एनसीसीएसवी
ANetCDFसंगत, UTF-8, CSV फ़ाइल विनिर्देश संस्करण 1.20
बॉब सिमोन और स्टीव Hankin बॉब सि�मोन और स्टीव हैनकिन द्वारा "NCCSV" को लाइसेंस दिया गया है।सीसी द्वारा 4.0
परिचय
यह दस्तावेज़ एक UTF-8 CSV टेक्स्ट फ़ाइल प्रारूप को निर्दिष्ट करता है जिसमें सभी जानकारी शामिल हो सकती है। (मेटाडाटा और डेटा) कि एक में पाया जा सकता हैNetCDF .ncफ़ाइल जिसमें डेटा की CSV फ़ाइल जैसी तालिका होती है। इस विनिर्देश के बाद एक UTF-8 CSV टेक्स्ट फ़ाइल के लिए फ़ाइल एक्सटेंशन .csv होना चाहिए ताकि इसे आसानी से और सही ढंग से एक्सेल और गूगल शीट जैसे स्प्रेडशीट कार्यक्रमों में पढ़ा जा सके। बॉब सिमोन एक NCCSV फ़ाइल को एक में बदलने के लिए सॉफ्टवेयर लिखेंगेNetCDF-3 (शायदNetCDF-4) .ncफ़ाइल, और रिवर्स, सूचना के नुकसान के साथ। बॉब सिमोन संशोधित हैERDDAP™इस प्रकार की फ़ाइल पढ़ने और लिखने का समर्थन करने के लिए।
एनसीसीएसवी प्रारूप को डिज़ाइन किया गया है ताकि एक्सेल और गूगल शीट्स जैसे स्प्रेडशीट सॉफ़्टवेयर को संपादन के लिए तैयार स्प्रेडशीट कोशिकाओं में सभी जानकारी के साथ एक एनसीसीएसवी फ़ाइल के रूप में आयात किया जा सकता है। या, NCCSV सम्मेलनों के बाद एक स्प्रेडशीट को खरोंच से बनाया जा सकता है। स्प्रेडशीट के स्रोत के बावजूद, अगर इसे फिर एक .csv फ़ाइल के रूप में निर्यात किया जाता है, तो यह NCCSV विनिर्देश के अनुरूप होगा और कोई जानकारी नहीं खो जाएगी। NCCSV फ़ाइलों और अनुरूप स्प्रेडशीट फ़ाइलों के बीच एकमात्र अंतर है जो इन सम्मेलनों का पालन करते हैं:
- NCCSV फ़ाइलों में एक लाइन पर मान होता है जो अल्पविराम से अलग होती है। स्प्रेडशीट के पास आसन्न कोशिकाओं में एक रेखा पर मान होता है।
- NCCSV फ़ाइलों में स्ट्रिंग अक्सर डबल उद्धरण से घिरे होते हैं। स्प्रेडशीट में स्ट्रिंग कभी डबल उद्धरण से घिरा नहीं है।
- आंतरिक डबल उद्धरण (") NCCSV फ़ाइलों में स्ट्रिंग में 2 डबल उद्धरण के रूप में दिखाई देते हैं। स्प्रेडशीट में आंतरिक डबल उद्धरण 1 डबल उद्धरण के रूप में दिखाई देते हैं।
देखेंस्प्रेडशीटअधिक जानकारी के लिए नीचे अनुभाग।
स्ट्रीमिंग
सामान्य रूप से CSV फ़ाइलों की तरह, NCCSV फ़ाइलों को स्ट्रीम करने योग्य हैं। इस प्रकार, यदि किसी NCSV को डेटा सर्वर जैसे डेटा सर्वर द्वारा ऑन-द-फ्लाई उत्पन्न किया जाता है।ERDDAP™सर्वर सभी डेटा एकत्र होने से पहले अनुरोधकर्ता को डेटा स्ट्रीम करना शुरू कर सकता है। यह एक उपयोगी और वांछनीय विशेषता है।NetCDFइसके विपरीत, फ़ाइलों को स्ट्रीम करने योग्य नहीं हैं।
ERDDAP
इस विनिर्देश को डिज़ाइन किया गया है ताकि एनसीसीएसवी फ़ाइलों और एनसीसीएसवी फ़ाइलों को डिजाइन किया जा सके।.ncउन फ़ाइलों को जो उनसे बनाई जा सकती हैं, उन्हें एक द्वारा इस्तेमाल किया जा सकता हैERDDAP™डेटा सर्वर (के माध्यम सेEDDTableFromNccsvFilesऔरEDDTableFromNcFilesडेटासेट प्रकार) लेकिन यह विनिर्देश बाहरी हैERDDAP।ERDDAP™कई आवश्यक वैश्विक विशेषताओं और कई अनुशंसित वैश्विक और परिवर्तनीय विशेषताओं, ज्यादातर CF और ACDD विशेषताओं पर आधारित है (देखें) /docs/server-admin/datasets#global-attributes).
शेष
एनसीसीएसवी प्रारूप का डिजाइन कई आवश्यकताओं का संतुलन है:
- फ़�ाइलों में सभी डेटा और मेटाडाटा होना चाहिए जो सारणीबद्ध में होगाNetCDFविशिष्ट डेटा प्रकार सहित फ़ाइल।
- फ़ाइलों को पढ़ने में सक्षम होना चाहिए और फिर किसी स्प्रेडशीट से बाहर लिखना चाहिए जिसमें सूचना का कोई नुकसान नहीं है।
- फ़ाइलों को बनाने, संपादित करने, पढ़ने और समझने के लिए मनुष्यों के लिए आसान होना चाहिए।
- फ़ाइलों को कंप्यूटर प्रोग्रामों द्वारा अस्पष्ट रूप से पार करने में सक्षम होना चाहिए।
यदि इस दस्तावेज़ में कुछ आवश्यकता विषम या picky लगती है, तो संभवतः इन आवश्यकताओं में से एक को पूरा करने की आवश्यकता होती है।
अन्य निर्दिष्टीकरण
यह विनिर्देश कई अन्य विनिर्देशों और पुस्तकालयों को संदर्भित करता है कि यह काम करने के लिए डिज़ाइन किया गया है, लेकिन यह विनिर्देश उन अन्य विनिर्देशों में से किसी का हिस्सा नहीं है, न ही उन्हें किसी भी बदलाव की आवश्यकता है, न ही यह उनके साथ संघर्ष करता है। यदि इन मानकों में से एक से संबंधित विवरण यहां निर्दिष्ट नहीं है, तो संबंधित विनिर्देश देखें। विशेष रूप से, इसमें शामिल हैं:
- डेटासेट डिस्कवरी के लिए योगदान सम्मेलन (एसीडी) मेटाडाटा मानक: https://wiki.esipfed.org/Attribute\_Convention\_for\_Data\_Discovery\_1-3 ।
- जलवायु और पूर्वानुमान (CF) मेटाडाटा मानक: https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html ।
- The The most of theNetCDFउपयोगकर्ता गाइड (एनयूजी) : https:///docs.unidata.ucar.edu/netcdf-java/current/userguide/index.html ।
- The The most of theNetCDFसॉफ्टवेयर पुस्तकालयों की तरहNetCDF-जावा औरNetCDFसी: https://www.unidata.ucar.edu/software/netcdf/ । य��े पुस्तकालय एनसीसीएसवी फ़ाइलों को नहीं पढ़ सकते हैं, लेकिन वे पढ़ सकते हैं.ncNCCSV फ़ाइलों से बनाई गई फाइलें।
- JSON: https://www.json.org/
अधिसूचना
इस विनिर्देशन में, कोष्ठक,\[ \], वैकल्पिक आइटम को दर्शाता है।
फ़ाइल संरचना
एक पूर्ण एनसीसीएसवी फ़ाइल में दो खंड होते हैं: मेटाडाटा अनुभाग, उसके बाद डेटा अनुभाग।
NCCSV फ़ाइलों में किसी भी UCS-2 वर्ण हो सकते हैं (i.e., 2-byte Unicode वर्ण, as inJava) UTF-8 के माध्यम से एन्कोड किया गया।ERDDAP™UTF-8 एन्कोडिंग का उपयोग करके NCCSV फ़ाइलों को पढ़ और लिखते हैं।
NCCSV फ़ाइलों को या तो newline का उपयोग कर सकते हैं (\n) (जो लिनक्स और मैक ओएस एक्स कंप्यूटर पर आम है) या गाड़ी वापसी प्लस नईलाइन (\r\n) (जो विंडोज कंप्यूटर पर आम है) अंत लाइन मार्करों के रूप में, लेकिन दोनों नहीं।
.nccsvमेटाडाटा
जब दोनों निर्माता और पाठक इसकी उम्मीद कर रहे हैं, तो यह भी संभव है और कभी-कभी एक NCCSV फ़ाइल का एक संस्करण बनाने में उपयोगी होता है जिसमें सिर्फ मेटाडाटा अनुभाग होता है। (सहित\*END \_METADATA\*रेखा) । परिणाम फ़ाइल की विशेषताओं, परिवर्तनीय नामों और डेटा प्रकारों का एक पूरा विवरण प्रदान करता है, इस प्रकार .das plus .dds प्रतिक्रियाओं के समान उद्देश्य की सेवा करता है।OPeNDAPसर्वरERDDAP™यदि आप फ़ाइल का अनुरोध करते हैं तो यह विविधता वापस आ जाएगी टाइप.nccsvमेटाडाटा से एकERDDAP™डेटासेट।
मेटाडाटा अनुभाग
एक NCCSV फ़ाइल में, मेटाडाटा अनुभाग की प्रत्येक पंक्ति प्रारूप का उपयोग करती है
चर नाम,विशेषता नाम,मूल्य1\[मूल्य2\]\[मूल्य3\]\[मूल्य4\]\[......\]
इससे पहले या बाद में आइटम की अनुमति नहीं है क्योंकि वे फ़ाइल को स्प्रेडशीट प्रोग्राम में आयात करते समय समस्याएं पैदा करते हैं।
सम्मेलन
एनसीसीएसवी फ़ाइल की पहली पंक्ति मेटाडाटा अनुभाग की पहली पंक्ति है और इसमें एक होना चाहिए\ग्लोबल\सम्मेलनों की विशेषता फ़ाइल में प्रयुक्त सभी सम्मेलनों को एक स्ट्रिंग के रूप में सूचीबद्ध करती है जिसमें CSV सूची शामिल है, उदाहरण के लिए: \*ग्लोबल\*सम्मेलनोंCOARDS, CF-1.6, ACDD-1.3, NCCSV-1.2 " सूचीबद्ध सम्मेलनों में से एक NCCSV-1.2 होना चाहिए, जो इस विनिर्देश के वर्तमान संस्करण को संदर्भित करता है।
अंत Metadata
एनसीसीएसवी फ़ाइल के मेटाडाटा अनुभाग के अंत को केवल एक पंक्ति द्वारा दर्शाया जाना चाहिए \END \_METADATA\
यह अनुशंसा की जाती है लेकिन यह आवश्यक नहीं है कि किसी दिए गए चर के लिए सभी गुण मेटाडाटा अनुभाग के आसन्न लाइनों पर दिखाई देते हैं। यदि एक NCCSV फ़ाइल को एक में बदल दिया जाता हैNetCDFफ़ाइल, यह आदेश कि वेरिएबलनाम पहले मेटाडाटा अनुभाग में दिखाई देते हैं, वेरिएबल का क्रम होगा।NetCDFफ़ाइल
वैकल्पिक रिक्त लाइनों के साथ आवश्यक पहली पंक्ति के बाद मेटाडाटा अनुभाग में अनुमति दी जाती है\ग्लोबल\ सम्मेलनसूचना (नीचे देखें) और इससे पहले अपेक्षित अंतिम पंक्ति के साथ\END \_METADATA\।
यदि एक स्प्रेडशीट एक NCCSV फ़ाइल से बनाई गई है, तो मेटाडाटा डेटा अनुभाग कॉलम A में परिवर्तनीय नामों के साथ दिखाई देगा, कॉलम B में नामों का श्रेय देगा और स्तंभ C में मान होगा।
यदि इन सम्मेलनों के बाद एक स्प्रेडशीट को CSV फ़ाइल के रूप में सहेजा जाता है, तो मेटाडाटा अनुभाग में लाइनों के अंत में अक्सर अतिरिक्त अल्पविराम होंगे। सॉफ्टवेयर जो NCCSV फ़ाइलों को परिवर्तित करता है.ncफ़ाइलों को अतिरिक्त अल्पविराम को अनदेखा करेगा।
चर नाम
चर नाम डेटा फ़ाइल में एक चर का केस-संवेदनशील नाम है। सभी परिवर्तनीय नामों को 7-bit ASCII अक्षर या अंडरस्कोर के साथ शुरू करना चाहिए और 7-bit ASCII अक्षरों, अंडरस्कोर और 7-bit ASCII अंकों से बना होना चाहिए।
ग्लोबल
विशेष चरनाम\ग्लोबल\इसका उ��पयोग वैश्विक मेटाडाटा को दर्शाने के लिए किया जाता है।
विशेषता नाम
विशेषता नाम एक वैरिएबल के साथ जुड़े एक विशेषता का केस-संवेदनशील नाम है या\ग्लोबल\। सभी विशेषताओं के नाम 7-bit ASCII अक्षर या अंडरस्कोर के साथ शुरू होना चाहिए और 7-bit ASCII अक्षरों, अंडरस्कोर और 7-bit ASCII अंकों से बना होना चाहिए।
स्कॉलर
विशेष विशेषता नाम\*स्कॉलर\*इसका उपयोग स्केलर डेटा वेरिएबल बनाने और इसके मूल्य को परिभाषित करने के लिए किया जा सकता है। डेटा प्रकार\*स्कॉलर\*चर के लिए डेटा प्रकार को परिभाषित करता है, इसलिए एक निर्दिष्ट नहीं है\*DATA \_TYPE\*स्केलर चर के लिए विशेषता। ध्यान दें कि एनसीसीएसवी फ़ाइल के डेटा अनुभाग में स्केलर परिवर्तनीय के लिए डेटा नहीं होना चाहिए।
उदाहरण के लिए, मूल्य "Okeanos Explorer" और cf\role विशेषता के साथ "शिप" नामक एक स्केलर चर बनाने के लिए, उपयोग करें: जहाज़\स्कॉलर\"Okeanos एक्सप्लोरर" जहाज, cf \_role, trajectory \_id जब एक स्केलर डेटा चर में पढ़ा जाता हैERDDAP™, स्केलर मान को हर पंक्ति पर समान मूल्य के साथ डेटा तालिका में एक कॉलम में परिवर्तित किया जाता है।
मूल्य
मूल्य मेटाडाटा विशेषता का मान है और एक सारणी होना चाहिए जिसमें एक बाइट, Ubyte, शॉर्ट, ushort, int, Uint, लॉन्ग, ulong, फ्लोट, डबल, स्ट्रिंग, या चार शामिल हों। अन्य डेटा प्रकारों का समर्थन नहीं किया जाता है। कोई मूल्य के साथ योगदान को अनदेखा नहीं किया जाएगा। यदि एक से अधिक उप-मूल्य है, तो उप-मूल्य सभी समान डेटा प्रकार के होना चाहिए। स्ट्रिंग्स के अलावा अन्य डेटा प्रकारों के लिए, मानों को अल्पविराम से अलग किया जाना चाहिए, उदाहरण के लिए: sst,actual\_range,0.17f,23.58f स्ट्रिंग्स के लिए एक स्ट्रिंग का उपयोग करें\n (नौटंकी) वर्ण सबस्ट्रिंग को अलग करते हैं।
विशेषता डेटा प्रकार की परिभाषाएं हैं:
बाइट
- byte विशेषता मान (8 बिट, हस्ताक्षरित) suffix 'b' के साथ लिखा जाना चाहिए, उदाहरण के लिए, -7b, 0b, 7b। मान्य बाइट मूल्यों की सीमा -128 से 127 है। एक नंबर जो एक बाइट की तरह दिखता है लेकिन अवैध है (उदाहरण के लिए, 128b) एक त्रुटि संदेश उत्पन्न करने या त्रुटि संदेश उत्पन्न करने के लिए एक लापता मान में परिवर्तित किया जाएगा।
Ubyte
- Ubyte विशेषता मान (8-bit, unsigned) suffix 'ub' के साथ लिखा जाना चाहिए, उदाहरण के लिए, 0ub, 7ub, 250ub। मान की सीमा 0 से 255 है। एक संख्या जो एक ubyte की तरह दिखती है लेकिन अवैध है (उदाहरण के लिए, 256ub) एक त्रुटि संदेश उत्पन्न करने या त्रुटि संदेश उत्पन्न करने के लिए एक लापता मान में परिवर्तित किया जाएगा। जब संभव हो, तो Ubyte के बजाय बाइट का उपयोग करें, क्योंकि कई सिस्टम असाइन किए गए बाइट का समर्थन नहीं करते हैं (उदाहरण के लिए, विशेषताओं मेंNetCDF-3 फाइलें) ।
छोटा
- लघु विशेषता मान (16 बिट, हस्ताक्षरित) Suffix 's' के साथ लिखा जाना चाहिए, उदाहरण के लिए, -30000s, 0s, 30000s। वैध लघु मानों की सीमा -32768 से 32767 है। एक संख्या जो एक छोटी सी लगती है लेकिन अवैध है (उदाहरण के लिए, 32768) एक त्रुटि संदेश उत्पन्न करने या त्रुटि संदेश उत्पन्न करने के लिए एक लापता मान में परिवर्तित किया जाएगा।
Ushort
- Ushort विशेषता मान (16-bit, unsigned) 'us', उदाहरण के लिए, 0us, 30000us, 60000us के साथ लिखा जाना चाहिए। वैध लघु मानों की सीमा 0 से 65535 है। एक संख्या जो एक ushort की तरह दिखती है लेकिन अवैध है (उदाहरण के लिए, 65536us) एक त्रुटि संदेश उत्पन्न करने या त्रुटि संदेश उत्पन्न करने के लिए एक लापता मान में परिवर्तित किया जाएगा। जब संभव हो, तो ushort के बजाय शॉर्ट का उपयोग करें, क्योंकि कई सिस्टम असाइन किए गए बाइट का समर्थन नहीं करते हैं (उदाहरण के लिए, विशेषताओं मेंNetCDF-3 फाइलें) ।
बाइट
- Int विशेषता मान (32 बिट, हस्ताक्षरित) एक दशमलव बिंदु या घाती के बिना JSON ints के रूप में लिखा जाना चाहिए, लेकिन प्रत्यय 'i' के साथ, उदाहरण के लिए, -12067978i, 0i, 12067978i। मान की सीमा -2147483648 से 2147483647 है। एक नंबर जो एक int की तरह दिखता है लेकिन अवैध है (उदाहरण क��े लिए, 2147483648i) एक त्रुटि संदेश उत्पन्न करने या त्रुटि संदेश उत्पन्न करने के लिए एक लापता मान में परिवर्तित किया जाएगा।
हिंदी
- Uint विशेषता मान (32-bit, unsigned) एक दशमलव बिंदु या घातक के बिना JSON ints के रूप में लिखा जाना चाहिए, लेकिन प्रत्यय 'ui', उदाहरण के लिए, 0ui, 12067978ui, 4123456789ui के साथ। मान की सीमा 0 से 4294967295 है। एक संख्या जो एक संकेत की तरह दिखती है लेकिन अवैध है (उदाहरण के लिए, 2147483648ui) एक त्रुटि संदेश उत्पन्न करने या त्रुटि संदेश उत्पन्न करने के लिए एक लापता मान में परिवर्तित किया जाएगा। जब संभव हो, तो यूंट के बजाय इंट का उपयोग करें, क्योंकि कई सिस्टम बिना हस्ताक्षर किए बाइट का समर्थन नहीं करते हैं (उदाहरण के लिए, विशेषताओं मेंNetCDF-3 फाइलें) ।
लंबा
- लंबी विशेषता मान (64-बिट, हस्ताक्षरित, वर्तमान में NUG द्वारा समर्थित औरERDDAP™लेकिन अभी तक CF द्वारा समर्थित नहीं है) एक दशमलव बिंदु के बिना और प्रत्यय 'एल' के साथ लिखा जाना चाहिए, उदाहरण के लिए, -12345678987654321L, 0L, 12345678987654321L। यदि आप रूपांतरण सॉफ्टवेयर का उपयोग करते हैं तो एक NCCSV फ़ाइल को लंबे मूल्यों के साथ एक NCCSV फ़ाइल में परिवर्तित करने के लिए।NetCDF-3 फ़ाइल, किसी भी लंबे मूल्यों को डबल मान में परिवर्तित किया जाएगा। वैध लंबे मूल्यों की सीमा -9223372036854775808 से 9223372036854775807 है। एक संख्या जो लंबे समय तक दिखती है लेकिन अवैध है (उदाहरण के लिए, 9223372036854775808L) एक त्रुटि संदेश उत्पन्न करने या त्रुटि संदेश उत्पन्न करने के लिए एक लापता मान में परिवर्तित किया जाएगा। जब संभव हो, तो ulong के बजाय डबल का उपयोग करें, क्योंकि कई सिस्टम लंबे समय तक समर्थन नहीं करते हैं (उदाहरण के लिएNetCDF-3 फाइलें) ।
ऊँचा
- लंबी विशेषता मान (64-bit, unsigned, वर्तमान में NUG द्वारा समर्थित औरERDDAP™लेकिन अभी तक CF द्वारा समर्थित नहीं है) एक दशमलव बिंदु के बिना और प्रत्यय 'यूएल' के साथ लिखा जाना चाहिए, उदाहरण के लिए, 0uL, 12345678987654321uL, 9007199254740992uL। यदि आप रूपांतरण सॉफ्टवेयर का उपयोग करते हैं तो एक NCCSV फ़ाइल को लंबे मूल्यों के साथ एक NCCSV फ़ाइल में परिवर्तित करने के लिए।NetCDF-3 फ़ाइल, किसी भी लंबे मूल्यों को डबल मान में परिवर्तित किया जाएगा। वैध लंबे मूल्यों की सीमा 0 से 18446744073709551615 है। एक संख्या जो एक ulong की तरह दिखती है लेकिन अवैध है (उदाहरण के लिए, 18446744073709551616uL) एक त्रुटि संदेश उत्पन्न करने या त्रुटि संदेश उत्पन्न करने के लिए एक लापता मान में परिवर्तित किया जाएगा। जब संभव हो, तो ulong के बजाय डबल का उपयोग करें, क्योंकि कई सिस्टम लंबे समय तक हस्ताक्षरित या हस्ताक्षरित समर्थन नहीं करते हैं (उदाहरण के लिएNetCDF-3 फाइलें) ।
फ्लोट
- फ्लोट विशेषता मान (32 बिट) Suffix 'f' के साथ लिखा जाना चाहिए और एक decimal बिंदु हो सकता है और/या एक exponent, उदाहरण के लिए, 0f, 1f, 12.34f, 1e12f, 1.23e+12f, 1.23e12f, 1.87E-7f. एक फ्लोट के लिए NaNf का उपयोग करें (लापता) मूल्य। फ्लोट की सीमा लगभग +/- 3.0282347E + 38f है (~7 महत्वपूर्ण दशमलव अंक) । एक नंबर जो फ्लोट की तरह दिखता है लेकिन अवैध है (उदाहरण के लिए, 1.0e39f) एक त्रुटि संदेश उत्पन्न करने या त्रुटि संदेश उत्पन्न करने के लिए एक लापता मान में परिवर्तित किया जाएगा।
डबल
- डबल विशेषता मान (64-बिट) Suffix 'd' के साथ लिखा जाना चाहिए और एक दशमलव बिंदु हो सकता है और / या एक घाती, उदाहरण के लिए, 0d, 1d, 12.34d, 1e12d, 1.23e+12d, 1.23e12d, 1.87E-7d। एक डबल नेन के लिए NaNd का प्रयोग करें (लापता) मूल्य। युगल ��की सीमा लगभग +/-1.79769313486231570E+308d है (~15 महत्वपूर्ण दशमलव अंक) । एक संख्या जो डबल की तरह दिखती है लेकिन अवैध है (उदाहरण के लिए, 1.0e309d) एक त्रुटि संदेश उत्पन्न करने या त्रुटि संदेश उत्पन्न करने के लिए एक लापता मान में परिवर्तित किया जाएगा।
स्ट्रिंग
- स्ट्रिंग विशेषता मान UCS-2 वर्णों का एक अनुक्रम है (i.e., 2-byte Unicode वर्ण, as inJava) , जिसे JSON-like स्ट्रिंग्स के रूप में लिखा जाना चाहिए।
- डबल उद्धरण (") एक स्ट्रिंग मान के भीतर दो डबल उद्धरण के रूप में कोडित किया जाना चाहिए ("") । यह क्या स्प्रेडशीट कार्यक्रमों की आवश्यकता होती है जब .csv फ़ाइलों को पढ़ने के लिए। यह क्या स्प्रेडशीट कार्यक्रम लिखते हैं जब आप एक स्प्रेडशीट को एक .csv फ़ाइल के रूप में सहेजते हैं।
- एक स्ट्रिंग मूल्य के भीतर विशेष जेएसओएन बैकस्लैश-��एनकोडेड वर्णों को जेएसओएन (विशेष रूप से) में कोडित किया जाना चाहिए।\n(newline), \\\ (backslash), \f (formfeed), \t (tab), \r (carriage return)\u hhhh वाक्यविन्यास एक स्प्रेडशीट में, एक टेक्स्ट सेल के भीतर एक नई लाइन निर्दिष्ट करने के लिए Alt Enter का उपयोग न करें; बजाय, उपयोग करें\n (2 वर्ण: बैकस्लैश और 'एन ') एक नई पंक्ति इंगित करने के लिए।
uhhhh
- चरित्र #32 से कम अन्य पात्रों को वाक्यविन्यास \u के साथ कोडित किया जाना चाहिए hhhh , जहां hhhh चरित्र की 4-digit hexadecimal संख्या है।
- चरित्र #126 से अधिक सभी प्रिंट करने योग्य वर्ण, उदाहरण के लिए, यूरो साइन, unencoded दिखाई दे सकता है, उदाहरण के लिए, € (यूरो चरित्र) , या साथ मेंकोड\u hhhh वाक्यविन्यास, उदाहरण के लिए, \u20AC। में संदर्भित कोड पृष्ठों को देखें https://en.wikipedia.org/wiki/Unicode विशिष्ट यूनिकोड वर्णों से जुड़े हेक्साडेसिमल संख्याओं को खोजने के लिए, या सॉफ्टवेयर लाइब्रेरी का उपयोग करें। ध्यान दें कि कुछERDDAP™आउटपुट फ़ाइल प्रकार, उदाहरण के लिए, .csv, ISO 8859-1 कैरेक्टर सेट का उपयोग करते हैं, इसलिए #255 के ऊपर यूनिकोड वर्ण खो जाएंगे जब ये डेटा मान उन फ़ाइल प्रकारों के लिए लिखे जाते हैं।
- चरित्र # 126 से अधिक सभी गैर-प्रिंट करने योग्य वर्ण, उदाहरण के लिए, चरित्र # 127, STRONGLY DISCOURAGED हैं, लेकिन आप SHOULD \uLD का उपयोग करते हैं hhhh यदि आप उन्हें शामिल करते हैं तो वाक्यविन्यास।
- यदि स्ट्रिंग की शुरुआत या अंत में एक स्थान है, या इसमें शामिल हैं " (डबल उद्धरण) या एक अल्पविराम, या उन मानों को शामिल करता है जिन्हें अन्यथा कुछ अन्य डेटा प्रकार के रूप में व्याख्या किया जाएगा। (उदाहरण के लिए, एक int) , या "null" शब्द है, पूरे स्ट्रिंग को डबल उद्धरणों में संलग्न किया जाना चाहिए; अन्यथा, JSON के विपरीत, संलग्न डबल उद��्धरण वैकल्पिक हैं। हम अनुशंसा करते हैं: जब संदेह में, पूरे स्ट्रिंग को डबल उद्धरणों में संलग्न करें। स्ट्रिंग की शुरुआत या अंत में रिक्त स्थान दृढ़ता से हतोत्साहित हैं।
char
- चार विशेषता मान एक एकल UCS-2 वर्ण हैं (i.e., 2-byte Unicode वर्ण, as inJava) । मुद्रण योग्य वर्ण (न्यूलाइन जैसे विशेष वर्णों के अलावा, ", ', और \) जैसा है लिखा जा सकता है। विशेष वर्ण (उदाहरण के लिए, न्यूलाइन) अन्य अनप्रिंटेबल वर्ण (उदाहरण के लिए, #127) होना चाहिए\u hhhh वाक्यविन्यास चार विशेषता मूल्यों एकल उद्धरण में संलग्न होना चाहिए (आंतरिक उद्धरण) और डबल उद्धरण (बाहरी उद्धरण) , उदाहरण के लिए, "'a", "'" (एक डबल उद्धरण चरित्र) , '' (एक एकल उद्धरण चरित्र) , "\t'" (एक टैब) , "\u007F" (हटाने 'character ') , और "'€'" (यूरो चरित्र) । एकल और डबल उद्धरणों का उपयोग करने की यह प्रणाली अजीब और बोझिल है, लेकिन यह एक तरह से स्ट्रिंग्स से चार मूल्यों को अलग करने का एक तरीका है जो स्प्रेडशीट के साथ काम करता है। एक मूल्य जो एक char की तरह दिखता है लेकिन अवैध है एक त्रुटि संदेश उत्पन्न करेगा। ध्यान दें कि कुछERDDAP™आउटपुट फ़ाइल प्रकार, उदाहरण के लिए, .csv, ISO 8859-1 कैरेक्टर सेट का उपयोग करते हैं, इसलिए #255 के ऊपर यूनिकोड वर्ण खो जाएंगे जब ये डेटा मान उन फ़ाइल प्रकारों के लिए लिखे जाते हैं।
Suffix
ध्यान दें कि NCCSV फ़ाइल के गुण अनुभाग में, सभी संख्यात्मक विशेषता मूल्यों में एक प्रत्यय पत्र होना चाहिए। (उदाहरण के लिए, 'बी') संख्यात्मक डेटा प्रकार की पहचान करने के लिए (उदाहरण के लिए, byte) । लेकिन एक NCCSV फ़ाइल के डेटा अनुभाग में, संख्यात्मक डेटा मानों में कभी इन प्रत्यय पत्रों को नहीं होना चाहिए (लंबे पूर्णांकों के लिए 'एल' के अपवाद के साथ और ulong पूर्णांक के लिए 'यूएल' के अपवाद के साथ) - डेटा प्रकार द्वारा निर्दिष्ट है\*DATA \_TYPE\*चर के लिए विशेषता।
डेटा प्रकार
प्रत्येक गैर के लिए डेटा प्रकारस्केलरचर को निर्दिष्ट किया जाना चाहिए\*DATA \_TYPE\*विशेषता जिसमें बाइट, ubyte, शॉर्ट, ushort, int, uint, लंब�े, ulong, फ्लोट, डबल, स्ट्रिंग, या char का मूल्य हो सकता है। (असंवेदनशील) । उदाहरण के लिए, qc \_flag,\*DATA \_TYPE\*बाइट चेतावनी: सही निर्दिष्ट करना\*DATA \_TYPE\*आपकी जिम्मेदारी है। गलत डेटा प्रकार निर्दिष्ट करना (उदाहरण के लिए, जब आपको फ्लोट निर्दिष्ट होना चाहिए) त्रुटि संदेश उत्पन्न नहीं करेगा और सूचना खो जाने का कारण बन सकती है (उदाहरण के लिए, फ्लोट मान को इन्ट्स के लिए गोल किया जाएगा) जब NCCSV फ़ाइल द्वारा पढ़ा जाता हैERDDAP™या एक में परिवर्तितNetCDFफ़ाइल
चार विवादित
चार डेटा मूल्यों का उपयोग हतोत्साहित है क्योंकि वे अन्य फ़ाइल प्रकारों में व्यापक रूप से समर्थित नहीं हैं। चार मूल्यों को एकल वर्णों के रूप में या स्ट्रिंग्स के रूप में डेटा अनुभाग में लिखा जा सकता है (विशेष रूप से, यदि आपको एक विशेष चरित्र लिखने की आवश्यकता है) । यदि एक स्ट्रिंग मिलती है, तो स्ट्रिंग का पहला चरित्र चार के मूल्य के रूप में इस्तेमाल किया जाएगा। शून्य लंबाई स्ट्रिंग्स और लापता मूल्यों को चरित्र \uff में परिवर्तित किया जाएगा। ध्यान दें किNetCDFफ़ाइल केवल एकल बाइट अक्षरों का समर्थन करती है, इसलिए चार #255 से अधिक किसी भी अक्षर को '?' में परिवर्तित किया जाएगा जब लेखनNetCDFफ़ाइलें जब तक एक charset विशेषता एक charset चर के लिए एक अलग charset निर्दिष्ट करने के लिए प्रयोग किया जाता है, ISO-8859-1 charset इस्तेमाल किया जाएगा।
लंबे और unsigned
लंबे और असाइन किए गए प्रकार की चर्चा की जाती है। हालांकि कई फ़ाइल प्रकार (उदाहरण के लिएNetCDF-4 और जेसन) औरERDDAP™लंबे और unsigned समर्थन (Ubyte, ushort, uint, ulong) मान, NCCSV फ़ाइलों में लंबे और असाइन किए गए मूल्यों का उपयोग वर्तमान में हतोत्साहित है क्योंकि वे वर्तमान में Excel, CF और CF द्वारा समर्थित नहीं हैं।NetCDF-3 फाइलें। यदि आप एक NCCSV फ़ाइल में लंबे या निर्दिष्ट मान निर्दिष्ट करना चाहते हैं (या इसी एक्सेल स्प्रेडशीट में) , आपको प्रत्यय 'एल' का उपयोग करना चाहिए ताकि एक्सेल कम परिशुद्धता के साथ फ्लोटिंग पॉइंट नंबर के रूप में संख्याओं का इलाज न करे। वर्तमान में, यदि एक NCCSV फ़ाइलों को एक में परिवर्तित किया जाता हैNetCDF-3.ncफ़ाइल, लंबे और लंबे डेटा मूल्यों को डबल मूल्यों में परिवर्तित किया जाएगा, जिससे बहुत बड़े मूल्यों के लिए सटीक नुकसान हो सकता है (लंबे समय तक, या 2^53 से अधिक लंबे और लंबे समय तक) । मेंNetCDF-3.ncफ़ाइलें, ubyte, ushort, और uint चर \_Unsigned=true मेटाडाटा विशेषता के साथ बाइट, शॉर्ट और int के रूप में दिखाई देते हैं। मेंNetCDF-3.ncफ़ाइलें, ubyte, ushort, और uint विशेषताएँ बाइट, शॉर्ट और इंट विशेषताओं के रूप में दिखाई देते हैं जिसमें संबंधित दो's-complement मान होते हैं। (उदाहरण के लिए, 255ub -1b के रूप में प्रकट होता है) । यह स्पष्ट रूप से परेशानी है, इसलिए साइन किए गए डेटा प्रकारों को जब भी संभव हो, असाइन किए गए डेटा प्रकारों के बजाय इस्तेमाल किया जाना चाहिए।
CF, ACDD, औरERDDAP™मेटाडाटा
चूंकि यह परिकल्पना की गई है कि अधिकांश NCCSV फ़ाइलें, या.ncउनमें से बनाई गई फ़ाइलों को पढ़ा जाएगाERDDAP, यह दृढ़ता से अनुशंसा की जाती है कि NCCSV फ़ाइलों में मेटाडाटा विशेषताओं को शामिल किया गया है, जिसकी आवश्यकता या अनुशंसित किया जाता है।ERDDAP™(देखें) /docs/server-admin/datasets#global-attributes). विशेषताएँ लगभग सभी CF और ACDD मेटाडाटा मानकों से हैं और डेटासेट का ठीक से वर्णन करने के लिए काम करते हैं। (कौन, कब, कहाँ, क्यों, कैसे) किसी को जो अन्यथा डेटासेट के बारे में कुछ नहीं जानता है। विशेष महत्व के बारे में, लगभग सभी संख्यात्मक चर में एक इकाई होना चाहिए, जिसमें एक इकाई होना चाहिए।UDUNITS-संगत मूल्य, उदाहरण के लिए, sst, इकाइयों, डिग्री \_C
अतिरिक्त विशेषताओ�ं को शामिल करना ठीक है जो सीएफ या एसीडीडी मानकों या से नहीं हैंERDDAP।
डेटा अनुभाग
संरचना
डेटा अनुभाग की पहली पंक्ति में परिवर्तनीय नामों की एक केस-संवेदनशील, अल्पविराम-अलग सूची होनी चाहिए। इस सूची में सभी चर मेटाडाटा अनुभाग में वर्णित किया जाना चाहिए, और इसके विपरीत (अन्य\ग्लोबल\गुण और\स्कॉलर\चर) ।
डेटा अनुभाग की दंडात्मक रेखाओं के माध्यम से दूसरे में मूल्यों की एक अल्पायोजित सूची होनी चाहिए। डेटा की प्रत्येक पंक्ति में समान संख्या मान होना चाहिए क्योंकि वेरिएबल नामों की अल्पसंख्यक सूची होगी। पहले या बाद में मूल्यों की अनुमति नहीं है क्योंकि वे फ़ाइल को स्प्रेडशीट प्रोग्राम में आयात करते समय समस्याओं का कारण बनते हैं। इस अनुभाग में प्रत्येक कॉलम में केवल मान होना चाहिए\*DATA \_TYPE\*उस चर के लिए निर्दिष्ट\*DATA \_TYPE\*उस चर के लिए विशेषता। विशेषताओं अनुभाग के विपरीत, डेटा अनुभाग में संख्यात्मक मानों में डेटा प्रकार को दर्शाने के लिए प्रत्यय पत्र नहीं होना चाहिए। विशेषताओं अनुभाग के विपरीत, डेटा अनुभाग में चार मान एकल उद्धरणों को जोड़ सकते हैं यदि उन्हें विघटन के लिए आवश्यक नहीं है (इस प्रकार, ',' और '' को यहां दर्शाया गया है) । एनसीसीएसवी फ़ाइल में इन डेटा पंक्तियों की कोई संख्या हो सकती है, लेकिन वर्तमान मेंERDDAP™केवल लगभग 2 बिलियन पंक्तियों के साथ NCCSV फ़ाइलों को पढ़ सकते हैं। सामान्य तौर पर, यह अनुशंसा की जाती है कि आप बड़े डेटासेट को एकाधिक NCCSV डेटा फ़ाइलों में विभाजित करते हैं, जिनमें प्रत्येक 1 मिलियन से कम पंक्तियां होती हैं।
अंत डेटा
डेटा अनुभाग के अंत को केवल एक पंक्ति द्वारा दर्शाया जाना चाहिए \END \_DATA\
यदि एनसीसीएसवी फ़ाइल में अतिरिक्त सामग्री है तो उसके बाद\*END \_DATA\*जब NCCSV फ़ाइल में परिवर्तित हो जाती है, तो इसे अनदेखा किया जाएगा.ncफ़ाइल इसलिए ऐसी सामग्री को हतोत्साहित किया जाता है।
इन सम्मेलनों के बाद एक स्प्रेडशीट में, चर नाम और डेटा मान कई स्तंभों में होंगे। नीचे उदाहरण देखें।
मिसिंग वैल्यू
न्यूमेरिक लापता मान को एक संख्यात्मक मान के रूप में लिखा जा सकता है जिसे एक द्वारा पहचाना जाता हैmissing\_valueउस परिवर्तनीय के लिए \_FillValue विशेषता। उदाहरण के लिए, इस डेटा पंक्ति पर दूसरा मान देखें: बेल M. Shimada,99,123.4 यह बायटे, ubyte, शॉर्ट, ushort, int, uint, लंबे और ulong चर के लिए लापता मूल्यों को संभालने का अनुशंसित तरीका है।
फ्लोट या डबल NaN मान को NaN के रूप में लिखा जा सकता है। उदाहरण के लिए, इस डेटा पंक्ति पर दूसरा मान देखें: बेल एम शिमाडा, नान, 123.4
स्ट्रिंग और संख्यात्मक लापता मूल्यों को एक खाली क्षेत्र द्वारा दर्शाया जा सकता है। उदाहरण के लिए, इस डेटा पंक्ति पर दूसरा मान देखें: बेल एम शिमाडा, 123.4
byte, ubyte, short, ushort, int, uint, long, और ulong चर के लिए, NCCSV कनवर्टर उपयोगिता औरERDDAP™उस डेटा प्रकार के लिए एक खाली क्षेत्र को अधिकतम अनुमत मान में बदल देगा (उदाहरण के लिए, बाइट्स के लिए 127) । यदि आप ऐसा करते हैं, तो एक जोड़ने के लिए सुनिश्चित करेंmissing\_valueइस मूल्य की पहचान करने के लिए उस परिवर्तनीय के लिए या \_FillValue विशेषता, उदाहरण के लिए, चर नाम , \_FillValue, 127b फ्लोट और डबल चर के लिए, एक खाली क्षेत्र को नान में परिवर्तित किया जाएगा।
डेटटाइम मान
डेटटाइम मान (तारीख मूल्यों है कि एक समय घटक नहीं है सहित) एनसीसीएसवी फ़ाइलों में संख्याओं या स्ट्रिंग के रूप में प्रतिनिधित्व किया जा सकता है। किसी दिए गए समय चर में केवल स्ट्रिंग मान या केवल संख्यात्मक मान हो सकते हैं, दोनों ही नहीं। एनसीसीएसवी सॉफ्टवेयर स्ट्रिंग डेटटाइम मूल्यों को संख्यात्मक तिथि में बदल देगा समय मान जब निर्माण.ncफ़ाइलें (सीएफ द्वारा आवश्यकतानुसार) । स्ट्रिंग डेटटाइम मूल्यों में मनुष्यों द्वारा आसानी से पढ़ने योग्य होने का लाभ होता है।
न्यूमेरिक मूल्यों के रूप में प्रतिनिधित्व करने वाले डेटटाइम मूल्यों में एक इकाई गुण होना चाहिए, जो निर्दिष्ट करता है " यूनिट बाद में तारीख समय "सीएफ द्वारा आवश्यकतानुसार और निर्दिष्ट करकेUDUNITS, उदाहरण के लिए, 1970-01-01T00:00:00Z के बाद से समय, इकाइयों, सेकंड
DateTime मूल्यों स्ट्रिंग मूल्यों के रूप में प्रतिनिधित्व एक स्ट्रिंग होना चाहिए\*DATA \_TYPE\*विशेषता और एक इकाई विशेषता जो एक तारीख निर्दिष्ट करता है द्वारा निर्दिष्ट समय पैटर्नJavaDateTimeFormatter ( https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html ) । उदाहरण के लिए, समय, इकाइयों,yyyy-MM-dd'T'H:mm: SsZ किसी दिए गए डेटा चर के लिए सभी डेटटाइम मान उसी प्रारूप का उपयोग करना चाहिए। अधिकांश मामलों में, आपको इकाइयों की विशेषता के लिए आवश्यक डेटटाइम पैटर्न इन प्रारूपों में से एक का एक रूप होगा:
- yyyy-MM-dd'T'H:mm:s. एसएसएसजेड - जो आईएसओ 8601:2004 है (E) तारीख समय स्वरूप आपको इसका एक छोटा संस्करण की आवश्यकता हो सकती है, उदाहरण के लिए,yyyy-MM-dd'T'H:mm: SsZ (केवल अनुशंसित प्रारूप) याyyyy-MM-dd। यदि आप अपने डेटटाइम मूल्यों के प्रारूप को बदल रहे हैं, तो NCCSV दृढ़ता से अनुशंसा ��करता है कि आप इस प्रारूप में बदलाव करें। (शायद छोटा) । यह प्रारूप है किERDDAP™जब यह NCCSV फ़ाइलों को लिखते हैं तो इसका उपयोग करेगा।
- yyymmddHmms.SSS — जो ISO 8601:2004 तारीख का कॉम्पैक्ट संस्करण है समय स्वरूप आपको इसका संक्षिप्त संस्करण, उदाहरण के लिए, yyyymmdd की आवश्यकता हो सकती है।
- M/d/yyyyy एच: मिमी: एस। एसएसएस - जो "3/23/2017 16:22:03.000" जैसे अमेरिकी शैली की तारीखों और तारीखों को संभालती है। आपको इसका एक छोटा संस्करण की आवश्यकता हो सकती है, उदाहरण के लिए, M/d/yyyyy.
- yyyydddhmmsssSS - जो वर्ष के साथ शून्य गद्देदार दिन है (उदाहरण के लिए, 001 = जनवरी 1, 365 = दिसंबर 31 एक गैर-लीप वर्ष में; कभी-कभी इसे कभी-कभी जूलियन तारीख कहा जाता है।) । आपको इसका एक छोटा संस्करण की आवश्यकता हो सकती है, उदाहरण के लिए, yyyddd।
प्रेसिजन
जब एक सॉफ्टवेयर पुस्तकालय एक परिवर्तित.ncएक NCCSV फ़ाइल में फ़ाइल, सभी तारीख समय मान ISO 8601:2004 के साथ स्ट्रिंग्स के रूप में लिखा जाएगा (E) तारीख समय प्रारूप, उदाहरण के लिए, 1970-01-01T00:00:00Z। आप परिशुद्धता को नियंत्रित कर सकते हैंERDDAPविशिष्ट विशेषताtime\_precision। देखें /docs/server-admin/datasets#time\_precision।
समय क्षेत्र
तारीख के लिए डिफ़ॉल्ट समय क्षेत्र समय मान हैZulu (या GMT) टाइम जोन, जिसमें कोई डेलाइट सेविंग टाइम पीरियड नहीं है। यदि एक डेटटाइम वेरिएबल के पास एक अलग समय क्षेत्र से डेटटाइम मान हैं, तो आपको इसके साथ निर्दिष्ट करना होगा।ERDDAPविशिष्ट विशेषताtime\_zone। यह आवश्यकता हैERDDAP™(देखें) /docs/server-admin/datasets#time\_zone).
डिग्री मान�
सीएफ द्वारा आवश्यकतानुसार, सभी डिग्री मान (उदाहरण के लिए, देशांतर और अक्षांश के लिए) दशमलव-डिग्री डबल मान के रूप में निर्दिष्ट किया जाना चाहिए, न कि एक डिग्री ° मिन'सेक" स्ट्रिंग या डिग्री, मिनट, सेकंड के लिए अलग-अलग चर के रूप में। निर्देश डिजाइनेटर एन, एस, ई, और डब्ल्यू की अनुमति नहीं है। पश्चिमी अक्षांशों और दक्षिण अक्षांशों के लिए नकारात्मक मूल्यों का उपयोग करें।
DSG फ़ीचर प्रकार
एक NCCSV फ़ाइल में CF असत सैम्पलिंग ज्यामिति हो सकती है ( https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html#discrete-sampling-geometries ) डेटा यह वह विशेषता है जो इस काम को बनाने के लिए है:
- CF की आवश्यकता के रूप में, NCCSV फ़ाइल में मेटाडाटा अनुभाग में एक पंक��्ति शामिल होनी चाहिए, जिसकी पहचान मेटाडाटा है।\ग्लोबल\ featureTypeविशेषता, उदाहरण के लिए, \ग्लोबल\,featureTypeट्रेजेक्टरी
- उपयोग के लिएERDDAP™, NCCSV फ़ाइल में मेटाडाटा अनुभाग में एक पंक्ति या रेखा शामिल होनी चाहिए जिसमें cf \_role=...\_id चर, e.g., जहाज, cf \_role, trajectory \_id यह CF के लिए वैकल्पिक है, लेकिन NCCSV में आवश्यक है।
- उपयोग के लिएERDDAP™, NCCSV फ़ाइल में मेटाडाटा अनुभाग में एक पंक्ति या रेखा शामिल होनी चाहिए, जिसमें वेरिएबल हर बार सेरीज़, ट्रेजेक्टरी या प्रोफाइल के साथ जुड़े होते हैं, जैसा कि आवश्यकता होती है।ERDDAP™(देखें) /docs/server-admin/datasets#cdm\_data\_type), उदाहरण के लिए, \ग्लोबल\,cdm \_trajectory \_variables, "शिप" या \ग्लोबल\,cdm \_timeseries \_variables, "station\_id, la,lon"
नमूना फ़ाइल
यहां एक नमूना फ़ाइल है जो एनसीसीएसवी फ़ाइल की कई विशेषताओं को दर्शाता है:
\\*GLOBAL\\*,Conventions,"COARDS, CF-1.6, ACDD-1.3, NCCSV-1.2"
\\*GLOBAL\\*,cdm\\_trajectory\\_variables,"ship"
\\*GLOBAL\\*,creator\\_email,erd.data@noaa.gov
\\*GLOBAL\\*,creator\\_name,Bob Simons
\\*GLOBAL\\*,creator\\_type,person
\\*GLOBAL\\*,creator\\_url,https://www.pfeg.noaa.gov
\\*GLOBAL\\*,featureType,trajectory
\\*GLOBAL\\*,infoUrl,https://erddap.github.io/docs/user/nccsv-1.20
\\*GLOBAL\\*,institution,"NOAA NMFS SWFSC ERD, NOAA PMEL"
\\*GLOBAL\\*,license,"""NCCSV Demonstration"" by Bob Simons and Steve Hankin is
licensed under CC BY 4.0, https://creativecommons.org/licenses/by/4.0/ ."
\\*GLOBAL\\*,keywords,"NOAA, sea, ship, sst, surface, temperature, trajectory"
\\*GLOBAL\\*,standard\\_name\\_vocabulary,CF Standard Name Table v55
\\*GLOBAL\\*,subsetVariables,"ship"
\\*GLOBAL\\*,summary,"This is a paragraph or two describing the dataset."
\\*GLOBAL\\*,title,"NCCSV Demonstration"
ship,\\*DATA\\_TYPE\\*,String
ship,cf\\_role,trajectory\\_id
time,\\*DATA\\_TYPE\\*,String
time,standard\\_name,time
time,units,"yyyy-MM-dd'T'HH:mm:ssZ"
lat,\\*DATA\\_TYPE\\*,double
lat,units,degrees\\_north
lon,\\*DATA\\_TYPE\\*,double
"lon","units","degrees\\_east"
status,\\*DATA\\_TYPE\\*,char
status,comment,"From http://some.url.gov/someProjectDocument , Table C"
testByte,\\*DATA\\_TYPE\\*,byte
testByte,units,1
testUByte,\\*DATA\\_TYPE\\*,ubyte
testUByte,units,1
testLong,\\*DATA\\_TYPE\\*,long
testLong,units,1
testULong,\\*DATA\\_TYPE\\*,ulong
testULong,units,1
sst,\\*DATA\\_TYPE\\*,float
sst,standard\\_name,sea\\_surface\\_temperature
sst,actual\\_range,0.17f,23.58f
sst,units,degree\\_C
sst,missing\\_value,99f
sst,testBytes,-128b,0b,127b
sst,testShorts,-32768s,0s,32767s
sst,testInts,-2147483648i,0i,2147483647i
sst,testLongs,-9223372036854775808L,0L,9223372036854775807L
sst,testFloats,-3.40282347e38f,0f,3.40282347E+38f
sst,testDoubles,-1.79769313486231570e308d,0d,1.79769313486231570E+308d
sst,testChars,"','","'""'","'€'"
sst,testStrings," a~,\\n'z""\\u20AC"
sst,testUBytes,0ub,127ub,255ub
sst,testUInts,0ui,2147483647ui,4294967295ui
sst,testULongs,0uL,9223372036854775807uL,18446744073709551615uL
sst,testUShorts,0us,32767us,65535us
\\*END\\_METADATA\\*
ship,time,lat,lon,status,testByte,testUByte,testLong,testULong,sst
Bell M. Shimada,2017-03-23T00:45:00Z,28.0002,-130.2576,A,-128, 0,-9223372036854775808L,0uL,10.9
Bell M. Shimada,2017-03-23T01:45:00Z,28.0003,-130.3472,\\u20AC,0,127,-9007199254740992L,9223372036854775807uL,10.0
"Bell M. Shimada","2017-03-23T02:45:00Z",28.0001,-130.4305,"'\\t'",126,254,9223372036854775806L,18446744073709551614uL,99
"Bell M. Shimada",2017-03-23T12:45:00Z,27.9998,-131.5578,"'""'",127,255,9223372036854775807L,18446744073709551615uL,NaN
नोट्स:
- इस नमूना फ़ाइल में कई कठिन मामले शामिल हैं (उदाहरण के लिए, चार और लंबे चर और मुश्किल स्ट्रिंग मान) । अधिकांश NCCSV फाइलें बहुत सरल होंगी।
- लाइसेंस लाइन यहां दो लाइनों में टूट गई है, लेकिन नमूना फ़ाइल में सिर्फ एक पंक्ति है।
- \u20ac है\uhhh€ का h एन्कोडिंग। \u00FC है\uhhhएच एन्कोडिंग आप सीधे अ��नकोडेड वर्णों का भी उपयोग कर सकते हैं।
- कई उदाहरण में स्ट्रिंग्स को डबल उद्धरणों द्वारा संलग्न किया जाता है, भले ही उन्हें नहीं होना चाहिए, उदाहरण के लिए, शीर्षक सहित कई वैश्विक विशेषताओं, lon इकाइयों की विशेषता, और डेटा की तीसरी पंक्ति।
- यह स्पष्ट और बेहतर होगा यदि इकाइयों को परीक्षण के लिए विशेषता दीर्घकालीन दो उद्धरणों में लिखा गया था जो इंगित करता है कि यह एक स्ट्रिंग मान है। लेकिन वर्तमान प्रतिनिधित्व (1, बिना उद्धरण) एक स्ट्रिंग के रूप में सही ढंग से व्याख्या की जाएगी, एक पूर्णांक नहीं, क्योंकि कोई 'मैं' प्रत्यय नहीं है।
- अन्य संख्यात्मक डेटा प्रकारों के विपरीत, डेटा अनुभाग में लंबे मूल्य में प्रत्यय होता है ('एल') यह उनके संख्यात्मक डेटा प्रकार की पहचान करता है। इसे स्प्रेडशीट को फ्लोटिंग पॉइंट नंबर के रूप में मानों की व्याख्या करने से रोकने और इस प्रकार परिशुद्धता खोने के लिए आवश्यक है।
स्प्रेडशीट
एक स्प्रेडशीट में, एक NCCSV फ़ाइल में:
- एनसीसीएसवी फ़ाइलों के लिए निर्दिष्ट संख्यात्मक विशेषता मान लिखें (उदाहरण के लिए, एक प्रत्यय पत्र के साथ, उदाहरण के लिए, 'f', विशेषता के डेटा प्रकार की पहचान करने के लिए) ।
- स्ट्रिंग में, सभी गैर-मुद्रित और विशेष वर्णों को JSON जैसी बैकस्लैश वर्ण के रूप में लिखा जाना चाहिए (उदाहरण के लिए\nन्यूलाइन के लिए) या हेक्साडेसिमल यूनिकोड वर्ण संख्या के रूप में (असंवेदनशील) वाक्यविन्यास\u hhhh । विशेष रूप से उपयोग\n (2 वर्ण: बैकस्लैश और 'एन ') एक स्ट्रिंग के भीतर एक नई लाइन को इंगित करने के लिए, Alt Enter नहीं। सभी प्रिंट करने योग्य पात्रों को अनकोडित या वाक्यविन्यास के साथ लिखा जा सकता है\u hhhh ।
NCCSV फ़ाइलों और अनुरूप स्प्रेडशीट के बीच एकमात्र अंतर जो इन सम्मेलनों का पालन करता है:
- NCCSV फ़ाइलों में एक लाइन पर मान होता है जो अल्पविराम से अलग होती है। स्प्रेडशीट के पास आसन्न कोशिकाओं में एक रेखा पर मान होता है।
- NCCSV फ़ाइलों में स्ट्रिंग अक्सर डबल उद्धरण से घिरे होते हैं। स्प्रेडशीट में स्ट्रिंग कभी डबल उद्धरण से घिरा नहीं है।
- आंतरिक डबल उद्धरण (") NCCSV फ़ाइलों में स्ट्रिंग में 2 डबल उद्धरण के रूप में दिखाई देते हैं। स्प्रेडशीट में आंतरिक डबल उद्धरण 1 डबल उद्धरण के रूप में दिखाई देते हैं।
यदि इन सम्मेलनों के बाद एक स्प्रेडशीट को CSV फ़ाइल के रूप में सहेजा जाता है, तो कई लाइनों के अंत में अक्सर अतिरिक्त अल्पविराम होता है। सॉफ्टवेयर जो NCCSV फ़ाइलों को परिवर्तित करता है.ncफ़ाइलों को अतिरिक्त अल्पविराम को अनदेखा करेगा।
एक्सेल
Excel में एक NCCSV फ़ाइल आयात करने के लिए:
- फ़ाइल चुनें : Open.
- फ़ाइल प्रकार को टेक्स्ट फ़ाइल में बदलें (\.prn;\.txt; \*.csv) ।
- निर्देशिका खोजें और NCCSV .csv फ़ाइल पर क्लिक करें।
- ओपन क्लिक करें।
एक एक्सेल स्प्रेडशीट से एक NCCSV फ़ाइल बनाने के लिए:
- फ़ाइल चुनें : सहेजें के रूप में.
- सेव को टाइप के रूप में बदलें: CSV होना (Comma delimited) (Csv) ।
- संगतता चेतावनी के जवाब में, हाँ पर क्लिक करें।
- जिसके परिणामस्वरूप .csv फ़ाइल में CSV पंक्तियों के अलावा अन्य सभी पंक्तियों के अंत में अतिरिक्त अल्पविराम होंगे। आप उन्हें अनदेखा कर सकते हैं।
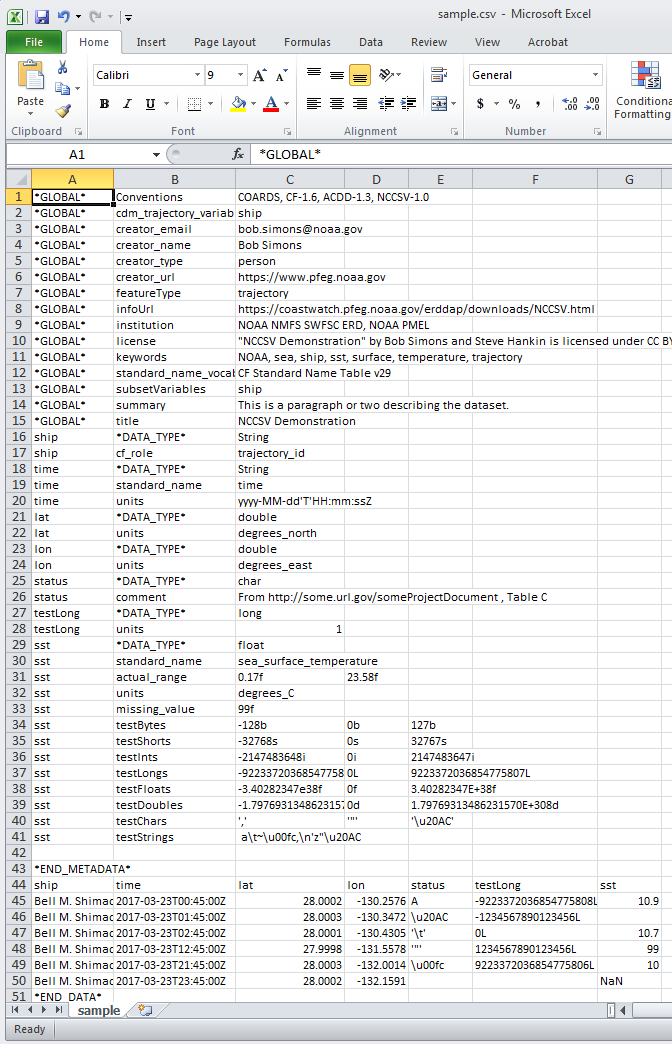
Excel में, ऊपर नमूना NCCSV फ़ाइल जैसा दिखाई देता है
गूगल शीट्स
Google शीट्स में एक NCCSV फ़ाइल आयात करने के लिए:
- फ़ाइल चुनें : आयात करें।
- एक फ़ाइल अपलोड करने के लिए चुनें और अपने कंप्यूटर से फ़ाइल अपलोड करें। फ़ाइल का चयन करें, फिर ओपन क्लिक करें।
या, मेरी ड्राइव का चयन करें और फ़ाइल प्रकार को सभी फ़ाइल प्रकारों के लिए चयन नीचे छोड़ दें। फ़ाइल का चयन करें, फिर ओपन क्लिक करें।
Google शीट्स स्प्रेडशीट से एक NCCSV फ़ाइल बनाने के लिए:
- फ़ाइल चुनें : सहेजें के रूप में.
- सेव को टाइप के रूप में बदलें: CSV होना (Comma delimited) (Csv) ।
- संगतता चेतावनी के जवाब में, हाँ पर क्लिक करें।
- जिसके परिणामस्वरूप .csv फ़ाइल में CSV पंक्तियों के अलावा अन्य सभी पंक्तियों के अंत में अतिरिक्त अल्पविराम होंगे। उन्हें पहचानो।
समस्याएं / चेतावनी
- यदि आप एक पाठ संपादक के साथ एक NCCSV फ़ाइल बनाते हैं या यदि आप एक स्प्रेडशीट कार्यक्रम में एक अनुरूप स्प्रेडशीट बनाते हैं, तो पाठ संपादक या स्प्रेडशीट कार्यक्रम यह नहीं जांचेगा कि आपने इन सम्मेलनों को सही ढंग से पालन किया है। यह आपके लिए सही तरीके से इन सम्मेलनों का पालन करने के लिए है।
- इस सम्मेलन के बाद एक स्प्रेडशीट का रूपांतरण csv फ़ाइल में (इस प्रकार, एक NCCSV फ़ाइल) CSV डेटा पंक्तियों के अलावा अन्य सभी पंक्तियों के अंत में अतिरिक्त अल्पविराम का कारण होगा। उन्हें पहचानो। इसके बाद सॉफ्टवेयर NCCSV फ़ाइलों को परिवर्तित करता है.ncफ़ाइलों को उन्हें अनदेखा करेगा।
- यदि एक NCCSV फ़ाइल में पंक्तियों के अंत में अतिरिक्त अल्पविराम है, तो आप उन्हें NCCSV फ़ाइल को एक फ़ाइल में बदलकर हटा सकते हैं।NetCDFफ़ाइल और फिर परिवर्तित करनाNetCDFएक NCCSV फ़ाइल में वापस फाइल करें।
- जब आप एक NCCSV फ़ाइल को एक में बदलने की कोशिश करते हैंNetCDFफ़ाइल, सॉफ्टवेयर द्वारा कुछ त्रुटियों का पता लगाया जाएगा और त्रुटि संदेश उत्पन्न करेगा, जिससे रूपांतरण विफल हो जाएगा। अन्य समस्याओं को पकड़ने के लिए कठिन या असंभव है और त्रुटि संदेश या चेतावनी उत्पन्न नहीं करेगा। अन्य समस्याएं (उदाहरण के लिए, पंक्तियों के अंत में अतिरिक्त अल्पविराम) ध्यान दिया जाएगा। फ़ाइल कनवर्टर परिणामस्वरूप की शुद्धता की केवल न्यूनतम जांच करेगाNetCDFफ़ाइल, उदाहरण के लिए, CF अनुपालन के संबंध में। यह फ़ाइल निर्माता और फ़ाइल उपयोगकर्ता की जिम्मेदारी है कि यह जांचने के लिए कि रूपांतरण के परिणाम वांछित और सही हैं। जांच करने के दो तरीके हैं:
- सामग्री प्रिंट करें.ncncdump के साथ फ़ाइल ( https://linux.die.net/man/1/ncdump ) ।
- डेटा की सामग्री देखेंERDDAP™।
परिवर्तन
मूल संस्करण थाNCCSV v1.00 (मेंERDDAP™v1.76, 2017-05-12 जारी)
- में प्रस्तुत परिवर्तनNCCSV v1.10 (मेंERDDAP™v2.10, 2020-11-05 जारी) :
- ubyte, ushort, uint, ulong के लिए समर्थन जोड़ा गया। CF में इन डेटा प्रकारों के लिए समर्थन जोड़ने के लिए धन्यवाद।
- परिवर्तन v1.20 में शुरू हुआ (मेंERDDAP™v2.23, 2023-02-27 जारी) :
- ASCII कैरेक्टर से स्विच किया गया, जिसमें UTF-8 को NCCSV .csv फ़ाइलों के लिए एन्कोडिंग शामिल है।
- ERDDAP™अभी भी NCCSV के पिछले सभी संस्करणों से फ़ाइलों को पढ़ सकते हैं।
- ERDDAP™अब हमेशा NCCSV v1.20 फ़ाइलों को लिखते हैं।
- यदि आपने एनसीसीएसवी फ़ाइलों को पढ़ने के लिए एक क्लाइंट लिखा है, तो इसे बदल दें ताकि यह सभी एनसीसीएसवी फाइलों को यूटीएफ-8 फ़ाइलों के रूप में मानता है। यह पुरानी NCCSV फ़ाइलों के साथ काम करेगा क्योंकि ASCII UTF-8 कैरेक्टर एन्कोडिंग का एक उपसेट है।
- पॉलिन चौवेत, नेत और थॉमस ग�ार्डिनर के लिए धन्यवाद।
- ASCII कैरेक्टर से स्विच किया गया, जिसमें UTF-8 को NCCSV .csv फ़ाइलों के लिए एन्कोडिंग शामिल है।