NCCSV -
ANetCDF-Caractéristiques de fichiers ASCII CSV compatibles, Version 1.10
Bob Simons et Steve Hankin "NCCSV" de Bob Simons et Steve Hankin est sous licenceCC PAR 4,0
Présentation
Ce document spécifie un format de fichier texte CSV ASCII qui peut contenir toutes les informations (métadonnées et données) qui peuvent être trouvés dans uneNetCDF .ncfichier qui contient une table de données de type CSV. L'extension de fichier pour un fichier texte ASCII CSV suivant cette spécification doit être .csv afin qu'il puisse être lu facilement et correctement dans les programmes de tableurs comme Excel et Google Sheets. Bob Simons écrira un logiciel pour convertir un fichier NCCSV en unNetCDF-3 (et peut-être aussiNetCDF-4) .ncfichier, et l'inverse, sans perte d'information. Bob Simons a modifiéERDDAP™pour prendre en charge la lecture et l'écriture de ce type de fichier.
Le format NCCSV est conçu de sorte que les logiciels de tableur tels qu'Excel et Google Sheets puissent importer un fichier NCCSV comme fichier csv, avec toutes les informations dans les cellules de la tableur prêt à être édité. Ou, un tableur peut être créé à partir de zéro suite aux conventions du CCNSV. Quelle que soit la source de la feuille de calcul, si elle est ensuite exportée comme fichier .csv, elle sera conforme aux spécifications du CCNSV et aucune information ne sera perdue. Les seules différences entre les fichiers CCNSV et les fichiers de tableurs analogues qui suivent ces conventions sont :
- Les fichiers NCCSV ont des valeurs sur une ligne séparée par des virgules. Les feuilles de calcul ont des valeurs sur une ligne dans les cellules adjacentes.
- Les chaînes des fichiers NCCSV sont souvent entourées de guillemets doubles. Les chaînes de tableurs ne sont jamais entourées de guillemets doubles.
- Doubles citations internes (") dans les chaînes dans les fichiers CCNSV apparaissent comme 2 guillemets doubles. Les doubles citations internes dans les feuilles de calcul apparaissent comme 1 double citation.
VoirFeuille de calculsection ci-dessous pour plus d'informations.
Recyclable
Comme les fichiers CSV en général, les fichiers NCCSV sont streamables. Ainsi, si un NCSV est généré à la volée par un serveur de données commeERDDAP™, le serveur peut commencer à diffuser les données vers le demandeur avant que toutes les données aient été recueillies. C'est une caractéristique utile et souhaitable.NetCDFles fichiers, par contre, ne sont pas streamables.
ERDDAP™
Cette spécification est conçue de manière à ce que les fichiers CCNSV et.ncles fichiers qui peuvent être créés à partir d'eux peuvent être utilisés par unERDDAP™serveur de données (parEDDTableFromNccsvFilesetEDDTableFromNcFilestypes de données) , mais cette spécification est externe àERDDAP.ERDDAP™a plusieurs attributs globaux requis et de nombreux attributs globaux et variables recommandés, principalement basés sur les attributs CF et ACDD (voir /docs/serveur-admin/données#attributs globaux) .
Solde
La conception du format CCNSV est un équilibre entre plusieurs exigences :
- Les fichiers doivent contenir toutes les données et métadonnées figurant dans un tableau.NetCDFfichier, y compris les types de données spécifiques.
- Les fichiers doivent pouvoir être lus et ensuite écrits sur un tableur sans perte d'information.
- Les fichiers doivent être faciles à créer, à modifier, à lire et à comprendre.
- Les fichiers doivent pouvoir être analysés sans ambiguïté par des programmes informatiques.
Si certaines exigences de ce document semblent étranges ou difficiles, il est probablement nécessaire de satisfaire à l'une de ces exigences.
Autres spécifications
Cette spécification se réfère à plusieurs autres spécifications et bibliothèques avec lesquelles elle est conçue, mais cette spécification ne fait partie d'aucune de ces autres spécifications, et n'a pas besoin de modifications, ni de conflit avec elles. Si un détail relatif à l'une de ces normes n'est pas précisé ici, voir la spécification correspondante. Cela comprend notamment:
- La Convention des Attributs pour la Découverte des Données (ACDD) Norme de métadonnées: https://wiki.esipfed.org/Attribute\_Convention\_for\_Data\_Discovery\_1-3 .
- Climat et prévisions (FC) Norme de métadonnées: https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html .
- LesNetCDFGuide de l'utilisateur (NUCEAU) : https:///docs.unidata.ucar.edu/netcdf-java/current/userguide/index.html .
- LesNetCDFbibliothèques de logiciels commeNetCDF-java etNetCDF-c: https://www.unidata.ucar.edu/software/netcdf/ . Ces bibliothèques ne peuvent pas lire les fichiers CCNSV, mais elles peuvent lire.ncfichiers créés à partir de fichiers NCCSV.
Notation
Dans cette spécification, entre parenthèses,\[ \], indiquer les éléments facultatifs.
Structure du fichier
Un fichier CCNSV complet comprend deux sections : la section des métadonnées, suivie de la section des données.
Les fichiers CCNSV ne doivent contenir que des caractères ASCII 7 bits. Pour cette raison, le jeu de caractères ou l'encodage utilisé pour écrire et lire le fichier peut être tout jeu de caractères ou l'encodage compatible avec le jeu de caractères ASCII 7 bits, par exemple ISO-8859-1.ERDDAP™lit et écrit les fichiers NCCSV avec le charset ISO-8859-1.
Les fichiers CCNSV peuvent utiliser l'une ou l'autre nouvelle ligne (\n) (qui est courant sur les ordinateurs Linux et Mac OS X) retour plus nouvelle ligne (\r\n) (qui est commun sur les ordinateurs Windows) mais pas les deux.
.nccsvMétadonnées
Lorsque le créateur et le lecteur s'y attendent, il est également possible et parfois utile de faire une variante d'un fichier NCCSV qui ne contient que la section métadonnées (y compris les\*END\_METADATA\*ligne) . Le résultat fournit une description complète des attributs du fichier, des noms de variables et des types de données, servant ainsi le même but que les réponses .das plus .dds d'unOPeNDAPserveur.ERDDAP™retournera cette modification si vous demandez un fichier Type=.nccsvMétadonnées d'unERDDAP™ensemble de données.
Section des métadonnées
Dans un fichier CCNSV, chaque ligne de la section des métadonnées utilise le format
variable Dénomination,attribut Dénomination,valeur1\[Valeur2\]\[Valeur3\]\[Valeur4\]\[...\]
Les espaces avant ou après les éléments ne sont pas autorisés parce qu'ils causent des problèmes lors de l'importation du fichier dans les programmes de tableur.
Conventions
La première ligne d'un fichier CCNSV est la première ligne de la section des métadonnées et doit comporter un\GLOBAL\attribut Conventions énumérant toutes les conventions utilisées dans le fichier comme une chaîne contenant une liste CSV, par exemple: \GLOBAL\"Les conventions."COARDS, CF-1.6, ACDD-1.3, CCNSV-1.1" L'une des conventions énumérées doit être le CCNSV-1.1, qui fait référence à la version actuelle de cette spécification.
END_METADATA
La fin de la section métadonnées d'un fichier CCNSV doit être indiquée par une ligne avec seulement \END\_METADATA\
Il est recommandé mais non exigé que tous les attributs d'une variable donnée apparaissent sur les lignes adjacentes de la section des métadonnées. Si un fichier CCNSV est converti enNetCDFfichier, l'ordre que les noms variables apparaissent en premier dans la section métadonnées sera l'ordre des variables dans leNetCDFfichier.
Les lignes blanches optionnelles sont autorisées dans la section des métadonnées après la première ligne\GLOBAL\ ConventionsInformations (voir ci-dessous) et avant la dernière ligne avec\END\_METADATA\.
Si un tableur est créé à partir d'un fichier CCNSV, la section des données des métadonnées apparaîtra avec les noms de variables dans la colonne A, les noms d'attributs dans la colonne B et les valeurs dans la colonne C.
Si un tableur suivant ces conventions est enregistré comme fichier CSV, il y aura souvent des virgules supplémentaires à la fin des lignes dans la section métadonnées. Le logiciel qui convertit les fichiers NCCSV en.ncfichiers ignoreront les virgules supplémentaires.
variable Dénomination
variable Dénomination est le nom sensible au cas par cas d'une variable dans le fichier de données. Tous les noms de variables doivent commencer par une lettre ASCII 7 bits ou souligner et être composés de lettres ASCII 7 bits, de soulignements et de chiffres ASCII 7 bits.
GLOBAL
La variable spécialeNom\GLOBAL\est utilisé pour désigner les métadonnées mondiales.
attribut Dénomination
attribut Dénomination est le nom sensible au cas par cas d'un attribut associé à une variable ou\GLOBAL\. Tous les noms d'attributs doivent commencer par une lettre ou un soulignement ASCII 7 bits et être composés de lettres, de soulignement et de chiffres ASCII 7 bits.
BARÈME
L'attribut spécial Dénomination\*BARÈME\*peut être utilisé pour créer une variable de données scalaire et définir sa valeur. Le type de données\*BARÈME\*définit le type de données pour la variable, donc ne spécifiez pas\*DONNÉES\*attribut pour les variables scalaires. Notez qu'il ne doit pas y avoir de données pour la variable scalaire dans la section Données du fichier CCNSV.
Par exemple, pour créer une variable scalaire nommée "ship" avec la valeur "Okeanos Explorer" et un attribut cf\_role, utilisez : navire,\BARÈME\"Okeanos Explorer" ship,cf\_role,trajectoire\_id Quand une variable de données scalaire est lue dansERDDAP™, la valeur scalaire est convertie en colonne dans la table de données avec la même valeur à chaque ligne.
valeur
valeur est la valeur de l'attribut métadonnées et doit être un tableau avec un ou plusieurs octets, ubyte, court, ushort, int, uint, long, ulong, flotteur, double, string ou char. Aucun autre type de données n'est pris en charge. Les attributs sans valeur seront ignorés. S'il y a plus d'une sous-valeur, les sous-valeurs doivent toutes être du même type de données et séparées par des virgules, par exemple: sst,actual\_range,0,17f,23.58f S'il y a plusieurs valeurs de chaîne, utilisez une seule chaîne avec\n (nouvelle ligne) caractères séparant les sous-chaînes.
Les définitions des types de données d'attribut sont les suivantes:
octet
- valeurs de l'attribut octet (8 bits, signé) doit être écrit avec le suffixe 'b', p.ex. -7b, 0b, 7b . La plage des valeurs d'octets valides est de -128 à 127. Un nombre qui ressemble à un octet mais qui est invalide (Par exemple, 128b) sera converti en une valeur manquante ou générera un message d'erreur.
uoctet
- Valeurs de l'attribut ubyte (8 bits, non signé) doit être écrit avec le suffixe 'ub', p.ex. 0ub, 7ub, 250ub. La plage des valeurs d'octets valides est de 0 à 255. Un nombre qui ressemble à un ubyte mais qui est invalide (Par exemple 256ub) sera converti en une valeur manquante ou générera un message d'erreur. Lorsque c'est possible, utiliser octet au lieu d'ubyte, car de nombreux systèmes ne supportent pas les octets non signés (Par exemple, les attributsNetCDF-3 fichiers) .
courte
- valeurs de l'attribut court (16 bits, signé) doivent être écrites avec le suffixe 's', par exemple -30000s, 0s, 30000s. La plage de valeurs courtes valides est de -32768 à 32767. Un nombre qui ressemble à un court mais qui est invalide (Par exemple, 32768s) sera converti en une valeur manquante ou générera un message d'erreur.
ucourt
- Valeurs de l'attribut ucourt (16 bits, non signé) doivent être écrits avec le suffixe «nous», par exemple 0us, 30000us, 60000us. La plage de valeurs courtes valides est de 0 à 65535. Un nombre qui ressemble à un ushort mais qui est invalide (par exemple 65536us) sera converti en une valeur manquante ou générera un message d'erreur. Lorsque c'est possible, utiliser court au lieu de ushort, parce que de nombreux systèmes ne supportent pas les octets non signés (Par exemple, les attributsNetCDF-3 fichiers) .
Int
- valeurs d'attribut int (32 bits, signé) doivent être écrits comme des int JSON sans point décimal ou exposant, mais avec le suffixe 'i', p.ex. -12067978i, 0i, 12067978i. La plage des valeurs d'int valides est de -2147483648 à 2147483647. Un nombre qui ressemble à un int mais qui est invalide (Par exemple, 2147483648i) sera converti en une valeur manquante ou générera un message d'erreur.
uint
- Valeurs de l'attribut uint (32 bits, non signé) doivent être écrits en tant qu'ints JSON sans point décimal ou exposant, mais avec le suffixe «ui», p.ex. 0ui, 12067978ui, 4123456789ui. La plage des valeurs d'entrée valides est de 0 à 4294967295. Un nombre qui ressemble à un uint mais qui est invalide (Par exemple, 2147483648ui) sera converti en une valeur manquante ou générera un message d'erreur. Dans la mesure du possible, utiliser int au lieu d'uint, car de nombreux systèmes ne supportent pas les octets non signés (Par exemple, les attributsNetCDF-3 fichiers) .
longue
- valeurs des attributs longs (64 bits, signé, actuellement soutenu par le NUG etERDDAP™mais pas encore soutenu par les FC) doivent être écrits sans point décimal et avec le suffixe «L», p.ex. -12345678987654321L, 0L, 12345678987654321L. Si vous utilisez le logiciel de conversion pour convertir un fichier NCCSV avec des valeurs longues en unNetCDF-3 fichier, toutes les valeurs longues seront converties en valeurs doubles. La plage des valeurs longues valides est de -9223372036854775808 à 9223372036854775807. Un nombre qui ressemble à un long mais qui est invalide (Par exemple, 9223372036854775808L) sera converti en une valeur manquante ou générera un message d'erreur. Lorsque c'est possible, utilisez le double au lieu d'un long, parce que beaucoup de systèmes ne supportent pas longtemps (Par exemple,NetCDF-3 fichiers) .
longue
- Valeurs de l'attribut ulong (64 bits, non signé, actuellement soutenu par le NUG etERDDAP™mais pas encore soutenu par les FC) doivent être écrites sans point décimal et avec le suffixe «uL», p.ex. 0uL, 12345678987654321uL, 9007199254740992uL. Si vous utilisez le logiciel de conversion pour convertir un fichier NCCSV avec des valeurs longues en unNetCDF-3 fichier, toutes les valeurs longues seront converties en valeurs doubles. La plage des valeurs longues valides est de 0 à 18446744073709551615. Un nombre qui ressemble à un ulong mais qui est invalide (Par exemple, 18446744073709551616uL) sera converti en une valeur manquante ou générera un message d'erreur. Lorsque c'est possible, utilisez le double au lieu d'un long, parce que de nombreux systèmes ne supportent pas le long signé ou non signé (Par exemple,NetCDF-3 fichiers) .
flotteur
- Valeurs des attributs flottants (32 bits) doit être écrit avec le suffixe «f» et peut avoir un point décimal et/ou un exposant, par exemple, 0f, 1f, 12.34f, 1e12f, 1.23e+12f, 1.23e12f, 1.87E-7f. Utiliser NaNf pour un flotteur NaN (manquant) valeur. La portée des flotteurs est d'environ +/-3.40282347E+38f (~7 chiffres décimaux significatifs) . Un nombre qui ressemble à un flotteur mais qui est invalide (Par exemple, 1,0e39f) sera converti en une valeur manquante ou générera un message d'erreur.
double
- valeurs du double attribut (64 bits) doit être écrit avec le suffixe 'd' et peut avoir un point décimal et/ou un exposant, p.ex. 0d, 1d, 12.34d, 1e12d, 1.23e+12d, 1.23e12d, 1.87E-7d. Utiliser NaNd pour un double NaN (manquant) valeur. La plage des doubles est d'environ +/- 1,79769313486231570E+308d (~15 chiffres décimaux significatifs) . Un nombre qui ressemble à un double mais qui est invalide (Par exemple, 1,0e309d) sera converti en une valeur manquante ou générera un message d'erreur.
Chaîne
- Les valeurs de l'attribut chaîne sont une séquence de caractères UCS-2 (i.e., caractères Unicode à 2 octets, comme dansJava) , qui doit être écrit comme ASCII 7 bits, des chaînes de type JSON pour que les caractères non ASCII puissent être spécifiés.
- Double citations (") doit être codé comme deux guillemets doubles ("") . C'est ce que les programmes de tableur exigent lors de la lecture des fichiers .csv. C'est ce que les programmes de tableur écrire quand vous enregistrez un tableur comme un fichier .csv.
- Les caractères spéciaux en code arrière JSON doivent être encodés comme dans JSON (notamment\n(newline), mais aussi \\ (backslash), \f (formfeed), \t (tab), \r (retour de chargement) ou avec la\u - Oui. syntaxe. Dans un tableur, n'utilisez pas Alt Enter pour spécifier une nouvelle ligne dans une cellule de texte; utilisez plutôt\n (2 caractères : backslash et 'n ') pour indiquer une nouvelle ligne.
uhhhh
- \u hhhh - Tous les caractères inférieurs au caractère #32 ou supérieurs au caractère #126, et non autrement encodés, doivent être encodés avec la syntaxe \u hhhh*, où hhhh est le numéro hexadécimal à 4 chiffres du caractère, par exemple, le signe Euro est \u20AC. Voir les pages de code référencées à https://en.wikipedia.org/wiki/Unicode pour trouver les numéros hexadécimaux associés à des caractères Unicode spécifiques, ou utiliser une bibliothèque logicielle.
- Si la chaîne a un espace au début ou à la fin, ou inclut " (double citation) ou une virgule, ou contient des valeurs qui seraient autrement interprétées comme un autre type de données (Par exemple, une auberge) , ou est le mot "null", la chaîne entière doit être jointe en guillemets doubles; sinon, contrairement à JSON, les guillemets doubles enclos sont facultatifs. Nous vous recommandons: en cas de doute, enfermez l'ensemble de la chaîne en guillemets doubles. Les espaces au début ou à la fin d'une corde sont fortement découragés.
- Pour l'instant, l'utilisation de caractères supérieurs à 255 est découragée. Le CCNV les soutient.ERDDAP™les soutient en interne. Certains types de fichiers de sortie les supportent (Par exemple,.jsonet.nccsv) . Mais de nombreux types de fichiers de sortie ne les supportent pas. Par exemple,NetCDF-3 fichiers ne supportent pas ces caractères parce queNetCDFles fichiers utilisent des caractères de 1-octet et CF n'a actuellement pas de système pour spécifier comment les caractères Unicode sont encodés dansNetCDFChaînes (Par exemple, UTF-8) . Cela s'améliorera probablement avec le temps.
Char
- Les valeurs de l'attribut char sont un seul caractère UCS-2 (i.e., caractères Unicode à 2 octets, comme dansJava) , qui doit être écrit en caractères ASCII 7 bits, comme JSON pour que d'autres caractères puissent être spécifiés (voir la définition de chaîne ci-dessus pour l'encodage de caractères spéciaux, avec l'ajout de l'encodage d'un seul devis comme \ ') . Les valeurs de l'attribut Char doivent être jointes en guillemets simples (les citations intérieures) et doubles citations (les citations extérieures) , par exemple, "'a'", "'""" (un caractère double citation) , "'\''" (un caractère de citation unique) , "'\t'" (un onglet) "\u20AC" (un caractère euro) . Ce système d'utilisation de guillemets simples et doubles est étrange et lourd, mais c'est un moyen de distinguer les valeurs char de Strings d'une manière qui fonctionne avec des tableurs. Une valeur qui ressemble à un char mais est invalide générera un message d'erreur. Comme dans le cas des cordes, l'utilisation de caractères supérieurs à 255 est actuellement découragée.
Suffixe
Notez que dans la section des attributs d'un fichier CCNSV, toutes les valeurs d'attribut numériques doivent avoir une lettre suffixe (Par exemple, "b") pour identifier le type de données numériques (Par exemple, octet) . Mais dans la section de données d'un fichier CCNSV, les valeurs numériques de données ne doivent jamais avoir ces lettres suffixes (à l'exception de 'L' pour les entiers longs et 'uL' pour les entiers longs) — le type de données est spécifié par\*DONNÉES\*attribut pour la variable.
DONNÉES
Le type de données pour chaquescalairevariable doit être spécifiée par une\*DONNÉES\*attribut qui peut avoir une valeur d'octet, ubyte, court, ushort, int, uint, long, ulong, flotteur, double, chaîne ou char (insensible au cas) . Par exemple, qc\_flag,\DONNÉES\,octet ATTENTION: Préciser le bon\*DONNÉES\*est votre responsabilité. Spécifier le mauvais type de données (Par exemple, int quand vous auriez dû spécifier flotteur) ne générera pas de message d'erreur et pourrait entraîner la perte d'informations (Par exemple, les valeurs du flotteur seront arrondies aux int.) lorsque le fichier NCCSV est lu parERDDAP™ou converties enNetCDFfichier.
Char découragé
L'utilisation des valeurs de données char est découragée parce qu'elles ne sont pas largement supportées dans d'autres types de fichiers. Les valeurs char peuvent être écrites dans la section de données en caractères simples ou en chaînes (notamment, si vous avez besoin d'écrire un caractère spécial) . Si une chaîne est trouvée, le premier caractère de la chaîne sera utilisé comme valeur du char. Les chaînes de longueur zéro et les valeurs manquantes seront converties en caractère \uFFFF. Notez queNetCDFfichiers supportent seulement les caractères d'octet unique, de sorte que tous les caractères supérieurs à char #255 seront convertis en '?' lors de l'écritureNetCDFfichiers. Sauf si un attribut charset est utilisé pour spécifier un autre charset pour une variable char, le charset ISO-8859-1 sera utilisé.
Long et non signé découragé
Bien que de nombreux types de fichiers (Par exemple,NetCDF-4 et json) etERDDAP™long et non signé (uoctet, ushort, uint, ulong) les valeurs, l'utilisation de valeurs longues et non signées dans les fichiers CCNSV est actuellement découragée parce qu'elles ne sont pas soutenues actuellement par Excel, CF etNetCDF- Trois dossiers. Si vous voulez spécifier des valeurs longues ou non signées dans un fichier CCNSV (ou dans la feuille de calcul Excel correspondante) , vous devez utiliser le suffixe 'L' pour qu'Excel ne traite pas les nombres comme des nombres flottants avec une précision inférieure. Actuellement, si un fichier CCNSV est converti enNetCDF-3.ncles valeurs de fichiers, de données longues et de données longues seront converties en valeurs doubles, ce qui entraînera une perte de précision pour des valeurs très importantes (moins de -2^53 pour le long, ou plus de 2^53 pour le long et le long) . EnNetCDF-3.ncfichiers, ubyte, ushort, et uint variables apparaissent comme octet, court, et int avec l'attribut \_Unsigned=true metata. EnNetCDF-3.ncfichiers, ubyte, ushort, et uint attributs apparaissent comme octet, court, et int attributs contenant la valeur de complément de deux correspondant (Par exemple, 255ub apparaît comme -1b) . C'est évidemment un problème, de sorte que les types de données signés devraient être utilisés au lieu de types de données non signés chaque fois que possible.
FC, ACDD, etERDDAP™Métadonnées
Comme il est prévu que la plupart des fichiers du CCNSV,.ncfichiers créés à partir d'eux, sera lu dansERDDAP, il est fortement recommandé que les fichiers CCNSV incluent les attributs de métadonnées requis ou recommandés parERDDAP™(voir /docs/serveur-admin/données#attributs globaux) . Les attributs proviennent presque tous des normes de métadonnées CF et ACDD et servent à décrire correctement l'ensemble de données (qui, quoi, quand, où, pourquoi,) à quelqu'un qui autrement ne sait rien de l'ensemble de données. D'une importance particulière, presque toutes les variables numériques devraient avoir un attribut d'unités avec unUDUNITS-valeur compatible, p.ex., sst, unités, degré\_C
Il est bon d'inclure d'autres attributs qui ne sont pas des normes FC ou ACDD ou deERDDAP.
La Section des données
Structure
La première ligne de la section de données doit comporter une liste de noms de variables sensibles aux cas et séparés par des virgules. Toutes les variables de cette liste doivent être décrites dans la section métadonnées, et vice versa. (autres que\GLOBAL\attributs et\BARÈME\variables) .
La deuxième à travers l'avant-dernière ligne de la section de données doit avoir une liste de valeurs séparées par des virgules. Chaque ligne de données doit avoir le même nombre de valeurs que la liste des noms de variables séparées par des virgules. Les espaces avant ou après les valeurs ne sont pas permis parce qu'ils causent des problèmes lors de l'importation du fichier dans les programmes de tableur. Chaque colonne de cette section ne doit contenir que des valeurs de\*DONNÉES\*spécifiée pour cette variable par la\*DONNÉES\*attribut pour cette variable. Contrairement à la section des attributs, les valeurs numériques de la section des données ne doivent pas comporter de lettres suffixes pour indiquer le type de données. Contrairement à la section des attributs, les valeurs de char dans la section des données peuvent omettre les guillemets simples qui ne sont pas nécessaires pour la désambiguer. (Par conséquent, ',' et '\'' doivent être cités comme indiqué ici) . Il peut y avoir n'importe quel nombre de ces lignes de données dans un fichier CCNSV, mais actuellementERDDAP™ne peut lire que des fichiers NCCSV contenant jusqu'à 2 milliards de lignes. En général, il est recommandé de diviser de grands ensembles de données en plusieurs fichiers de données CCNSV avec moins d'un million de lignes chacune.
FIN_DATA
La fin de la section de données doit être indiquée par une ligne avec seulement \END\_DATA\
S'il y a du contenu supplémentaire dans le fichier NCCSV après\*END\_DATA\*ligne, il sera ignoré lorsque le fichier NCCSV est converti en un.ncfichier. Ce contenu est donc découragé.
Dans un tableur suivant ces conventions, les noms de variables et les valeurs de données seront dans plusieurs colonnes. Voir l'exemple ci-dessous.
Valeurs manquantes
Les valeurs numériques manquantes peuvent être écrites comme une valeur numérique identifiée parmissing\_valueou \_FillValue attribut pour cette variable. Par exemple, voir la deuxième valeur de cette ligne de données : Bell M. Shimada 99 123.4 C'est la façon recommandée de gérer les valeurs manquantes pour les variables octet, ubyte, courte, ushort, int, uint, longue et ulong.
Les valeurs de flotteur ou de double NaN peuvent être écrites comme NaN. Par exemple, voir la deuxième valeur de cette ligne de données : Bell M. Shimada,NaN,123,4
Les chaînes et les valeurs numériques manquantes peuvent être indiquées par un champ vide. Par exemple, voir la deuxième valeur de cette ligne de données : Bell M. Shimada, 123.4
Pour les variables octet, ubyte, courte, ushort, int, uint, longue et ulong, l'utilité du convertisseur CCNSV etERDDAP™convertira un champ vide en la valeur maximale autorisée pour ce type de données (Par exemple 127 pour les octets) . Si vous faites cela, assurez-vous d'ajouter unmissing\_valueou \_FillValue attribut pour cette variable pour identifier cette valeur, par exemple, variable Dénomination Valeur de remplissage,127b Pour les variables flottantes et doubles, un champ vide sera converti en NaN.
Valeurs de l'heure de date
Valeurs DateHeure (y compris les valeurs de date qui n'ont pas de composante temporelle) peut être représenté par des nombres ou des chaînes dans des fichiers CCNSV. Une variable dateTime donnée peut seulement avoir des valeurs String ou seulement des valeurs numériques, pas les deux. Le logiciel NCCSV convertira les valeurs de la date de chaîne en date numérique Valeurs temporelles lors de la création.ncfichiers (selon les exigences des FC) . La date des chaînesLes valeurs temporelles ont l'avantage d'être facilement lisibles par les humains.
Les valeurs DateTime représentées par des valeurs numériques doivent avoir un attribut unit qui spécifie " unités depuis date Heure " selon les exigences des FC et précisées parUDUNITS, par exemple, heure,unités,secondes depuis 1970-01-01T00:00:00Z
Les valeurs DateTime représentées comme des valeurs de chaîne doivent avoir une chaîne\*DONNÉES\*attribut et un attribut units qui spécifie une date Modèle de temps tel que spécifié par laJavaDateTimeFormatière classe ( https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html ) . Par exemple, temps, unités,yyyy-MM-dd'T'HH:mm:ssZ Toutes les valeurs de date pour une variable donnée doivent utiliser le même format. Dans la plupart des cas, le modèle dateTime dont vous avez besoin pour l'attribut unit sera une variation de l'un de ces formats:
- yyyy-MM-dd'T'HH:mm:ss. SSSZ — qui est la norme ISO 8601:2004 (E) date Format horaire. Vous pouvez avoir besoin d'une version abrégée de ceci, par exemple,yyyy-MM-dd'T'HH:mm:ssZ (le seul format recommandé) ouyyyy-MM-dd. Si vous changez le format de vos valeurs dateTime, le CCNSV vous recommande fortement de modifier ce format (peut-être raccourci) . C'est le format quiERDDAP™utilisera quand il écrit des fichiers NCCSV.
- yyyyMMddHHmmss.SSS — qui est la version compacte de la date ISO 8601:2004 Format horaire. Vous pouvez avoir besoin d'une version abrégée de ceci, p.ex. aaayMMdd.
- M/j/aaaa H:mm:ss. SSS — qui gère les dates et les dates de style américain, comme "3/23/2017 16:22:03.000". Vous pouvez avoir besoin d'une version abrégée de ceci, par exemple, M/d/aaaa.
- yyyyDDDHHmmssSSS — qui est l'année plus le jour de l'année zéro-remboursé (Par exemple, 001 = 1er janvier 365 = 31 décembre d'une année où il n'y a pas de congé; cela s'appelle parfois à tort la date de Julian) . Vous pourriez avoir besoin d'une version abrégée de ceci, par exemple, yyyDDD .
Précision
Lorsqu'une bibliothèque de logiciels convertit une.ncfichier dans un fichier CCNSV, toute date Les valeurs temporelles seront écrites sous forme de cordes avec la norme ISO 8601:2004 (E) date Format horaire, p.ex., 1970-01-01T00:00:00Z . Vous pouvez contrôler la précision avec leERDDAP-attribut spécifiquetime\_precision. Voir /docs/serveur-admin/données#time\_precision.
fuseau horaire
Le fuseau horaire par défaut pour la date Les valeurs temporelles sont lesZulu (ou GMT) fuseau horaire, qui n'a pas de périodes d'heure. Si une variable dateTime a des valeurs dateTime d'un fuseau horaire différent, vous devez spécifier ceci avec leERDDAP-attribut spécifiquetime\_zone. C'est une exigenceERDDAP™(voir /docs/serveur-admin/données#time\_zone) .
Valeurs du degré
Comme l'exigent les FC, toutes les valeurs de degré (Par exemple, pour la longitude et la latitude) doit être spécifié comme des valeurs doubles décimales, non pas comme une chaîne de degré°min'sec" ou comme des variables séparées pour les degrés, minutes, secondes. Les indicateurs de direction N, S, E et W ne sont pas autorisés. Utiliser des valeurs négatives pour les longitudes ouest et sud.
DSG Types de fonctionnalités
Un fichier CCNSV peut contenir une géométrie d'échantillonnage discrète des FC ( https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html#discrete-sampling-geometries ) données. Ce sont les attributs qui font que cela fonctionne:
- Comme l'exigent les FC, le fichier CCNSV doit inclure une ligne dans la section sur les métadonnées qui identifie les\GLOBAL\ featureTypeattribut, par exemple, \GLOBAL\,featureType,trajectoire
- Pour utilisation dansERDDAP™, le fichier CCNSV doit inclure une ou plusieurs lignes dans la section des métadonnées identifiant les variables cf\_role=...\_id, p. ex., ship,cf\_role,trajectoire\_id Ceci est facultatif pour les FC, mais requis dans le CCNSV.
- Pour utilisation dansERDDAP™, le fichier CCNSV doit inclure une ligne ou des lignes dans la section des métadonnées identifiant les variables associées à chaque série de temps, trajectoire ou profil, comme l'exigeERDDAP™(voir /docs/serveur-admin/datasets#cdm\_data\_type), par exemple, \GLOBAL\,cdm\_trajectoire\_variables,"navire" ou \GLOBAL\,cdm\_timeseries\_variables",station\_id,lat,lon"
Fichier exemple
Voici un exemple de fichier qui démontre plusieurs des caractéristiques d'un fichier CCNSV:
\\*GLOBAL\\*,Conventions,"COARDS, CF-1.6, ACDD-1.3, NCCSV-1.1"
\\*GLOBAL\\*,cdm\\_trajectory\\_variables,"ship"
\\*GLOBAL\\*,creator\\_email,erd.data@noaa.gov
\\*GLOBAL\\*,creator\\_name,Bob Simons
\\*GLOBAL\\*,creator\\_type,person
\\*GLOBAL\\*,creator\\_url,https://www.pfeg.noaa.gov
\\*GLOBAL\\*,featureType,trajectory
\\*GLOBAL\\*,infoUrl,https://erddap.github.io/docs/user/nccsv-1.10
\\*GLOBAL\\*,institution,"NOAA NMFS SWFSC ERD, NOAA PMEL"
\\*GLOBAL\\*,license,"""NCCSV Demonstration"" by Bob Simons and Steve Hankin is
licensed under CC BY 4.0, https://creativecommons.org/licenses/by/4.0/ ."
\\*GLOBAL\\*,keywords,"NOAA, sea, ship, sst, surface, temperature, trajectory"
\\*GLOBAL\\*,standard\\_name\\_vocabulary,CF Standard Name Table v55
\\*GLOBAL\\*,subsetVariables,"ship"
\\*GLOBAL\\*,summary,"This is a paragraph or two describing the dataset."
\\*GLOBAL\\*,title,"NCCSV Demonstration"
ship,\\*DATA\\_TYPE\\*,String
ship,cf\\_role,trajectory\\_id
time,\\*DATA\\_TYPE\\*,String
time,standard\\_name,time
time,units,"yyyy-MM-dd'T'HH:mm:ssZ"
lat,\\*DATA\\_TYPE\\*,double
lat,units,degrees\\_north
lon,\\*DATA\\_TYPE\\*,double
"lon","units","degrees\\_east"
status,\\*DATA\\_TYPE\\*,char
status,comment,"From http://some.url.gov/someProjectDocument , Table C"
testByte,\\*DATA\\_TYPE\\*,byte
testByte,units,1
testUByte,\\*DATA\\_TYPE\\*,ubyte
testUByte,units,1
testLong,\\*DATA\\_TYPE\\*,long
testLong,units,1
testULong,\\*DATA\\_TYPE\\*,ulong
testULong,units,1
sst,\\*DATA\\_TYPE\\*,float
sst,standard\\_name,sea\\_surface\\_temperature
sst,actual\\_range,0.17f,23.58f
sst,units,degree\\_C
sst,missing\\_value,99f
sst,testBytes,-128b,0b,127b
sst,testShorts,-32768s,0s,32767s
sst,testInts,-2147483648i,0i,2147483647i
sst,testLongs,-9223372036854775808L,0L,9223372036854775807L
sst,testFloats,-3.40282347e38f,0f,3.40282347E+38f
sst,testDoubles,-1.79769313486231570e308d,0d,1.79769313486231570E+308d
sst,testChars,"','","'""'","'\\u20AC'"
sst,testStrings," a~,\\n'z""\\u20AC"
sst,testUBytes,0ub,127ub,255ub
sst,testUInts,0ui,2147483647ui,4294967295ui
sst,testULongs,0uL,9223372036854775807uL,18446744073709551615uL
sst,testUShorts,0us,32767us,65535us
\\*END\\_METADATA\\*
ship,time,lat,lon,status,testByte,testUByte,testLong,testULong,sst
Bell M. Shimada,2017-03-23T00:45:00Z,28.0002,-130.2576,A,-128, 0,-9223372036854775808L,0uL,10.9
Bell M. Shimada,2017-03-23T01:45:00Z,28.0003,-130.3472,\\u20AC,0,127,-9007199254740992L,9223372036854775807uL,10.0
"Bell M. Shimada","2017-03-23T02:45:00Z",28.0001,-130.4305,"'\\t'",126,254,9223372036854775806L,18446744073709551614uL,99
"Bell M. Shimada",2017-03-23T12:45:00Z,27.9998,-131.5578,"'""'",127,255,9223372036854775807L,18446744073709551615uL,NaN
Remarques:
- Ce fichier exemple comprend de nombreux cas difficiles (Par exemple, les variables char et longues et les valeurs de chaînes difficiles) . La plupart des fichiers CCNSV seront beaucoup plus simples.
- La ligne de licence est divisée en deux lignes ici, mais n'est qu'une ligne dans le fichier échantillon.
- \u20AC est l'encodage du caractère Euro et \u00FC est l'encodage de ü.
- Nombreux Les chaînes de l'exemple sont jointes par des guillemets doubles, même s'ils n'ont pas à être, par exemple, de nombreux attributs globaux, dont le titre, l'attribut lon units et la 3e ligne de données.)
- Il serait plus clair et mieux si l'attribut unit pour la variable testLong était écrit en guillemets doubles indiquant qu'il s'agit d'une valeur String. Mais la représentation actuelle (1, sans citations) sera interprété correctement comme une chaîne, pas comme un entier, parce qu'il n'y a pas de suffixe 'i'.
- Contrairement à d'autres types de données numériques, les valeurs longues dans la section de données ont le suffixe ('L') qui identifie leur type de données numériques. Ceci est nécessaire pour empêcher les tableurs d'interpréter les valeurs comme des nombres flottants et ainsi perdre de la précision.
Feuilles de calcul
Dans un tableur, comme dans un fichier CCNSV :
- Écrire des valeurs d'attributs numériques comme spécifié pour les fichiers NCCSV (Par exemple, avec une lettre suffixe, par exemple « f », pour identifier le type de données de l'attribut) .
- Dans Strings, écrivez tous les caractères moins que le caractère ASCII #32 ou plus que le caractère #126 comme un caractère rétro-slashé de type JSON (Par exemple,\npour newline) ou comme le numéro de caractères Unicode hexadécimal (insensible au cas) avec la syntaxe\u - Oui. (Par exemple, \u20AC pour le signe Euro) . Utilisation\n (2 caractères : backslash et 'n ') pour indiquer une nouvelle ligne, pas Alt Enter.
Les seules différences entre les fichiers du CCNSV et le tableur analogue qui suivent ces conventions sont :
- Les fichiers NCCSV ont des valeurs sur une ligne séparée par des virgules. Les feuilles de calcul ont des valeurs sur une ligne dans les cellules adjacentes.
- Les chaînes des fichiers NCCSV sont souvent entourées de guillemets doubles. Les chaînes de tableurs ne sont jamais entourées de guillemets doubles.
- Doubles citations internes (") dans les chaînes dans les fichiers CCNSV apparaissent comme 2 guillemets doubles. Les doubles citations internes dans les feuilles de calcul apparaissent comme 1 double citation.
Si un tableur suivant ces conventions est enregistré comme un fichier CSV, il y aura souvent des virgules supplémentaires à la fin de beaucoup de lignes. Le logiciel qui convertit les fichiers NCCSV en.ncfichiers ignoreront les virgules supplémentaires.
Excel
Pour importer un fichier CCNSV dans Excel :
- Choisissez Fichier : Ouvrir .
- Changer le type de fichier en fichiers texte (\.prn;\.txt; \*.csv) .
- Faites une recherche dans les répertoires et cliquez sur le fichier NCCSV .csv.
- Cliquez sur Ouvrir .
Pour créer un fichier NCCSV à partir d'un tableur Excel :
- Choisissez Fichier : Enregistrer sous .
- Modifier le type d'enregistrement: pour être CSV (Comma délimité) (*.csv) .
- En réponse à l'avertissement de compatibilité, cliquez sur Oui .
- Le fichier .csv résultant aura des virgules supplémentaires à la fin de toutes les lignes autres que les lignes CSV. Vous pouvez les ignorer.
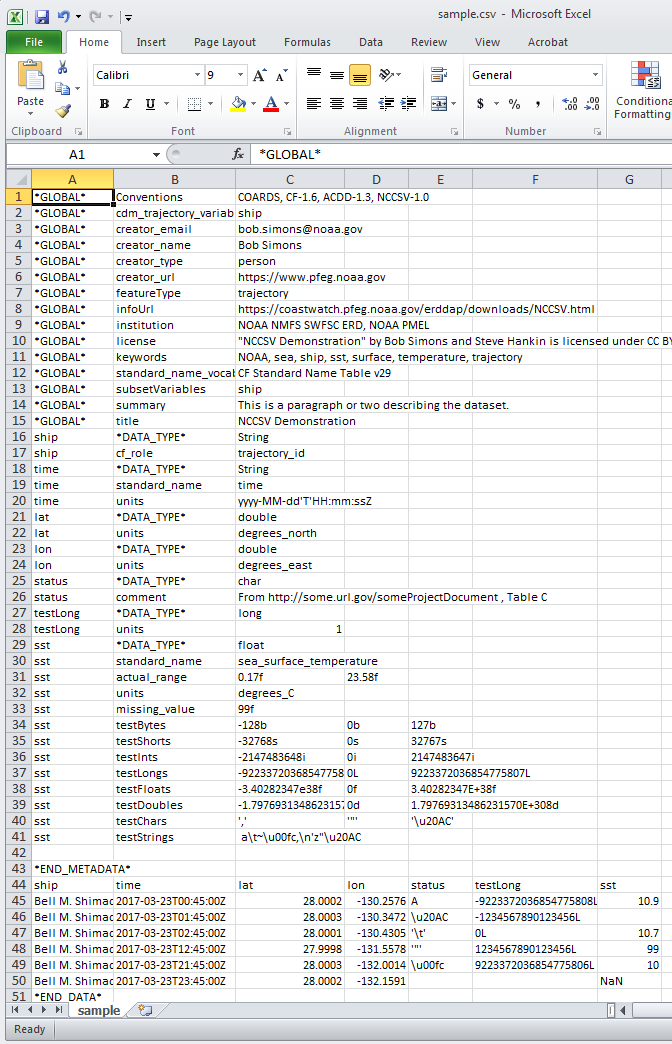
Dans Excel, l'échantillon de fichier NCCSV ci-dessus apparaît comme
Feuilles Google
Pour importer un fichier CCNSV dans Google Sheets :
- Choisissez Fichier : Ouvrir .
- Choisissez de télécharger un fichier et cliquez sur Télécharger un fichier depuis votre ordinateur. Sélectionnez le fichier, puis cliquez sur Ouvrir .
Ou, choisissez My Drive et changez la sélection déroulante de type de fichier à Tous les types de fichier . Sélectionnez le fichier, puis cliquez sur Ouvrir .
Pour créer un fichier NCCSV à partir d'un tableur Feuilles Google :
- Choisissez Fichier : Enregistrer sous .
- Modifier le type d'enregistrement: pour être CSV (Comma délimité) (*.csv) .
- En réponse à l'avertissement de compatibilité, cliquez sur Oui .
- Le fichier .csv résultant aura des virgules supplémentaires à la fin de toutes les lignes autres que les lignes CSV. Ignore-les.
Problèmes/avertissements
- Si vous créez un fichier NCCSV avec un éditeur de texte ou si vous créez un tableur analogue dans un programme de tableur, l'éditeur de texte ou le programme de tableur ne vérifiera pas que vous avez suivi correctement ces conventions. C'est à vous de suivre correctement ces conventions.
- La conversion d'un tableur suivant cette convention en un fichier csv (Ainsi, un fichier NCCSV) sera conduit à des virgules supplémentaires à la fin de toutes les lignes autres que les lignes de données CSV. Ignore-les. Le logiciel convertit ensuite les fichiers NCCSV en.ncles fichiers les ignoreront.
- Si un fichier NCCSV a des virgules excédentaires à la fin des lignes, vous pouvez les supprimer en convertissant le fichier NCCSV en unNetCDFfichier et puis la conversionNetCDFfichier dans un fichier NCCSV.
- Lorsque vous essayez de convertir un fichier NCCSV en unNetCDFfichier, certaines erreurs seront détectées par le logiciel et généreront des messages d'erreurs, causant l'échec de la conversion. D'autres problèmes sont difficiles ou impossibles à attraper et ne généreront pas de messages d'erreur ou d'avertissements. Autres problèmes (Par exemple, les virgules excédentaires à la fin des lignes) seront ignorés. Le convertisseur de fichiers fera seulement un minimum de vérification de l'exactitude du résultatNetCDFdossier, p. ex., concernant la conformité des FC. Il est de la responsabilité du créateur et de l'utilisateur du fichier de vérifier que les résultats de la conversion sont tels que désirés et corrects. Voici deux façons de vérifier :
- Imprimer le contenu.ncfichier avec ncdump ( https://linux.die.net/man/1/ncdump ) .
- Afficher le contenu des données dansERDDAP.
Changements
- Changements Introduit dans v1.10 (Avril 2020) :
- Ajout du support pour ubyte, ushort, uint, ulong.