NCCSV -
ANetCDF- Compatibil, UTF-8, CSV Specificație fișier, Versiunea 1.20
Bob Simons şi Steve Hankin "NCCSV" de Bob Simons şi Steve Hankin este licenţiatCC cu 4.0
Introducere
Acest document specifică un format de fișier text UTF-8 CSV care poate conține toate informațiile (metadate și date) care pot fi găsite înNetCDF .ncfișier care conține un tabel de date asemănător cu fișierul CSV. Extensia fișierului pentru un fișier text UTF-8 CSV care urmează acestei specificații trebuie să fie .csv, astfel încât acesta să poată fi citit cu ușurință și corect în programele foilor de calcul precum Excel și Google Sheets. Bob Simons va scrie software-ul pentru a converti un fișier NCCSV într-oNetCDF- 3 (şi poate şi unNetCDF- 4) .ncfișier, și invers, cu nici o pierdere de informații. Bob Simons a modificatERDDAP™pentru a sprijini citirea și scrierea acestui tip de fișier.
Formatul NCCSV este conceput astfel încât software-ul foii de calcul precum Excel și Google Sheets să poată importa un fișier NCCSV ca fișier CSV, cu toate informațiile din celulele foii de calcul gata de editare. Sau, o foaie de calcul poate fi creată de la zero în urma convențiilor NCCSV. Indiferent de sursa foii de calcul, în cazul în care este apoi exportat ca un fișier .csv, se va conforma cu specificațiile NCCSV și nu vor fi pierdute informații. Singurele diferențe între fișierele NCCSV și fișierele similare foii de calcul care urmează acestor convenții sunt:
- Fișierele NCCSV au valori pe o linie separată de virgule. Foile de calcul au valori pe o linie în celulele adiacente.
- Stringurile din fișierele NCCSV sunt adesea înconjurate de citate duble. Stringurile din foile de calcul nu sunt niciodată înconjurate de citate duble.
- Citate duble interne (") în Strings în fișiere NCCSV apar ca 2 citate duble. Intern dublu cotații în foi de calcul apar ca 1 citat dublu.
VeziFișă de calculsecțiunea de mai jos pentru mai multe informații.
Streamable
Precum fişierele CSV în general, fişierele NCCSV pot fi transmise. Astfel, în cazul în care un NCSV este generat on-the-fly de un server de date, cum ar fiERDDAP™, serverul poate începe să transmită date către solicitant înainte de colectarea tuturor datelor. Aceasta este o caracteristică utilă și de dorit.NetCDFÎn schimb, dosarele nu pot fi transmise.
ERDDAP
Această specificație este concepută astfel încât fișierele NCCSV și.ncfișiere care pot fi create din ele pot fi folosite de către oERDDAP™server de date (prin intermediulTabel EDD de la NCCSvFilesşiTabel EDDFromNcFilesTipuri de seturi de date) , dar această specificație este externăERDDAP.ERDDAP™are mai multe atribute globale necesare și multe atribute globale și variabile recomandate, în principal bazate pe atributele CF și ACDD (a se vedea /docs/server-admin/datesets#global-attributes).
Sold
Concepția formatului NCCSV este un echilibru de mai multe cerințe:
- Fișierele trebuie să conțină toate datele și metadatele care ar fi într-un tabelNetCDFfișier, inclusiv tipuri specifice de date.
- Fișierele trebuie să poată fi citite și apoi scrise dintr-o foaie de calcul fără pierderi de informații.
- Fişierele trebuie să fie uşor de creat, editat, citit şi înţeles.
- Fişierele trebuie să fie protejate fără echivoc de programe de calculator.
Dacă o cerinţă din acest document pare ciudată sau pretenţioasă, este probabil necesară îndeplinirea uneia dintre aceste cerinţe.
Alte specificații
Această specificație se referă la mai multe alte specificații și biblioteci cu care este concepută pentru a lucra, dar această specificație nu face parte din oricare dintre aceste alte specificații și nici nu are nevoie de modificări ale acestora și nici nu intră în conflict cu acestea. Dacă nu se specifică aici un detaliu legat de unul dintre aceste standarde, a se vedea specificațiile aferente. În special, aceasta include:
- Convenţia de atribuire a datelor (ACDD) standard de metadate: https://wiki.esipfed.org/Attribute\_Convention\_for\_Data\_Discovery\_1-3 .
- Clima şi prognoza (CF) standard de metadate: https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html .
- ăNetCDFGhid utilizator (NUG) : https:///docs.unidata.ucar.edu/netcdf-java/current/userguide/index.html .
- ăNetCDFbiblioteci software caNetCDF- Java şiNetCDF-c: https://www.unidata.ucar.edu/software/netcdf/ . Aceste biblioteci nu pot citi fișiere NCCSV, dar pot citi.ncfișiere create din fișiere NCCSV.
- JSON: https://www.json.org/
Număr
În prezenta specificație, paranteze,\[ \], indică elemente opționale.
Structura fișierului
Un fișier complet NCCSV constă din două secțiuni: secțiunea metadate, urmată de secțiunea de date.
Fișierele NCCSV pot conține orice caractere UCS-2 (și anume, caractere unicode de 2 octeți, ca înJava) codat prin UTF-8.ERDDAP™citeste si scrie fisiere NCCSV folosind codarea UTF-8.
Fișierele NCCSV pot utiliza oricare linie nouă (\n) (care este comună pe Linux și Mac OS X calculatoare) sau transportReturn plus linie nouă (\r\n) (care este comună pe computerele Windows) ca markeri de final de linie, dar nu ambele.
.nccsvMetadate
Atunci când atât creatorul cât și cititorul îl așteaptă, este, de asemenea, posibil și uneori util să se facă o variantă a unui fișier NCCSV care conține doar secțiunea metadate (inclusiv\*SFÂRŞIT\*linie) . Rezultatul oferă o descriere completă a atributelor fișierului, a numelor variabile și a tipurilor de date, servind astfel același scop ca și răspunsurile .das plus .dds de la oOPeNDAPserver.ERDDAP™va returna această variație dacă solicitați fișierul Tip =.nccsvMetadate de la oERDDAP™Set de date.
Secțiunea Metadate
Într-un fișier NCCSV, fiecare linie a secțiunii metadate utilizează formatul
variabilă Nume,atribut Nume,valoare1\[,valoare2\]\[,valoare3\]\[,valoare4\]\[...\]
Spațiile înainte sau după elemente nu sunt permise pentru că acestea cauzează probleme atunci când importa fișierul în programele foii de calcul.
Convenții
Prima linie a unui fișier NCCSV este prima linie a secțiunii metadate și trebuie să aibă o\GLOBAL\Convențiile atribuie listarea tuturor convențiilor utilizate în dosar ca string care conține o listă CSV, de exemplu: \GLOBAL\, Conventions,"COARDS, CF-1.6, ACDD-1.3, NCCSV-1.2" Una dintre convențiile enumerate trebuie să fie NCCSV-1.2, care se referă la versiunea actuală a prezentei specificații.
Metadate finale
Sfârșitul secțiunii de metadate a unui fișier NCCSV trebuie să fie indicat printr-o linie numai cu \SFÂRŞIT\
Se recomandă, dar nu este necesar ca toate atributele pentru o anumită variabilă să apară pe liniile adiacente ale secțiunii metadate. Dacă un fișier NCCSV este convertit înNetCDFfișier, ordinea că numele variabile apar mai întâi în secțiunea metadate va fi ordinea variabilelor înNetCDFDosar.
Liniile opţionale goale sunt permise în secţiunea metadate după prima linie cu\GLOBAL\ Convențiiinformații (vezi mai jos) și înainte de ultima linie necesară cu\SFÂRŞIT\.
În cazul în care o foaie de calcul este creată dintr-un fișier NCCSV, secțiunea de date privind metadatele va apărea cu denumiri variabile în coloana A, denumirile atributelor din coloana B și valorile din coloana C.
În cazul în care o foaie de calcul care urmează acestor convenții este salvată ca fișier CSV, vor exista adesea comunicații suplimentare la sfârșitul liniilor în secțiunea metadate. Software-ul care convertește fișiere NCCSV în.ncDosarele vor ignora virgule suplimentare.
variabilă Nume
variabilă Nume este denumirea sensibilă la caz a unei variabile din fișierul de date. Toate denumirile variabile trebuie să înceapă cu o literă ASCII de 7 biți sau cu o subliniere și să fie compuse din litere ASCII de 7 biți, accente și cifre ASCII de 7 biți.
GLOBAL
Variabila specială Denumire\GLOBAL\este utilizat pentru a desemna metadate globale.
atribut Nume
atribut Nume este denumirea sensibilă la caz a unui atribut asociat unei variabile sau\GLOBAL\. Toate denumirile atributelor trebuie să înceapă cu o literă ASCII de 7 biți sau să fie evidențiate și compuse din litere ASCII de 7 biți, accente și cifre ASCII de 7 biți.
SCALAR
Atributul special Nume\*SCALAR\*poate fi folosit pentru a crea o variabilă de date scalare și pentru a defini valoarea acesteia. Tipul de date al\*SCALAR\*definește tipul de date pentru variabilă, astfel încât să nu se specifice a\*DATE\_TYPE\*atribut pentru variabile scalare. Rețineți că nu trebuie să existe date pentru variabila scalară din secțiunea de date a fișierului NCCSV.
De exemplu, pentru a crea o variabilă scalară numită "navă" cu valoarea "Okeanos Explorer" și un atribut cf\_rol, utilizați: nava;\SCALAR\"Okeanos Explorer" nava,cf\_rol,traiectorie\_id Atunci când o variabilă de date scalare este citită înERDDAP™, valoarea scalară este convertită într-o coloană din tabelul de date cu aceeași valoare pe fiecare rând.
valoare
valoare este valoarea atributului metadatelor și trebuie să fie un array cu unul sau mai multe fie un octet, ubit, scurt, scurt, scurt, int, uint, lung, lung, float, dublu, String, sau Char. Nu sunt sprijinite alte tipuri de date. Atributele fără valoare vor fi ignorate. Dacă există mai mult de o subvaloare, subvalorile trebuie să fie de același tip de date. Pentru alte tipuri de date decât Strings, valorile trebuie separate prin virgule, de exemplu: sst,actual\_range,0.17f,23.58f Pentru Strings, utilizați un singur String cu\n (linie nouă) Personaje care separă corzile.
Definițiile tipurilor de date privind atributele sunt:
octet
- valori atribute bite (8 biți, semnat) trebuie să fie scris cu sufixul "b," de exemplu -7b, 0b, 7b. Gama de valori octet valabile este -128 la 127. Un număr care arată ca un octet dar este invalid (de exemplu, 128b) va fi convertită la o valoare lipsă sau va genera un mesaj de eroare.
ubyte
- valori atribute ubyte (8 biți, nesemnat) trebuie să fie scris cu sufixul "ub," de exemplu, 0ub, 7ub, 250ub. Gama de valori valide ale octeților este cuprinsă între 0 și 255. Un număr care arată ca un ubyte dar este invalid (De exemplu, 256ub) va fi convertită la o valoare lipsă sau va genera un mesaj de eroare. Când este posibil, utilizați octet în loc de ubyte, pentru că multe sisteme nu suportă octeți nesemnate (de exemplu atribute înNetCDF-3 fișiere) .
scurt
- valori ale atributelor scurte (16 biți, semnat) trebuie să fie scrise cu sufixul 's', de exemplu -30000, 0s, 30000. Gama de valori scurte valabile este -32768 -32767. Un număr care arată ca un scurt, dar este invalid (de exemplu, 32768s) va fi convertită la o valoare lipsă sau va genera un mesaj de eroare.
scurt
- valori ale atributelor scurte (16 biți, nesemnat) trebuie să fie scris cu sufixul "noi," de exemplu 0us, 30000us, 60000us. Gama de valori scurte valabile este de 0 până la 65535. Un număr care arată ca un scurt, dar este invalid (de exemplu, 65536us) va fi convertită la o valoare lipsă sau va genera un mesaj de eroare. Când este posibil, utilizați scurt în loc de scurt, deoarece multe sisteme nu suportă octeți nesemnate (de exemplu atribute înNetCDF-3 fișiere) .
octet
- valorile atributelor int (32 biți, semnat) trebuie să fie scrise sub formă de int JSON fără punct zecimal sau exponent, dar cu sufixul "i," de exemplu -12067978i, 0i, 12067978i. Intervalul valorilor int valabile este -2147483648 -2147483647. Un numar care arata ca un int dar este invalid (De exemplu, 2147483648i) va fi convertită la o valoare lipsă sau va genera un mesaj de eroare.
uint
- valori atribute uint (32 biți, nesemnat) trebuie să fie scrise sub formă de int JSON fără punct zecimal sau exponent, dar cu sufixul "ui," de exemplu, 0ui, 12067978ui, 41234456789ui. Gama valorilor int valabile este de la 0 la 4294967295. Un număr care arată ca un uint dar este invalid (de exemplu, 2147483648ui) va fi convertită la o valoare lipsă sau va genera un mesaj de eroare. Când este posibil, utilizați int în loc de uint, pentru că multe sisteme nu suportă octeți nesemnate (de exemplu atribute înNetCDF-3 fișiere) .
lung
- valori ale atributelor lungi (64 de biți, semnat, susținut în prezent de NUG șiERDDAP™dar nu încă sprijinit de CF) trebuie să fie scris fără punct zecimal și cu sufixul "L," de exemplu -12345678987654321L, 0L, 12345678987654321L. Dacă utilizați software-ul de conversie pentru a converti un fișier NCCSV cu valori lungi în aNetCDF-3 fişier, orice valoare lungă va fi convertită în valori duble. Gama de valori lungi valabile este -9223372036854775808 până la 9223372036854775807. Un număr care arată ca un lung, dar este invalid (de exemplu, 9223372036854775808L) va fi convertită la o valoare lipsă sau va genera un mesaj de eroare. Când este posibil, utilizaţi dublu în loc de lung, deoarece multe sisteme nu suport mult timp (de exemplu,NetCDF-3 fișiere) .
ulong
- valori ale atributelor lungi (64 de biți, nesemnată, susținută în prezent de GNU șiERDDAP™dar nu încă sprijinit de CF) trebuie să fie scrise fără punct zecimal și cu sufixul "uL," de exemplu, 0uL, 12345678987654321uL, 9007199254740992uL. Dacă utilizați software-ul de conversie pentru a converti un fișier NCCSV cu valori lungi în aNetCDF-3 fişier, orice valoare lungă va fi convertită în valori duble. Gama de valori lungi valabile este cuprinsă între 0 şi 184467440737095511615. Un număr care arată ca un lung, dar este invalid (de exemplu, 18446744407370955116uL) va fi convertită la o valoare lipsă sau va genera un mesaj de eroare. Când este posibil, utilizați dublu în loc de lung, pentru că multe sisteme nu suport semnat sau nesemnat mult timp (de exemplu,NetCDF-3 fișiere) .
float
- Valorile atributelor float (32 biți) trebuie să fie scris cu sufixul "f" și poate avea un punct zecimal și/sau un exponent, de exemplu, 0f, 1f, 12,34f, 1e12f, 1,23e+12f, 1,23e12f, 1,87E-7f. Utilizați NaNf pentru o naN plutitoare (lipsă) valoare. Gama de flotoare este de aproximativ +/-3.40282347E+38f (~7 cifre zecimale semnificative) . Un număr care arată ca un float dar este invalid (de exemplu, 1,0e39f) va fi convertită la o valoare lipsă sau va genera un mesaj de eroare.
dublu
- Valorile atributelor duble (64 biți) trebuie să fie scris cu sufixul "d" și poate avea un punct zecimal și/sau un exponent, de exemplu, 0d, 1d, 12,34d, 1e12d, 1,23e+12d, 1,23e12d, 1,87E-7d. Utilizaţi NaNd pentru un NaN dublu (lipsă) valoare. Gama de duble este de aproximativ +/-1.79769313486231570E+308d (~15 cifre zecimale semnificative) . Un număr care arată ca un dublu, dar este invalid (de exemplu, 1,0e309d) va fi convertită la o valoare lipsă sau va genera un mesaj de eroare.
String
- Valorile atributelor string sunt o secvență de caractere UCS-2 (și anume, caractere unicode de 2 octeți, ca înJava) , care trebuie să fie scris ca JSON-ca siruri de caractere.
- Citate duble (") într-o valoare de coardă trebuie să fie codificate ca două citate duble (") . Aceasta este ceea ce programele foii de calcul necesită atunci când citiți fișiere .csv. Aceasta este ceea ce programe de foi de calcul scrie atunci când salvați o foaie de calcul ca un fișier .csv.
- Personajele speciale JSON backslash-codate într-o valoare de coardă trebuie să fie codificate ca în JSON (în special\n(newline), \\\ (backslash), \f (formfeed), \t (tab), \r (carry return) sau cu\u hhhh Sintaxă. Într-o foaie de calcul, nu utilizați Alt Enter pentru a specifica o nouă linie într-o celulă de text; în schimb, utilizați\n (2 caractere: backslash and 'n ') pentru a indica o nouă linie.
uhhhh
- Toate celelalte personaje mai puţin decât personajul #32 trebuie codificate cu sintaxa hhhh , unde hhhh este numărul hexazecimal de 4 cifre al personajului.
- Toate personajele tipografice mai mari decât personajul #126, de exemplu, semnul Euro, pot apărea necodate, de exemplu, € (caracterul Euro) , sau codificat cu\u hhhh sintaxă, de exemplu, \u20AC. A se vedea paginile de cod menționate la https://en.wikipedia.org/wiki/Unicode să găsească numerele hexazecimale asociate cu caractere specifice Unicode sau să folosească o bibliotecă de software. Observaţi că uniiERDDAP™tipuri de fișiere de ieșire, de exemplu, .csv, utilizați setul de caractere ISO 8859-1, astfel încât caracterele Unicode de mai sus #255 vor fi pierdute atunci când aceste valori de date sunt scrise acestor tipuri de fișiere.
- Toate personajele care nu pot fi tipărite mai mari decât personajul #126, de exemplu, personajul #127, sunt foarte distorsionate, dar ar trebui să utilizați hhhh Sintaxă dacă le incluzi.
- În cazul în care String are un spațiu la început sau la sfârșit, sau include " (citat dublu) sau o virgulă sau conține valori care altfel ar fi interpretate ca alte tipuri de date (de exemplu, un int) , sau este cuvântul "null," întregul String trebuie să fie inclus în ghilimele duble; altfel, spre deosebire de JSON, ghilimelele duble incluse sunt opționale. Vă recomandăm: atunci când sunteți în îndoială, anexați întregul String în ghilimele duble. Spaţiile de la începutul sau sfârşitul unei coarde sunt puternic descurajate.
char
- Valorile atributelor char sunt un singur caracter UCS-2 (și anume, caractere unicode de 2 octeți, ca înJava) . Personaje imprimate (altele decât caractere speciale, cum ar fi Newline, "," și \) poate fi scris aşa cum este. Personaje speciale (de exemplu, newline) și alte caractere netipăribile (de exemplu, #127) trebuie să fie scris cu\u hhhh Sintaxă. Valorile atributelor Char trebuie incluse în ghilimele unice (citatele interioare) și citate duble (citatele exterioare) , de exemplu, "'a'," "'"""" (un caracter dublu) , "'\'" (un singur caracter citat) , "'\t'" (o filă) , "'\u007F'" ("Caracteristica de ștergere" ') , și ""€"" (caracterul Euro) . Acest sistem de utilizare a ghilimelelor simple și duble este ciudat și greoaie, dar este o modalitate de a distinge valorile Char de Strings într-un mod care funcționează cu foile de calcul. O valoare care arata ca un char, dar este invalid va genera un mesaj de eroare. Observaţi că uniiERDDAP™tipuri de fișiere de ieșire, de exemplu, .csv, utilizați setul de caractere ISO 8859-1, astfel încât caracterele Unicode de mai sus #255 vor fi pierdute atunci când aceste valori de date sunt scrise acestor tipuri de fișiere.
Sufix
Notă: în secțiunea atribute a unui fișier NCCSV, toate valorile atributelor numerice trebuie să aibă o literă sufixă (de exemplu, "b") identificarea tipului de date numerice (de exemplu, octet) . Dar în secțiunea de date a unui fișier NCCSV, valorile datelor numerice nu trebuie să aibă niciodată aceste litere sufixe (cu excepția "L" pentru numere întregi lungi și "ul" pentru numere întregi lungi) Tipul de date este specificat de\*DATE\_TYPE\*atributul variabilei.
Tip de date
Tipul de date pentru fiecare non-scalarvariabila trebuie să fie specificată de un\*DATE\_TYPE\*atribut care poate avea o valoare de octet, ubyte, scurt, ushort, int, uint, lung, lung, lung, float, dublu, String, sau char (insensibil la caz) . De exemplu, qc\_flag,\DATE\_TYPE\,byte ATENŢIONARE: Specificarea corectă\*DATE\_TYPE\*este responsabilitatea ta. Specificarea tipului de date greșit (de exemplu, atunci când ar fi trebuit să specificați float) nu va genera un mesaj de eroare și poate determina pierderea informațiilor (De exemplu, valorile float vor fi rotunjite la int) atunci când fișierul NCCSV este citit deERDDAP™sau transformat într-oNetCDFDosar.
Char Descurajat
Utilizarea valorilor datelor char este descurajată deoarece acestea nu sunt susținute pe scară largă în alte tipuri de fișiere. Valorile char pot fi scrise în secțiunea de date ca caractere unice sau ca strings (în special, dacă aveți nevoie pentru a scrie un caracter special) . În cazul în care un String este găsit, primul caracter al String va fi folosit ca valoare Char. Lungime zero Strings și valorile lipsă vor fi convertite în caracter \ \uFFFF. Notă:NetCDFfișiere numai suport o singură chars byte, astfel încât orice Chars mai mare decât char #255 va fi convertit la "?," atunci când scrieNetCDFDosare. Cu excepția cazului în care se utilizează un atribut charset pentru a specifica un set de caractere diferit pentru o variabilă char, se va utiliza setul de caractere ISO-8859-1.
Lung şi nesemnat
Tipurile lungi şi nesemnate sunt descurajate. Deși multe tipuri de fișiere (de exemplu,NetCDF- 4 şi Json.) şiERDDAP™suport lung și nesemnat (ubyte, ushort, uint, ulong) valorile, utilizarea valorilor lungi și nesemnate în fișierele NCCSV sunt în prezent descurajate, deoarece acestea nu sunt în prezent susținute de Excel, CF șiNetCDF- 3 dosare. Dacă doriți să specificați valori lungi sau nesemnate într-un fișier NCCSV (sau în foaia de calcul Excel corespunzătoare) , trebuie să utilizați sufixul "L" astfel încât Excel să nu trateze numerele ca numere de puncte plutitoare cu precizie mai mică. În prezent, în cazul în care un fișier NCCSV este transformat înNetCDF- 3.ncvalorile de date de lung şi lung vor fi convertite în valori duble, cauzând o pierdere de precizie pentru valori foarte mari (mai mică de -2^53 pentru mult timp sau mai mare de 2^53 pentru mult timp și lung) . ÎnNetCDF- 3.ncfișierele, ubyte, ushort, și variabile uint apar ca byte, scurt, și int cu atributul \_Unsigned=real metadate. ÎnNetCDF- 3.ncfișiere, ubyte, ushort, și atribute uint apar ca octet, scurt, și atribute int care conțin valoarea corespunzătoare două-complement (De exemplu, 255ub apare ca -1b) . Acest lucru este în mod evident o problemă, astfel încât tipurile de date semnate ar trebui utilizate în loc de tipuri de date nesemnate ori de câte ori este posibil.
CF, ACDD șiERDDAP™Metadate
Deoarece se prevede că cele mai multe fișiere NCCSV, sau.ncfișiere create din ele, vor fi citite înERDDAP, se recomandă cu fermitate ca fișierele NCCSV să includă atributele metadatelor care sunt necesare sau recomandate deERDDAP™(vezi /docs/server-admin/datesets#global-attributes). Atribuțiile sunt aproape toate din standardele de metadate CF și ACDD și servesc la descrierea corectă a setului de date. (Cine, ce, când, unde, de ce, cum) cuiva care altfel nu ştie nimic despre set. De o importanță deosebită, aproape toate variabilele numerice ar trebui să aibă un atribut de unități cu unUDUNITS-valoare compatibilă, de exemplu, sst, Unităţi,grad\_C
Este bine să se includă atribute suplimentare care nu sunt din standardele CF sau ACDD sau dinERDDAP.
Secțiunea pentru date
Structura
Prima linie a secțiunii de date trebuie să aibă o listă de nume variabile sensibile la caz, separate de virgulă. Toate variabilele din această listă trebuie descrise în secțiunea metadate și invers (altele decât\GLOBAL\atribute și\SCALAR\variabile) .
Al doilea prin penultima linie a secţiunii de date trebuie să aibă o listă de valori separată de virgulă. Fiecare rând de date trebuie să aibă același număr de valori ca și lista separată de denumiri variabile. Spațiile înainte sau după valori nu sunt permise deoarece acestea cauzează probleme atunci când importa fișierul în programele foii de calcul. Fiecare coloană din această secțiune trebuie să conțină numai valorile\*DATE\_TYPE\*specificată pentru variabila respectivă de către\*DATE\_TYPE\*atribut pentru acea variabilă. Spre deosebire de secțiunea atribute, valorile numerice din secțiunea de date nu trebuie să aibă litere sufixe pentru a desemna tipul de date. Spre deosebire de secțiunea atribute, valorile char din secțiunea de date pot omite cotațiile unice aferente dacă acestea nu sunt necesare pentru dezamagire (Prin urmare, "" și "\"" trebuie citate astfel cum se arată aici) . Poate exista orice număr de aceste rânduri de date într-un fișier NCCSV, dar în prezentERDDAP™poate citi doar fișiere NCCSV cu până la aproximativ 2 miliarde de rânduri. În general, se recomandă să împărțiți seturi mari de date în mai multe fișiere de date NCCSV cu mai puțin de 1 milion de rânduri fiecare.
Sfârșitul datelor
Sfârşitul secţiunii de date trebuie indicat printr-o linie numai cu \SFÂRŞIT\
Dacă există conținut suplimentar în fișierul NCCSV după\*SFÂRŞIT\*linie, acesta va fi ignorat atunci când fișierul NCCSV este convertit într-o.ncDosar. Prin urmare, acest conţinut este descurajat.
Într-o foaie de calcul care urmează acestor convenții, denumirile variabile și valorile datelor vor fi în mai multe coloane. A se vedea exemplul de mai jos.
Valori lipsă
Valorile lipsă numerice pot fi scrise ca valoare numerică identificată de omissing\_valuesau atribut \_FillValue pentru acea variabilă. De exemplu, a se vedea a doua valoare a acestui rând de date: Bell M. Shimada,99,123.4 Acesta este modul recomandat de a trata valorile lipsă pentru variabilele octet, ubit, scurt, scurt, int, int, uint, lung și lung.
valorile variabile sau duble ale NaN pot fi scrise ca NaN. De exemplu, a se vedea a doua valoare a acestui rând de date: Bell M. Shimada, NaN,123.4
Valorile lipsă ale stringurilor și numerice pot fi indicate de un câmp gol. De exemplu, a se vedea a doua valoare a acestui rând de date: Bell M. Shimada, 123.4
Pentru variabilele octet, ubyte, scurt, scurt, scurt, int, uint, lung și lung, utilitatea convertorului NCCSV șiERDDAP™va converti un câmp gol în valoarea maximă permisă pentru acel tip de date (De exemplu, 127 pentru octeți) . Dacă faceți acest lucru, asigurați-vă că pentru a adăuga unmissing\_valuesau atributul \_FillValue pentru acea variabilă pentru identificarea acestei valori, de exemplu, variabilă Nume ,\_FillValue,127b Pentru variabilele float și dublu, un câmp gol va fi convertit la NaN.
Valori de dată
Valori dateTime (inclusiv valorile de dată care nu au o componentă de timp) pot fi reprezentate ca numere sau ca strings în fișiere NCCSV. O variabilă datăTime poate avea numai valori String sau numai valori numerice, nu ambele. Software-ul NCCSV va converti valorile String dateTime în dată numerică Valori ale timpului la crearea.ncfișiere (conform cerințelor CF) . Valorile String dateTime au avantajul de a fi ușor de citit de către oameni.
Valorile DataTime reprezentate ca valori numerice trebuie să aibă un atribut de unități care specifică " unități din data Timp " conform cerințelor CF și specificate deUDUNITS, de exemplu, timp, unităţi, secunde din 1970-01-01T00:00:00Z
Valorile dateTime reprezentate ca valori String trebuie să aibă o coardă\*DATE\_TYPE\*atribut și atribut de unități care specifică o dată Tipul de timp specificat de cătreJavaDataTimeFormatery class ( https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html ) . De exemplu, timp, unități;yyyy-MM-dd'T'HH:mm:ssZ Toate valorile dateTime pentru o anumită variabilă de date trebuie să utilizeze același format. În majoritatea cazurilor, modelul dataTime de care aveți nevoie pentru atributul unități va fi o variație a unuia dintre aceste formate:
- yyyy-MM-dd'T'HH:mm:ss. (E) data Format de timp. S-ar putea să fie nevoie de o versiune scurtată a acestui lucru, de exemplu,yyyy-MM-dd'T'HH:mm:ssZ (singurul format recomandat) sauyyyy-MM-dd. Dacă schimbi formatul valorilor dateTime, NCCSV recomandă cu fermitate schimbarea în acest format (Poate scurtat.) . Acesta este formatul careERDDAP™va utiliza atunci când scrie fișiere NCCSV.
- YYammddHHmmss.SSS Format de timp. Este posibil să aveți nevoie de o versiune scurtată a acesteia, de exemplu, aaaammdd.
- M/d/aaaa H:mm:ss. Ce se ocupă de date și date în stil american, cum ar fi "3/23/2017 16:22:03.000." S-ar putea să fie nevoie de o versiune scurtată a acestui lucru, de exemplu, M/d/aaaa.
- aaaaddDHHmmssSS (De exemplu, 001 = 1 ianuarie 365 = 31 decembrie într-un an neleap; acest lucru este uneori numit în mod eronat data Julian) . Este posibil să aveți nevoie de o versiune scurtată a acestui lucru, de exemplu, aaaaDD.
Precizie
Când o bibliotecă de software convertește o.ncfișier într-un fișier NCCSV, toată data Valorile timpului vor fi scrise ca stringuri cu ISO 8601:2004 (E) data Format orar, de exemplu 1970-01-01T00:00:00Z . Puteți controla precizia cuERDDAP- atribut specifictime\_precision. Vezi? /docs/server-admin/sets#time\_precision.
Zona temporală
Perioada de timp implicită pentru dată Valorile timpului esteZulu (sau GMT) fusul orar, care nu are perioade de timp de vară. Dacă o variabilă dataTime are valori dataTime dintr-un fus orar diferit, trebuie să specificaţi acest lucru cuERDDAP- atribut specifictime\_zone. Aceasta este o cerință pentruERDDAP™(vezi /docs/server-admin/sets#time\_zone).
Valori de grad
Conform cerințelor CF, toate valorile gradelor (De exemplu, pentru longitudine și latitudine) trebuie să fie specificate ca valori duble de gradul zecimal, nu ca un gradomin'sec" String sau ca variabile separate pentru grade, minute, secunde. Designatoarele de direcție N, S, E și W nu sunt permise. Utilizaţi valori negative pentru longitudinea vestică şi pentru latitudinea sudică.
DSG Tipuri de caracteristici
Un fișier NCCSV poate conține Geometria de eșantionare a discretelor CF ( https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html#discrete-sampling-geometries ) date. Este atributele care fac acest lucru:
- În conformitate cu cerințele CF, fișierul NCCSV trebuie să includă o linie în secțiunea metadate care identifică\GLOBAL\ featureTypeatribut, de exemplu, \GLOBAL\,featureType,traiectorie
- A se utiliza înERDDAP™, fișierul NCCSV trebuie să includă o linie sau linii în secțiunea metadate care identifică cf\_rolul=...\_id variabile, de exemplu, nava,cf\_rol,traiectorie\_id Acest lucru este opțional pentru CF, dar este necesar în NCCSV.
- A se utiliza înERDDAP™, fișierul NCCSV trebuie să includă o linie sau linii în secțiunea metadate care să identifice variabilele asociate cu fiecare serie de timp, traiectorie sau profil, conform cerințelorERDDAP™(vezi /docs/server-admin/datasets#cdm\_data\_type), de exemplu, \GLOBAL\,cdm\_traiectorie\_variabile,"navă" sau \GLOBAL\,cdm\_timeseries\_variables,"station\_id,lat,lon"
Fișier eșantion
Aici este un fișier eșantion care demonstrează multe dintre caracteristicile unui fișier NCCSV:
\\*GLOBAL\\*,Conventions,"COARDS, CF-1.6, ACDD-1.3, NCCSV-1.2"
\\*GLOBAL\\*,cdm\\_trajectory\\_variables,"ship"
\\*GLOBAL\\*,creator\\_email,erd.data@noaa.gov
\\*GLOBAL\\*,creator\\_name,Bob Simons
\\*GLOBAL\\*,creator\\_type,person
\\*GLOBAL\\*,creator\\_url,https://www.pfeg.noaa.gov
\\*GLOBAL\\*,featureType,trajectory
\\*GLOBAL\\*,infoUrl,https://erddap.github.io/docs/user/nccsv-1.20
\\*GLOBAL\\*,institution,"NOAA NMFS SWFSC ERD, NOAA PMEL"
\\*GLOBAL\\*,license,"""NCCSV Demonstration"" by Bob Simons and Steve Hankin is
licensed under CC BY 4.0, https://creativecommons.org/licenses/by/4.0/ ."
\\*GLOBAL\\*,keywords,"NOAA, sea, ship, sst, surface, temperature, trajectory"
\\*GLOBAL\\*,standard\\_name\\_vocabulary,CF Standard Name Table v55
\\*GLOBAL\\*,subsetVariables,"ship"
\\*GLOBAL\\*,summary,"This is a paragraph or two describing the dataset."
\\*GLOBAL\\*,title,"NCCSV Demonstration"
ship,\\*DATA\\_TYPE\\*,String
ship,cf\\_role,trajectory\\_id
time,\\*DATA\\_TYPE\\*,String
time,standard\\_name,time
time,units,"yyyy-MM-dd'T'HH:mm:ssZ"
lat,\\*DATA\\_TYPE\\*,double
lat,units,degrees\\_north
lon,\\*DATA\\_TYPE\\*,double
"lon","units","degrees\\_east"
status,\\*DATA\\_TYPE\\*,char
status,comment,"From http://some.url.gov/someProjectDocument , Table C"
testByte,\\*DATA\\_TYPE\\*,byte
testByte,units,1
testUByte,\\*DATA\\_TYPE\\*,ubyte
testUByte,units,1
testLong,\\*DATA\\_TYPE\\*,long
testLong,units,1
testULong,\\*DATA\\_TYPE\\*,ulong
testULong,units,1
sst,\\*DATA\\_TYPE\\*,float
sst,standard\\_name,sea\\_surface\\_temperature
sst,actual\\_range,0.17f,23.58f
sst,units,degree\\_C
sst,missing\\_value,99f
sst,testBytes,-128b,0b,127b
sst,testShorts,-32768s,0s,32767s
sst,testInts,-2147483648i,0i,2147483647i
sst,testLongs,-9223372036854775808L,0L,9223372036854775807L
sst,testFloats,-3.40282347e38f,0f,3.40282347E+38f
sst,testDoubles,-1.79769313486231570e308d,0d,1.79769313486231570E+308d
sst,testChars,"','","'""'","'€'"
sst,testStrings," a~,\\n'z""\\u20AC"
sst,testUBytes,0ub,127ub,255ub
sst,testUInts,0ui,2147483647ui,4294967295ui
sst,testULongs,0uL,9223372036854775807uL,18446744073709551615uL
sst,testUShorts,0us,32767us,65535us
\\*END\\_METADATA\\*
ship,time,lat,lon,status,testByte,testUByte,testLong,testULong,sst
Bell M. Shimada,2017-03-23T00:45:00Z,28.0002,-130.2576,A,-128, 0,-9223372036854775808L,0uL,10.9
Bell M. Shimada,2017-03-23T01:45:00Z,28.0003,-130.3472,\\u20AC,0,127,-9007199254740992L,9223372036854775807uL,10.0
"Bell M. Shimada","2017-03-23T02:45:00Z",28.0001,-130.4305,"'\\t'",126,254,9223372036854775806L,18446744073709551614uL,99
"Bell M. Shimada",2017-03-23T12:45:00Z,27.9998,-131.5578,"'""'",127,255,9223372036854775807L,18446744073709551615uL,NaN
Note:
- Acest fișier eșantion include multe cazuri dificile (de exemplu, variabilele char și lungi și valorile dificile ale stringurilor) . Cele mai multe fișiere NCCSV vor fi mult mai simple.
- Linia de licență este rupt în două linii aici, dar este doar o linie în fișierul eșantion.
- \ \u20ac este\uhhhh codarea €. \u00FC este\uhhhh codarea ü. Puteți utiliza, de asemenea, caractere necodate direct.
- Multe Strings in the example are address by double cotations even though they don't have to be, ex., many global atributs including the title, the lon units atributed, and the 3rd line of data.)
- Ar fi mai clar și mai bine dacă unitățile atribute pentru variabila testLong ar fi scrise în ghilimele duble care indică faptul că este o valoare string. Dar reprezentarea actuală (1, fără citate) va fi interpretată corect ca o coardă, nu ca un întreg, deoarece nu există sufix "i."
- Spre deosebire de alte tipuri de date numerice, valorile lungi din secțiunea de date au sufixul ('L') care identifică tipul lor de date numerice. Acest lucru este necesar pentru a împiedica foile de calcul să interpreteze valorile ca numere de puncte plutitoare și, astfel, să piardă precizia.
Foi de calcul
Într-o foaie de calcul, ca într-un fișier NCCSV:
- Scrie valorile atributelor numerice specificate pentru fișierele NCCSV (de exemplu, cu o literă sufixă, de exemplu, "f," pentru a identifica tipul de date al atributului) .
- În Strings, toate caracterele neimprimate și speciale trebuie să fie scrise fie ca un personaj backslashed JSON (de exemplu,\npentru linia nouă) sau ca număr de caracter hexazecimal Unicode (insensibil la caz) cu sintaxa\u hhhh . În mod special, utilizați\n (2 caractere: backslash and 'n ') pentru a indica o nouă linie într-un String, nu Alt Enter. Toate caracterele imprimate pot fi scrise necodate sau cu sintaxa\u hhhh .
Singurele diferențe dintre fișierele NCCSV și foaia de calcul similară care urmează acestor convenții sunt:
- Fișierele NCCSV au valori pe o linie separată de virgule. Foile de calcul au valori pe o linie în celulele adiacente.
- Stringurile din fișierele NCCSV sunt adesea înconjurate de citate duble. Stringurile din foile de calcul nu sunt niciodată înconjurate de citate duble.
- Citate duble interne (") în Strings în fișiere NCCSV apar ca 2 citate duble. Intern dublu cotații în foi de calcul apar ca 1 citat dublu.
În cazul în care o foaie de calcul care urmează acestor convenții este salvată ca un fișier CSV, vor exista adesea virgule suplimentare la sfârșitul multor linii. Software-ul care convertește fișiere NCCSV în.ncDosarele vor ignora virgule suplimentare.
Excelează
Pentru a importa un fișier NCCSV în Excel:
- Alegeți fișierul: Deschideți .
- Schimbă tipul de fișier în fișiere text (\.prn;\.txt; \*csv) .
- Căutați directoarele și faceți clic pe fișierul NCCSV .csv.
- Click Open .
Pentru a crea un fișier NCCSV dintr-o foaie de calcul Excel:
- Alegeți fișierul: Salvați ca .
- Schimbă Salvare ca tip: pentru a fi CSV (Comma delimitat) (\*.csv) .
- Ca răspuns la avertismentul de compatibilitate, faceți clic pe Da .
- Fișierul .csv rezultat va avea viraje suplimentare la sfârșitul tuturor rândurilor, altele decât rândurile CSV. Îi poţi ignora.
În Excel, eșantionul de fișier NCCSV de mai sus apare ca
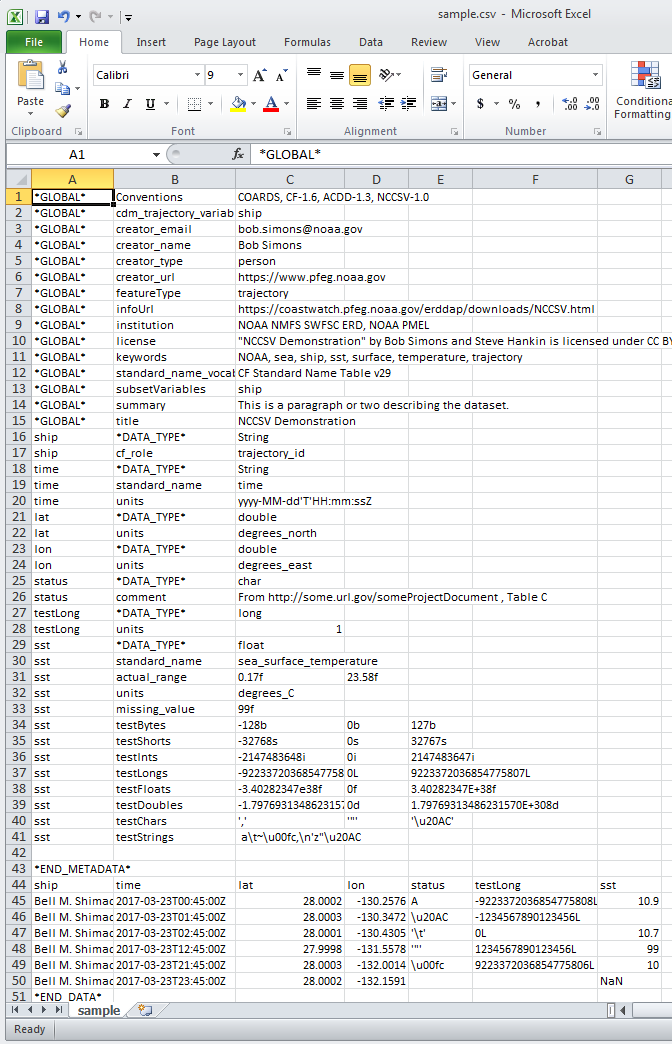
Fișe Google
Pentru a importa un fișier NCCSV în foi Google:
- Alegeți fișierul: Import .
- Alegeți să încărcați un fișier și faceți clic pe Încărcați un fișier din calculator. Selectaţi fişierul, apoi faceţi clic pe Deschide .
Sau, alege My Drive și de a schimba tipul de fișier picătură în jos selecție la toate tipurile de fișiere. Selectaţi fişierul, apoi faceţi clic pe Deschide .
Pentru a crea un fișier NCCSV dintr-o foaie de calcul a foilor Google:
- Alegeți fișierul: Salvați ca .
- Schimbă Salvare ca tip: pentru a fi CSV (Comma delimitat) (\*.csv) .
- Ca răspuns la avertismentul de compatibilitate, faceți clic pe Da .
- Fișierul .csv rezultat va avea viraje suplimentare la sfârșitul tuturor rândurilor, altele decât rândurile CSV. Ignoră-i.
Probleme/Atenționări
- Dacă creați un fișier NCCSV cu un editor de text sau dacă creați o foaie de calcul similară într-un program de calcul, editorul de text sau programul foii de calcul nu va verifica dacă ați urmat corect aceste convenții. Depinde de tine să urmezi aceste congrese în mod corect.
- Transformarea unei foi de calcul care urmează acestei convenții într-un fișier Csv (astfel, un fișier NCCSV) va duce la comunicații suplimentare la sfârșitul tuturor rândurilor, altele decât rândurile de date CSV. Ignoră-i. Software-ul apoi convertește fișiere NCCSV în.ncDosarele le vor ignora.
- În cazul în care un fișier NCCSV are viraje în exces la sfârșitul rândurilor, le puteți elimina prin conversia fișierului NCCSV într-oNetCDFfișier și apoi convertireaNetCDFfișier înapoi într-un fișier NCCSV.
- Când încercați să convertiți un fișier NCCSV într-oNetCDFfişier, unele erori vor fi detectate de software-ul şi vor genera mesaje de eroare, ceea ce duce la eşecul conversiei. Alte probleme sunt greu sau imposibil de prins și nu va genera mesaje de eroare sau avertismente. Alte probleme (De exemplu, virgule în exces la sfârșitul rândurilor) vor fi ignorate. Convertorul de fișiere va face doar verificarea minimă a corectitudinii rezultatuluiNetCDFdosar, de exemplu, în ceea ce privește conformitatea CF. Este responsabilitatea creatorului de fișiere și a utilizatorului de fișiere să verifice dacă rezultatele conversiei sunt cele dorite și corecte. Două moduri de a verifica sunt:
- Tipărește conținutul.ncfișier cu ncdump ( https://linux.die.net/man/1/ncdump ) .
- Vezi conţinutul datelor înERDDAP™.
Modificări
Versiunea originală a fostNCCSV v1.00 (înERDDAP™v1.76, lansat 2017-05-12)
- Modificări introduse înNCCSV v1.10 (înERDDAP™v2.0, lansat în 2020-11-05) :
- Adaugat suport pentru ubyte, scurt, uint, lung. Datorită CF pentru adăugarea de sprijin pentru aceste tipuri de date în CF.
- Modificări introduse în v1.20 (înERDDAP™v2.23, eliberat 2023-02-27) :
- Comutat de la codarea caracterelor ASCII la codarea UTF-8 pentru fișiere NCCSV.csv.
- ERDDAP™poate citi încă fișiere din toate versiunile anterioare și actuale ale NCCSV.
- ERDDAP™Acum scrie mereu fișiere NCCSV v1.20.
- Dacă ați scris un client pentru a citi fișiere NCCSV, modificați-l astfel încât tratează toate fișierele NCCSV ca fișiere UTF-8. Aceasta va funcționa cu fișiere NCCSV mai vechi, deoarece ASCII este un subset al codării caracterelor UTF-8.
- Mulţumită lui Pauline Chauvet, Nate şi Thomas Gardiner.
- Comutat de la codarea caracterelor ASCII la codarea UTF-8 pentru fișiere NCCSV.csv.