NCCSV -
ANetCDF-Kompatible ASCII CSV Datei Spezifikation, Version 1.10
Bob Simons und Steve Hankin "NCCSV" von Bob Simons und Steve Hankin ist lizenziert unterCC BY 4.0
Einleitung
Dieses Dokument gibt ein ASCII CSV-Textdateiformat an, das alle Informationen enthalten kann (Metadaten und Daten) die in einemNetCDF .ncDatei, die eine CSV-Datei-ähnliche Datentabelle enthält. Die Dateierweiterung für eine ASCII CSV Textdatei nach dieser Spezifikation muss .csv sein, so dass sie einfach und korrekt in Tabellenkalkulationen wie Excel und Google Sheets gelesen werden kann. Bob Simons wird Software schreiben, um eine NCCSV-Datei in eineNetCDF-3 (und vielleicht auchNetCDF-4) .ncDatei und umgekehrt, ohne Informationsverlust. Bob Simons hat geändertERDDAP™um das Lesen und Schreiben dieser Datei zu unterstützen.
Das NCCSV-Format ist so konzipiert, dass Tabellenkalkulationssoftware wie Excel und Google Sheets eine NCC-Datei als csv-Datei importieren können, wobei alle Informationen in den Zellen des Tabellenkalkblatts zur Bearbeitung bereit sind. Oder, ein Tabellenblatt kann von Grund auf nach den NCCSV-Konventionen erstellt werden. Unabhängig von der Quelle des Tabellenblatts, wenn es dann als .csv-Datei exportiert wird, wird es der NCCSV Spezifikation entsprechen und keine Informationen verloren gehen. Die einzigen Unterschiede zwischen NCCSV-Dateien und den analogen Tabellenkalkulationsdateien, die diesen Konventionen folgen, sind:
- NCCSV-Dateien haben Werte auf einer durch Kommas getrennten Zeile. Spreadsheets haben Werte auf einer Zeile in benachbarten Zellen.
- Strings in NCCSV-Dateien sind oft von doppelten Zitaten umgeben. Strings in Tabellenkalkulationen sind nie von doppelten Zitaten umgeben.
- Interne doppelte Zitate (") in Strings in NCCSV-Dateien erscheinen als 2 doppelte Zitate. Interne Doppel-Zitate in Tabellenkalkulationen erscheinen als 1 Doppel-Zitate.
SieheSpreadsheetAbschnitt unten für weitere Informationen.
Streaming
Wie CSV-Dateien im Allgemeinen sind NCCSV-Dateien streambar. Wird also ein NCSV on-the-fly von einem Datenserver wieERDDAP™, kann der Server starten, um Daten an den Requester zu streamen, bevor alle Daten gesammelt wurden. Dies ist ein nützliches und wünschenswertes Merkmal.NetCDFDateien dagegen sind nicht Streambar.
ERDDAP™
Diese Spezifikation ist so konzipiert, dass NCCSV-Dateien und die.ncDateien, die von ihnen erstellt werden können, können von einemERDDAP™Datenserver (über dieEDDTableFromNccsvFilesundEDDTableFromNcFisDatensatztypen) , aber diese Spezifikation ist extern anERDDAP.ERDDAP™hat mehrere benötigte globale Attribute und viele empfohlene globale und variable Attribute, meist basierend auf CF- und ACDD-Attributen (siehe /docs/server-admin/datasets#global-attributes)
Saldo
Die Gestaltung des NCCSV-Formats ist eine Balance mehrerer Anforderungen:
- Die Dateien müssen alle Daten und Metadaten enthalten, die in einer tabellarischenNetCDFDatei, einschließlich bestimmter Datentypen.
- Die Dateien müssen in der Lage sein, eingelesen und dann aus einem Tabellenblatt ohne Informationsverlust geschrieben werden.
- Die Dateien müssen für Menschen leicht sein, zu erstellen, zu bearbeiten, zu lesen und zu verstehen.
- Die Dateien müssen eindeutig durch Computerprogramme parsiert werden können.
Wenn einige Anforderung in diesem Dokument seltsam oder wählerisch scheint, ist es wahrscheinlich erforderlich, eine dieser Anforderungen zu erfüllen.
Weitere Spezifikationen
Diese Spezifikation bezieht sich auf mehrere andere Spezifikationen und Bibliotheken, mit denen sie arbeiten soll, aber diese Spezifikation ist nicht Teil einer dieser anderen Spezifikationen, noch braucht sie Änderungen an ihnen, und sie kollidiert nicht mit ihnen. Wenn hier ein mit einem dieser Standards verbundenes Detail nicht angegeben ist, siehe die zugehörige Spezifikation. Insbesondere umfasst dies:
- Die Attributkonvention für Dataset Discovery (ANLAGE) Metadatenstandard: https://wiki.esipfed.org/Attribute\_Convention\_for\_Data\_Discovery\_1-3 .
- Das Klima und Prognose (CF) Metadatenstandard: https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html .
- DieNetCDFBenutzerhandbuch (NUG) : https:///docs.unidata.ucar.edu/netcdf-java/current/userguide/index.html .
- DieNetCDFSoftwarebibliotheken wieNetCDF- Java undNetCDF-c: https://www.unidata.ucar.edu/software/netcdf/ . Diese Bibliotheken können NCCSV-Dateien nicht lesen, aber sie können lesen.ncDateien, die aus NCCSV-Dateien erstellt wurden.
- JSON: https://www.json.org/
Notierung
In dieser Spezifikation, Klammern,\[ \], bezeichnet optionale Elemente.
Dateistruktur
Eine vollständige NCCSV-Datei besteht aus zwei Abschnitten: dem Metadatenabschnitt, gefolgt von dem Datenabschnitt.
NCCSV-Dateien müssen nur 7-Bit ASCII-Zeichen enthalten. Die zum Schreiben und Lesen der Datei verwendete Zeichensatz- oder Kodierung kann daher jede Zeichensatz- oder Kodierung sein, die mit dem 7-Bit ASCII-Zeichensatz, z.B. ISO-8859-1, kompatibel ist.ERDDAP™liest und schreibt NCCSV-Dateien mit dem ISO-8859-1 Zeichensatz.
NCCSV-Dateien können entweder newline (\n) (die auf Linux und Mac OS X Computern üblich ist) Zurück zur Übersicht (\r\n) (die auf Windows-Computern üblich ist) als End-of-line-Marker, aber nicht beide.
.nccsvMetadaten
Wenn sowohl der Schöpfer als auch der Leser es erwarten, ist es auch möglich und manchmal nützlich, eine Variante einer NCCSV-Datei zu machen, die nur den Metadatenabschnitt enthält. (einschließlich\*END\_METADATA\*Linie) . Das Ergebnis liefert eine vollständige Beschreibung der Attribute der Datei, Variablennamen und Datentypen, so dass der gleiche Zweck wie die .das plus .dds Antworten von einemOPeNDAPServer.ERDDAP™wird diese Variation zurückgeben, wenn Sie die Datei anfordern Typ.nccsvMetadaten aus einemERDDAP™Datensatz.
Die Metadaten Sektion
In einer NCCSV-Datei verwendet jede Zeile des Metadatenabschnitts das Format
Variable Name,Eigenschaften Name,Wert1\[,Wert2\]\[,Wert3\]\[,Wert4\]\[...\]
Leerzeichen vor oder nach Artikeln sind nicht erlaubt, weil sie Probleme beim Import der Datei in Tabellenkalkulationsprogramme verursachen.
Übereinkommen
Die erste Zeile einer NCCSV-Datei ist die erste Zeile des Metadatenabschnitts und muss eine\GLOBAL\Konventionen, die alle in der Datei verwendeten Konventionen als String mit einer CSV-Liste enthalten, z.B.: \GLOBAL\,Conventions,"COARDS, CF-1.6, ACDD-1.3, NCCSV-1.1" Eine der aufgeführten Konventionen muss NCCSV-1.1 sein, die sich auf die aktuelle Version dieser Spezifikation bezieht.
END_METADATA
Das Ende des Metadatenabschnitts einer NCCSV-Datei muss nur durch eine Zeile mit \END\_METADATA\
Es wird empfohlen, aber nicht erforderlich, dass alle Attribute für eine bestimmte Variable auf benachbarten Zeilen des Metadatenabschnitts angezeigt werden. Wenn eine NCCSV-Datei in eineNetCDFDatei, die Reihenfolge, die die VariableNames zuerst im Metadatenbereich erscheinen, wird die Reihenfolge der Variablen imNetCDFDatei.
Optionale Leerzeilen werden im Metadatenbereich nach der erforderlichen ersten Zeile mit\GLOBAL\ ÜbereinkommenInformationen (siehe unten) und vor der erforderlichen letzten Zeile mit\END\_METADATA\.
Wird aus einer NCCSV-Datei ein Tabellenblatt erstellt, wird der Metadaten-Abschnitt mit variablen Namen in Spalte A, Attributnamen in Spalte B und Werte in Spalte C angezeigt.
Wenn ein Tabellenblatt nach diesen Konventionen als CSV-Datei gespeichert wird, wird am Ende der Zeilen im Metadatenbereich oft zusätzliche Kommas vorhanden sein. Die Software, die NCCSV-Dateien in.ncDateien werden die extra Kommas ignorieren.
Variable Name
Variable Name ist der case-sensitive Name einer Variable in der Datendatei. Alle variablen Namen müssen mit einem 7-Bit ASCII-Brief oder Unterstrich beginnen und aus 7-Bit ASCII-Briefen, Unterstrichen und 7-Bit ASCII-Zeichen zusammengesetzt sein.
GLOBAL
Die SondervariableName\GLOBAL\wird verwendet, um globale Metadaten zu bezeichnen.
Eigenschaften Name
Eigenschaften Name ist der case-sensitive Name eines Attributs, das einer Variablen zugeordnet ist oder\GLOBAL\. Alle Attributnamen müssen mit einem 7-Bit ASCII Buchstaben oder Unterstrich beginnen und aus 7-Bit ASCII Buchstaben, Unterstrichen und 7-Bit ASCII Ziffern zusammengesetzt sein.
SCALAR
Das besondere Attribut Name\*SCALAR\*kann verwendet werden, um eine skalare Datengröße zu erstellen und seinen Wert zu definieren. Der Datentyp der\*SCALAR\*den Datentyp für die Variable definiert, also keine\*DATEN\*Attribute für skalare Variablen. Beachten Sie, dass im Datenbereich der NCCSV-Datei keine Daten für die Skalarvariable vorliegen dürfen.
Zum Beispiel, um eine Skalarvariable namens "Schiff" mit dem Wert "Okeanos Explorer" und ein cf\_role Attribut zu erstellen, verwenden Sie: Schiff,\SCALAR\,"Okeanos Explorer" Schiff,cf\_role,trajectory\_id Wenn eine skalare Datengröße eingelesen wirdERDDAP™, wird der Skalarwert in eine Spalte in der Datentabelle mit dem gleichen Wert in jeder Zeile umgewandelt.
Wert
Wert ist der Wert des Metadaten-Attributs und muss ein Array mit einem oder mehreren von entweder einem Byte, ubyte, kurz, ushort, int, uint, lang, ulong, float, double, String oder char sein. Es werden keine anderen Datentypen unterstützt. Attribute ohne Wert werden ignoriert. Liegt mehr als ein Subwert vor, müssen die Subwerte alle vom gleichen Datentyp sein und beispielsweise durch Kommas getrennt sein: sst,actual\_range,0.17f,23.58f Wenn mehrere String-Werte vorhanden sind, verwenden Sie eine einzelne String mit\n (Neuheit) Zeichen, die die Substrings trennen.
Die Definitionen der Attributdatentypen sind:
Byte
- Byte Attributwerte (8-Bit, signiert) muss mit dem Suffix 'b' geschrieben werden, z.B. -7b, 0b, 7b . Der Bereich der gültigen Byte-Werte beträgt -128 bis 127. Eine Zahl, die wie ein Byte aussieht, aber ungültig ist (z.B. 128b) wird in einen fehlenden Wert umgewandelt oder eine Fehlermeldung generiert.
Ubyte
- ubyte Attributwerte (8-Bit, unbezeichnet) muss mit dem Suffix 'ub' geschrieben werden, z.B. 0ub, 7ub, 250ub . Der Bereich der gültigen Byte-Werte beträgt 0 bis 255. Eine Zahl, die wie ein Ubyte aussieht, aber ungültig ist (z.B. 256ub) wird in einen fehlenden Wert umgewandelt oder eine Fehlermeldung generiert. Wenn möglich, verwenden Byte anstelle von Ubyte, weil viele Systeme nicht unbezeichnete Bytes unterstützen (z.B. Attribute inNetCDF-3 Dateien) .
kurz
- kurze Attributwerte (16-Bit, signiert) muss mit dem Suffix 's geschrieben werden, z.B. -30000s, 0s, 30000s. Die Reichweite der gültigen Kurzwerte beträgt -32768 bis 32767. Eine Nummer, die wie eine kurze, aber ungültig aussieht (z.B. 32768s) wird in einen fehlenden Wert umgewandelt oder eine Fehlermeldung generiert.
Ussur
- ushort Attributwerte (16-Bit, unbezeichnet) muss mit dem Suffix 'us' geschrieben werden, z.B. 0us, 30000us, 60000us. Der Bereich der gültigen Kurzwerte beträgt 0 bis 65535. Eine Nummer, die wie ein Ushort aussieht, aber ungültig ist (z.B. 65536us) wird in einen fehlenden Wert umgewandelt oder eine Fehlermeldung generiert. Wenn möglich, verwenden Sie kurz statt ushort, weil viele Systeme nicht unbezeichnete Bytes unterstützen (z.B. Attribute inNetCDF-3 Dateien) .
in
- In den Warenkorb (32-Bit, signiert) muss als JSON-Ints ohne Dezimalpunkt oder Exponent geschrieben werden, aber mit dem Suffix 'i', z.B. -12067978i, 0i, 12067978i. Der Umfang der gültigen Intwerte beträgt -2147483648 bis 2147483647. Eine Zahl, die wie ein Int aussieht, aber ungültig ist (z.B. 2147483648i) wird in einen fehlenden Wert umgewandelt oder eine Fehlermeldung generiert.
U.S.
- Werte der Attribute (32-Bit, unbezeichnet) muss als JSON-Ints ohne Dezimalpunkt oder Exponent geschrieben werden, aber mit dem Suffix 'ui', z.B. 0ui, 12067978ui, 4123456789ui. Der Bereich der gültigen Intwerte beträgt 0 bis 4294967295. Eine Zahl, die wie ein Uint aussieht, aber ungültig ist (z.B. 2147483648ui) wird in einen fehlenden Wert umgewandelt oder eine Fehlermeldung generiert. Wenn möglich, verwenden Sie Int anstelle von Uint, weil viele Systeme nicht unbezeichnete Bytes unterstützen (z.B. Attribute inNetCDF-3 Dateien) .
lang
- lange Attributwerte (64-Bit, signiert, derzeit von NUG unterstützt undERDDAP™aber noch nicht unterstützt von CF) muss ohne Dezimalpunkt und mit dem Suffix 'L' geschrieben werden, z.B. -12345678987654321L, 0L, 12345678987654321L . Wenn Sie die Konvertierungssoftware verwenden, um eine NCCSV-Datei mit langen Werten in eineNetCDF-3 Datei, alle langen Werte werden in doppelte Werte umgewandelt. Die Reichweite der gültigen Langwerte beträgt -9223372036854775808 bis 9223372036854775807. Eine Zahl, die wie eine lange aussieht, aber ungültig ist (z.B. 9223372036854775808L) wird in einen fehlenden Wert umgewandelt oder eine Fehlermeldung generiert. Wenn möglich, verwenden Sie doppelt statt Ulong, weil viele Systeme nicht lange unterstützen (z.B.,NetCDF-3 Dateien) .
Ulong
- Ulong Attributwerte (64-Bit, unbezeichnet, derzeit von NUG unterstützt undERDDAP™aber noch nicht unterstützt von CF) muss ohne Dezimalpunkt und mit dem Suffix 'uL' geschrieben werden, z.B. 0uL, 12345678987654321uL, 9007199254740992uL . Wenn Sie die Konvertierungssoftware verwenden, um eine NCCSV-Datei mit langen Werten in eineNetCDF-3 Datei, alle langen Werte werden in doppelte Werte umgewandelt. Der Bereich der gültigen Langwerte beträgt 0 bis 18446744073709551615. Eine Zahl, die wie ein Ulong aussieht, aber ungültig ist (z.B. 184467440737095516uL) wird in einen fehlenden Wert umgewandelt oder eine Fehlermeldung generiert. Wenn möglich, verwenden Sie Doppel statt Ulong, weil viele Systeme nicht unterschrieben oder unbezeichnet lange (z.B.,NetCDF-3 Dateien) .
Flossen
- Attributwerte der Flossen (32-Bit) muss mit dem Suffix 'f' geschrieben werden und einen Dezimalpunkt und/oder einen Exponenten haben, z.B. 0f, 1f, 12.34f, 1e12f, 1.23e+12f, 1.23e12f, 1.87E-7f. Verwenden Sie NaNf für einen Float NaN (fehlen) Wert. Die Bandbreite der Schwimmer beträgt ca. +/-3.40282347E+38f (~7 signifikante Dezimalziffern) . Eine Zahl, die wie ein Schwimmer aussieht, aber ungültig ist (z.B. 1,0e39f) wird in einen fehlenden Wert umgewandelt oder eine Fehlermeldung generiert.
Doppelzimmer
- doppelte Attributwerte (64-Bit) muss mit dem Suffix 'd' geschrieben werden und einen Dezimalpunkt und/oder einen Exponenten haben, z.B. 0d, 1d, 12.34d, 1e12d, 1.23e+12d, 1.23e12d, 1.87E-7d. Verwenden Sie NaNd für eine doppelte NaN (fehlen) Wert. Der doppelte Bereich beträgt ca. +/-1.79769313486231570E+308d (~15 signifikante Dezimalziffern) . Eine Zahl, die wie ein Doppel aussieht, aber ungültig ist (z.B. 1,0e309d) wird in einen fehlenden Wert umgewandelt oder eine Fehlermeldung generiert.
Streichung
- String Attributwerte sind eine Folge von UCS-2 Zeichen (d.h. 2-byte Unicode Zeichen, wie inJava) , die als 7-Bit ASCII geschrieben werden muss, JSON-ähnliche Strings, so dass nicht-ASCII-Zeichen angegeben werden können.
- Doppelte Zitate (") muss als zwei doppelte Zitate kodiert werden (") . Das ist, was Tabellenkalkulation Programme erfordern, wenn Sie .csv Dateien lesen. Das ist, was Tabellenkalkulation Programme schreiben, wenn Sie ein Tabellenkalkulation als .csv-Datei speichern.
- Die speziellen JSON-Backslash-codierten Zeichen müssen wie in JSON kodiert werden (insbesondere\n(newline), aber auch \\\ (backslash), \f (formfeed), \t (tab), \r (carriage return) oder mit der,, h Syntax. In einem Tabellenblatt verwenden Sie nicht Alt Enter, um eine neue Zeile innerhalb einer Textzelle anzugeben; stattdessen verwenden Sie\n (2 Zeichen: Backslash und 'n ') eine neue Linie angeben.
uhhhh
- ,, hhhh - Alle Zeichen kleiner als Zeichen #32 oder größer als Zeichen #126, und nicht anders codiert, müssen mit der Syntax \u codiert werden hhhh*, wo hhhh die 4-stellige hexadezimale Zahl des Zeichens ist, z.B. das Euro-Zeichen ist \u20AC. Siehe die auf der https://en.wikipedia.org/wiki/Unicode die hexadezimalen Zahlen, die mit bestimmten Unicode-Zeichen verbunden sind, zu finden oder eine Software-Bibliothek zu verwenden.
- Wenn der String einen Raum am Anfang oder Ende hat, oder " (doppeltes Angebot) oder ein Komma oder enthält Werte, die sonst als ein anderer Datentyp interpretiert würden (z.B. ein Int) , oder ist das Wort "null", die gesamte String muss in doppelten Zitaten eingeschlossen werden; andernfalls, im Gegensatz zu JSON, sind die einschließenden doppelten Zitate optional. Wir empfehlen: wenn im Zweifel, um die gesamte String in doppelte Zitate. Räume am Anfang oder Ende eines Strings werden stark entmutigt.
- Für die Zeit wird die Verwendung von Zeichen größer als #255 entmutigt. NCCSV unterstützt sie.ERDDAP™unterstützt sie intern. Einige Ausgabedateitypen unterstützen sie (z.B.,.jsonund.nccsv) . Aber viele Ausgabedateitypen unterstützen sie nicht. Zum BeispielNetCDF-3 Dateien unterstützen solche Zeichen nicht, weilNetCDFDateien verwenden 1-Byte-Zeichen und CF hat derzeit kein System zur Angabe, wie Unicode-Zeichen inNetCDFStreicher (z.B. UTF-8) . Das wird sich im Laufe der Zeit wahrscheinlich verbessern.
!
- char Attributwerte sind ein einziges UCS-2 Zeichen (d.h. 2-byte Unicode Zeichen, wie inJava) , die als 7-Bit ASCII, JSON-ähnliche Zeichen geschrieben werden muss, damit andere Zeichen spezifiziert werden können (siehe oben die String-Definition zur Kodierung von Sonderzeichen, mit der Hinzufügung der Kodierung eines einzigen Zitats als \ ') . Char Attributwerte müssen in einzelnen Zitaten eingeschlossen werden (die inneren Zitate) und doppelte Zitate (die äußeren Zitate) , z.B. "'a'", "'"" (ein doppeltes Zitatzeichen) , "''" (ein einziges Zitat) , "'\t" (ein Tab) "'\u20AC'" (ein Euro-Zeichen) . Dieses System der Verwendung von einzelnen und doppelten Zitaten ist seltsam und umständlich, aber es ist eine Möglichkeit, Char-Werte von Strings in einer Weise zu unterscheiden, die mit Tabellenkalkulationen arbeitet. Ein Wert, der wie ein Zeichen aussieht, aber ungültig ist, erzeugt eine Fehlermeldung. Wie bei Strings wird derzeit die Verwendung von Zeichen größer als #255 entmutigt.
Suffix
Beachten Sie, dass im Attributbereich einer NCCSV-Datei alle numerischen Attributwerte einen Suffix-Brief haben müssen (z.B. 'b') zur Identifizierung des numerischen Datentyps (z.B. Byte) . Aber im Datenbereich einer NCCSV-Datei dürfen numerische Datenwerte diese Suffix-Briefe nie haben (mit Ausnahme von 'L' für lange ganze Zahlen und 'uL' für ulong ganze Zahlen) — der Datentyp durch\*DATEN\*Attribut für die Variable.
DATA_TYPE
Der Datentyp für jede Nicht-ScalarVariable muss durch eine\*DATEN\*Attribute, die einen Wert von Byte, ubyte, kurz, ushort, int, uint, lang, ulong, float, double, String oder char haben können (Fall unempfindlich) . Zum Beispiel Qc\_flag,\DATEN\,byte WARNING: Angabe der richtigen\*DATEN\*ist Ihre Verantwortung. Angabe des falschen Datentyps (z.B., Int, wenn Sie spezifizierten Float) wird keine Fehlermeldung erzeugen und kann dazu führen, dass Informationen verloren gehen (z.B. werden Floatwerte auf Ints gerundet) wenn die NCCSV-Datei gelesen wirdERDDAP™oder in eineNetCDFDatei.
Char Entmutigt
Die Verwendung von Zeichendatenwerten wird entmutigt, weil sie in anderen Dateitypen nicht weit unterstützt werden. char-Werte können im Datenbereich als einzelne Zeichen oder als Strings geschrieben werden (insbesondere, wenn Sie ein besonderes Zeichen schreiben müssen) . Wenn ein String gefunden wird, wird der erste Charakter des Strings als Wert des Chars verwendet. Nulllänge Strings und fehlende Werte werden in Zeichen \uFFFF umgewandelt. Anmerkung:NetCDFDateien unterstützen nur einzelne Byte-Wagen, so dass alle Zeichen größer als char #255 werden in '?' beim Schreiben umgewandeltNetCDFDateien. Es sei denn, ein Charset-Attribut wird verwendet, um ein anderes Charset für eine char-Variable anzugeben, wird das ISO-8859-1 Charset verwendet.
Lange und unbezeichnete Entmutigung
Obwohl viele Dateitypen (z.B.,NetCDF-4 und json) undERDDAP™Unterstützung lang und unbezeichnet (ubyte, ushort, uint, ulong) Werte, die Verwendung von langen und unbezeichneten Werten in NCCSV-Dateien wird derzeit entmutigt, weil sie derzeit nicht von Excel, CF undNetCDF- 3 Akten. Wenn Sie in einer NCCSV-Datei lange oder unbezeichnete Werte angeben möchten (oder in der entsprechenden Excel-Tabelle) , Sie müssen den Suffix 'L' verwenden, so dass Excel die Zahlen nicht als Floating Point Zahlen mit geringerer Präzision behandelt. Derzeit, wenn eine NCCSV-Dateien in eineNetCDF-3.ncDatei-, lange und ulong-Datenwerte werden in Doppelwerte umgewandelt, was einen Präzisionsverlust für sehr große Werte verursacht (weniger als -2^53 für lange oder mehr als 2^53 für lange und lange) . InNetCDF-3.ncDateien, ubyte, ushort und uint Variablen erscheinen als Byte, Short und int mit dem \_Unsigned=true metadata Attribut. InNetCDF-3.ncDateien, ubyte, ushort und uint-Attribute erscheinen als Byte, Short und Int-Attribute, die den entsprechenden Zwei-Komplement-Wert enthalten (z.B. 255ub erscheint als -1b) . Dies ist offensichtlich ein Problem, so dass signierte Datentypen anstelle von unbeschriebenen Datentypen verwendet werden sollten, wenn möglich.
CF, ACDD undERDDAP™Metadaten
Da es vorgesehen ist, dass die meisten NCCSV-Dateien, oder.ncDateien, die von ihnen erstellt werden, werden inERDDAP, es wird dringend empfohlen, dass NCCSV-Dateien die Metadaten-Attribute enthalten, die vonERDDAP™(siehe /docs/server-admin/datasets#global-attributes) Die Attribute sind fast alle aus den CF- und ACDD-Metadatenstandards und dienen dazu, den Datensatz richtig zu beschreiben (wer, was, wann, wo, warum, wie) jemand, der sonst nichts über den Datensatz weiß. Von besonderer Bedeutung sollten fast alle numerischen Variablen ein Attribut mit einemUDUNITS-kompatibler Wert, z. sst,units,degree\_C
Es ist gut, zusätzliche Attribute, die nicht aus den CF- oder ACDD-Standards oder ausERDDAP.
Die Datenabteilung
Struktur
Die erste Zeile des Datenabschnitts muss eine case-sensitive, komma-separierte Liste mit variablen Namen aufweisen. Alle Variablen in dieser Liste müssen im Metadatenbereich beschrieben werden, und umgekehrt (andere\GLOBAL\Attribute und\SCALAR\Variablen) .
Die zweite durch die vorletzten Zeilen des Datenabschnitts muss eine komma getrennte Werteliste aufweisen. Jede Zeile der Daten muss die gleiche Anzahl von Werten haben wie die komma getrennte Liste von Variablennamen. Leerzeichen vor oder nach Werten sind nicht erlaubt, weil sie Probleme beim Import der Datei in Tabellenkalkulationsprogramme verursachen. Jede Spalte in diesem Abschnitt muss nur Werte der\*DATEN\*für diese Variable durch die\*DATEN\*Attribut für diese Variable. Im Gegensatz zum Attributbereich dürfen numerische Werte im Datenbereich keine Suffix-Briefe aufweisen, um den Datentyp zu bezeichnen. Im Gegensatz zum Attributbereich können Char-Werte im Datenbereich die einschließenden einzelnen Zitate aussetzen, wenn sie nicht zur Disambiguation benötigt werden. ("," und "" müssen also wie hier gezeigt zitiert werden) . Es kann eine beliebige Anzahl dieser Datenzeilen in einer NCCSV-Datei geben, aber derzeitERDDAP™kann NCCSV-Dateien nur mit bis zu etwa 2 Milliarden Zeilen lesen. Im Allgemeinen wird empfohlen, dass Sie große Datensätze in mehrere NCCSV-Datendateien mit jeweils weniger als 1 Million Zeilen teilen.
END_DATA
Das Ende des Datenabschnitts muss durch eine Zeile mit nur \END\_DATA\
Wenn nach der NCCSV-Datei weitere Inhalte vorhanden sind\*END\_DATA\*line, es wird ignoriert, wenn die NCCSV-Datei in eine.ncDatei. Solche Inhalte werden daher entmutigt.
In einem Tabellenblatt nach diesen Konventionen werden die Variablennamen und Datenwerte in mehreren Spalten liegen. Siehe unten das Beispiel.
Fehlende Werte
Numerische fehlende Werte können als numerischer Wert geschrieben werden, der durch einenmissing\_valueoder \_FillValue Attribut für diese Variable. Siehe beispielsweise den zweiten Wert in dieser Datenzeile: Bell M. Shimada,99,123.4 Dies ist der empfohlene Weg, um fehlende Werte für Byte, Ubyte, kurze, ushort, int, uint, lange und ulong Variablen zu handhaben.
Float oder doppelte NaN-Werte können als NaN geschrieben werden. Siehe beispielsweise den zweiten Wert in dieser Datenzeile: Bell M. Shimada,NaN,123.4
String- und numerische fehlende Werte können durch ein leeres Feld angezeigt werden. Siehe beispielsweise den zweiten Wert in dieser Datenzeile: Bell M. Shimada, 123.4
Für Byte-, Ubyte-, Short-, Uhort-, Int-, Uint-, Long- und Ulong-Variablen, NCCSV-Konverter-Dienstprogramm undERDDAP™ein leeres Feld in den maximal zulässigen Wert für diesen Datentyp umwandelt (z.B. 127 für Bytes) . Wenn Sie dies tun, stellen Sie sicher, einmissing\_valueoder \_FillValue Attribut für diese Variable, um diesen Wert zu identifizieren, z. Variable Name ,\_FillValue,127b Für Schwimmer und Doppelvariablen wird ein leeres Feld in NaN umgewandelt.
Datum Zeitwerte
Datum Zeitwerte (einschließlich Datumswerte, die keine Zeitkomponente haben) kann als Zahlen oder als Strings in NCCSV-Dateien dargestellt werden. Eine vorgegebene Datumszeitvariable kann nur String-Werte oder nur numerische Werte haben, nicht beides. Die NCCSV-Software wird String dateTime-Werte in numerisches Datum konvertieren Zeitwerte bei der Erstellung.ncDateien (nach Bedarf durch CF) . String dateTime Werte haben den Vorteil, von Menschen leicht lesbar zu sein.
Die als numerische Werte dargestellten Zeitpunkte müssen ein Einheitenattribut haben, das die " Einheiten seit Datum Zeit " nach Bedarf von CF und spezifiziert vonUDUNITS, z. Zeit, Einheiten,Sekunden seit 1970-01-01T00:00Z
Datums-Zeitwerte, die als String-Werte dargestellt sind, müssen einen String aufweisen\*DATEN\*Attribut und ein Einheitenattribut, das ein Datum angibt Zeitmuster, wie durch dieJavaDatumTimeFormatter Unterricht ( https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html ) . Zum Beispiel Zeit, Einheiten,yyyy-MM-dd'T'HH:mm:ssZ Alle Datumszeitwerte für eine bestimmte Datenvariable müssen das gleiche Format verwenden. In den meisten Fällen wird das DatumTime-Muster, das Sie für die Einheiten Attribut benötigen, eine Variation eines dieser Formate sein:
- yyyy-MM-ddT'HH:mm:ss. SSSZ — die ISO 8601:2004 (E) Datum Zeitformat. Sie können eine verkürzte Version davon benötigen, z.B.yyyy-MM-dd'T'HH:mm:ssZ (das einzige empfohlene Format) oderyyyy-MM-dd. Wenn Sie das Format Ihrer DateTime-Werte ändern, empfiehlt NCCSV dringend, dass Sie dieses Format ändern. (vielleicht verkürzt) . Dies ist das Format, dasERDDAP™wird verwendet, wenn es NCCSV-Dateien schreibt.
- yyyyMMddHHmmss.SSS — die kompakte Version des ISO 8601:2004 Datums Zeitformat. Sie können eine verkürzte Version davon benötigen, z.B. yyyyMMdd.
- M/d/yyyy H:mm:ss. SSS — die mit US-Stil Daten und Datum Zeit wie "3/23/2017 16:22:03.000". Sie können eine verkürzte Version dieser, z.B. M/d/yyyy benötigen.
- yyyyDDDHHmmsSSS — das ist das Jahr plus der null-gepolsterte Tag des Jahres (z.B. 001 = Jan 1, 365 = Dec 31 in einem Nicht-Leap-Jahr; dies wird manchmal irrtümlich als das Julianische Datum bezeichnet) . Sie können eine verkürzte Version dieser benötigen, z.B. yyyyDDD .
Präzision
Wenn eine Software-Bibliothek ein.ncDatei in eine NCCSV-Datei, alle Datum Zeitwerte werden als Strings mit der ISO 8601:2004 geschrieben (E) Datum Zeitformat, z.B. 1970-01-01T00:00Z . Sie können die Präzision mit derERDDAP-spezifisches Attributtime\_precision. Vgl. /docs/server-admin/datasets#time\_precision.
Zeitzone
Die Standardzeitzone für Datum Die Zeitwerte sindZulu (oder GMT) Zeitzone, die keine Tageslichtsparzeiten hat. Wenn eine Datumszeitvariable Datum Zeitwerte aus einer anderen Zeitzone hat, müssen Sie diese mit derERDDAP-spezifisches Attributtime\_zone. Dies ist eine ForderungERDDAP™(siehe /docs/server-admin/datasets#time\_zone)
Gradwerte
Wie von CF gefordert, alle Gradwerte (z.B. für Länge und Breite) als Dezimalgrad-Doppelwerte, nicht als Grad°min'sec" String oder als separate Größen für Grad, Minuten, Sekunden angegeben werden. Die Richtungsbezeichner N, S, E und W sind nicht erlaubt. Verwenden Sie negative Werte für West-Längen und für Süd-Längen.
DSG Eigenschaften
Eine NCCSV-Datei kann CF Discrete Sampling Geometry enthalten ( https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html#discrete-sampling-geometries ) Daten. Es sind die Attribute, die diese Arbeit machen:
- Die NCCSV-Datei muss, wie von CF gefordert, eine Zeile im Metadatenbereich enthalten, die die\GLOBAL\ featureTypeAttribut, z.B. \GLOBAL\,featureType,Trajektorie
- Für den Einsatz inERDDAP™, die NCCSV-Datei muss eine Zeile oder Zeilen im Metadatenabschnitt enthalten, die die cf\_role=...\_id-Variablen, z. Schiff,cf\_role,trajectory\_id Dies ist optional für CF, aber in NCCSV erforderlich.
- Für den Einsatz inERDDAP™, die NCCSV-Datei muss eine Zeile oder Zeilen in dem Metadatenabschnitt enthalten, die identifizieren, welche Variablen jeder ZeitSerie, Trajektorie oder Profil zugeordnet sind, wie dies vonERDDAP™(siehe /docs/server-admin/datasets#cdm\_data\_type), z.B. \GLOBAL\,cdm\_trajectory\_variables,"ship" oder \GLOBAL\,cdm\_timeseries\_variables,"station\_id,lat,lon"
Beispieldatei
Hier eine Beispieldatei, die viele der Funktionen einer NCCSV-Datei demonstriert:
\\*GLOBAL\\*,Conventions,"COARDS, CF-1.6, ACDD-1.3, NCCSV-1.1"
\\*GLOBAL\\*,cdm\\_trajectory\\_variables,"ship"
\\*GLOBAL\\*,creator\\_email,erd.data@noaa.gov
\\*GLOBAL\\*,creator\\_name,Bob Simons
\\*GLOBAL\\*,creator\\_type,person
\\*GLOBAL\\*,creator\\_url,https://www.pfeg.noaa.gov
\\*GLOBAL\\*,featureType,trajectory
\\*GLOBAL\\*,infoUrl,https://erddap.github.io/docs/user/nccsv-1.10
\\*GLOBAL\\*,institution,"NOAA NMFS SWFSC ERD, NOAA PMEL"
\\*GLOBAL\\*,license,"""NCCSV Demonstration"" by Bob Simons and Steve Hankin is
licensed under CC BY 4.0, https://creativecommons.org/licenses/by/4.0/ ."
\\*GLOBAL\\*,keywords,"NOAA, sea, ship, sst, surface, temperature, trajectory"
\\*GLOBAL\\*,standard\\_name\\_vocabulary,CF Standard Name Table v55
\\*GLOBAL\\*,subsetVariables,"ship"
\\*GLOBAL\\*,summary,"This is a paragraph or two describing the dataset."
\\*GLOBAL\\*,title,"NCCSV Demonstration"
ship,\\*DATA\\_TYPE\\*,String
ship,cf\\_role,trajectory\\_id
time,\\*DATA\\_TYPE\\*,String
time,standard\\_name,time
time,units,"yyyy-MM-dd'T'HH:mm:ssZ"
lat,\\*DATA\\_TYPE\\*,double
lat,units,degrees\\_north
lon,\\*DATA\\_TYPE\\*,double
"lon","units","degrees\\_east"
status,\\*DATA\\_TYPE\\*,char
status,comment,"From http://some.url.gov/someProjectDocument , Table C"
testByte,\\*DATA\\_TYPE\\*,byte
testByte,units,1
testUByte,\\*DATA\\_TYPE\\*,ubyte
testUByte,units,1
testLong,\\*DATA\\_TYPE\\*,long
testLong,units,1
testULong,\\*DATA\\_TYPE\\*,ulong
testULong,units,1
sst,\\*DATA\\_TYPE\\*,float
sst,standard\\_name,sea\\_surface\\_temperature
sst,actual\\_range,0.17f,23.58f
sst,units,degree\\_C
sst,missing\\_value,99f
sst,testBytes,-128b,0b,127b
sst,testShorts,-32768s,0s,32767s
sst,testInts,-2147483648i,0i,2147483647i
sst,testLongs,-9223372036854775808L,0L,9223372036854775807L
sst,testFloats,-3.40282347e38f,0f,3.40282347E+38f
sst,testDoubles,-1.79769313486231570e308d,0d,1.79769313486231570E+308d
sst,testChars,"','","'""'","'\\u20AC'"
sst,testStrings," a~,\\n'z""\\u20AC"
sst,testUBytes,0ub,127ub,255ub
sst,testUInts,0ui,2147483647ui,4294967295ui
sst,testULongs,0uL,9223372036854775807uL,18446744073709551615uL
sst,testUShorts,0us,32767us,65535us
\\*END\\_METADATA\\*
ship,time,lat,lon,status,testByte,testUByte,testLong,testULong,sst
Bell M. Shimada,2017-03-23T00:45:00Z,28.0002,-130.2576,A,-128, 0,-9223372036854775808L,0uL,10.9
Bell M. Shimada,2017-03-23T01:45:00Z,28.0003,-130.3472,\\u20AC,0,127,-9007199254740992L,9223372036854775807uL,10.0
"Bell M. Shimada","2017-03-23T02:45:00Z",28.0001,-130.4305,"'\\t'",126,254,9223372036854775806L,18446744073709551614uL,99
"Bell M. Shimada",2017-03-23T12:45:00Z,27.9998,-131.5578,"'""'",127,255,9223372036854775807L,18446744073709551615uL,NaN
Anmerkungen:
- Diese Beispieldatei enthält viele schwierige Fälle (z.B. Char und lange Variablen und schwierige String-Werte) . Die meisten NCCSV-Dateien werden viel einfacher.
- Die Lizenzlinie ist hier in zwei Zeilen gebrochen, ist aber nur eine Zeile in der Musterdatei.
- \u20AC ist die Kodierung des Euro-Zeichens und \u00FC ist die Kodierung von ü.
- Viele Strings im Beispiel werden von doppelten Zitaten eingeschlossen, auch wenn sie nicht sein müssen, z.B. viele globale Attribute einschließlich des Titels, des lon Units Attributs und der 3. Zeile der Daten.)
- Es wäre klarer und besser, wenn die Einheiten Attribut für die TestLong-Variable in doppelten Zitaten geschrieben wurden, die angeben, dass es ein String-Wert ist. Aber die aktuelle Darstellung (1, ohne Zitate) wird korrekt als String interpretiert, nicht als Ganzes, weil es keinen 'i'-Suffix gibt.
- Im Gegensatz zu anderen numerischen Datentypen haben die langen Werte im Datenbereich den Suffix (L) dass ihren numerischen Datentyp identifiziert. Dies ist erforderlich, um zu verhindern, dass die Tabellenkalkulationen die Werte als Floating Point numbers interpretieren und damit Präzision verlieren.
Tabellen
In einem Tabellenblatt wie in einer NCCSV-Datei:
- Schreiben Sie numerische Attributwerte wie für NCCSV-Dateien angegeben (z.B. mit einem Suffixbrief, z.B. 'f', um den Datentyp des Attributs zu identifizieren) .
- In Strings, schreiben Sie alle Zeichen weniger als ASCII Zeichen #32 oder größer als Zeichen #126 als entweder ein JSON-ähnliches Hintergrundbild (z.B.,\nfür neue Linie) oder als hexadezimale Unicode-Zeichennummer (Fall unempfindlich) mit der Syntax,, h (z.B. \u20AC für das Euro-Zeichen) . Verwendung\n (2 Zeichen: Backslash und 'n ') um eine neue Zeile anzuzeigen, nicht Alt Enter.
Die einzigen Unterschiede zwischen NCCSV-Dateien und der analogen Tabellenkalkulation, die diesen Konventionen folgen, sind:
- NCCSV-Dateien haben Werte auf einer durch Kommas getrennten Zeile. Spreadsheets haben Werte auf einer Zeile in benachbarten Zellen.
- Strings in NCCSV-Dateien sind oft von doppelten Zitaten umgeben. Strings in Tabellenkalkulationen sind nie von doppelten Zitaten umgeben.
- Interne doppelte Zitate (") in Strings in NCCSV-Dateien erscheinen als 2 doppelte Zitate. Interne Doppel-Zitate in Tabellenkalkulationen erscheinen als 1 Doppel-Zitate.
Wenn ein Tabellenblatt nach diesen Konventionen als CSV-Datei gespeichert wird, wird es oft zusätzliche Kommas am Ende vieler Zeilen geben. Die Software, die NCCSV-Dateien in.ncDateien werden die extra Kommas ignorieren.
Excel
Zum Importieren einer NCCSV-Datei in Excel:
- Wählen Sie Datei : Öffnen .
- Ändern Sie den Dateityp in Textdateien (\.prn;\.txt; \*.csv) .
- Suchen Sie die Verzeichnisse und klicken Sie auf die Datei NCCSV .csv.
- Klicken Sie auf Öffnen .
Um eine NCCSV-Datei aus einem Excel-Tabelle zu erstellen:
- Wählen Sie Datei : Speichern als .
- Speichern als Typ ändern: CSV sein (Comma begrenzt) ()) .
- Klicken Sie als Antwort auf die Kompatibilitätswarnung auf Ja .
- Die resultierende .csv-Datei wird am Ende aller Zeilen außer den CSV-Zeilen zusätzliche Kommas haben. Sie können sie ignorieren.
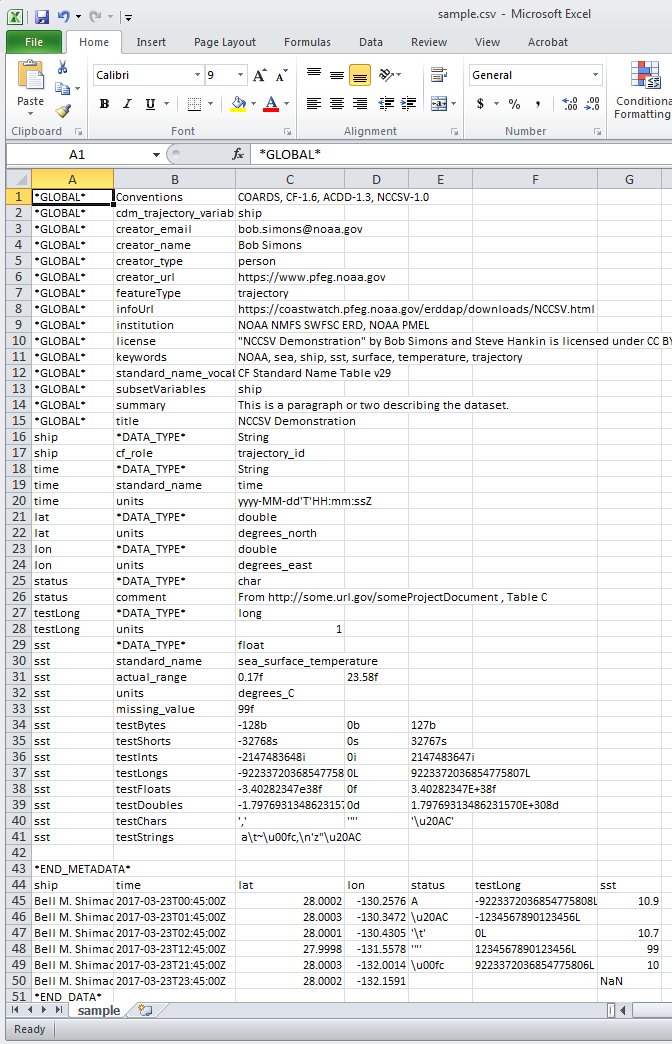
In Excel erscheint die obige NCCSV-Datei als
Google Platten
Zum Importieren einer NCCSV-Datei in Google Sheets:
- Wählen Sie Datei : Öffnen .
- Wählen Sie zum Hochladen einer Datei und klicken Sie auf Hochladen einer Datei von Ihrem Computer. Wählen Sie die Datei aus, klicken Sie dann auf Öffnen .
Oder, wählen Sie My Drive und ändern Sie die Dateityp Dropdown-Auswahl auf Alle Dateitypen . Wählen Sie die Datei aus, klicken Sie dann auf Öffnen .
Um eine NCCSV-Datei aus einem Google Sheetsheet zu erstellen:
- Wählen Sie Datei : Speichern als .
- Speichern als Typ ändern: CSV sein (Comma begrenzt) ()) .
- Klicken Sie als Antwort auf die Kompatibilitätswarnung auf Ja .
- Die resultierende .csv-Datei wird am Ende aller Zeilen außer den CSV-Zeilen zusätzliche Kommas haben. Ignoriere sie.
Probleme/Warnungen
- Wenn Sie eine NCCSV-Datei mit einem Texteditor erstellen oder ein analoges Tabellenkalkulationsblatt in einem Tabellenkalkulationsprogramm erstellen, wird der Texteditor oder das Tabellenkalkulationsprogramm nicht überprüfen, ob Sie diesen Konventionen korrekt gefolgt sind. Es liegt an Ihnen, diese Konventionen richtig zu verfolgen.
- Umwandlung eines Tabellenblatts nach dieser Konvention in eine csv-Datei (eine NCCSV-Datei) wird am Ende aller anderen Zeilen als der CSV-Datenzeilen zu zusätzlichen Kommas führen. Ignoriere sie. Die Software konvertiert dann NCCSV-Dateien in.ncDateien werden sie ignorieren.
- Wenn eine NCCSV-Datei am Ende von Zeilen überschüssige Kommas hat, können Sie sie entfernen, indem Sie die NCCSV-Datei in eineNetCDFDatei und dann die KonvertierungNetCDFDatei zurück in eine NCCSV-Datei.
- Wenn Sie versuchen, die Datei NCCSV in eine zu konvertierenNetCDFDatei, einige Fehler werden von der Software erkannt und erzeugt Fehlermeldungen, wodurch die Konvertierung zu scheitern. Andere Probleme sind schwer oder unmöglich zu fangen und erzeugt keine Fehlermeldungen oder Warnungen. Sonstige Probleme (z.B. überschüssige Kommas am Ende der Zeilen) wird ignoriert. Der Dateikonverter wird nur minimale Überprüfung der Korrektheit des resultierendenNetCDFDatei, z.B. in Bezug auf CF-Compliance. Es ist die Aufgabe des Datei-Erstellers und des Datei-Benutzers zu überprüfen, ob die Ergebnisse der Konvertierung beliebig und korrekt sind. Zwei Möglichkeiten zu prüfen sind:
- Drucken Sie den Inhalt des.ncDatei mit ncdump ( https://linux.die.net/man/1/ncdump ) .
- Inhalt der Daten inERDDAP.
Änderungen
- Änderungen Einführung in v1.10 (April 2020) :
- Unterstützung für ubyte, ushort, uint, ulong.