NCCSV -
ANetCDF-Compatibile, UTF-8, CSV Specificazione del file, Versione 1.20
Bob Simons e Steve Hankin "NCCSV" di Bob Simons e Steve HankinCC BY 4.0
Introduzione
Questo documento specifica un formato di file di testo UTF-8 CSV che può contenere tutte le informazioni (metadati e dati) che si trova in unNetCDF .ncfile che contiene una tabella di dati CSV-file. L'estensione del file per un file di testo UTF-8 CSV a seguito di questa specifica deve essere .csv in modo che possa essere letto facilmente e correttamente in programmi di foglio di calcolo come Excel e Google Sheets. Bob Simons scriverà il software per convertire un file NCCSV in unNetCDF-3 (e forse ancheNetCDF-4) .ncfile, e il rovescio, senza perdita di informazioni. Bob Simons ha modificatoERDDAP™per supportare la lettura e la scrittura di questo tipo di file.
Il formato NCCSV è progettato in modo che il software del foglio di calcolo come Excel e Google Sheets possa importare un file NCCSV come file csv, con tutte le informazioni nelle celle del foglio di calcolo pronte per la modifica. Oppure, un foglio di calcolo può essere creato da zero seguendo le convenzioni NCCSV. Indipendentemente dalla fonte del foglio di calcolo, se viene esportato come file .csv, si conforma alle specifiche NCCSV e nessuna informazione verrà persa. Le uniche differenze tra i file NCCSV e i file di fogli di calcolo analogici che seguono queste convenzioni sono:
- I file NCCSV hanno valori su una linea separata da virgole. I fogli di calcolo hanno valori su una linea nelle celle adiacenti.
- Le stringhe nei file NCCSV sono spesso circondate da doppie citazioni. Le stringhe nei fogli di calcolo non sono mai circondate da doppie citazioni.
- Virgolette interne (") in Strings in file NCCSV appaiono come 2 doppie citazioni. Le doppie citazioni interne nei fogli di calcolo appaiono come 1 doppia citazione.
Vedere laScheda tecnicasezione qui sotto per maggiori informazioni.
Streaming
Come i file CSV in generale, i file NCCSV sono in streaming. Pertanto, se un NCSV viene generato on-the-fly da un server dati comeERDDAP™, il server può iniziare a trasmettere i dati al richiedente prima che tutti i dati siano raccolti. Questa è una caratteristica utile e desiderabile.NetCDFi file, al contrario, non sono in streaming.
ERDDAP
Questa specifica è progettata in modo che i file NCCSV e.nci file che possono essere creati da loro possono essere utilizzati da unERDDAP™server dati (via ilEDDTableFromNccsvFileseEDDTableFromNcFilestipi di dataset) , ma questa specifica è esterna aERDDAP.ERDDAP™ha diversi attributi globali richiesti e molti attributi globali e variabili raccomandati, principalmente basati sugli attributi CF e ACDD (vedi /docs/server-admin/datasets#global-attributes).
Bilancio
Il design del formato NCCSV è un equilibrio di diversi requisiti:
- I file devono contenere tutti i dati e i metadati che sarebbero in un tabulareNetCDFfile, compresi i tipi di dati specifici.
- I file devono essere in grado di essere letti e poi scritti da un foglio di calcolo senza perdita di informazioni.
- I file devono essere facili per gli esseri umani per creare, modificare, leggere e capire.
- I file devono essere in grado di essere analizzati in modo non ambiguo dai programmi per computer.
Se qualche requisito in questo documento sembra strano o piccante, è probabilmente necessario soddisfare uno di questi requisiti.
Altre specifiche
Questa specifica si riferisce a diverse altre specifiche e librerie che è progettato per lavorare con, ma questa specificazione non è una parte di qualsiasi di quelle altre specifiche, né ha bisogno di modifiche a loro, né in conflitto con loro. Se un dettaglio relativo a uno di questi standard non è specificato qui, vedere le specifiche relative. In particolare, questo include:
- La Convenzione Attributiva per la Scoperta di Dataset (ACDDETTI) standard di metadati: https://wiki.esipfed.org/Attribute\_Convention\_for\_Data\_Discovery\_1-3 .
- Il clima e la previsione (CFU) standard di metadati: https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html .
- TheNetCDFGuida utente (NUG) : https:///docs.unidata.ucar.edu/netcdf-java/current/userguide/index.html .
- TheNetCDFlibrerie di software comeNetCDF- Java eNetCDF-c: https://www.unidata.ucar.edu/software/netcdf/ . Queste librerie non possono leggere i file NCCSV, ma possono leggere.ncfile creati dai file NCCSV.
- JSON: https://www.json.org/
Notazione
In questa specifica, parentesi,\[ \], indicare gli elementi facoltativi.
Struttura del file
Un file NCCSV completo è composto da due sezioni: la sezione metadati, seguita dalla sezione dati.
I file NCCSV possono contenere caratteri UCS-2 (cioè, 2 byte caratteri Unicode, come inJava) codificato tramite UTF-8.ERDDAP™legge e scrive i file NCCSV utilizzando la codifica UTF-8.
I file NCCSV possono utilizzare sia la nuova linea (\n) (che è comune su computer Linux e Mac OS X) o carrelloRitorno più novità (\r\n) (che è comune su computer Windows) come marcatori di fine linea, ma non entrambi.
.nccsvMetadati
Quando sia il creatore che il lettore lo aspettano, è anche possibile e talvolta utile fare una variante di un file NCCSV che contiene solo la sezione dei metadati (incluso il\*END\_METADATA\*linea) . Il risultato fornisce una descrizione completa degli attributi del file, dei nomi variabili e dei tipi di dati, servendo così lo stesso scopo delle risposte .das plus .dds di unOPeNDAPserver.ERDDAP™restituirà questa variazione se si richiede il file Traduzione:.nccsvMetadati da unERDDAP™Dataset.
La sezione Metadati
In un file NCCSV, ogni riga della sezione metadati utilizza il formato
variabile Nome♪attributo Nome♪valore 1\[, valore 2\]\[, valore 3\]\[, valore 4\]\[...\]
Spazi prima o dopo gli articoli non sono ammessi perché causano problemi quando importano il file in programmi di foglio di calcolo.
Convenzioni
La prima linea di un file NCCSV è la prima linea della sezione dei metadati e deve avere una\GLOBALE\Le convenzioni attribuiscono l'elenco di tutte le convenzioni utilizzate nel file come String contenente un elenco CSV, ad esempio: \GLOBALE\,Convenzioni,"COARDS, CF-1.6, ACDD-1.3, NCCSV-1.2" Una delle convenzioni elencate deve essere NCCSV-1.2, che si riferisce alla versione attuale di questa specifica.
Metadati finali
La fine della sezione dei metadati di un file NCCSV deve essere denotata da una riga con solo \END\_METADATA\
Si raccomanda ma non è necessario che tutti gli attributi per una determinata variabile appariscano sulle linee adiacenti della sezione metadati. Se un file NCCSV viene convertito in unNetCDFfile, l'ordine che le variabiliNami appaiono prima nella sezione metadati sarà l'ordine delle variabili nellaNetCDFfile.
Le linee vuote opzionali sono consentite nella sezione metadati dopo la prima riga richiesta con\GLOBALE\ Convenzioniinformazioni (vedi sotto) e prima dell'ultima riga richiesta con\END\_METADATA\.
Se un foglio di calcolo viene creato da un file NCCSV, la sezione dei dati dei metadati apparirà con i nomi variabili nella colonna A, i nomi degli attributi nella colonna B e i valori nella colonna C.
Se un foglio di calcolo che segue queste convenzioni viene salvato come file CSV, ci saranno spesso virgole extra alla fine delle righe nella sezione dei metadati. Il software che converte i file NCCSV in.nci file ignoreranno le virgole extra.
variabile Nome
variabile Nome è il nome caso-sensibile di una variabile nel file di dati. Tutti i nomi variabili devono iniziare con una lettera ASCII a 7 bit o sottolinearsi ed essere composti da lettere ASCII a 7 bit, underscore e cifre ASCII a 7 bit.
GLOBALE
La speciale variabileName\GLOBALE\è usato per indicare i metadati globali.
attributo Nome
attributo Nome è il nome caso-sensibile di un attributo associato a una variabile o\GLOBALE\. Tutti i nomi dell'attributo devono iniziare con una lettera ASCII a 7 bit o sottolinearlo ed essere composti da lettere ASCII a 7 bit, underscores e cifre ASCII a 7 bit.
SCALAR
L'attributo speciale Nome\*SCALAR\*può essere utilizzato per creare una variabile di dati scalare e definire il suo valore. Il tipo di dati del\*SCALAR\*definisce il tipo di dati per la variabile, quindi non specificare un\*DATA\_TYPE\*attributo per variabili scalari. Si noti che non ci devono essere dati per la variabile scalare nella sezione dati del file NCCSV.
Ad esempio, per creare una variabile scalare denominata "ship" con il valore "Okeanos Explorer" e un attributo cf\_role, utilizzare: nave,\SCALAR\"Okeanos Explorer" nave, v\_role,traiettoria\_id Quando una variabile di dati scalare viene lettaERDDAP™, il valore scalare viene convertito in una colonna nella tabella dei dati con lo stesso valore su ogni riga.
valore
valore è il valore dell'attributo dei metadati e deve essere un array con uno o più di uno o più byte, ubyte, short, ushort, int, uint, long, ulong, float, double, String, or char. Non sono supportati altri tipi di dati. Gli attributi senza valore saranno ignorati. Se c'è più di un sottovalore, i sottovalori devono essere tutti dello stesso tipo di dati. Per tipi di dati diversi dalle stringhe, i valori devono essere separati da virgole, ad esempio: sst♪actual\_range,0.17f, 23.58f Per Strings, utilizzare un singolo String con\n (novità) caratteri che separano i sottostringi.
Le definizioni dei tipi di dati attributo sono:
byte
- byte valori attributo (8 bit, firmato) deve essere scritto con il suffisso 'b', ad esempio, -7b, 0b, 7b . La gamma di valori di byte validi è da -128 a 127. Un numero che sembra un byte ma non è valido (ad esempio, 128b) verrà convertito in un valore mancante o generare un messaggio di errore.
Ubyte
- valori di attributo ubyte (8-bit, senza firma) deve essere scritto con il suffisso 'ub', ad esempio, 0ub, 7ub, 250ub . La gamma di valori di byte validi è da 0 a 255. Un numero che sembra un ubyte ma non è valido (ad esempio, 256ub) verrà convertito in un valore mancante o generare un messaggio di errore. Quando possibile, utilizzare byte invece di ubyte, perché molti sistemi non supportano byte non firmati (ad esempio, attributi inNetCDF-3 file) .
breve
- valori di attributo breve (16 bit, firmato) deve essere scritto con il suffisso 's', ad esempio, -30000s, 0s, 30000s. La gamma di valori brevi validi è da -32768 a 32767. Un numero che sembra breve ma non è valido (ad esempio, 32768s) verrà convertito in un valore mancante o generare un messaggio di errore.
noihort
- ushort valori attributo (16-bit, senza firma) deve essere scritto con il suffisso 'noi', ad esempio, 0us, 30000us, 60000us. La gamma di valori brevi validi è da 0 a 65535. Un numero che sembra un cavalletto ma non è valido (per esempio, 65536us) verrà convertito in un valore mancante o generare un messaggio di errore. Quando possibile, utilizzare corto invece di ushort, perché molti sistemi non supportano byte non firmate (ad esempio, attributi inNetCDF-3 file) .
byte
- int valori di attributo (32-bit, firmato) deve essere scritto come ints JSON senza un punto decimale o esponente, ma con il suffisso 'i', ad esempio, -12067978i, 0i, 12067978i. La gamma di valori int validi è -2147483648 a 2147483647. Un numero che sembra un int ma non è valido (per esempio, 2147483648i) verrà convertito in un valore mancante o generare un messaggio di errore.
U.
- valori di attributo uint (32-bit, senza firma) deve essere scritto come ints JSON senza un punto decimale o esponente, ma con il suffisso 'ui', ad esempio, 0ui, 12067978ui, 4123456789ui. La gamma di valori int validi è da 0 a 4294967295. Un numero che sembra un uint ma non è valido (per esempio, 2147483648ui) verrà convertito in un valore mancante o generare un messaggio di errore. Quando possibile, utilizzare int invece di uint, perché molti sistemi non supportano byte non firmate (ad esempio, attributi inNetCDF-3 file) .
lungo
- valori di attributo lunghi (64-bit, firmato, attualmente supportato da NUG eERDDAP™ma non ancora supportato da CF) deve essere scritto senza un punto decimale e con il suffisso 'L', ad esempio -12345678987654321L, 0L, 12345678987654321L . Se si utilizza il software di conversione per convertire un file NCCSV con valori lunghi in unNetCDF-3 file, tutti i valori lunghi saranno convertiti in doppi valori. La gamma di valori lunghi validi è -9223372036854775808 a 9223372036854775807. Un numero che sembra lungo ma non è valido (ad esempio, 9223372036854775808L) verrà convertito in un valore mancante o generare un messaggio di errore. Quando possibile, utilizzare il doppio invece di ulong, perché molti sistemi non supportano a lungo (ad esempio,NetCDF-3 file) .
*
- valori dell'attributo (64-bit, non firmato, attualmente supportato da NUG eERDDAP™ma non ancora supportato da CF) deve essere scritto senza un punto decimale e con il suffisso 'uL', ad esempio, 0uL, 12345678987654321uL, 9007199254740992uL . Se si utilizza il software di conversione per convertire un file NCCSV con valori lunghi in unNetCDF-3 file, tutti i valori lunghi saranno convertiti in doppi valori. La gamma di valori lunghi validi è da 0 a 18446744073709551615. Un numero che sembra un ulong ma non è valido (per esempio, 184467440737095516uL) verrà convertito in un valore mancante o generare un messaggio di errore. Quando possibile, utilizzare il doppio invece di ulong, perché molti sistemi non supportano firmato o non firmato a lungo (ad esempio,NetCDF-3 file) .
galleggiante
- valori dell'attributo float (32 bit) deve essere scritto con il suffisso 'f' e può avere un punto decimale e/o un esponente, ad esempio 0f, 1f, 12.34f, 1e12f, 1.23e+12f, 1.23e12f, 1.87E-7f. Usa NaNf per un galleggiante NaN (mancante) valore. La gamma di galleggianti è di circa +/-3.40282347E+38f (~7 cifre decimali significative) . Un numero che sembra un galleggiante ma non è valido (ad esempio, 1.0e39f) verrà convertito in un valore mancante o generare un messaggio di errore.
doppio
- valori doppio attributo (64 bit) deve essere scritto con il suffisso 'd' e può avere un punto decimale e/o un esponente, ad esempio 0d, 1d, 12.34d, 1e12d, 1.23e+12d, 1.23e12d, 1,87E-7d. Utilizzare NaNd per un doppio NaN (mancante) valore. La gamma di doppie è di circa +/-1.79769313486231570E+308d (~15 cifre decimali significative) . Un numero che sembra un doppio ma non è valido (ad esempio, 1.0e309d) verrà convertito in un valore mancante o generare un messaggio di errore.
String
- I valori dell'attributo di stringa sono una sequenza di caratteri UCS-2 (cioè, 2 byte caratteri Unicode, come inJava) , che deve essere scritto come stringhe JSON-like.
- Citazioni doppie (") all'interno di un valore di stringa deve essere codificato come due doppie citazioni (") . Questo è ciò che i programmi di foglio di calcolo richiedono quando si legge i file .csv. Questo è ciò che i programmi di foglio di calcolo scrivono quando si salva un foglio di calcolo come file .csv.
- Lo speciale JSON backslash-encoded caratteri all'interno di un valore String deve essere codificato come in JSON (in particolare\n(newline), \\\ (backslash), \f (formfeed), \t (tab), \r (ritorno del trasporto) o con# # Sintassi. In un foglio di calcolo, non utilizzare Alt Enter per specificare una nuova riga all'interno di una cella di testo; invece, utilizzare\n (2 caratteri: backslash e 'n ') per indicare una nuova linea.
uhhhh
- Tutti gli altri personaggi meno del personaggio #32 devono essere codificati con la sintassi \u # , dove hhhh è il numero esadecimale a 4 cifre del personaggio.
- Tutti i caratteri stampabili superiori al carattere #126, ad esempio, il segno Euro, possono apparire inediti, ad esempio, € (il carattere Euro) , o codificato con# # sintassi, ad esempio, \u20AC. Vedi le pagine del codice https://en.wikipedia.org/wiki/Unicode per trovare i numeri esadecimali associati a caratteri specifici Unicode, o utilizzare una libreria software. Nota che alcuniERDDAP™tipi di file di output, ad esempio, .csv, utilizzare il set di caratteri ISO 8859-1, quindi i caratteri Unicode sopra #255 saranno persi quando questi valori di dati sono scritti a quei tipi di file.
- Tutti i caratteri non stampabili maggiore del carattere #126, ad esempio, carattere #127, sono STRONGLY DISCOURAGED, ma si SHOULD utilizzare il \u # sintassi se li include.
- Se lo String ha uno spazio all'inizio o alla fine, o include " (doppia citazione) o una virgola, o contiene valori che altrimenti sarebbero interpretati come un altro tipo di dati (per esempio, un int) , o è la parola "null", l'intero String deve essere racchiuso in doppie citazioni; altrimenti, a differenza di JSON, le doppie citazioni racchiudenti sono facoltative. Consigliamo: quando in dubbio, racchiudere l'intero String in doppie citazioni. Gli spazi all'inizio o alla fine di uno String sono fortemente scoraggiati.
carbone
- valori dell'attributo di beneficenza sono un singolo carattere UCS-2 (cioè, 2 byte caratteri Unicode, come inJava) . Caratteri stampabili (altri personaggi speciali come newline, ", ', e \) può essere scritto come è. Personaggi speciali (ad esempio, newline) e altri caratteri non stampabili (ad esempio, #127) deve essere scritto con# # Sintassi. I valori dell'attributo Char devono essere racchiusi in singole citazioni (le citazioni interne) e doppie citazioni (le citazioni esterne) , ad esempio, "'a'", "'" (a doppia citazione carattere) # (un singolo carattere citazione) # (una scheda) , "'\u007F" (il delete 'character ') # E... # (il carattere Euro) . Questo sistema di utilizzo di singole e doppie citazioni è strano e ingombrante, ma è un modo per distinguere i valori di beneficenza da Strings in un modo che funziona con fogli di calcolo. Un valore che sembra un char ma non è valido genererà un messaggio di errore. Nota che alcuniERDDAP™tipi di file di output, ad esempio, .csv, utilizzare il set di caratteri ISO 8859-1, quindi i caratteri Unicode sopra #255 saranno persi quando questi valori di dati sono scritti a quei tipi di file.
Suffisso
Si noti che nella sezione attributi di un file NCCSV, tutti i valori di attributo numerico devono avere una lettera di suffisso (ad esempio, 'b') per identificare il tipo di dati numerico (ad esempio, byte) . Ma nella sezione dati di un file NCCSV, i valori numerici dei dati non devono mai avere queste lettere suffissi (con l'eccezione di 'L' per interi lunghi e 'uL' per interi lunghi) — il tipo di dati è specificato dal\*DATA\_TYPE\*attributo per la variabile.
Tipo di dati
Il tipo di dati per ogni non-scalarevariabile deve essere specificata da una\*DATA\_TYPE\*attributo che può avere un valore di byte, ubyte, short, ushort, int, uint, long, ulong, float, double, String, o char (caso insensibile) . Per esempio, Qc\_flag,\*DATA\_TYPE\*Ciao. ATTENZIONE: Specificare il corretto\*DATA\_TYPE\*è vostra responsabilità. Specificare il tipo di dati sbagliato (ad esempio, int quando si dovrebbe specificare galleggiante) non genera un messaggio di errore e può causare la perdita di informazioni (ad esempio, i valori del galleggiante saranno arrotondati ai punti) quando il file NCCSV è letto daERDDAP™o convertito in unNetCDFfile.
Char Discouraged
L'uso di valori di dati di beneficenza è scoraggiato perché non sono ampiamente supportati in altri tipi di file. valori di beneficenza possono essere scritti nella sezione dati come singoli caratteri o come Strings (in particolare, se avete bisogno di scrivere un carattere speciale) . Se si trova uno String, il primo carattere dello String sarà usato come valore del char. Le stringhe e i valori mancanti saranno convertiti in carattere \uFFFF. Nota:NetCDFi file supportano solo i chars byte singoli, quindi qualsiasi char maggiore di #255 verrà convertito in '?' quando si scriveNetCDFfile. A meno che un attributo charset non sia usato per specificare un set di beneficenza diverso per una variabile di beneficenza, il set di char ISO-8859-1 verrà utilizzato.
Lungo e senza iscrizioni
tipi lunghi e non firmati sono scoraggiati. Anche se molti tipi di file (ad esempio,NetCDF-4 e json) eERDDAP™supporto lungo e senza firma (ubyte, ushort, uint, ulong) valori, l'uso di valori lunghi e non firmati nei file NCCSV è attualmente scoraggiato perché attualmente non sono supportati da Excel, CF eNetCDF- 3 file. Se si desidera specificare valori lunghi o non firmati in un file NCCSV (o nel foglio di calcolo corrispondente di Excel) , è necessario utilizzare il suffisso 'L' in modo che Excel non tratta i numeri come numeri di punti galleggianti con precisione inferiore. Attualmente, se un file NCCSV viene convertito in unNetCDF-3.nci valori di dati lunghi e lunghi saranno convertiti in doppi valori, causando una perdita di precisione per valori molto grandi (meno di -2^53 per lungo, o superiore a 2^53 per lungo e lungo) . InNetCDF-3.ncfile, ubyte, ushort e variabili uint appaiono come byte, short e int con l'attributo \_Unsigned=true metadati. InNetCDF-3.nci file, gli attributi ubyte, ushort e uint appaiono come attributi byte, short e int contenenti il valore corrispondente di due-complemento (per esempio, 255b appare come -1b) . Questo è ovviamente un problema, quindi i tipi di dati firmati dovrebbero essere utilizzati invece di tipi di dati non firmati quando possibile.
CF, ACDD, eERDDAP™Metadati
Dal momento che è previsto che la maggior parte dei file NCCSV, o.nci file creati da loro, saranno letti inERDDAP, è fortemente raccomandato che i file NCCSV includono gli attributi dei metadati richiesti o raccomandati daERDDAP™(v. /docs/server-admin/datasets#global-attributes). Gli attributi sono quasi tutti dagli standard di metadati CF e ACDD e servono per descrivere correttamente il set di dati (chi, cosa, quando, dove, perché, come) a qualcuno che altrimenti non sa nulla del set di dati. Di particolare importanza, quasi tutte le variabili numeriche dovrebbero avere un attributo unità con unUDUNITS-valore compatibile, ad esempio, sst, unità, grado\_C
È bene includere attributi aggiuntivi che non sono dagli standard CF o ACDD o daERDDAP.
La sezione dati
Struttura
La prima riga della sezione dati deve avere un elenco di nomi variabili, separato da virgola. Tutte le variabili in questo elenco devono essere descritte nella sezione metadati, e viceversa (altri\GLOBALE\attributi e\SCALAR\variabili) .
Il secondo attraverso la penultima riga della sezione dati deve avere una lista di valori separati da virgola. Ogni riga di dati deve avere lo stesso numero di valori come l'elenco separato da virgola di nomi variabili. Spazi prima o dopo i valori non sono permessi perché causano problemi quando importano il file in programmi di foglio di calcolo. Ogni colonna in questa sezione deve contenere solo valori della\*DATA\_TYPE\*specificato per quella variabile da\*DATA\_TYPE\*attributo per quella variabile. A differenza della sezione attributi, i valori numerici nella sezione dati non devono avere lettere sufficienti per indicare il tipo di dati. A differenza della sezione attributi, i valori di beneficenza nella sezione dati possono omettere l'inclusione di singole citazioni se non sono necessari per la disambiguazione (Pertanto, ',' e '' devono essere citati come mostrato qui) . Ci può essere un numero qualsiasi di queste righe di dati in un file NCCSV, ma attualmenteERDDAP™può solo leggere i file NCCSV con fino a circa 2 miliardi di righe. In generale, si consiglia di dividere grandi set di dati in più file di dati NCCSV con meno di 1 milione di righe ciascuna.
Fine dei dati
La fine della sezione dati deve essere denotata da una riga con solo \DATI\
Se c'è contenuto aggiuntivo nel file NCCSV dopo il\*DATI\*linea, verrà ignorato quando il file NCCSV viene convertito in un.ncfile. Tale contenuto è quindi scoraggiato.
In un foglio di calcolo che segue queste convenzioni, i nomi variabili e i valori di dati saranno in più colonne. Vedi l'esempio qui sotto.
Valori mancanti
I valori mancanti numerici possono essere scritti come un valore numerico identificato da unmissing\_valueo attributo \_FillValue per quella variabile. Per esempio, vedere il secondo valore su questa riga di dati: Bell M. Shimada,99,123.4 Questo è il modo consigliato per gestire i valori mancanti per byte, ubyte, short, ushort, int, uint, long, e ulong variabili.
i valori di galleggiamento o doppia NaN possono essere scritti come NaN. Per esempio, vedere il secondo valore su questa riga di dati: Bell M. Shimada, NaN, 123.4
I valori mancanti di stringa e numerica possono essere indicati da un campo vuoto. Per esempio, vedere il secondo valore su questa riga di dati: Bell M. Shimada, 123.4
Per byte, ubyte, short, ushort, int, uint, long e ulong variabili, il convertitore NCCSV utilità eERDDAP™convertirà un campo vuoto nel valore massimo consentito per quel tipo di dati (ad esempio, 127 per byte) . Se lo fai, assicurati di aggiungere unmissing\_valueo attributo \_FillValue per tale variabile per identificare questo valore, ad esempio, variabile Nome ,\_FillValue,127b Per il galleggiamento e le doppie variabili, un campo vuoto verrà convertito in NaN.
Valori della data
Valori della data (compresi i valori della data che non hanno un componente temporale) può essere rappresentato come numeri o come stringhe nei file NCCSV. Una determinata variabile dateTime può avere solo valori di stringa o solo valori numerici, non entrambi. Il software NCCSV convertirà i valori String dateTime in data numerica Valori del tempo durante la creazione.ncfile (come richiesto da CF) . I valori del tempo hanno il vantaggio di essere facilmente leggibili dagli esseri umani.
I valori DateTime rappresentati come valori numerici devono avere un attributo delle unità che specifica il " unità da data Tempo " come richiesto da CF e specificato daUDUNITSPer esempio, tempo,unità, secondi dal 1970-01T00:00:00Z
DateTime valori rappresentati come valori di stringa devono avere uno String\*DATA\_TYPE\*attributo e attributo unità che specifica una data Time pattern come specificato dallaJavaDateTimeFormatter classe ( https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html ) . Per esempio, tempo, unità,yyyy-MM-dd'T'HH:mm:ssZ Tutti i valori dateTime per una determinata variabile di dati devono utilizzare lo stesso formato. Nella maggior parte dei casi, il modello dateTime di cui hai bisogno per l'attributo delle unità sarà una variazione di uno di questi formati:
- yyyy-MM-ddSs. SSSZ — che è la ISO 8601:2004 (E) data Formato del tempo. Potrebbe essere necessario una versione abbreviata di questo, ad esempio,yyyy-MM-dd'T'HH:mm:ssZ (l'unico formato consigliato) oyyyy-MM-dd. Se stai cambiando il formato dei valori dateTime, NCCSV raccomanda vivamente di cambiare a questo formato (forse abbreviato) . Questo è il formato cheERDDAP™userà quando scrive i file NCCSV.
- yyymmddHmmss.SSS — che è la versione compatta della data ISO 8601:2004 Formato del tempo. Potrebbe essere necessario una versione abbreviata di questo, ad esempio, yyyymmdd.
- M/d/yyyyy H:mm:ss. SSS — che gestisce le date e la data in stile americanoOrari come "3/23/2017 16:22:03.000". Potrebbe essere necessario una versione abbreviata di questo, ad esempio, M/d/yyyyy .
- yyyyDDDHmmssSSS — che è l'anno più il giorno zero-integrato dell'anno (e.g, 001 = 1 gennaio, 365 = 31 dicembre in un anno non adeguato; questo è talvolta erroneamente chiamato la data Julian) . Potrebbe essere necessario una versione abbreviata di questo, ad esempio, yyyyDDD .
Precisione
Quando una libreria software converte un.ncfile in un file NCCSV, tutta la data I valori del tempo saranno scritti come Strings con la ISO 8601:2004 (E) data Formato orario, ad esempio, 1970-01-01T00:00:00Z . È possibile controllare la precisione con laERDDAP-attributo specificotime\_precision. Vedi /docs/server-admin/datasets#time\_precision.
Tempo
Il fuso orario predefinito per la data I valori del tempo sonoZulu (o GMT) fuso orario, che non ha periodi di tempo di risparmio di luce del giorno. Se una variabile dateTime ha i valori dateTime da un'altra zona di tempo, è necessario specificare questo conERDDAP-attributo specificotime\_zone. Questo è un requisito perERDDAP™(v. /docs/server-admin/datasets#time\_zone).
Valori di laurea
Come richiesto da CF, tutti i valori di grado (ad esempio, per longitudine e latitudine) deve essere specificato come valori doppi decimali, non come stringa di grado°min'sec o come variabili separate per gradi, minuti, secondi. I progettisti di direzione N, S, E e W non sono ammessi. Utilizzare valori negativi per le longitudini occidentali e per le latitudini del Sud.
DSG Tipi di funzionalità
Un file NCCSV può contenere CF Discrete Sampling Geometry ( https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html#discrete-sampling-geometries ) dati. Sono gli attributi che rendono questo lavoro:
- Come richiesto dal CF, il file NCCSV deve includere una linea nella sezione metadati che identifica la\GLOBALE\ featureTypeattributo, ad esempio, \GLOBALE\♪featureType, traiettoria
- Per l'uso inERDDAP™, il file NCCSV deve includere una linea o linee nella sezione metadati che identifica le variabili cf\_role=...\_id, ad esempio, nave, v\_role,traiettoria\_id Questo è facoltativo per CF, ma richiesto in NCCSV.
- Per l'uso inERDDAP™, il file NCCSV deve includere una linea o linee nella sezione metadati che identificano quali variabili sono associate ad ogni voltaSeries, traiettoria o profilo come richiesto dallaERDDAP™(v. /docs/server-admin/datasets#cdm\_data\_type), ad esempio, \GLOBALE\,cdm\_trajectory\_variables,"ship" o \GLOBALE\,cdm\_timeseries\_variables,"station\_id,lat,lon"
Esempio di file
Ecco un file campione che mostra molte delle caratteristiche di un file NCCSV:
\\*GLOBAL\\*,Conventions,"COARDS, CF-1.6, ACDD-1.3, NCCSV-1.2"
\\*GLOBAL\\*,cdm\\_trajectory\\_variables,"ship"
\\*GLOBAL\\*,creator\\_email,erd.data@noaa.gov
\\*GLOBAL\\*,creator\\_name,Bob Simons
\\*GLOBAL\\*,creator\\_type,person
\\*GLOBAL\\*,creator\\_url,https://www.pfeg.noaa.gov
\\*GLOBAL\\*,featureType,trajectory
\\*GLOBAL\\*,infoUrl,https://erddap.github.io/docs/user/nccsv-1.20
\\*GLOBAL\\*,institution,"NOAA NMFS SWFSC ERD, NOAA PMEL"
\\*GLOBAL\\*,license,"""NCCSV Demonstration"" by Bob Simons and Steve Hankin is
licensed under CC BY 4.0, https://creativecommons.org/licenses/by/4.0/ ."
\\*GLOBAL\\*,keywords,"NOAA, sea, ship, sst, surface, temperature, trajectory"
\\*GLOBAL\\*,standard\\_name\\_vocabulary,CF Standard Name Table v55
\\*GLOBAL\\*,subsetVariables,"ship"
\\*GLOBAL\\*,summary,"This is a paragraph or two describing the dataset."
\\*GLOBAL\\*,title,"NCCSV Demonstration"
ship,\\*DATA\\_TYPE\\*,String
ship,cf\\_role,trajectory\\_id
time,\\*DATA\\_TYPE\\*,String
time,standard\\_name,time
time,units,"yyyy-MM-dd'T'HH:mm:ssZ"
lat,\\*DATA\\_TYPE\\*,double
lat,units,degrees\\_north
lon,\\*DATA\\_TYPE\\*,double
"lon","units","degrees\\_east"
status,\\*DATA\\_TYPE\\*,char
status,comment,"From http://some.url.gov/someProjectDocument , Table C"
testByte,\\*DATA\\_TYPE\\*,byte
testByte,units,1
testUByte,\\*DATA\\_TYPE\\*,ubyte
testUByte,units,1
testLong,\\*DATA\\_TYPE\\*,long
testLong,units,1
testULong,\\*DATA\\_TYPE\\*,ulong
testULong,units,1
sst,\\*DATA\\_TYPE\\*,float
sst,standard\\_name,sea\\_surface\\_temperature
sst,actual\\_range,0.17f,23.58f
sst,units,degree\\_C
sst,missing\\_value,99f
sst,testBytes,-128b,0b,127b
sst,testShorts,-32768s,0s,32767s
sst,testInts,-2147483648i,0i,2147483647i
sst,testLongs,-9223372036854775808L,0L,9223372036854775807L
sst,testFloats,-3.40282347e38f,0f,3.40282347E+38f
sst,testDoubles,-1.79769313486231570e308d,0d,1.79769313486231570E+308d
sst,testChars,"','","'""'","'€'"
sst,testStrings," a~,\\n'z""\\u20AC"
sst,testUBytes,0ub,127ub,255ub
sst,testUInts,0ui,2147483647ui,4294967295ui
sst,testULongs,0uL,9223372036854775807uL,18446744073709551615uL
sst,testUShorts,0us,32767us,65535us
\\*END\\_METADATA\\*
ship,time,lat,lon,status,testByte,testUByte,testLong,testULong,sst
Bell M. Shimada,2017-03-23T00:45:00Z,28.0002,-130.2576,A,-128, 0,-9223372036854775808L,0uL,10.9
Bell M. Shimada,2017-03-23T01:45:00Z,28.0003,-130.3472,\\u20AC,0,127,-9007199254740992L,9223372036854775807uL,10.0
"Bell M. Shimada","2017-03-23T02:45:00Z",28.0001,-130.4305,"'\\t'",126,254,9223372036854775806L,18446744073709551614uL,99
"Bell M. Shimada",2017-03-23T12:45:00Z,27.9998,-131.5578,"'""'",127,255,9223372036854775807L,18446744073709551615uL,NaN
Note:
- Questo file campione include molti casi difficili (ad esempio, carbone e variabili lunghe e valori difficili) . La maggior parte dei file NCCSV sarà molto più semplice.
- La linea di licenza è rotta in due righe qui, ma è solo una linea nel file campione.
- \u20ac è il\uhhhh codifica di €. \u00FC è la\uhhhh codificazione del ü. È inoltre possibile utilizzare i caratteri non codificati direttamente.
- Molti Le stringhe nell'esempio sono racchiuse da doppie citazioni anche se non devono essere, ad esempio, molti attributi globali tra cui il titolo, l'attributo unità lon e la terza linea di dati.)
- Sarebbe più chiaro e migliore se l'attributo delle unità per il testLong variabile è stato scritto in doppia citazione che indica che è un valore String. Ma la rappresentazione attuale (1, senza citazioni) sarà interpretato correttamente come uno String, non un intero, perché non c'è 'i' suffisso.
- A differenza di altri tipi di dati numerici, i valori lunghi nella sezione dati hanno il suffisso ('L') che identifica il loro tipo di dati numerico. Ciò è necessario per impedire ai fogli di calcolo di interpretare i valori come numeri di punti fluttuanti e quindi perdere precisione.
Fogli di calcolo
In un foglio di calcolo, come in un file NCCSV:
- Scrivere valori di attributo numerico come specificato per i file NCCSV (ad esempio, con una lettera suffissa, ad esempio, 'f', per identificare il tipo di dati dell'attributo) .
- In Strings, tutti i caratteri non stampabili e speciali devono essere scritti come un personaggio di backslashed simile a JSON (ad esempio,\nper la nuova linea) o come numero di carattere esadecimale Unicode (caso insensibile) con la sintassi# # . In particolare, uso\n (2 caratteri: backslash e 'n ') per indicare una nuova linea all'interno di uno String, non Alt Enter. Tutti i caratteri stampabili possono essere scritti non codificati o con la sintassi# # .
Le uniche differenze tra i file NCCSV e il foglio di calcolo analogo che seguono queste convenzioni sono:
- I file NCCSV hanno valori su una linea separata da virgole. I fogli di calcolo hanno valori su una linea nelle celle adiacenti.
- Le stringhe nei file NCCSV sono spesso circondate da doppie citazioni. Le stringhe nei fogli di calcolo non sono mai circondate da doppie citazioni.
- Virgolette interne (") in Strings in file NCCSV appaiono come 2 doppie citazioni. Le doppie citazioni interne nei fogli di calcolo appaiono come 1 doppia citazione.
Se un foglio di calcolo che segue queste convenzioni viene salvato come file CSV, ci saranno spesso virgole extra alla fine di molte delle righe. Il software che converte i file NCCSV in.nci file ignoreranno le virgole extra.
Excel
Per importare un file NCCSV in Excel:
- Scegliere File: Apri .
- Modificare il tipo di file in File di testo (\.prn;\.txt; \*.csv) .
- Cerca le directory e clicca sul file NCCSV .csv.
- Fare clic su Apri .
Per creare un file NCCSV da un foglio di calcolo Excel:
- Scegliere File: Salva come .
- Modificare il Salva come tipo: per essere CSV (Comma delimitato) (*) .
- In risposta all'avviso di compatibilità, fare clic su Sì .
- Il file .csv risultante avrà virgole extra alla fine di tutte le righe diverse dalle righe CSV. Puoi ignorarli.
In Excel, il file NCCSV campione sopra appare come
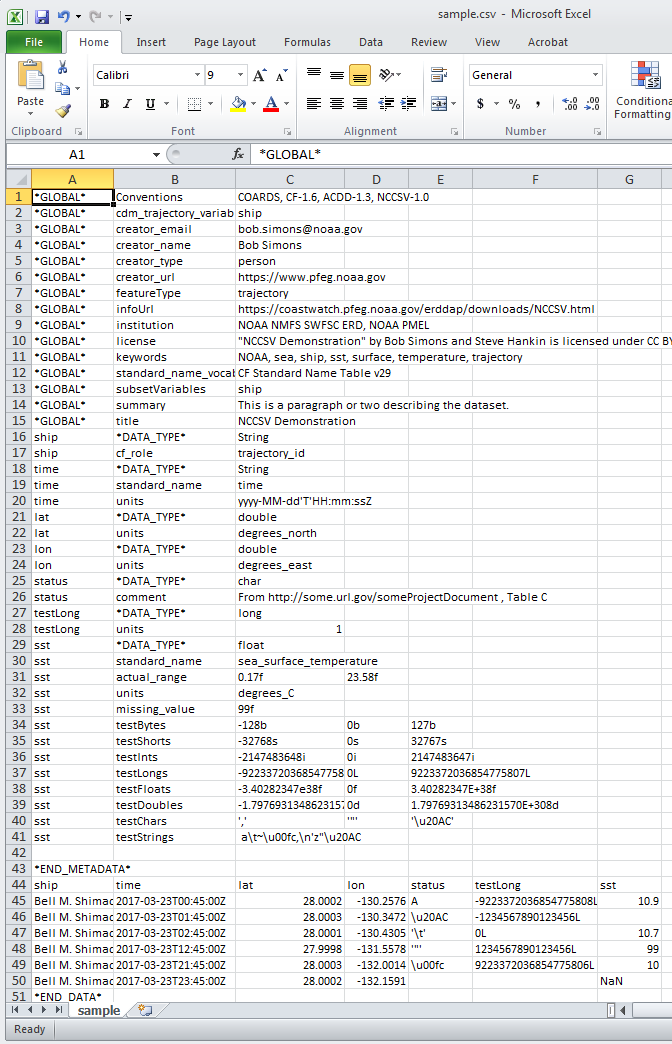
Fogli di Google
Per importare un file NCCSV in Google Sheets:
- Scegliere File: Import .
- Scegliere di caricare un file e fare clic su Carica un file dal computer . Selezionare il file, quindi fare clic su Apri .
Oppure, scegliere My Drive e cambiare il tipo di file a discesa selezione a tutti i tipi di file . Selezionare il file, quindi fare clic su Apri .
Per creare un file NCCSV da un foglio di calcolo Google Sheets:
- Scegliere File: Salva come .
- Modificare il Salva come tipo: per essere CSV (Comma delimitato) (*) .
- In risposta all'avviso di compatibilità, fare clic su Sì .
- Il file .csv risultante avrà virgole extra alla fine di tutte le righe diverse dalle righe CSV. Ignorali.
Problemi / Avvertenze
- Se si crea un file NCCSV con un editor di testo o se si crea un foglio di calcolo analogo in un programma di foglio di calcolo, l'editor di testo o il programma di foglio di calcolo non controllerà che hai seguito queste convenzioni correttamente. Spetta a voi seguire correttamente queste convenzioni.
- La conversione di un foglio di calcolo dopo questa convenzione in un file csv (quindi, un file NCCSV) porterà a virgole extra alla fine di tutte le righe diverse dalle righe di dati CSV. Ignorali. Il software quindi converte i file NCCSV in.nci file li ignoreranno.
- Se un file NCCSV ha virgole in eccesso alla fine delle righe, è possibile rimuoverli convertendo il file NCCSV in unNetCDFfile e quindi la conversione delNetCDFfile di nuovo in un file NCCSV.
- Quando si tenta di convertire un file NCCSV in unNetCDFfile, alcuni errori saranno rilevati dal software e genererà messaggi di errore, causando la conversione a fallire. Altri problemi sono difficili o impossibili da catturare e non genereranno messaggi di errore o avvisi. Altri problemi (ad esempio, virgole in eccesso alla fine delle righe) sarà ignorato. Il convertitore di file farà solo il controllo minimo della correttezza del risultatoNetCDFfile, ad esempio, per quanto riguarda la conformità CF. È responsabilità del creatore del file e dell'utente del file verificare che i risultati della conversione sono come desiderato e corretto. Due modi per controllare sono:
- Stampa il contenuto del.ncfile con ncdump ( https://linux.die.net/man/1/ncdump ) .
- Visualizza il contenuto dei dati inERDDAP™.
Cambiamenti
La versione originale eraNCCSV v1.00 (inERDDAP™v1.76, rilasciato 2017-05-12)
- Variazioni introdotteNCCSV v1.10 (inERDDAP™v2.10, rilasciato 2020-11-05) :
- Aggiunto il supporto per ubyte, ushort, uint, ulong. Grazie a CF per aggiungere supporto per questi tipi di dati in CF.
- Variazioni introdotte in v1.20 (inERDDAP™v2.23, rilasciato 2023-02-27) :
- Passato dalla codifica dei caratteri ASCII alla codifica UTF-8 per i file NCCSV .csv.
- ERDDAP™può ancora leggere i file da tutte le versioni precedenti e attuali di NCCSV.
- ERDDAP™ora scrive sempre i file NCCSV v1.20.
- Se hai scritto un client per leggere i file NCCSV, cambialo così tratta tutti i file NCCSV come file UTF-8. Questo funzionerà con i file NCCSV più vecchi perché ASCII è un sottoinsieme della codifica del carattere UTF-8.
- Grazie a Pauline Chauvet, Nate e Thomas Gardiner.
- Passato dalla codifica dei caratteri ASCII alla codifica UTF-8 per i file NCCSV .csv.