NCCSV -
ANetCDF- Compatibele ASCII CSV Bestandsspecificatie, Versie 1.00
Bob Simons en Steve Hankin "NCCSV" door Bob Simons en Steve Hankin is gelicentieerd onderCC BY 4.0
Inleiding
Dit document specificeert een ASCII CSV-tekstbestandsformaat dat alle informatie kan bevatten (metagegevens en gegevens) dat kan worden gevonden in eenNetCDF .ncbestand dat een CSV-bestand-achtige tabel van gegevens bevat. De bestandsextensie voor een ASCII CSV tekstbestand na deze specificatie moet .csv, zodat het gemakkelijk en correct kan worden gelezen in spreadsheet programma's zoals Excel en Google Sheets. Bob Simons zal software schrijven om een NCCSV-bestand te converteren naar eenNetCDF-3 (en misschien ook eenNetCDF-4) .ncbestand, en omgekeerd, zonder verlies van informatie. Bob Simons heeft zich aangepast.ERDDAP™om het lezen en schrijven van dit type bestand te ondersteunen.
Het NCCSV-formaat is zo ontworpen dat spreadsheetsoftware zoals Excel en Google Sheets een NCCSV-bestand kunnen importeren als een csv-bestand, met alle informatie in de cellen van de spreadsheet klaar om te bewerken. Of, een spreadsheet kan vanaf nul worden gemaakt na de NCCSV conventies. Ongeacht de bron van het spreadsheet, als het dan wordt geëxporteerd als een .csv bestand, zal het voldoen aan de NCCSV specificatie en geen informatie verloren gaan. De enige verschillen tussen NCCSV-bestanden en de analoge spreadsheetbestanden die deze conventies volgen zijn:
- NCCSV-bestanden hebben waarden op een lijn gescheiden door komma's. Spreadsheets hebben waarden op een regel in aangrenzende cellen.
- Strings in NCCSV-bestanden worden vaak omgeven door dubbele citaten. Strings in spreadsheets worden nooit omringd door dubbele citaten.
- Interne dubbele citaten (") in Strings in NCCSV-bestanden verschijnen als 2 dubbele citaten. Interne dubbele citaten in spreadsheets verschijnen als 1 dubbele quote.
ZieSpreadsheethieronder voor meer informatie.
Stroombaar
Net als CSV-bestanden in het algemeen, NCCSV-bestanden zijn streamable. Dus als een NCSV on-the-fly wordt gegenereerd door een dataserver zoalsERDDAP™, kan de server beginnen met het streamen van gegevens naar de aanvrager voordat alle gegevens zijn verzameld. Dit is een nuttige en wenselijke eigenschap.NetCDFbestanden zijn daarentegen niet streamable.
ERDDAP™
Deze specificatie is zo ontworpen dat NCCSV bestanden en de.ncbestanden die kunnen worden gemaakt van hen kan worden gebruikt door eenERDDAP™dataserver (via deEDDtabelVanNccsvFilesenEDDtabelVanNcFilesdatasets) , maar deze specificatie is buitenERDDAP.ERDDAP™heeft verschillende vereiste globale attributen en vele aanbevolen globale en variabele attributen, meestal gebaseerd op CF en ACDD attributen (zie /docs/server-admin/datasets#global-attributes).
Saldo
Het ontwerp van het NCCSV-formaat is een evenwicht tussen verschillende eisen:
- De bestanden moeten alle gegevens en metagegevens bevatten die in een tabel zouden staanNetCDFbestand, met inbegrip van specifieke gegevenstypes.
- De bestanden moeten kunnen worden ingelezen en vervolgens uit een spreadsheet worden geschreven zonder verlies van informatie.
- De bestanden moeten gemakkelijk zijn voor mensen om te maken, bewerken, lezen en begrijpen.
- De bestanden moeten ondubbelzinnig door computerprogramma's kunnen worden ontleed.
Als een bepaalde eis in dit document vreemd of kieskeurig lijkt, is het waarschijnlijk nodig om aan een van deze eisen te voldoen.
Andere specificaties
Deze specificatie verwijst naar verschillende andere specificaties en bibliotheken waarmee het is ontworpen om mee te werken, maar deze specificatie maakt geen deel uit van een van die andere specificaties, noch heeft het wijzigingen nodig, noch is het in strijd met hen. Als een detail met betrekking tot een van deze normen hier niet wordt gespecificeerd, zie de bijbehorende specificatie. Dit omvat met name:
- Het Attribuutverdrag voor de ontdekking van gegevens (ACDD) Metadatastandaard: https://wiki.esipfed.org/Attribute\_Convention\_for\_Data\_Discovery\_1-3 .
- Klimaat en prognose (CF) Metadatastandaard: https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html .
- DeNetCDFHandleiding (NUG) : https://docs.unidata.ucar.edu/netcdf-java/current/userguide/index.html .
- DeNetCDFsoftwarebibliotheken zoalsNetCDF- Java enNetCDF-c: https://www.unidata.ucar.edu/software/netcdf/ . Deze bibliotheken kunnen NCCSV-bestanden niet lezen, maar ze kunnen wel lezen.ncbestanden gemaakt van NCCSV-bestanden.
- JSON: https://www.json.org/
Notatie
In deze specificatie, haakjes,\[ \], aangeven optionele items.
Bestandsstructuur
Een compleet NCCSV-bestand bestaat uit twee secties: de metadata sectie, gevolgd door de data sectie.
NCCSV-bestanden moeten slechts 7-bit ASCII-tekens bevatten. Hierdoor kan de tekenset of codering die gebruikt wordt om het bestand te schrijven en te lezen elke tekenset of codering zijn die compatibel is met de 7-bit ASCII-tekenset, bijvoorbeeld ISO-8859-1.ERDDAP™leest en schrijft NCCSV bestanden met de ISO-8859-1 tekenset.
NCCSV-bestanden kunnen een nieuwe regel gebruiken (\n) (wat gebruikelijk is op Linux en Mac OS X computers) of vervoerTerugkeer plus nieuwe lijn (\r\n) (wat gebruikelijk is op Windows computers) als end-of-line markers, maar niet beide.
.nccsvMetadata
Wanneer zowel de maker als de lezer verwachten, is het ook mogelijk en soms nuttig om een variant van een NCCSV-bestand dat alleen de metagegevens sectie bevat te maken (waaronder de\*END\_METADATA\*regel) . Het resultaat geeft een volledige beschrijving van de eigenschappen van het bestand, variabele namen en data types, dus dienend hetzelfde doel als de .das plus .dds antwoorden van eenOPeNDAPserver.ERDDAP™geeft deze variatie terug als u een bestand aanvraagt Type=.nccsvMetadata van eenERDDAP™dataset.
De sectie Metagegevens
In een NCCSV-bestand gebruikt elke regel van de metadata sectie het formaat
variabele Naam,eigenschap Naam,waarde1\[,waarde2\]\[,waarde3\]\[,waarde4\]\[...\]
Ruimten voor of na items zijn niet toegestaan omdat ze problemen veroorzaken bij het importeren van het bestand in spreadsheet programma's.
Overeenkomsten
De eerste regel van een NCCSV bestand is de eerste regel van de metagegevens sectie en moet een\GLOBAL\Conventions attribuut een lijst van alle conventies die in het bestand worden gebruikt als een tekenreeks die een CSV-lijst bevat, bijvoorbeeld: \GLOBAL\,Conventies,"COARDS, CF-1.6, ACDD-1.3, NCCSV-1.0" Een van de genoemde verdragen moet NCCSV-1.0 zijn, dat verwijst naar de huidige versie van deze specificatie.
END_METADATA
Het einde van de metagegevens sectie van een NCCSV bestand moet worden aangeduid met een regel met alleen \END\_METADATA\
Het wordt aanbevolen maar niet vereist dat alle attributen voor een bepaalde variabele verschijnen op aangrenzende lijnen van de metagegevens sectie. Als een NCCSV-bestand wordt omgezet in eenNetCDFbestand, de volgorde die de variabeleNames eerst in de metadata sectie zal de volgorde van de variabelen in deNetCDFbestand.
Optionele lege regels zijn toegestaan in de metagegevens sectie na de vereiste eerste regel met\GLOBAL\ Overeenkomsteninformatie (zie hieronder) en vóór de vereiste laatste regel met\END\_METADATA\.
Als een spreadsheet wordt aangemaakt uit een NCCSV-bestand, zal de metadata data sectie verschijnen met variabele namen in kolom A, attribuutnamen in kolom B en waarden in kolom C.
Als een spreadsheet na deze conventies wordt opgeslagen als een CSV-bestand, zullen er vaak extra komma's zijn aan het einde van de regels in de metadata sectie. De software die NCCSV bestanden converteert in.ncbestanden zullen de extra komma's negeren.
variabele Naam
variabele Naam is de hoofdlettergevoelige naam van een variabele in het gegevensbestand. Alle variabele namen moeten beginnen met een 7-bit ASCII letter of underscore en bestaan uit 7-bit ASCII letters, underscores en 7-bit ASCII cijfers.
GLOBAL
De speciale variabeleNaam\GLOBAL\wordt gebruikt om globale metagegevens aan te duiden.
eigenschap Naam
eigenschap Naam de hoofdlettergevoelige naam is van een attribuut dat is gekoppeld aan een variabele of\GLOBAL\. Alle attribuutnamen moeten beginnen met een 7-bit ASCII letter of underscore en bestaan uit 7-bit ASCII letters, underscores en 7-bit ASCII cijfers.
SCALAR
Het speciale kenmerk Naam\*SCALAR\*kan worden gebruikt om een schaalgegevens variabele te maken en de waarde ervan te definiëren. Het gegevenstype van de\*SCALAR\*definieert het gegevenstype voor de variabele, dus geen een\*GEGEVENS\_TYPE\*eigenschap voor scalaire variabelen. Merk op dat er geen gegevens mogen zijn voor de scalar variabele in de Data Section van het NCCSV bestand.
Om bijvoorbeeld een scalar variabele genaamd "ship" aan te maken met de waarde "Okeanos Explorer" en een cf\_role attribuut, gebruik: schip,\SCALAR\,"Okeanos Explorer" ship,cf\_role,trajectory\_id Wanneer een schaalgegevensvariabele wordt ingelezenERDDAP™, de schaalwaarde wordt omgezet in een kolom in de gegevenstabel met dezelfde waarde op elke rij.
waarde
waarde is de waarde van het metadataattribuut en moet een array zijn met een of meer van een byte, short, int, long, float, double, string of char. Geen andere gegevenstypes worden ondersteund. Attributen zonder waarde worden genegeerd. Als er meer dan één subwaarde is, moeten de subwaarden allemaal van hetzelfde gegevenstype zijn en gescheiden worden door komma's, bijvoorbeeld: sst,actual\_range0,17f, 23,58f Als er meerdere tekenreekswaarden zijn, gebruik dan één tekenreeks met\n (nieuwe regel) tekens die de subtekenreeks scheiden.
De definities van de typen attribuutgegevens zijn:
byte
- byte-attribuutwaarden (8-bit, ondertekend) moet worden geschreven met het achtervoegsel 'b', bijvoorbeeld -7b, 0b, 7b . Het bereik van geldige bytewaarden is -128 tot 127. Een getal dat lijkt op een byte maar ongeldig is (bv. 128b) zal een foutmelding genereren.
kort
- korte attribuutwaarden (16-bit, ondertekend) moet worden geschreven met het achtervoegsel 's', bijvoorbeeld -30000s, 0s, 30000s. Het bereik van geldige korte waarden is -32768 tot 32767. Een getal dat lijkt op een korte maar ongeldig is (bv. 32768s) zal een foutmelding genereren.
int
- int-attribuutwaarden (32-bit, ondertekend) moet worden geschreven als JSON ints zonder een decimaal of exponent, maar met het achtervoegsel 'i', bijvoorbeeld -12067978i, 0i, 12067978i. Het bereik van geldige int waarden is -2147483648 tot 2147483647. Een getal dat lijkt op een int maar ongeldig is (bv. 2147483648i) zal een foutmelding genereren.
lang
- long attribuutwaarden (64-bit, ondertekend, momenteel ondersteund door NUG enERDDAP™maar nog niet ondersteund door CF) moet worden geschreven zonder decimaal en met het achtervoegsel "L," bv. -12345678987654321L, 0L, 12345678987654321L. Als u de conversiesoftware gebruikt om een NCCSV-bestand met lange waarden om te zetten in eenNetCDF-3 bestand, alle lange waarden worden omgezet in dubbele waarden. Het bereik van geldige lange waarden is -9223372036854775808 tot 9223372036854775807. Een getal dat eruit ziet als een lang maar ongeldig is (bv. 9223372036854775808L) zal een foutmelding genereren.
drijvend
- floatattribuutwaarden (32-bit) moet worden geschreven met het achtervoegsel 'f' en mag een decimaal en/of een exponent hebben, bijvoorbeeld 0f, 1f, 12.34f, 1e12f, 1.23e+12f, 1.23e12f, 1.87E-7f. Gebruik NaNf voor een float NaN (ontbrekend) waarde. Het bereik van praalwagens is ongeveer +/-3.40282347E+38f (~7 significante decimale cijfers) . Een getal dat lijkt op een float maar ongeldig is (bijv. 1,0e39f) zal een foutmelding genereren.
dubbel
- dubbele attribuutwaarden (64-bit) moet worden geschreven met het achtervoegsel 'd' en mag een decimaal en/of een exponent hebben, bijvoorbeeld, 0d, 1d, 12.34d, 1e12d, 1.23e+12d, 1.23e12d, 1.87E-7d. Gebruik NaNd voor een dubbele NaN (ontbrekend) waarde. Het bereik van doubles is ongeveer +/-1.79769313486231570E+308d (~15 significante decimale cijfers) . Een getal dat eruit ziet als een dubbel maar ongeldig is (bijv. 1,0e309d) zal een foutmelding genereren.
Tekenreeks
- String attribuutwaarden zijn een reeks van UCS-2 tekens (d.w.z. 2-byte Unicode tekens, zoals inJava) , die moeten worden geschreven als 7-bit ASCII, JSON-achtige strings zodat niet-ASCII-tekens kunnen worden opgegeven.
- Dubbele citaten (") moet worden gecodeerd als twee dubbele aanhalingstekens ("") . Dat is wat spreadsheet programma's vereisen bij het lezen van .csv bestanden. Dat is wat spreadsheet programma's schrijven als je een spreadsheet opslaat als een .csv bestand.
- De speciale JSON backslash-gecodeerde tekens moeten worden gecodeerd zoals in JSON (met name\n(nieuwe regel), maar ook \\ (backslash), \f (formfeed), \t (tab), \r (carriage return) of met de\u Hhhh syntaxis. Gebruik in een spreadsheet Alt Enter niet om een nieuwe regel binnen een tekstcel op te geven; gebruik in plaats daarvan\n (2 tekens: backslash en 'n ') om een nieuwe regel aan te geven.
\uhhhh
- Alle tekens minder dan teken #32 of groter dan teken #126, en niet anders gecodeerd, moet worden gecodeerd met de syntax \u Hhhh , waarbij hhhh het viercijferige hexadecimaal getal van het teken is, bijvoorbeeld, het Euroteken is \u20AC. Zie de referentiepagina's https://en.wikipedia.org/wiki/Unicode het vinden van hexadecimale getallen in verband met specifieke Unicode tekens, of het gebruik van een softwarebibliotheek.
- Als de tekenreeks een spatie heeft aan het begin of het einde, of " (dubbel citaat) of een komma, of bevat waarden die anders zouden worden geïnterpreteerd als een ander gegevenstype (bv. een int) , of is het woord "null," de gehele tekenreeks moet worden ingesloten in dubbele aanhalingstekens; anders, in tegenstelling tot JSON, de bijvoegende dubbele aanhalingstekens zijn facultatief. Wij raden aan: bij twijfel, sluit de gehele String in dubbele citaten. Ruimten aan het begin of het einde van een tekenreeks worden sterk ontmoedigd.
- Voorlopig wordt het gebruik van tekens groter dan #255 ontmoedigd. NCCSV steunt hen.ERDDAP™ondersteunt ze intern. Sommige uitvoer bestandstypen ondersteunen hen (bv..jsonen.nccsv) . Maar veel uitvoer bestandstypen ondersteunen ze niet. Bijvoorbeeld,NetCDF-3 bestanden ondersteunen dergelijke tekens niet omdatNetCDFbestanden gebruiken 1-byte tekens en CF heeft momenteel geen systeem om aan te geven hoe Unicode tekens gecodeerd zijn inNetCDFTekenreeks (bv. UTF-8) . Dit zal waarschijnlijk in de loop van de tijd verbeteren.
char
- tekenattribuutwaarden zijn een enkel UCS-2 teken (d.w.z. 2-byte Unicode tekens, zoals inJava) , die moet worden geschreven als 7-bit ASCII, JSON-achtige tekens zodat andere tekens kunnen worden gespecificeerd (zie de tekenreeks definitie hierboven voor het coderen van speciale tekens, met de toevoeging van een enkele quote als \ ') . Char-attribuutwaarden moeten in enkele aanhalingstekens worden opgenomen (de innerlijke citaten) en dubbele citaten (de buitenste citaten) , bv. "'a'," "'""" (een dubbel aanhalingsteken) , "'\'" (een enkel aanhalingsteken) , "'\t" (een tabblad) , "'\u20AC" (een euroteken) . Dit systeem van het gebruik van enkele en dubbele aanhalingen is vreemd en omslachtig, maar het is een manier om char waarden te onderscheiden van Strings op een manier die werkt met spreadsheets. Een waarde die eruit ziet als een teken maar ongeldig is zal een foutmelding genereren. Net als bij Strings is het gebruik van tekens groter dan #255 momenteel ontmoedigd.
Achtervoegsel
Merk op dat in de attributensectie van een NCCSV-bestand alle numerieke attribuutwaarden een achtervoegselletter moeten hebben (b.v.) om het numerieke gegevenstype te identificeren (bv. byte) . Maar in de gegevenssectie van een NCCSV-bestand mogen numerieke gegevenswaarden nooit deze achtervoegselletters hebben (met uitzondering van 'L' voor lange gehele getallen) Het gegevenstype wordt gespecificeerd door de\*GEGEVENS\_TYPE\*attribuut voor de variabele.
DATA_TYPE
Het gegevenstype voor elke niet-scalarvariabele moet worden gespecificeerd door a\*GEGEVENS\_TYPE\*attribuut dat een waarde van byte kan hebben, short, int, long, float, double, String, of char (hoofdletter ongevoelig) . Bijvoorbeeld, qc\_vlag,\GEGEVENS\_TYPE\,byte WAARSCHUWING: Het juiste specificeren\*GEGEVENS\_TYPE\*is jouw verantwoordelijkheid. Het verkeerde gegevenstype specificeren (b.v., int wanneer je float had moeten opgeven) zal geen foutmelding genereren en kan leiden tot verlies van informatie (bv. floatwaarden worden afgerond op ints) wanneer het NCCSV-bestand wordt gelezen doorERDDAP™of omgezet in eenNetCDFbestand.
Char ontmoedigd
Het gebruik van char data waarden wordt ontmoedigd omdat ze niet breed worden ondersteund in andere bestandstypen. tekenwaarden kunnen in de gegevenssectie worden geschreven als afzonderlijke tekens of als tekenreeksen (vooral als je een speciaal karakter moet schrijven) . Als een tekenreeks wordt gevonden, zal het eerste teken van de tekenreeks worden gebruikt als de waarde van de tekenreeks. Nul lengte tekenreeksen en ontbrekende waarden worden omgezet naar teken \uFFFF. Merk op datNetCDFbestanden ondersteunen alleen enkele byte tekens, dus alle tekens groter dan teken #255 zal worden omgezet in '?' bij het schrijvenNetCDFdossiers. Tenzij een tekensetattribuut wordt gebruikt om een andere tekenset voor een tekensetvariabele op te geven, wordt de ISO-8859-1 tekenset gebruikt.
Lang ontmoedigd
Hoewel veel bestandstypen (bv.NetCDF-4 en json) enERDDAP™ondersteunen lange data waarden, het gebruik van lange data waarden in NCCSV bestanden is momenteel ontmoedigd omdat ze momenteel niet worden ondersteund door Excel, CF enNetCDF- Drie dossiers. Als u lange gegevenswaarden wilt opgeven in een NCCSV-bestand (of in het bijbehorende Excel-spreadsheet) , moet je het achtervoegsel 'L' gebruiken zodat Excel de getallen niet behandelt als zwevende puntnummers met lagere precisie. Momenteel, als een NCCSV-bestanden wordt omgezet in eenNetCDF-3.ncbestand, lange data waarden worden omgezet in dubbele waarden, waardoor een verlies van precisie voor zeer grote waarden (minder dan -2^53 of meer dan 2^53) .
CF, ACDD, enERDDAP™Metadata
Aangezien het is voorzien dat de meeste NCCSV-bestanden, of de.ncbestanden gemaakt van hen, zal worden ingelezen inERDDAP, is het sterk aanbevolen dat NCCSV-bestanden de metagegevens attributen die zijn vereist of aanbevolen doorERDDAP™(zie /docs/server-admin/datasets#global-attributes). De attributen zijn bijna allemaal afkomstig van de CF en ACDD metadata standaarden en dienen om de dataset correct te beschrijven (wie, wat, wanneer, waar, waarom, hoe) aan iemand die anders niets weet over de dataset. Van bijzonder belang, bijna alle numerieke variabelen moeten een eenheden attribuut met eenUDUNITS-compatibele waarde, bv. sst,units,grade\_C
Het is prima om aanvullende attributen op te nemen die niet afkomstig zijn van de CF- of ACDD-normen of vanERDDAP.
De afdeling Gegevens
Structuur
De eerste regel van de gegevenssectie moet een hoofdlettergevoelige, door komma's gescheiden lijst van variabele namen bevatten. Alle variabelen in deze lijst moeten worden beschreven in de metagegevens sectie, en vice versa (andere dan\GLOBAL\attributen en\SCALAR\variabelen) .
De tweede door de voorlaatste regels van de data sectie moet een door komma's gescheiden lijst van waarden hebben. Elke rij gegevens moet hetzelfde aantal waarden hebben als de door komma's gescheiden lijst van variabele namen. Ruimten voor of na waarden zijn niet toegestaan omdat ze problemen veroorzaken bij het importeren van het bestand in spreadsheet programma's. Elke kolom in deze sectie mag alleen waarden van de\*GEGEVENS\_TYPE\*gespecificeerd voor die variabele door de\*GEGEVENS\_TYPE\*attribuut voor die variabele. Anders dan in de sectie attributen mogen numerieke waarden in de gegevenssectie geen achtervoegselletters hebben om het gegevenstype aan te duiden. Anders dan in de attributen sectie, kunnen tekenswaarden in de gegevens sectie de omsluiten enkele aanhalingen weglaten als ze niet nodig zijn voor disambiguatie (Dus, ',' en '\' moeten worden geciteerd zoals hier getoond) . Er kan een aantal van deze gegevens rijen in een NCCSV bestand, maar momenteelERDDAP™kan alleen NCCSV-bestanden lezen met maximaal 2 miljard rijen. In het algemeen wordt aanbevolen dat u grote datasets splitst in meerdere NCCSV-gegevensbestanden met minder dan 1 miljoen rijen elk.
Eindgegevens
Het einde van de gegevenssectie moet worden aangeduid met een regel met alleen \END\_DATA\
Als er na de\*END\_DATA\*regel, het zal worden genegeerd wanneer het NCCSV bestand wordt omgezet in een.ncbestand. Dergelijke inhoud wordt daarom ontmoedigd.
In een spreadsheet na deze conventies zullen de variabele namen en gegevenswaarden in meerdere kolommen staan. Zie het voorbeeld hieronder.
Ontbrekende waarden
Numerieke ontbrekende waarden kunnen worden geschreven als een numerieke waarde die door eenmissing\_valueof \_FillValue attribuut voor die variabele. Zie bijvoorbeeld de tweede waarde op deze gegevensrij: Bell M. Shimada,99,123,4 Dit is de aanbevolen manier om ontbrekende waarden voor byte, korte, int en lange variabelen te behandelen.
float of dubbele NaN-waarden kunnen worden geschreven als NaN. Zie bijvoorbeeld de tweede waarde op deze gegevensrij: Bell M. Shimada, NaN,123.4
Tekenreeks en numerieke ontbrekende waarden kunnen worden aangegeven door een leeg veld. Zie bijvoorbeeld de tweede waarde op deze gegevensrij: Bell M. Shimada, 123,4
Voor byte, korte, int, en lange variabelen, de NCCSV converter utility enERDDAP™zal een leeg veld omzetten in de maximaal toegestane waarde voor dat gegevenstype (bv. 127 voor bytes) . Als u dit doet, moet u eenmissing\_valueof \_FillValue attribuut voor die variabele om deze waarde te identificeren, bijvoorbeeld, variabele Naam ,\_FillValue,127b Voor float en dubbele variabelen wordt een leeg veld omgezet naar NaN.
Datumtijd
Datumtijd (inclusief datumwaarden die geen tijdcomponent hebben) kan worden weergegeven als getallen of als tekenreeksen in NCCSV-bestanden. Een gegeven datumTijdvariabele mag alleen tekenreekswaarden of alleen numerieke waarden hebben, niet beide. De NCCSV software zal String datumTijd waarden omzetten in numerieke datum Tijdswaarden bij aanmaken.ncbestanden (zoals vereist door CF) . TekstdatumTijdwaarden hebben het voordeel dat ze gemakkelijk leesbaar zijn door mensen.
Datumtijdswaarden die als numerieke waarden worden weergegeven, moeten een eenheidsattribuut hebben dat de " eenheden sinds datum Tijd " zoals vereist door CF en gespecificeerd doorUDUNITS, bijvoorbeeld, time,units,seconden sinds 1970-01-01T00:00:00Z
DatumTijd waarden weergegeven als tekenreeks waarden moeten een tekenreeks hebben\*GEGEVENS\_TYPE\*attribuut en een eenheidsattribuut dat een datum specificeert Tijdpatroon zoals gespecificeerd door deJavaDatumTijdFormatter klasse ( https://docs.oracle.com/javase/8/docs/api/java/time/format/DateTimeFormatter.html ) . Bijvoorbeeld, tijd, eenheden,yyyy-MM-dd'T'HH:mm:ssZ Alle datumTijdswaarden voor een gegeven gegevensvariabele moeten hetzelfde formaat gebruiken. In de meeste gevallen zal het dateTijd patroon dat u nodig hebt voor de eenheden attribuut een variatie van een van deze formaten zijn:
- yyyy-MM-dd'T'HH:mm:ss. ISO 8601:2004 (E) datum Tijdformaat. U kunt een verkorte versie van dit, bijvoorbeeld,yyyy-MM-dd'T'HH:mm:ssZ (het enige aanbevolen formaat) ofyyyy-MM-dd. Als u het formaat van uw datum wijzigtTijdwaarden, NCCSV raadt u sterk aan om dit formaat te wijzigen (misschien ingekort) . Dit is het formaat datERDDAP™zal gebruiken wanneer het NCCSV-bestanden schrijft.
- jjjjMMddHHmmss.SSS Tijdformaat. U kunt een verkorte versie van dit, bijvoorbeeld jjjjMMdd.
- M/d/jjjj H:mm:ss. › waarin data en datum in Amerikaanse stijl worden verwerktTijden zoals "3/23/2017 16:22:03.000." U kunt een verkorte versie hiervan nodig hebben, bijvoorbeeld M/d/jjjj .
- jjjjDDDHHmmssSSS (Bijvoorbeeld, 001 = 1 januari, 365 = 31 december in een niet-leap jaar; dit wordt soms ten onrechte de Juliaanse datum genoemd) . U kunt een verkorte versie van dit, bijvoorbeeld jjjjDDD .
Precisie
Wanneer een softwarebibliotheek een.ncbestand in een NCCSV bestand, alle datum Tijdswaarden worden geschreven als tekenreeksen met de ISO 8601:2004 (E) datum Tijdformaat, bv. 1970-01-01T00:00:00Z . U kunt de precisie met deERDDAP-specifieke eigenschaptime\_precision. Zie /docs/server-admin/datasets#time\_precision.
Tijdzone
De standaard tijdzone voor datum Tijdswaarden zijn deZulu (of GMT) tijdzone, die geen lokale tijdsperioden heeft. Als een datumTijd variabele datumTijd waarden uit een andere tijdzone, moet u dit specificeren met deERDDAP-specifieke eigenschaptime\_zone. Dit is een vereiste voorERDDAP™(zie /docs/server-admin/datasets#time\_zone).
Graadwaarden
Zoals vereist door CF, alle graden waarden (bv. voor lengte- en breedtegraad) moet worden gespecificeerd als decimale graad dubbele waarden, niet als een graden°min'sec" tekenreeks of als afzonderlijke variabelen voor graden, minuten, seconden. De richtingsontwerpers N, S, E en W zijn niet toegestaan. Gebruik negatieve waarden voor de westelijke en zuidelijke breedtegraden.
DSG Kenmerken
Een NCCSV-bestand kan CF Discrete Sampling Geometry bevatten ( https://cfconventions.org/Data/cf-conventions/cf-conventions-1.8/cf-conventions.html#discrete-sampling-geometries ) gegevens. Het zijn de eigenschappen die dit laten werken:
- Zoals vereist door CF, moet het NCCSV-bestand een regel bevatten in de metagegevens sectie die de\GLOBAL\ featureTypeattribuut, bijvoorbeeld, \GLOBAL\,featureType,trajectory
- Voor gebruik inERDDAP™, het NCCSV bestand moet een regel of regels bevatten in de metadata sectie die de cf\_role=...\_id variabelen identificeren, bijvoorbeeld, ship,cf\_role,trajectory\_id Dit is facultatief voor CF, maar vereist in NCCSV.
- Voor gebruik inERDDAP™, het NCCSV-bestand moet een regel of regels in de metagegevens sectie bevatten om te bepalen welke variabelen worden geassocieerd met elke tijdSerie, traject of profiel zoals vereist doorERDDAP™(zie /docs/server-admin/datasets#cdm\_data\_type), bijvoorbeeld, \GLOBAL\,cdm\_trajectory\_variabeles,"ship" of \GLOBAL\,cdm\_timeserie\_variabelen,"station\_id,lat,lon"
Voorbeeldbestand
Hier is een voorbeeldbestand dat veel van de functies van een NCCSV-bestand toont:
\\*GLOBAL\\*,Conventions,"COARDS, CF-1.6, ACDD-1.3, NCCSV-1.0"
\\*GLOBAL\\*,cdm\\_trajectory\\_variables,"ship"
\\*GLOBAL\\*,creator\\_email,erd.data@noaa.gov
\\*GLOBAL\\*,creator\\_name,Bob Simons
\\*GLOBAL\\*,creator\\_type,person
\\*GLOBAL\\*,creator\\_url,https://www.pfeg.noaa.gov
\\*GLOBAL\\*,featureType,trajectory
\\*GLOBAL\\*,infoUrl,https://erddap.github.io/docs/user/nccsv-1.00
\\*GLOBAL\\*,institution,"NOAA NMFS SWFSC ERD, NOAA PMEL"
\\*GLOBAL\\*,license,"""NCCSV Demonstration"" by Bob Simons and Steve Hankin is
licensed under CC BY 4.0, https://creativecommons.org/licenses/by/4.0/ ."
\\*GLOBAL\\*,keywords,"NOAA, sea, ship, sst, surface, temperature, trajectory"
\\*GLOBAL\\*,standard\\_name\\_vocabulary,CF Standard Name Table v55
\\*GLOBAL\\*,subsetVariables,"ship"
\\*GLOBAL\\*,summary,"This is a paragraph or two describing the dataset."
\\*GLOBAL\\*,title,"NCCSV Demonstration"
ship,\\*DATA\\_TYPE\\*,String
ship,cf\\_role,trajectory\\_id
time,\\*DATA\\_TYPE\\*,String
time,standard\\_name,time
time,units,"yyyy-MM-dd'T'HH:mm:ssZ"
lat,\\*DATA\\_TYPE\\*,double
lat,units,degrees\\_north
lon,\\*DATA\\_TYPE\\*,double
"lon","units","degrees\\_east"
status,\\*DATA\\_TYPE\\*,char
status,comment,"From http://some.url.gov/someProjectDocument , Table C"
testLong,\\*DATA\\_TYPE\\*,long
testLong,units,1
sst,\\*DATA\\_TYPE\\*,float
sst,standard\\_name,sea\\_surface\\_temperature
sst,actual\\_range,0.17f,23.58f
sst,units,degree\\_C
sst,missing\\_value,99f
sst,testBytes,-128b,0b,127b
sst,testShorts,-32768s,0s,32767s
sst,testInts,-2147483648i,0i,2147483647i
sst,testLongs,-9223372036854775808L,0L,9223372036854775807L
sst,testFloats,-3.40282347e38f,0f,3.40282347E+38f
sst,testDoubles,-1.79769313486231570e308d,0d,1.79769313486231570E+308d
sst,testChars,"','","'""'","'\\u20AC'"
sst,testStrings," a~,\\n'z""\\u20AC"
\\*END\\_METADATA\\*
ship,time,lat,lon,status,testLong,sst
Bell M. Shimada,2017-03-23T00:45:00Z,28.0002,-130.2576,A,-9223372036854775808L,10.9
Bell M. Shimada,2017-03-23T01:45:00Z,28.0003,-130.3472,\\u20AC,-1234567890123456L,
"Bell M. Shimada","2017-03-23T02:45:00Z",28.0001,-130.4305,"'\\t'",0L,10.7
Bell M. Shimada,2017-03-23T12:45:00Z,27.9998,-131.5578,"'""'",1234567890123456L,99
Bell M. Shimada,2017-03-23T21:45:00Z,28.0003,-132.0014,\\u00fc,9223372036854775806L,10.0
Bell M. Shimada,2017-03-23T23:45:00Z,28.0002,-132.1591,,NaN
Opmerkingen:
- Dit voorbeeldbestand bevat vele moeilijke gevallen (bijv. char en lange variabelen en moeilijke tekenreekswaarden) . De meeste NCCSV-bestanden zullen veel eenvoudiger zijn.
- De licentieregel is hier in twee regels gebroken, maar is slechts één regel in het voorbeeldbestand.
- \u20AC is de codering van het Euroteken en \u00FC is de codering van ü.
- Veel Tekenreeksen in het voorbeeld worden ingesloten door dubbele aanhalingstekens, ook al hoeven ze niet, bijvoorbeeld, vele globale attributen te zijn, waaronder de titel, de lon units attribuut, en de 3e regel van gegevens.)
- Het zou duidelijker en beter zijn als de eenhedenattribuut voor de testLange variabele werden geschreven in dubbele aanhalingstekens die aangeven dat het een tekenreekswaarde is. Maar de huidige vertegenwoordiging (1, zonder quotes) zal correct worden geïnterpreteerd als een tekenreeks, geen geheel getal, omdat er geen 'i' achtervoegsel is.
- In tegenstelling tot andere numerieke gegevenstypes hebben de lange waarden in de gegevenssectie het achtervoegsel ('L') die hun numerieke gegevenstype identificeren. Dit is nodig om te voorkomen dat spreadsheets de waarden interpreteren als zwevende puntnummers en daardoor de precisie verliezen.
Werkbladen
In een spreadsheet, zoals in een NCCSV bestand:
- Schrijf numerieke attribuutwaarden zoals gespecificeerd voor NCCSV-bestanden (b.v. met een achtervoegselletter, bijvoorbeeld 'f', om het gegevenstype van het attribuut te identificeren) .
- In Strings, schrijf alle karakters minder dan ASCII karakter #32 of groter dan karakter #126 als ofwel een JSON-achtige backslashed karakter (bv.\nvoor nieuwe regel) of als hexadecimaal Unicode tekennummer (hoofdletter ongevoelig) met de syntax\u Hhhh (bv. \u20AC voor het Euroteken) . Gebruik\n (2 tekens: backslash en 'n ') om een nieuwe regel aan te geven, niet Alt Enter.
De enige verschillen tussen NCCSV-bestanden en de analoge spreadsheet die deze conventies volgen zijn:
- NCCSV-bestanden hebben waarden op een lijn gescheiden door komma's. Spreadsheets hebben waarden op een regel in aangrenzende cellen.
- Strings in NCCSV-bestanden worden vaak omgeven door dubbele citaten. Strings in spreadsheets worden nooit omringd door dubbele citaten.
- Interne dubbele citaten (") in Strings in NCCSV-bestanden verschijnen als 2 dubbele citaten. Interne dubbele citaten in spreadsheets verschijnen als 1 dubbele quote.
Als een spreadsheet na deze conventies wordt opgeslagen als een CSV-bestand, zullen er vaak extra komma's aan het einde van veel van de regels. De software die NCCSV bestanden converteert in.ncbestanden zullen de extra komma's negeren.
Excel
Om een NCCSV-bestand in Excel te importeren:
- Kies Bestand: Openen.
- Het bestandstype wijzigen naar tekstbestanden (\.prn;\.txt; \*.csv) .
- Doorzoek de mappen en klik op het NCCSV .csv bestand.
- Klik op Openen.
Om een NCCSV-bestand te maken van een Excel-spreadsheet:
- Bestand kiezen: Opslaan als .
- Opslaan als type wijzigen: CSV zijn (Comma afgebakend) (\*.csv) .
- Als reactie op de compatibiliteit waarschuwing, klik op Ja .
- Het resulterende .csv bestand zal extra komma's hebben aan het einde van alle rijen anders dan de CSV rijen. Je kunt ze negeren.
In Excel verschijnt het voorbeeld NCCSV bestand hierboven als
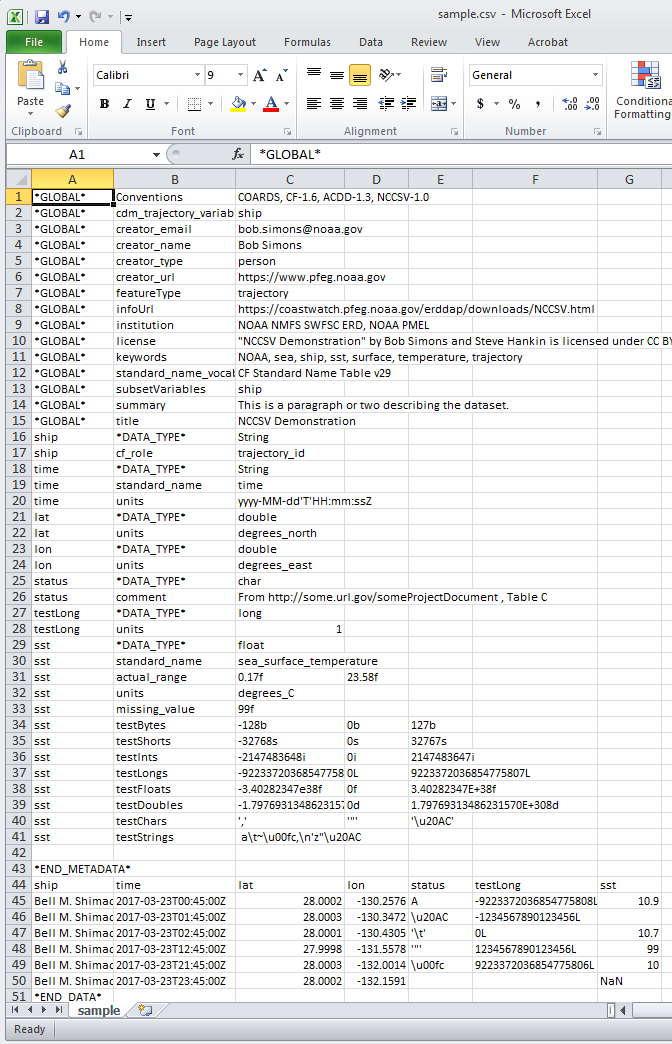
Google-sheets
Om een NCCSV-bestand in Google Sheets te importeren:
- Kies Bestand: Openen.
- Kies om een bestand te uploaden en klik op Upload een bestand van uw computer. Selecteer het bestand en klik vervolgens op Openen.
Of kies Mijn Drive en wijzig het bestandstype drop-down selectie naar Alle bestandstypen . Selecteer het bestand en klik vervolgens op Openen.
Om een NCCSV-bestand te maken van een Google Sheets spreadsheet:
- Bestand kiezen: Opslaan als .
- Opslaan als type wijzigen: CSV zijn (Comma afgebakend) (\*.csv) .
- Als reactie op de compatibiliteit waarschuwing, klik op Ja .
- Het resulterende .csv bestand zal extra komma's hebben aan het einde van alle rijen anders dan de CSV rijen. Negeer ze.
Problemen/waarschuwingen
- Als je een NCCSV-bestand maakt met een teksteditor of als je een analoge spreadsheet maakt in een spreadsheetprogramma, zal de teksteditor of het spreadsheetprogramma niet controleren of je deze conventies correct hebt gevolgd. Het is aan u om deze conventies correct te volgen.
- De omzetting van een spreadsheet na deze conventie in een csv-bestand (dus een NCCSV-bestand) zal leiden tot extra komma's aan het einde van alle rijen andere dan de CSV-gegevensrijen. Negeer ze. De software zet vervolgens NCCSV bestanden in.ncbestanden zullen ze negeren.
- Als een NCCSV bestand heeft overtollige komma's aan het einde van rijen, kunt u ze verwijderen door het NCCSV bestand te converteren naar eenNetCDFbestand en vervolgens converteren van deNetCDFbestand terug in een NCCSV bestand.
- Wanneer u probeert om een NCCSV-bestand te converteren naar eenNetCDFbestand, sommige fouten zullen worden gedetecteerd door de software en zal foutmeldingen genereren, waardoor de conversie te mislukken. Andere problemen zijn moeilijk of onmogelijk te vangen en zullen geen foutmeldingen of waarschuwingen genereren. Andere problemen (b.v. overtollige komma's aan het einde van rijen) zal genegeerd worden. De file converter zal slechts minimale controle van de juistheid van de resulterendeNetCDFbestand, bijvoorbeeld wat betreft de naleving van het CF. Het is de verantwoordelijkheid van de bestandsmaker en de gebruiker om te controleren of de resultaten van de conversie zijn zoals gewenst en correct. Twee manieren om te controleren zijn:
- Print de inhoud van de.ncbestand met nudump ( https://linux.die.net/man/1/ncdump ) .
- Bekijk de inhoud van de gegevens inERDDAP.