NCCSV -
ANetCDF- Kompatibilní, UTF-8, CSV Specifikace souboru, Verze 1.20
Bob Simons a Steve Hankin "NCCSV" od Boba Simonse a Steva Hankina má licenci podleCC BY 4.0
Úvod
Tento dokument určuje formát textového souboru UTF-8 CSV, který může obsahovat všechny informace (metadata a údaje) který lze nalézt vNetCDF .ncsoubor, který obsahuje tabulku dat podobnou CSV souboru. Přípona souboru pro textový soubor UTF-8 CSV následující po této specifikaci musí být .csv tak, aby mohl být snadno a správně čten do tabulkových programů jako Excel a Google Sheets. Bob Simons bude psát software pro převod NCCSV soubor doNetCDF- 3 (a možná takéNetCDF- 4) .ncsoubor, a naopak, bez ztráty informací. Bob Simons se změnil.ERDDAP™podporovat čtení a psaní tohoto typu souboru.
Formát NCCSV je navržen tak, aby tabulkový software, jako jsou Excel a Google Sheets, mohl importovat NCCSV soubor jako csv soubor, se všemi informacemi v celách tabulky připravené k editaci. Nebo lze vytvořit tabulku od nuly po NCCSV konvencích. Bez ohledu na zdroj tabulky, pokud je exportován jako .csv soubor, bude odpovídat specifikaci NCCSV a žádné informace nebudou ztraceny. Jedinými rozdíly mezi soubory NCCSV a analogickými tabulkovými soubory, které se řídí těmito úmluvami, jsou:
- NCCSV soubory mají hodnoty na řádku oddělené čárkami. Tabulky mají hodnoty na lince v přilehlých buňkách.
- Struny v souborech NCCSV jsou často obklopeny dvojitými uvozovkami. Struny v tabulkách nejsou nikdy obklopeny dvojitými uvozovkami.
- Vnitřní dvojité kotace (") v Struny v NCCSV souborech se zobrazují jako 2 dvojité uvozovky. Vnitřní dvojité citace v tabulkách se zobrazují jako 1 dvojitá citace.
VizTabulkový listsekce níže pro více informací.
Streamovatelné
Stejně jako CSV soubory obecně, NCCSV soubory jsou streamovatelné. Pokud je tedy NCSV generován on-the-fly datovým serverem, jako jeERDDAP™, server může začít streamovat data do dotazovatele dříve, než budou shromážděna všechna data. Je to užitečná a žádoucí vlastnost.NetCDFNaproti tomu soubory nelze streamovat.
ERDDAP
Tato specifikace je navržena tak, aby NCCSV soubory a.ncsoubory, které mohou být vytvořeny z nich mohou být použityERDDAP™datový server (prostřednictvímEDDTableFromNccsvFilesaEDDTableFromNcFilesTypy souborů údajů) , ale tato specifikace je externíERDDAP.ERDDAP™má několik požadovaných globálních atributů a mnoho doporučených globálních a proměnných atributů, většinou založených na atributech CF a ACDD (viz /docs/server-admin/datasets#globální atributy).
Zůstatek
Návrh formátu NCCSV je bilance několika požadavků:
- Soubory musí obsahovat všechna data a metadata, která by byla v tabulceNetCDFsoubor, včetně specifických datových typů.
- Soubory musí být schopny číst a pak zapisovat z tabulky bez ztráty informací.
- Soubory musí být pro lidi snadné vytvářet, upravovat, číst a chápat.
- Soubory musí být schopny jednoznačně analyzovat pomocí počítačových programů.
Pokud se některé požadavky v tomto dokumentu jeví podivné nebo vybíravé, je pravděpodobně nutné splnit jeden z těchto požadavků.
Ostatní specifikace
Tato specifikace odkazuje na několik dalších specifikací a knihoven, se kterými má pracovat, ale tato specifikace není součástí žádné z těchto jiných specifikací, ani nepotřebuje žádné změny, ani s nimi není v rozporu. Pokud zde není uveden detail týkající se jednoho z těchto standardů, viz související specifikace. To zahrnuje zejména:
- Úmluva o atributu pro odhalení datových souborů (ACDD) standard metadat: https://wiki.esipfed.org/Attribute\_Convention\_for\_Data\_Discovery\_1-3 .
- Klima a předpovědi (CF) standard metadat: https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html .
- TheNetCDFUživatelská příručka (NUG) : https:///docs.unidata.ucar.edu/netcdf-java/current/userguide/index.html .
- TheNetCDFsoftwarové knihovny jakoNetCDF- Java aNetCDF-c: https://www.unidata.ucar.edu/software/netcdf/ . Tyto knihovny nemohou číst NCCSV soubory, ale mohou číst.ncsoubory vytvořené z NCCSV souborů.
- JSON: https://www.json.org/
Zápis
V této specifikaci, závorkách,\[ \], označuje nepovinné položky.
Struktura souboru
Kompletní NCCSV soubor se skládá ze dvou sekcí: sekce metadat, následovaná datovou sekcí.
NCCSV soubory mohou obsahovat jakékoli UCS-2 znaky (tj. 2-bajtové Unicode znaky jakoJava) Zakódováno přes UTF-8.ERDDAP™čte a píše NCCSV soubory pomocí UTF-8 kódování.
NCCSV soubory mohou používat buď nový řádek (\n) (což je běžné na počítačích Linux a Mac OS X) nebo kočárReturn plus newline (\r\n) (což je běžné na počítačích Windows) jako koncové značky, ale ne obojí.
.nccsvMetadata
Když to tvůrce i čtenář očekávají, je také možné a někdy užitečné vytvořit variantu NCCSV souboru, který obsahuje pouze část metadat (včetně\*END\_METADATA\*řádek) . Výsledkem je úplný popis atributů souboru, jmen proměnných a datových typů, čímž slouží stejnému účelu jako odpovědi .das plus .dds z anOPeNDAPserver.ERDDAP™vrátí tuto změnu, pokud požadujete soubor Type=.nccsvMetadata zERDDAP™Soubor dat.
Sekce metadat
V NCCSV souboru používá každý řádek sekce metadat formát
proměnná Název,atribut Název,hodnota 1\[, hodnota 2\]\[, hodnota 3\]\[, hodnota 4\]\[...\]
Prostory před nebo po položek nejsou povoleny, protože způsobují problémy při importu souboru do tabulkových programů.
Sjezdy
První řádek NCCSV souboru je první řádek sekce metadat a musí mít\GLOBÁLNÍ\Konvence připisují seznam všech úmluv použitých v souboru jako řetězec obsahující seznam CSV, například: \GLOBÁLNÍ\,Konvence,"COARDS, CF-1,6, ACDD-1,3, NCCSV-1,2" Jednou z uvedených úmluv musí být NCCSV-1.2, která odkazuje na stávající verzi této specifikace.
Konec metadat
Konec sekce metadat NCCSV souboru musí být označen pouze řádkem \END\_METADATA\
Doporučuje se, ale nevyžaduje se, aby se všechny atributy dané proměnné objevily na přilehlých řádcích sekce metadat. Pokud je NCCSV soubor převeden naNetCDFsoubor, pořadí, že proměnnáNázvy první objeví v sekci metadat bude pořadí proměnných vNetCDFSložka.
Volitelné prázdné řádky jsou povoleny v sekci metadat po požadovaném prvním řádku s\GLOBÁLNÍ\ Sjezdyinformace (viz níže) a před požadovaným posledním řádku s\END\_METADATA\.
Pokud je z NCCSV souboru vytvořena tabulková tabulka, zobrazí se sekce dat metadat s názvy proměnných ve sloupci A, názvy atributů ve sloupci B a hodnoty ve sloupci C.
Pokud je tabulky následujících konvencí uložena jako soubor CSV, budou na konci řádků v sekci metadat často další čárky. Software, který převádí NCCSV soubory do.ncsoubory budou ignorovat další čárky.
proměnná Název
proměnná Název je název proměnné citlivé na případ v datovém souboru. Všechny proměnné musí začít 7-bitovým písmenem ASCII nebo podtržením a musí být složeny z 7-bitových ASCII písmen, podtržených a 7-bitových ASCII číslic.
GLOBÁLNÍ
Speciální proměnnáName\GLOBÁLNÍ\používá k označení globálních metadat.
atribut Název
atribut Název je jméno atributu spojeného s proměnnou nebo\GLOBÁLNÍ\. Všechny názvy atributů musí začít 7-bitovým ASCII písmenem nebo podtržením a musí se skládat z 7-bitových ASCII písmen, podtržených a 7-bitových ASCII číslic.
SCALAR
Zvláštní atribut Název\*SCALAR\*lze použít k vytvoření skalární datové proměnné a definovat její hodnotu. Datový typ\*SCALAR\*definuje datový typ proměnné, takže nespecifikujte\*DATA\_TYPE\*atribut pro skalární proměnné. Všimněte si, že v datové sekci NCCSV souboru nesmí být data pro skalární proměnnou.
Například pro vytvoření skalární proměnné s názvem "loď" s hodnotou "Okeanos Explorer" a atribut cf\_role použijte: loď,\SCALAR\"Okeanos Explorer" loď,cf\_role,trajektorie\_id Když je do proměnné skalárních dat načtenoERDDAP™, skalární hodnota se převede do sloupce v datové tabulce se stejnou hodnotou v každém řádku.
hodnota
hodnota je hodnota atributu metadat a musí být pole s jedním nebo více z byte, ubyte, krátký, uhort, int, uint, long, ulong, float, double, String, nebo char. Nejsou podporovány žádné jiné datové typy. Atributy bez hodnoty budou ignorovány. Pokud existuje více než jedna dílčí hodnota, musí být všechny dílčí hodnoty stejného datového typu. U datových typů jiných než Strings se hodnoty MUSÍ oddělit čárkami, například: sst,actual\_range,0.17f,23.58f Pro Struny použijte jeden řetězec\n (nový řádek) znaky oddělující podřetězce.
Definice atributových datových typů jsou:
byte
- hodnoty atributu byte (8-bit, podepsaný) musí být napsáno příponou "b," např. -7b, 0b, 7b . Rozsah platných bajtů je -128 až 127. Číslo, které vypadá jako byte, ale je neplatné (např. 128b) bude převeden na chybějící hodnotu nebo generovat chybovou zprávu.
ubyte
- hodnoty atributu ubyte (8- bit, nesignováno) musí být napsáno příponou "ub," např. 0ub, 7ub, 250ub . Rozsah platných bajtů je 0 až 255. Číslo, které vypadá jako ubyte, ale je neplatné (např. 256ub) bude převeden na chybějící hodnotu nebo generovat chybovou zprávu. Pokud je to možné, použijte byte místo ubyte, protože mnoho systémů nepodporuje nepodepsané byty (např. atributy vNetCDF-3 soubory) .
krátké
- krátké hodnoty atributu (16-bit, sign.) musí být napsáno příponou "s," např. -30000s, 0s, 30000s. Rozsah platných krátkých hodnot je -32768 až 32767. Číslo, které vypadá jako krátké, ale je neplatné (např. 32768s) bude převeden na chybějící hodnotu nebo generovat chybovou zprávu.
krátké
- ukrátit hodnoty atributu (16- bit, nesignováno) musí být napsáno příponou "nás," např. 0us, 30000us, 60000us. Rozsah platných krátkých hodnot je 0 až 65535. Číslo, které vypadá jako krátké, ale je neplatné (např. 65536us) bude převeden na chybějící hodnotu nebo generovat chybovou zprávu. Pokud je to možné, použijte krátký místo krátký, protože mnoho systémů nepodporuje nepodepsané byty (např. atributy vNetCDF-3 soubory) .
byte
- hodnoty atributu int (32-bit, sign.) musí být napsány jako JSON ints bez desetinné čárky nebo exponentu, ale s příponou 'i', např. -12067978i, 0i, 12067978i. Rozsah platných int hodnot je -2147483648 až 2147483647. Číslo, které vypadá jako int, ale je neplatné (např. 2147483648i) bude převeden na chybějící hodnotu nebo generovat chybovou zprávu.
uint
- hodnoty atributu uint (32- bitové, nepodepsané) musí být napsán jako JSON ints bez desetinné čárky nebo exponentu, ale s příponou 'ui', např., 0ui, 12067978ui, 4123456789ui. Rozsah platných hodnot int je 0 až 4294967295. Číslo, které vypadá jako uint, ale je neplatné (např. 2147483648ui) bude převeden na chybějící hodnotu nebo generovat chybovou zprávu. Pokud je to možné, použijte int místo uint, protože mnoho systémů nepodporuje nepodepsané bajty (např. atributy vNetCDF-3 soubory) .
dlouhé
- dlouhé hodnoty atributu (64-bit, podepsáno, v současné době podporováno NUG aERDDAP™ale dosud nepodporovaná CF) musí být napsáno bez desetinné čárky a příponou "L," např. -12345678987654321L, 0L, 12345678987654321L . Pokud používáte konvertující software pro převod NCCSV souboru s dlouhými hodnotami naNetCDF-3 soubor, jakékoli dlouhé hodnoty budou převedeny na dvojnásobek hodnot. Rozsah platných dlouhých hodnot je -9223372036854775808 až 922337236854775807. Číslo, které vypadá jako dlouhé, ale je neplatné (např. 9223372036854775808L) bude převeden na chybějící hodnotu nebo generovat chybovou zprávu. Pokud je to možné, použijte dvojité místo ulong, protože mnoho systémů nepodporuje dlouho (např.NetCDF-3 soubory) .
ulong
- hodnoty atributu ulong (64-bitová, nepodepsaná, v současné době podporovaná NUG aERDDAP™ale dosud nepodporovaná CF) musí být napsáno bez desetinného místa a příponou "uL," např. 0uL, 12345678987654321uL, 9007199254740992uL . Pokud používáte konvertující software pro převod NCCSV souboru s dlouhými hodnotami naNetCDF-3 soubor, jakékoli dlouhé hodnoty budou převedeny na dvojnásobek hodnot. Rozsah platných dlouhých hodnot je 0 až 184467440737095516115. Číslo, které vypadá jako ulong, ale je neplatné (např. 1844674073709551616uL) bude převeden na chybějící hodnotu nebo generovat chybovou zprávu. Pokud je to možné, použijte dvojité místo ulong, protože mnoho systémů nepodporuje podepsání nebo nepodepsání dlouho (např.NetCDF-3 soubory) .
plavat
- hodnoty atributu plováku (32-bit) musí být napsáno příponou "f" a může mít desetinnou čárku a/nebo exponent, např. 0f, 1f, 12.34f, 1e12f, 1.23e+12f, 1.23e12f, 1.87E-7f. Použijte NaNf pro plovoucí NaN (chybí) hodnota. Rozsah plováků je přibližně +/-3.40282347E+38f (~7 významných desetinných míst) . Číslo, které vypadá jako plovák, ale je neplatné (např. 1,0e39f) bude převeden na chybějící hodnotu nebo generovat chybovou zprávu.
dvakrát
- hodnoty dvojího atributu (64-bit) musí být napsáno příponou "d" a může mít desetinnou čárku a/nebo exponent, např. 0d, 1d, 12.34d, 1e12d, 1.23e+12d, 1.23e12d, 1.87E-7d. Použít NaNd pro dvojité NaN (chybí) hodnota. Rozsah dvojníků je přibližně +/-1.79769313486231570E+308d (~ 15 významných desetinných míst) . Číslo, které vypadá jako dvojité, ale je neplatné (např. 1,0e309d) bude převeden na chybějící hodnotu nebo generovat chybovou zprávu.
String
- Hodnoty atributu String jsou posloupností znaků UCS-2 (tj. 2-bajtové Unicode znaky jakoJava) , které musí být napsány jako JSON-jako řetězce.
- Dvojité citace (") v hodnotě String musí být zakódována jako dvě dvojité uvozovky ("") . To je to, co tabulkové programy vyžadují při čtení .csv souborů. To je to, co programy tabulky psát, když uložíte tabulku jako .csv soubor.
- Speciální JSON backslash-kódované znaky v hodnotě String musí být zakódovány jako v JSON (zejména\n(newline), \\ (backslash), \f (formfeed), \t (tab), \r (carriage return) nebo s\\ u Hhhh Syntaxe. V tabulce nepoužívejte Alt Enter k určení nového řádku v textové buňce; místo toho použijte\n (2 znaky: backslash and 'n ') Naznačit novou linku.
uhhhh
- Všechny ostatní znaky menší než znak # 32 musí být zakódovány pomocí syntaxe \u Hhhh , kde hhhh je 4-místný hexadecimální číslo znaku.
- Všechny potiskovatelné znaky větší než znak #126, např. znak Euro, se mohou objevit nezakódované, např. € (znak eura) , nebo kódován s\\ u Hhhh syntaxe, např. \u20AC. Viz stránky kódů odkazované na https://en.wikipedia.org/wiki/Unicode najít hexadecimální čísla spojená s konkrétními znaky Unicode nebo použít softwarovou knihovnu. Všimněte si, že někteříERDDAP™výstupní typy souborů, např. .csv, použijte znakovou sadu ISO 8859-1, takže znaky Unicode nad #255 budou ztraceny, když se tyto hodnoty zapíší do těchto typů souborů.
- Všechny netištěné znaky větší než znak #126, např. znak #127, jsou STRONGLIE DISKURAGED, ale měli byste použít \u Hhhh Syntaxe, pokud je zahrnete.
- Pokud String má prostor na začátku nebo na konci, nebo zahrnuje " (dvojitá citace) nebo čárka nebo obsahuje hodnoty, které by jinak byly vykládány jako jiný datový typ (např. int) , nebo je slovo "null," celý String musí být přiložen ve dvou citacích; jinak, na rozdíl od JSON, enclosing double citations jsou volitelné. Doporučujeme: když máte pochybnosti, zavřete celý řetězec do dvou citací. Prostory na začátku nebo na konci řetězce jsou silně odrazovány.
char
- znak atribut hodnoty jsou jeden UCS-2 znak (tj. 2-bajtové Unicode znaky jakoJava) . Tiskitelné znaky (jiné než zvláštní znaky jako nová linka, ", " a \) může být napsáno tak, jak je. Zvláštní znaky (např. nová linka) a jiné neoznačitelné znaky (např. 127) musí být napsán s\\ u Hhhh Syntaxe. Hodnoty atributu Char musí být uvedeny v jednotlivých uvozovkách (vnitřní uvozovky) a dvojité uvozovky (vnější uvozovky) , např. "'a'," "'""""" (dvojcitační znak) , "'\'" (jediný znak citace) , "'\ t'" (záložka) , "'\ u007F'" (znak "smazat" ') , a "'€'" (znak eura) . Tento systém používání jednoduchých a dvojitých uvozovek je zvláštní a těžkopádný, ale je to způsob, jak rozlišit hodnoty znaku od řetězců způsobem, který pracuje s tabulkovými listy. Hodnota, která vypadá jako znak, ale je neplatná, vytvoří chybovou zprávu. Všimněte si, že někteříERDDAP™výstupní typy souborů, např. .csv, použijte znakovou sadu ISO 8859-1, takže znaky Unicode nad #255 budou ztraceny, když se tyto hodnoty zapíší do těchto typů souborů.
Sufix
Všimněte si, že v části atributů NCCSV musí mít všechny číselné hodnoty atributů příponu. (např. 'b') pro identifikaci číselného datového typu (např. byte) . Ale v datové sekci NCCSV souboru nesmí mít číselné hodnoty nikdy tato příponová písmena (s výjimkou 'L' pro dlouhá celá čísla a 'uL' pro ulong celá čísla) ?\*DATA\_TYPE\*atribut pro proměnnou.
Typ údajů
Datový typ pro každý ne-skalárproměnná musí být specifikována\*DATA\_TYPE\*atribut, který může mít hodnotu byte, ubyte, krátký, uhort, int, uint, long, ulong, float, double, String, or char (případ necitlivý) . Například, qc\_flag,\DATA\_TYPE\,byte UPOZORNĚNÍ: Upřesnění správného\*DATA\_TYPE\*je tvoje zodpovědnost. Zadání nesprávného datového typu (např. int, kdy jste měli určit plovák) nevygeneruje chybovou zprávu a může způsobit ztrátu informací (Například hodnoty plováku se zaokrouhlí na ints) při čtení NCCSV souboruERDDAP™nebo přeměněn naNetCDFSložka.
Char Distrovered
Použití hodnot znakových dat je deprimováno, protože nejsou široce podporovány v jiných typech souborů. hodnoty znaku mohou být v datové sekci zapsány jako jednotlivé znaky nebo jako řetězce (zejména, pokud potřebujete napsat zvláštní znak) . Pokud se najde String, bude první znak Stringu použit jako hodnota znaku. Nulová délka Struny a chybějící hodnoty budou převedeny na znak \uFFFF. Všimněte si, žeNetCDFsoubory podporují pouze jednotlivé byte chars, takže všechny znaky větší než znak # 255 budou převedeny na '?' při psaníNetCDFSložky. Pokud není atribut znakové sady použit k určení jiné znakové sady pro proměnnou znaku, použije se znaková sada ISO-8859-1.
Dlouhá a nepodepsaná sklíčenost
Dlouhé a nepodepsané typy jsou znechuceny. Ačkoli mnoho typů souborů (např.NetCDF-4 a Json) aERDDAP™podpora dlouhá a nepodepsaná (ubyte, uhort, uint, ulong) hodnoty, použití dlouhých a nepodepsaných hodnot v NCCSV souborech je v současné době odrazeno, protože v současné době nejsou podporovány Excel, CF aNetCDF- Tři složky. Pokud chcete zadat dlouhé nebo nepodepsané hodnoty v NCCSV souboru (nebo v příslušné tabulce Excel) , Musíte použít příponu 'L' tak, aby Excel neléčí čísla jako plovoucí bod čísla s nižší přesností. V současné době, pokud jsou NCCSV soubory převedeny naNetCDF- 3.ncSoubor, dlouhé a dlouhé hodnoty dat budou převedeny do dvou hodnot, což způsobí ztrátu přesnosti pro velmi velké hodnoty (menší než -2^53 na dlouhé nebo větší než 2^53 na dlouhé a ulong) . InNetCDF- 3.ncsoubory, ubytovat, ukrátit a uint proměnné se objeví jako byte, short, a int s atributem \_Unsigned=true metadata. InNetCDF- 3.ncsoubory, ubyte, uhort, a uint atributy se zobrazují jako byte, short, and int atributy obsahující odpovídající hodnotu 2 's-komplement (např. 255ub vypadá jako -1b) . To je samozřejmě problém, takže podepsané datové typy by měly být použity místo nepodepsaných datových typů, kdykoli je to možné.
CF, ACDD aERDDAP™Metadata
Protože se předpokládá, že většina NCCSV souborů, nebo.ncsoubory vytvořené z nich, budou přečteny doERDDAP, důrazně se doporučuje, aby NCCSV soubory obsahují atributy metadat, které jsou požadovány nebo doporučenéERDDAP™(viz /docs/server-admin/datasets#globální atributy). Vlastnosti jsou téměř všechny ze standardů CF a ACDD metadat a slouží k správnému popisu datového souboru (Kdo, co, kdy, kde, proč, jak) pro někoho, kdo jinak neví nic o datovém souboru. Zvláštní význam by měly mít téměř všechny číselné proměnné atribut jednotek sUDUNITS-kompatibilní hodnota, např. sst, jednotky, stupeň\_C
Je v pořádku zahrnout další atributy, které nejsou ze standardů CF nebo ACDD nebo zERDDAP.
Oddíl údajů
Struktura
První řádek datové sekce musí mít seznam názvů proměnných, který je citlivý na případy, oddělený čárkou. Všechny proměnné v tomto seznamu musí být popsány v sekci metadat a naopak (jiné než\GLOBÁLNÍ\atributy a\SCALAR\proměnné) .
Druhý přes předposlední řádky datové sekce musí mít čárkový seznam hodnot. Každý řádek údajů musí mít stejný počet hodnot jako čárka oddělený seznam názvů proměnných. Prostory před nebo po hodnotách nejsou povoleny, protože způsobují problémy při importu souboru do tabulkových programů. Každý sloupec v tomto oddíle musí obsahovat pouze hodnoty\*DATA\_TYPE\*určené pro tuto proměnnou\*DATA\_TYPE\*atribut pro tuto proměnnou. Na rozdíl od části atributů nesmí mít číselné hodnoty v datové sekci příponu pro označení datového typu. Na rozdíl od části atributů mohou hodnoty znaku v datové sekci vynechat enclosing single citations, pokud nejsou potřebné pro deambiciaci (tak, ',' a '\' ', jak je uvedeno zde) . V NCCSV souboru může být nějaký počet těchto řádků dat, ale v současné doběERDDAP™lze číst pouze soubory NCCSV s až 2 miliardami řad. Obecně se doporučuje rozdělit velké datové soubory na více souborů NCCSV s méně než 1 milion řádků.
Ukončit údaje
Konec datové sekce musí být označen pouze řádkem \END\_DATA\
Pokud je další obsah v NCCSV souboru po\*END\_DATA\*řádek, bude ignorován při přeměně NCCSV souboru na.ncSložka. Takový obsah je proto odrazován.
V tabulce, která následuje po těchto konvencích, budou názvy proměnných a hodnoty dat ve více sloupcích. Viz příklad níže.
Chybějící hodnoty
Počet chybějících hodnot může být zapsán jako numerická hodnota určenámissing\_valuenebo atribut \_FillValue pro tuto proměnnou. Viz například druhá hodnota v tomto řádku dat: Bell M. Shimada, 99,123.4 To je doporučený způsob, jak zvládnout chybějící hodnoty pro byte, ubyte, krátké, uhort, int, uint, long a ulong proměnné.
float nebo double NaN hodnoty mohou být zapsány jako NaN. Viz například druhá hodnota v tomto řádku dat: Bell M. Shimada, NaN,123.4
Smyčcové a numerické chybějící hodnoty mohou být označeny prázdným polem. Viz například druhá hodnota v tomto řádku dat: Bell M. Shimada, 123.4
Pro byte, ubyte, short, uhort, int, uint, long a ulong proměnné, NCCSV převodník nástroj aERDDAP™převést prázdné pole na maximální povolenou hodnotu pro tento datový typ (např. 127 pro bajty) . Pokud to uděláte, určitě přidejtemissing\_valuenebo atribut \_FillValue pro tuto proměnnou pro identifikaci této hodnoty, např. proměnná Název ,\_FillValue,127b Pro float a dvojité proměnné bude prázdné pole převedeno na NaN.
Hodnoty dataTime
Hodnoty DateTime (včetně hodnot datumu, které nemají časovou složku) mohou být zastoupeny jako čísla nebo jako Struny v NCCSV souborech. Zadané datumTime proměnné mohou mít pouze String hodnoty nebo pouze číselné hodnoty, ne obojí. NCCSV software převede hodnoty String dateTime na numerické datum Hodnoty času při vytváření.ncsoubory (podle požadavků CF) . Hodnoty string dateTime mají tu výhodu, že jsou snadno čitelné lidmi.
Hodnoty DateTime zastoupené jako číselné hodnoty musí mít atribut jednotek, který určuje " jednotky od datum Čas " podle požadavků CF a určenýchUDUNITSnapř. čas, jednotky, sekundy od 1970-01-01T00:00:00Z
Hodnoty DateTime představující hodnoty String musí mít String\*DATA\_TYPE\*atribut a atribut jednotek, který určuje datum Časový vzorec podle specifikaceJavaTřída DateTimeForhmota ( https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html ) . Například, čas, jednotky,yyyy-MM-ddT'HH:mm:ssZ Všechny hodnoty dataTime pro danou datovou proměnnou musí používat stejný formát. Ve většině případů bude dateTime vzor, který potřebujete pro atribut jednotek, variací jednoho z těchto formátů:
- yyyy-MM-ddT'HH:mm:ss. SSSZ, což je ISO 8601:2004 (E) datum Časový formát. Možná budete potřebovat zkrácenou verzi, např.yyyy-MM-ddT'HH:mm:ssZ (pouze doporučený formát) neboyyyy-MM-dd. Pokud měníte formát vašich dateTime hodnot, NCCSV důrazně doporučuje změnit tento formát (možná zkrácené) . Toto je formát, kterýERDDAP™použije, když píše NCCSV soubory.
- rrrrMMddHHmmss.SSS Časový formát. Můžete potřebovat zkrácenou verzi tohoto, např. rrrrMMdd.
- M/d/rrrr H:mm:ss. Systém SSS, který zpracovává data a data ve stylu USA, jako je "3/23/2017 16:22:03.000." Můžete potřebovat zkrácenou verzi, např. M/d/rrrr .
- YYYDDDHmmssSSS ? což je rok plus nula-polstrovaný den roku (např. 001 = 1. leden 365 = 31. prosinec v nelegálním roce; to je někdy chybně nazýváno Julian datum) . Můžete potřebovat zkrácenou verzi tohoto, např. rrrrDDD .
Přesnost
Když knihovna softwaru konvertuje.ncsoubor do NCCSV souboru, celé datum Časové hodnoty budou napsány jako řetězce s ISO 8601:2004 (E) datum Časový formát, např. 1970-01-01T00:00:00Z . Přesnost můžete ovládat pomocíERDDAP- specifický atributtime\_precision. Viz /docs/server-admin/datasets#time\_precision.
Časové pásmo
Výchozí časové pásmo pro datum Časové hodnoty jsouZulu (nebo GMT) časové pásmo, které nešetří denní světlo. Pokud má proměnná dateTime hodnoty dateTime z jiného časového pásma, musíte to zadat pomocíERDDAP- specifický atributtime\_zone. To je požadavek proERDDAP™(viz /docs/server-admin/datasets#time\_zone).
Hodnoty stupně
Jak vyžaduje CF, všechny hodnoty stupně (např. u zeměpisné délky a zeměpisné šířky) musí být specifikovány jako dvojité hodnoty desetinného stupně, nikoli jako stupeň°min'sec" String nebo jako samostatné proměnné pro stupně, minuty, sekundy. Směrové konstrukce N, S, E a W nejsou povoleny. Použijte záporné hodnoty pro západní délky a pro jižní šířky.
DSG Typy funkcí
NCCSV soubor může obsahovat CF Diskrétní odběr vzorků geometrie ( https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html#discrete-sampling-geometries ) data. Jsou to atributy, díky kterým to funguje:
- Jak vyžaduje CF, musí soubor NCCSV obsahovat řádek v sekci metadat označující\GLOBÁLNÍ\ featureTypeatribut, např., \GLOBÁLNÍ\,featureType,trajektorie
- Pro použití vERDDAP™, NCCSV soubor musí obsahovat řádek nebo řádky v sekci metadat označující proměnné cf\_role=...\_id, např. loď,cf\_role,trajektorie\_id To je volitelné pro CF, ale požadované v NCCSV.
- Pro použití vERDDAP™, NCCSV soubor musí obsahovat řádek nebo řádky v sekci metadat, které proměnné jsou spojeny s každým časemSérie, trajektorie, nebo profil, jak požadujeERDDAP™(viz /docs/server-admin/datasets#cdm\_data\_type), např. \GLOBÁLNÍ\,cdm\_trajectory\_variables,"ship" nebo \GLOBÁLNÍ\,cdm\_timeseries\_variables,"station\_id,lat,lon"
Soubor vzorku
Zde je ukázkový soubor, který ukazuje mnoho funkcí NCCSV souboru:
\\*GLOBAL\\*,Conventions,"COARDS, CF-1.6, ACDD-1.3, NCCSV-1.2"
\\*GLOBAL\\*,cdm\\_trajectory\\_variables,"ship"
\\*GLOBAL\\*,creator\\_email,erd.data@noaa.gov
\\*GLOBAL\\*,creator\\_name,Bob Simons
\\*GLOBAL\\*,creator\\_type,person
\\*GLOBAL\\*,creator\\_url,https://www.pfeg.noaa.gov
\\*GLOBAL\\*,featureType,trajectory
\\*GLOBAL\\*,infoUrl,https://erddap.github.io/docs/user/nccsv-1.20
\\*GLOBAL\\*,institution,"NOAA NMFS SWFSC ERD, NOAA PMEL"
\\*GLOBAL\\*,license,"""NCCSV Demonstration"" by Bob Simons and Steve Hankin is
licensed under CC BY 4.0, https://creativecommons.org/licenses/by/4.0/ ."
\\*GLOBAL\\*,keywords,"NOAA, sea, ship, sst, surface, temperature, trajectory"
\\*GLOBAL\\*,standard\\_name\\_vocabulary,CF Standard Name Table v55
\\*GLOBAL\\*,subsetVariables,"ship"
\\*GLOBAL\\*,summary,"This is a paragraph or two describing the dataset."
\\*GLOBAL\\*,title,"NCCSV Demonstration"
ship,\\*DATA\\_TYPE\\*,String
ship,cf\\_role,trajectory\\_id
time,\\*DATA\\_TYPE\\*,String
time,standard\\_name,time
time,units,"yyyy-MM-dd'T'HH:mm:ssZ"
lat,\\*DATA\\_TYPE\\*,double
lat,units,degrees\\_north
lon,\\*DATA\\_TYPE\\*,double
"lon","units","degrees\\_east"
status,\\*DATA\\_TYPE\\*,char
status,comment,"From http://some.url.gov/someProjectDocument , Table C"
testByte,\\*DATA\\_TYPE\\*,byte
testByte,units,1
testUByte,\\*DATA\\_TYPE\\*,ubyte
testUByte,units,1
testLong,\\*DATA\\_TYPE\\*,long
testLong,units,1
testULong,\\*DATA\\_TYPE\\*,ulong
testULong,units,1
sst,\\*DATA\\_TYPE\\*,float
sst,standard\\_name,sea\\_surface\\_temperature
sst,actual\\_range,0.17f,23.58f
sst,units,degree\\_C
sst,missing\\_value,99f
sst,testBytes,-128b,0b,127b
sst,testShorts,-32768s,0s,32767s
sst,testInts,-2147483648i,0i,2147483647i
sst,testLongs,-9223372036854775808L,0L,9223372036854775807L
sst,testFloats,-3.40282347e38f,0f,3.40282347E+38f
sst,testDoubles,-1.79769313486231570e308d,0d,1.79769313486231570E+308d
sst,testChars,"','","'""'","'€'"
sst,testStrings," a~,\\n'z""\\u20AC"
sst,testUBytes,0ub,127ub,255ub
sst,testUInts,0ui,2147483647ui,4294967295ui
sst,testULongs,0uL,9223372036854775807uL,18446744073709551615uL
sst,testUShorts,0us,32767us,65535us
\\*END\\_METADATA\\*
ship,time,lat,lon,status,testByte,testUByte,testLong,testULong,sst
Bell M. Shimada,2017-03-23T00:45:00Z,28.0002,-130.2576,A,-128, 0,-9223372036854775808L,0uL,10.9
Bell M. Shimada,2017-03-23T01:45:00Z,28.0003,-130.3472,\\u20AC,0,127,-9007199254740992L,9223372036854775807uL,10.0
"Bell M. Shimada","2017-03-23T02:45:00Z",28.0001,-130.4305,"'\\t'",126,254,9223372036854775806L,18446744073709551614uL,99
"Bell M. Shimada",2017-03-23T12:45:00Z,27.9998,-131.5578,"'""'",127,255,9223372036854775807L,18446744073709551615uL,NaN
Poznámky:
- Tento soubor obsahuje mnoho složitých případů (např. znakové a dlouhé proměnné a obtížné hodnoty řetězce) . Většina NCCSV souborů bude mnohem jednodušší.
- Licenční čára je zde rozdělena do dvou řádků, ale je to jen jeden řádek ve vzorku souboru.
- \\ u20ac je\uhhhh kódování €. \u00FC je\uhhhh kódování ü. Můžete také použít nekódované znaky přímo.
- Mnoho Struny v příkladu jsou přiloženy dvojími uvozovkami, i když nemusí být např. mnoha globálními atributy včetně názvu, atributu lon jednotek a třetího řádku dat.)
- Bylo by jasnější a lepší, kdyby atribut jednotek pro testDlouhá proměnná byla zapsána ve dvoucitacích, což naznačuje, že je hodnota Stringu. Ale současné zastoupení (1, bez kotací) bude interpretován správně jako String, ne celé číslo, protože neexistuje žádný 'i' přípona.
- Na rozdíl od jiných numerických datových typů mají dlouhé hodnoty v datovém oddílu příponu ("L") který identifikuje jejich číselný datový typ. To je nutné, aby se zabránilo tomu, aby tabulky interpretovaly hodnoty jako čísla plovoucích bodů, a tím ztratily přesnost.
Tabulky
V tabulce, stejně jako v NCCSV souboru:
- Zapsat číselné hodnoty atributu, jak je uvedeno pro NCCSV soubory (např. s příponou, např. 'f', pro identifikaci datového typu atributu) .
- V Strings musí být všechny netisknutelné a speciální znaky psány buď jako JSON-jako backslashed charakter (např.\npro nový řádek) nebo jako hexadecimální znakové číslo Unicode (případ necitlivý) se syntaxi\\ u Hhhh . Použití\n (2 znaky: backslash and 'n ') k označení nové linie uvnitř řetězce, nikoli Alt Enter. Všechny znaky, které lze tisknout, mohou být napsány nekódované nebo se syntaxi\\ u Hhhh .
Jedinými rozdíly mezi soubory NCCSV a analogickou tabulkou, která se řídí těmito úmluvami, jsou:
- NCCSV soubory mají hodnoty na řádku oddělené čárkami. Tabulky mají hodnoty na lince v přilehlých buňkách.
- Struny v souborech NCCSV jsou často obklopeny dvojitými uvozovkami. Struny v tabulkách nejsou nikdy obklopeny dvojitými uvozovkami.
- Vnitřní dvojité kotace (") v Struny v NCCSV souborech se zobrazují jako 2 dvojité uvozovky. Vnitřní dvojité citace v tabulkách se zobrazují jako 1 dvojitá citace.
Pokud je tabulky následujících konvencí uložena jako soubor CSV, často budou na konci mnoha řádků další čárky. Software, který převádí NCCSV soubory do.ncsoubory budou ignorovat další čárky.
Excel
Pro import NCCSV souboru do Excelu:
- Vyberte soubor: Otevřít .
- Změnit typ souboru na textové soubory (\.prn;\.txt; \*.csv) .
- Prohledejte adresáře a klikněte na NCCSV .csv soubor.
- Klepněte na tlačítko Otevřít .
Vytvořit NCCSV soubor z tabulky Excel:
- Vyberte soubor: Uložit jako .
- Změnit Uložit jako typ: být CSV (Čárka delimited) (\*.csv) .
- V reakci na upozornění na kompatibilitu klikněte na Ano .
- Výsledný soubor .csv bude mít na konci všech řádků kromě řádků CSV další čárky. Můžete je ignorovat.
V aplikaci Excel se výše uvedený vzorek NCCSV souboru objeví jako
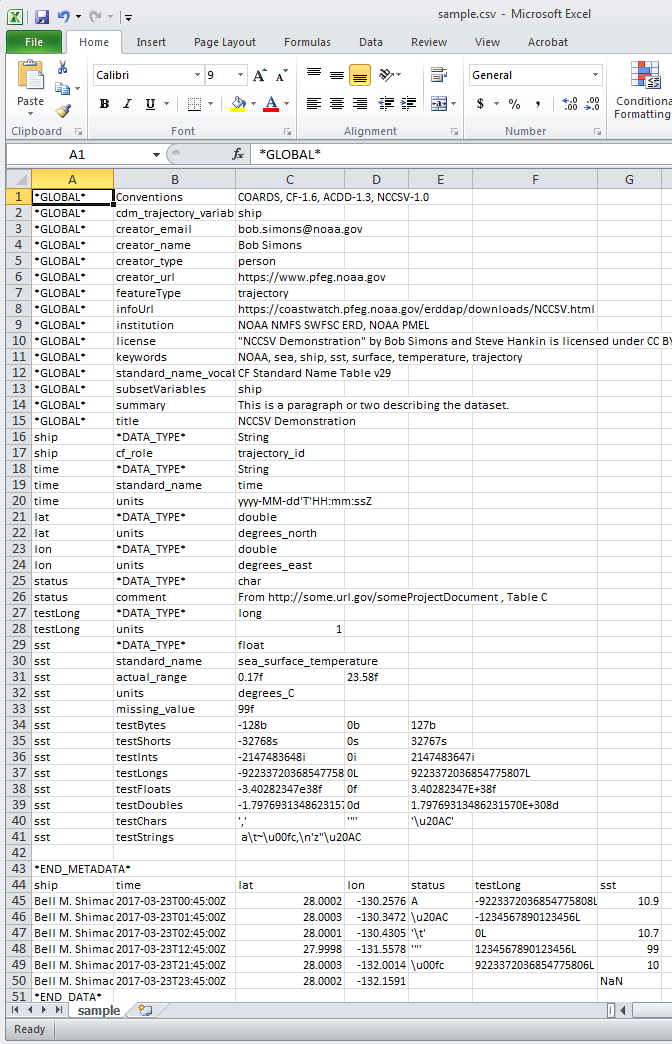
Google listy
Importovat NCCSV soubor do Google Sheets:
- Vyberte soubor: Importovat .
- Vyberte si nahrát soubor a klikněte na Nahrát soubor z počítače . Vyberte soubor a poté klikněte na Otevřít .
Nebo zvolte My Drive a změňte výběr typu souboru na všechny typy souborů . Vyberte soubor a poté klikněte na Otevřít .
Vytvořit NCCSV soubor z tabulky Google Sheets:
- Vyberte soubor: Uložit jako .
- Změnit Uložit jako typ: být CSV (Čárka delimited) (\*.csv) .
- V reakci na upozornění na kompatibilitu klikněte na Ano .
- Výsledný soubor .csv bude mít na konci všech řádků kromě řádků CSV další čárky. Ignoruj je.
Problémy / Varování
- Pokud vytvoříte NCCSV soubor s textovým editorem nebo vytvoříte analogickou tabulku v tabulkovém programu, textový editor nebo tabulkový program nebude kontrolovat, zda jste tyto konvence správně sledovali. Je na vás, abyste se řídili těmito sjezdy správně.
- Převod tabulky podle této úmluvy na soubor csv (takže soubor NCCSV) na konci všech řádků kromě řádků dat CSV povede k dalším čárkám. Ignoruj je. Software pak konvertuje NCCSV soubory do.ncsoubory je budou ignorovat.
- Pokud NCCSV soubor má nadbytečnou čárku na konci řádků, můžete je odstranit převodem NCCSV souboru doNetCDFsoubor a pak převéstNetCDFsoubor zpět do NCCSV souboru.
- Když se snažíte převést NCCSV soubor doNetCDFsoubor, některé chyby budou detekovány software a bude generovat chybové zprávy, což způsobí, že konverze selže. Jiné problémy jsou těžké nebo nemožné chytit a nebudou generovat chybové zprávy nebo varování. Další problémy (Například přebytečné čárky na konci řádku) budou ignorováni. Převodník souborů provede pouze minimální kontrolu správnosti výslednéNetCDFsoubor, např. pokud jde o dodržování předpisů CF. Je povinností tvůrce souboru a uživatele souboru ověřit, zda jsou výsledky konverze požadované a správné. Dva způsoby kontroly jsou:
- Vytiskněte obsah.ncsoubor s ncdump ( https://linux.die.net/man/1/ncdump ) .
- Zobrazit obsah dat vERDDAP™.
Změny
Původní verze bylaNCCSV v1.00 (vERDDAP™v1.76, propuštěn 2017-05-12)
- ZměnyNCCSV v1.10 (vERDDAP™v2.10, propuštěn 2020-11-05) :
- Přidána podpora pro ubyte, uhort, uint, ulong. Díky CF za přidání podpory pro tyto datové typy v CF.
- Změny zavedené v1.20 (vERDDAP™v2.23, propuštěn 2023-02-27) :
- Přepnuto z kódování znaků ASCII na kódování UTF-8 pro NCCSV .csv soubory.
- ERDDAP™lze stále číst soubory ze všech předchozích i aktuálních verzí NCCSV.
- ERDDAP™Nyní vždy píše NCCSV v1.20 soubory.
- Pokud jste napsali klienta pro čtení NCCSV souborů, změňte jej tak, aby bral všechny NCCSV soubory jako UTF-8 soubory. To bude fungovat se staršími NCCSV soubory, protože ASCII je podmnožina UTF-8 kódování znaků.
- Díky Pauline Chauvetové, Nateovi a Thomasi Gardinerovi.
- Přepnuto z kódování znaků ASCII na kódování UTF-8 pro NCCSV .csv soubory.