NCCSV -
ANetCDF-Compatible ASCII CSV File Specification, Versión 1.10
Bob Simons y Steve Hankin "NCCSV" de Bob Simons y Steve Hankin está bajo licenciaCC BY 4.0
Introducción
Este documento especifica un formato de archivo de texto ASCII CSV que puede contener toda la información (metadatos y datos) que se puede encontrar en unNetCDF .ncarchivo que contiene una tabla de datos tipo CSV. La extensión de archivo para un archivo de texto ASCII CSV después de esta especificación debe ser .csv para que pueda leerse fácilmente y correctamente en programas de hoja de cálculo como Excel y Hojas de Google. Bob Simons escribirá software para convertir un archivo NCCSV en unNetCDF-3 (y quizás tambiénNetCDF-4) .ncarchivo, y el reverso, sin pérdida de información. Bob Simons ha modificadoERDDAP™para apoyar la lectura y escritura de este tipo de archivo.
El formato NCCSV está diseñado para que el software de hoja de cálculo como Excel y Google Sheets pueda importar un archivo NCCSV como un archivo csv, con toda la información en las celdas de la hoja de cálculo listas para la edición. O, una hoja de cálculo se puede crear desde cero siguiendo las convenciones NCCSV. Independientemente de la fuente de la hoja de cálculo, si se exporta como archivo .csv, se ajustará a la especificación NCCSV y no se perderá información. Las únicas diferencias entre los archivos NCCSV y los archivos analógicos de hoja de cálculo que siguen estas convenciones son:
- Los archivos NCCSV tienen valores en una línea separada por comas. Las hojas de cálculo tienen valores en una línea en células adyacentes.
- Las cadenas en los archivos NCCSV a menudo están rodeadas de citas dobles. Las cuerdas en hojas de cálculo nunca están rodeadas de citas dobles.
- Cifras dobles internas (") en Strings en archivos NCCSV aparecen como 2 citas dobles. Las citas dobles internas en hojas de cálculo aparecen como 1 doble cita.
Ver elhoja de cálculosección abajo para más información.
Streamable
Como archivos CSV en general, los archivos NCCSV son streamable. Así, si un NCSV es generado en la marcha por un servidor de datos comoERDDAP™, el servidor puede comenzar a transmitir datos al solicitante antes de que se hayan recopilado todos los datos. Esta es una característica útil y deseable.NetCDFLos archivos, por contraste, no son transmisibles.
ERDDAP™
Esta especificación está diseñada para que los archivos NCCSV y los.ncarchivos que se pueden crear de ellos pueden ser utilizados por unERDDAP™servidor de datos (a través deEDDTableDesdeNccsvFilesyEDDTableDesdeNcFilestipos de conjunto de datos) , pero esta especificación es externaERDDAP.ERDDAP™tiene varios atributos globales requeridos y muchos atributos globales y variables recomendados, principalmente basados en atributos CF y ACDD (ver /docs/servidor-admin/datasets#global-atributos).
Saldo
El diseño del formato NCCSV es un balance de varios requisitos:
- Los archivos deben contener todos los datos y metadatos que estarían en un tabularNetCDFarchivo, incluyendo tipos de datos específicos.
- Los archivos deben ser capaces de ser leídos y luego escritos de una hoja de cálculo sin pérdida de información.
- Los archivos deben ser fáciles de crear, editar, leer y comprender.
- Los archivos deben ser capaces de ser analizados inequívocamente por programas informáticos.
Si algún requisito en este documento parece extraño o exigente, es probable que sea necesario cumplir uno de estos requisitos.
Otras especificaciones
Esta especificación se refiere a varias otras especificaciones y bibliotecas con las que está diseñado para trabajar, pero esta especificación no es parte de ninguna de esas otras especificaciones, ni necesita ningún cambio para ellos, ni contradice con ellos. Si un detalle relacionado con uno de estos estándares no se especifica aquí, vea la especificación relacionada. Notablemente, esto incluye:
- El Convenio de Atributo para el Descubrimiento de Dataset (ACDD) metadatos estándar: https://wiki.esipfed.org/Attribute\_Convention\_for\_Data\_Discovery\_1-3 .
- The Climate and Forecast (CF) metadatos estándar: https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html .
- ElNetCDFGuía del usuario (NUG) : https:///docs.unidata.ucar.edu/netcdf-java/current/userguide/index.html .
- ElNetCDFbibliotecas de software comoNetCDF-java yNetCDF-c: https://www.unidata.ucar.edu/software/netcdf/ . Estas bibliotecas no pueden leer archivos NCCSV, pero pueden leer.ncarchivos creados de archivos NCCSV.
- JSON: https://www.json.org/
Notación
En esta especificación, corchetes,\[ \], denota artículos opcionales.
Estructura de archivo
Un archivo NCCSV completo consta de dos secciones: la sección metadatos, seguida de la sección de datos.
Los archivos NCCSV deben contener sólo caracteres ASCII de 7 bits. Debido a esto, el conjunto de caracteres o codificación utilizado para escribir y leer el archivo puede ser cualquier conjunto de caracteres o codificación que sea compatible con el conjunto de caracteres ASCII de 7 bits, por ejemplo, ISO-8859-1.ERDDAP™lee y escribe archivos NCCSV con el charset ISO-8859-1.
Los archivos NCCSV pueden utilizar una nueva línea (\n) (que es común en las computadoras Linux y Mac OS X) o carruajeRetorno más nueva línea (\r\n) (que es común en las computadoras de Windows) como marcadores finales de línea, pero no ambos.
.nccsvMetadatos
Cuando tanto el creador como el lector lo esperan, también es posible y a veces útil hacer una variante de un archivo NCCSV que contiene sólo la sección de metadatos (incluido el\*END\_METADATA\*línea) . El resultado proporciona una descripción completa de los atributos, nombres variables y tipos de datos del archivo, sirviendo así el mismo propósito que las respuestas .das más .dds de unaOPeNDAPservidor.ERDDAP™devolverá esta variación si usted solicita archivo Tipo=.nccsvMetadatos de unERDDAP™Dataset.
Sección de Metadatos
En un archivo NCCSV, cada línea de la sección metadatos utiliza el formato
variable Nombre,atributo Nombre,valor1\[,valor2\]\[,valor3\]\[,valor4\]\[...\]
Los espacios antes o después de los artículos no se permiten porque causan problemas al importar el archivo en programas de hoja de cálculo.
Convenciones
La primera línea de un archivo NCCSV es la primera línea de la sección de metadatos y debe tener un\GLOBAL\Las convenciones atribuyen la inclusión de todas las convenciones utilizadas en el archivo como una cadena que contiene una lista CSV, por ejemplo: \GLOBAL\,Convenciones,"COARDS, CF-1.6, ACDD-1.3, NCCSV-1.1 Una de las convenciones enumeradas debe ser NCCSV-1.1, que se refiere a la versión actual de esta especificación.
END_METADATA
El final de la sección de metadatos de un archivo NCCSV debe ser denotado por una línea con sólo \END\_METADATA\
Se recomienda pero no se requiere que todos los atributos para una variable determinada aparezcan en líneas adyacentes de la sección metadatos. Si un archivo NCCSV se convierte en unNetCDFarchivo, el orden que la variableNames aparezca primero en la sección metadatos será el orden de las variables en laNetCDFarchivo.
Las líneas en blanco opcionales se permiten en la sección metadatos después de la primera línea requerida con\GLOBAL\ Convencionesinformación (véase infra) y antes de la última línea requerida con\END\_METADATA\.
Si se crea una hoja de cálculo de un archivo NCCSV, la sección de datos de metadatos aparecerá con nombres variables en la columna A, nombres de atributos en la columna B y valores en la columna C.
Si una hoja de cálculo siguiendo estas convenciones se guarda como un archivo CSV, a menudo habrá comas adicionales al final de las líneas en la sección de metadatos. El software que convierte los archivos NCCSV en.ncLos archivos ignorarán los comas adicionales.
variable Nombre
variable Nombre es el nombre sensible al caso de una variable en el archivo de datos. Todos los nombres variables deben comenzar con una letra o subrayado ASCII de 7 bits y estar compuestos de letras ASCII de 7 bits, subrayados y dígitos ASCII de 7 bits.
GLOBAL
La variable especialName\GLOBAL\se utiliza para denotar metadatos globales.
atributo Nombre
atributo Nombre es el nombre sensible al caso de un atributo asociado con una variable o\GLOBAL\. Todos los nombres de los atributos deben comenzar con una letra ASCII de 7 bits o subrayar y estar compuesto de letras ASCII de 7 bits, subrayados y dígitos ASCII de 7 bits.
SCALAR
El atributo especial Nombre\*SCALAR\*se puede utilizar para crear una variable de datos escalar y definir su valor. El tipo de datos del\*SCALAR\*define el tipo de datos para la variable, así que no especifique un\*DATA\_TYPE\*atributo para variables de escalar. Tenga en cuenta que no debe haber datos para la variable de escalar en la Sección de Datos del archivo NCCSV.
Por ejemplo, para crear una variable escalar llamada "ship" con el valor "Okeanos Explorer" y un atributo cf\_role, utilice: nave,\SCALAR\"Okeanos Explorer" nave,cf\_role,trajectory\_id Cuando se lee una variable de datos de escalarERDDAP™, el valor de escalar se convierte en una columna en la tabla de datos con el mismo valor en cada fila.
valor
valor es el valor del atributo de metadatos y debe ser un array con uno o más de un byte, ubyte, short, ushort, int, uint, long, ulong, flotador, doble, String o char. No se admiten otros tipos de datos. Los atributos sin valor serán ignorados. Si hay más de un subvalor, los subvalores deben ser todos del mismo tipo de datos y separados por comas, por ejemplo: sst,actual\_range,0.17f,23.58f Si hay varios valores de cuerda, utilice una sola cuerda con\n (newline) caracteres que separan las subestrings.
Las definiciones de los tipos de datos de atributos son:
byte
- valores de atributo (8-bit, firmado) debe ser escrito con el sufijo 'b', por ejemplo, -7b, 0b, 7b. El rango de valores de byte válidos es -128 a 127. Un número que parece un byte pero es inválido (por ejemplo, 128b) será convertido a un valor perdido o generar un mensaje de error.
ubyte
- valores de atributo ubyte (8 bits, sin firmar) debe ser escrito con el sufijo 'ub', por ejemplo, 0ub, 7ub, 250ub . El rango de valores de byte válidos es de 0 a 255. Un número que parece un ubyte pero es inválido (por ejemplo, 256ub) será convertido a un valor perdido o generar un mensaje de error. Cuando sea posible, use byte en lugar de ubyte, porque muchos sistemas no soportan bytes no firmados (por ejemplo, atributos enNetCDF-3 archivos) .
corto
- valores de atributo corto (16-bit, firmado) debe ser escrito con el sufijo 's', por ejemplo, -30000s, 0s, 30000s. El rango de valores cortos válidos es -32768 a 32767. Un número que parece corto pero inválido (por ejemplo, 32768) será convertido a un valor perdido o generar un mensaje de error.
ushort
- valores de atributo ushort (16 bits, sin firmar) debe ser escrito con el sufijo 'nosotros', por ejemplo, 0us, 30000us, 60000us. El rango de valores cortos válidos es de 0 a 65535. Un número que parece un ushort pero es inválido (por ejemplo, 65536us) será convertido a un valor perdido o generar un mensaje de error. Cuando sea posible, use corto en lugar de ushort, porque muchos sistemas no soportan bytes sin firma (por ejemplo, atributos enNetCDF-3 archivos) .
int
- valores de atributo (32-bit, firmado) debe ser escrito como JSON ints sin un punto decimal o exponente, pero con el sufijo 'i', por ejemplo, -12067978i, 0i, 12067978i. La gama de valores de entrada válidos es -2147483648 a 2147483647. Un número que parece un int pero no es válido (por ejemplo, 2147483648i) será convertido a un valor perdido o generar un mensaje de error.
Uint
- valores de atributo uint (32-bit, sin firma) debe ser escrito como JSON ints sin un punto decimal o exponente, pero con el sufijo 'ui', por ejemplo, 0ui, 12067978ui, 4123456789ui. La gama de valores int válidos es de 0 a 4294967295. Un número que parece un uint pero es inválido (por ejemplo, 2147483648ui) será convertido a un valor perdido o generar un mensaje de error. Cuando sea posible, use int en lugar de uint, porque muchos sistemas no soportan bytes sin firma (por ejemplo, atributos enNetCDF-3 archivos) .
largo
- valores de atributo largo (64-bit, firmado, actualmente apoyado por NUG yERDDAP™pero aún no apoyado por CF) debe ser escrito sin un punto decimal y con el sufijo 'L', por ejemplo, -12345678987654321L, 0L, 12345678987654321L . Si utiliza el software de conversión para convertir un archivo NCCSV con valores largos en unNetCDF-3 archivo, cualquier valor largo será convertido a valores dobles. La gama de valores largos válidos es -9223372036854775808 a 9223372036854775807. Un número que parece largo pero inválido (por ejemplo, 9223372036854775808L) será convertido a un valor perdido o generar un mensaje de error. Cuando sea posible, usa el doble en lugar de ulong, porque muchos sistemas no soportan mucho tiempo (por ejemplo,NetCDF-3 archivos) .
ulong
- valores de atributo ulong (64-bit, no firmado, actualmente apoyado por NUG yERDDAP™pero aún no apoyado por CF) debe ser escrito sin un punto decimal y con el sufijo 'uL', por ejemplo, 0uL, 12345678987654321uL, 9007199254740992uL . Si utiliza el software de conversión para convertir un archivo NCCSV con valores largos en unNetCDF-3 archivo, cualquier valor largo será convertido a valores dobles. La gama de valores largos válidos es de 0 a 18446744073709551615. Un número que parece un ulong pero es inválido (por ejemplo, 184467440737095516uL) será convertido a un valor perdido o generar un mensaje de error. Cuando sea posible, use el doble en lugar de ulong, porque muchos sistemas no soportan el largo firmado o no firmado (por ejemplo,NetCDF-3 archivos) .
flotador
- valores de atributo flotante (32-bit) debe ser escrito con el sufijo 'f' y puede tener un punto decimal y/o un exponente, por ejemplo, 0f, 1f, 12.34f, 1e12f, 1.23e+12f, 1.23e12f, 1.87E-7f. Usa NaNf para un NaN flotante (desaparecido) valor. La gama de flotadores es aproximadamente +/-3.40282347E+38f (~7 dígitos decimales importantes) . Un número que parece un flotador pero es inválido (por ejemplo, 1.0e39f) será convertido a un valor perdido o generar un mensaje de error.
doble
- valores de doble atributo (64-bit) debe ser escrito con el sufijo 'd' y puede tener un punto decimal y/o un exponente, por ejemplo, 0d, 1d, 12.34d, 1e12d, 1.23e+12d, 1.23e12d, 1.87E-7d. Use NaNd para un doble NaN (desaparecido) valor. La gama de dobles es de aproximadamente +/-1.79769313486231570E+308d (~15 dígitos decimales importantes) . Un número que parece doble pero inválido (por ejemplo, 1.0e309d) será convertido a un valor perdido o generar un mensaje de error.
String
- Los valores de atributo de cuerda son una secuencia de caracteres UCS-2 (i.e., 2 caracteres Unicode, como enJava) , que debe ser escrito como cadenas ASCII de 7 bits, JSON-like para que los caracteres no-ASCII puedan ser especificados.
- Citas dobles (") debe ser codificado como dos citas dobles (") . Eso es lo que los programas de hoja de cálculo requieren al leer archivos .csv. Eso es lo que los programas de hoja de cálculo escriben cuando guardas una hoja de cálculo como un archivo .csv.
- Los caracteres especiales JSON backslash-encoded deben ser codificados como en JSON (en particular\n(newline), pero también \\ (backslash), \f (formfeed), \t (tab), \r (retorno del coche) o con el\u hhhh sintaxis. En una hoja de cálculo, no utilice Alt Enter para especificar una nueva línea dentro de una célula de texto; en lugar de ello, use\n (2 caracteres: backslash y 'n ') para indicar una nueva línea.
uhhhh
- \u hhhh - Todos los caracteres menos que el carácter #32 o mayor que el carácter #126, y no de otro modo codificados, deben ser codificados con la sintaxis \u hhhh*, donde hhhh es el número hexadecimal de 4 dígitos del personaje, por ejemplo, el signo Euro es \u20AC. Ver las páginas de código mencionadas https://en.wikipedia.org/wiki/Unicode para encontrar los números hexadecimales asociados con caracteres Unicode específicos, o utilizar una biblioteca de software.
- Si el String tiene un espacio al principio o al final, o incluye " (doble cita) o una coma, o contiene valores que de otro modo se interpretarían como algún otro tipo de datos (por ejemplo, una int) , o es la palabra "null", todo el String debe ser encerrado en citas dobles; de lo contrario, a diferencia de JSON, las citas dobles adjuntas son opcionales. Recomendamos: cuando en duda, cierre todo el String en citas dobles. Los espacios al principio o al final de una cuerda están fuertemente desalentados.
- Por ahora, se desalienta el uso de caracteres superiores a #255. NCCSV los apoya.ERDDAP™los apoya internamente. Algunos tipos de archivos de salida los apoyan (por ejemplo,.jsony.nccsv) . Pero muchos tipos de archivos de salida no los soportan. Por ejemplo,NetCDF-3 archivos no soportan tales caracteres porqueNetCDFLos archivos usan caracteres de 1 byte y CF actualmente no tiene un sistema para especificar cómo los caracteres Unicode están codificados enNetCDFPendientes (por ejemplo, UTF-8) . Esto probablemente mejorará con el tiempo.
char
- valores de atributo char son un único personaje UCS-2 (i.e., 2 caracteres Unicode, como enJava) , que debe ser escrito como caracteres ASCII de 7 bits, JSON-like para que otros caracteres puedan ser especificados (ver la definición de String arriba para la codificación de caracteres especiales, con la adición de codificación de una sola cita como \ ') . Los valores de atributo de Char deben ser encerrados en citas individuales (las citas internas) y citas dobles (las citas externas) , por ejemplo, "'a'", "''" (un personaje de cita doble) , "'''" (un único personaje de cita) , "'\t'" (una pestaña) "'\u20AC'" (un carácter Euro) . Este sistema de usar citas individuales y dobles es extraño y engorroso, pero es una manera de distinguir los valores de char de Strings de una manera que funciona con hojas de cálculo. Un valor que parece un char pero es inválido generará un mensaje de error. Al igual que con Strings, el uso de caracteres superiores a #255 se desalienta actualmente.
Suffix
Tenga en cuenta que en la sección de atributos de un archivo NCCSV, todos los valores de atributos numéricos deben tener una letra de sufijo (por ejemplo, 'b') para identificar el tipo de datos numéricos (por ejemplo, byte) . Pero en la sección de datos de un archivo NCCSV, los valores numéricos de datos nunca deben tener estas letras de sufijo (con la excepción de 'L' para enteros largos y 'uL' para enteros ulong) — el tipo de datos es especificado por el\*DATA\_TYPE\*atributo para la variable.
DATA_TYPE
El tipo de datos para cada no-scalarvariable debe especificarse por una\*DATA\_TYPE\*atributo que puede tener un valor de byte, ubyte, short, ushort, int, uint, long, ulong, flotador, doble, cuerda o char (caso insensible) . Por ejemplo, qc\_flag,\DATA\_TYPE\, adiós ATENCIÓN: Especificación de lo correcto\*DATA\_TYPE\*es tu responsabilidad. Especificar el tipo de datos incorrecto (por ejemplo, int cuando debe haber especificado flotador) no generará un mensaje de error y puede causar la pérdida de información (por ejemplo, los valores de flotación se redondearán a las entradas) cuando el archivo NCCSV es leído porERDDAP™o convertido enNetCDFarchivo.
Char Discouraged
Se desalienta el uso de valores de datos de char porque no están ampliamente apoyados en otros tipos de archivos. los valores de char pueden ser escritos en la sección de datos como caracteres individuales o como Strings (notablemente, si necesita escribir un personaje especial) . Si se encuentra un String, el primer personaje del String se utilizará como valor del char. Cero longitud Las cuerdas y los valores perdidos se convertirán en caracteres \uFFFF. Note queNetCDFLos archivos sólo soportan solo byte chars, por lo que cualquier char más grande que char #255 se convertirá a '?' al escribirNetCDFarchivos. A menos que se utilice un atributo de charset para especificar un charset diferente para una variable char, se utilizará el charset ISO-8859-1.
Discouraged long and Unsigned
Aunque muchos tipos de archivos (por ejemplo,NetCDF-4 y json) yERDDAP™apoyo largo y no firmado (ubyte, ushort, uint, ulong) valores, el uso de valores largos y no firmados en archivos NCCSV se desalienta actualmente porque actualmente no están apoyados por Excel, CF yNetCDF-3 archivos. Si desea especificar valores largos o no firmados en un archivo NCCSV (o en la hoja de cálculo correspondiente de Excel) , debe utilizar el sufijo 'L' para que Excel no trate los números como números de puntos flotantes con menor precisión. Actualmente, si un archivo NCCSV se convierte en unNetCDF-3.ncarchivos, valores de datos largos y largos se convertirán en valores dobles, causando una pérdida de precisión para valores muy grandes (menos de -2^53 por largo, o superior a 2^53 por largo y largo) . InNetCDF-3.ncficheros, ubyte, ushort y uint variables aparecen como byte, short, e int con el atributo \_Unsigned=true metadata. InNetCDF-3.ncarchivos, ubyte, ushort, y los atributos uint aparecen como atributos byte, short, e int que contienen el valor correspondiente de dos (por ejemplo, 255ub aparece como -1b) . Esto es obviamente problema, por lo que los tipos de datos firmados deben ser utilizados en lugar de los tipos de datos no firmados siempre que sea posible.
CF, ACDD yERDDAP™Metadatos
Ya que se imagina que la mayoría de los archivos NCCSV, o.ncarchivos creados de ellos, se leerá enERDDAP, se recomienda encarecidamente que los archivos NCCSV incluyan los atributos de metadatos que son requeridos o recomendados porERDDAP™(ver /docs/servidor-admin/datasets#global-atributos). Los atributos son casi todos de los estándares de metadatos CF y ACDD y sirven para describir adecuadamente el conjunto de datos (quién, qué, cuándo, dónde, por qué, cómo) a alguien que no sabe nada sobre el conjunto de datos. De particular importancia, casi todas las variables numéricas deben tener un atributo de unidades con unUDUNITS- valor compatible, por ejemplo, sst,units,degree\_C
Está bien incluir atributos adicionales que no sean de las normas CF o ACDD o deERDDAP.
La Sección de Datos
Estructura
La primera línea de la sección de datos debe tener una lista de nombres variables sensible a casos y separados por coma. Todas las variables de esta lista deben describirse en la sección de metadatos, y viceversa (fuera de la\GLOBAL\atributos y\SCALAR\variables) .
El segundo a través de las líneas penúltimas de la sección de datos debe tener una lista de valores separada por coma. Cada fila de datos debe tener el mismo número de valores que la lista separada por coma de nombres variables. Los espacios antes o después de los valores no se permiten porque causan problemas al importar el archivo en programas de hoja de cálculo. Cada columna en esta sección debe contener sólo los valores de la\*DATA\_TYPE\*especificado para esa variable por\*DATA\_TYPE\*atributo para esa variable. A diferencia de la sección atributos, los valores numéricos en la sección de datos no deben tener letras sufijo para denotar el tipo de datos. A diferencia de la sección de atributos, los valores de char en la sección de datos pueden omitir las citas únicas adjuntas si no son necesarias para la desambiguación (así, ',' y '' debe ser citado como se muestra aquí) . Puede haber cualquier número de estas filas de datos en un archivo NCCSV, pero actualmenteERDDAP™sólo puede leer archivos NCCSV con hasta unos 2 mil millones de filas. En general, se recomienda dividir grandes conjuntos de datos en múltiples archivos de datos NCCSV con menos de 1 millón de filas cada uno.
END_DATA
El final de la sección de datos debe ser denotado por una línea con sólo \END\_DATA\
Si hay contenido adicional en el archivo NCCSV después del\*END\_DATA\*línea, se ignorará cuando el archivo NCCSV se convierte en un.ncarchivo. Por lo tanto, se desalienta ese contenido.
En una hoja de cálculo siguiendo estas convenciones, los nombres variables y los valores de datos estarán en múltiples columnas. Vea el ejemplo a continuación.
Valores perdidos
Los valores numéricos perdidos pueden ser escritos como un valor numérico identificado por unmissing\_valueo atributo \_FillValue para esa variable. Por ejemplo, vea el segundo valor en esta fila de datos: Bell M. Shimada,99,123.4 Esta es la forma recomendada para manejar valores perdidos para variables byte, ubyte, short, ushort, int, uint, long y ulong.
flotar o doble valores NaN pueden ser escritos como NaN. Por ejemplo, vea el segundo valor en esta fila de datos: Bell M. Shimada,NaN,123.4
Los valores perdidos de cuerda y numérica pueden ser indicados por un campo vacío. Por ejemplo, vea el segundo valor en esta fila de datos: Bell M. Shimada, 123.4
Para variables byte, ubyte, short, ushort, int, uint, long y ulong, la utilidad del convertidor NCCSV yERDDAP™convertir un campo vacío en el valor máximo permitido para ese tipo de datos (por ejemplo, 127 para bytes) . Si haces esto, asegúrate de añadir unmissing\_valueo atributo \_FillValue para esa variable para identificar este valor, por ejemplo, variable Nombre ,\_FillValue,127b Para las variables flotantes y dobles, un campo vacío se convertirá a NaN.
Valores de DateTime
Valores de DateTime (incluyendo valores de fecha que no tienen un componente de tiempo) puede ser representado como números o como Strings en archivos NCCSV. Una variable DateTime dada puede tener valores de String o sólo valores numéricos, no ambos. El software NCCSV convertirá los valores de String dateTime en fecha numérica Valores del tiempo al crear.ncarchivos (exigido por la CF) . Valores de la fecha de crianzaLos valores tienen la ventaja de ser fácilmente legibles por los humanos.
Los valores DateTime representados como valores numéricos deben tener un atributo de unidades que especifica el " unidades desde entonces Fecha Hora " según lo requerido por CF y especificado porUDUNITS, por ejemplo, tiempo,unidades,segundos desde 1970-01T00:00Z
Valores de DateTime representados como valores de String deben tener una cuerda\*DATA\_TYPE\*atributo y atributo de unidades que especifica una fecha patrón de tiempo especificado por elJavaDateTimeFormatter class ( https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html ) . Por ejemplo, tiempo, unidades,yyyy-MM-dd'T'HH:mm:ssZ Todos los valores dateTime para una variable de datos dada deben usar el mismo formato. En la mayoría de los casos, el patrón dateTime que necesita para el atributo de unidades será una variación de uno de estos formatos:
- yyyy-MM-dd'T'HH:mm:ss. SSSZ —que es la ISO 8601:2004 (E) Fecha Formato de tiempo. Usted puede necesitar una versión acortada de esto, por ejemplo,yyyy-MM-dd'T'HH:mm:ssZ (el único formato recomendado) oyyyy-MM-dd. Si está cambiando el formato de sus valores dateTime, NCCSV recomienda encarecidamente que cambie a este formato (tal vez acortado) . Este es el formato queERDDAP™utilizará cuando escriba archivos NCCSV.
- yyyyyMMddHHmmss.SSS — que es la versión compacta de la fecha ISO 8601:2004 Formato de tiempo. Usted puede necesitar una versión acortada de esto, por ejemplo, yyyyyMMdd.
- M/d/yyyy H:mm:ss. SSS —que maneja fechas y fechas de estilo estadounidenseTiempos como "3/23/2017 16:22:03.000". Usted puede necesitar una versión acortada de esto, por ejemplo, M/d/yyyy.
- yyyyyDDDHHmmsSSS — que es el año más el día de cero-pagado del año (por ejemplo, 001 = 1 de enero de 365 = 31 de diciembre en un año siniestro; esto a veces se llama erróneamente la fecha de Julian) . Usted puede necesitar una versión acortada de esto, por ejemplo, yyyyDDD .
Precisión
Cuando una biblioteca de software convierte una.ncarchivo en un archivo NCCSV, toda la fecha Los valores de tiempo se escribirán como Pendientes con la ISO 8601:2004 (E) Fecha Formato del tiempo, por ejemplo, 1970-01-01T00:00:00Z . Puede controlar la precisión con laERDDAP- atributo específicotime\_precision. See /docs/servidor-admin/datasets#time\_precision.
Zona horaria
La zona horaria predeterminada para la fecha Los valores del tiempo sonZulu (o GMT) zona horaria, que no tiene períodos de tiempo de verano. Si una variable dateTime tiene valores dateTime desde una zona horaria diferente, debe especificar esto con laERDDAP- atributo específicotime\_zone. Este es un requisitoERDDAP™(ver /docs/servidor-admin/datasets#time\_zone).
Valores de grado
Como exige CF, todos los valores de grado (por ejemplo, por longitud y latitud) debe especificarse como valores dobles decimale-degree, no como grado°min'sec" Crianza o como variables separadas para grados, minutos, segundos. No se permiten los designadores de dirección N, S, E y W. Use valores negativos para las longitudes oeste y para latitudes sur.
DSG Tipos de función
Un archivo NCCSV puede contener geometría de muestreo CF Discrete ( https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html#discrete-sampling-geometries ) datos. Son los atributos que hacen este trabajo:
- Como exige CF, el archivo NCCSV debe incluir una línea en la sección de metadatos identificando el\GLOBAL\ featureTypeatributo, por ejemplo, \GLOBAL\,featureType,trajectory
- Para uso enERDDAP™, el archivo NCCSV debe incluir una línea o líneas en la sección metadatos identificando las variables cf\_role=...\_id, por ejemplo, nave,cf\_role,trajectory\_id Esto es opcional para CF, pero requerido en NCCSV.
- Para uso enERDDAP™, el archivo NCCSV debe incluir una línea o líneas en la sección metadatos identificando qué variables están asociadas con cada vezSeries, trayectoria o perfil según sea requerido porERDDAP™(ver /docs/servidor-admin/datasets#cdm\_data\_tipo), por ejemplo, \GLOBAL\,cdm\_trajectory\_variables,"ship" o \GLOBAL\,cdm\_timeseries\_variables,"station\_id,lat,lon"
Muestra de archivos
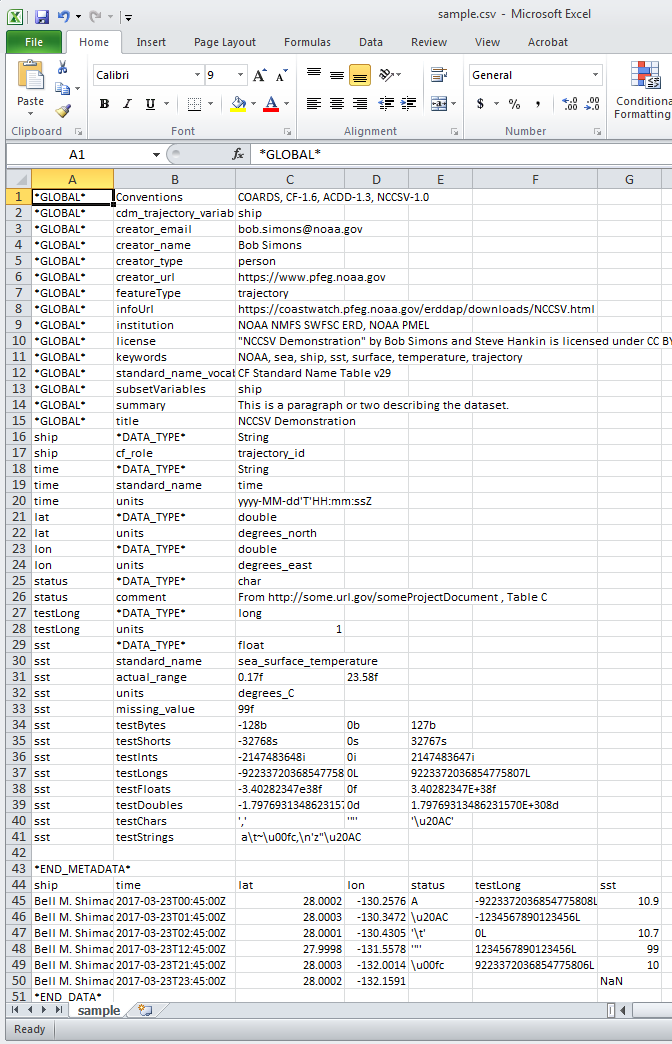
Aquí hay un archivo de muestra que muestra muchas de las características de un archivo NCCSV:
\\*GLOBAL\\*,Conventions,"COARDS, CF-1.6, ACDD-1.3, NCCSV-1.1"
\\*GLOBAL\\*,cdm\\_trajectory\\_variables,"ship"
\\*GLOBAL\\*,creator\\_email,erd.data@noaa.gov
\\*GLOBAL\\*,creator\\_name,Bob Simons
\\*GLOBAL\\*,creator\\_type,person
\\*GLOBAL\\*,creator\\_url,https://www.pfeg.noaa.gov
\\*GLOBAL\\*,featureType,trajectory
\\*GLOBAL\\*,infoUrl,https://erddap.github.io/docs/user/nccsv-1.10
\\*GLOBAL\\*,institution,"NOAA NMFS SWFSC ERD, NOAA PMEL"
\\*GLOBAL\\*,license,"""NCCSV Demonstration"" by Bob Simons and Steve Hankin is
licensed under CC BY 4.0, https://creativecommons.org/licenses/by/4.0/ ."
\\*GLOBAL\\*,keywords,"NOAA, sea, ship, sst, surface, temperature, trajectory"
\\*GLOBAL\\*,standard\\_name\\_vocabulary,CF Standard Name Table v55
\\*GLOBAL\\*,subsetVariables,"ship"
\\*GLOBAL\\*,summary,"This is a paragraph or two describing the dataset."
\\*GLOBAL\\*,title,"NCCSV Demonstration"
ship,\\*DATA\\_TYPE\\*,String
ship,cf\\_role,trajectory\\_id
time,\\*DATA\\_TYPE\\*,String
time,standard\\_name,time
time,units,"yyyy-MM-dd'T'HH:mm:ssZ"
lat,\\*DATA\\_TYPE\\*,double
lat,units,degrees\\_north
lon,\\*DATA\\_TYPE\\*,double
"lon","units","degrees\\_east"
status,\\*DATA\\_TYPE\\*,char
status,comment,"From http://some.url.gov/someProjectDocument , Table C"
testByte,\\*DATA\\_TYPE\\*,byte
testByte,units,1
testUByte,\\*DATA\\_TYPE\\*,ubyte
testUByte,units,1
testLong,\\*DATA\\_TYPE\\*,long
testLong,units,1
testULong,\\*DATA\\_TYPE\\*,ulong
testULong,units,1
sst,\\*DATA\\_TYPE\\*,float
sst,standard\\_name,sea\\_surface\\_temperature
sst,actual\\_range,0.17f,23.58f
sst,units,degree\\_C
sst,missing\\_value,99f
sst,testBytes,-128b,0b,127b
sst,testShorts,-32768s,0s,32767s
sst,testInts,-2147483648i,0i,2147483647i
sst,testLongs,-9223372036854775808L,0L,9223372036854775807L
sst,testFloats,-3.40282347e38f,0f,3.40282347E+38f
sst,testDoubles,-1.79769313486231570e308d,0d,1.79769313486231570E+308d
sst,testChars,"','","'""'","'\\u20AC'"
sst,testStrings," a~,\\n'z""\\u20AC"
sst,testUBytes,0ub,127ub,255ub
sst,testUInts,0ui,2147483647ui,4294967295ui
sst,testULongs,0uL,9223372036854775807uL,18446744073709551615uL
sst,testUShorts,0us,32767us,65535us
\\*END\\_METADATA\\*
ship,time,lat,lon,status,testByte,testUByte,testLong,testULong,sst
Bell M. Shimada,2017-03-23T00:45:00Z,28.0002,-130.2576,A,-128, 0,-9223372036854775808L,0uL,10.9
Bell M. Shimada,2017-03-23T01:45:00Z,28.0003,-130.3472,\\u20AC,0,127,-9007199254740992L,9223372036854775807uL,10.0
"Bell M. Shimada","2017-03-23T02:45:00Z",28.0001,-130.4305,"'\\t'",126,254,9223372036854775806L,18446744073709551614uL,99
"Bell M. Shimada",2017-03-23T12:45:00Z,27.9998,-131.5578,"'""'",127,255,9223372036854775807L,18446744073709551615uL,NaN
Notas:
- Este archivo muestra muchos casos difíciles (por ejemplo, char y variables largas y difíciles valores de String) . La mayoría de los archivos NCCSV serán mucho más simples.
- La línea de licencia se divide en dos líneas aquí, pero es sólo una línea en el archivo de la muestra.
- \u20AC es la codificación del carácter Euro y \u00FC es la codificación de ü.
- Muchos Las cuerdas en el ejemplo están cerradas por citas dobles aunque no tengan que ser, por ejemplo, muchos atributos globales incluyendo el título, el atributo de las unidades de lon, y la tercera línea de datos.)
- Sería más claro y mejor si las unidades atributos para la variable testLong se redactaran en citas dobles indicando que es un valor String. Pero la representación actual (1, sin citas) será interpretado correctamente como un String, no un entero, porque no hay sufijo 'i'.
- A diferencia de otros tipos de datos numéricos, los valores largos en la sección de datos tienen el sufijo ('L') que identifica su tipo de datos numéricos. Esto es necesario para evitar que las hojas de cálculo interpreten los valores como números de puntos flotantes y así perder precisión.
Hojas de cálculo
En una hoja de cálculo, como en un archivo NCCSV:
- Escriba valores de atributo numéricos como se especifica para los archivos NCCSV (por ejemplo, con una carta de sufijo, por ejemplo, 'f', para identificar el tipo de datos del atributo) .
- En Strings, escriba todos los caracteres menos que el personaje de ASCII #32 o superior al personaje #126 como un personaje de JSON (por ejemplo,\npara la nueva línea) o como el número de caracteres de Unicode hexadecimal (caso insensible) con la sintaxis\u hhhh (por ejemplo, \u20AC para el signo Euro) . Uso\n (2 caracteres: backslash y 'n ') para indicar una nueva línea, no Alt Enter.
Las únicas diferencias entre los archivos NCCSV y la hoja de cálculo analógica que siguen estas convenciones son:
- Los archivos NCCSV tienen valores en una línea separada por comas. Las hojas de cálculo tienen valores en una línea en células adyacentes.
- Las cadenas en los archivos NCCSV a menudo están rodeadas de citas dobles. Las cuerdas en hojas de cálculo nunca están rodeadas de citas dobles.
- Cifras dobles internas (") en Strings en archivos NCCSV aparecen como 2 citas dobles. Las citas dobles internas en hojas de cálculo aparecen como 1 doble cita.
Si una hoja de cálculo siguiendo estas convenciones se guarda como un archivo CSV, a menudo habrá comas adicionales al final de muchas de las líneas. El software que convierte los archivos NCCSV en.ncLos archivos ignorarán los comas adicionales.
Excel
Para importar un archivo NCCSV en Excel:
- Seleccione Archivo : Abrir .
- Cambiar el tipo de archivo a Archivos de texto (\- Sí.\.txt; \*.csv) .
- Busque los directorios y haga clic en el archivo NCCSV .csv.
- Haga clic en Abrir .
Para crear un archivo NCCSV de una hoja de cálculo Excel:
- Elija Archivo : Guardar Como .
- Cambiar el Guardar como tipo: ser CSV (Comma delimited) (\*.csv) .
- En respuesta a la advertencia de compatibilidad, haga clic en Sí .
- El archivo .csv resultante tendrá comas adicionales al final de todas las filas que no sean las filas CSV. Puedes ignorarlos.
En Excel, el archivo NCCSV aparece como
Hojas de Google
Para importar un archivo NCCSV en Google Sheets:
- Seleccione Archivo : Abrir .
- Elija Subir un archivo y haga clic en Subir un archivo desde su computadora. Seleccione el archivo, luego haga clic en Abrir .
O, elegir My Drive y cambiar el tipo de archivo desplegable selección a todos los tipos de archivos . Seleccione el archivo, luego haga clic en Abrir .
Para crear un archivo NCCSV de una hoja de cálculo de hojas de Google:
- Elija Archivo : Guardar Como .
- Cambiar el Guardar como tipo: ser CSV (Comma delimited) (\*.csv) .
- En respuesta a la advertencia de compatibilidad, haga clic en Sí .
- El archivo .csv resultante tendrá comas adicionales al final de todas las filas que no sean las filas CSV. Ignóralos.
Problemas/Advertencias
- Si creas un archivo NCCSV con un editor de texto o si creas una hoja de cálculo analógica en un programa de hoja de cálculo, el editor de texto o el programa de hoja de cálculo no comprobarán que hayas seguido correctamente estas convenciones. Depende de usted seguir correctamente estas convenciones.
- La conversión de una hoja de cálculo después de esta convención en un archivo csv (así, un archivo NCCSV) llevará a comas adicionales al final de todas las filas que no sean las filas de datos CSV. Ignóralos. El software convierte los archivos NCCSV en.ncLos archivos los ignorarán.
- Si un archivo NCCSV tiene exceso de comas al final de las filas, puede eliminarlos convirtiendo el archivo NCCSV en unNetCDFarchivo y luego la conversiónNetCDFvolver a un archivo NCCSV.
- Cuando intenta convertir un archivo NCCSV en unNetCDFarchivo, algunos errores serán detectados por el software y generarán mensajes de error, causando que la conversión falle. Otros problemas son difíciles o imposibles de atrapar y no generarán mensajes de error o advertencias. Otros problemas (por ejemplo, exceso de comas al final de las filas) será ignorado. El convertidor de archivo sólo hará una comprobación mínima de la corrección del resultadoNetCDFarchivo, por ejemplo, en lo que respecta al cumplimiento de CF. Es responsabilidad del creador de archivos y del usuario de archivos comprobar que los resultados de la conversión son tan deseados y correctos. Dos formas de comprobar son:
- Imprima el contenido del.ncarchivo con ncdump ( https://linux.die.net/man/1/ncdump ) .
- Vea el contenido de los datos enERDDAP.
Cambios
- Cambios Introducido en v1.10 (Abril 2020) :
- Añadido soporte para ubyte, ushort, uint, ulong.