NCCSV-
ANetCDF-Kompatibel, UTF-8, CSV Filspesifikasjon, Versjon 1.20
Bob Simons og Steve Hankin "NCCSV" av Bob Simons og Steve Hankin er lisensiert underCC BY 4.0
Introduksjon
Dette dokumentet angir et UTF-8 CSV-tekstfilformat som kan inneholde all informasjonen (Metadata og data) som kan finnes i enNetCDF .ncfil som inneholder en CSV-fillignende tabell med data. filtypen for en UTF-8 CSV tekstfil etter denne spesifikasjonen må være .csv slik at den kan leses enkelt og riktig i regneark programmer som Excel og Google Sheets. Bob Simons vil skrive programvare for å konvertere en NCCSV-fil til enNetCDF-3 (Og kanskje ogsåNetCDF-4) .ncfil, og omvendt, uten tap av informasjon. Bob Simons har endretERDDAP™å støtte lesing og skriving av denne filtypen.
NCCSV-formatet er designet slik at regnearkprogramvare som Excel og Google Sheets kan importere en NCCSV-fil som en csv-fil, med all informasjon i regnearksceller som er klare til redigering. Eller et regneark kan opprettes fra grunnen etter NCCSV-konvensjonene. Uansett kilden til regnearket, hvis det deretter eksporteres som en .csv-fil, vil det være i samsvar med NCCSV-spesifikasjonen og ingen informasjon vil gå tapt. De eneste forskjellene mellom NCCSV-filer og analoge regnearkfiler som følger disse konvensjonene er:
- NCCSV-filer har verdier på en linje separert med komma. Rekneark har verdier på en linje i tilstøtende celler.
- Strenger i NCCSV-filer er ofte omgitt av dobbelt sitater. Strenger i regneark er aldri omgitt av doble sitater.
- Interne dobbel sitater (") i Strenger i NCCSV-filer vises som 2 doble sitater. Interne dobbel sitater i regneark vises som 1 dobbel sitat.
SeReknearkSeksjonen nedenfor for mer informasjon.
Streamable
Som CSV-filer generelt, er NCCSV-filer streamingbare. Hvis en NCSV genereres on-the-fly av en dataserver somERDDAP™, kan serveren begynne å streame data til forespøreren før alle data er samlet. Dette er en nyttig og ønskelig funksjon.NetCDFFilene kan derimot ikke streames.
ERDDAP
Denne spesifikasjonen er designet slik at NCCSV-filer og.ncfiler som kan opprettes fra dem kan brukes av enERDDAP™dataserver (viaEDDTableFraNccsvFilerogEDDTableFraNcFilerdatasetttyper) , men denne spesifikasjonen er utenforERDDAP..ERDDAP™har flere nødvendige globale attributter og mange anbefalte globale og variable attributter, hovedsakelig basert på CF og ACDD attributter (se /docs/server-admin/datasett#global-atributer).
Balanse
Utformingen av NCCSV-formatet er en balanse på flere krav:
- Filene må inneholde alle data og metadata som vil være i en tabellNetCDFfil, inkludert spesifikke datatyper.
- Filene må være i stand til å leses inn og deretter skrevet ut av et regneark uten tap av informasjon.
- Filene må være enkle for mennesker å opprette, redigere, lese og forstå.
- Filene må være i stand til å være entydig tolket av datamaskinprogrammer.
Hvis noen krav i dette dokumentet virker merkelig eller picky, er det sannsynligvis nødvendig å oppfylle et av disse kravene.
Andre spesifikasjoner
Denne spesifikasjonen refererer til flere andre spesifikasjoner og biblioteker som den er utformet for å jobbe med, men denne spesifikasjonen er ikke en del av noen av de andre spesifikasjonene, og trenger heller ikke noen endringer i dem, og heller ikke i konflikt med dem. Hvis det ikke er angitt noen detaljer knyttet til en av disse standardene her, se den relaterte spesifikasjonen. Dette inkluderer:
- Attributkonvensjonen for oppdaging av datasett (ACDD) metadatastandard: https://wiki.esipfed.org/Attribute\_Convention\_for\_Data\_Discovery\_1-3 ..
- Klima og prognoser (CF) metadatastandard: https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html ..
- DenNetCDFBrukerveiledning (NUG) :) https:///docs.unidata.ucar.edu/netcdf-java/current/userguide/index.html ..
- DenNetCDFprogramvarebiblioteker somNetCDF-java ogNetCDF-c: https://www.unidata.ucar.edu/software/netcdf/ .. Disse bibliotekene kan ikke lese NCCSV-filer, men de kan lese.ncfiler opprettet fra NCCSV-filer.
- JSON: https://www.json.org/
Notasjon
I denne spesifikasjonen, parenteser,\[ \], betegne valgfrie elementer.
Filstruktur
En komplett NCCSV-fil består av to deler: metadataseksjonen, etterfulgt av dataseksjonen.
NCCSV-filer kan inneholde eventuelle UCS-2-tegn (2 byte Unicode-tegn som iJava) kodet via UTF-8.ERDDAP™leser og skriver NCCSV-filer ved hjelp av UTF-8-kodingen.
NCCSV-filer kan bruke enten nylinje (\n) (som er vanlig på Linux og Mac OS X datamaskiner) eller vogn tilbake pluss nylinje (\r\n) (som er vanlig på Windows datamaskiner) som ende-of-line markører, men ikke begge.
.nccsvMetadata
Når både skaperen og leseren forventer det, er det også mulig og noen ganger nyttig å gjøre en variant av en NCCSV-fil som inneholder bare metadata-seksjonen (inkludert\*END\_METADATA\*linje) .. Resultatet gir en fullstendig beskrivelse av filtypens attributter, variable navn og datatyper, og dermed tjener det samme formålet som .das pluss .dds-svar fra enOPeNDAPserver.ERDDAP™vil returnere denne varianten hvis du ber om fil Type=.nccsvMetadata fra enERDDAP™- Datasett.
Metadataseksjonen
I en NCCSV-fil bruker hver linje i metadata-delen formatet
variabel Navn,attributt Navn,verdi1\[,verdi2\]\[,verdi3\]\[,verdi4\]\[...\]
Avstander før eller etter elementene er ikke tillatt fordi de forårsaker problemer ved import av filen til regnearkprogrammer.
Konvensjoner
Den første linjen i en NCCSV-fil er den første linjen i metadata-seksjonen og må ha en\GLOBAL\Konvensjoner tilordner oppføring av alle konvensjoner som brukes i filen som en streng som inneholder en CSV-liste, for eksempel: \GLOBAL\, Konvensjoner "COARDS, CF-1.6, ACDD-1.3, NCCSV-1.2" En av konvensjonene som er oppført, må være NCCSV-1,2, som refererer til den aktuelle versjonen av denne spesifikasjonen.
Sluttmetadata
Slutten på metadataseksjonen i en NCCSV-fil må angis med en linje med bare \END\_METADATA\
Det anbefales men ikke at alle attributtene for en gitt variabel vises på tilstøtende linjer i metadata-seksjonen. Hvis en NCCSV-fil konverteres til enNetCDFfil, rekkefølgen som variabelen først vises i metadata- delen, vil være rekkefølgen på variablene iNetCDFfil.
Valgfrie tomme linjer er tillatt i metadata-delen etter den nødvendige første linjen med\GLOBAL\ KonvensjonerInformasjon (Se nedenfor) og før nødvendig siste linje med\END\_METADATA\..
Hvis et regneark opprettes fra en NCCSV-fil, vises metadatadatadelen med variable navn i kolonne A, attributtnavn i kolonne B og verdier i kolonne C.
Hvis et regneark som følger disse konvensjonene lagres som en CSV-fil, vil det ofte være ekstra komma i slutten av linjene i metadata-seksjonen. Programvaren som konverterer NCCSV-filer til.ncfiler vil ignorere ekstra komma.
variabel Navn
variabel Navn er det tilfelle-følsomme navnet på en variabel i datafilen. Alle variable navn må begynne med en 7-bits ASCII-bokstav eller understrek og være sammensatt av 7-bits ASCII-bokstaver, understrek og 7-bits ASCII-siffer.
GLOBAL
Den spesielle variabelenName\GLOBAL\brukes til å betegne globale metadata.
attributt Navn
attributt Navn er det tilfelle-følsomme navnet på en attributt assosiert med en variabel eller\GLOBAL\.. Alle attributtnavn må begynne med en 7-bits ASCII-bokstav eller understrek og være sammensatt av 7-bits ASCII-bokstaver, understrekninger og 7-bits ASCII-siffer.
SCALAR
Den spesielle egenskapen Navn\*SCALAR\*kan brukes til å opprette en skalardatavariabel og definere dens verdi. Datatypen av\*SCALAR\*definerer datatypen for variabelen, så ikke angi en\*DATA\ TYPE\*attributt for skalarvariabler. Merk at det ikke må være data for skalarvariabelen i Dataseksjonen i NCCSV-filen.
For eksempel, for å opprette en skalar variabel som heter " skip" med verdien "Okeanos Explorer" og en cf__role attributt, bruk: skip,\SCALAR\,"Okeanos Explorer" skip, cf__role, trajeksjon\_id Når en skalardatavariabel leses inn iERDDAP™Skalarverdien omdannes til en kolonne i datatabellen med samme verdi på hver rad.
verdi
verdi er verdien av metadata-attributten og må være en tabell med en eller flere av enten en byte, ubyte, kort, ukort, intent, uint, lang, ulong, flyte, dobbel, streng eller tegn. Ingen andre datatyper støttes. Egenskaper uten verdi vil bli ignorert. Hvis det er mer enn én underverdi, må underverdiene alle være av samme type data. For andre datatyper enn strenger, må verdiene separeres med komma, for eksempel: sst,actual\_range,0.17f,23.58f For strenger, bruk en enkelt streng med\n (Newline) tegn som skiller understrengene.
Definisjonene av egenskapsdatatypene er:
Byte
- byte attributtverdier (8-bits, signert) må skrives med suffikset 'b', f.eks. -7b, 0b, 7b. Området av gyldige byteverdier er -128 til 127. Et nummer som ser ut som en byte, men som er ugyldig (f.eks. 128b) vil bli konvertert til en manglende verdi eller generere en feilmelding.
ubyte
- ubyte attributtverdier (8-bits, ubesvart) må skrives med suffikset 'ub', f.eks. 0ub, 7ub, 250ub . Området av gyldige byteverdier er 0 til 255. Et nummer som ser ut som en ubyte, men som er ugyldig (f.eks. 256ub) vil bli konvertert til en manglende verdi eller generere en feilmelding. Når det er mulig, bruk byte i stedet for ubyte, fordi mange systemer ikke støtter usignerte byter (f.eks. attributter iNetCDF-3 filer) ..
kort
- korte attributtverdier (16-bits, signert) må skrives med suffikset 's', f.eks. -30000s, 0s, 30000s. Området av gyldige korte verdier er -32768 til 32767. Et nummer som ser ut som en kort, men som er ugyldig (f.eks. 32768s) vil bli konvertert til en manglende verdi eller generere en feilmelding.
ushort
- ushort attributtverdier (16-biters, usignert) må skrives med suffikset 'os', f.eks. 0us, 30000us, 60000us. Området av gyldige korte verdier er 0 til 65535. Et nummer som ser ut som en ushort, men som er ugyldig (f.eks. 65536us) vil bli konvertert til en manglende verdi eller generere en feilmelding. Når det er mulig, bruk kort i stedet for ushort, fordi mange systemer ikke støtter ubetalte byter (f.eks. attributter iNetCDF-3 filer) ..
Byte
- integrerte attributtverdier (32-bits, signert) må skrives som JSON-innlegg uten desimalpunkt eller eksponent, men med suffikset 'i', f.eks. -12067978i, 0i, 12067978i. Området av gyldige verdier er -2147483648 til 2147483647. Et tall som ser ut som en int, men som er ugyldig (f.eks. 2147483648i) vil bli konvertert til en manglende verdi eller generere en feilmelding.
uint
- uint attributtverdier (32-biters, usignert) må skrives som JSON-innlegg uten et desimalpunkt eller eksponent, men med suffikset 'ui', f.eks. 0ui, 12067978ui, 4123456789ui. Området av gyldige inte-verdier er 0 til 4294967295. Et tall som ser ut som et uint, men som er ugyldig (f.eks. 2147483648ui) vil bli konvertert til en manglende verdi eller generere en feilmelding. Når det er mulig, bruk intent i stedet for uint, fordi mange systemer ikke støtter usignerte byter (f.eks. attributter iNetCDF-3 filer) ..
lang
- lange attributtverdier (64-bit, signert, støttet av NUG ogERDDAP™Men ennå ikke støttet av CF) må skrives uten et desimalpunkt og med suffikset 'L', f.eks. -1234567678987874321L, 0L, 12345678987654321L. Hvis du bruker konverteringsprogramvaren til å konvertere en NCCSV-fil med lange verdier til enNetCDF-3 fil, alle lange verdier vil bli konvertert til doble verdier. Området av gyldige lange verdier er -9223372036854775808 til 9223372036854775807. Et nummer som ser ut som et langt, men som er ugyldig (f.eks. 9223372036854775808L) vil bli konvertert til en manglende verdi eller generere en feilmelding. Når det er mulig, bruk dobbelt i stedet for ulong, fordi mange systemer ikke støtter lenge (f.eks.NetCDF-3 filer) ..
ulong
- ulange attributtverdier (64-biters, upåslått, støttes for tiden av NUG ogERDDAP™Men ennå ikke støttet av CF) må skrives uten et desimalpunkt og med suffikset 'uL', f.eks. 0uL, 12345678987654321uL, 9007199254740992uL. Hvis du bruker konverteringsprogramvaren til å konvertere en NCCSV-fil med lange verdier til enNetCDF-3 fil, alle lange verdier vil bli konvertert til doble verdier. Området av gyldige lange verdier er 0 til 18446744073709551615. Et nummer som ser ut som en ulong, men som er ugyldig (f.eks. 18446744073709551616uL) vil bli konvertert til en manglende verdi eller generere en feilmelding. Når det er mulig, bruk dobbel i stedet for ulong, fordi mange systemer ikke støtter signert eller ubetegnet lenge (f.eks.NetCDF-3 filer) ..
flyte
- flyte attributtverdier (32-bits) må skrives med suffikset "f" og kan ha et desimalpunkt og/eller en eksponent, f.eks. 0f, 1f, 12,34f, 1e12f, 1,23e+12f, 1,23e12f, 1,87E-7f. Bruk NaNf for en flytende NaN (manglende) Værdi. Området av flyter er ca. +/-3.40282347E+38f (~7 signifikante desimaler) .. Et nummer som ser ut som en flyte, men som er ugyldig (f.eks. 1.0e39f) vil bli konvertert til en manglende verdi eller generere en feilmelding.
dobbel
- dobbel attributtverdier (64-bits) må skrives med suffikset "d" og kan ha et desimalpunkt og/eller en eksponent, f.eks. 0d, 1d, 12.34d, 1e12d, 1.23e+12d, 1.23e12d, 1.87E-7d. Bruk NaNd for en dobbel NaN (manglende) Værdi. Dobbelområdet er ca. +/-1.79769313486231570E+308d (~15 signifikante desimaltall) .. Et tall som ser ut som en dobbel men er ugyldig (f.eks. 1.0e309d) vil bli konvertert til en manglende verdi eller generere en feilmelding.
Streng
- Strenge attributtverdier er en sekvens av UCS-2 tegn (2 byte Unicode-tegn som iJava) som må skrives som JSON-lignende strenger.
- Dobbel sitat (") innenfor en strengverdi må kodes som to dobbelt sitater (") .. Det er det regneark programmer krever når du leser .csv-filer. Det er det regnearkprogrammer skriver når du lagrer et regneark som en .csv-fil.
- De spesielle JSON backslash-kodede tegnene i en strengverdi må kodes som i JSON (bemerkelsesverdigvis\n(newline), \\ (backslash), \f (formfeed), \t (tab), \r (transport retur) eller med\u hhhh Syntaks. I et regneark, ikke bruk Alt Enter til å angi en ny linje i en tekstcelle. I stedet, bruk\n (2 tegn: backslash og 'n ") For å angi en ny linje.
uhhhh
- Alle andre tegn mindre enn tegn #32 må kodes med syntaksen \u hhhh , hvor hhhh er det 4-sifrete heksadesimale antall av tegnet.
- Alle utskrivbare tegn som er større enn tegn #126, for eksempel Euro-tegnet, kan vises ukodet, for eksempel € (Euro-karakteren) , eller kodet med\u hhhh Syntaks, for eksempel \u20AC. Se kodesidene som vises på https://en.wikipedia.org/wiki/Unicode å finne de heksadesimale tallene tilknyttet spesifikke Unicode tegn, eller bruke et programvarebibliotek. Merk at noenERDDAP™utdatafiltypene, for eksempel .csv, bruker ISO 8859-1 tegnsettet, så Unicode tegn over #255 vil gå tapt når disse dataverdiene er skrevet til disse filtypene.
- Alle tegn som ikke kan skrives ut, større enn tegn #126, f.eks. tegn #127, er STRONGLY DISCOURAGED, men du SHOULD bruker \u hhhh Syntaks hvis du inkluderer dem.
- Hvis strengen har en plass i begynnelsen eller slutten, eller inkluderer (dobbel sitat) eller et komma, eller inneholder verdier som ellers vil bli tolket som noen annen datatype (f.eks. et intenst) , eller er ordet " Null", hele strengen må være innesluttet i doble sitater; ellers, i motsetning til JSON, er de omsluttende doble sitater valgfrie. Vi anbefaler: Når i tvil, legge hele strengen i doble sitater. Rommene i begynnelsen eller slutten av en streng er sterkt misfornøyd.
tegn
- tegn attributtverdier er et enkelt UCS-2 tegn (2 byte Unicode-tegn som iJava) .. Utskrivbare tegn (andre enn spesielle tegn som newline, ', og \) Kan skrives som det er. Spesielle tegn (For eksempel newline) og andre uskrivelige tegn (f.eks. #127) Må skrives med\u hhhh Syntaks. Char attributtverdier må være innesluttet i enkelt sitater (de indre sitatene) og dobbelt sitater (de ytre sitatene) , f.eks. (en dobbel sitat tegn) "'''' (Et enkelt sitattegn) , " " " " (en fane) , " " "u007F" (slette 'tegner ") og "'' (Euro-karakteren) .. Dette systemet med å bruke enkelt- og dobbel sitater er merkelig og tungt, men det er en måte å skille tegnverdier fra strenger på en måte som fungerer med regneark. En verdi som ser ut som et tegn, men som er ugyldig, vil generere en feilmelding. Merk at noenERDDAP™utdatafiltypene, for eksempel .csv, bruker ISO 8859-1 tegnsettet, så Unicode tegn over #255 vil gå tapt når disse dataverdiene er skrevet til disse filtypene.
Suffix
Merk at i egenskapsdelen av en NCCSV-fil må alle numeriske attributtverdier ha en suffiks bokstav (For eksempel "b") å identifisere den numeriske datatypen (For eksempel byte) .. Men i datadelen av en NCCSV-fil, må numeriske dataverdier aldri ha disse suffiks bokstavene (med unntak av "L" for lange heltal og "UL" for avlange heltal) — datatypen er angitt av\*DATA\ TYPE\*attributt for variabelen.
Datatype
Datatypen for hver ikke-Scalarvariabel må angis av en\*DATA\ TYPE\*attributt som kan ha en verdi av byte, ubyte, kort, ushort, inten, uint, lang, avlang, flyte, dobbel, streng eller tegn (tilfelle ufølsom) .. For eksempel qc\_flag,\DATA\ TYPE\,byte ADVARSEL: Angi riktig\*DATA\ TYPE\*Det er ditt ansvar. Oppgi feil datatype (For eksempel når du skal ha spesifisert flyte) vil ikke generere en feilmelding og kan føre til at informasjon går tapt (F.eks. vil flyteverdier bli avrundet til intensjoner) når NCCSV-filen leses avERDDAP™eller forvandlet til etNetCDFfil.
Char Discouraged
Bruken av tegndataverdier er nedslått fordi de ikke er mye støttet i andre filtyper. tegnverdier kan skrives i dataseksjonen som enkelttegn eller som strenger (spesielt hvis du trenger å skrive en spesiell karakter) .. Hvis det finnes en streng, vil det første tegnet i strengen bli brukt som tegnverdien. Null lengde Strenger og manglende verdier vil bli konvertert til tegn \uFFFF. Merk atNetCDFfiler bare støtter enkelt byte tegn, så noen tegn større enn tegn # 255 vil bli konvertert til '?' ved skrivingNetCDFFiler. Med mindre en tegnsettende attributt brukes til å angi en annen tegnsett for en tegnvariabel, vil ISO-8859-1-tegnsettet bli brukt.
Lang og usignet diskursert
lange og ikke-signerte typer er diskutert. Selv om mange filtyper (f.eks.NetCDF-4 og json) ogERDDAP™støtte lang og uforutsett (ubyte, ushort, uint, ulong) verdier, bruken av lange og ubegrensede verdier i NCCSV-filer er for tiden mislykket fordi de ikke støttes av Excel, CF ogNetCDF-3 filer. Hvis du vil angi lange eller ubegrensede verdier i en NCCSV-fil (eller i det tilsvarende Excel-reknearket) , du må bruke suffikset 'L' slik at Excel ikke behandler tallene som flytende punkt tall med lavere presisjon. Foreløpig, hvis en NCCSV-filer konverteres til enNetCDF-3.ncfil, lange og avlange dataverdier vil bli konvertert til doble verdier, noe som forårsaker tap av presisjon for svært store verdier (mindre enn -2^53 for lang, eller mer enn 2^53 for lang og avlang) .. INetCDF-3.ncfiler, ubyte, ushort og uint variabler vises som byte, kort og intenst med egenskapen \_Unsigned=true metadata. INetCDF-3.ncFiler, ubyte, ushort og uint-attributter vises som byte, korte og intenst-attributter som inneholder den tilsvarende to-komplementsverdien (For eksempel vises 255ub som -1b) .. Dette er åpenbart problemer, så signerte datatyper bør brukes i stedet for uoppklarte datatyper når det er mulig.
CF, ACDD ogERDDAP™Metadata
Siden det er angitt at de fleste NCCSV-filer, eller.ncfiler opprettet av dem, vil bli lest innERDDAP, det anbefales sterkt at NCCSV-filer inkluderer metadataattributter som kreves eller anbefales avERDDAP™(se /docs/server-admin/datasett#global-atributer). Attributene er nesten alle fra CF- og ACDD-metadatastandardene og tjener til å beskrive datasettet på riktig måte (Hva, når, hvor, hvorfor, hvordan) til noen som ellers ikke vet noe om datasettet. Av særlig betydning, bør nesten alle numeriske variabler ha en enhet attributt med enUDUNITS-kompatibel verdi, f.eks. sst,units, Grade\_C
Det er fint å inkludere ytterligere egenskaper som ikke er fra CF- eller ACDD-standardene eller fraERDDAP..
Dataseksjonen
Struktur
Den første linjen i dataseksjonen må ha en case-sensitive, komma-separert liste over variable navn. Alle variabler i denne listen må beskrives i metadataseksjonen, og omvendt (annet enn\GLOBAL\attributter og\SCALAR\Variabler) ..
Det andre gjennom de penultimate linjene i dataseksjonen må ha en kommaseparert liste over verdier. Hver rekke data må ha samme antall verdier som den kommaseparerte listen over variabelnavn. Avstander før eller etter verdier er ikke tillatt fordi de forårsaker problemer ved import av filen til regnearkprogrammer. Hver kolonne i dette avsnittet må inneholde bare verdier i\*DATA\ TYPE\*angitt for den variabelen av\*DATA\ TYPE\*attributt for den variabelen. I motsetning til egenskapsdelen, må numeriske verdier i datadelen ikke ha suffiks bokstaver for å betegne datatypen. I motsetning til attributtseksjonen kan tegnverdier i dataseksjonen utelate de omsluttende enkelt sitatene dersom de ikke er nødvendig for å avslå (Derfor må "," og "\" siteres som vist her.) .. Det kan være noen av disse datalinjene i en NCCSV-fil, men for tidenERDDAP™kan bare lese NCCSV-filer med opptil 2 milliarder rader. Generelt anbefales det at du deler store datasett i flere NCCSV-datafiler med mindre enn 1 million rader hver.
Sluttdata
Slutten av dataseksjonen må betegnes med en linje med bare \END\_DATA\
Hvis det er ekstra innhold i NCCSV-filen etter\*END\_DATA\*linje, vil det ignoreres når NCCSV-filen konverteres til en.ncfil. Dette innholdet er derfor misfornøyd.
I et regneark etter disse konvensjonene vil variable navn og dataverdier være i flere kolonner. Se eksemplet nedenfor.
manglende verdier
Numre manglende verdier kan skrives som en numerisk verdi identifisert av enmissing\_valueeller \_FallValue-attributt for den variabelen. For eksempel, se den andre verdien på denne dataraden: Bell M. Shimada,99,123.4 Dette er den anbefalte måten å håndtere manglende verdier for byte, ubyte, korte, ushort, int, uint, lange og ulong variabler.
flyte eller doble NaN-verdier kan skrives som NaN. For eksempel, se den andre verdien på denne dataraden: Bell M. Shimada,NaN,123.4
Streng og numerisk manglende verdier kan indikeres av et tomt felt. For eksempel, se den andre verdien på denne dataraden: Bell M. Shimada, 123.4
For byte, ubyte, korte, ukorte, intente, lange og avlange variabler, NCCSV-omformerverktøyet ogERDDAP™vil konvertere et tomt felt til den maksimale tillatte verdien for den datatypen (For eksempel 127 for byter) .. Hvis du gjør dette, må du legge til enmissing\_valueeller \_FillValue-attributt for den variabelen for å identifisere denne verdien, f.eks. variabel Navn , \_FallValue,127b For flytende og dobbel variabler vil et tomt felt bli konvertert til NaN.
Datotid
Datotidverdier (inkludert datoverdier som ikke har en tidskomponent) kan representeres som tall eller som strenger i NCCSV-filer. En gitt datoTidsvariabel kan bare ha strengverdier eller bare numeriske verdier, ikke begge deler. NCCSV-programvaren vil konvertere strenge datoverdier til numerisk dato Tidsverdier når du oppretter.ncfiler (som kreves av CF) .. String dateTime-verdier har fordelen av å være lett å lese av mennesker.
DateTime-verdier representert som numeriske verdier må ha en enhetsattributt som angir " enheter siden dato Tid " som det kreves av CF og spesifisert avUDUNITSf.eks. tid, enheter, sekunder siden 1970-01-01T00:00:00Z
DatoTime-verdier representert som strengverdier må ha en streng\*DATA\ TYPE\*attributt og enhetsattributt som angir en dato Tidsmønster som angitt avJavaDatoTimeFormater klasse ( https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html ) .. For eksempel tid, enheter,yyyy-MM-ddT'HH:mm:ssZ Alle datotider for en gitt datavariabel må bruke samme format. I de fleste tilfeller vil datoTidsmønsteret du trenger for enhetsattributten være en variasjon av et av disse formatene:
- yyyy-MM-dd'T'H:mm:ss. SSSZ — som er ISO 8601:2004 (E) dato Tidsformat. Du kan trenge en forkortet versjon av dette, f.eks.yyyy-MM-ddT'HH:mm:ssZ (det eneste anbefalte formatet) elleryyyy-MM-dd.. Hvis du endrer formatet på datoene dine, anbefaler NCCSV sterkt at du endrer til dette formatet (Kanskje forkortet) .. Dette er det formatet somERDDAP™vil bruke når den skriver NCCSV-filer.
- YYMMddHHmmss.SSS — som er den kompakte versjonen av ISO 8601:2004-datoen Tidsformat. Du kan trenge en forkortet versjon av dette, f.eks.
- M/d/YYY H:mm:ss. SSS — som håndterer amerikansk stil datoer og datotider som "3/23/2017 16:22:03.000". Du kan trenge en forkortet versjon av dette, f.eks. M/d/YYY.
- YYDDDHmmssSSS — som er året pluss årets null-polert dag (f.eks. 001 = jan 1, 365 = dec 31 i et ikke-leap år; dette kalles noen ganger feilaktig den julianske datoen) .. Du kan trenge en forkortet versjon av dette, f.eks.
Precision
Når et programvarebibliotek konverterer en.ncfil til en NCCSV-fil, alle datoer Tidsverdier vil bli skrevet som Strenger med ISO 8601:2004 (E) dato Tidsformat, f.eks. 1970-01-01T00:00:00Z. Du kan styre nøyaktigheten medERDDAP-spesifikke egenskapertime\_precision.. Se /docs/server-admin/datasett#time\_precision..
Tidssone
Standard tidssone for dato Tidsverdier erZulu (eller GMT) Tidssone, som ikke har noen tidsbesparende perioder. Hvis en datoTidsvariabel har datoTidsverdier fra en annen tidssone, må du angi dette medERDDAP-spesifikke egenskapertime\_zone.. Dette er et krav tilERDDAP™(se /docs/server-admin/datasett#time\_zone).
Gradverdier
Som det kreves av CF, alle grader (f.eks. lengdegrad og breddegrad) må være spesifisert som desimalgrads dobbelverdier, ikke som grad°minsec-streng eller som separate variabler for grader, minutter, sekunder. Retningsdesignere N, S, E og W er ikke tillatt. Bruk negative verdier for vestlige lengdegrader og for sørlige breddegrader.
DSG Funksjonstyper
En NCCSV-fil kan inneholde CF Discrete Sampling Geometri ( https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html#discrete-sampling-geometries ) Data. Det er de egenskapene som gjør dette arbeidet:
- Som CF krever, må NCCSV-filen inneholde en linje i metadatadelen som identifiserer\GLOBAL\ featureTypeegenskap, f.eks. \GLOBAL\,featureType,trajectory
- Til bruk iERDDAP™, NCCSV-filen må inneholde en linje eller linjer i metadataseksjonen som identifiserer cf__role=...\_id-variabler, f.eks. skip, cf__role, trajeksjon\_id Dette er valgfritt for CF, men kreves i NCCSV.
- Til bruk iERDDAP™NCCSV-filen skal inneholde en linje eller linjer i metadataseksjonen som identifiserer hvilke variabler som er assosiert med hver timeSeries, baner eller profil som kreves avERDDAP™(se /docs/server-admin/datasett#cdm\_data\_type), f.eks. \GLOBAL\,cdm\_trajectory\_variables,"skip" eller \GLOBAL\,cdm\_timeseries\_variables,"station\_id,lat,lon"
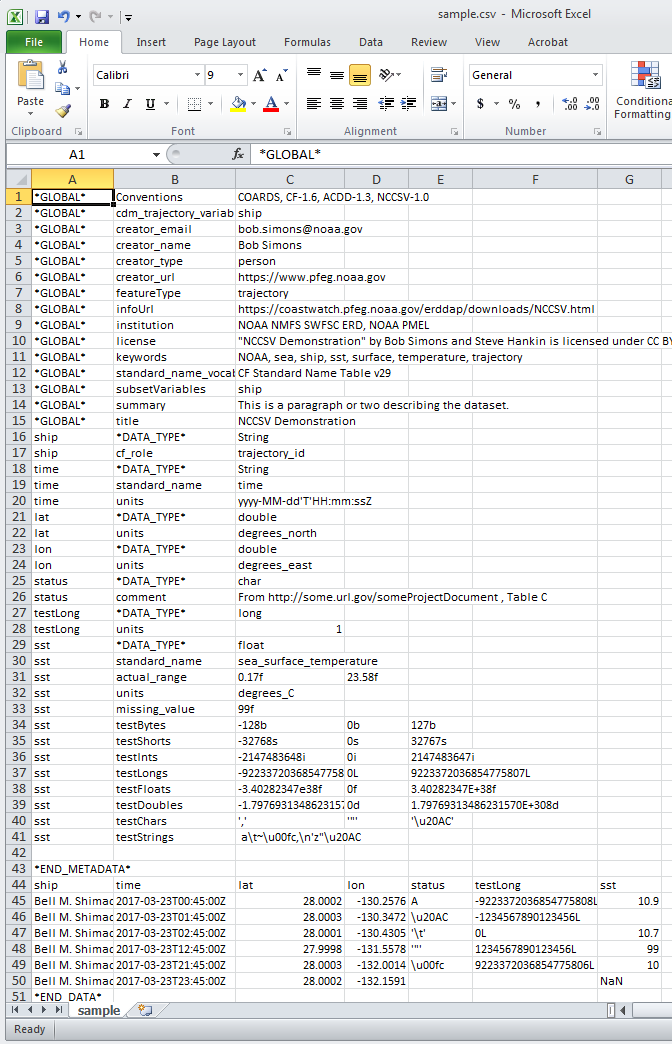
Prøvefil
Her er en prøvefil som demonstrerer mange av funksjonene til en NCCSV-fil:
\\*GLOBAL\\*,Conventions,"COARDS, CF-1.6, ACDD-1.3, NCCSV-1.2"
\\*GLOBAL\\*,cdm\\_trajectory\\_variables,"ship"
\\*GLOBAL\\*,creator\\_email,erd.data@noaa.gov
\\*GLOBAL\\*,creator\\_name,Bob Simons
\\*GLOBAL\\*,creator\\_type,person
\\*GLOBAL\\*,creator\\_url,https://www.pfeg.noaa.gov
\\*GLOBAL\\*,featureType,trajectory
\\*GLOBAL\\*,infoUrl,https://erddap.github.io/docs/user/nccsv-1.20
\\*GLOBAL\\*,institution,"NOAA NMFS SWFSC ERD, NOAA PMEL"
\\*GLOBAL\\*,license,"""NCCSV Demonstration"" by Bob Simons and Steve Hankin is
licensed under CC BY 4.0, https://creativecommons.org/licenses/by/4.0/ ."
\\*GLOBAL\\*,keywords,"NOAA, sea, ship, sst, surface, temperature, trajectory"
\\*GLOBAL\\*,standard\\_name\\_vocabulary,CF Standard Name Table v55
\\*GLOBAL\\*,subsetVariables,"ship"
\\*GLOBAL\\*,summary,"This is a paragraph or two describing the dataset."
\\*GLOBAL\\*,title,"NCCSV Demonstration"
ship,\\*DATA\\_TYPE\\*,String
ship,cf\\_role,trajectory\\_id
time,\\*DATA\\_TYPE\\*,String
time,standard\\_name,time
time,units,"yyyy-MM-dd'T'HH:mm:ssZ"
lat,\\*DATA\\_TYPE\\*,double
lat,units,degrees\\_north
lon,\\*DATA\\_TYPE\\*,double
"lon","units","degrees\\_east"
status,\\*DATA\\_TYPE\\*,char
status,comment,"From http://some.url.gov/someProjectDocument , Table C"
testByte,\\*DATA\\_TYPE\\*,byte
testByte,units,1
testUByte,\\*DATA\\_TYPE\\*,ubyte
testUByte,units,1
testLong,\\*DATA\\_TYPE\\*,long
testLong,units,1
testULong,\\*DATA\\_TYPE\\*,ulong
testULong,units,1
sst,\\*DATA\\_TYPE\\*,float
sst,standard\\_name,sea\\_surface\\_temperature
sst,actual\\_range,0.17f,23.58f
sst,units,degree\\_C
sst,missing\\_value,99f
sst,testBytes,-128b,0b,127b
sst,testShorts,-32768s,0s,32767s
sst,testInts,-2147483648i,0i,2147483647i
sst,testLongs,-9223372036854775808L,0L,9223372036854775807L
sst,testFloats,-3.40282347e38f,0f,3.40282347E+38f
sst,testDoubles,-1.79769313486231570e308d,0d,1.79769313486231570E+308d
sst,testChars,"','","'""'","'€'"
sst,testStrings," a~,\\n'z""\\u20AC"
sst,testUBytes,0ub,127ub,255ub
sst,testUInts,0ui,2147483647ui,4294967295ui
sst,testULongs,0uL,9223372036854775807uL,18446744073709551615uL
sst,testUShorts,0us,32767us,65535us
\\*END\\_METADATA\\*
ship,time,lat,lon,status,testByte,testUByte,testLong,testULong,sst
Bell M. Shimada,2017-03-23T00:45:00Z,28.0002,-130.2576,A,-128, 0,-9223372036854775808L,0uL,10.9
Bell M. Shimada,2017-03-23T01:45:00Z,28.0003,-130.3472,\\u20AC,0,127,-9007199254740992L,9223372036854775807uL,10.0
"Bell M. Shimada","2017-03-23T02:45:00Z",28.0001,-130.4305,"'\\t'",126,254,9223372036854775806L,18446744073709551614uL,99
"Bell M. Shimada",2017-03-23T12:45:00Z,27.9998,-131.5578,"'""'",127,255,9223372036854775807L,18446744073709551615uL,NaN
Merknader:
- Denne prøvefilen inneholder mange vanskelige tilfeller (For eksempel Char og lange variabler og vanskelige strengverdier) .. De fleste NCCSV-filer vil være mye enklere.
- Lisenslinjen er inndelt i to linjer her, men er bare én linje i prøvefilen.
- \u20ac er\uhhhh koding på €. \u00FC er\uhhhH koding av ü. Du kan også bruke de ukodede tegnene direkte.
- Mange Strenger i eksemplet er innesluttet av doble sitater selv om de ikke trenger å være, for eksempel, mange globale attributter inkludert tittelen, lonenhetene attributt og den tredje linjen av data.)
- Det ville være klarere og bedre hvis enhetene attributt for testLong variabelen ble skrevet i doble sitater som indikerer det er en strengeverdi. Men den nåværende representasjonen (1, uten tilbud) vil bli tolket riktig som en streng, ikke et heltall, fordi det ikke er noe "i" suffiks.
- I motsetning til andre numeriske datatyper har de lange verdiene i dataseksjonen suffiks ("L") som identifiserer sin numeriske datatype. Dette er nødvendig for å hindre regneark fra å tolke verdiene som flytende punkttall og dermed miste presisjon.
Rekneark
I et regneark som i en NCCSV-fil:
- Skriv numeriske attributtverdier som spesifisert for NCCSV-filer (f.eks. med et suffiksbrev, f.eks. «f», for å identifisere egenskapens datatype) ..
- I strenger, må alle ikke-utskrivbare og spesielle tegn skrives som enten en JSON-lignende backslashed tegn (f.eks.\nfor newline) eller som det heksadesimale Unicode-tegnnummeret (tilfelle ufølsom) med syntaksen\u hhhh .. Spesielt bruk\n (2 tegn: backslash og 'n ") å angi en ny linje i en streng, ikke Alt Enter. Alle utskrivbare tegn kan skrives ukodet eller med syntaksen\u hhhh ..
De eneste forskjellene mellom NCCSV-filer og det analoge regneark som følger disse konvensjonene er:
- NCCSV-filer har verdier på en linje separert med komma. Rekneark har verdier på en linje i tilstøtende celler.
- Strenger i NCCSV-filer er ofte omgitt av dobbelt sitater. Strenger i regneark er aldri omgitt av doble sitater.
- Interne dobbel sitater (") i Strenger i NCCSV-filer vises som 2 doble sitater. Interne dobbel sitater i regneark vises som 1 dobbel sitat.
Hvis et regneark som følger disse konvensjonene lagres som en CSV-fil, vil det ofte være ekstra komma på slutten av mange linjer. Programvaren som konverterer NCCSV-filer til.ncfiler vil ignorere ekstra komma.
Excel
Hvis du vil importere en NCCSV-fil til Excel:
- Velg Fil: Åpne.
- Endre filtypen til tekstfiler (\.prn;\.txt; \*.csv) ..
- Søk i mappene og klikk på NCCSV .csv-filen.
- Klikk Åpne.
Hvis du vil opprette en NCCSV-fil fra et Excel-regneark:
- Velg fil : Lagre som .
- Endre Lagre som type: å være CSV (Comma avgrenset) (\*.csv) ..
- Som svar på advarselen om kompatibilitet klikker du på Ja.
- Den resulterende .csv-filen vil ha ekstra komma i slutten av alle andre rader enn CSV-linjene. Du kan ignorere dem.
I Excel vises NCCSV-filen ovenfor som
Google Sheets
Hvis du vil importere en NCCSV-fil til Google Sheets:
- Velg Fil: Importer.
- Velg å laste opp en fil og klikk på Last opp en fil fra datamaskinen . Velg filen, og klikk deretter Åpne.
Eller velg My Drive og endre filtypen faller ned utvalget til alle filtyper . Velg filen, og klikk deretter Åpne.
Hvis du vil opprette en NCCSV-fil fra et Google Sheets-regneark:
- Velg fil : Lagre som .
- Endre Lagre som type: å være CSV (Comma avgrenset) (\*.csv) ..
- Som svar på advarselen om kompatibilitet klikker du på Ja.
- Den resulterende .csv-filen vil ha ekstra komma i slutten av alle andre rader enn CSV-linjene. Ignorer dem.
Problemer/varsler
- Hvis du oppretter en NCCSV-fil med et tekstredigeringsprogram eller oppretter et analogt regneark i et regnearksprogram, vil tekstredigeringsprogrammet eller regnearkprogrammet ikke sjekke at du fulgte disse konvensjonene riktig. Det er opp til deg å følge disse konvensjonene riktig.
- Konvertering av et regneark etter denne konvensjonen til en csv-fil (En NCCSV-fil) vil føre til ekstra komma på slutten av alle andre rader enn CSV-datalinjene. Ignorer dem. Programvaren konverterer deretter NCCSV-filer til.ncFilene vil ignorere dem.
- Hvis en NCCSV-fil har overskudd komma på slutten av radene, kan du fjerne dem ved å konvertere NCCSV-filen til enNetCDFfil og deretter konvertereNetCDFfil tilbake til en NCCSV-fil.
- Når du prøver å konvertere en NCCSV-fil til enNetCDFfil, noen feil vil bli oppdaget av programvaren og vil generere feilmeldinger, noe som gjør konverteringen feil. Andre problemer er vanskelig eller umulig å fange og vil ikke generere feilmeldinger eller advarsler. Andre problemer (f.eks. overskudd komma ved slutten av radene) vil bli ignorert. Filomformeren vil gjøre bare minimal kontroll av riktighet av resultatetNetCDFfil, f.eks. med hensyn til overholdelse av CF. Det er filskaperens og filbrukerens ansvar å sjekke at resultatene av konverteringen er som ønsket og riktig. To måter å sjekke på er:
- Skriv ut innholdet i.ncfil med ncdump ( https://linux.die.net/man/1/ncdump ) ..
- Vis innholdet i dataene iERDDAP™..
Endringer
Den opprinnelige versjonen varNCCSV v1.00 (iERDDAP™v1.76, utgitt 2017-05-12)
- Endringer innført iNCCSV v1.10 (iERDDAP™v2.10, utgitt 2020-11-05) :)
- Legg til støtte for ubyte, ushort, uint, ulong. Takk til CF for å legge til støtte for disse datatypene i CF.
- Endringer i v1.20 (iERDDAP™v2.23-02-27) :)
- Bytt fra ASCII tegnkoding til UTF-8 koding for NCCSV .csv-filer.
- ERDDAP™kan fortsatt lese filer fra alle tidligere og gjeldende versjoner av NCCSV.
- ERDDAP™Nå skriver NCCSV v1.20 filer.
- Hvis du skrev en klient for å lese NCCSV-filer, endrer det slik at det behandler alle NCCSV-filer som UTF-8-filer. Det vil fungere med eldre NCCSV-filer fordi ASCII er en undergruppe av UTF-8 tegnkoding.
- Takk til Pauline Chauvet, Nate og Thomas Gardiner.
- Bytt fra ASCII tegnkoding til UTF-8 koding for NCCSV .csv-filer.