NCSSV -
ANetCDF-Kompatybilna specyfikacja pliku ASCII CSV, Wersja 1.00
Bob Simons i Steve Hankin "NCSSV" Bob Simons i Steve Hankin jest licencjonowany naCC BY 4.0
Wprowadzenie
Niniejszy dokument określa format pliku tekstowego ASCII CSV, który może zawierać wszystkie informacje (metadane i dane) które można znaleźć wNetCDF .ncplik zawierający tabelę danych podobną do pliku CSV. Rozszerzenie pliku dla pliku tekstowego ASCII CSV po tej specyfikacji musi być .csv tak, że może być łatwo i poprawnie odczytywane do programów arkuszy kalkulacyjnych, takich jak Excel i Google Sheets. Bob Simons napisze oprogramowanie do konwersji pliku NCSV wNetCDF-3 (i być może równieżNetCDF- 4) .ncplik i odwrotnie, bez utraty informacji. Bob Simons zmodyfikowałERDDAP™obsługuje czytanie i pisanie tego typu plików.
Format NCSSV jest zaprojektowany tak, aby oprogramowanie arkusza kalkulacyjnego, takie jak Excel i Google Sheets, mogło importować plik NCSV jako plik csv, ze wszystkimi informacjami w komórkach arkusza kalkulacyjnego, gotowymi do edycji. Albo arkusz kalkulacyjny może być stworzony od podstaw zgodnie z konwencjami NCSV. Niezależnie od źródła arkusza kalkulacyjnego, jeśli jest on następnie eksportowany jako plik .csv, będzie on zgodny ze specyfikacją NCSSV i żadne informacje nie zostaną utracone. Jedyne różnice pomiędzy plikami NCSSV a analogicznymi plikami arkusza kalkulacyjnego, które są następujące po tych konwencjach, to:
- Pliki NCSSV mają wartości na linii oddzielonej przecinkami. Arkusze kalkulacyjne mają wartości na linii w sąsiadujących komórkach.
- Fragmenty w plikach NCSV są często otoczone podwójnymi cytatami. Struny w arkuszach kalkulacyjnych nigdy nie są otoczone podwójnymi cytatami.
- Wewnętrzne podwójne kwotowania (") w Strings w plikach NCSSV pojawiają się jako 2 podwójne cytaty. Wewnętrzne podwójne cytaty w arkuszach kalkulacyjnych pojawiają się jako 1 podwójny cytat.
PatrzArkusz kalkulacyjnyPoniższa sekcja zawiera więcej informacji.
Trwałe
Podobnie jak ogólnie w przypadku plików CSV, pliki NCSV są usprawnione. Tak więc, jeśli NCSV jest generowany na -the-fly przez serwer danych, takich jakERDDAP™, serwer może rozpocząć strumieniowanie danych do requester przed zebraniem wszystkich danych. Jest to przydatna i pożądana cecha.NetCDFpliki nie są natomiast usprawnione.
ERDDAP™
Ta specyfikacja jest tak zaprojektowany, że NCSSV pliki i.ncpliki, które mogą być tworzone z nich mogą być używane przezERDDAP™serwer danych (przezPliki EDDTableFromNccsvNameorazPliki EDDTableFromNc@@typy zbioru danych) , ale ta specyfikacja jest zewnętrznaERDDAP.ERDDAP™posiada kilka wymaganych atrybutów globalnych oraz wiele zalecanych atrybutów globalnych i zmiennych, głównie opartych na atrybutach CF i ACDD (patrz: / docs / server- admin / datasets # global- attributes).
Saldo
Projekt formatu NCSSV jest równowagą kilku wymagań:
- Pliki muszą zawierać wszystkie dane i metadane, które byłyby w tabeliNetCDFplik, w tym konkretne rodzaje danych.
- Pliki muszą być odczytywane i zapisywane z arkusza kalkulacyjnego bez utraty informacji.
- Pliki muszą być łatwe dla ludzi do tworzenia, edycji, czytania i rozumienia.
- Pliki muszą być jednoznacznie analizowane przez programy komputerowe.
Jeżeli pewien wymóg w niniejszym dokumencie wydaje się dziwny lub wybredny, to prawdopodobnie konieczne jest spełnienie jednego z tych wymogów.
Inne specyfikacje
Specyfikacja ta odnosi się do kilku innych specyfikacji i bibliotek, z którymi jest ona przeznaczona, ale specyfikacja ta nie jest częścią żadnej z tych innych specyfikacji, ani nie wymaga żadnych zmian, ani nie jest z nimi sprzeczna. Jeżeli nie określono w tym miejscu szczegółów dotyczących jednej z tych norm, zob. odnośna specyfikacja. W szczególności obejmuje to:
- Konwencja o atrybucie dla wyszukiwania danych (ACDD) standard metadanych: https://wiki.esipfed.org/Attribute\_Convention\_for\_Data\_Discovery\_1-3 .
- Klimat i prognoza (CF) standard metadanych: https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html .
- WNetCDFPrzewodnik dla użytkowników (NUG) : https://docs.unidata.ucar.edu/netcdf-java/current/userguide/index.html .
- WNetCDFbiblioteki oprogramowania, takie jakNetCDF- Java iNetCDF- c: https://www.unidata.ucar.edu/software/netcdf/ . Te biblioteki nie mogą czytać plików NCSV, ale mogą czytać.ncpliki utworzone z plików NCSV.
- / https://www.json.org/
Notowanie
W niniejszej specyfikacji, nawiasy,\[ \], określić pozycje opcjonalne.
Struktura pliku
Kompletny plik NCSSV składa się z dwóch sekcji: sekcji metadanych, a następnie sekcji danych.
Pliki NCSSV muszą zawierać tylko 7- bitowe znaki ASCII. W związku z tym, zestaw znaków lub kodowanie używane do zapisu i odczytu pliku może być dowolny zestaw znaków lub kodowanie, które jest zgodne z 7- bitowym zestawem znaków ASCII, np. ISO- 8859-1.ERDDAP™odczytuje i pisze pliki NCSSV za pomocą zestawu znaków ISO- 8859-1.
Pliki NCSSV mogą używać albo nowej linii (\n) (co jest powszechne na komputerach Linux i Mac OS X) lub powóz Powrót plus nowa linia (\r\n) (co jest powszechne na komputerach Windows) jako znaczniki końca linii, ale nie oba.
.nccsvMetadane
Kiedy zarówno twórca, jak i czytelnik się tego spodziewają, jest również możliwe, a czasami przydatne, aby wariant pliku NCSSV, który zawiera tylko sekcję metadanych (w tym\*END\ _ METADATA\*linia) . Wynik zawiera pełny opis atrybutów pliku, nazw zmiennych i typów danych, co służy temu samemu celowi co odpowiedzi .das plus .dds zOPeNDAPserwer.ERDDAP™zwróci tę zmianę, jeśli zażądasz pliku Typ =.nccsvMetadane zERDDAP™zestaw danych.
Sekcja metadanych
W pliku NCCSV każda linia sekcji metadanych używa formatu
zmienna Nazwa,atrybut Nazwa,wartość 1\[, value2\]\[, wartość 3\]\[, wartość\]\[...\]
Spacje przed lub po pozycji nie są dozwolone, ponieważ powodują problemy przy importowaniu pliku do programów arkusza kalkulacyjnego.
Konwencje
Pierwsza linia pliku NCSSV jest pierwszą linią sekcji metadanych i musi mieć\GLOBAL\Konwencje przypisują wszystkie konwencje używane w pliku jako String zawierający listę CSV, na przykład: \GLOBAL\, konwencje ",COARDS, CF- 1.6, ACDD- 1.3, NCSSV - 1.0 " Jedną z wymienionych konwencji musi być NCSV- 1.0, która odnosi się do obecnej wersji niniejszej specyfikacji.
END _ METADATA
Koniec sekcji metadanych pliku NCSSV musi być oznaczony linią tylko \END\ _ METADATA\
Zaleca się, ale nie wymaga się, aby wszystkie atrybuty danej zmiennej pojawiały się na sąsiadujących liniach sekcji metadanych. Jeśli plik NCSSV jest przekształcany wNetCDFplik, kolejność, że zmienne Nazwy po raz pierwszy pojawiają się w sekcji metadanych będzie kolejność zmiennych wNetCDFplik.
Opcjonalne puste linie są dozwolone w sekcji metadanych po wymaganej pierwszej linii z\GLOBAL\ Konwencjeinformacje (zob. poniżej) i przed wymaganą ostatnią linią z\END\ _ METADATA\.
Jeżeli arkusz kalkulacyjny jest tworzony z pliku NCCSV, sekcja danych metadanych pojawi się ze zmiennymi nazwami w kolumnie A, nazwami atrybutów w kolumnie B oraz wartościami w kolumnie C.
Jeżeli arkusz kalkulacyjny następujący po tych konwencjach jest zapisywany jako plik CSV, często na końcu wierszy w sekcji metadanych będą dodatkowe przecinki. Oprogramowanie, które konwertuje pliki NCSSV do.ncpliki zignorują dodatkowe przecinki.
zmienna Nazwa
zmienna Nazwa jest nazwą zmiennej wrażliwej na przypadek w pliku danych. Wszystkie nazwy zmiennych muszą zaczynać się od 7- bitowej litery ASCII lub podkreślenia i składać się z 7- bitowych liter ASCII, podkreśleń i 7- bitowych cyfr ASCII.
GLOBAL
Specjalna nazwa zmiennej\GLOBAL\jest używany do określenia globalnych metadanych.
atrybut Nazwa
atrybut Nazwa jest nazwą atrybutu powiązaną ze zmienną wrażliwą na przypadek lub\GLOBAL\. Wszystkie nazwy atrybutów muszą zaczynać się od 7-bitowej litery ASCII lub podkreślenia i składać się z 7-bitowych liter ASCII, podkreśleń i 7-bitowych cyfr ASCII.
SKALAR
Atrybut specjalny Nazwa\*SKALAR\*może być użyty do stworzenia zmiennej danych skalarnych i zdefiniowania jej wartości. Typ danych\*SKALAR\*definiuje typ danych dla zmiennej, więc nie określaj a\*DANE\ _ TYP\*atrybut zmiennych skalarnych. Należy zauważyć, że nie może być danych dla zmiennej skalarnej w sekcji danych pliku NCSV.
Na przykład, aby utworzyć zmienną skalarną o nazwie "statek" o wartości "Okeanos Explorer" i atrybucie cf\ _ role, użyj: statek,\SKALAR\, "Okeanos Explorer" statek, cf\ _ rola, trajektoria\ _ id Kiedy zmienna danych skalarnych jest odczytywanaERDDAP™, wartość skalarna jest zamieniana na kolumnę w tabeli danych o tej samej wartości w każdym wierszu.
wartość
wartość jest wartością atrybutu metadanych i musi być tablicą z jednym lub większą liczbą bajtów, krótkich, int, długich, płaskich, podwójnych, strun lub znaków. Nie są obsługiwane żadne inne typy danych. Atrybuty bez wartości będą ignorowane. Jeżeli istnieje więcej niż jedna wartość podrzędna, wartości podrzędne muszą być tego samego typu danych i oddzielone przecinkami, na przykład: sst,actual\_range,0.17f, 23.58f Jeśli istnieje wiele wartości String, użyj pojedynczego String z\n (newline) znaki oddzielające podciągi.
Definicje typów danych atrybutów są następujące:
bajt
- wartości atrybutów bajtów (8- bit, podpisany) musi być napisane przyrostkiem 'b', np. -7b, 0b, 7b. Zakres poprawnych wartości bajtów wynosi od -128 do 127. Liczba, która wygląda jak bajt, ale jest niepoprawna (np. 128b) wygeneruje komunikat błędu.
krótkie
- krótkie wartości atrybutów (16- bit, podpisany) musi być napisane przyrostkiem, np. -30000s, 0s, 30000s. Zakres ważnych wartości krótkich wynosi od -32768 do 32767. Liczba, która wygląda jak krótki, ale jest niepoprawna (np. 32768s) wygeneruje komunikat błędu.
int
- wartość atrybutu int (32- bit, podpisany) musi być napisane jako JSON ints bez dziesiętnego punktu lub wykładnika, ale z przyrostkiem 'i', np., -12067978i, 0i, 12067978i. Zakres ważnych wartości int wynosi -2147483648 do 2147483647. Liczba, która wygląda jak int, ale jest nieprawidłowa (np. 2147483648i) wygeneruje komunikat błędu.
długi
- długie wartości atrybutów (64- bit, podpisane, obecnie obsługiwane przez NUG iERDDAP™ale jeszcze nie wspierane przez CF) musi być napisane bez punktu dziesiętnego i z przyrostkiem 'L', np. -12345678987654321L, 0L, 12345678987654321L. Jeśli używasz oprogramowania do konwersji do konwersji pliku NCSV z długimi wartościamiNetCDF-3 plik, wszelkie długie wartości będą konwertowane na podwójne wartości. Zakres ważnych wartości długich wynosi -9223372036854775808 do 9223372036854775807. Liczba, która wygląda jak długi, ale jest niepoprawna (np. 9223372036854775808L) wygeneruje komunikat błędu.
float
- wartości atrybutów float (32- bit) musi być napisane przyrostkiem "f" i może mieć punkt dziesiętny i / lub wykładnik, np. 0f, 1f, 12.34f, 1e12f, 1.23e + 12f, 1.23e12f, 1.87E- 7f. Użyj NaNf do pływania NaN (brak) wartość. Zakres pływaków wynosi w przybliżeniu + / -3.40282347E + 38f (~ 7 znaczących cyfr dziesiętnych) . Liczba, która wygląda jak float, ale jest nieprawidłowa (np. 1.0e39f) wygeneruje komunikat błędu.
podwójne
- podwójne wartości atrybutów (64- bit) musi być napisane przyrostkiem "d" i może mieć punkt dziesiętny i / lub wykładnik, np. 0d, 1d, 12.34d, 1e12d, 1.23e + 12d, 1.23e12d, 1.87E- 7d. d. Użyj NaNd do podwójnego NaN (brak) wartość. Zakres dubles jest w przybliżeniu + / -1.79769313486231570E + 308d (~ 15 znaczących cyfr dziesiętnych) . Numer, który wygląda jak podwójny ale jest niepoprawny (np. 1.0e309d) wygeneruje komunikat błędu.
String
- Wartości atrybutów String są sekwencją znaków UCS-2 (2-bajtowe znaki Unicode, jak wJava) , które muszą być zapisane jako 7- bit ASCII, JSON- jak ciągów tak, że znaki nie-ASCII mogą być określone.
- Podwójne cytaty (") musi być zakodowany jako dwa podwójne cytaty ("") . Tego wymagają programy arkuszy kalkulacyjnych podczas odczytu plików .csv. Tak piszą programy arkuszy kalkulacyjnych, gdy zapisujesz arkusz kalkulacyjny jako plik .csv.
- Specjalne znaki zakodowane przez JSON muszą być zakodowane jak w JSON (w szczególności\n(newline), ale także\\ (backslash),\ f (formfeed),\ t (tab),\ r (powóz return) lub z\ u hhhh Składnia. W arkuszu kalkulacyjnym nie używaj Alt Enter, aby określić nową linię w komórce tekstowej; zamiast tego użyj\n (2 znaki: backslash i 'n') by wskazać nową linię.
\uhhhh
- Wszystkie znaki mniejsze od znaku # 32 lub większe od znaku # 126 i nie zakodowane w inny sposób, muszą być kodowane z składnią\ u hhhh , gdzie hhhh jest czterocyfrową liczbą szesnastkową znaku, np. znakiem Euro jest\ u20AC. Zob. strony kodowe, o których mowa w https://en.wikipedia.org/wiki/Unicode znaleźć numery szesnastkowe związane z określonymi znakami Unicode lub używać biblioteki oprogramowania.
- Jeśli String ma miejsce na początku lub końcu, lub zawiera " (Podwójny cytat) lub przecinek, lub zawiera wartości, które w innym przypadku byłyby interpretowane jako jakiś inny typ danych (np. int) , lub jest słowo "null", cały String musi być dołączony do podwójnych cudzysłówek; w przeciwnym razie, w przeciwieństwie do JSON, dodatkowe podwójne cudzysłówka są opcjonalne. Polecamy: w razie wątpliwości, załączyć cały String w podwójnych cytaty. Przestrzenie na początku lub końcu struny są mocno zniechęcone.
- Na razie zniechęca się do używania znaków większych niż # 255. NCSSV je wspiera.ERDDAP™wspiera je wewnętrznie. Niektóre typy plików wyjściowych je obsługują (np.,.jsonoraz.nccsv) . Ale wiele typów plików wyjściowych ich nie obsługuje. Na przykład:NetCDF-3 pliki nie obsługują takich znaków, ponieważNetCDFpliki używają znaków 1- bajtowych, a CF obecnie nie posiada systemu określania, w jaki sposób znaki Unicode są kodowaneNetCDFStruny (np. UTF- 8) . To prawdopodobnie poprawi się z czasem.
char
- wartości atrybutów char są pojedynczym znakiem UCS-2 (2-bajtowe znaki Unicode, jak wJava) , które muszą być zapisane jako 7- bit ASCII, znaków JSON- jak tak, że inne znaki mogą być określone (zobacz powyższą definicję String dla kodowania znaków specjalnych, z dodatkiem kodowania pojedynczego cytatu jako\ ') . Wartości atrybutów Char muszą być zawarte w pojedynczych kwotowaniach (wewnętrzne kwotowania) i podwójne cytaty (zewnętrzne kwotowania) , np. "" a "" "" "" "" (znak podwójnego cytatu) ", '\" " (znak pojedynczego cytatu) ", '\ t'" (zakładka) ", '\ u20AC'" (znak euro) . Ten system stosowania pojedynczych i podwójnych cytatów jest dziwny i uciążliwy, ale jest to sposób na odróżnienie wartości znaków od Strings w sposób, który działa z arkuszy kalkulacyjnych. Wartość, która wygląda jak znak, ale jest nieprawidłowa, wygeneruje komunikat błędu. Podobnie jak w przypadku Strings, używanie znaków większych niż # 255 jest obecnie zniechęcane.
Suffix
Należy zauważyć, że w sekcji atrybutów pliku NCSSV wszystkie wartości atrybutów numerycznych muszą mieć literę przyrostową (np. 'b') identyfikacja typu danych liczbowych (np. bajt) . Ale w sekcji danych pliku NCSV, numeryczne wartości danych nie mogą mieć tych przyrostków. (z wyjątkiem "L" dla długich liczb całkowitych) - typ danych jest określony przez\*DANE\ _ TYP\*atrybut zmiennej.
DANE _ TYP
Typ danych dla każdegoskalarzmienna musi być określona przez\*DANE\ _ TYP\*atrybut, który może mieć wartość bajtów, krótkich, int, długich, pływaków, podwójnych, strun lub znaków (nieczuły przypadek) . Na przykład: qc\ _ flag,\DANE\ _ TYP\, bajt OSTRZEŻENIE: Określanie poprawności\*DANE\ _ TYP\*To twoja odpowiedzialność. Określanie niewłaściwego typu danych (np. int, kiedy powinieneś określić float) nie wygeneruje komunikatu błędu i może spowodować utratę informacji (np. wartości zmiennoprzecinkowe zostaną zaokrąglone do intów) kiedy plik NCSSV jest odczytywany przezERDDAP™lub przekształcone wNetCDFplik.
Char zniechęcony
Stosowanie wartości znaków jest zniechęcane, ponieważ nie są one szeroko obsługiwane w innych typach plików. wartości char można zapisać w sekcji danych jako pojedyncze znaki lub jako Strings (zwłaszcza, jeśli musisz napisać specjalny znak) . Jeśli zostanie znaleziony String, pierwszy znak String będzie użyty jako wartość znaku. Zero długości Strings i brakujące wartości zostaną zamienione na znak\ uING. Zauważ, żeNetCDFpliki obsługują tylko pojedyncze znaki bajtowe, więc każdy znak większy niż znak # 255 zostanie przekonwertowany na '?' podczas pisaniaNetCDFpliki. O ile atrybut charset nie jest używany do określenia innego zbioru znaków dla zmiennej znaków, zostanie użyty zestaw znaków ISO- 8859-1.
Długie zniechęcenie
Chociaż wiele typów plików (np.,NetCDF- 4 i Json) orazERDDAP™obsługuje długie wartości danych, stosowanie długich wartości danych w plikach NCSV jest obecnie zniechęcane, ponieważ nie są one obecnie wspierane przez Excel, CF iNetCDF-3 pliki. Jeśli chcesz podać długie wartości danych w pliku NCSV (lub w odpowiednim arkuszu kalkulacyjnym Excel) , musisz użyć przyrostka 'L' tak, aby Excel nie traktował liczb jako liczby zmiennoprzecinkowe z niższą precyzją. Obecnie, jeśli pliki NCSSV są konwertowane naNetCDF-3.ncplik, długie wartości danych zostaną przekształcone w podwójne wartości, powodując utratę precyzji dla bardzo dużych wartości (mniej niż -2 ^ 53 lub więcej niż 2 ^ 53) .
CF, ACDD orazERDDAP™Metadane
Ponieważ jest przewidziane, że większość plików NCSSV, lub.ncpliki utworzone z nich, będą odczytywaneERDDAP, zdecydowanie zaleca się, aby pliki NCCSV zawierały atrybuty metadanych, które są wymagane lub zalecane przezERDDAP™(patrz / docs / server- admin / datasets # global- attributes). Atrybuty są prawie wszystkie ze standardów metadanych CF i ACDD i służą do właściwego opisu zbioru danych (Kto, co, kiedy, gdzie, dlaczego, jak) komuś, kto inaczej nic nie wie o zbiorze danych. Niemal wszystkie zmienne liczbowe powinny mieć atrybut jednostek zUDUNITS-wartość kompatybilna, np., sst, jednostki, stopień\ _ C
W porządku jest włączenie dodatkowych atrybutów, które nie pochodzą ze standardów CF lub ACDD lub zERDDAP.
Sekcja danych
Struktura
Pierwsza linia sekcji danych musi mieć listę nazw zmiennych oddzieloną od sprawy. Wszystkie zmienne z tej listy muszą być opisane w sekcji metadanych i odwrotnie (inne niż\GLOBAL\atrybuty oraz\SKALAR\zmienne) .
Drugi przez przedostatnią linię sekcji danych musi posiadać oddzielną od comma- listę wartości. Każdy wiersz danych musi mieć taką samą liczbę wartości jak oddzielona comma- lista nazw zmiennych. Spacje przed lub po wartości nie są dozwolone, ponieważ powodują problemy przy importowaniu pliku do programów arkusza kalkulacyjnego. Każda kolumna w tej sekcji musi zawierać tylko wartości\*DANE\ _ TYP\*określone dla tej zmiennej przez\*DANE\ _ TYP\*atrybut tej zmiennej. W przeciwieństwie do sekcji atrybutów, wartości numeryczne w sekcji danych nie mogą zawierać liter przyrostowych oznaczających typ danych. W przeciwieństwie do sekcji atrybutów, wartości znaków w sekcji danych mogą pomijać dodatkowe pojedyncze kwotowania, jeśli nie są one potrzebne do dyskryminacji (tak więc ",", "i"\ "muszą być cytowane jak pokazano tutaj) . W pliku NCSSV może być jakaś liczba tych wierszy danych, ale obecnieERDDAP™można odczytać tylko pliki NCSSV z do około 2 miliardów wierszy. Ogólnie rzecz biorąc, zaleca się podzielenie dużych zbiorów danych na wiele plików NCSV zawierających mniej niż milion wierszy.
Dane końcowe
Koniec sekcji danych musi być oznaczony tylko linią \ZAKOŃCZENIE\ _ DANE\
Jeśli w pliku NCSV znajduje się dodatkowa zawartość\*ZAKOŃCZENIE\ _ DANE\*linia, zostanie zignorowana, gdy plik NCCSV zostanie przekształcony w.ncplik. Taka treść jest zatem zniechęcana.
W arkuszu kalkulacyjnym po tych konwencjach nazwy zmiennych i wartości danych będą w wielu kolumnach. Patrz przykład poniżej.
Brak wartości
Brak wartości numerycznych może być zapisany jako wartość numeryczna określona przezmissing\_valuelub atrybut\ _ FillValue dla tej zmiennej. Na przykład patrz druga wartość w tym wierszu danych: Bell M. Shimada, 99,123.4 Jest to zalecany sposób obsługi brakujących wartości dla zmiennych bajtowych, krótkich, int i długich.
wartości zmiennoprzecinkowe lub podwójne NaN można zapisać jako NaN. Na przykład patrz druga wartość w tym wierszu danych: Bell M. Shimada, NaN, 123.4
Brakujące wartości strun i numeryczne mogą być wskazywane przez puste pole. Na przykład patrz druga wartość w tym wierszu danych: Bell M. Shimada, ,123.4
Dla zmiennych bajtowych, krótkich, int i długich, narzędzie konwertera NCSV orazERDDAP™przekształca puste pole w maksymalną dopuszczalną wartość dla danego typu danych (np. 127 dla bajtów) . Jeśli to zrobisz, musisz dodaćmissing\_valuelub atrybut\ _ FillValue dla tej zmiennej do identyfikacji tej wartości, np., zmienna Nazwa ,\ _ FillValue, 127b Dla zmiennych float i podwójnych puste pole zostanie przekonwertowane na NaN.
Wartości DateTime
Wartości DateTime (w tym wartości daty, które nie mają komponentu czasu) mogą być reprezentowane jako numery lub jako Strings w plikach NCSV. Podana zmienna dateTime może mieć tylko wartości String lub tylko wartości numeryczne, nie oba. Oprogramowanie NCCSV przekonwertuje wartości String dateTime na datę numeryczną Wartości czasu podczas tworzenia.ncpliki (zgodnie z wymogami CF) . String dateTime wartości mają tę zaletę, że są łatwo czytelne przez ludzi.
Wartości DateTime reprezentowane jako wartości liczbowe muszą posiadać atrybut jednostek określający " jednostki od data Czas "zgodnie z wymaganiami CF i określonymi przezUDUNITS, np., czas, jednostki, sekundy od 1970- 01-01T00: 00: 00Z
Wartości DateTime reprezentowane jako wartości String muszą mieć String\*DANE\ _ TYP\*atrybut i atrybut jednostek określający datę Schemat czasowy określony przezJavaKlasa DateTimeFormatter ( https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html ) . Na przykład: czas, jednostki,yyyy-MM-ddNie. Wszystkie wartości dateTime dla danej zmiennej danych muszą używać tego samego formatu. W większości przypadków, schemat dateTime potrzebny dla atrybutu jednostek będzie zmiennością jednego z tych formatów:
- yyyy-MM-ddNie. SSZ - czyli ISO 8601: 2004 (E) data Format czasowy. Może być potrzebna skrócona wersja, np.:yyyy-MM-ddNie. (jedyny zalecany format) lubyyyy-MM-dd. Jeśli zmieniasz format swoich wartości dateTime, NCSSV zdecydowanie zaleca, aby zmienić ten format (być może skrócony) . To jest format, któryERDDAP™będzie używać podczas pisania plików NCSV.
- yyyMddHHmms.SSS - która jest zwarta w wersji ISO 8601: 2004 Format czasowy. Możesz potrzebować skróconej wersji tego, np. yyyyMMdd.
- M / d / rrrr H: mm: ss. SSS - który obsługuje daty i daty w stylu US- Times jak "3 / 23 / 2017 16: 22: 03.000". Może być potrzebna skrócona wersja, np. M / d / rrrr.
- yyyyDDHHmmssSSS - który jest rokiem powiększonym o zerowy dzień roku (np., 001 = 1 stycznia, 365 = 31 grudnia w roku bez skoku; jest to czasami błędnie nazywane datą Juliana) . Możesz potrzebować skróconej wersji tego, np. yyyydDD.
Precyzja
Kiedy biblioteka oprogramowania konwertuje.ncplik do pliku NCSV, wszystkie daty Wartości czasowe zostaną zapisane jako Strings z ISO 8601: 2004 (E) data Format czasowy, np. 1970- 01-01T00: 00: 00Z. Możesz kontrolować precyzję zERDDAP-specyficzny atrybuttime\_precision. Patrz / docs / server- admin / datasets #time\_precision.
Strefa czasowa
Domyślna strefa czasowa dla daty Wartość czasu jestZulu (lub GMT) strefa czasowa, która nie ma okresów dziennych. Jeśli zmienna dateTime posiada wartości dateTime z innej strefy czasowej, należy to określić za pomocąERDDAP-specyficzny atrybuttime\_zone. Jest to wymógERDDAP™(patrz / docs / server- admin / datasets #time\_zone).
Wartości stopnia
Zgodnie z wymogami CF, wszystkie wartości stopnia (np. dla długości i szerokości geograficznej) muszą być określone jako podwójne wartości stopnia decymalowego, nie jako stopień ° min 'sec "String lub jako oddzielne zmienne dla stopni, minut, sekund. Kierunkowskazy N, S, E i W nie są dozwolone. Użyj wartości ujemnych dla zachodnich i południowych szerokości geograficznych.
DSG Rodzaje cech
Plik NCSSV może zawierać geometrię pobierania próbek dyskretnych CF ( https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html#discrete-sampling-geometries ) dane. To atrybuty sprawiają, że to działa:
- Zgodnie z wymaganiami CF plik NCCSV musi zawierać wiersz w sekcji metadanych określającej\GLOBAL\ featureTypeatrybut, np., \GLOBAL\,featureType, trajektoria
- Do stosowania wERDDAP™, plik NCCSV musi zawierać wiersz lub wiersze w sekcji metadanych określającej zmienne cf\ _ role =...\ _ id, np., statek, cf\ _ rola, trajektoria\ _ id Jest to opcjonalne dla CF, ale wymagane w NCSSV.
- Do stosowania wERDDAP™, plik NCCSV musi zawierać linię lub linie w sekcji metadanych określającej, które zmienne są związane z każdym timeSeries, trajektorii lub profilu zgodnie z wymaganiamiERDDAP™(patrz / docs / server- admin / datasets # cdm\ _ data\ _ type), np., \GLOBAL\, cdm\ _ trajektoria\ _ zmienne, "statek" lub \GLOBAL\, cdm\ _ timeseries\ _ variables, "station\ _ id, lat, lon"
Plik próbki
Oto przykładowy plik, który pokazuje wiele cech pliku NCSSV:
\\*GLOBAL\\*,Conventions,"COARDS, CF-1.6, ACDD-1.3, NCCSV-1.0"
\\*GLOBAL\\*,cdm\\_trajectory\\_variables,"ship"
\\*GLOBAL\\*,creator\\_email,erd.data@noaa.gov
\\*GLOBAL\\*,creator\\_name,Bob Simons
\\*GLOBAL\\*,creator\\_type,person
\\*GLOBAL\\*,creator\\_url,https://www.pfeg.noaa.gov
\\*GLOBAL\\*,featureType,trajectory
\\*GLOBAL\\*,infoUrl,https://erddap.github.io/docs/user/nccsv-1.00
\\*GLOBAL\\*,institution,"NOAA NMFS SWFSC ERD, NOAA PMEL"
\\*GLOBAL\\*,license,"""NCCSV Demonstration"" by Bob Simons and Steve Hankin is
licensed under CC BY 4.0, https://creativecommons.org/licenses/by/4.0/ ."
\\*GLOBAL\\*,keywords,"NOAA, sea, ship, sst, surface, temperature, trajectory"
\\*GLOBAL\\*,standard\\_name\\_vocabulary,CF Standard Name Table v55
\\*GLOBAL\\*,subsetVariables,"ship"
\\*GLOBAL\\*,summary,"This is a paragraph or two describing the dataset."
\\*GLOBAL\\*,title,"NCCSV Demonstration"
ship,\\*DATA\\_TYPE\\*,String
ship,cf\\_role,trajectory\\_id
time,\\*DATA\\_TYPE\\*,String
time,standard\\_name,time
time,units,"yyyy-MM-dd'T'HH:mm:ssZ"
lat,\\*DATA\\_TYPE\\*,double
lat,units,degrees\\_north
lon,\\*DATA\\_TYPE\\*,double
"lon","units","degrees\\_east"
status,\\*DATA\\_TYPE\\*,char
status,comment,"From http://some.url.gov/someProjectDocument , Table C"
testLong,\\*DATA\\_TYPE\\*,long
testLong,units,1
sst,\\*DATA\\_TYPE\\*,float
sst,standard\\_name,sea\\_surface\\_temperature
sst,actual\\_range,0.17f,23.58f
sst,units,degree\\_C
sst,missing\\_value,99f
sst,testBytes,-128b,0b,127b
sst,testShorts,-32768s,0s,32767s
sst,testInts,-2147483648i,0i,2147483647i
sst,testLongs,-9223372036854775808L,0L,9223372036854775807L
sst,testFloats,-3.40282347e38f,0f,3.40282347E+38f
sst,testDoubles,-1.79769313486231570e308d,0d,1.79769313486231570E+308d
sst,testChars,"','","'""'","'\\u20AC'"
sst,testStrings," a~,\\n'z""\\u20AC"
\\*END\\_METADATA\\*
ship,time,lat,lon,status,testLong,sst
Bell M. Shimada,2017-03-23T00:45:00Z,28.0002,-130.2576,A,-9223372036854775808L,10.9
Bell M. Shimada,2017-03-23T01:45:00Z,28.0003,-130.3472,\\u20AC,-1234567890123456L,
"Bell M. Shimada","2017-03-23T02:45:00Z",28.0001,-130.4305,"'\\t'",0L,10.7
Bell M. Shimada,2017-03-23T12:45:00Z,27.9998,-131.5578,"'""'",1234567890123456L,99
Bell M. Shimada,2017-03-23T21:45:00Z,28.0003,-132.0014,\\u00fc,9223372036854775806L,10.0
Bell M. Shimada,2017-03-23T23:45:00Z,28.0002,-132.1591,,NaN
Uwagi:
- Ten plik zawiera wiele trudnych przypadków (np. Charr i długie zmienne i trudne wartości String) . Większość plików NCSSV będzie znacznie prostsza.
- Linia licencyjna jest podzielona na dwie, ale jest tylko jedną linią w pliku próbnym.
- \ u20AC jest kodowaniem znaku euro, a\ u00FC jest kodowaniem uU.
- Wiele Fragmenty w przykładzie są zawarte w podwójnych kwotowaniach, nawet jeśli nie muszą być, np., wieloma atrybutami globalnymi, w tym tytułem, atrybutem jednostek lonu i trzecią linią danych.)
- Byłoby jaśniej i lepiej, gdyby atrybut jednostek dla zmiennej testLong został zapisany w podwójnych kwotowaniach wskazujących, że jest to wartość String. Ale obecna reprezentacja (1, bez notowań) będzie poprawnie interpretowany jako String, nie jako integer, ponieważ nie ma przyrostka 'i'.
- W przeciwieństwie do innych typów danych liczbowych, długie wartości w sekcji danych mają przyrostek ('L') które identyfikują ich typ danych liczbowych. Jest to wymagane, aby zapobiec interpretacji arkuszy kalkulacyjnych wartości jako liczby zmiennoprzecinkowe i tym samym utraty precyzji.
Arkusze kalkulacyjne
W arkuszu kalkulacyjnym, jak w pliku NCSSV:
- Zapisz wartości atrybutów numerycznych określone dla plików NCSV (np. z literą przyrostową, np. 'f', w celu identyfikacji typu danych atrybutu) .
- W Strings, napisz wszystkie znaki mniejsze niż ASCII znak # 32 lub większe niż znak # 126 jako albo JSON- jak odwrotny znak (np.,\ndla nowej linii) lub jako szesnastkowy numer znaków Unicode (nieczuły przypadek) z składnią\ u hhhh (np.\ u20AC dla znaku Euro) . Stosowanie\n (2 znaki: backslash i 'n') aby wskazać nową linię, a nie Alt Enter.
Jedyne różnice pomiędzy plikami NCSSV a analogicznym arkuszem kalkulacyjnym, które są następujące po tych konwencjach, to:
- Pliki NCSSV mają wartości na linii oddzielonej przecinkami. Arkusze kalkulacyjne mają wartości na linii w sąsiadujących komórkach.
- Fragmenty w plikach NCSV są często otoczone podwójnymi cytatami. Struny w arkuszach kalkulacyjnych nigdy nie są otoczone podwójnymi cytatami.
- Wewnętrzne podwójne kwotowania (") w Strings w plikach NCSSV pojawiają się jako 2 podwójne cytaty. Wewnętrzne podwójne cytaty w arkuszach kalkulacyjnych pojawiają się jako 1 podwójny cytat.
Jeśli arkusz kalkulacyjny następujący po tych konwencjach jest zapisywany jako plik CSV, często będą dodatkowe przecinki na końcu wielu linii. Oprogramowanie, które konwertuje pliki NCSSV do.ncpliki zignorują dodatkowe przecinki.
Excel
Aby zaimportować plik NCCSV do Excel:
- Wybierz plik: Otwórz.
- Zmień typ pliku na pliki tekstowe (\.prn;\.txt;\ * .csv) .
- Szukaj katalogów i kliknij na plik NCSSV .csv.
- Kliknij Otwórz.
Aby utworzyć plik NCCSV z arkusza kalkulacyjnego Excel:
- Wybierz plik: Zapisz jako.
- Zmień zapis jako typ: do CSV (Wyznaczony przecinek) (\ * .csv) .
- W odpowiedzi na ostrzeżenie o zgodności kliknij przycisk Tak.
- Powstały plik .csv będzie miał dodatkowe przecinki na końcu wszystkich wierszy innych niż wiersze CSV. Możesz ich zignorować.
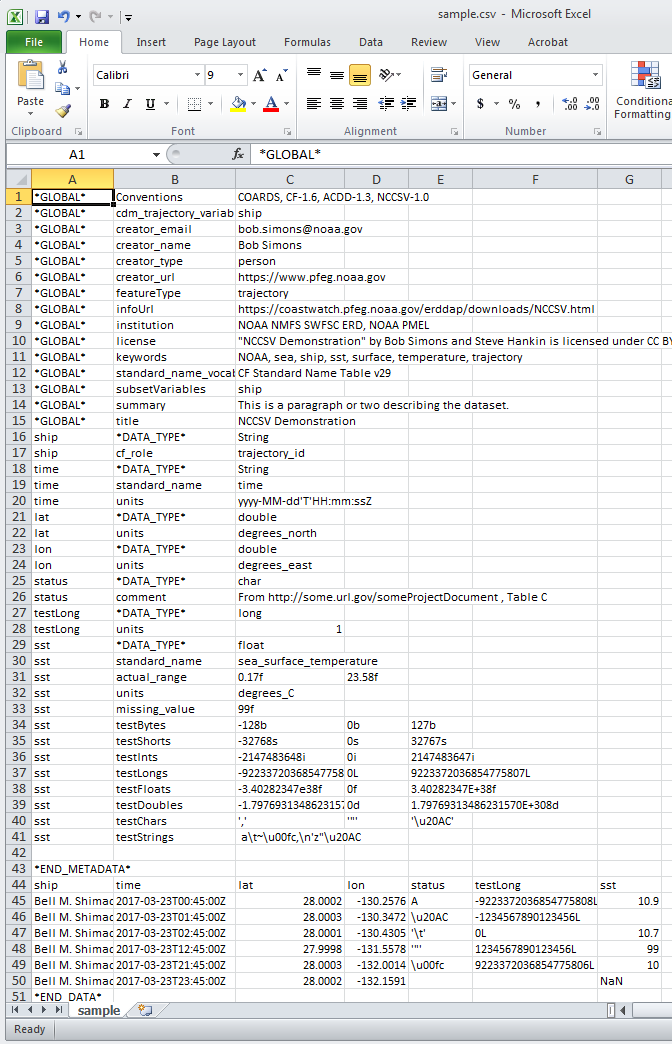
W Excel, próbka pliku NCSSV powyżej pojawia się jako
Arkusze Google
Zaimportowanie pliku NCSV do arkuszy Google:
- Wybierz plik: Otwórz.
- Wybierz, aby przesłać plik i kliknij na Wyślij plik z komputera. Wybierz plik, a następnie kliknij Otwórz.
Albo wybierz mój dysk i zmień typ rozwijanego pliku na wszystkie typy plików. Wybierz plik, a następnie kliknij Otwórz.
Aby utworzyć plik NCCSV z arkusza kalkulacyjnego Google:
- Wybierz plik: Zapisz jako.
- Zmień zapis jako typ: do CSV (Wyznaczony przecinek) (\ * .csv) .
- W odpowiedzi na ostrzeżenie o zgodności kliknij przycisk Tak.
- Powstały plik .csv będzie miał dodatkowe przecinki na końcu wszystkich wierszy innych niż wiersze CSV. Ignoruj ich.
Problemy / ostrzeżenia
- Jeśli utworzysz plik NCSSV z edytorem tekstu lub jeśli utworzysz analogiczny arkusz kalkulacyjny w programie arkusza kalkulacyjnego, edytor tekstowy lub program arkusza kalkulacyjnego nie sprawdzi, czy postępujesz zgodnie z tymi konwencjami prawidłowo. Od was zależy prawidłowe przestrzeganie tych konwencji.
- Konwersja arkusza kalkulacyjnego po tej konwencji do pliku csv (więc plik NCSSV) będzie prowadzić do dodatkowych przecinków na końcu wszystkich wierszy innych niż wiersze danych CSV. Ignoruj ich. Oprogramowanie konwertuje pliki NCSSV do.ncPliki ich zignorują.
- Jeśli plik NCCSV ma nadmiar przecinków na końcu wiersza, można je usunąć poprzez konwersję pliku NCSV wNetCDFplik, a następnie przekształcenieNetCDFz powrotem do pliku NCSV.
- Kiedy próbujesz przekształcić plik NCSSV wNetCDFplik, niektóre błędy zostaną wykryte przez oprogramowanie i wygenerują komunikaty błędów, powodując niepowodzenie konwersji. Inne problemy są trudne lub niemożliwe do złapania i nie generują komunikatów błędów lub ostrzeżeń. Inne problemy (np. nadmiar przecinków na końcu wiersza) zostaną zignorowane. Konwerter plików będzie tylko minimalne sprawdzenie poprawności wynikającychNetCDFdokumentację, np. w odniesieniu do zgodności CF. Zadaniem twórcy i użytkownika plików jest sprawdzenie, czy wyniki konwersji są tak pożądane i prawidłowe. Dwa sposoby sprawdzenia to:
- Drukuj zawartość.ncplik z ncdump ( https://linux.die.net/man/1/ncdump ) .
- Wyświetl zawartość danych wERDDAP.