文件必须在元数据部分包含一行或数行识别cf\_role=...\_id变量,例如, 飞船,cf\_role,弹射\_id 这对于CF是可选的,但在NCCSV中是需要的.
- 用于ERDDAP™,NCCSV文件必须在元数据部分中包含一行或数行,确定哪些变量与每次时间序列、轨迹或配置文件相关联。ERDDAP™(见 /docs/server-admin/dataset#cdm\data\ 类型例如, \*全球\*飞船 或 \全球\,cdm 时间系列 ,可变,"station id,lat,lon"
文件样本
以下是一个样本文件,它显示了NCCSV文件的许多特性:
\\*GLOBAL\\*,Conventions,"COARDS, CF-1.6, ACDD-1.3, NCCSV-1.1"
\\*GLOBAL\\*,cdm\\_trajectory\\_variables,"ship"
\\*GLOBAL\\*,creator\\_email,erd.data@noaa.gov
\\*GLOBAL\\*,creator\\_name,Bob Simons
\\*GLOBAL\\*,creator\\_type,person
\\*GLOBAL\\*,creator\\_url,https://www.pfeg.noaa.gov
\\*GLOBAL\\*,featureType,trajectory
\\*GLOBAL\\*,infoUrl,https://erddap.github.io/docs/user/nccsv-1.10
\\*GLOBAL\\*,institution,"NOAA NMFS SWFSC ERD, NOAA PMEL"
\\*GLOBAL\\*,license,"""NCCSV Demonstration"" by Bob Simons and Steve Hankin is
licensed under CC BY 4.0, https://creativecommons.org/licenses/by/4.0/ ."
\\*GLOBAL\\*,keywords,"NOAA, sea, ship, sst, surface, temperature, trajectory"
\\*GLOBAL\\*,standard\\_name\\_vocabulary,CF Standard Name Table v55
\\*GLOBAL\\*,subsetVariables,"ship"
\\*GLOBAL\\*,summary,"This is a paragraph or two describing the dataset."
\\*GLOBAL\\*,title,"NCCSV Demonstration"
ship,\\*DATA\\_TYPE\\*,String
ship,cf\\_role,trajectory\\_id
time,\\*DATA\\_TYPE\\*,String
time,standard\\_name,time
time,units,"yyyy-MM-dd'T'HH:mm:ssZ"
lat,\\*DATA\\_TYPE\\*,double
lat,units,degrees\\_north
lon,\\*DATA\\_TYPE\\*,double
"lon","units","degrees\\_east"
status,\\*DATA\\_TYPE\\*,char
status,comment,"From http://some.url.gov/someProjectDocument , Table C"
testByte,\\*DATA\\_TYPE\\*,byte
testByte,units,1
testUByte,\\*DATA\\_TYPE\\*,ubyte
testUByte,units,1
testLong,\\*DATA\\_TYPE\\*,long
testLong,units,1
testULong,\\*DATA\\_TYPE\\*,ulong
testULong,units,1
sst,\\*DATA\\_TYPE\\*,float
sst,standard\\_name,sea\\_surface\\_temperature
sst,actual\\_range,0.17f,23.58f
sst,units,degree\\_C
sst,missing\\_value,99f
sst,testBytes,-128b,0b,127b
sst,testShorts,-32768s,0s,32767s
sst,testInts,-2147483648i,0i,2147483647i
sst,testLongs,-9223372036854775808L,0L,9223372036854775807L
sst,testFloats,-3.40282347e38f,0f,3.40282347E+38f
sst,testDoubles,-1.79769313486231570e308d,0d,1.79769313486231570E+308d
sst,testChars,"','","'""'","'\\u20AC'"
sst,testStrings," a~,\\n'z""\\u20AC"
sst,testUBytes,0ub,127ub,255ub
sst,testUInts,0ui,2147483647ui,4294967295ui
sst,testULongs,0uL,9223372036854775807uL,18446744073709551615uL
sst,testUShorts,0us,32767us,65535us
\\*END\\_METADATA\\*
ship,time,lat,lon,status,testByte,testUByte,testLong,testULong,sst
Bell M. Shimada,2017-03-23T00:45:00Z,28.0002,-130.2576,A,-128, 0,-9223372036854775808L,0uL,10.9
Bell M. Shimada,2017-03-23T01:45:00Z,28.0003,-130.3472,\\u20AC,0,127,-9007199254740992L,9223372036854775807uL,10.0
"Bell M. Shimada","2017-03-23T02:45:00Z",28.0001,-130.4305,"'\\t'",126,254,9223372036854775806L,18446744073709551614uL,99
"Bell M. Shimada",2017-03-23T12:45:00Z,27.9998,-131.5578,"'""'",127,255,9223372036854775807L,18446744073709551615uL,NaN
注释:
- 此样本文件包括许多困难案件 (例如,字符和长变量以及难度字符串值) 。 。 。 大多数NCCSV文件会简单得多.
- 这里的许可证线被分成两条线,但只是样本文件中的一条线.
- \u20AC是欧元字符的编码,\u00FC是ü的编码.
- 许多 例子中的字符串被双引号所包围,尽管它们不必是,例如,许多全局属性,包括标题,lon单位属性,以及数据的第3行. )
- 如果将测试Long变量的单位属性用双引号写成表示它是一��个字符串值,则会更清晰,更好. 但是,目前的代表权 (1, 不引用) 将正确解释为字符串,而不是整数,因为没有“i”后缀。
- 与其他数字数据类型不同,数据部分的长值有后缀 ('L'(我)) 表示其数字数据类型。 这样做是为了防止电子表格将数值解释为浮点数从而失去精度.
电子表格
在电子表格中,如NCCSV文件中:
- 写入指定 NCCSV 文件的数字属性值 (例如,带有后缀字母,例如“f”,以识别属性的数据类型) 。 。 。 。
- 在字符串中,将所有小于ASCII字符#32或大于字符#126的字符写成类似JSON的反斜字符 (例如,\n用于新行) 或作为十六进制 Unicode 字符号 (大小写不敏感) 语法\u 嘘 (例如,欧元标志的\u20AC) 。 。 。 。 使用\n (2个字符:反斜和n ') 以表示新行,而不是 Alt Enter 。
NCCSV文件与遵循这些惯例的类似电子表格之间的唯一区别是:
- NCCSV文件在以逗号分隔的行上有值. 电子表格在相邻单元格的一行中有值。
- NCCSV文件中的字符串经常被双引号包围. 电子表格中的字符串从未被双引号包围 。
- 内部双引号 (" , ") 在NCCSV文件中的字符串中,以2个双引号出现。 电子表格中的内部双引号为1双引号.
如果遵循这些惯例的电子表格被保存为 CSV 文件,很多行的结尾往往会有额外的逗号. 将 NCCSV 文件转换为.nc文件会忽略额外的逗号 。
外壳
要将 NCCSV 文件导入 Excel :
- 选择文件 : 打开。
- 将文件类型更改为文本文件 (\.prn; (中文(简体) ).\.txt; \*.csv) 。 。 。 。
- 搜索目录并点击 NCCSV .csv 文件 。
- 点击打开 。
要从 Excel 电子表格创建 NCCSV 文件 :
- 选择文件 : 另存为 。
- 将“保存”改为类型:改为 CSV (已定义的逗号) (翻译:) 。 。 。 。
- 针对兼容性警告,单击是。
- 由此产生的 .csv 文件除了 CSV 行之外,所有行的末尾都会有额外的逗号. 你可以忽略他们。
在Excel中,上面的NCCSV文件样本为:
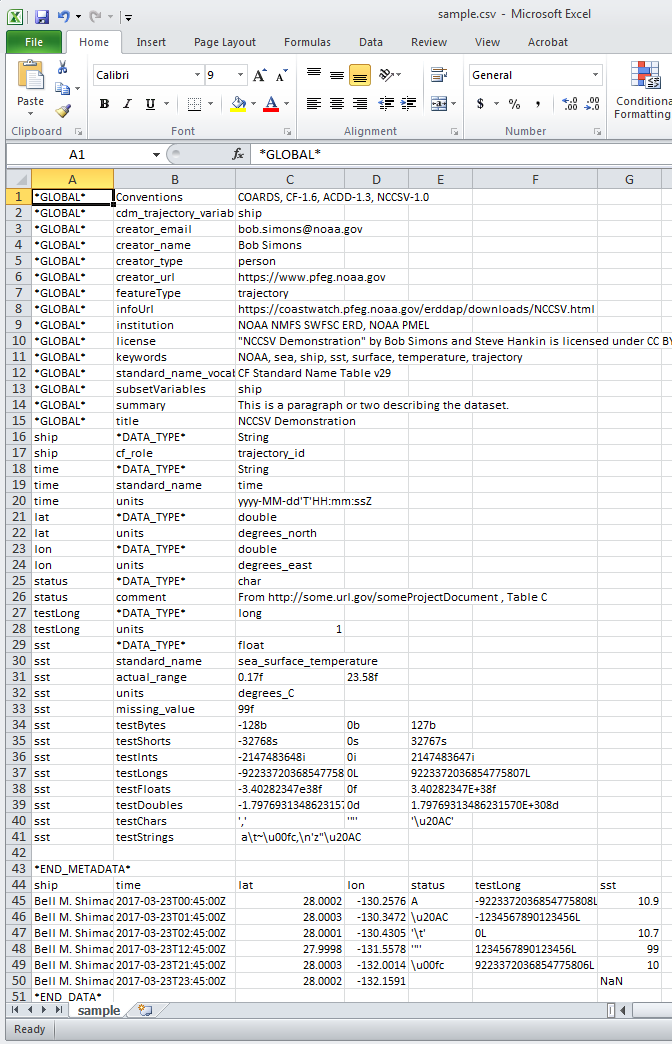
谷歌页
要导入 NCCSV 文件到 Google 工作表 :
- 选择文件 : 打开。
- 选择上传文件并单击上传计算机上的文件。 选择文件,然后单击打开。
或者,选择My Drive,然后将文件类型降为所有文件类型 。 选择文件,然后单击打开。
要从 Google 工作表电子表格创建 NCCSV 文件 :
- 选择文件 : 另存为 。
- 将“保存”改为类型:改为 CSV (已定义的逗号) (翻译:) 。 。 。 。
- 针对兼容性警告,单击是。
- 由此产生的 .csv 文件除了 CSV 行之外,所有行的末尾都会有额外的逗号. 别理他们
问题/警告
- 如果您用文本编辑器创建了 NCCSV 文件, 或者您在电子表格程序中创建了类似的电子表格, 文本编辑器或电子表格程序将不会检查您是否正确遵循了这些常规 。 你们应该正确遵守这些公约。
- 在此常规之后将电子表格转换为 csv 文件 (因此,一个 NCCSV 文件) 将在 CSV 数据行以外的所有行的末尾产生额外的逗号。 别理他们 软件然后将 NCCSV 文件转换为.nc文件会忽略它们。
- 如果一个 NCCSV 文件在行尾有多余的逗号, 您可以通过将 NCCSV 文件转换为NetCDF文件然后转换NetCDF文件返回到 NCCSV 文件。
- 当尝试将 NCCSV 文件转换为NetCDF文件,软件会发现一些错误并生成错误消息,导致转换失败. 其他问题很难或不可能抓住,不会产生错误消息或警告. 其他问题 (例如,行尾的多余逗号) 将被忽略。 文件转换器只会对结果的正确性做最小检查NetCDF例如,关于遵守《公约》的情况。 文件创建者和文件用户有责任检查转换结果是否如所期望和正确. 检查的两种方法是:
- 打印内容.nc带有 ncdump 的文件 ( https://linux.die.net/man/1/ncdump ) 。 。 。 。
- 查看数据内容ERDDAP。 。 。 。
变动
- 变动 v1.10中介绍 (2020年4月 (中文(简体) ).) 数字 :
- 增加了对ubyte,ushort,uint,ulong的支持.