NCCSV -
ANetCDF- 兼容的 ASCII CSV 檔案规格, 1.10版本
鮑勃·西蒙斯和史蒂夫·漢金 "NCCSV"由鮑勃·西蒙斯和史蒂夫·漢金授權依據創用CC授權使用
引言
此文件指定了 ASCII CSV 文字檔案格式, 可以包含所有資訊 (中繼資料與資料) 可以在NetCDF .nc包含類似 CSV 文件的資料表格的檔案。 ASCII CSV 文字檔案的延伸檔名必須是 . csv , 才能輕易地正确讀取到 Excel 和 Google 工作表 等电子表��格程序 。 Bob Simons會寫入軟體, 將 NCCSV 檔案轉換成NetCDF-3 (也可能是NetCDF-4) .nc檔案,反之亦然。 鮑勃·西蒙斯修改了ERDDAP™以支援讀取與寫入此檔案。
NCCSV格式的設計使得Excel和Google Sheets等电子表格軟體可以將NCCSV檔案匯入為csv檔案,所有資訊都在电子表格的儲存格中可以進行編輯. 或者, 可以在 NCCSV 常规之後從零開始建立工作表 。 不管电子表格的來源如何, 如果它被匯出為 . csv 檔案, 它會符合 NCCSV 的规格, 不會丟失任何資訊 。 NCCSV 檔案和遵循這些約定的相似的电子表格檔的唯一不同是:
- NCCSV 檔案在以逗號分隔的行上有值 。 電子表格在相邻单元格的行上有值 。
- NCCSV 檔案中的字串常被雙引號包圍 。 工作表中的字串從來不用雙引號包圍 。
- 內部雙引號 (") 在 NCCSV 檔案中的字串中, 以 2 雙引號顯示 。 內部雙引數在电子表格中以 1 雙引數出現 。
看电子表格更多信息。
可流性
和一般的 CSV 文件一樣, NCCSV 文件是可流的 。 因此,如果NCSV是由數據伺服器如:ERDDAP™,伺服器可以在所有資料被收集之前開始將資料流到要求者。 這是有益和可取的特征。NetCDF相形之下,檔案不能流動 。
ERDDAP™
此规格的設計使 NCCSV 文件與.nc可以從它們中產��生的檔案可以用ERDDAP™資料伺服器 (通過Nccsv 檔案中的 IDD 表格和NcFiles 的 EDD 表格數據集類型) ,但此规格是外部的ERDDAP.ERDDAP™有一些需要的全局屬性以及很多建議的全局和變數屬性,大多以 CF 和 ACDD 屬性為基礎(參見 /docs/server-admin/datasets# 全球屬性).
平衡
NCCSV格式的設計平衡了几种要求:
- 文件必須包含表格中的所有資料和中繼資料NetCDF檔案,包括特定的資料類型。
- 檔案必須能被讀入並從工作表中寫出, 且不失去資訊 。
- 檔案必須方便人類建立、編輯、讀取和理解。
- 檔案必須能用電腦程式清晰解析 。
如果此文件的某些要求似乎奇怪或挑剔,可能需要满足其中之一。
其他规格
這項规格是指它所設計的另外几项规格和文庫, 但這項规格並非其他规格的一部分, 若在此未指定與其中一個標準相關的細節, 請參考相關的說明 。 主要是:
- 數據集探索的屬性常规 (ACDD) 元数据標準 : https://wiki.esipfed.org/Attribute\_Convention\_for\_Data\_Discovery\_1-3 .
- 气候与預測 (CF) 元数据標準 : https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html .
- 其NetCDF使用者指南 (努格) : https:///docs.unidata.ucar.edu/netcdf-java/current/userguide/index.html .
- 其NetCDF軟體文庫類型NetCDF- 賈瓦和NetCDF-c: https://www.unidata.ucar.edu/software/netcdf/ . 這些文庫無法讀取 NCCSV 檔案, 但可以讀取.nc從 NCCSV 檔案建立檔案 。
- 杰森: https://www.json.org/
标记
括弧\[ \],表示可選項。
文件结构
完整的 NCCSV 檔案包含兩個區段: 元数据區段, 其後是數據區段 。
NCCSV 檔案必須只包含 7 位 ASCII 字元 。 因此,用于寫入和讀取檔案的字符集或編碼可能是任何與7位 ASCII 字符集兼容的字符集或編碼,例如ISO-8859-1.ERDDAP™使用 ISO- 8859-1 字元集讀寫 NCCSV 檔案 。
NCCSV 檔案可能使用新線 (\n) (在 Linux 和 Mac OS X 電腦上常见的) 或馬車 返回加新線 (\r\n) (在 Windows 電腦上常用的) 作為線末的標記,但不是兩者兼有。
.nccsv中繼資料
當創作人和讀者都期待它時, 也有可能, 有時會有用, (包括\*安德曼達塔\*行) . 結果可以完整描述檔案的屬性、變數名稱和數據類型,因此和.das加.dds的回應具有相同的目的。OPeNDAP伺服器。ERDDAP™如果您要求檔案, 會傳回此變更 類型=.nccsv從 a 中繼資料ERDDAP™數據集。
元数据科
在 NCCSV 檔案中, 元数据段的每行都使用格式
變數 姓名,屬性 姓名,值1\[值2\]\[值 3\]\[值 4\]\[...\]
項目之前或之後的空間不被允許, 因為它們在將檔案匯入电子表格程式時會造成問題 。
公约
NCCSV 文件的第一行是元数据段的第一行,必須有\全球\例如: \全球\"公约"COARDS,CF-1.6, ACDD-1.3, NCCSV-1.1 ” 其中之一必須是NCCSV-1.1,
末端(_M)
NCCSV 檔案的元数据區段的尾端必須用只有一行表示 \安德曼達塔\
建議但不要求指定變數的所有屬性都出現在元件區域的相邻線上 。 如果 NCCSV 文件被轉換成NetCDF檔案中,變數名稱最早出现在元件區域的顺序是NetCDF文件。
選取的空白行可以在元数据區�域中, 在需要的第一行之后與\全球\ 公约信息 (见下文) 在要求的最后一行之前\安德曼達塔\.
如果從 NCCSV 檔案建立电子表格, 元数据段會以變數名稱出現在 A 列, 屬性名稱出現在 B 列, 值出現在 C 列 。
如果這些傳統之後的电子表格被儲存為 CSV 檔案, 在元数据區域的行尾會經常有额外的逗號 。 將 NCCSV 檔案轉換成.nc檔案會忽略额外的逗號 。
變數 姓名
變數 姓名 是數據檔中變數的大小寫名稱。 所有可變名稱必須從 7 位 ASCII 字母或下划線開始, 由 7 位 ASCII 字母、 下划線和 7 位 ASCII 數字組成 。
全球
特殊變數Name\全球\用于表示全局元数据。
屬性 姓名
屬性 姓名 是與變數或\全球\. 所有屬性名稱必須從 7 位 ASCII 字母或下划線開始, 由 7 位 ASCII 字母、 下划線 和 7 位 ASCII 數字組成 。
星座
特殊屬性 姓名\*星座\*可以用來建立 scalar 資料變數并定義其值。 數據型態\*星座\*定義變數的資料類型, 所以不要指定\*数据类型\*刻度變數的屬性。 注意 NCCSV 檔的資料區中必須有 scalar 變數的資料 。
例如, 要建立一個命名為"船" 的 scalar 變數, 其值為「 Okeanos Explorer 」 , 以及 cf\_role 屬性, 使用 : 船,\*星座\*奧基亞諾斯探險家 船,cf\role, 傳射\ 當刻度數據變數被讀入ERDDAP™中,平面值會轉換成每行數值相同的資料表中的列。
值
值 是中繼屬性的數值, 必須是一個數目, 其中一個或多個字節、 ubyte、 短、 ushort、 int、 uint、 uint、 長、 ulong、 浮、 雙倍、 字符串或 char 。 不支援其他資料類型 。 沒有值的屬性會被忽略 。 如果有不止一個子數值,子數值都必須是同樣的資料類型,並用逗號分隔,例如: sst,actual\_range0.17f,23.58f 如果有多重字符串值, 請使用一個字符串\n (新行) 字符分隔子串。
屬性數據類型的定義有:
位元組
- 位元屬性值 (8 位, 簽署) 必須用后缀'b'來寫,例如 -7b, 0b, 7b 。 有效的位元數範圍為 -128 到 127 。 看起來像位元組但無效的數字 (例如,128b) 將轉換成缺失值或產生錯誤訊息。
u字節
- ubyte 屬性值 (8 位, 未簽署) 必須用後缀「 ub」 寫, 例如 0ub, 7ub, 250ub 。 有效的位元數範圍為 0 到 255 。 看起來像 ubyte 的數字不合法 (例如,256ub) 將轉換成缺失值或產生錯誤訊息。 可能時使用字節而�不是ubyte, 因為很多系統不支援未簽署的字節 (例如,NetCDF- 3 文件) .
短
- 短屬性值 (16 位, 簽署) 必須用後缀's'來寫, 例如 - 3000s, 0s, 3000s 。 有效短數值的範圍為 -32768 到 32767. 看起來很短但無效的數字 (例如,32768s) 將轉換成缺失值或產生錯誤訊息。
超速
- ushort 屬性值 (16 位, 未簽署) 必須用後缀「 us 」 寫成, 例如 0us, 30000us, 60000us 。 有效短數值的範圍為 0 到 65535 。 看起來像用戶的數字不合法 (例如,65536us) 將轉換成缺失值或產生錯誤訊息。 可能時, 使用簡短的字節來代替 ushort, 因為很多系統不支援未簽署的字節 (例如,NetCDF- 3 文件) .
英寸
- 英特屬性值 (32 位, 簽署) 必須以 JSON ints 寫入, 沒有小數點或 expresent , 但有後缀 'i' , 例如 -12067978i, 0i, 12067978i 。 有效的內值為 -2147483648 至 2147483647。 看起來像 int 的數字不合法 (例如,2147483648i) 將轉換成缺失值或產生錯誤訊息。
昆特
- uint 屬性值 (32 位, 未簽署) 必須寫成 JSON ints 沒有小數點 或 expresent, 但有後缀 'ui', 例如 0ui, 12067978ui, 4123456789ui 。 有效的 int 值的範圍為 0 到 4294967295 。 看起來像 uint 的數字不合法 (例�如,2147483648ui) 將轉換成缺失值或產生錯誤訊息。 可能時使用 int 而不是 uint , 因為很多系統不支援未簽署的字節 (例如,NetCDF- 3 文件) .
長
- 長屬性值 (64 位, 簽署, 目前由 NUG 支援ERDDAP™CF 尚未支援) 必須不使用小數點寫入,並使用后缀“ L”,例如: -12345678987654321L, 0L, 12345678987654321L。 如果您使用轉換軟體將有長數值的 NCSV 文件轉換成NetCDF-3 檔案, 任何長數值都會轉換成雙數值 。 有效長值的範圍是 -922337203685475808 至 92237203685475807. 看起來很長但無效的數字 (例如,922337203685475808L) 將轉換成缺失值或產生錯誤訊息。 如果可能的話, 使用雙倍而不是烏龍, 因為很多系統不會支持很久 (例如,NetCDF- 3 文件) .
烏龍
- ulong 屬性值 (64 位, 未簽署, 目前由 NUG 和ERDDAP™CF 尚未支援) 必須用小數點寫入, 并加上後缀 'uL', 例如 0uL, 12345678987654321uL, 9007199254740992uL 。 如果您使用轉換軟體將有長數值的 NCSV 文件轉換成NetCDF-3 檔案, 任何長數值都會轉換成雙數值 。 有效長值的範圍為0至1844644073709551615. 一個看起來像烏龍但無效的數字 (例如,184467437095516uL) 將轉換成缺失值或產生錯誤訊息。 可能時, 使用雙倍而不是烏龍, 因為很多系統不支援簽署或未簽署長時間 (例如,NetCDF- 3 文件) .
浮
- 浮點數值 (32 位元) 必須用后缀'f'來寫,可能會有小數點和/或引數,例如 0f, 1f, 12.34f, 1e12f, 1.23e+12f, 1.23e12f, 1.87E-7f。 用 NaNf 表示浮動的 NaN (缺少) 值。 浮力範圍约为+/-3.40282347E+38f (~7 重要的小數位數) . 看起來像浮點數但無效的數字 (例如,1.0e39f) 將轉換成缺失值或產生錯誤訊息。
雙倍
- 雙倍屬性值 (64 位元) 必須用后缀'd'來寫,可能會有小數點和(或)引數,例如 0d, 1d, 12.34d, 1e12d, 1.23e+12d, 1.23e12d, 1.87E-7d。 用 NaNd 做雙份 NaN (缺少) 值。 雙胞胎的範圍约为+/-1.79769313486231570E+308d (~15 位小數) . 看起來是雙倍但無效的數字 (例如,1.0e309d) 將轉換成缺失值或產生錯誤訊息。
字符串
- 字符串屬性值是 UCS-2 字符序列 (例如, 2字节的Unicode 字符, 如Java) ,它必須被寫成 7 位 ASCII, JSON 類的字符串才能指定非 ASCII 字元 。
- 雙引號 (") 必須編碼為兩個雙引號 ("") . 电子表格程式在讀取 .csv 檔案時需要這個 這就是电子表格程式在儲存电子表格為.csv檔案時所寫的.
- 特殊 JSON 反斜編碼的字元必須像 JSON 一樣編碼( 特别是)\n(新行),但也有(背斜),\f(格式),\ t(tab),\r(返回)或与\u 啊 語法。 在工作表中,不要使用 Alt Enter 在文字格內指定新行;而是使用\n (2 個字元:反斜和n ' ') 表示新行。
uhhhh
- \u hhhh - 所有字符都小于32或大�于字符 #126, 而不是其他編碼, 必須用語法\u編碼 hhh*, 其中hhh是字符的四位數十六進位數字, 例如歐洲標籤是\u20AC 。 參考 https://en.wikipedia.org/wiki/Unicode 查找與特定 Unicode 字元相關的十六進制數字, 或者使用軟體文庫 。
- 如果字串在起始或末端有空格,或包括 " (雙引號) 或 逗號,或包含會被解釋成其他資料類型的數值 (例如,) , 或者是「 null 」 一词, 整個字串必須用雙引號來包圍; 否則, 和 JSON 不同的是, 附加的雙引號是可選擇的 。 我們建議:當懷疑的時候,你應當把整條弦帶入兩句。 字串起始或末端的空格很不方便 。
- 目前, NCCSV支持他們.ERDDAP™在內部支援他們。 一些輸出檔案類型支援它們 (例如,.json和.nccsv) . 但很多輸出檔案型態不支援它們. 例如,NetCDF-3份文件不支持此字元, 因為NetCDF檔案使用 1字节字元, CF 目前沒有指定 Unicode 字元如何編碼的系統NetCDF字串 (例如UTF-8) . 這可能會隨時改善
字符
- 字元屬性值是單一個 UCS-2 字元 (例如, 2字节的Unicode 字符, 如Java) ,它必須被寫成 7 位 ASCII, JSON 類型的字符才能指定其他字符 (參觀上面對特殊字元編碼的字串定義, 加上單句編碼為\ ' ') . 字元屬性值必須用單引號封存 (內部引言) 雙倍引號 (外部引文) ,例如:"'a',"''" (雙引號字元) ,"''" (單一引號字符) ,"'\" (分頁) ,"'\u20AC'" (a 歐元字元) . 使用單引數和雙引數的系統是奇特而繁琐的, 但是它是用工作表格來区分字符串和字符串的方法 。 看起來像字元��但無效的值會產生錯誤訊息 。 和 Strings 一樣,目前不鼓励使用大于 # 255 的字符 。
后缀
注意, 在 NCCSV 檔案的屬性區域中, 所有數字屬性值必須有後缀字母 (例如,“b”) 以表示數據型態 (例如,字节) . 但在 NCCSV 檔案的資料區域中,數值絕對不能有這些後缀字母 (除長整數的 L 和 ulong 整數的 UL 外) ─數據型態由\*数据类型\*變數的屬性。
数据(_T)
每個非- 的資料型態斜拉變數必須用\*数据类型\*屬性可以有字节,ubyte,短, ushort, int, uint, uint, 長, ulong, 浮, 雙倍, 字符串, 或 char (大小寫不敏感) . 例如, qc\_flag,\*数据类型\*字节 警告:指定正确\*数据类型\*這是你的責任 指定錯誤的資料類型 (例如, 當您應該指定浮點數時) 不會產生錯誤訊息, 可能會造成資訊流失 (例如,浮點數值將四舍五入為整數) NCCSV 檔案讀取時ERDDAP™或轉換成 aNetCDF文件。
已忽略字符
使用 char 資料值被阻擋, 因為在其他檔案類型中並沒有被廣泛支持 。 字元值可能以單字元或字串寫入資料區域 (特別的是,如果你需要寫一個特殊的字元) . 如果找到字串, 字串的第一個字元將被用作字串的值 。 0 長弦與缺失值將轉換為字元\ uFFFF 。 注意:NetCDF檔案只支援單位字元字元字元, 所以比字元 # 255 更大的字元會在寫入時轉�換成「 ? 」NetCDF文件。 除非使用 charset 屬性指定 char 變數的不同的 charset, 否则會使用 ISO- 8859-1 字元集 。
長且未署名
雖然有很多檔案類型 (例如,NetCDF-4和Json) 和ERDDAP™支援長且未簽署 (烏比特 烏比特 烏比特) 值,目前不鼓励在 NCCSV 檔案中使用長和未簽署的值, 因為目前沒有 Excel、 CF 和NetCDF-3份文件。 如果您要在 NCSV 檔案中指定長或未簽署的值 (或相应的 Excel 电子表格) ,您必須使用“L”的後缀,以便 Excel 不以更低的精度把數字當做浮點數。 目前, NCCSV 檔案被轉換成NetCDF-3.nc檔案、 長數值和烏龍數值會轉換成雙數值, 造成非常大數值的精度損失 (長小於 -2^53, 或長於 2^53 和 烏龍) . 在NetCDF-3.nc檔案、 ubyte、 ushort 和 uint 變數以字節、 短節和 QQUnsign= true medata 屬性顯示 。 在NetCDF-3.nc檔案、 ubyte、 ushort 和 uint 屬性以字节、 短和 int 字元顯示, 包含相對的 2 的補充值 (例如, 255ub 是 - 1b) . 這顯然是個麻煩, 所以只要可能, 簽署的資料型態就應該使用, 而不是未簽署的資料型態 。
CF、 ACDD 和ERDDAP™中繼資料
大部分NCCSV檔案或.nc從它們產生的檔案, 會被讀入ERDDAP, 強烈建議 NCCSV 檔案包含需要或建議的元数据屬性ERDDAP™(看 /docs/server-admin/datasets# 全球屬性). 屬性幾乎都來自 CF 和 ACDD 中繼資料標準, 並且能正确描述��數據集 (誰,什麼,當,在哪裡,為什麼,如何) 給一個對數據集一無所知的人 尤其重要的是,几乎所有數值變數都應有單位屬性,且UDUNITS- 相容值,例如, sst單位,分數
加入不來自 CF 或 ACDD 標準或 ACDD 的附加屬性是好的ERDDAP.
資料科
结构
數據區域的第一行必須有對大小寫敏感、逗號分隔的變數名稱清單 。 此清單中的所有變數必須在元数据區段描述,反之亦然 (除\全球\屬性和\星座\變數) .
第二行通過數據區域的倒數第二行必須有逗號分隔的數值列表 。 每列資料的數值必須與逗號分隔的變數列表相同 。 數值之前或之後的空間不被允許, 因為它們在匯入檔案到电子表格程式時會產生問題 。 本部分的每欄必須只包含數值\*数据类型\*按\*数据类型\*此變數的屬性 。 和屬性區域不同的是,資料區域的數值不能有後缀字母表示資料類型 。 和屬性區域不同的是, 資料區域的 char 值可能會忽略附帶的單引數, 如果這些引數不為混淆所需要的話 (因此, 必須引用 '、' 和 '\' 。) . NCCSV 檔案中可能有這些資料列的數量, 但目前ERDDAP™只能讀取 NCCSV 檔案, 最多可達20億列 。 總而言之, 建議您將大數據集分拆成多個 NCCSV 資料檔, 每檔不到 100 萬列 。
結束(_D)
數據區域的末端必須用只有 \末日\
如果在 NCCSV 文件之后有其他內容\*末日\*中,它會被忽略.nc文件。 因此,这些内容令人灰心。
在這些會議之後的表格中, 變數名稱和數值會分為多列 。 参见下文的例子。
缺少值
數字缺失數值可能會被寫成數值missing\_value或 FillValue 變數的屬性 。 例如, 參考此資料列上的第二值 : 島田貝爾,99,123.4 這是處理字節, ubyte, 短、 ushort, int, uint, 長、 ulong 變數的建議方式 。
浮式或雙倍的 NaN 值可以寫成 NaN 。 例如, 參考此資料列上的第二值 : Bell M. Shimada, NAN,123.4
字串和數值缺失可能由空字段表示 。 例如, 參考此資料列上的第二值 : Bell M. Shimada, 123.4,
單位、 ubyte、 短、 ushort、 int、 uint、 長、 ulong 變數, NCCSV 轉換器工具與ERDDAP™會將空白字段轉換成此資料類型的最大允許值 (例如, 127 位元組) . 如果你這樣做,一定要加一個missing\_value或 QQFillValue 屬性, 以辨識此值, 例如 , 變數 姓名 127.b 對浮點數和雙倍變數, 空域會轉換成 NaN 。
日期數值
日期值 (包括沒有時間元件的日期值) 可以在 NCCSV 檔案中以數字或字串表示 。 指定日期時變數可能只有字符串值或只有數值, 而不是兩者兼有 。 NCCSV 軟體會將 String 日期值轉換成數字日期 建立時的時間值.nc文件 (按CF要��求) . 弦日期值的优点是人類很容易讀取
以數值表示的日期時值必須有指定 " 單位 自 日期 時間 " 按CF的要求和UDUNITS例如, 1970-01-01T00:00Z
以字串值表示的日期時值必須有字串\*数据类型\*屬性與指定日期的單位屬性 指定時間模式Java日期 ( https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html ) . 例如, 時間 單位yyyy-MM-dd'T'HH:mm:sZ 指定資料變數的所有日期時值必須使用相同的格式 。 大多數情况下,您需要的單位屬性的日期時刻模式會是其中一個格式的變化 :
- yyyy-MM-dd'T'HH:mm:s。 SSSZ——即ISO 8601:2004 (英) 日期 時間格式 。 你可能需要簡化的版本,例如,yyyy-MM-dd'T'HH:mm:sZ (唯一推荐格式) 或yyyy-MM-dd. 如果您要改變日期時值的格式, NCCSV 強烈建議您變更此格式 (可能缩短) . 此格式ERDDAP™會在它寫入 NCCSV 檔案時使用 。
- yyyMMddHHmms.SSS — 是 ISO 8601: 2004 日期的紧凑版本 時間格式 。 您可能需要簡化的版本, 例如 YyyMMdd 。
- 男/女 H:mm:s。 SSS——處理美國式的日期和日期, 您可能需要簡化的版本, 例如 M/d/yyyy 。
- YyyDDHHHmmsSS——一年加上一年零增加的一天 (例如, 001 = Jan 1, 365 = Dec 31 in a non leap year;這有時被誤稱為朱利安日期) . 您可能需要簡化的版本, 例如 YyyDD 。
精度
當軟體文庫轉換一個.nc所有日期 時間值會寫成 ISO 8601: 2004 的字串 (英) 日期 時間格式,例如1970-01-01T00:00Z. 你可�以用ERDDAP- 特定屬性time\_precision. 看 /docs/server-admin/datas集#time\_precision.
時區
日期的預設時區 時間值是Zulu (或格林尼治平时) 時區, 如果日期變數有不同時區的日期值, 您必須用ERDDAP- 特定屬性time\_zone. 這是要求ERDDAP™(看 /docs/server-admin/datas集#time\_zone).
度值
根據CF的要求,所有度值 (例如,經度和纬度) 必須指定為十進位的雙倍數, 而不是為度為°min'sec" 的字串, 或是為 度、 分、 秒 的獨立變數 。 方向設計者N,S,E,和W不得使用. 使用西經和南纬的負值。
副秘书长 特性類型
NCCSV 檔案可能包含 CF Discrete 采样几何 ( https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html#discrete-sampling-geometries ) 數據 由於這些特性,
- 根據 CF 的要求, NCCSV 檔案必須在元件區域中包含一行, 以表示\全球\ featureType屬性,例如, \全球\,featureType傳射
- 用于ERDDAP™, NCCSV 檔案必須在元数据區域中包含一行或一行, 表示 cf\_role=...\_id 變數, 例如 , 船,cf\role, 傳射\ 這對 CF 是可選的, 但NCCSV 需要 。
- 用于ERDDAP™, NCCSV 檔案必須在中繼器區域中包含一行或多行, 以辨識每個時序、 軌道或設定檔中需要的變數ERDDAP™(看 /docs/ server-admin/ datasets#cdm_%data_%type),例如, \全球\"船" 或 \*全球\*時空系列可以變化,
樣本檔案
以下是一個樣本檔案, 它顯示了 NCCSV 檔案的许多功能 :
\\*GLOBAL\\*,Conventions,"COARDS, CF-1.6, ACDD-1.3, NCCSV-1.1"
\\*GLOBAL\\*,cdm\\_trajectory\\_variables,"ship"
\\*GLOBAL\\*,creator\\_email,erd.data@noaa.gov
\\*GLOBAL\\*,creator\\_name,Bob Simons
\\*GLOBAL\\*,creator\\_type,person
\\*GLOBAL\\*,creator\\_url,https://www.pfeg.noaa.gov
\\*GLOBAL\\*,featureType,trajectory
\\*GLOBAL\\*,infoUrl,https://erddap.github.io/docs/user/nccsv-1.10
\\*GLOBAL\\*,institution,"NOAA NMFS SWFSC ERD, NOAA PMEL"
\\*GLOBAL\\*,license,"""NCCSV Demonstration"" by Bob Simons and Steve Hankin is
licensed under CC BY 4.0, https://creativecommons.org/licenses/by/4.0/ ."
\\*GLOBAL\\*,keywords,"NOAA, sea, ship, sst, surface, temperature, trajectory"
\\*GLOBAL\\*,standard\\_name\\_vocabulary,CF Standard Name Table v55
\\*GLOBAL\\*,subsetVariables,"ship"
\\*GLOBAL\\*,summary,"This is a paragraph or two describing the dataset."
\\*GLOBAL\\*,title,"NCCSV Demonstration"
ship,\\*DATA\\_TYPE\\*,String
ship,cf\\_role,trajectory\\_id
time,\\*DATA\\_TYPE\\*,String
time,standard\\_name,time
time,units,"yyyy-MM-dd'T'HH:mm:ssZ"
lat,\\*DATA\\_TYPE\\*,double
lat,units,degrees\\_north
lon,\\*DATA\\_TYPE\\*,double
"lon","units","degrees\\_east"
status,\\*DATA\\_TYPE\\*,char
status,comment,"From http://some.url.gov/someProjectDocument , Table C"
testByte,\\*DATA\\_TYPE\\*,byte
testByte,units,1
testUByte,\\*DATA\\_TYPE\\*,ubyte
testUByte,units,1
testLong,\\*DATA\\_TYPE\\*,long
testLong,units,1
testULong,\\*DATA\\_TYPE\\*,ulong
testULong,units,1
sst,\\*DATA\\_TYPE\\*,float
sst,standard\\_name,sea\\_surface\\_temperature
sst,actual\\_range,0.17f,23.58f
sst,units,degree\\_C
sst,missing\\_value,99f
sst,testBytes,-128b,0b,127b
sst,testShorts,-32768s,0s,32767s
sst,testInts,-2147483648i,0i,2147483647i
sst,testLongs,-9223372036854775808L,0L,9223372036854775807L
sst,testFloats,-3.40282347e38f,0f,3.40282347E+38f
sst,testDoubles,-1.79769313486231570e308d,0d,1.79769313486231570E+308d
sst,testChars,"','","'""'","'\\u20AC'"
sst,testStrings," a~,\\n'z""\\u20AC"
sst,testUBytes,0ub,127ub,255ub
sst,testUInts,0ui,2147483647ui,4294967295ui
sst,testULongs,0uL,9223372036854775807uL,18446744073709551615uL
sst,testUShorts,0us,32767us,65535us
\\*END\\_METADATA\\*
ship,time,lat,lon,status,testByte,testUByte,testLong,testULong,sst
Bell M. Shimada,2017-03-23T00:45:00Z,28.0002,-130.2576,A,-128, 0,-9223372036854775808L,0uL,10.9
Bell M. Shimada,2017-03-23T01:45:00Z,28.0003,-130.3472,\\u20AC,0,127,-9007199254740992L,9223372036854775807uL,10.0
"Bell M. Shimada","2017-03-23T02:45:00Z",28.0001,-130.4305,"'\\t'",126,254,9223372036854775806L,18446744073709551614uL,99
"Bell M. Shimada",2017-03-23T12:45:00Z,27.9998,-131.5578,"'""'",127,255,9223372036854775807L,18446744073709551615uL,NaN
注:
- 此樣本檔案包含很多難題 (例如,字符與長變數和困難的字符串值) . 大多數NCCSV檔案會簡單得多 。
- 駕照線被分成兩行 但只是樣本檔的一行
- \u20AC 是歐元的編碼, 而\u00FC 是 ü 的編碼 。
- 很多 示例中的字串被雙引號所封閉, 即使它們不必是, 例如, 包括標題、 Lon 單位屬性, 以及數據的第 3 行在内的許多全球屬性 。 )
- 如果測試Long 變數的單位屬性是以雙引號寫成, 表示它是一個字串值, 這會更明確和更好 。 但目前的代表 (1, 不引號) 會被正确解釋為字符串而不是整數, 因為沒有 'i' 後缀 。
- 不像其他數據類型, 資料區的長數值有後缀 ('L') 表示其數據型態。 這是為了防止电子表格把數值解釋成浮點數,从而失去精度。
电子表格
在工作表中, 如 NCCSV 檔案中:
- 按指定的 NCCSV 檔案寫入數值屬性值 (例如, 加上一個後缀字母, 例如 'f', 以辨識屬性資料型態) .
- 在字串中, 寫入所有小於 ASCII 字元 # 32 或大于字元 # 126 的字元為 JSON 類似反擊字元 (例如,\n新行) 或為十六進制 Unicode 字元數字 (大小寫不敏感) 用語法\u 啊 (例如, 歐洲標籤的\u20AC) . 使用\n (2 個字元:反斜和n ' ') 以指示新行,而不是 Alt Enter 。
NCCSV 檔案和遵循這些約定的類似工作表的唯一不同是:
- NCCSV 檔案在以逗號分隔的行上有值 。 電子表格在相邻单元格的行上有值 。
- NCCSV 檔案中的字串常被雙引號包圍 。 工作表中的字串從來不用雙引號包圍 。
- 內部雙引號 (") 在 NCCSV 檔案中的字串中, 以 2 雙引號顯示 。 內部雙引�數在电子表格中以 1 雙引數出現 。
如果這些會議之後的电子表格被儲存為 CSV 檔案, 許多行的尾部會有额外的逗號 。 將 NCCSV 檔案轉換成.nc檔案會忽略额外的逗號 。
埃塞爾
要匯入 NCCSV 檔案到 Excel :
- 選擇檔案 : 開啟 。
- 變更檔案類型為文字檔案 (\四月;\.txt; \*.csv) .
- 搜尋目錄並點擊 NCCSV .csv 檔案 。
- 點擊開啟 。
要從 Excel 工作表中建立 NCCSV 檔案 :
- 選擇檔案 : 另存為 。
- 變更儲存為類型: 要成為 CSV (已指定逗號) (========) .
- 對相容性警告, 點選是 。
- 產生的 . csv 檔案除 CSV 列外, 其它列的尾部會有额外的逗號 。 你可以忽略他們。
在 Excel 中,上面的 NCCSV 檔案樣本為
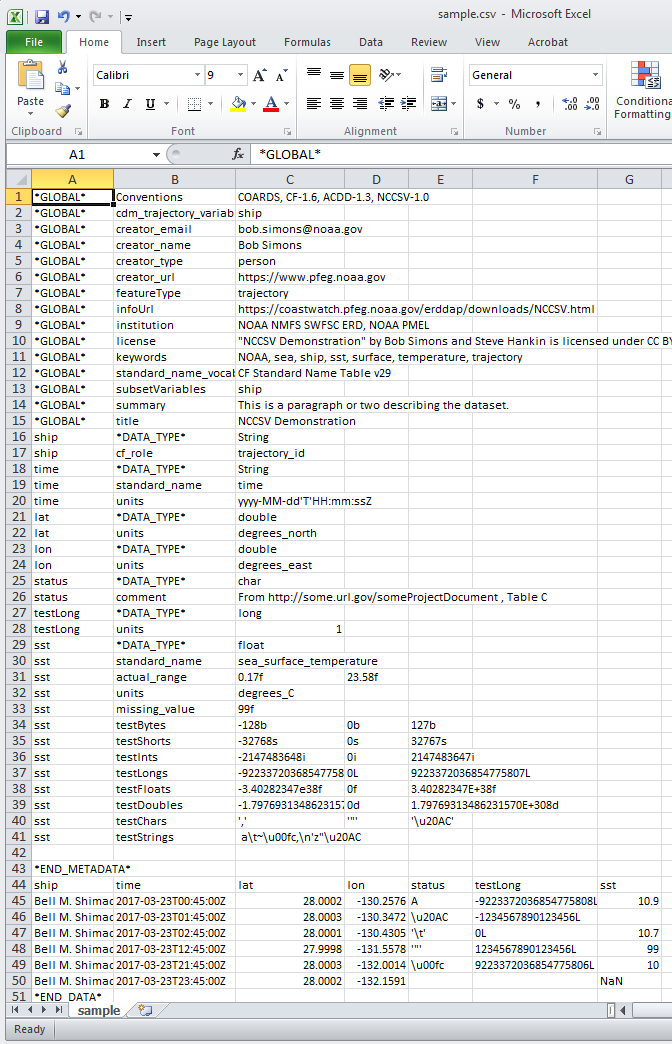
谷歌工作表
要匯入 NCCSV 檔案到 Google 工作表 :
- 選擇檔案 : 開啟 。
- 選擇上傳檔案並點擊從電腦上傳檔案 。 選擇檔案,然後點擊 Open 。
或者, 選擇 My Drive 將檔案類型降為所有檔案類型 。 選擇檔案,然後點擊 Open 。
要從 Google 工作表中建立 NCCSV 檔案 :
- 選擇檔案 : 另存為 。
- 變更儲存為類型: 要成為 CSV (已指定逗號) (========) .
- 對相容性警告, 點選是 。
- 產生的 . csv �檔案除 CSV 列外, 其它列的尾部會有额外的逗號 。 別理他們
問題/警告
- 如果您用文字編輯器建立 NCCSV 檔案, 或者您在工作表中建立類似的工作表, 工作表編輯器或工作表程式不會檢查您是否正確地遵循了這些常规 。 你必須正确遵守這些會議
- 此會議之後的电子表格轉換成 csv 文件 (因此, NCCSV 文件) 除 CSV 數據列外, 會導致所有列的尾部增加逗號 。 別理他們 軟體將 NCCSV 檔案轉換成.nc文件會忽略它們 。
- 如果 NCCSV 檔案在行尾有多余的逗號, 您可以將 NCCSV 檔案轉換成NetCDF檔案,然后轉換NetCDF檔案回到 NCCSV 文件。
- 當您試圖將 NCCSV 文件轉換成NetCDF檔案中, 軟體會發現一些錯誤, 並產生錯誤訊息, 造成轉換失敗 。 其它問題都很難或無法抓住, 不會產生錯誤訊息或警告 。 其他問題 (例如行尾的過量逗號) 會被忽略的 檔案轉換器只會對結果的正確性做最小檢查NetCDF例如,在遵守CF方面。 檔案建立者及檔案使用者的責任是檢查轉換結果是否如願與正確 。 兩種檢查方式是:
- 列印其中的內容.nc使用 ncdump 的檔案 ( https://linux.die.net/man/1/ncdump ) .
- 檢視資料內容於ERDDAP.
變更
- 變更 引入于 v1. 10 (2020年4月) :
- 增加支持ubyte, ushort, uint, ulong。